【世界模型】INSPATIO-WORLD: A Real-Time 4D World Simulator via Spatiotemporal Autoregressive Modeling

标题:INSPATIO-WORLD:基于时空自回归建模的实时四维世界模拟器
原文链接:https://arxiv.org/pdf/2604.07209
源码链接:https://inspatio.github.io/inspatio-world/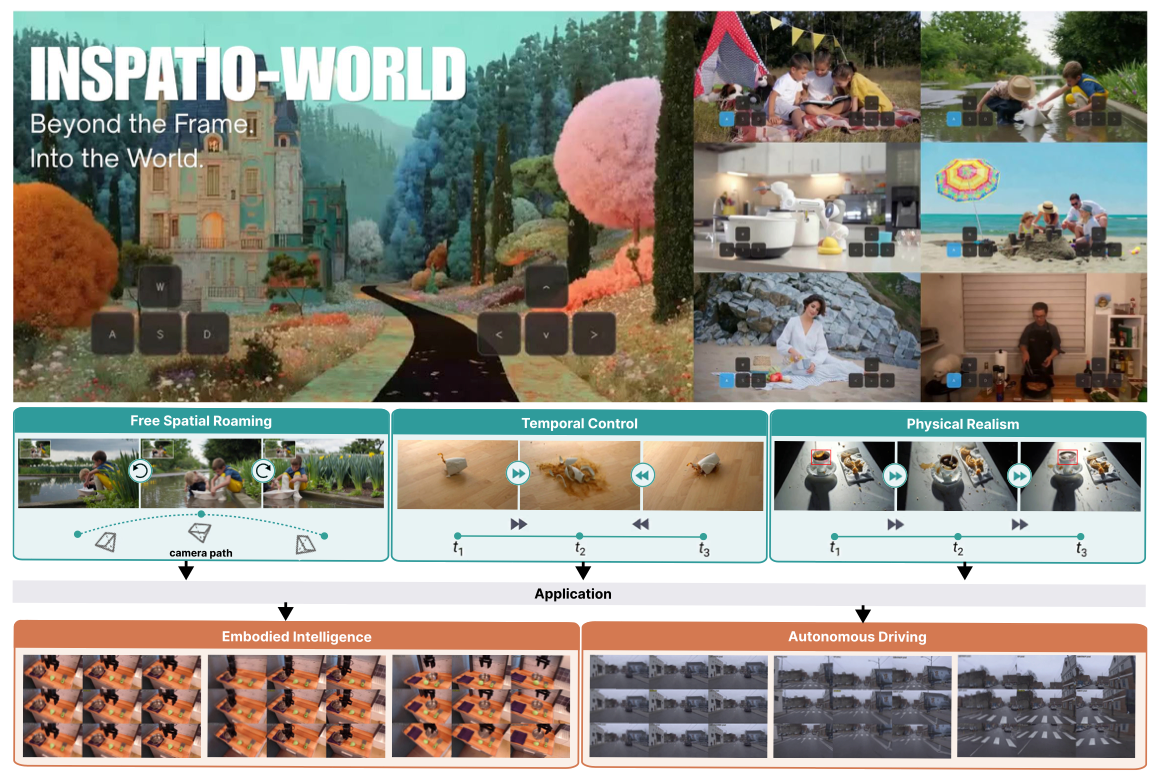
图1:INSPATIO-WORLD:迈向通用四维世界模拟器。顶部:本框架可从单段视频合成多样化动态场景,支持实时、高自由度交互式四维漫游体验。中部:系统由三大核心能力驱动:沿用户自定义相机轨迹的自由空间漫游、对动态场景演化的时序控制,以及物理真实性的保持。底部:这些能力赋予INSPATIO-WORLD作为实时四维新视角渲染引擎的潜力,有望支撑具身智能、自动驾驶等下游任务。
摘要
构建具备空间一致性与实时交互性的世界模型,是计算机视觉领域的核心挑战。当前视频生成范式往往面临空间持久性不足、视觉真实度欠缺的问题,难以支撑复杂环境下的无缝漫游。为解决这些难题,本文提出INSPATIO-WORLD,一种全新的实时框架,能够从单段参考视频中重建并生成高保真、动态交互式场景。
本方法的核心是**时空自回归(STAR)**架构,通过两个紧密耦合的组件实现场景的一致性与可控演化:隐式时空缓存将参考观测与历史观测聚合为潜在世界表征,确保长时程漫游中的全局一致性;显式空间约束模块强化几何结构,并将用户交互转化为精准且符合物理规律的相机轨迹。
此外,本文提出**联合分布匹配蒸馏(JDMD)**方法。该方法以真实世界数据分布作为正则化引导,有效克服了过度依赖合成数据导致的保真度下降问题。
大量实验表明,INSPATIO-WORLD在空间一致性与交互精度上显著超越现有最优(SOTA)模型,在WorldScore-Dynamic基准测试的实时/交互式方法中位列第一,并构建了一套可用于单目视频重建四维环境漫游的实用流程。
项目主页:https://inspatio.github.io/inspatio-world/
代码仓库:https://github.com/inspatio/inspatio-world
1 引言
构建具备空间一致性与实时交互性的世界模型,是计算机视觉领域的核心目标。随着视频扩散模型的近期发展,从文本合成高质量动态视频的能力已展现出模拟物理世界复杂特性的巨大潜力。尤其是交互式视频生成的兴起,使得在生成环境中实现实时漫游与动态反馈成为可能,为构建高自由度虚拟世界奠定了基础。
尽管现有视频扩散模型能够合成视觉效果出色的短片段,但在复杂动态环境中进行长时程漫游任务时,仍面临根本性挑战。当前方法主要受限于以下三大瓶颈:
- 空间持久性退化:现有自回归框架缺乏有效的记忆机制与显式几何引导,导致长期运行或大视角切换时出现场景结构丢失、环境状态偏移或漂移问题。
- 合成-真实域差异:由于过度依赖合成训练数据,生成视频在光照、纹理、材质属性等方面与真实世界视觉统计分布存在偏差。
- 控制精度不足:现有模型普遍无法精准执行用户自定义轨迹,反映出其底层空间几何推理能力的根本性缺陷。
为突破上述瓶颈,本文提出INSPATIO-WORLD,一种全新的实时四维世界模型。与现有世界模型不同,INSPATIO-WORLD不局限于文本与图像输入,而是支持将参考视频转化为可实时交互的“鲜活世界”。
本文的核心创新分为两方面:
- 架构层面,提出**时空自回归(STAR)**框架。该架构可将单目视频转化为动态、交互式、沉浸式的漫游体验,同时有效提升空间一致性与交互控制精度。具体而言,本文设计隐式时空缓存,在固定滑动窗口内聚合参考帧与历史生成信息,构建耦合的长短时记忆机制,确保实时探索中长程生成的时序稳定性。在此基础上,通过引入显式空间约束,将用户交互转化为精准相机轨迹,并无缝融入空间推理流程,实现高精度相机可控生成。显式空间约束的概念最初在本文团队的前期工作InSpatio-WorldFM中探索,本文将其推广至视频生成模型,并赋予其可选的空间记忆机制。
- 学习机制层面,提出**联合分布匹配蒸馏(JDMD)**方法,缓解合成训练数据固有的视觉外观退化问题。该方法将训练分解为两个互补的蒸馏任务:可控视频重渲染(视频到视频,V2V),从合成数据中学习精准运动控制与时序一致性;文本到视频(T2V)任务,捕获与真实世界数据分布对齐的文本条件生成。核心机制在于两个任务的统一权重共享。从真实世界T2V分布中提取的梯度引导,推动共享特征空间向高保真分布对齐与校准。由此,V2V任务在保持高精度可控性的同时,直接受益于真实世界分布的优质纹理细节与光照保真度,实现可控生成与照片级真实感的协同。此外,两个任务迥异的输入结构避免了运动控制学习与视觉保真度优化之间的梯度干扰,使模型在严格遵循指定输入条件的同时优化视觉质量。
本文主要贡献总结如下:
- 提出INSPATIO-WORLD,一种全新的单目视频时空漫游实时框架,开源代码与模型。
- 提出时空自回归(STAR)架构,通过隐式时空缓存与显式空间约束,实现实时、高一致性、高精度的相机控制(3.2节)。
- 提出联合分布匹配蒸馏(JDMD),一种权重共享多任务学习框架,利用真实世界数据分布引导学生模型的特征空间对齐,有效提升生成区域的保真度(3.3节)。
- 大量定量与定性实验表明,INSPATIO-WORLD在运动鲁棒性与视觉质量上显著超越现有生成式世界模型。此外,本系统实现24帧/秒的实时性能,同时保持卓越的时空一致性。
2 相关工作
视频扩散模型
视频扩散模型已成为高保真视频生成的主流范式。近年来,架构从传统U-Net转向更具扩展性的基于Transformer的设计,带来更优的真实感与动态保真度。这一基础进展为构建更复杂、交互式的时空仿真提供了强大的生成骨干网络。其中,Wan2.1作为开源模型展现出优异的生成能力,因此被选为本工作的骨干网络。
新视角合成与相机可控生成
经典新视角合成方法依赖显式三维表征,如神经辐射场或三维高斯泼溅,这类方法需要多视角输入且需针对每个场景优化。近期研究积极探索基于扩散模型的相机可控视频生成。部分方法通过交叉注意力、通道拼接或普吕克嵌入直接注入相机参数。为提供更强的几何保真度并缓解数值位姿信号与视觉内容之间的跨模态对齐差距,基于渲染的方法通过将深度提升至点云并使用渲染代理视频,融入显式三维感知条件,例如Gen3C、MVGenMaster、TrajectoryCrafter等方法。此外,已有多项无需训练的方法被提出以实现灵活的相机控制。
针对开放式生成与动态场景探索,Infinite-World、CameraCtrl II、LingBot-World、Google Genie 3、World Labs RTFM、Matrix-game 2.0等方法瞄准无边界长时程生成。然而,这些现有方法因缺乏有效记忆机制与显式几何引导,从根本上面临空间持久性退化问题;因过度依赖合成训练数据,产生视觉统计上的合成-真实域差异;且因底层空间几何推理能力不足,导致控制精度欠缺。
与之相对,INSPATIO-WORLD通过将参考帧注入键值缓存作为全局时空锚点,并利用联合分布匹配蒸馏将显式三维约束与隐式空间记忆、真实世界先验相结合,系统性地突破这些瓶颈,实现高保真、精准可控的空间漫游。
自回归视频扩散
自回归范式通过将序列建模为逐步条件分布,实现无界长度生成,逐渐受到关注。传统方法通过下一token预测,逐一生成时空token。近期,融合自回归与扩散框架的混合模型成为视频与其他连续序列生成建模的有潜力方向。此外,滚动扩散变体采用渐进式噪声调度进行序列生成,但其对未来帧的过早承诺限制了对用户注入控制的实时响应能力。
在自回归扩散范式中,CausVid引入因果注意力掩码将双向模型转化为自回归模型,而Self-Forcing弥合训练-测试差异以实现基于键值缓存的流式生成。然而,这些方法天生缺乏融入实时动态控制信号(如连续相机轨迹或几何约束)的机制,因此无法支撑交互式四维漫游,即无法将实时用户意图转化为确定性的场景探索。
为打破这一局限,INSPATIO-WORLD显式设计多条件自回归通路,无缝注入动态空间约束,将被动流式生成转化为高可控、长时程的交互式导航。
分布匹配蒸馏
扩散模型的推理效率长期以来是限制其实际应用的主要瓶颈。尽管生成对抗网络近期被重新用于蒸馏视频扩散模型,但将生成分布与高保真目标对齐仍具挑战。早期加速方案(如DDIM或采样器优化)取得可观效果,但难以实现极短步数(如4步)生成。为实现这一目标,渐进式蒸馏通过在每个阶段将步数减半,逐步压缩采样轨迹。与之相对,一致性模型沿常微分方程轨迹学习一致性映射,尝试单步从噪声重建图像。
分布匹配蒸馏的出现标志着蒸馏范式的转变。然而,其现有应用主要聚焦于单教师设置。在相机可控生成中,单纯从运动条件教师(通常在合成数据上训练)进行蒸馏,不可避免地将学生模型推向合成域偏移,导致严重的感知退化、纹理平滑与类塑料伪影。
为打破几何控制与视觉质量之间的零和博弈,本工作将分布匹配蒸馏扩展至联合双教师架构。通过协同利用感知教师提供物理先验正则化、运动教师实现精准几何对齐,INSPATIO-WORLD在不损失精确相机控制的前提下,确保高保真纹理保留。
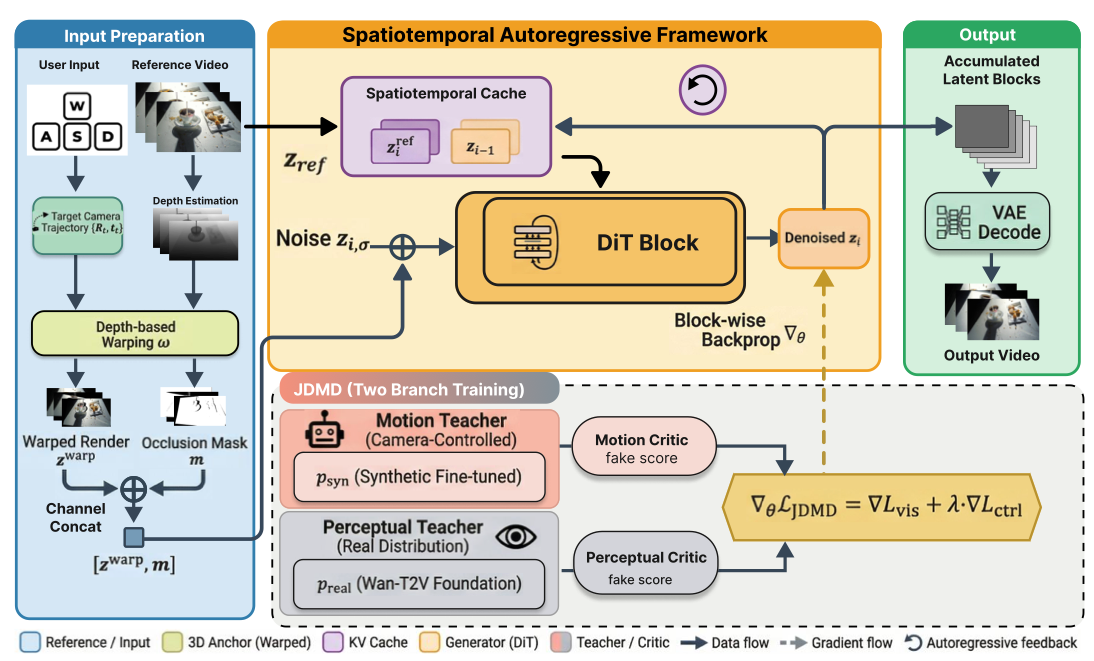
图2:时空自回归框架与联合分布匹配蒸馏(JDMD)流程架构
该框架利用参考信息与历史生成结果构建时空缓存,借助基于深度的扭曲操作建立显式几何约束,以实现一致性自回归视频生成。联合分布匹配蒸馏阶段采用权重共享的多任务蒸馏机制,由包含感知教师与运动教师的双教师架构提供监督。
3 方法
3.1 问题建模
为实现多模态约束下的长时程生成,本文将生成过程建模为分块条件自回归任务,每个块由连续 K K K 帧构成。给定全局参考上下文 C r e f C_{ref} Cref 与一组实时用户交互指令 T \mathcal{T} T,本文目标是建模潜在序列 Z 1 : I Z_{1:I} Z1:I 的分布。遵循 Self-Forcing 方法,本文应用概率链式法则将该分布分解为逐步骤条件概率的乘积:
p ( Z 1 : I ∣ C r e f , T ) = ∏ i = 1 T p ( z i ∣ z < i , c i r e f , τ i ) p\left(Z_{1:I} | C_{ref}, \mathcal{T}\right)=\prod_{i=1}^{T} p\left(z_{i} | z_{<i}, c_{i}^{ref}, \tau_{i}\right) p(Z1:I∣Cref,T)=i=1∏Tp(zi∣z<i,ciref,τi)
其中,第 i i i 个块 z i z_{i} zi 的生成受历史上下文 z < i z_{<i} z<i、参考引导 c i r e f c_{i}^{ref} ciref 与交互项 τ i \tau_{i} τi 的联合约束。
3.2 时空自回归框架
为保障长时程交互式漫游中的空间持久性与交互精度,本文提出时空自回归框架。该框架包含两个核心组件:
- 通过聚合历史帧与参考帧构建隐式时空缓存,利用短期历史记忆与长期参考信息联合引导生成过程,维持时序连续性与空间一致性。
- 融入参考帧的几何信息以提升多视角一致性,系统将用户控制指令转化为显式空间约束,实现高精度相机控制。
最终,系统将隐式记忆状态与显式几何约束协同注入扩散Transformer(DiT),实现高保真、实时的交互式动态环境生成。
在该框架下,生成第 i i i 个块的去噪过程可表示为:
z ^ i = Denoise θ ( z i , σ ∣ z < i , z i r e f , [ z i w a r p , m i ] ) \hat{z}_{i}= \text{Denoise}_{\theta}\left(z_{i, \sigma} | z_{<i}, z_{i}^{ref},\left[z_{i}^{warp }, m_{i}\right]\right) z^i=Denoiseθ(zi,σ∣z<i,ziref,[ziwarp,mi])
其中 Z i , σ Z_{i, \sigma} Zi,σ 为噪声水平 σ \sigma σ 下第 i i i 个块的初始潜在表示。模型受三类条件协同约束:
- 历史条件 ( z < i ) (z_{<i}) (z<i):先前块的生成潜在表示,承载局部时序上下文,保障块间运动平滑与逻辑连续性。
- 参考条件 ( z i r e f ) (z_{i}^{ref}) (ziref):从参考视频中实时检索并压缩的对应潜在表示,作为全局空间锚点,确保模型在长时程漫游后仍能精准回溯原始场景的纹理与语义特征。
- 几何条件 ( [ z i w a r p , m i ] ) ([z_{i}^{warp }, m_{i}]) ([ziwarp,mi]):由当前交互指令 τ i \tau_{i} τi 驱动的显式约束。其中 z i w a r p z_{i}^{warp } ziwarp 为几何对齐的重投影特征, m i m_{i} mi 为有效像素掩码,二者共同提供确定性空间结构引导,避免场景畸变。
3.2.1 可微重计算的时空缓存机制
为有效缓解自回归生成中常见的状态漂移,并满足交互式实时推理需求,本文提出时空缓存机制。该机制的核心是融合短期时序信息(历史帧)与长期时空锚点(参考帧),以恒定的键值缓存内存开销实现高保真端到端内容生成。具体而言,生成第 i i i 个块时,系统从参考视频中检索对应潜在表示 z i r e f z_{i}^{ref} ziref 作为全局稳定的时空锚点;同时,为保障运动平滑性,先前生成的潜在表示 Z i − 1 Z_{i-1} Zi−1 以滑动窗口形式存入缓存,既避免长序列推理时的内存溢出,又维持局部时序连续性。
此外,为解决长时程推理中旋转位置编码(RoPE)随序列长度增长引发的分布偏移,本文采用位置索引固定策略。将当前块 z i z_{i} zi、参考锚点 z i r e f z_{i}^{ref} ziref 与历史块 z i − 1 z_{i-1} zi−1 的起始位置索引锚定至预设绝对坐标原点(分别记为 f i f_{i} fi、 f i r f_{i}^{r} fir、 f i h f_{i}^{h} fih),将模型感受野约束在稳定表征空间内。这种相对位姿固定编码消除时序外推带来的数值不稳定性,辅助含噪潜在表示与参考、历史上下文建立稳定关联,显著提升空间一致性。
另外,为应对训练时的可微性需求与内存瓶颈,本文提出分块反向传播策略。现有自回归扩散模型在计算分布损失(如分布匹配蒸馏损失)时,因序列长度增长带来的内存压力过大,常采用无梯度模式构建键值缓存,这种不可微性迫使模型被动拟合特征,制约整体生成质量。本文提出的策略将前向推理与反向优化解耦,将峰值内存占用降至单个块的规模。流程分为两个阶段:
- 阶段1:以无梯度模式执行全长推理,仅保留最终输出计算分布匹配蒸馏损失,以可忽略的计算开销捕获全局监督信号。
- 阶段2:逐块重新执行前向传播以触发反向传播,该过程覆盖全流程(包括键值缓存构建与去噪),且中间表示在每次梯度更新后立即释放。这种时空权衡策略保障每个块内的全链路可微性,使模型精准学习更具表达力的时空特征,显著提升生成保真度。
3.2.2 几何感知显式约束
为精准响应动态交互指令 τ i \tau_{i} τi,本文引入显式几何约束机制,将离散用户操作转化为确定性空间结构引导。该过程分为位姿演化与几何特征投影两个阶段:
首先,系统将用户对当前块的旋转、平移与视角变换指令映射为六自由度(6-DoF)相对位姿变换 Δ T i \Delta T_{i} ΔTi。第 i i i 个块对应的全局位姿 T i T_{i} Ti 定义为所有历史交互的累积,通过对先前相机状态 T i − 1 T_{i-1} Ti−1 应用 Δ T i \Delta T_{i} ΔTi 递归推导得到。
获取当前位姿 T i T_{i} Ti 后,系统通过投影函数将参考特征与当前视角几何对齐。具体而言,采用前馈重建(FFR)方法从参考视频潜在表示中提取几何先验,得到深度图 D r e f D_{ref} Dref 与相机内参 K K K。基于 T i T_{i} Ti,系统执行以下重投影操作:
z i w a r p , m i = Proj ( z r e f ∣ FFR ( z r e f ) , T i ) z_{i}^{warp }, m_{i}=\text{Proj}\left(z^{ref} | \text{FFR}\left(z^{ref}\right), T_{i}\right) ziwarp,mi=Proj(zref∣FFR(zref),Ti)
其中 z i w a r p z_{i}^{warp } ziwarp 为几何对齐的引导特征。为有效区分纯黑纹理与不可见区域,本文将二元掩码 m i m_{i} mi 拼接至潜在表示。该掩码通过显式定义有效重投影区域,引导自回归模型在确定性结构约束下生成。
此外,本模型原生支持几何约束注入,可实现可选的显式结构记忆机制。通过对生成视频重建并动态扩展点云地图,系统以极小计算开销构建场景结构化表征。该显式几何约束有效充当空间记忆代理,为长程生成提供基础结构锚点。
边生成视频边攒场景的 3D 点云地图,用极低算力记住场景的真实结构,让模型长时间漫游、随便转视角,都不会把场景画歪、画飘,稳稳保持空间一致性。
3.2.3 多条件因果初始化
在自回归视频生成领域,设计合理的初始化策略是保障训练收敛稳定性与序列一致性的关键前提。以CausVid为代表的主流框架,通常采用因果注意力掩码初始化学生模型,强制当前帧合成严格依赖先前生成上下文的因果生成范式。
然而,这种依赖因果注意力掩码的初始化策略,在多条件可控生成中存在明显缺陷。由于每个块的合成需融合异构输入(包括先前帧、参考图像、几何约束),简单因果掩码无法建模这些异质信号间复杂的因果关联,直接应用该范式常导致生成质量不佳。
为解决该挑战,本文提出多条件因果初始化策略。与传统静态因果掩码不同,该策略直接在真实标签数据或教师模型常微分方程轨迹上执行分块自回归多步预演,确保模型在初始阶段与各类条件建立精准关联。在后续蒸馏阶段,因已建立稳健的因果依赖,学生模型将重心转向采样加速(多步变少步)与保真度优化(粗细节变细细节)。
此外,通过通道拼接注入的显式几何约束仅作用于当前去噪块,对历史块对应通道采用零填充,确保历史缓存仅提供纯图像信息。该设计避免过往几何信号渗透,保障可控时空自回归过程的完整性与生成逻辑的鲁棒性。
3.3 联合分布匹配蒸馏
交互式漫游任务的实现高度依赖视觉连续性与运动反馈的精准解耦。然而,支撑参考视频输入的训练过程需要多视角同步视频流,这类高保真标注数据在真实场景中极为稀缺。尽管合成数据能提供完美的几何约束,但其固有的域偏移常导致纹理平滑、结构重复等感知退化现象。为规避可控性与视觉保真度间的固有矛盾,本文提出联合分布匹配蒸馏(JDMD)。
本文首先简要回顾分布匹配蒸馏(DMD)的基本原理。标准分布匹配蒸馏通过最小化KL散度训练学生生成器,使其匹配教师扩散模型的分布。学生模型参数的梯度为:
∇ θ E t [ D K L ( p θ , t ∥ p d a t a , t ) ] = − E t , x ^ t [ ( s r e a l ( x ^ t , t ) − s f a k e ( x ^ t , t ) ) ∂ x ^ ∂ θ ] \nabla_{\theta} \mathbb{E}_{t}\left[D_{KL}\left(p_{\theta, t} \| p_{data , t}\right)\right]=-\mathbb{E}_{t, \hat{x}_{t}}\left[\left(s_{real }\left(\hat{x}_{t}, t\right)-s_{fake }\left(\hat{x}_{t}, t\right)\right) \frac{\partial \hat{x}}{\partial \theta}\right] ∇θEt[DKL(pθ,t∥pdata,t)]=−Et,x^t[(sreal(x^t,t)−sfake(x^t,t))∂θ∂x^]
其中 s r e a l s_{real} sreal 与 s f a k e s_{fake} sfake 分别为真实(教师)与伪(学生跟踪)分数网络近似的分数函数, x ^ t \hat{x}_{t} x^t 为学生模型输出的含噪版本。
JDMD的核心思想是采用多任务学习范式,以真实世界数据分布作为正则化引导,克服合成数据固有的保真度退化问题。具体而言,JDMD在训练迭代中交替激活两个蒸馏任务,利用两个冻结的教师分布协同引导学生模型:
在可控视频重渲染(V2V)任务中,学生模型接收参考视频与几何信息,专注学习精准运动控制与时空一致性,其中合成数据分布 p s y n p_{syn} psyn 由在合成数据上微调的教师模型表征,用于计算条件控制损失 L c t r l L_{ctrl} Lctrl;
同时,在文本到视频(T2V)任务中,学生模型仅以文本为条件,专注捕获真实世界数据的保真度与丰富性,其中真实世界数据分布 p r e a l p_{real} preal 由原始Wan-T2V基础模型表征,用于计算视觉蒸馏损失 L v i s L_{vis} Lvis。
通过结合这两个目标,总损失函数被建模为加权和:
L J D M D = L v i s + λ c t r l L c t r l \mathcal {L}_{JDMD}=\mathcal {L}_{vis}+\lambda _{ctrl}\mathcal {L}_{ctrl} LJDMD=Lvis+λctrlLctrl
其中 λ c t r l \lambda_{ctrl} λctrl 为平衡视觉保真度与运动控制权重的超参数。
这种双轨蒸馏机制确保,当学生模型接收交互指令 τ \tau τ 与参考视频时,从可控V2V任务学到的条件遵循能力占主导,保障生成输出的精准相机运动与时空一致性;同时,T2V任务的蒸馏过程通过将特征空间与真实世界数据分布对齐,执行关键的分布校准,显著提升生成输出的视觉保真度。
通过联合分布匹配蒸馏,INSPATIO-WORLD成功平衡运动依从性与视觉保真度:在保持原生高保真图像质量的同时,模型实现对参考视频与复杂相机轨迹的精准遵循。该机制使系统最终突破合成数据的分布限制,在交互式漫游任务中实现空间一致性与视觉真实感的有效平衡。


3.4 实现细节
本训练框架利用多样化数据源,包括大规模公开互联网视频(如RealEstate10K),以及专为新视角视频重渲染任务定制的合成数据集。后者包括虚幻引擎(UE)渲染序列与公开的ReCamMaster数据集。对于每个视频片段,本文采用前馈重建模型估计深度信息。
训练流程遵循Self-Forcing范式,以Wan2.1为骨干网络。训练过程分为三个阶段,聚焦学习率调度而非迭代次数:
- 教师训练:训练教师模型以建立稳健的性能基线,学习率为 2 × 10 − 5 2 ×10^{-5} 2×10−5。
- 初始化阶段:学生模型执行初始化阶段以建立自回归推理能力,采用与教师训练阶段一致的学习率。
- 学生蒸馏(JDMD):在预训练教师的监督下训练学生模型。该阶段中,学生网络与伪分数判别器的学习率分别设为 4.0 × 10 − 6 4.0 ×10^{-6} 4.0×10−6 与 8.0 × 10 − 7 8.0 ×10^{-7} 8.0×10−7。
为提升推理效率,本文采用两项加速策略:
首先,用轻量级Tiny-VAE替换原始Wan-VAE。尽管该替换会带来轻微性能下降,但为低延迟实时应用提供了有利的权衡。
其次,尽管蒸馏后的模型已实现高效推理,本文仍通过图级编译优化(使用torch.compile)进一步降低运行时开销,带来额外的实际速度提升。
结合天然兼容流式推理的模型架构,这些优化使INSPATIO-WORLD(1.3B模型)在NVIDIA H系列GPU上实现24帧/秒的实时推理速度,在消费级RTX 4090 GPU上仍保持极具竞争力的10帧/秒。这证明该框架在不同硬件约束下,对交互式应用的广泛适用性。
4 实验
4.1 实验设置
本文通过三项互补任务验证INSPATIO-WORLD的有效性:
- WorldScore基准测试,通过衡量指令控制精度、空间结构稳定性与物理动态真实性,评估模型的下一帧场景生成性能;
- 长时程图像到视频生成,采用RealEstate10K(RE10K)数据集,通过生成长序列视频,检验模型在长程相机控制、内容分布一致性与视觉质量方面的表现;
- 相机可控生成式视频重渲染,在真实世界与合成数据集上均进行评估,测试给定参考视频约束下的相机控制精度、生成质量与对原始视频条件的遵循度。
在WorldScore评估中,本文严格遵循官方建议,采用其定义的全部10项核心评估指标。对于长时程图像到视频生成与视频重渲染任务,本文构建了多维度、全面的定量评估框架:
- 控制精度,通过计算生成序列与预设轨迹间的旋转误差(Rot)和平移误差(Trans),量化相机运动控制的精准度;
- 生成分布质量,分别使用FID与FVD从图像与视频维度衡量生成结果与真实数据分布的相似度;
- 视觉质量,涵盖VBench的六项关键维度:美学质量、图像质量、时序闪烁、运动平滑度、主体一致性与背景一致性。
为全面验证性能,本文将INSPATIO-WORLD与不同技术路线下的现有最优模型进行对比,包括WorldScore评估模型(FantasyWorld、TeleWorld)、工业级模型(CogVideoX-I2V、Gen-3、LTXVideo、Hailuo)、开源世界模型(Infinite-World、LingBot-World、HY-WorldPlay),以及生成式视频重渲染基线模型(TrajectoryCrafter、ReCamMaster、NeoVerse)。
4.2 WorldScore基准测试
本文在WorldScore基准测试上对INSPATIO-WORLD开展全面评估。如表1与图3所示,INSPATIO-WORLD(1.3B)在指标与计算效率上均取得现有最优(SOTA)性能,在所有实时/交互式方法中位列第一。
定量分析(表1)表明,INSPATIO-WORLD在三项核心指标上超越现有方法:运动平滑度(71.91)、相机控制精度(81.51)与光度质量(93.00)。优异的运动平滑度与精准控制验证了时空自回归框架的优越性,而领先的光度质量证实了JDMD对生成质量的提升作用。
值得注意的是,在取得这些优异结果的同时,本文方法的生成速度也处于顶尖水平;据本文所知,这是榜单中唯一能达到24帧/秒实时运行的世界模型。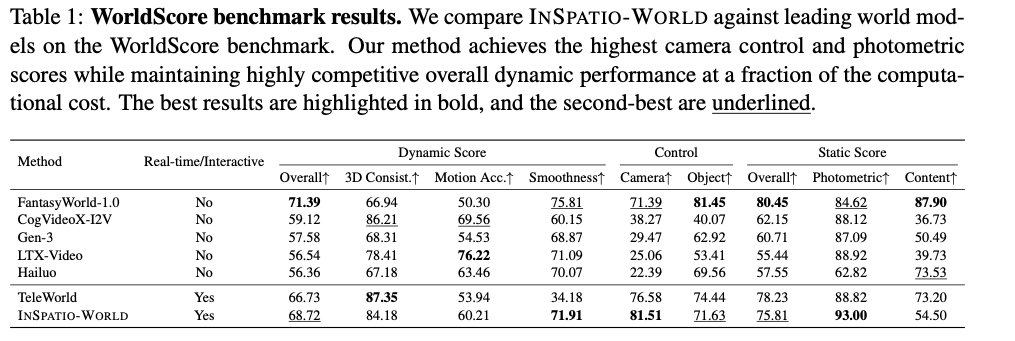
表1:WorldScore基准测试结果。本文在WorldScore基准测试上将INSPATIO-WORLD与主流世界模型对比。本方法在相机控制与光度得分上取得最高值,同时保持极具竞争力的整体动态性能,且计算成本更低。最优结果加粗标注,次优结果下划线标注。
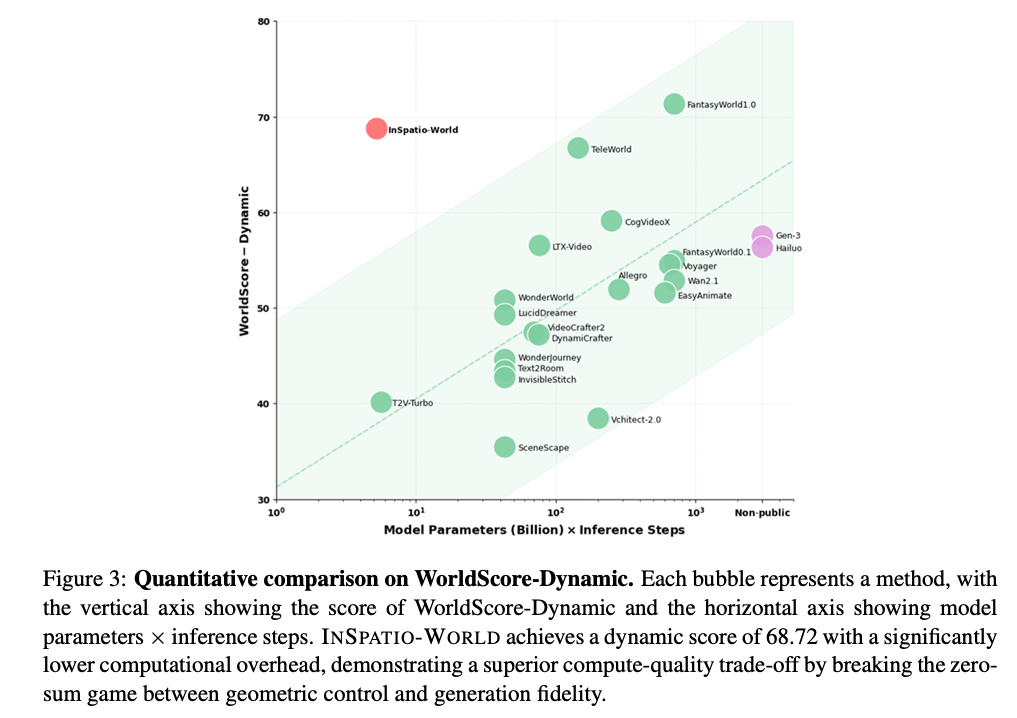
图3:WorldScore-Dynamic定量对比。每个气泡代表一种方法,纵轴为WorldScore-Dynamic得分,横轴为模型参数×推理步数。INSPATIO-WORLD以显著更低的计算开销取得68.72的动态得分,打破几何控制与生成保真度间的零和博弈,展现出更优的计算-质量权衡。
4.3 长时程图像到视频生成
长时程生成是评估交互式世界模型的关键任务,因为它要求模型在扩展序列中维持空间持久性、抑制运动漂移与误差累积。
本文从RE10K数据集中随机选取100段超过150帧的序列,构建严格的评估基准。在相同输入条件下,将INSPATIO-WORLD与现有最优(SOTA)世界模型对比。为公平对比,本文采用14B版本,与LingBot-World保持一致。
如表2所示,INSPATIO-WORLD在所有指标上均取得大幅提升。在生成质量方面,本文方法取得42.68的FID与100.55的FVD,显著超越现有最优方法。最突出的是,在相机运动精度上,INSPATIO-WORLD展现出压倒性优势,其轨迹误差远低于第二名LingBot-World。这一数值优势证实了本框架在处理复杂、长时程交互式漫游任务时的优越性。
定性结果(见图4)进一步揭示了基线模型在扩展生成过程中的典型失效模式:Infinite-World随序列长度增加出现严重的结构畸变与几何扭曲;HY-WorldPlay缺乏稳健的运动控制,常退化为静态帧生成;LingBot-World虽能保持单帧视觉质量,但因相机位姿估计不准确,无法精准遵循目标轨迹。
与之相对,INSPATIO-WORLD通过融入全局空间参考,保障场景的几何完整性并维持精准相机控制,实现无伪影的长时程导航。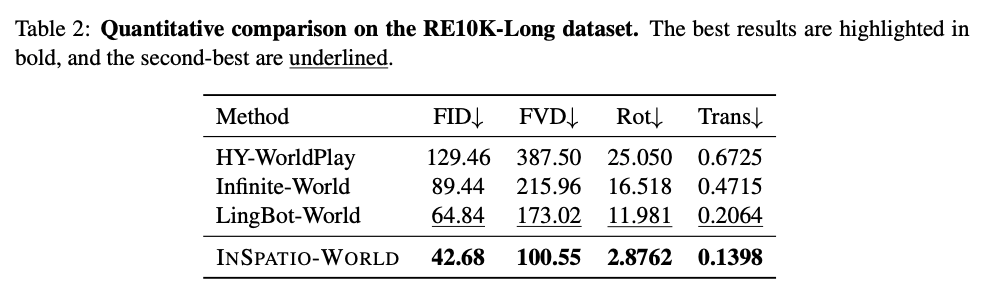
表2:RE10K-Long数据集定量对比。最优结果加粗标注,次优结果下划线标注。

图4:RE10K-Long数据集定性对比。对于两个场景中的每个场景,最左侧图像为输入源图像。对于每种方法,顶行展示生成序列的中间帧,底行展示最终帧。随着生成过程推进,基线方法出现不同程度的失效,如相机位姿漂移或结构扭曲。与之相对,INSPATIO-WORLD在整个扩展序列中维持精准轨迹控制与持久的几何一致性。
4.4 相机可控生成式视频重渲染
为评估INSPATIO-WORLD在相机可控生成式视频重渲染任务上的性能,本文在合成Blender数据集与真实世界OpenVid数据集上均开展实验。Blender评估集包含100个样本,每个样本均有精准轨迹与真值视频。OpenVid评估集包含240个样本,由40段原始OpenVid视频与6条不同方向的复杂轨迹匹配构建。
由于OpenVid视频无对应的真值目标视频用于计算分布差异,本文采用VBench评估视频生成质量。为公平对比,本文采用14B版本,与Neoverse保持一致。
定量结果表明,本文方法在两个数据集上均取得现有最优(SOTA)性能(见表3)。具体而言,INSPATIO-WORLD在FID、FVD与综合视频质量指标上超越现有方法,同时实现与当前最优模型相当的相机控制精度。这充分证实了所提方法的有效性。
此外,定性评估(见图5)直观凸显了本文方法的优势。与其他方法相比,INSPATIO-WORLD展现出更优的视频生成质量。值得注意的是,尽管Neoverse展现出良好的生成质量与相机控制精度,但其在保留与输入视频的时空一致性方面能力有限,导致FID与FVD得分更低。与之相对,本文方法在实现高质量生成的同时,严格保持与输入参考视频的高一致性。
最后,据本文所知,INSPATIO-WORLD是当前唯一开源、可实时运行的生成式视频重渲染方案。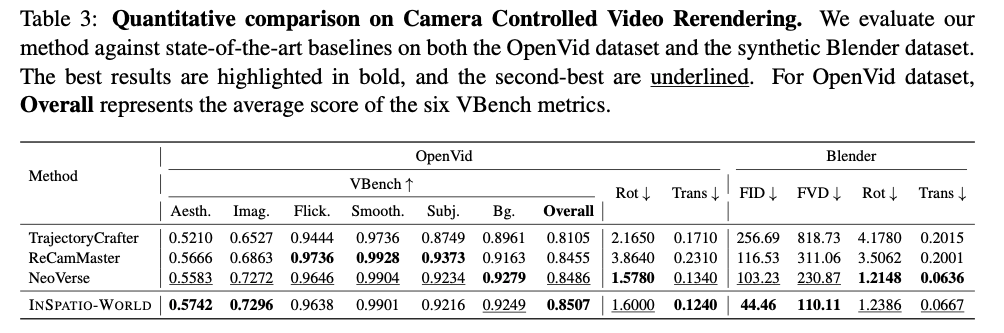
表3:相机可控视频重渲染定量对比。本文在OpenVid数据集与合成Blender数据集上,将本文方法与现有最优基线模型对比。最优结果加粗标注,次优结果下划线标注。对于OpenVid数据集,Overall为六项VBench指标的平均分。

图5:相机可控视频重渲染定性对比。每一行代表一个不同场景。从左至右:参考视频第一帧、扭曲最终帧,以及TrajectoryCrafter、ReCamMaster、NeoVerse与本文方法生成的最终帧。与现有方法相比,本文方法对原始场景的结构保真度更高,纹理细节表现显著更优。同时,本文方法展现出更优的指令遵循能力,实现与渲染真值几乎一致的精准相机轨迹。展示的参考帧采样自在线视频平台,仅用于学术演示。
5 讨论与结论
本文提出INSPATIO-WORLD,一种专为实时交互式漫游设计的创新四维生成式世界模型。通过构建高效的时空自回归框架,本文成功集成用于长时程时空锚定的隐式时空缓存与显式空间约束。所提框架有效缓解了交互式视频生成中空间持久性丢失与控制不精准的核心难题。
为进一步提升视觉质量,本文提出联合分布匹配蒸馏(JDMD),采用双教师范式解耦并同时优化运动保真度与感知真实感,有效弥合合成仿真与物理现实之间的域差异。
实验结果表明,所提框架在空间连续性与视觉精度上建立了新的现有最优标准,同时保持24帧/秒的高效性能,为合成虚拟世界中的高自由度导航提供了稳健基础。
5.1 局限性
尽管INSPATIO-WORLD取得显著进展,该系统在维持生成区域的长时程一致记忆与实现无缝360度动态漫游方面仍存在一定局限。
具体而言,尽管本框架成功集成外部时空锚点与显式点云记忆以保障空间一致性,但其主要作为结构骨架,难以对自主生成区域的细粒度纹理细节进行持久编码。此外,尽管该显式几何方案有效支持静态环境中的大规模位移,但在广角、全向视角切换时保障动态元素的多视角一致性与时空连贯性仍为开放挑战。
5.2 未来工作
展望未来,本文将聚焦开发更深度的语义记忆系统,探索几何结构与高维纹理特征的深度耦合,实现对生成区域的全面、全时空记录与重建。
同时,本文计划通过在自回归过程中引入更强的物理先验,研究长程动态约束机制。目标是在物理引导下实现大规模、高复杂度动态场景的完美闭环仿真,持续推动生成式世界模型向更高维度与更广阔应用前景发展。
思考
- 架构创新:提出时空自回归(STAR)框架
设计隐式时空缓存,融合参考帧与历史生成信息,解决长时漫游的场景漂移、结构崩坏问题;
加入显式几何约束,将用户交互转化为精准相机轨迹,实现6 自由度高可控的相机生成;
用分块反向传播与位置固定策略,保障长序列生成的时空一致性。 - 学习机制创新:提出联合分布匹配蒸馏(JDMD)
采用双教师 + 双任务权重共享模式:用合成数据练运动 / 几何控制精度,用真实数据练视觉纹理保真度;
破解 “可控性与画面真实感无法兼顾” 的矛盾,消除合成数据带来的塑料感、纹理模糊问题。 - 性能与落地创新:实现实时交互式 4D 生成
轻量化优化 + 编译加速,在消费级 GPU 上实现10-24FPS实时推理;
全球首个开源、可实时运行的生成式视频重渲染方案,从单视频即可构建可漫游 4D 世界;
突破传统模型仅支持文本 / 图像输入的限制,直接将单目视频转化为动态交互世界。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)