基于 LTX-2 模型的文生视频工作流部署指南
随着 AI 视频生成技术的快速发展,端到端视频扩散模型正在成为新的技术趋势。LTX-2 作为由 Lightricks 推出的高质量视频生成模型,在运动连贯性、细节一致性和画面真实感方面都有出色表现。本期教程将带你在 BitaHub 平台 上完成 LTX-2 模型的部署,并结合 ComfyUI 工作流实现完整的文生视频生成流程。
🤖 一、LTX-2 模型简介
LTX-2 是一款面向视频生成场景的扩散模型,不同于传统逐帧生成方案,它直接在 latent 空间中对空间结构与时间维度进行联合建模。这种方式可以显著提升视频中的动作连续性、镜头稳定性以及光影变化的自然程度。在实际使用中,LTX-2 具备以下优势:
-
支持端到端视频生成
-
运动表现更加真实自然
-
支持二次放大增强,适配高清输出
-
可拓展 LoRA、图生视频等进阶玩法
接下来我们将基于 BitaHub 平台,完整跑通一套 LTX-2 文生视频工作流。
☁️ 二、在 BitaHub 创建任务与环境配置
1.ComfyUI准备
克隆 ComfyUI到本地
git clone https://github.com/comfyanonymous/ComfyUI.git打开BitaHub工作台,将ComfyUI代码仓库上传至文件存储。
2.下载模型文件
LTX-2 需要多个模型组件,虽然 ComfyUI 能够自动下载,但推荐手动下载再上传到对应的目录位置,确保版本正确、路径规范,请分别下载以下文件并放入对应目录:
ComfyUI/models/checkpoints/ltx-2-19b-dev-fp8/
ComfyUI/models/text_encoders/gemma-3-12b-it-qat-q4_0-unquantized/
ComfyUI/models/latent_upscale_models/ltx-2-spatial-upscaler-x2-1.0/其中:
👉(1)主模型:ltx-2-19b-dev-fp8
这是整套视频生成流程的“中枢神经系统”,也是工作流中最关键的 Checkpoint 权重文件。
作用:
该模型基于 Diffusion Transformer(DiT)架构 构建,在 latent 空间中同时建模空间结构与时间动态,学习真实世界中的运动规律、镜头变化和光影演化过程。本质上,它负责从随机噪声中逐步“推演”出完整的视频序列,是视频生成能力的来源。
特点:
-
19B 参数规模:约 190 亿参数,使模型具备强大的时序建模能力,能够生成更加自然、连贯的动作与镜头过渡。
-
FP8 低精度推理:在尽量保持画面质量的前提下,大幅降低显存与算力需求,使超大模型也能在消费级 GPU 上运行,兼顾性能与可用性。
👉(2)文本编码器:gemma-3-12b-it-qat-q4_0-unquantized
这是工作流中的“语言理解中枢”,负责把人类自然语言翻译成模型可理解的语义表示。
作用:
它基于 Gemma 3 大语言模型架构,将输入的 prompt(场景描述、镜头语言、风格指令等)编码成高维语义向量,作为条件输入引导 LTX-2 主模型进行视频生成。换句话说,它决定模型如何理解你的描述。
特点:
具备强大的长文本理解能力;it 版本针对指令微调优化,更适合 prompt 解析;qat + q4_0 量化方案在保证语义精度的同时降低显存与算力消耗,使大模型在本地环境也可稳定运行。
👉(3)放大模型:ltx-2-spatial-upscaler-x2-1.0
这是工作流中的“高清增强引擎”,专门用于第二阶段的视频质量提升。
作用:
它在 latent 空间对视频进行 2 倍空间放大,不仅增强分辨率,还会同步优化纹理细节、光影层次和边缘结构,同时保持时间维度上的连续性,避免普通超分模型常见的闪烁和抖动问题。
特点:
不同于传统图像超分模型,它是专为视频 latent 设计的增强网络,在放大过程中会同时考虑前后帧之间的关联性,因此生成的视频更加稳定、自然,更接近真实摄影效果。
3.创建开发环境
将上述准备好的 ComfyUI 文件夹挂载到 BitaHub 开发机任务的的文件存储中。此外,我们还需要定义容器端口,BitaHub 平台通过自定义容器端口功能,让外部能发 HTTP 请求到容器服务(如 ComfyUI),实现开发验证(功能调试、接口测试等 )。ComfyUI 默认情况下使用端口号 8188 进行访问。
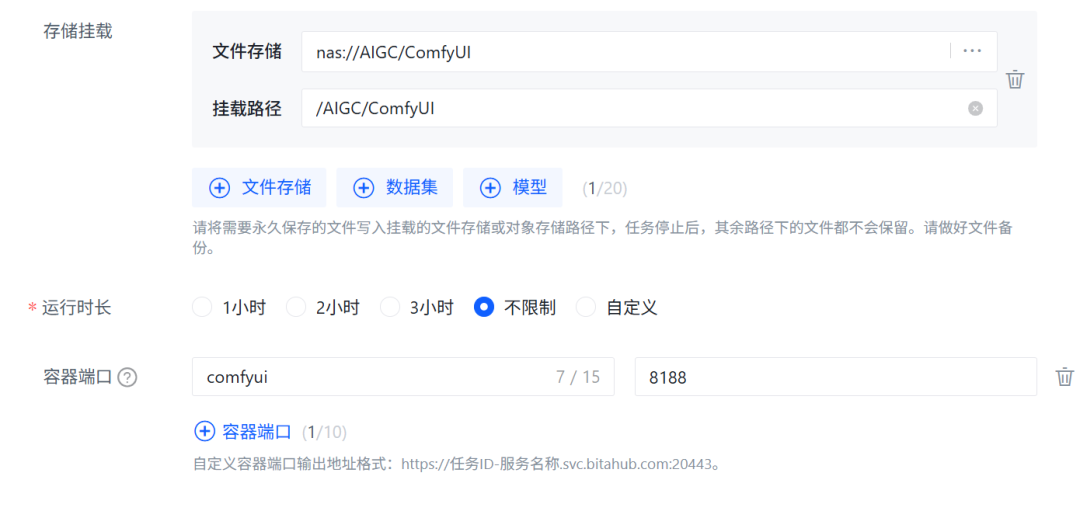
最后,选择单卡 A100 GPU,并通过JupyterLab访问方式进入开发环境。
4.环境配置
打开终端,通过venv创建虚拟环境→激活环境→进入项目目录→安装依赖这一系列操作为 ComfyUI 搭建起独立运行环境。(/AIGC/ComfyUI 是示例路径,实际要替换成你 ComfyUI 代码所在的真实路径)
python3 -m venv comfy_env
source comfy_env/bin/activate
cd /AIGC/ComfyUI
pip install -r requirements.txt运行 ComfyUI 服务,在项目根目录下执行以下命令启动:
python main.py --listen 0.0.0.0 --port 8188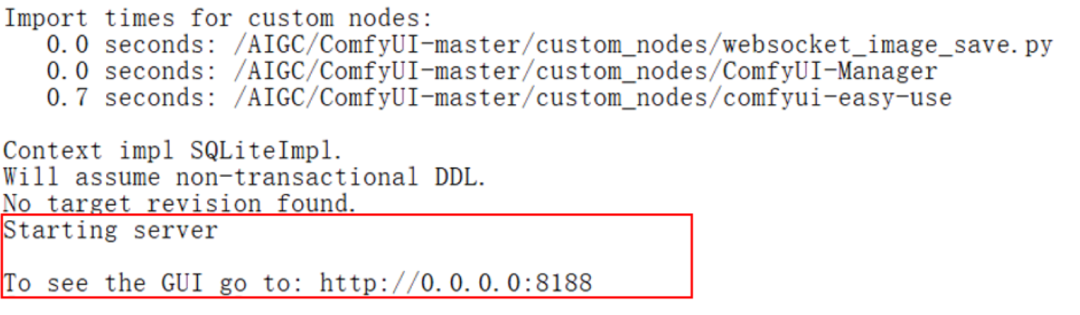
当日志输出上图红框中的信息说明你已成功部署 ComfyUI 并启动服务,随后回到开发环境,复制完整的地址并用浏览器打开即可看到 ComfyUI Web 界面。
🔗 三、ComfyUI 工作流配置
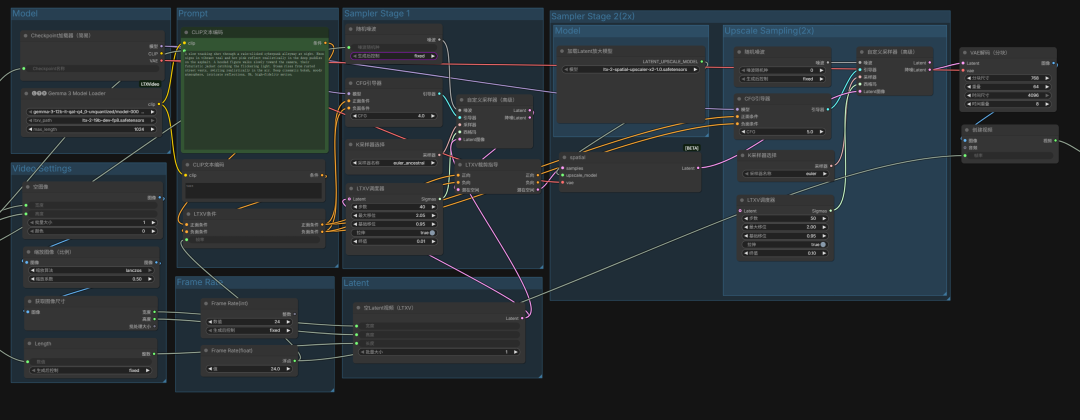
1.模型加载区 (Model Loaders)
这是工作流的算力基石。我们采用分体加载策略以确保维度匹配:
-
Checkpoint 加载器:负责加载
ltx-2-19b-dev-fp8主模型,提供核心视频生成能力。 -
Gemma 3 Model Loader:专门加载
gemma-3-12b文本编码器。它输出的 3840 维度 CLIP 数据是 LTX-2 19B 理解复杂指令的关键。 -
加载 Latent 放大模型:引入
ltx-2-spatial-upscaler-x2-1.0权重,为后续的 2 倍高清放大打下基础。
2.Prompt 编码区 (Prompt Conditioning)
在此区域,我们将文字转化为模型可处理的信号:
-
文本编码节点:分别输入正向与负向提示词。
-
LTXV 条件节点:将 CLIP 数据与提示词整合,精确控制视频的内容走向与视觉风格。
3.视频参数区 (Video Settings & Latent)
在此定义视频的“物理属性”:
-
空 Latent 视频 (LTXV):设置初始分辨率、视频长度及批次大小。
-
帧率控制:推荐设置 24fps,以获得最符合电影感官的流畅度。
4.第一阶段采样 (Sampler Stage 1)
这是视频初稿生成的阶段,决定了动作的逻辑性:
-
LTXV 调度器:推荐将步数设为 40,并将 Max Shift(最大移位)设为 2.05,以增强画面的初始细节。
-
自定义采样器:通过 CFG 4.0 的引导,生成具有基础结构和动态逻辑的视频潜空间数据。
5.第二阶段放大采样 (Upscale Sampling 2x)
利用潜空间放大技术,将画质提升至新高度:
-
Spatial 节点:将第一阶段的 Latent 数据进行 2 倍空间放大。
-
二次精修:在第二阶段采样器中,我们将 CFG 提高到 5.0,步数设为 50,配合第一阶段提示词的再次注入,能够有效消除噪点并补全超清细节。
6.VAE 解码 & 视频导出 (VAE Decode & Video Combine)
最后一步是将数学数据转化为可视画面:
-
VAE 解码 (分块):设置
tile_size为 768。分块解码能有效缓解超高清视频生成时的显存压力,并保持画面通透感。 -
视频输出:通过
Video Combine节点将解码后的图像序列封装成高清 MP4 文件。
💡 运行建议:只需按照上述逻辑顺序连接节点,并确保 Gemma 文本编码器与主模型版本对应,即可实现一键生成。
在基础工作流跑通后,你还可以进一步提升生成质量:
-
风格定制:接入 LoRA 节点 快速切换动漫、电影或写实画风。
-
画质压榨:继续提高采样步数(细腻度)或调高 CFG(文字遵循度)。
-
图生视频:将
空Latent替换为图像编码节点,赋予静态照片流动的生命力。
📌 四、总结
在本期教程中,我们系统走通了 LTX-2 模型的部署流程与 ComfyUI 自定义节点的安装配置,完整搭建了一套高效稳定的文生视频工作流。从基础扩散采样到二阶段高清增强,再到最终视频产出,每一个环节都进行了深入拆解,旨在帮助你全面理解并掌握 AI 视频生成的核心技术路径。
同时也强烈推荐大家使用 BitaHub 算力平台。在这里,你可以依托强大的算力资源,第一时间体验前沿视频生成模型,大幅缩短 AI 项目从灵感构想到实际落地的周期。欢迎来到 BitaHub,让我们一起在更酷的 AI 应用世界中,释放无限创作可能!
温馨提示:
平台暂不支持一键部署,但已提供完整可下载资源,大家可根据教程自行搭建运行。另外,项目部分依赖包版本与最新版存在不适配情况,部署时请务必按照文中标注的具体版本号进行配置,详细依赖需求可查看最新说明,避免因版本问题导致运行异常

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)