SAM3 震撼来袭!手把手教你在 BitaHub 部署“语义级”智能隐私护盾
🚀 教程前言:AI 时代的“隐私护盾”
在数字化生存的今天,无论是分享生活瞬间还是发布专业视频,隐私保护已成为不可忽视的环节。传统的“手动打码”不仅耗时费力,且难以应对动态视频中的复杂场景。
本教程将带你实战部署一个基于 SAM3 的智能隐私护盾。借助 BitaHub 平台提供的 GPU 算力,我们将实现从“像素操作”到“语义理解”的飞跃。只需输入简单的文本指令(如“人脸”、“车牌”),AI 即可秒懂意图,精准锁定目标并执行高质量模糊处理。
🧠 一.技术核心:为何选择 SAM3?
Segment Anything Model 3 (SAM3) 是 Meta 在多模态视觉分割领域的巅峰之作。相比前代,它的核心优势在于:
-
语义化分割 (Promptable Segmentation):支持直接通过文本指令(Text Prompt)定位目标,彻底摆脱了必须手动点击或绘制边界框的限制。
-
零样本迁移 (Zero-shot Transfer):模型在海量数据集上预训练,无需针对特定物体(如某种特殊的隐私标识)进行二次微调,即可实现精准分割。
-
端到端优化:在处理长视频流时,SAM3 表现出极高的时空连续性,能够有效减少打码区域在视频帧间的抖动。
🏗️ 二.任务准备
首先进入平台首页模型库,搜索“sam3”,将模型的权重文件保存到控制台的个人存储空间当中。
随后进入控制台,创建开发机任务,选择单卡4090套餐,并将刚刚转存的 sam3 文件挂载到任务当中。
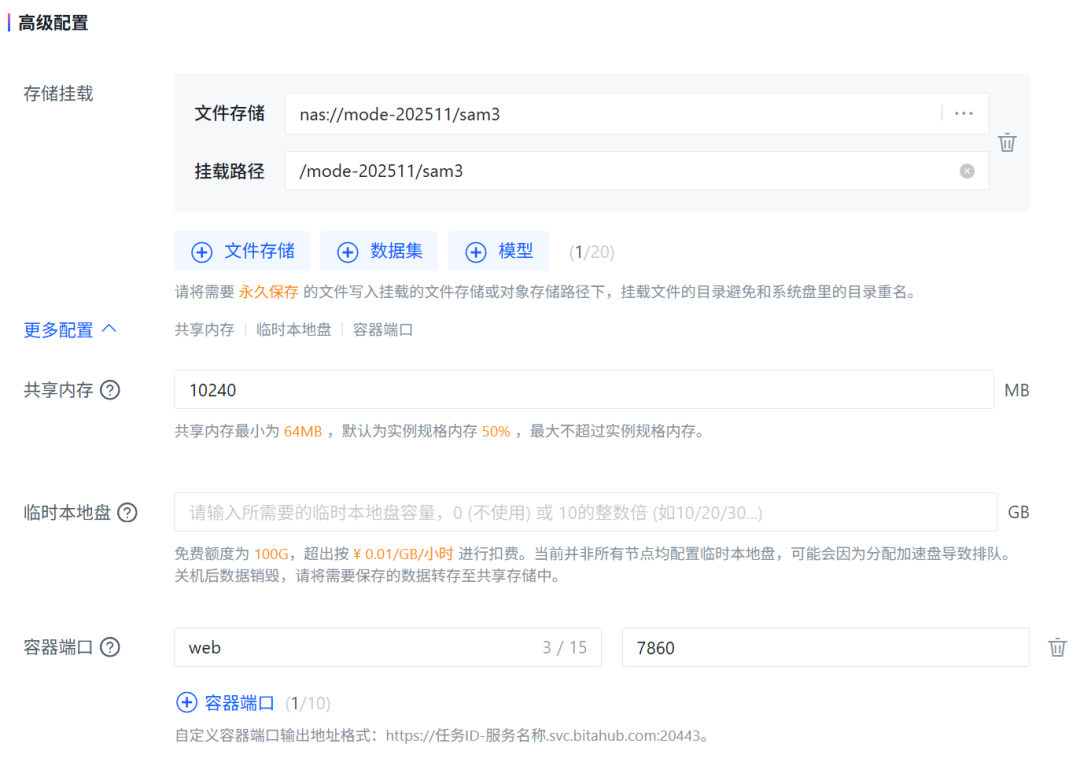
最后,本示例中 Gradio 服务运行在 7860 端口,部署容器时需将容器端口配置为 7860,以确保平台能够将外部访问请求正确路由至应用服务。
🛠️ 三.代码解读与实战
1.环境搭建
首先创建并激活一个独立的 Python 虚拟环境,避免依赖冲突;随后安装最新版 transformers,以确保支持 SAM3 等前沿模型;最后安装 PyTorch、Gradio 以及图像和视频处理相关依赖,为后续模型推理和可视化应用运行做好准备。
python3 -m venv my_notebook_env
source my_notebook_env/bin/activate
pip install git+https://github.com/huggingface/transformers.git
pip install accelerate gradio numpy pillow torch torchvision "imageio[ffmpeg]"2.依赖库引入
首先,引入必要的工程库。Gradio 作为前端框架,能在几分钟内将复杂的推理脚本包装成交互式网页应用。
import gradio as gr
import torch
import numpy as np
import imageio
from PIL import Image, ImageFilter
from transformers import Sam3Processor, Sam3Model3.构建推理引擎类 Sam3PrivacyEngine
该类封装了模型的加载与逻辑推理,是整个系统的“大脑”。
-
硬件自适应:代码自动检测 CUDA 环境,确保在 BitaHub 的 GPU 节点上运行,大幅提升视频帧的处理速度。
-
权重加载:通过 from_pretrained 接口加载本地路径 /mode-202511/sam3 下的预训练权重。
-
后处理逻辑:调用 post_process_instance_segmentation 将原始张量转化为可读的二值化掩膜(Mask),标记出所有需要保护的区域。
classSam3PrivacyEngine: def__init__(self): self.device = "cuda"if torch.cuda.is_available() else"cpu" self.model = None self.processor = None print(f"Initializing SAM3 on {self.device}") try: model_path = "/mode-202511/sam3" self.model = Sam3Model.from_pretrained(model_path).to(self.device) self.processor = Sam3Processor.from_pretrained(model_path) self.model.eval() print("✅ SAM3 Loaded Successfully!") except Exception as e: print(f"❌ Error loading SAM3: {e}") defpredict_masks(self, image_pil, text_prompt, threshold=0.4): if self.model isNone: return [] inputs = self.processor( images=image_pil, text=text_prompt, return_tensors="pt" ).to(self.device) with torch.no_grad(): outputs = self.model(**inputs) results = self.processor.post_process_instance_segmentation( outputs, threshold=threshold, mask_threshold=0.5, target_sizes=inputs["original_sizes"].tolist() )[0] masks = [] if"masks"in results: for mask_tensor in results["masks"]: mask_np = (mask_tensor.cpu().numpy() * 255).astype(np.uint8) masks.append(Image.fromarray(mask_np)) return masks engine = Sam3PrivacyEngine()
4.核心算法:基于掩膜的局部模糊
为了保证非敏感区域的画质不受损,我们采用了遮罩粘贴(Mask Pasting)技术。
defapply_blur_pure(image_pil, masks, blur_strength):
ifnot masks:
return image_pil
blurred_image = image_pil.filter(
ImageFilter.GaussianBlur(radius=blur_strength)
)
composite_mask = Image.new("L", image_pil.size, 0)
for mask in masks:
composite_mask.paste(255, (0, 0), mask=mask)
final_image = image_pil.copy()
final_image.paste(blurred_image, (0, 0), mask=composite_mask)
return final_image
这种方法的科学严谨性在于:它通过逻辑代数运算实现了原图与模糊层的线性融合,确保边缘过渡自然且不影响背景。
5. 图像与视频流处理
图像处理:将上传的 NumPy 数组转为 PIL 格式,调用引擎得到结果并保存。
defprocess_image(input_img, text_prompt, blur_strength, confidence):
if input_img isNone:
returnNone, None
ifisinstance(input_img, np.ndarray):
image_pil = Image.fromarray(input_img).convert("RGB")
else:
image_pil = input_img.convert("RGB")
masks = engine.predict_masks(image_pil, text_prompt, confidence)
result_pil = apply_blur_pure(image_pil, masks, blur_strength)
output_path = "privacy_image.png"
result_pil.save(output_path)
return np.array(result_pil), output_path视频处理函数 process_video 引入了 imageio 库,实现了对视频帧的高速读取与回写。
-
帧率保持:自动获取原视频元数据,确保输出视频的 FPS 与原视频一致。
-
流控机制:设置 max_frames 参数,允许用户在生产大规模视频前,先进行小样本的快速效果验证。
defprocess_video(video_path, text_prompt, blur_strength, confidence, max_frames): ifnot video_path: returnNone, None try: reader = imageio.get_reader(video_path) meta = reader.get_meta_data() fps = meta.get("fps", 24) output_path = "privacy_video.mp4" writer = imageio.get_writer( output_path, fps=fps, codec="libx264", pixelformat="yuv420p", macro_block_size=1 ) print("🎬 Starting video processing...") for i, frame inenumerate(reader): if i >= max_frames: break frame_pil = Image.fromarray(frame).convert("RGB") masks = engine.predict_masks(frame_pil, text_prompt, confidence) processed_pil = apply_blur_pure(frame_pil, masks, blur_strength) writer.append_data(np.array(processed_pil)) if i % 10 == 0: print(f"Processed frame {i}") writer.close() reader.close() print("✅ Video processing complete.") return output_path, output_path except Exception as e: print(f"❌ Video error: {e}") returnNone, None
6.交互层设计 (Gradio UI)
采用分栏式布局,为“图像”和“视频处理”提供了独立的 Tab 页面。用户可以通过滑块实时调节两个关键超参数:
-
模糊强度 (Blur Strength):控制高斯模糊的半径,决定隐私遮蔽的程度。
-
置信度阈值 (Confidence):决定 AI 判定目标的严苛程度。调低可捕获更多潜在敏感物,调高则更精准。
with gr.Blocks(title="SAM3 Privacy Filter", theme=gr.themes.Soft()) as demo:
gr.Markdown("# 🛡️ SAM3 隐私护盾")
gr.Markdown("输入文字指令,自动模糊人脸与敏感物体")
with gr.Tabs():
with gr.Tab("图像"):
with gr.Row():
with gr.Column():
im_input = gr.Image(label="输入图像", type="numpy")
im_prompt = gr.Textbox(label="文本指令", value="faces")
im_blur = gr.Slider(5, 100, value=30, label="模糊强度")
im_conf = gr.Slider(0.1, 1.0, value=0.4, label="置信度")
im_btn = gr.Button("模糊处理图片", variant="primary")
with gr.Column():
im_output = gr.Image(label="预览效果")
im_dl = gr.File(label="下载处理后图片")
im_btn.click(
process_image,
inputs=[im_input, im_prompt, im_blur, im_conf],
outputs=[im_output, im_dl]
)
with gr.Tab("视频处理"):
with gr.Row():
with gr.Column():
vid_input = gr.Video(label="输入视频")
vid_prompt = gr.Textbox(label="文本指令", value="faces")
vid_blur = gr.Slider(5, 100, value=30, label="模糊强度")
vid_conf = gr.Slider(0.1, 1.0, value=0.4, label="置信度")
vid_limit = gr.Slider(10, 300, value=60, step=10, label="最大处理帧数")
vid_btn = gr.Button("模糊处理视频", variant="primary")
with gr.Column():
vid_output = gr.Video(label="预览效果")
vid_dl = gr.File(label="下载处理后视频")
vid_btn.click(
process_video,
inputs=[vid_input, vid_prompt, vid_blur, vid_conf, vid_limit],
outputs=[vid_output, vid_dl]
)
demo.launch(share=True, debug=True)将上述几段代码保存为main.py文件,并打开终端执行。

模型加载成功后,复制链接到浏览器中打开即可看到我们创建的UI界面。
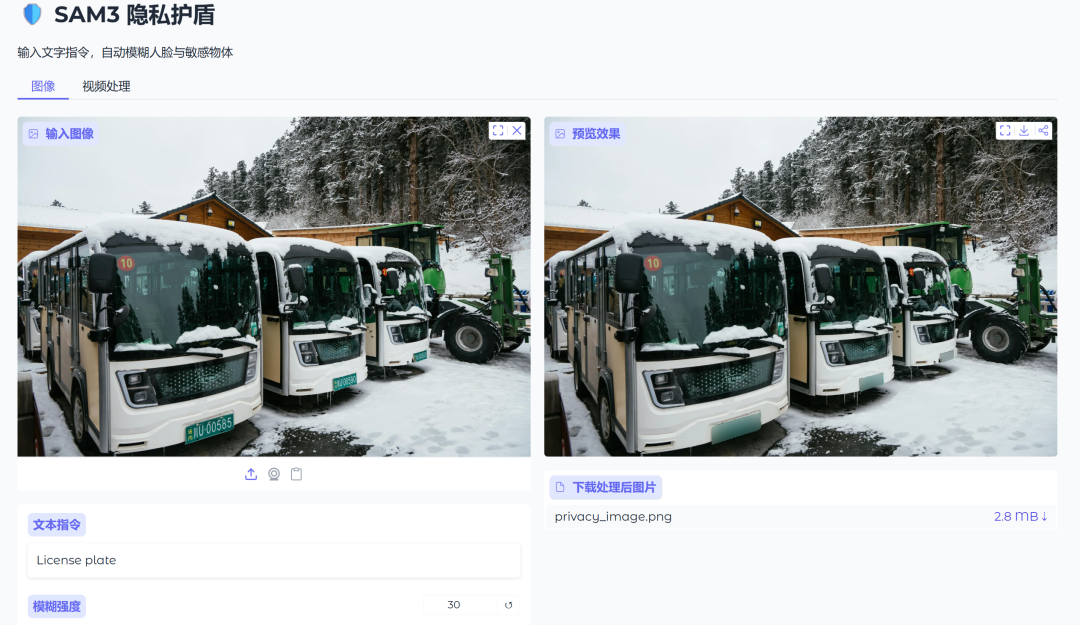
只需上传一张图片或一段视频,并通过文本形式指定需要遮挡的内容(如 “License plate”),模型便能够自动理解语义并精准定位对应区域,最终完成隐私区域的自动打码,实现真正的“文本驱动式”隐私保护。
💡 总结与技术展望
通过本次实战,我们见证了 SAM3 如何将原本繁琐的隐私保护工作简化为一行文本指令。它标志着视觉处理技术已从简单的“滤镜时代”迈入了深度的“语义时代”。
结语:隐私无小事,技术有温度。在 BitaHub 高性能算力的加持下,原本需要数小时手动处理的视频打码任务,现在只需几分钟即可自动化完成。我们不仅是在保护数据,更是在用 AI 技术构建一个更加安全、从容的数字足迹空间。欢迎在 BitaHub 平台部署本教程代码,开启你的智能隐私防护之旅!
温馨提示:
平台暂不支持一键部署,但已提供完整可下载资源,大家可根据教程自行搭建运行。另外,项目部分依赖包版本与最新版存在不适配情况,部署时请务必按照文中标注的具体版本号进行配置,详细依赖需求可查看最新说明,避免因版本问题导致运行异常

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)