第6节:vLLm架构设计与工作流程以及单机部署模式【从理论到实战】
文章目录
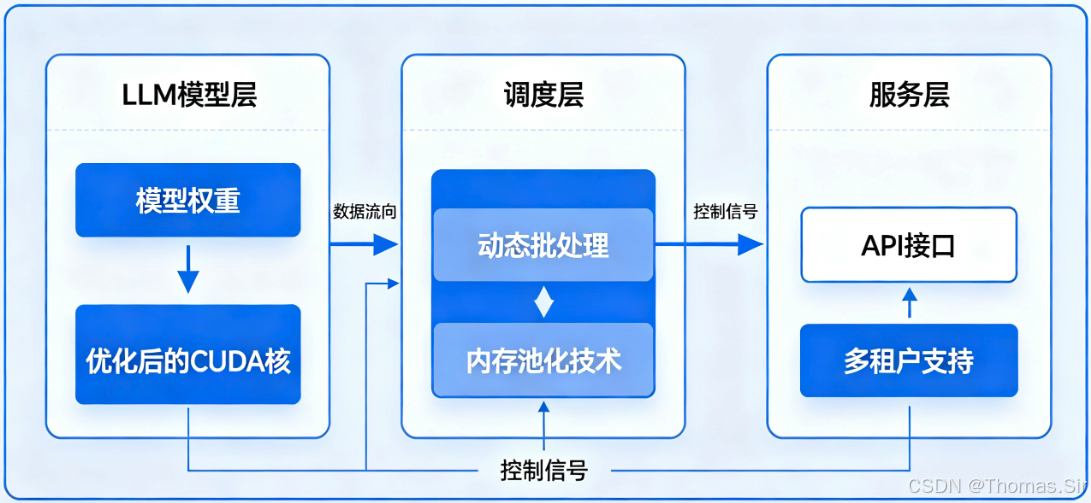
一、vLLM架构设计与工作流程
1.1 vLLM整体架构拆解
核心组件及其功能
vLLM采用分层架构设计,各组件职责清晰,协同工作以实现高效的大语言模型推理:
1. LLM引擎(LLM Engine)
class LLMEngine:
"""LLM引擎 - 系统核心调度器"""
def __init__(self, model_config, cache_config):
self.model_runner = ModelRunner(model_config) # 模型执行器
self.scheduler = Scheduler() # 任务调度器
self.kv_cache = KVCache(cache_config) # KV缓存管理器
self.worker_pool = WorkerPool() # 工作线程池
self.request_queue = PriorityQueue() # 请求队列
def add_request(self, request: Request):
"""添加推理请求"""
self.request_queue.put(request)
def step(self):
"""执行单步推理"""
# 1. 调度请求
scheduled_requests = self.scheduler.schedule(self.request_queue)
# 2. 准备KV缓存
cache_blocks = self.kv_cache.allocate(scheduled_requests)
# 3. 执行模型推理
outputs = self.model_runner.run(
scheduled_requests,
cache_blocks
)
# 4. 更新缓存和返回结果
self.kv_cache.update(cache_blocks, outputs)
return outputs
2. Worker(工作进程)
class Worker:
"""工作进程 - 负责具体计算任务"""
def __init__(self, worker_id, gpu_id):
self.worker_id = worker_id
self.gpu_id = gpu_id
self.model_instance = None
self.current_batch = []
def load_model(self, model_path):
"""加载模型到GPU"""
self.model_instance = load_model_to_gpu(model_path, self.gpu_id)
def process_batch(self, batch_requests):
"""处理批次请求"""
# 准备输入数据
inputs = self._prepare_inputs(batch_requests)
# 执行推理
with torch.cuda.stream(self.stream):
outputs = self.model_instance(inputs)
# 后处理
results = self._postprocess(outputs)
return results
def _prepare_inputs(self, requests):
"""将请求转换为模型输入张量"""
# 合并token序列,处理填充
token_ids = []
attention_masks = []
positions = []
for req in requests:
token_ids.append(req.token_ids)
attention_masks.append(req.attention_mask)
positions.append(req.position_ids)
return {
'input_ids': pad_sequence(token_ids),
'attention_mask': pad_sequence(attention_masks),
'position_ids': pad_sequence(positions)
}
3. Model Runner(模型执行器)
class ModelRunner:
"""模型执行器 - 封装模型推理逻辑"""
def __init__(self, model_config):
self.model_config = model_config
self.layers = self._build_model_layers()
self.operators = self._initialize_operators()
def run(self, requests, cache_blocks):
"""执行模型推理"""
hidden_states = self._embed(requests.input_ids)
# 逐层执行Transformer
for layer_idx, layer in enumerate(self.layers):
# 注意力层
attn_output = self._attention_layer(
hidden_states,
cache_blocks.key_cache[layer_idx],
cache_blocks.value_cache[layer_idx],
requests.attention_mask
)
# FFN层
ffn_output = self._ffn_layer(attn_output)
# 残差连接
hidden_states = hidden_states + ffn_output
# 输出层
logits = self._lm_head(hidden_states)
return logits
def _attention_layer(self, hidden_states, key_cache, value_cache, mask):
"""优化的注意力层实现"""
# 使用PagedAttention
return paged_attention(
query=hidden_states,
key_cache=key_cache,
value_cache=value_cache,
block_table=cache_blocks.block_table,
attention_mask=mask,
scale=self.model_config.scale
)
4. API Server(API服务器)
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
app = FastAPI()
class CompletionRequest(BaseModel):
prompt: str
max_tokens: int = 100
temperature: float = 0.7
stream: bool = False
class APIServer:
"""API服务器 - 提供外部接口"""
def __init__(self, engine: LLMEngine):
self.engine = engine
self.request_counter = 0
@app.post("/v1/completions")
async def create_completion(self, request: CompletionRequest):
"""创建补全请求"""
request_id = self._generate_request_id()
# 创建内部请求对象
internal_request = Request(
id=request_id,
prompt=request.prompt,
max_tokens=request.max_tokens,
temperature=request.temperature
)
# 添加到引擎
self.engine.add_request(internal_request)
if request.stream:
# 流式响应
return self._stream_response(request_id)
else:
# 阻塞响应
return await self._blocking_response(request_id)
def _stream_response(self, request_id):
"""流式响应生成器"""
async def generate():
while True:
result = self.engine.get_result(request_id)
if result is None:
await asyncio.sleep(0.01)
continue
if result.finished:
yield f"data: [DONE]\n\n"
break
yield f"data: {json.dumps({'text': result.text})}\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
各组件的交互逻辑
┌─────────────────────────────────────────────────────────────┐
│ Client Applications │
└───────────────┬────────────────────┬────────────────────────┘
│ │
▼ ▼
┌──────────────┐ ┌─────────────────┐
│ API Server │ │ gRPC Server │
└──────┬───────┘ └────────┬────────┘
│ │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ Request Queue │
│ (Priority-based) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ Scheduler │
│ (Batch Scheduling) │
└──────────┬──────────┘
│
▼
┌─────────────────────┐
│ LLM Engine │
└──────────┬──────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
┌──────────────┐ ┌──────────────┐ ┌──────────────┐
│ Model Runner │ │ KV Cache │ │ Worker Pool │
│ │ │ Manager │ │ │
└──────┬───────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
└────────────────┼─────────────────┘
│
▼
┌─────────────────────┐
│ GPU Resources │
└─────────────────────┘
交互时序示例:
# 1. 客户端发送请求
request = {
"prompt": "Hello, how are you?",
"max_tokens": 50
}
# 2. API Server接收并验证
api_server.validate_request(request)
# 3. 转换为内部请求格式
internal_req = Request.from_api_request(request)
# 4. 添加到LLM Engine队列
llm_engine.add_request(internal_req)
# 5. Scheduler调度批次
batch = scheduler.get_next_batch()
# 6. 准备KV缓存
cache_blocks = kv_cache.allocate(batch)
# 7. Model Runner执行推理
outputs = model_runner.run(batch, cache_blocks)
# 8. 更新缓存和生成结果
results = post_processor.process(outputs)
# 9. 返回给客户端
api_server.send_response(results)
架构设计的核心优势
1. 高可用性设计
class HighAvailabilityManager:
"""高可用性管理器"""
def __init__(self, num_replicas=3):
self.replicas = [LLMEngine() for _ in range(num_replicas)]
self.health_checker = HealthChecker()
self.load_balancer = LoadBalancer()
def process_request(self, request):
"""处理请求(带故障转移)"""
for replica in self.load_balancer.select_replica():
try:
if self.health_checker.is_healthy(replica):
return replica.process(request)
except Exception as e:
logger.warning(f"Replica failed: {e}")
self.health_checker.mark_unhealthy(replica)
raise ServiceUnavailableError("All replicas unavailable")
def auto_recovery(self):
"""自动恢复机制"""
for replica in self.replicas:
if not self.health_checker.is_healthy(replica):
self._restart_replica(replica)
2. 高扩展性设计
class ScalableArchitecture:
"""可扩展架构"""
def __init__(self):
self.workers = []
self.scaling_policy = AutoScalingPolicy()
def scale_up(self, num_instances):
"""水平扩展"""
new_workers = []
for i in range(num_instances):
worker = Worker()
worker.initialize()
self.workers.append(worker)
new_workers.append(worker)
# 重新分配负载
self.load_balancer.redistribute(new_workers)
def scale_out(self, model_sharding):
"""垂直扩展 - 模型分片"""
if model_sharding == "tensor_parallel":
self._enable_tensor_parallel()
elif model_sharding == "pipeline_parallel":
self._enable_pipeline_parallel()
elif model_sharding == "sequence_parallel":
self._enable_sequence_parallel()
def _enable_tensor_parallel(self):
"""启用张量并行"""
# 将模型层拆分到多个GPU
for layer_idx, layer in enumerate(self.model.layers):
gpu_id = layer_idx % self.num_gpus
layer.to(f"cuda:{gpu_id}")
3. 低耦合设计
# 使用依赖注入和接口抽象
from abc import ABC, abstractmethod
class InferenceService(ABC):
"""推理服务抽象接口"""
@abstractmethod
def infer(self, prompt: str) -> str:
pass
class CachingStrategy(ABC):
"""缓存策略抽象接口"""
@abstractmethod
def get(self, key: str):
pass
@abstractmethod
def set(self, key: str, value: any):
pass
# 具体实现
class vLLMInferenceService(InferenceService):
def __init__(self,
model_loader: ModelLoader,
cache_strategy: CachingStrategy,
scheduler: Scheduler):
# 通过依赖注入降低耦合
self.model_loader = model_loader
self.cache_strategy = cache_strategy
self.scheduler = scheduler
def infer(self, prompt: str) -> str:
# 使用抽象接口,不依赖具体实现
cached = self.cache_strategy.get(prompt)
if cached:
return cached
result = self._do_inference(prompt)
self.cache_strategy.set(prompt, result)
return result
1.2 vLLM推理全流程解析
请求接收与预处理
1. Tokenization流程
class TokenizationPipeline:
"""分词处理管道"""
def __init__(self, tokenizer_path):
self.tokenizer = AutoTokenizer.from_pretrained(tokenizer_path)
self.vocab_size = self.tokenizer.vocab_size
self.special_tokens = self.tokenizer.special_tokens_map
def process(self, text: str, request_config: dict) -> TokenizedRequest:
"""完整的分词处理流程"""
# 步骤1: 文本清洗
cleaned_text = self._clean_text(text)
# 步骤2: 特殊标记处理
if request_config.get('add_special_tokens', True):
text_with_specials = self._add_special_tokens(cleaned_text)
else:
text_with_specials = cleaned_text
# 步骤3: 分词
tokens = self.tokenizer.encode(
text_with_specials,
truncation=request_config.get('truncation', True),
max_length=request_config.get('max_length', 2048),
padding=False
)
# 步骤4: 构建请求对象
return TokenizedRequest(
token_ids=tokens,
attention_mask=[1] * len(tokens),
position_ids=list(range(len(tokens))),
original_text=text,
request_id=generate_request_id()
)
def batch_tokenize(self, texts: List[str]) -> BatchTokenized:
"""批量分词优化"""
# 使用tokenizer的批量处理能力
encoded = self.tokenizer.batch_encode_plus(
texts,
padding=True,
truncation=True,
return_tensors="pt"
)
return BatchTokenized(
input_ids=encoded['input_ids'],
attention_masks=encoded['attention_mask'],
position_ids=self._generate_position_ids(encoded['attention_mask'])
)
2. 请求解析与验证
class RequestParser:
"""请求解析器"""
def parse(self, raw_request: dict) -> ParsedRequest:
"""解析原始请求"""
# 验证必需字段
self._validate_required_fields(raw_request)
# 解析参数
parsed = ParsedRequest(
prompt=raw_request.get('prompt', ''),
max_tokens=self._parse_max_tokens(raw_request),
temperature=self._parse_temperature(raw_request),
top_p=self._parse_top_p(raw_request),
stream=raw_request.get('stream', False),
stop_sequences=raw_request.get('stop', []),
presence_penalty=raw_request.get('presence_penalty', 0.0),
frequency_penalty=raw_request.get('frequency_penalty', 0.0),
logprobs=raw_request.get('logprobs', None),
echo=raw_request.get('echo', False)
)
# 验证参数范围
self._validate_parameter_ranges(parsed)
return parsed
def _parse_max_tokens(self, request: dict) -> int:
"""解析最大token数"""
max_tokens = request.get('max_tokens', 16)
# 应用系统限制
system_limit = self.config.get('max_tokens_limit', 4096)
return min(max_tokens, system_limit)
def _parse_temperature(self, request: dict) -> float:
"""解析温度参数"""
temp = request.get('temperature', 1.0)
if temp < 0 or temp > 2:
raise InvalidParameterError(
f"Temperature must be between 0 and 2, got {temp}"
)
# 温度为0时使用贪心解码
if temp == 0:
self.logger.info("Temperature=0, using greedy decoding")
return temp
任务调度与批处理
1. 动态批处理调度器
class DynamicBatchScheduler:
"""动态批处理调度器"""
def __init__(self, config):
self.max_batch_size = config.get('max_batch_size', 32)
self.max_seq_len = config.get('max_seq_len', 2048)
self.scheduling_policy = config.get('scheduling_policy', 'fcfs')
self.waiting_requests = []
self.ready_batches = []
def schedule(self, current_requests: List[Request]) -> List[Batch]:
"""调度请求形成批次"""
batches = []
current_batch = []
current_batch_size = 0
# 根据调度策略排序请求
sorted_requests = self._sort_requests(current_requests)
for request in sorted_requests:
request_size = self._calculate_request_size(request)
# 检查是否可加入当前批次
if self._can_add_to_batch(current_batch, request):
current_batch.append(request)
current_batch_size += request_size
else:
# 完成当前批次
if current_batch:
batches.append(self._create_batch(current_batch))
# 开始新批次
current_batch = [request]
current_batch_size = request_size
# 检查批次是否已满
if current_batch_size >= self.max_batch_size:
batches.append(self._create_batch(current_batch))
current_batch = []
current_batch_size = 0
# 处理剩余请求
if current_batch:
batches.append(self._create_batch(current_batch))
return batches
def _sort_requests(self, requests: List[Request]) -> List[Request]:
"""根据调度策略排序请求"""
if self.scheduling_policy == 'fcfs':
# 先到先服务
return sorted(requests, key=lambda r: r.arrival_time)
elif self.scheduling_policy == 'sjf':
# 最短作业优先
return sorted(requests, key=lambda r: r.estimated_tokens)
elif self.scheduling_policy == 'priority':
# 优先级调度
return sorted(requests, key=lambda r: (-r.priority, r.arrival_time))
elif self.scheduling_policy == 'fairness':
# 公平调度
return self._fair_scheduling(requests)
def _can_add_to_batch(self, batch: List[Request], new_request: Request) -> bool:
"""检查新请求是否可以加入批次"""
if not batch:
return True
# 检查批次大小限制
batch_size = len(batch)
if batch_size >= self.max_batch_size:
return False
# 检查序列长度兼容性
max_seq_len_in_batch = max(r.seq_len for r in batch)
if max(max_seq_len_in_batch, new_request.seq_len) > self.max_seq_len:
return False
# 检查解码模式兼容性
decoding_mode = batch[0].decoding_mode
if new_request.decoding_mode != decoding_mode:
return False
return True
2. 资源分配策略
class ResourceAllocator:
"""资源分配器"""
def allocate(self, batch: Batch, available_gpus: List[GPUInfo]) -> Allocation:
"""为批次分配资源"""
allocation = Allocation()
# 计算资源需求
requirements = self._calculate_requirements(batch)
# 选择最优GPU
selected_gpu = self._select_gpu(requirements, available_gpus)
# 分配显存
memory_allocation = self._allocate_memory(requirements, selected_gpu)
# 分配计算资源
compute_allocation = self._allocate_compute(requirements, selected_gpu)
allocation.gpu = selected_gpu
allocation.memory = memory_allocation
allocation.compute = compute_allocation
allocation.batch = batch
return allocation
def _calculate_requirements(self, batch: Batch) -> ResourceRequirements:
"""计算资源需求"""
requirements = ResourceRequirements()
# 计算显存需求
model_memory = self._estimate_model_memory(batch.model_config)
kv_cache_memory = self._estimate_kv_cache_memory(batch)
activation_memory = self._estimate_activation_memory(batch)
requirements.total_memory = (
model_memory +
kv_cache_memory +
activation_memory +
SAFETY_MARGIN
)
# 计算计算需求
requirements.flops = self._estimate_flops(batch)
requirements.memory_bandwidth = self._estimate_bandwidth(batch)
return requirements
def _select_gpu(self, requirements: ResourceRequirements,
gpus: List[GPUInfo]) -> GPUInfo:
"""选择最合适的GPU"""
suitable_gpus = []
for gpu in gpus:
# 检查显存是否足够
if gpu.free_memory < requirements.total_memory:
continue
# 检查计算能力是否足够
if not self._check_compute_capability(gpu, requirements):
continue
suitable_gpus.append(gpu)
if not suitable_gpus:
raise InsufficientResourcesError("No suitable GPU available")
# 选择策略:最小化碎片
return min(suitable_gpus, key=lambda g: g.free_memory - requirements.total_memory)
模型推理计算
1. PagedAttention执行流程
class PagedAttentionExecutor:
"""PagedAttention执行器"""
def execute(self, query: Tensor, kv_cache: KVCache,
attention_mask: Tensor) -> Tensor:
"""执行分页注意力计算"""
# 步骤1: 准备查询向量
Q = self._project_query(query)
# 步骤2: 从KV缓存获取键值
K, V = self._retrieve_from_cache(kv_cache)
# 步骤3: 计算注意力分数
scores = self._compute_attention_scores(Q, K, attention_mask)
# 步骤4: 应用softmax
attention_weights = self._apply_softmax(scores)
# 步骤5: 加权求和
output = self._weighted_sum(attention_weights, V)
# 步骤6: 输出投影
final_output = self._project_output(output)
return final_output
def _retrieve_from_cache(self, kv_cache: KVCache) -> Tuple[Tensor, Tensor]:
"""从KV缓存检索数据"""
# 获取当前序列的块表
block_table = kv_cache.get_block_table(self.sequence_id)
# 计算需要访问的块
blocks_to_access = self._calculate_blocks_to_access(block_table)
# 批量读取块数据
K_blocks = []
V_blocks = []
for block_id in blocks_to_access:
K_block, V_block = kv_cache.read_block(block_id)
K_blocks.append(K_block)
V_blocks.append(V_block)
# 合并块数据
K = torch.cat(K_blocks, dim=1)
V = torch.cat(V_blocks, dim=1)
return K, V
def _compute_attention_scores(self, Q: Tensor, K: Tensor,
mask: Tensor) -> Tensor:
"""计算注意力分数(优化版)"""
# 使用分块计算避免O(n^2)内存
batch_size, num_heads, seq_len, head_dim = Q.shape
# 分块大小
chunk_size = min(seq_len, 256)
scores = torch.zeros(
batch_size, num_heads, seq_len, seq_len,
device=Q.device, dtype=Q.dtype
)
# 分块计算
for i in range(0, seq_len, chunk_size):
i_end = min(i + chunk_size, seq_len)
for j in range(0, seq_len, chunk_size):
j_end = min(j + chunk_size, seq_len)
# 计算当前块的注意力分数
Q_chunk = Q[:, :, i:i_end, :]
K_chunk = K[:, :, j:j_end, :]
chunk_scores = torch.matmul(Q_chunk, K_chunk.transpose(-2, -1))
chunk_scores = chunk_scores / math.sqrt(head_dim)
# 应用注意力掩码
if mask is not None:
mask_chunk = mask[:, i:i_end, j:j_end]
chunk_scores = chunk_scores.masked_fill(
mask_chunk == 0, float('-inf')
)
scores[:, :, i:i_end, j:j_end] = chunk_scores
return scores
2. KV缓存管理
class KVCacheManager:
"""KV缓存管理器"""
def __init__(self, config):
self.cache_pool = MemoryPool(config.cache_size)
self.block_size = config.block_size
self.eviction_policy = config.eviction_policy
self.sequence_blocks = {} # sequence_id -> [block_ids]
self.block_metadata = {} # block_id -> BlockMetadata
def allocate(self, sequence_id: str, num_tokens: int) -> List[int]:
"""为序列分配缓存块"""
required_blocks = math.ceil(num_tokens / self.block_size)
# 检查现有分配
if sequence_id in self.sequence_blocks:
existing_blocks = self.sequence_blocks[sequence_id]
existing_capacity = len(existing_blocks) * self.block_size
if existing_capacity >= num_tokens:
return existing_blocks[:required_blocks]
# 需要新分配
new_blocks = []
for _ in range(required_blocks):
# 尝试分配新块
block_id = self._allocate_block()
if block_id is None:
# 内存不足,触发淘汰
self._evict_blocks()
block_id = self._allocate_block()
if block_id is None:
raise OutOfMemoryError("Cannot allocate KV cache block")
new_blocks.append(block_id)
# 更新序列块映射
if sequence_id in self.sequence_blocks:
self.sequence_blocks[sequence_id].extend(new_blocks)
else:
self.sequence_blocks[sequence_id] = new_blocks
return new_blocks
def _allocate_block(self) -> Optional[int]:
"""分配单个缓存块"""
# 尝试从内存池分配
memory_chunk = self.cache_pool.allocate(self.block_size)
if memory_chunk is None:
return None
# 创建块元数据
block_id = self._generate_block_id()
self.block_metadata[block_id] = BlockMetadata(
id=block_id,
memory_chunk=memory_chunk,
sequence_id=None,
last_access_time=time.time(),
access_count=0
)
return block_id
def _evict_blocks(self):
"""淘汰缓存块"""
if self.eviction_policy == 'lru':
eviction_candidates = self._get_lru_candidates()
elif self.eviction_policy == 'lfu':
eviction_candidates = self._get_lfu_candidates()
elif self.eviction_policy == 'random':
eviction_candidates = self._get_random_candidates()
# 淘汰选中的块
for block_id in eviction_candidates:
self._evict_block(block_id)
def _evict_block(self, block_id: int):
"""淘汰单个块"""
metadata = self.block_metadata[block_id]
# 从序列映射中移除
if metadata.sequence_id:
seq_blocks = self.sequence_blocks[metadata.sequence_id]
if block_id in seq_blocks:
seq_blocks.remove(block_id)
# 释放内存
self.cache_pool.free(metadata.memory_chunk)
# 移除元数据
del self.block_metadata[block_id]
def update(self, sequence_id: str, new_token: int,
K: Tensor, V: Tensor):
"""更新KV缓存"""
# 获取序列的块表
block_table = self.sequence_blocks.get(sequence_id, [])
if not block_table:
raise ValueError(f"No cache allocated for sequence {sequence_id}")
# 计算token所在的块和偏移
token_index = self._get_sequence_length(sequence_id)
block_index = token_index // self.block_size
block_offset = token_index % self.block_size
if block_index >= len(block_table):
# 需要新块
new_block = self._allocate_block()
if new_block is None:
self._evict_blocks()
new_block = self._allocate_block()
block_table.append(new_block)
self.sequence_blocks[sequence_id] = block_table
# 写入KV缓存
block_id = block_table[block_index]
self._write_to_block(block_id, block_offset, K, V)
# 更新元数据
metadata = self.block_metadata[block_id]
metadata.last_access_time = time.time()
metadata.access_count += 1
metadata.sequence_id = sequence_id
3. 算子执行优化
class OperatorExecutor:
"""算子执行器"""
def execute(self, operator: Operator, inputs: Dict[str, Tensor],
context: ExecutionContext) -> Tensor:
"""执行算子"""
# 选择最优实现
implementation = self._select_implementation(operator, inputs, context)
# 准备执行环境
execution_env = self._prepare_environment(implementation, context)
# 执行算子
with torch.cuda.stream(execution_env.stream):
output = implementation.execute(inputs)
# 同步和清理
if context.requires_sync:
execution_env.stream.synchronize()
return output
def _select_implementation(self, operator: Operator,
inputs: Dict[str, Tensor],
context: ExecutionContext) -> OperatorImpl:
"""选择最优算子实现"""
available_impls = operator.get_implementations()
# 根据硬件特性筛选
compatible_impls = []
for impl in available_impls:
if self._is_compatible(impl, context.hardware):
compatible_impls.append(impl)
if not compatible_impls:
raise NoCompatibleImplementationError(
f"No compatible implementation for {operator.name}"
)
# 根据输入特征选择
best_impl = None
best_score = -1
for impl in compatible_impls:
score = self._score_implementation(impl, inputs, context)
if score > best_score:
best_score = score
best_impl = impl
return best_impl
def _score_implementation(self, impl: OperatorImpl,
inputs: Dict[str, Tensor],
context: ExecutionContext) -> float:
"""评分算子实现"""
score = 0.0
# 考虑计算效率
compute_efficiency = self._estimate_compute_efficiency(impl, inputs)
score += compute_efficiency * 0.4
# 考虑内存效率
memory_efficiency = self._estimate_memory_efficiency(impl, inputs)
score += memory_efficiency * 0.3
# 考虑硬件适配
hardware_compatibility = self._check_hardware_compatibility(impl, context)
score += hardware_compatibility * 0.2
# 考虑实现成熟度
implementation_maturity = impl.maturity_score
score += implementation_maturity * 0.1
return score
结果后处理与返回
1. 解码策略
class DecodingStrategy:
"""解码策略基类"""
def decode(self, logits: Tensor, context: DecodingContext) -> DecodedOutput:
"""解码logits为token"""
raise NotImplementedError
class GreedyDecoding(DecodingStrategy):
"""贪心解码"""
def decode(self, logits: Tensor, context: DecodingContext) -> DecodedOutput:
# 选择概率最高的token
next_token = torch.argmax(logits[:, -1, :], dim=-1)
return DecodedOutput(
token_ids=next_token,
scores=torch.max(logits[:, -1, :], dim=-1).values,
finished=self._check_finished(next_token, context)
)
class SamplingDecoding(DecodingStrategy):
"""采样解码"""
def decode(self, logits: Tensor, context: DecodingContext) -> DecodedOutput:
# 应用温度
if context.temperature > 0:
logits = logits / context.temperature
# 应用top-p过滤
if context.top_p < 1.0:
logits = self._apply_top_p(logits, context.top_p)
# 应用top-k过滤
if context.top_k > 0:
logits = self._apply_top_k(logits, context.top_k)
# 采样
probs = torch.softmax(logits[:, -1, :], dim=-1)
next_token = torch.multinomial(probs, num_samples=1).squeeze(-1)
return DecodedOutput(
token_ids=next_token,
scores=probs.gather(-1, next_token.unsqueeze(-1)).squeeze(-1),
finished=self._check_finished(next_token, context)
)
class BeamSearchDecoding(DecodingStrategy):
"""束搜索解码"""
def decode(self, logits: Tensor, context: DecodingContext) -> DecodedOutput:
beam_width = context.beam_width
# 扩展beam
expanded_logits = logits.repeat_interleave(beam_width, dim=0)
# 计算top-k候选
topk_values, topk_indices = torch.topk(
expanded_logits[:, -1, :],
k=beam_width,
dim=-1
)
# 更新beam状态
new_beams = []
for beam_idx in range(beam_width):
for candidate_idx in range(beam_width):
token_id = topk_indices[beam_idx, candidate_idx]
score = topk_values[beam_idx, candidate_idx]
new_beam = Beam(
token_ids=context.beams[beam_idx].token_ids + [token_id],
score=context.beams[beam_idx].score + score,
finished=self._check_finished(token_id, context)
)
new_beams.append(new_beam)
# 选择top beam_width个beam
new_beams.sort(key=lambda b: b.score, reverse=True)
selected_beams = new_beams[:beam_width]
return DecodedOutput(
beams=selected_beams,
finished=all(b.finished for b in selected_beams)
)
2. Token转换与流式输出
class OutputProcessor:
"""输出处理器"""
def __init__(self, tokenizer):
self.tokenizer = tokenizer
self.streaming_buffers = {}
def process(self, decoded_output: DecodedOutput,
request: Request) -> ProcessedOutput:
"""处理解码输出"""
# 转换为文本
text_output = self._tokens_to_text(decoded_output.token_ids, request)
# 构建响应
response = {
'id': request.request_id,
'object': 'text_completion',
'created': int(time.time()),
'model': request.model,
'choices': [{
'text': text_output,
'index': 0,
'logprobs': decoded_output.logprobs if hasattr(decoded_output, 'logprobs') else None,
'finish_reason': decoded_output.finish_reason
}],
'usage': {
'prompt_tokens': request.prompt_tokens,
'completion_tokens': len(decoded_output.token_ids),
'total_tokens': request.prompt_tokens + len(decoded_output.token_ids)
}
}
return ProcessedOutput(
response=response,
raw_tokens=decoded_output.token_ids,
finished=decoded_output.finished
)
def stream_process(self, decoded_output: DecodedOutput,
request: Request) -> StreamingChunk:
"""流式处理输出"""
request_id = request.request_id
# 初始化缓冲区
if request_id not in self.streaming_buffers:
self.streaming_buffers[request_id] = {
'token_buffer': [],
'text_buffer': '',
'last_sent_index': 0
}
buffer = self.streaming_buffers[request_id]
# 添加新token到缓冲区
buffer['token_buffer'].extend(decoded_output.token_ids)
# 转换为文本
full_text = self._tokens_to_text(buffer['token_buffer'], request)
# 提取新增文本
new_text = full_text[len(buffer['text_buffer']):]
buffer['text_buffer'] = full_text
# 构建流式chunk
chunk = {
'id': request_id,
'object': 'text_completion.chunk',
'created': int(time.time()),
'model': request.model,
'choices': [{
'text': new_text,
'index': 0,
'finish_reason': decoded_output.finish_reason if decoded_output.finished else None
}]
}
# 清理完成的请求
if decoded_output.finished:
del self.streaming_buffers[request_id]
return StreamingChunk(
chunk=chunk,
finished=decoded_output.finished
)
def _tokens_to_text(self, token_ids: List[int], request: Request) -> str:
"""将token IDs转换为文本"""
# 使用tokenizer解码
text = self.tokenizer.decode(
token_ids,
skip_special_tokens=not request.echo,
clean_up_tokenization_spaces=True
)
# 处理停止序列
if request.stop_sequences:
for stop_seq in request.stop_sequences:
if stop_seq in text:
text = text.split(stop_seq)[0]
return text
二、vLLM实战部署——单机部署
2.1 部署环境准备
硬件要求
| GPU型号 | 最小显存 | 推荐显存 | 支持模型规模 | 备注 |
|---|---|---|---|---|
| NVIDIA RTX 3060/4060 | 8GB | 12GB | ≤7B | 入门级推理 |
| NVIDIA RTX 3090/4090 | 12GB | 24GB | ≤13B | 主流消费级 |
| NVIDIA A10 | 12GB | 24GB | ≤13B | 云服务器常用 |
| NVIDIA A100 40GB | 20GB | 40GB | ≤70B | 专业级单卡 |
| NVIDIA A100 80GB | 40GB | 80GB | ≤175B | 大模型推理 |
| NVIDIA H100 80GB | 40GB | 80GB | ≤340B | 最新架构 |
CPU与内存要求:
- CPU:≥4核,支持AVX2指令集
- 系统内存:≥16GB(建议≥32GB,与模型大小成正比)
- 硬盘空间:≥50GB可用空间(用于模型缓存)
软件环境配置
# 1. 操作系统检查(以Ubuntu 20.04/22.04为例)
cat /etc/os-release
uname -a
# 2. 安装Python 3.8+
python3 --version
# 如果版本低于3.8,安装Python 3.9:
sudo apt update
sudo apt install python3.9 python3.9-venv python3.9-dev
# 3. 安装CUDA Toolkit(根据GPU驱动版本选择)
# 查看CUDA版本
nvidia-smi
# 安装对应版本的CUDA Toolkit,例如CUDA 11.8:
wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run
sudo sh cuda_11.8.0_520.61.05_linux.run
# 4. 安装cuDNN(可选但推荐)
# 从NVIDIA开发者网站下载对应版本
# 5. 创建虚拟环境
python3.9 -m venv vllm_env
source vllm_env/bin/activate
# 6. 升级pip
pip install --upgrade pip
vLLM安装步骤
方式一:pip安装(推荐)
# 安装vLLM核心包
pip install vllm
# 安装可选依赖
pip install vllm[all] # 包含所有可选依赖
# 或按需安装
pip install vllm[awq] # 支持AWQ量化
pip install vllm[tensorizer] # 支持Tensorizer
pip install vllm[benchmark] # 包含基准测试工具
方式二:源码编译安装(适用于开发或最新特性)
# 1. 克隆源码
git clone https://github.com/vllm-project/vllm.git
cd vllm
# 2. 安装编译依赖
pip install -e ".[all]"
# 或使用make安装
make install
# 3. 验证安装
python -c "import vllm; print(vllm.__version__)"
方式三:Docker安装(生产环境推荐)
# 1. 拉取官方镜像
docker pull vllm/vllm-openai:latest
# 2. 运行容器
docker run --runtime nvidia --gpus all \
-p 8000:8000 \
--env MODEL=huggyllama/llama-7b \
vllm/vllm-openai:latest
# 3. 或使用docker-compose
cat > docker-compose.yml << EOF
version: '3'
services:
vllm:
image: vllm/vllm-openai:latest
runtime: nvidia
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
ports:
- "8000:8000"
environment:
- MODEL=meta-llama/Llama-2-7b-chat-hf
- HOST=0.0.0.0
- PORT=8000
- GPU_MEMORY_UTILIZATION=0.9
volumes:
- ./models:/models
- ./data:/data
EOF
docker-compose up -d
2.2 单机离线推理实战
支持的模型类型与加载方式
vLLM支持多种模型格式,主要包括:
-
Hugging Face模型:
from vllm import LLM # 从Hugging Face加载 llm = LLM(model="meta-llama/Llama-2-7b-chat-hf") # 指定特定版本 llm = LLM(model="meta-llama/Llama-2-7b-chat-hf", revision="main") -
本地模型:
# 本地目录结构 # /path/to/model/ # ├── config.json # ├── model.safetensors # └── tokenizer.json llm = LLM(model="/path/to/model") -
量化模型:
# AWQ量化 llm = LLM( model="TheBloke/Llama-2-7B-Chat-AWQ", quantization="awq", dtype="float16" ) # GPTQ量化 llm = LLM( model="TheBloke/Llama-2-7B-Chat-GPTQ", quantization="gptq", dtype="float16" ) # SqueezeLLM量化 llm = LLM( model="squeeze-llm/Llama-2-7B-Chat-4bit", quantization="squeezellm" ) -
自定义模型:
from vllm import LLM, SamplingParams from vllm.model_executor.models import LlamaForCausalLM from vllm.model_executor.weight_utils import ( initialize_dummy_weights, get_quant_config) # 自定义模型类 class CustomLlamaForCausalLM(LlamaForCausalLM): def __init__(self, *args, **kwargs): super().__init__(*args, **kwargs) # 加载自定义模型 llm = LLM( model="meta-llama/Llama-2-7b-chat-hf", model_loader=CustomLlamaForCausalLM )
完整可运行代码
# vllm_offline_inference.py
import torch
from vllm import LLM, SamplingParams
from vllm.model_executor.parallel_utils.parallel_state import destroy_model_parallel
import time
import json
from typing import List, Dict, Any
import argparse
class VLLMInferenceDemo:
"""vLLM离线推理演示类"""
def __init__(self, model_path: str, **kwargs):
"""
初始化推理引擎
参数:
model_path: 模型路径
**kwargs: 传递给LLM的额外参数
"""
self.model_path = model_path
self.model_args = kwargs
self.llm = None
self.tokenizer = None
def initialize(self):
"""初始化模型和分词器"""
print(f"正在加载模型: {self.model_path}")
start_time = time.time()
# 构建LLM配置
llm_kwargs = {
"model": self.model_path,
"trust_remote_code": True,
"max_num_seqs": 16, # 最大并发序列数
"max_model_len": 4096, # 最大模型长度
"gpu_memory_utilization": 0.9, # GPU内存利用率
"swap_space": 4, # CPU交换空间(GB)
"tensor_parallel_size": 1, # 张量并行大小
"dtype": "auto", # 自动选择精度
"seed": 42, # 随机种子
"enforce_eager": False, # 是否强制eager模式
}
# 更新用户参数
llm_kwargs.update(self.model_args)
# 加载模型
self.llm = LLM(**llm_kwargs)
# 获取分词器
self.tokenizer = self.llm.get_tokenizer()
load_time = time.time() - start_time
print(f"模型加载完成,耗时: {load_time:.2f}秒")
print(f"模型配置: {json.dumps(llm_kwargs, indent=2, default=str)}")
def generate_text(
self,
prompts: List[str],
max_tokens: int = 100,
temperature: float = 0.7,
top_p: float = 0.9,
top_k: int = 50,
frequency_penalty: float = 0.0,
presence_penalty: float = 0.0,
stop: List[str] = None,
stream: bool = False,
**kwargs
) -> List[Dict[str, Any]]:
"""
生成文本
参数:
prompts: 提示词列表
max_tokens: 最大生成token数
temperature: 温度参数
top_p: top-p采样参数
top_k: top-k采样参数
frequency_penalty: 频率惩罚
presence_penalty: 存在惩罚
stop: 停止词列表
stream: 是否流式输出
**kwargs: 其他采样参数
返回:
生成结果列表
"""
if self.llm is None:
raise RuntimeError("请先调用initialize()初始化模型")
# 设置采样参数
sampling_params = SamplingParams(
n=1, # 每个提示生成n个结果
best_of=None, # 从best_of个候选中选择
presence_penalty=presence_penalty,
frequency_penalty=frequency_penalty,
repetition_penalty=1.0 + frequency_penalty, # 重复惩罚
temperature=temperature,
top_p=top_p,
top_k=top_k,
min_p=0.0, # 最小概率阈值
seed=42,
stop=stop or [],
stop_token_ids=self._get_stop_token_ids(stop) if stop else None,
ignore_eos=False, # 是否忽略EOS token
max_tokens=max_tokens,
logprobs=None, # 返回logprobs的数量
prompt_logprobs=None, # 提示词的logprobs
skip_special_tokens=True, # 跳过特殊token
spaces_between_special_tokens=True,
)
print(f"\n开始生成,批量大小: {len(prompts)}")
print(f"采样参数: temperature={temperature}, top_p={top_p}, max_tokens={max_tokens}")
# 执行推理
start_time = time.time()
if stream:
# 流式生成
outputs = []
for prompt in prompts:
stream_output = self.llm.generate(
prompt,
sampling_params,
use_tqdm=True
)
outputs.append(list(stream_output))
else:
# 批量生成
outputs = self.llm.generate(prompts, sampling_params)
inference_time = time.time() - start_time
# 处理结果
results = []
total_tokens = 0
for i, output in enumerate(outputs):
if stream:
# 处理流式输出
full_output = ""
for chunk in output:
if hasattr(chunk.outputs[0], 'text'):
full_output += chunk.outputs[0].text
result = {
"prompt": prompts[i],
"generated_text": full_output,
"finish_reason": "length" if len(full_output) >= max_tokens else "stop",
}
else:
# 处理批量输出
generated_text = output.outputs[0].text
token_ids = output.outputs[0].token_ids
total_tokens += len(token_ids)
result = {
"prompt": output.prompt,
"generated_text": generated_text,
"finish_reason": output.outputs[0].finish_reason,
"token_ids": token_ids,
"cumulative_logprob": output.outputs[0].cumulative_logprob,
"logprobs": output.outputs[0].logprobs if hasattr(output.outputs[0], 'logprobs') else None,
"prompt_token_ids": output.prompt_token_ids,
"prompt_logprobs": output.prompt_logprobs if hasattr(output, 'prompt_logprobs') else None,
}
results.append(result)
# 打印结果
print(f"\n{'='*50}")
print(f"结果 {i+1}/{len(prompts)}:")
print(f"提示: {prompts[i][:100]}..." if len(prompts[i]) > 100 else f"提示: {prompts[i]}")
print(f"生成: {result['generated_text']}")
print(f"结束原因: {result['finish_reason']}")
if not stream:
print(f"生成长度: {len(result['token_ids'])} tokens")
# 性能统计
print(f"\n{'='*50}")
print(f"性能统计:")
print(f" 总推理时间: {inference_time:.2f}秒")
print(f" 总生成token数: {total_tokens}")
if total_tokens > 0:
print(f" 吞吐量: {total_tokens/inference_time:.2f} tokens/秒")
print(f" 每个token平均时间: {inference_time/total_tokens*1000:.2f}ms")
return results
def _get_stop_token_ids(self, stop_strings: List[str]) -> List[int]:
"""将停止字符串转换为token ids"""
stop_token_ids = []
for stop_str in stop_strings:
token_ids = self.tokenizer.encode(stop_str, add_special_tokens=False)
if token_ids:
stop_token_ids.append(token_ids[0]) # 只取第一个token
return stop_token_ids
def benchmark(
self,
prompts: List[str],
batch_sizes: List[int] = [1, 2, 4, 8, 16],
max_tokens: int = 100,
num_runs: int = 3
) -> Dict[str, Any]:
"""
性能基准测试
参数:
prompts: 测试提示词列表
batch_sizes: 测试的批次大小列表
max_tokens: 生成的最大token数
num_runs: 每个配置的运行次数
返回:
基准测试结果
"""
print(f"\n{'='*50}")
print("开始性能基准测试")
print(f"测试批次大小: {batch_sizes}")
print(f"每个配置运行次数: {num_runs}")
benchmark_results = {}
for batch_size in batch_sizes:
print(f"\n测试批次大小: {batch_size}")
batch_times = []
token_throughputs = []
for run in range(num_runs):
# 准备当前批次的提示词
current_prompts = prompts[:batch_size]
if len(current_prompts) < batch_size:
# 重复提示词以填充批次
current_prompts = (current_prompts * (batch_size // len(current_prompts) + 1))[:batch_size]
# 运行推理
start_time = time.time()
results = self.generate_text(
prompts=current_prompts,
max_tokens=max_tokens,
temperature=0.0, # 使用贪心解码保证一致性
stream=False
)
end_time = time.time()
# 计算统计
run_time = end_time - start_time
total_tokens = sum(len(r['token_ids']) for r in results)
throughput = total_tokens / run_time
batch_times.append(run_time)
token_throughputs.append(throughput)
print(f" 运行 {run+1}: {run_time:.2f}秒, {throughput:.2f} tokens/秒")
# 计算平均和标准差
avg_time = sum(batch_times) / len(batch_times)
avg_throughput = sum(token_throughputs) / len(token_throughputs)
std_throughput = (sum((t - avg_throughput) ** 2 for t in token_throughputs) / len(token_throughputs)) ** 0.5
benchmark_results[batch_size] = {
"avg_time_seconds": avg_time,
"avg_throughput_tokens_per_second": avg_throughput,
"std_throughput": std_throughput,
"batch_times": batch_times,
"throughputs": token_throughputs
}
return benchmark_results
def save_results(self, results: List[Dict[str, Any]], filename: str = "results.json"):
"""保存结果到文件"""
with open(filename, 'w', encoding='utf-8') as f:
json.dump(results, f, ensure_ascii=False, indent=2)
print(f"\n结果已保存到: {filename}")
def cleanup(self):
"""清理资源"""
if self.llm is not None:
destroy_model_parallel()
self.llm = None
torch.cuda.empty_cache()
print("资源已清理")
def main():
"""主函数"""
parser = argparse.ArgumentParser(description="vLLM离线推理演示")
parser.add_argument("--model", type=str, required=True, help="模型路径或Hugging Face模型ID")
parser.add_argument("--prompt", type=str, default="请介绍一下人工智能的发展历史:", help="提示词")
parser.add_argument("--max-tokens", type=int, default=100, help="最大生成token数")
parser.add_argument("--temperature", type=float, default=0.7, help="温度参数")
parser.add_argument("--top-p", type=float, default=0.9, help="top-p采样参数")
parser.add_argument("--batch-size", type=int, default=1, help="批处理大小")
parser.add_argument("--quantization", type=str, choices=[None, "awq", "gptq", "squeezellm"], default=None, help="量化方法")
parser.add_argument("--dtype", type=str, default="auto", help="数据类型")
parser.add_argument("--gpu-memory-utilization", type=float, default=0.9, help="GPU内存利用率")
parser.add_argument("--run-benchmark", action="store_true", help="运行性能基准测试")
parser.add_argument("--output-file", type=str, default="inference_results.json", help="输出文件路径")
args = parser.parse_args()
# 创建推理实例
inference = VLLMInferenceDemo(
model_path=args.model,
quantization=args.quantization,
dtype=args.dtype,
gpu_memory_utilization=args.gpu_memory_utilization,
tensor_parallel_size=1,
)
try:
# 初始化模型
inference.initialize()
# 准备提示词
prompts = [args.prompt] * args.batch_size
if args.run_benchmark:
# 运行基准测试
benchmark_prompts = [
"什么是机器学习?",
"请解释深度学习的基本原理。",
"人工智能有哪些应用领域?",
"自然语言处理是什么?",
"计算机视觉的主要任务是什么?"
]
results = inference.benchmark(
prompts=benchmark_prompts,
batch_sizes=[1, 2, 4, 8],
max_tokens=args.max_tokens,
num_runs=3
)
# 保存基准测试结果
with open("benchmark_results.json", 'w') as f:
json.dump(results, f, indent=2)
else:
# 运行推理
results = inference.generate_text(
prompts=prompts,
max_tokens=args.max_tokens,
temperature=args.temperature,
top_p=args.top_p,
stop=["。", "!", "?"], # 中文停止词
stream=False
)
# 保存结果
inference.save_results(results, args.output_file)
finally:
# 清理资源
inference.cleanup()
if __name__ == "__main__":
main()
运行示例:
# 基本推理
python vllm_offline_inference.py \
--model "meta-llama/Llama-2-7b-chat-hf" \
--prompt "请介绍一下人工智能的发展历史:" \
--max-tokens 200 \
--temperature 0.7 \
--batch-size 4
# 使用量化模型
python vllm_offline_inference.py \
--model "TheBloke/Llama-2-7B-Chat-AWQ" \
--quantization awq \
--prompt "What is the meaning of life?" \
--max-tokens 100
# 运行基准测试
python vllm_offline_inference.py \
--model "meta-llama/Llama-2-7b-chat-hf" \
--run-benchmark \
--batch-size 8
关键参数调优
# 优化配置示例
llm = LLM(
model="meta-llama/Llama-2-7b-chat-hf",
# 1. 批处理与并发参数
max_num_batched_tokens=4096, # 最大批处理token数
max_num_seqs=16, # 最大并发序列数
max_paddings=128, # 最大填充数
# 2. 内存优化参数
gpu_memory_utilization=0.9, # GPU内存利用率 (0.0-1.0)
swap_space=8, # CPU交换空间(GB),用于KV缓存
enforce_eager=False, # 禁用eager模式以启用图优化
# 3. 模型参数
max_model_len=4096, # 最大模型长度
download_dir="./models", # 模型下载目录
load_format="auto", # 加载格式: auto, pt, safetensors, numpy
# 4. 性能参数
disable_custom_all_reduce=False, # 是否禁用自定义all-reduce
tokenizer_mode="auto", # tokenizer模式: auto, slow
tensor_parallel_size=1, # 张量并行大小
pipeline_parallel_size=1, # 流水线并行大小
# 5. 量化参数
quantization="awq", # 量化方法
quantization_param_path=None, # 量化参数路径
dtype="auto", # 数据类型: auto, half, float16, bfloat16
# 6. 高级参数
seed=42, # 随机种子
served_model_name=None, # 服务模型名称
block_size=16, # KV缓存块大小
enable_prefix_caching=False, # 是否启用前缀缓存
# 7. 分布式参数
distributed_executor_backend="nccl", # 分布式后端
ray_workers_use_nsight=False, # 是否使用Nsight
trust_remote_code=True, # 信任远程代码
)
参数调优建议:
-
显存优化:
# 根据GPU显存调整 gpu_memory = torch.cuda.get_device_properties(0).total_memory / 1e9 # GB if gpu_memory < 16: # 小显存显卡 llm = LLM(model=model, gpu_memory_utilization=0.85, swap_space=4) elif gpu_memory < 24: # 中等显存 llm = LLM(model=model, gpu_memory_utilization=0.9, swap_space=8) else: # 大显存 llm = LLM(model=model, gpu_memory_utilization=0.95, swap_space=16) -
批处理优化:
# 根据请求模式调整 if is_interactive: # 交互式应用 llm = LLM(model=model, max_num_seqs=4, max_num_batched_tokens=1024) else: # 批量处理 llm = LLM(model=model, max_num_seqs=32, max_num_batched_tokens=8192) -
精度优化:
# 根据模型和硬件选择 if supports_bfloat16: # A100+支持bfloat16 llm = LLM(model=model, dtype="bfloat16") elif supports_fp16: # 大多数GPU支持fp16 llm = LLM(model=model, dtype="float16") else: # 回退到fp32 llm = LLM(model=model, dtype="float32")
2.3 单机在线服务部署
vLLM内置API服务器启动
vLLM提供了开箱即用的API服务器,兼容OpenAI API格式。
基本启动命令:
# 启动OpenAI兼容API服务器
python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--host 0.0.0.0 \
--port 8000 \
--served-model-name llama-2-7b-chat \
--api-key "sk-1234567890abcdef" \
--log-level info
完整配置示例:
# 创建启动脚本 start_server.sh
#!/bin/bash
# 服务器配置
MODEL="meta-llama/Llama-2-7b-chat-hf"
HOST="0.0.0.0"
PORT=8000
API_KEY="sk-$(openssl rand -hex 16)" # 生成随机API密钥
LOG_LEVEL="info"
WORKERS=1
# 模型加载配置
MAX_MODEL_LEN=4096
GPU_MEMORY_UTILIZATION=0.9
QUANTIZATION="" # awq, gptq, squeezellm
DTYPE="auto"
TRUST_REMOTE_CODE=true
# 批处理配置
MAX_NUM_SEQS=16
MAX_NUM_BATCHED_TOKENS=4096
MAX_PADDINGS=128
# 服务配置
MAX_CONCURRENT_REQUESTS=100
REQUEST_TIMEOUT=600
ALLOW_ORIGINS='["*"]' # CORS设置
ALLOW_CREDENTIALS=true
# 启动命令
python -m vllm.entrypoints.openai.api_server \
--model $MODEL \
--host $HOST \
--port $PORT \
--served-model-name llama-2-7b-chat \
--api-key $API_KEY \
--log-level $LOG_LEVEL \
--workers $WORKERS \
\
--max-model-len $MAX_MODEL_LEN \
--gpu-memory-utilization $GPU_MEMORY_UTILIZATION \
${QUANTIZATION:+--quantization $QUANTIZATION} \
--dtype $DTYPE \
--trust-remote-code $TRUST_REMOTE_CODE \
\
--max-num-seqs $MAX_NUM_SEQS \
--max-num-batched-tokens $MAX_NUM_BATCHED_TOKENS \
--max-paddings $MAX_PADDINGS \
\
--max-concurrent-requests $MAX_CONCURRENT_REQUESTS \
--request-timeout $REQUEST_TIMEOUT \
--allow-origins '$ALLOW_ORIGINS' \
--allow-credentials $ALLOW_CREDENTIALS \
\
--enable-prefix-caching true \
--block-size 16 \
--swap-space 8 \
--disable-custom-all-reduce false
使用systemd管理服务:
# 创建systemd服务文件 /etc/systemd/system/vllm.service
[Unit]
Description=vLLM API Server
After=network.target
Requires=network.target
[Service]
Type=exec
User=vllm
Group=vllm
WorkingDirectory=/opt/vllm
Environment="PATH=/usr/local/bin:/usr/bin:/bin"
Environment="CUDA_VISIBLE_DEVICES=0"
Environment="PYTHONPATH=/opt/vllm"
# 启动命令
ExecStart=/opt/vllm/venv/bin/python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--host 0.0.0.0 \
--port 8000 \
--served-model-name llama-2-7b-chat \
--api-key "sk-1234567890abcdef" \
--max-model-len 4096 \
--gpu-memory-utilization 0.9 \
--max-concurrent-requests 100 \
--request-timeout 600
# 重启策略
Restart=always
RestartSec=10
StartLimitInterval=0
# 资源限制
LimitNOFILE=65536
LimitNPROC=65536
LimitMEMLOCK=infinity
# 安全配置
PrivateTmp=true
NoNewPrivileges=true
ProtectSystem=strict
ReadWritePaths=/opt/vllm/models
ReadWritePaths=/opt/vllm/logs
# 日志配置
StandardOutput=journal
StandardError=journal
SyslogIdentifier=vllm
[Install]
WantedBy=multi-user.target
# 启用并启动服务
sudo systemctl daemon-reload
sudo systemctl enable vllm
sudo systemctl start vllm
# 查看服务状态
sudo systemctl status vllm
# 查看日志
sudo journalctl -u vllm -f
使用supervisor管理:
# /etc/supervisor/conf.d/vllm.conf
[program:vllm]
command=/opt/vllm/venv/bin/python -m vllm.entrypoints.openai.api_server \
--model meta-llama/Llama-2-7b-chat-hf \
--host 0.0.0.0 \
--port 8000 \
--served-model-name llama-2-7b-chat \
--api-key "sk-1234567890abcdef"
directory=/opt/vllm
user=vllm
autostart=true
autorestart=true
startsecs=10
startretries=3
stopasgroup=true
killasgroup=true
stdout_logfile=/var/log/vllm/out.log
stdout_logfile_maxbytes=50MB
stdout_logfile_backups=10
stderr_logfile=/var/log/vllm/err.log
stderr_logfile_maxbytes=50MB
stderr_logfile_backups=10
environment=
PATH="/opt/vllm/venv/bin:/usr/local/bin:/usr/bin:/bin",
CUDA_VISIBLE_DEVICES="0",
PYTHONPATH="/opt/vllm"
服务配置详解
网络配置:
# 网络绑定
--host 0.0.0.0 # 监听所有接口
--port 8000 # 监听端口
--workers 4 # Worker进程数
# CORS配置
--allow-origins '["http://localhost:3000", "https://example.com"]'
--allow-credentials true
--allow-methods '["GET", "POST", "OPTIONS"]'
--allow-headers '["*"]'
--expose-headers '["*"]'
--max-age 86400
安全配置:
# API密钥认证
--api-key "sk-1234567890abcdef" # 静态密钥
--api-keys "sk-abc,sk-def" # 多个密钥
--api-key-file /path/to/api_keys.txt # 从文件加载密钥
# 请求限制
--max-concurrent-requests 100 # 最大并发请求
--request-timeout 600 # 请求超时(秒)
--limit-requests 1000 # 每分钟请求限制
--limit-tokens 10000 # 每分钟token限制
模型配置:
# 模型加载
--model meta-llama/Llama-2-7b-chat-hf
--revision main # Git版本
--tokenizer meta-llama/Llama-2-7b-chat-hf # 单独指定tokenizer
--tokenizer-mode auto # tokenizer模式
--download-dir ./models # 下载目录
--load-format auto # 加载格式
# 精度配置
--dtype auto # 数据类型
--quantization awq # 量化
--quantization-param-path ./awq_params.json
性能配置:
# 批处理配置
--max-num-seqs 16 # 最大序列数
--max-num-batched-tokens 4096 # 最大批处理token
--max-paddings 128 # 最大填充
# 内存配置
--gpu-memory-utilization 0.9 # GPU内存利用率
--swap-space 8 # CPU交换空间(GB)
--block-size 16 # KV缓存块大小
--enable-prefix-caching true # 前缀缓存
# 并行配置
--tensor-parallel-size 1 # 张量并行
--pipeline-parallel-size 1 # 流水线并行
--worker-use-ray false # 是否使用Ray
服务调用示例
Python客户端调用:
# vllm_client.py
import openai
import json
from typing import Generator, Dict, Any, List
import time
from dataclasses import dataclass
from openai import OpenAI, Stream
from openai.types.chat import ChatCompletionChunk
from openai.types.completion import Completion
import asyncio
import aiohttp
@dataclass
class VLLMClientConfig:
"""vLLM客户端配置"""
base_url: str = "http://localhost:8000/v1"
api_key: str = "sk-1234567890abcdef"
timeout: int = 60
max_retries: int = 3
retry_delay: float = 1.0
class VLLMClient:
"""vLLM API客户端"""
def __init__(self, config: VLLMClientConfig = None):
self.config = config or VLLMClientConfig()
self.client = OpenAI(
base_url=self.config.base_url,
api_key=self.config.api_key,
timeout=self.config.timeout
)
def list_models(self) -> List[Dict[str, Any]]:
"""获取可用模型列表"""
try:
response = self.client.models.list()
return [model.model_dump() for model in response.data]
except Exception as e:
print(f"获取模型列表失败: {e}")
return []
def create_completion(
self,
prompt: str,
model: str = "llama-2-7b-chat",
max_tokens: int = 100,
temperature: float = 0.7,
top_p: float = 0.9,
top_k: int = 50,
frequency_penalty: float = 0.0,
presence_penalty: float = 0.0,
stop: List[str] = None,
stream: bool = False,
**kwargs
) -> Dict[str, Any]:
"""创建文本补全"""
for attempt in range(self.config.max_retries):
try:
if stream:
return self._stream_completion(
prompt=prompt,
model=model,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
top_k=top_k,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty,
stop=stop,
**kwargs
)
else:
response = self.client.completions.create(
model=model,
prompt=prompt,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
top_k=top_k,
frequency_penalty=frequency_penalty,
presence_penalty=presence_penalty,
stop=stop or [],
**kwargs
)
return response.model_dump()
except Exception as e:
if attempt == self.config.max_retries - 1:
raise
print(f"请求失败,重试 {attempt + 1}/{self.config.max_retries}: {e}")
time.sleep(self.config.retry_delay * (2 ** attempt))
def _stream_completion(self, **kwargs) -> Generator[Dict[str, Any], None, None]:
"""流式文本补全"""
response = self.client.completions.create(stream=True, **kwargs)
for chunk in response:
yield chunk.model_dump()
def create_chat_completion(
self,
messages: List[Dict[str, str]],
model: str = "llama-2-7b-chat",
max_tokens: int = 100,
temperature: float = 0.7,
top_p: float = 0.9,
stream: bool = False,
**kwargs
) -> Dict[str, Any]:
"""创建聊天补全"""
for attempt in range(self.config.max_retries):
try:
if stream:
return self._stream_chat_completion(
messages=messages,
model=model,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
**kwargs
)
else:
response = self.client.chat.completions.create(
model=model,
messages=messages,
max_tokens=max_tokens,
temperature=temperature,
top_p=top_p,
**kwargs
)
return response.model_dump()
except Exception as e:
if attempt == self.config.max_retries - 1:
raise
print(f"请求失败,重试 {attempt + 1}/{self.config.max_retries}: {e}")
time.sleep(self.config.retry_delay * (2 ** attempt))
def _stream_chat_completion(self, **kwargs) -> Generator[Dict[str, Any], None, None]:
"""流式聊天补全"""
response = self.client.chat.completions.create(stream=True, **kwargs)
for chunk in response:
yield chunk.model_dump()
def get_usage(self) -> Dict[str, Any]:
"""获取使用统计"""
try:
# 注意:vLLM API可能不直接提供此端点
# 这里是一个示例实现
import requests
response = requests.get(f"{self.config.base_url}/usage", timeout=10)
return response.json()
except Exception as e:
return {"error": str(e)}
def health_check(self) -> bool:
"""健康检查"""
try:
response = requests.get(f"{self.config.base_url}/health", timeout=5)
return response.status_code == 200
except:
return False
class AsyncVLLMClient:
"""异步vLLM客户端"""
def __init__(self, config: VLLMClientConfig = None):
self.config = config or VLLMClientConfig()
self.async_client = openai.AsyncOpenAI(
base_url=self.config.base_url,
api_key=self.config.api_key,
timeout=self.config.timeout
)
async def create_chat_completion_async(
self,
messages: List[Dict[str, str]],
**kwargs
) -> Dict[str, Any]:
"""异步创建聊天补全"""
response = await self.async_client.chat.completions.create(
messages=messages,
**kwargs
)
return response.model_dump()
async def create_completion_async(
self,
prompt: str,
**kwargs
) -> Dict[str, Any]:
"""异步创建文本补全"""
response = await self.async_client.completions.create(
prompt=prompt,
**kwargs
)
return response.model_dump()
# 使用示例
def demo_client():
"""客户端使用演示"""
config = VLLMClientConfig(
base_url="http://localhost:8000/v1",
api_key="sk-1234567890abcdef"
)
client = VLLMClient(config)
# 1. 获取模型列表
print("可用模型:")
models = client.list_models()
for model in models:
print(f" - {model['id']}")
# 2. 文本补全
print("\n文本补全示例:")
result = client.create_completion(
prompt="Once upon a time",
max_tokens=50,
temperature=0.7
)
print(f"生成结果: {result['choices'][0]['text']}")
# 3. 流式文本补全
print("\n流式文本补全:")
stream = client.create_completion(
prompt="The future of AI is",
max_tokens=30,
stream=True
)
for chunk in stream:
if chunk['choices'][0]['text']:
print(chunk['choices'][0]['text'], end='', flush=True)
print()
# 4. 聊天补全
print("\n聊天补全示例:")
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is the capital of France?"}
]
result = client.create_chat_completion(
messages=messages,
max_tokens=50
)
print(f"回答: {result['choices'][0]['message']['content']}")
# 5. 流式聊天补全
print("\n流式聊天补全:")
messages = [
{"role": "user", "content": "Tell me a short story about a cat."}
]
stream = client.create_chat_completion(
messages=messages,
max_tokens=100,
stream=True
)
for chunk in stream:
if chunk['choices'][0]['delta'].get('content'):
print(chunk['choices'][0]['delta']['content'], end='', flush=True)
print()
# 6. 健康检查
if client.health_check():
print("\n服务健康状态: ✓")
else:
print("\n服务健康状态: ✗")
if __name__ == "__main__":
demo_client()
Postman调用示例:
-
获取模型列表:
GET http://localhost:8000/v1/models Headers: Authorization: Bearer sk-1234567890abcdef -
文本补全:
POST http://localhost:8000/v1/completions Headers: Content-Type: application/json Authorization: Bearer sk-1234567890abcdef Body (raw JSON): { "model": "llama-2-7b-chat", "prompt": "Once upon a time", "max_tokens": 50, "temperature": 0.7, "top_p": 0.9, "stream": false } -
聊天补全:
POST http://localhost:8000/v1/chat/completions Headers: Content-Type: application/json Authorization: Bearer sk-1234567890abcdef Body: { "model": "llama-2-7b-chat", "messages": [ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "What is AI?"} ], "max_tokens": 100, "temperature": 0.7, "stream": false } -
流式聊天补全(SSE):
POST http://localhost:8000/v1/chat/completions Headers: Content-Type: application/json Accept: text/event-stream Authorization: Bearer sk-1234567890abcdef Body: { "model": "llama-2-7b-chat", "messages": [ {"role": "user", "content": "Tell me a joke"} ], "max_tokens": 50, "stream": true }
cURL调用示例:
# 1. 获取模型列表
curl http://localhost:8000/v1/models \
-H "Authorization: Bearer sk-1234567890abcdef"
# 2. 文本补全
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234567890abcdef" \
-d '{
"model": "llama-2-7b-chat",
"prompt": "Once upon a time",
"max_tokens": 50
}'
# 3. 聊天补全
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234567890abcdef" \
-d '{
"model": "llama-2-7b-chat",
"messages": [
{"role": "user", "content": "Hello, how are you?"}
],
"max_tokens": 50
}'
# 4. 流式聊天补全
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-1234567890abcdef" \
-H "Accept: text/event-stream" \
-d '{
"model": "llama-2-7b-chat",
"messages": [
{"role": "user", "content": "Tell me a story"}
],
"max_tokens": 100,
"stream": true
}'
服务监控与运维
1. 日志配置与查看:
# logging_config.py
import logging
import sys
from logging.handlers import RotatingFileHandler, TimedRotatingFileHandler
import json
from datetime import datetime
def setup_logging(log_dir: str = "./logs", level: str = "INFO"):
"""配置结构化日志"""
# 创建日志目录
import os
os.makedirs(log_dir, exist_ok=True)
# 创建格式化器
class StructuredFormatter(logging.Formatter):
def format(self, record):
log_record = {
"timestamp": datetime.utcnow().isoformat() + "Z",
"level": record.levelname,
"logger": record.name,
"message": record.getMessage(),
"module": record.module,
"function": record.funcName,
"line": record.lineno,
}
# 添加额外字段
if hasattr(record, 'request_id'):
log_record['request_id'] = record.request_id
if hasattr(record, 'model'):
log_record['model'] = record.model
if hasattr(record, 'latency'):
log_record['latency_ms'] = record.latency
if record.exc_info:
log_record['exception'] = self.formatException(record.exc_info)
return json.dumps(log_record, ensure_ascii=False)
# 创建日志处理器
formatter = StructuredFormatter()
# 控制台处理器
console_handler = logging.StreamHandler(sys.stdout)
console_handler.setFormatter(formatter)
console_handler.setLevel(level)
# 文件处理器 - 按大小轮转
file_handler = RotatingFileHandler(
filename=f"{log_dir}/vllm.log",
maxBytes=100 * 1024 * 1024, # 100MB
backupCount=10,
encoding='utf-8'
)
file_handler.setFormatter(formatter)
file_handler.setLevel(level)
# 错误日志处理器
error_handler = TimedRotatingFileHandler(
filename=f"{log_dir}/error.log",
when='midnight',
interval=1,
backupCount=30,
encoding='utf-8'
)
error_handler.setFormatter(formatter)
error_handler.setLevel(logging.ERROR)
# 配置根日志
root_logger = logging.getLogger()
root_logger.setLevel(getattr(logging, level))
# 移除现有处理器
for handler in root_logger.handlers[:]:
root_logger.removeHandler(handler)
# 添加新处理器
root_logger.addHandler(console_handler)
root_logger.addHandler(file_handler)
root_logger.addHandler(error_handler)
# 配置vLLM日志
vllm_logger = logging.getLogger("vllm")
vllm_logger.setLevel(getattr(logging, level))
return root_logger
# 在启动时调用
setup_logging(log_dir="./logs", level="INFO")
日志查看命令:
# 实时查看日志
tail -f logs/vllm.log | jq '.' # 使用jq美化JSON输出
# 查看错误日志
tail -f logs/error.log | jq '.'
# 按时间过滤日志
grep '"timestamp": "2024-01-15' logs/vllm.log | jq '.'
# 按级别过滤
grep '"level": "ERROR"' logs/vllm.log | jq '.'
# 统计错误数量
grep -c '"level": "ERROR"' logs/vllm.log
# 查看慢查询
grep '"latency_ms"' logs/vllm.log | jq 'select(.latency_ms > 1000)'
性能监控
Prometheus监控指标:
# prometheus_monitoring.py
import psutil
import GPUtil
from datetime import datetime
import time
import json
from typing import Dict, Any, List
import threading
from prometheus_client import start_http_server, Gauge, Counter, Histogram, Info, REGISTRY
import logging
from collections import defaultdict
import torch
import gc
logger = logging.getLogger(__name__)
class VLLMMonitor:
"""vLLM服务性能监控"""
def __init__(self, prometheus_port: int = 9090, collect_interval: int = 5):
"""
初始化监控器
参数:
prometheus_port: Prometheus HTTP服务器端口
collect_interval: 指标收集间隔(秒)
"""
self.prometheus_port = prometheus_port
self.collect_interval = collect_interval
self.running = False
self.monitor_thread = None
self.start_time = datetime.now()
# 初始化Prometheus指标
self._init_metrics()
# 存储历史数据
self.history = defaultdict(list)
self.max_history_size = 1000
def _init_metrics(self):
"""初始化Prometheus指标"""
# 1. 请求相关指标
self.requests_total = Counter(
'vllm_requests_total',
'总请求数',
['model', 'endpoint', 'status_code']
)
self.request_duration_seconds = Histogram(
'vllm_request_duration_seconds',
'请求处理时间(秒)',
['model', 'endpoint'],
buckets=[0.1, 0.5, 1.0, 2.0, 5.0, 10.0, 30.0, 60.0]
)
self.request_tokens_total = Counter(
'vllm_request_tokens_total',
'总处理token数',
['model', 'token_type'] # token_type: prompt, completion
)
# 2. 批量处理指标
self.batch_size = Gauge(
'vllm_batch_size',
'当前批次大小'
)
self.sequences_processed_total = Counter(
'vllm_sequences_processed_total',
'处理的序列总数'
)
# 3. GPU指标
self.gpu_utilization = Gauge(
'vllm_gpu_utilization_percent',
'GPU利用率百分比',
['gpu_id']
)
self.gpu_memory_used = Gauge(
'vllm_gpu_memory_used_bytes',
'GPU显存使用量(字节)',
['gpu_id']
)
self.gpu_memory_total = Gauge(
'vllm_gpu_memory_total_bytes',
'GPU显存总量(字节)',
['gpu_id']
)
self.gpu_temperature = Gauge(
'vllm_gpu_temperature_celsius',
'GPU温度(摄氏度)',
['gpu_id']
)
self.gpu_power_usage = Gauge(
'vllm_gpu_power_usage_watts',
'GPU功耗(瓦特)',
['gpu_id']
)
# 4. CPU和内存指标
self.cpu_utilization = Gauge(
'vllm_cpu_utilization_percent',
'CPU利用率百分比'
)
self.system_memory_used = Gauge(
'vllm_system_memory_used_bytes',
'系统内存使用量(字节)'
)
self.system_memory_total = Gauge(
'vllm_system_memory_total_bytes',
'系统内存总量(字节)'
)
# 5. 模型推理指标
self.inference_latency_seconds = Histogram(
'vllm_inference_latency_seconds',
'推理延迟(秒)',
['model', 'phase'], # phase: prefill, decode
buckets=[0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1.0]
)
self.tokens_per_second = Gauge(
'vllm_tokens_per_second',
'每秒处理的token数',
['model', 'phase']
)
# 6. KV缓存指标
self.kv_cache_blocks_used = Gauge(
'vllm_kv_cache_blocks_used',
'使用的KV缓存块数'
)
self.kv_cache_blocks_total = Gauge(
'vllm_kv_cache_blocks_total',
'KV缓存总块数'
)
self.kv_cache_hit_rate = Gauge(
'vllm_kv_cache_hit_rate',
'KV缓存命中率'
)
# 7. 服务指标
self.active_requests = Gauge(
'vllm_active_requests',
'活动中的请求数'
)
self.queued_requests = Gauge(
'vllm_queued_requests',
'排队中的请求数'
)
self.service_uptime_seconds = Gauge(
'vllm_service_uptime_seconds',
'服务运行时间(秒)'
)
# 8. 错误指标
self.errors_total = Counter(
'vllm_errors_total',
'总错误数',
['error_type', 'model']
)
# 9. 模型信息
self.model_info = Info(
'vllm_model_info',
'模型信息'
)
def start(self):
"""启动监控"""
if self.running:
logger.warning("监控已启动")
return
# 启动Prometheus HTTP服务器
start_http_server(self.prometheus_port)
logger.info(f"Prometheus指标服务器启动在端口 {self.prometheus_port}")
# 启动监控线程
self.running = True
self.monitor_thread = threading.Thread(
target=self._monitor_loop,
daemon=True,
name="vllm-monitor"
)
self.monitor_thread.start()
logger.info("性能监控已启动")
def stop(self):
"""停止监控"""
self.running = False
if self.monitor_thread:
self.monitor_thread.join(timeout=5)
logger.info("性能监控已停止")
def _monitor_loop(self):
"""监控循环"""
while self.running:
try:
# 收集系统指标
self._collect_system_metrics()
# 收集GPU指标
self._collect_gpu_metrics()
# 收集模型指标
self._collect_model_metrics()
# 收集服务指标
self._collect_service_metrics()
# 更新运行时间
uptime = (datetime.now() - self.start_time).total_seconds()
self.service_uptime_seconds.set(uptime)
# 存储历史数据
self._store_history()
except Exception as e:
logger.error(f"收集监控指标时出错: {e}")
# 等待下一个收集周期
time.sleep(self.collect_interval)
def _collect_system_metrics(self):
"""收集系统指标"""
try:
# CPU利用率
cpu_percent = psutil.cpu_percent(interval=None)
self.cpu_utilization.set(cpu_percent)
# 内存使用
memory = psutil.virtual_memory()
self.system_memory_used.set(memory.used)
self.system_memory_total.set(memory.total)
except Exception as e:
logger.warning(f"收集系统指标失败: {e}")
def _collect_gpu_metrics(self):
"""收集GPU指标"""
try:
gpus = GPUtil.getGPUs()
for gpu in gpus:
gpu_id = str(gpu.id)
# GPU利用率
self.gpu_utilization.labels(gpu_id=gpu_id).set(gpu.load * 100)
# GPU显存
self.gpu_memory_used.labels(gpu_id=gpu_id).set(gpu.memoryUsed * 1024 * 1024 * 1024)
self.gpu_memory_total.labels(gpu_id=gpu_id).set(gpu.memoryTotal * 1024 * 1024 * 1024)
# GPU温度
if hasattr(gpu, 'temperature') and gpu.temperature is not None:
self.gpu_temperature.labels(gpu_id=gpu_id).set(gpu.temperature)
# GPU功耗
if hasattr(gpu, 'powerDraw') and gpu.powerDraw is not None:
self.gpu_power_usage.labels(gpu_id=gpu_id).set(gpu.powerDraw)
except Exception as e:
# 如果GPUtil不可用,尝试使用PyTorch
try:
if torch.cuda.is_available():
for i in range(torch.cuda.device_count()):
gpu_id = str(i)
# GPU利用率(PyTorch不直接提供,使用nvidia-smi)
# 这里简化处理,实际生产环境可能需要调用nvidia-smi
# GPU显存
memory_allocated = torch.cuda.memory_allocated(i)
memory_reserved = torch.cuda.memory_reserved(i)
memory_total = torch.cuda.get_device_properties(i).total_memory
self.gpu_memory_used.labels(gpu_id=gpu_id).set(memory_allocated)
self.gpu_memory_total.labels(gpu_id=gpu_id).set(memory_total)
except Exception as e2:
logger.warning(f"收集GPU指标失败: {e2}")
def _collect_model_metrics(self):
"""收集模型指标"""
# 这里需要与vLLM引擎集成
# 实际实现中,需要从vLLM引擎获取这些指标
pass
def _collect_service_metrics(self):
"""收集服务指标"""
# 这里需要与API服务器集成
# 实际实现中,需要从API服务器获取这些指标
pass
def _store_history(self):
"""存储历史数据"""
# 收集当前所有指标值
current_time = datetime.now().timestamp()
metrics_snapshot = {}
# 获取所有指标
for collector, samples in REGISTRY.collect():
for sample in samples.samples:
metric_name = sample.name
metric_value = sample.value
labels = sample.labels
# 创建唯一键
if labels:
label_str = ','.join(f'{k}="{v}"' for k, v in labels.items())
key = f'{metric_name}{{{label_str}}}'
else:
key = metric_name
metrics_snapshot[key] = {
'timestamp': current_time,
'value': metric_value,
'labels': labels
}
# 存储到历史
for key, data in metrics_snapshot.items():
self.history[key].append(data)
# 限制历史记录大小
if len(self.history[key]) > self.max_history_size:
self.history[key].pop(0)
def get_metrics_summary(self) -> Dict[str, Any]:
"""获取指标摘要"""
summary = {
'service': {
'uptime_seconds': (datetime.now() - self.start_time).total_seconds(),
'start_time': self.start_time.isoformat(),
},
'system': {},
'gpu': [],
'performance': {},
'requests': {}
}
try:
# 系统指标
memory = psutil.virtual_memory()
summary['system'] = {
'cpu_percent': psutil.cpu_percent(),
'memory_percent': memory.percent,
'memory_used_gb': memory.used / 1024**3,
'memory_total_gb': memory.total / 1024**3,
}
# GPU指标
gpus = GPUtil.getGPUs()
for gpu in gpus:
gpu_info = {
'id': gpu.id,
'name': gpu.name,
'load_percent': gpu.load * 100,
'memory_used_gb': gpu.memoryUsed,
'memory_total_gb': gpu.memoryTotal,
'memory_percent': gpu.memoryUtil * 100,
}
if hasattr(gpu, 'temperature') and gpu.temperature is not None:
gpu_info['temperature_c'] = gpu.temperature
if hasattr(gpu, 'powerDraw') and gpu.powerDraw is not None:
gpu_info['power_draw_w'] = gpu.powerDraw
summary['gpu'].append(gpu_info)
except Exception as e:
summary['error'] = str(e)
return summary
def record_request(self, model: str, endpoint: str,
duration: float, status_code: int,
prompt_tokens: int = 0, completion_tokens: int = 0):
"""记录请求指标"""
# 请求计数
self.requests_total.labels(
model=model,
endpoint=endpoint,
status_code=str(status_code)
).inc()
# 请求耗时
self.request_duration_seconds.labels(
model=model,
endpoint=endpoint
).observe(duration)
# token计数
if prompt_tokens > 0:
self.request_tokens_total.labels(
model=model,
token_type="prompt"
).inc(prompt_tokens)
if completion_tokens > 0:
self.request_tokens_total.labels(
model=model,
token_type="completion"
).inc(completion_tokens)
def record_inference(self, model: str, phase: str,
latency: float, tokens: int = 0):
"""记录推理指标"""
# 推理延迟
self.inference_latency_seconds.labels(
model=model,
phase=phase
).observe(latency)
# 吞吐量
if latency > 0 and tokens > 0:
tps = tokens / latency
self.tokens_per_second.labels(
model=model,
phase=phase
).set(tps)
def record_batch_info(self, batch_size: int, sequences_processed: int = 1):
"""记录批次信息"""
self.batch_size.set(batch_size)
if sequences_processed > 0:
self.sequences_processed_total.inc(sequences_processed)
def record_kv_cache_info(self, blocks_used: int, blocks_total: int,
hits: int = 0, misses: int = 0):
"""记录KV缓存信息"""
self.kv_cache_blocks_used.set(blocks_used)
self.kv_cache_blocks_total.set(blocks_total)
if hits + misses > 0:
hit_rate = hits / (hits + misses) * 100
self.kv_cache_hit_rate.set(hit_rate)
def record_queue_info(self, active_requests: int, queued_requests: int):
"""记录队列信息"""
self.active_requests.set(active_requests)
self.queued_requests.set(queued_requests)
def record_error(self, error_type: str, model: str = "unknown"):
"""记录错误"""
self.errors_total.labels(
error_type=error_type,
model=model
).inc()
def set_model_info(self, model_name: str, model_size: str,
quantization: str = None, **kwargs):
"""设置模型信息"""
info = {
'model_name': model_name,
'model_size': model_size,
}
if quantization:
info['quantization'] = quantization
info.update(kwargs)
self.model_info.info(info)
def export_metrics(self, format: str = "json") -> str:
"""导出指标数据"""
if format == "json":
return json.dumps(self.get_metrics_summary(), indent=2, default=str)
elif format == "prometheus":
# 导出为Prometheus格式
from prometheus_client import generate_latest
return generate_latest(REGISTRY).decode('utf-8')
else:
raise ValueError(f"不支持的格式: {format}")
def get_history_data(self, metric_name: str = None,
time_range: int = 3600) -> Dict[str, Any]:
"""获取历史数据"""
start_time = datetime.now().timestamp() - time_range
if metric_name:
# 返回特定指标的历史数据
data = self.history.get(metric_name, [])
filtered = [d for d in data if d['timestamp'] >= start_time]
return {metric_name: filtered}
else:
# 返回所有指标的历史数据
result = {}
for key, data in self.history.items():
filtered = [d for d in data if d['timestamp'] >= start_time]
if filtered:
result[key] = filtered
return result
# 与vLLM集成的装饰器
def monitor_request(model: str = "default", endpoint: str = "unknown"):
"""监控请求的装饰器"""
def decorator(func):
def wrapper(*args, **kwargs):
start_time = time.time()
status_code = 200
prompt_tokens = 0
completion_tokens = 0
try:
# 执行函数
result = func(*args, **kwargs)
# 从结果中提取token计数
if isinstance(result, dict):
prompt_tokens = result.get('prompt_tokens', 0)
completion_tokens = result.get('completion_tokens', 0)
return result
except Exception as e:
status_code = 500
# 记录错误
if monitor:
monitor.record_error(type(e).__name__, model)
raise e
finally:
# 记录请求指标
duration = time.time() - start_time
if monitor:
monitor.record_request(
model=model,
endpoint=endpoint,
duration=duration,
status_code=status_code,
prompt_tokens=prompt_tokens,
completion_tokens=completion_tokens
)
return wrapper
return decorator
# 全局监控器实例
monitor = None
def init_monitoring(prometheus_port: int = 9090,
collect_interval: int = 5,
model_info: Dict[str, Any] = None) -> VLLMMonitor:
"""初始化全局监控器"""
global monitor
if monitor is None:
monitor = VLLMMonitor(
prometheus_port=prometheus_port,
collect_interval=collect_interval
)
# 设置模型信息
if model_info:
monitor.set_model_info(**model_info)
# 启动监控
monitor.start()
return monitor
def get_monitor() -> VLLMMonitor:
"""获取监控器实例"""
global monitor
if monitor is None:
raise RuntimeError("监控器未初始化,请先调用init_monitoring()")
return monitor
Docker监控配置:
# docker-compose.monitoring.yml
version: '3.8'
services:
# Prometheus
prometheus:
image: prom/prometheus:latest
container_name: vllm-prometheus
restart: unless-stopped
ports:
- "9090:9090"
volumes:
- ./prometheus/prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/etc/prometheus/console_libraries'
- '--web.console.templates=/etc/prometheus/console_templates'
- '--storage.tsdb.retention.time=30d'
- '--web.enable-lifecycle'
networks:
- monitoring
# Grafana
grafana:
image: grafana/grafana:latest
container_name: vllm-grafana
restart: unless-stopped
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
- GF_USERS_ALLOW_SIGN_UP=false
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/provisioning:/etc/grafana/provisioning
- ./grafana/dashboards:/etc/grafana/dashboards
networks:
- monitoring
depends_on:
- prometheus
# Node Exporter (系统指标)
node-exporter:
image: prom/node-exporter:latest
container_name: vllm-node-exporter
restart: unless-stopped
ports:
- "9100:9100"
volumes:
- /proc:/host/proc:ro
- /sys:/host/sys:ro
- /:/rootfs:ro
command:
- '--path.procfs=/host/proc'
- '--path.sysfs=/host/sys'
- '--collector.filesystem.mount-points-exclude=^/(sys|proc|dev|host|etc)($$|/)'
networks:
- monitoring
# cAdvisor (容器指标)
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: vllm-cadvisor
restart: unless-stopped
ports:
- "8080:8080"
volumes:
- /:/rootfs:ro
- /var/run:/var/run:ro
- /sys:/sys:ro
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
devices:
- /dev/kmsg:/dev/kmsg
privileged: true
networks:
- monitoring
# vLLM服务
vllm:
image: vllm/vllm-openai:latest
container_name: vllm-server
restart: unless-stopped
ports:
- "8000:8000"
- "9095:9095" # Prometheus指标端口
environment:
- MODEL=meta-llama/Llama-2-7b-chat-hf
- HOST=0.0.0.0
- PORT=8000
- PROMETHEUS_PORT=9095
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
volumes:
- ./models:/models
- ./logs:/logs
networks:
- monitoring
labels:
- "prometheus.io/scrape=true"
- "prometheus.io/port=9095"
- "prometheus.io/path=/metrics"
networks:
monitoring:
driver: bridge
volumes:
prometheus_data:
grafana_data:
Prometheus配置:
# prometheus/prometheus.yml
global:
scrape_interval: 15s
evaluation_interval: 15s
external_labels:
monitor: 'vllm-monitoring'
rule_files:
- "alerts.yml"
alerting:
alertmanagers:
- static_configs:
- targets: []
# - alertmanager:9093
scrape_configs:
# vLLM服务
- job_name: 'vllm'
static_configs:
- targets: ['vllm:9095']
scrape_interval: 5s
metrics_path: /metrics
# 节点指标
- job_name: 'node'
static_configs:
- targets: ['node-exporter:9100']
scrape_interval: 5s
# 容器指标
- job_name: 'cadvisor'
static_configs:
- targets: ['cadvisor:8080']
scrape_interval: 5s
# Prometheus自身
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
# 远程写入配置(可选)
remote_write:
- url: "http://your-remote-prometheus:9090/api/v1/write"
queue_config:
max_shards: 200
capacity: 10000
max_samples_per_send: 10000
告警规则:
# prometheus/alerts.yml
groups:
- name: vllm_alerts
rules:
# GPU相关告警
- alert: HighGPUUsage
expr: avg(vllm_gpu_utilization_percent) > 90
for: 5m
labels:
severity: warning
annotations:
summary: "GPU利用率过高"
description: "GPU利用率已超过90%持续5分钟"
- alert: HighGPUMemoryUsage
expr: vllm_gpu_memory_used_bytes / vllm_gpu_memory_total_bytes * 100 > 90
for: 5m
labels:
severity: warning
annotations:
summary: "GPU显存使用率过高"
description: "GPU显存使用率已超过90%持续5分钟"
- alert: HighGPUTemperature
expr: vllm_gpu_temperature_celsius > 85
for: 3m
labels:
severity: critical
annotations:
summary: "GPU温度过高"
description: "GPU温度已超过85°C持续3分钟"
# 请求相关告警
- alert: HighRequestLatency
expr: histogram_quantile(0.95, rate(vllm_request_duration_seconds_bucket[5m])) > 10
for: 5m
labels:
severity: warning
annotations:
summary: "请求延迟过高"
description: "95%的请求延迟超过10秒"
- alert: HighErrorRate
expr: rate(vllm_errors_total[5m]) / rate(vllm_requests_total[5m]) * 100 > 5
for: 5m
labels:
severity: critical
annotations:
summary: "错误率过高"
description: "请求错误率超过5%"
# 服务相关告警
- alert: ServiceDown
expr: up{job="vllm"} == 0
for: 1m
labels:
severity: critical
annotations:
summary: "vLLM服务宕机"
description: "vLLM服务已不可用超过1分钟"
- alert: LowThroughput
expr: rate(vllm_request_tokens_total[5m]) < 100
for: 10m
labels:
severity: warning
annotations:
summary: "吞吐量过低"
description: "吞吐量低于100 tokens/秒持续10分钟"
# 队列相关告警
- alert: HighQueueLength
expr: vllm_queued_requests > 100
for: 5m
labels:
severity: warning
annotations:
summary: "请求队列过长"
description: "排队请求数超过100持续5分钟"
Grafana仪表板配置:
// grafana/dashboards/vllm-dashboard.json
{
"dashboard": {
"title": "vLLM服务监控仪表板",
"tags": ["vllm", "llm", "monitoring"],
"timezone": "browser",
"panels": [
{
"title": "服务概览",
"type": "stat",
"targets": [{
"expr": "vllm_service_uptime_seconds",
"legendFormat": "运行时间"
}],
"fieldConfig": {
"defaults": {
"unit": "s"
}
},
"gridPos": {"h": 3, "w": 6, "x": 0, "y": 0}
},
{
"title": "GPU利用率",
"type": "timeseries",
"targets": [{
"expr": "vllm_gpu_utilization_percent",
"legendFormat": "GPU {{gpu_id}}"
}],
"fieldConfig": {
"defaults": {
"unit": "percent"
}
},
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 3}
},
{
"title": "GPU显存使用率",
"type": "timeseries",
"targets": [{
"expr": "vllm_gpu_memory_used_bytes / vllm_gpu_memory_total_bytes * 100",
"legendFormat": "GPU {{gpu_id}}"
}],
"fieldConfig": {
"defaults": {
"unit": "percent"
}
},
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 3}
},
{
"title": "请求速率",
"type": "timeseries",
"targets": [{
"expr": "rate(vllm_requests_total[5m])",
"legendFormat": "{{endpoint}}"
}],
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 11}
},
{
"title": "请求延迟分布",
"type": "histogram",
"targets": [{
"expr": "histogram_quantile(0.95, rate(vllm_request_duration_seconds_bucket[5m]))",
"legendFormat": "P95延迟"
}],
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 11}
},
{
"title": "吞吐量 (tokens/秒)",
"type": "timeseries",
"targets": [{
"expr": "rate(vllm_request_tokens_total[5m])",
"legendFormat": "{{token_type}} tokens"
}],
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 19}
},
{
"title": "批次大小",
"type": "timeseries",
"targets": [{
"expr": "vllm_batch_size"
}],
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 19}
},
{
"title": "KV缓存使用率",
"type": "timeseries",
"targets": [{
"expr": "vllm_kv_cache_blocks_used / vllm_kv_cache_blocks_total * 100",
"legendFormat": "缓存使用率"
}],
"fieldConfig": {
"defaults": {
"unit": "percent"
}
},
"gridPos": {"h": 8, "w": 12, "x": 0, "y": 27}
},
{
"title": "活跃请求数",
"type": "timeseries",
"targets": [{
"expr": "vllm_active_requests"
}],
"gridPos": {"h": 8, "w": 12, "x": 12, "y": 27}
}
],
"refresh": "5s"
}
}
启动完整监控栈:
# 1. 创建监控目录结构
mkdir -p monitoring/{prometheus,grafana/provisioning,grafana/dashboards,logs}
# 2. 创建Prometheus配置
cat > monitoring/prometheus/prometheus.yml << 'EOF'
# 使用上面的Prometheus配置
EOF
# 3. 创建告警规则
cat > monitoring/prometheus/alerts.yml << 'EOF'
# 使用上面的告警规则配置
EOF
# 4. 创建Grafana配置
cat > monitoring/grafana/provisioning/datasources/prometheus.yml << 'EOF'
apiVersion: 1
datasources:
- name: Prometheus
type: prometheus
access: proxy
url: http://prometheus:9090
isDefault: true
editable: true
EOF
# 5. 创建Grafana仪表板配置
cat > monitoring/grafana/provisioning/dashboards/dashboards.yml << 'EOF'
apiVersion: 1
providers:
- name: 'vllm-dashboards'
orgId: 1
folder: 'vllm'
type: file
disableDeletion: false
editable: true
allowUiUpdates: true
options:
path: /etc/grafana/dashboards
EOF
# 6. 创建Grafana仪表板
cat > monitoring/grafana/dashboards/vllm-dashboard.json << 'EOF'
# 使用上面的仪表板配置
EOF
# 7. 创建docker-compose文件
cat > docker-compose.monitoring.yml << 'EOF'
# 使用上面的docker-compose配置
EOF
# 8. 启动监控栈
docker-compose -f docker-compose.monitoring.yml up -d
# 9. 访问服务
# Grafana: http://localhost:3000 (admin/admin)
# Prometheus: http://localhost:9090
# vLLM API: http://localhost:8000
# vLLM指标: http://localhost:9095/metrics
Python集成示例:
# vllm_with_monitoring.py
import argparse
from vllm import LLM, SamplingParams
from vllm.entrypoints.openai.api_server import run_server
import threading
import time
from typing import Dict, Any
import json
# 导入监控模块
from prometheus_monitoring import init_monitoring, get_monitor, monitor_request
def parse_args():
parser = argparse.ArgumentParser()
parser.add_argument("--model", type=str, required=True)
parser.add_argument("--host", type=str, default="0.0.0.0")
parser.add_argument("--port", type=int, default=8000)
parser.add_argument("--prometheus-port", type=int, default=9095)
parser.add_argument("--monitor-interval", type=int, default=5)
return parser.parse_args()
class MonitoredLLM:
"""带监控的LLM封装类"""
def __init__(self, model: str, **kwargs):
self.model_name = model
self.llm = LLM(model=model, **kwargs)
# 初始化监控
self.monitor = init_monitoring(
prometheus_port=args.prometheus_port,
collect_interval=args.monitor_interval,
model_info={
'model_name': model,
'model_size': '7B', # 从模型配置中获取
'quantization': kwargs.get('quantization', 'none')
}
)
# 启动监控更新线程
self._start_monitoring_thread()
def _start_monitoring_thread(self):
"""启动监控更新线程"""
def update_metrics():
while True:
try:
# 从vLLM引擎获取内部指标
engine = getattr(self.llm.llm_engine, 'engine', None)
if engine:
# 获取批次信息
scheduler = getattr(engine, 'scheduler', None)
if scheduler:
waiting = len(scheduler.waiting)
running = len(scheduler.running)
self.monitor.record_queue_info(
active_requests=running,
queued_requests=waiting
)
# 获取缓存信息
cache_manager = getattr(engine, 'cache_manager', None)
if cache_manager:
blocks_used = len(cache_manager.cached_blocks)
blocks_total = cache_manager.num_gpu_blocks
self.monitor.record_kv_cache_info(
blocks_used=blocks_used,
blocks_total=blocks_total
)
except Exception as e:
print(f"更新监控指标失败: {e}")
time.sleep(5)
thread = threading.Thread(target=update_metrics, daemon=True)
thread.start()
@monitor_request(model="llama-2-7b-chat", endpoint="generate")
def generate(self, prompts, **kwargs):
"""带监控的生成方法"""
start_time = time.time()
# 执行推理
outputs = self.llm.generate(prompts, **kwargs)
# 计算token数
total_prompt_tokens = 0
total_completion_tokens = 0
for output in outputs:
total_prompt_tokens += len(output.prompt_token_ids)
total_completion_tokens += len(output.outputs[0].token_ids)
# 记录推理指标
duration = time.time() - start_time
self.monitor.record_inference(
model=self.model_name,
phase="generate",
latency=duration,
tokens=total_completion_tokens
)
# 记录批次信息
self.monitor.record_batch_info(
batch_size=len(prompts),
sequences_processed=len(outputs)
)
return {
'outputs': outputs,
'prompt_tokens': total_prompt_tokens,
'completion_tokens': total_completion_tokens
}
def get_metrics(self, format: str = "json") -> str:
"""获取监控指标"""
return self.monitor.export_metrics(format)
def main():
args = parse_args()
# 启动vLLM服务
print(f"启动vLLM服务,模型: {args.model}")
print(f"API地址: http://{args.host}:{args.port}")
print(f"指标地址: http://{args.host}:{args.prometheus_port}/metrics")
# 创建带监控的LLM实例
llm = MonitoredLLM(
model=args.model,
gpu_memory_utilization=0.9,
max_num_seqs=16,
max_model_len=4096
)
# 运行API服务器
# 注意:这里需要修改vLLM的API服务器以集成监控
# 实际实现中,可以创建一个自定义的FastAPI应用
run_server(
llm.llm,
args.host,
args.port,
served_model_name=args.model.split('/')[-1]
)
if __name__ == "__main__":
main()
使用说明:
- 基本监控启动:
# 启动带监控的vLLM服务
python vllm_with_monitoring.py \
--model meta-llama/Llama-2-7b-chat-hf \
--host 0.0.0.0 \
--port 8000 \
--prometheus-port 9095
- 查询指标:
# 查询Prometheus指标
curl http://localhost:9095/metrics
# 查询指标摘要(JSON格式)
curl http://localhost:9095/metrics/summary
# 查询历史数据
curl "http://localhost:9095/metrics/history?metric=vllm_gpu_utilization_percent&hours=1"
- 健康检查端点:
# 在API服务器中添加健康检查端点
@app.get("/health")
async def health_check():
"""健康检查端点"""
monitor = get_monitor()
# 基本健康检查
health_status = {
"status": "healthy",
"timestamp": datetime.now().isoformat(),
"uptime": (datetime.now() - monitor.start_time).total_seconds(),
"version": "1.0.0"
}
# 检查GPU
try:
gpus = GPUtil.getGPUs()
health_status["gpu_count"] = len(gpus)
for gpu in gpus:
if gpu.temperature > 85:
health_status["status"] = "warning"
health_status["warning"] = "GPU温度过高"
except Exception as e:
health_status["status"] = "unhealthy"
health_status["error"] = str(e)
return health_status
@app.get("/metrics/summary")
async def metrics_summary():
"""获取指标摘要"""
monitor = get_monitor()
return monitor.get_metrics_summary()
@app.get("/metrics/history")
async def metrics_history(metric: str = None, hours: int = 1):
"""获取历史指标数据"""
monitor = get_monitor()
time_range = hours * 3600
return monitor.get_history_data(metric, time_range)
监控最佳实践:
-
指标分类:
- 业务指标:QPS、成功率、延迟
- 资源指标:GPU利用率、显存使用、CPU使用
- 性能指标:吞吐量、KV缓存命中率
- 服务质量指标:排队长度、错误率
-
告警策略:
- 设置多级告警(警告、严重、紧急)
- 避免告警风暴(合理设置静默期)
- 实现自动扩缩容
-
日志聚合:
# 使用ELK栈或Loki docker run -d --name=loki -p 3100:3100 grafana/loki:latest docker run -d --name=promtail -v /var/log:/var/log -v /path/to/promtail.yml:/etc/promtail/config.yml grafana/promtail:latest -
分布式追踪:
# 集成OpenTelemetry from opentelemetry import trace from opentelemetry.sdk.trace import TracerProvider from opentelemetry.sdk.trace.export import BatchSpanProcessor from opentelemetry.exporter.jaeger.thrift import JaegerExporter # 设置追踪 trace.set_tracer_provider(TracerProvider()) tracer = trace.get_tracer(__name__) # 添加Jaeger导出器 jaeger_exporter = JaegerExporter( agent_host_name="localhost", agent_port=6831, ) span_processor = BatchSpanProcessor(jaeger_exporter) trace.get_tracer_provider().add_span_processor(span_processor) # 在请求中记录追踪 @tracer.start_as_current_span("generate") def generate_text(prompt): with tracer.start_as_current_span("tokenize"): tokens = tokenize(prompt) with tracer.start_as_current_span("inference"): output = model(tokens) return output
通过以上完整的监控系统,您可以实时掌握vLLM服务的运行状态,及时发现和解决性能问题,确保服务的稳定性和可靠性。
🌟 感谢您耐心阅读到这里
💡 如果本文对您有所启发,请
👍 点赞📌 收藏 📤 分享给更多需要的伙伴
🗣️ 期待在评论区看到您的想法, 共同进步
🔔 关注我,持续获取更多干货内容
🤗 我们下篇文章见~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献229条内容
已为社区贡献229条内容

所有评论(0)