从零开始学习 AI 音乐生成:7 种音乐表示方法全解析(附完整代码)
导语:哈喽,大家好。我是翊博,你在AI和数据科学领域的好朋友~~~想让 AI 学会作曲?首先需要让 AI"听懂"音乐!本文将带你全面了解音乐在 AI 世界中的 7 种表示方法,从波形到 MIDI,从频谱到 MFCC,手把手教你用 Python 实现。
为什么需要学习音乐表示?
在 AI 音乐生成领域(如 MusicGen、Suno、Udio 等),音乐表示是第一步,也是最关键的一步。
想象一下:人类通过乐谱、听觉来理解音乐,但 AI 只能理解数字。如何把美妙的音乐转换成 AI 能理解的数字形式?这就是"音乐表示"要解决的问题。
本文将带你掌握 7 种核心音乐表示方法,并附上完整的 Python 代码,让你从零开始构建 AI 音乐生成的知识体系!
环境准备
首先安装必要的库:
!pip install -q librosa soundfile matplotlib numpy scipy torch torchaudio pretty_midi
核心库说明:
librosa:音频处理的神器matplotlib:可视化频谱图pretty_midi:处理 MIDI 文件torchaudio:PyTorch 音频处理
1. 音频波形(Waveform)—— 音乐的最原始形态
什么是波形?
波形是声音在时域上的表示,展示了振幅随时间的变化。就像你看到的声波图一样。

可视化波形
plt.figure(figsize=(12, 4))
plt.plot(y)
plt.title("时域波形 (Time Domain Waveform)")
plt.xlabel("采样点")
plt.ylabel("振幅")
plt.show()
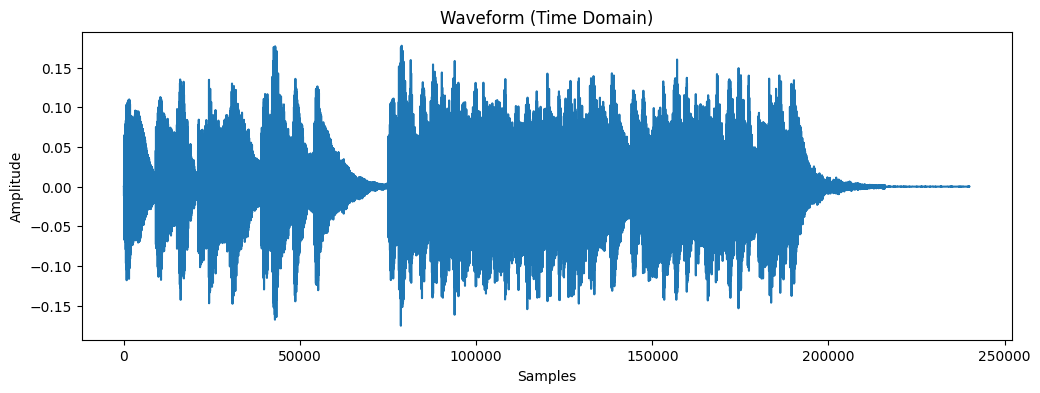
知识点:波形是最直观的音乐表示,但对 AI 来说信息密度太低,需要进一步转换。
2. 频域分析(FFT)—— 拆解音乐的"基因"
什么是频域?
如果说时域看的是"声音随时间怎么变化",那么频域看的就是"声音由哪些频率组成"。
核心概念:FFT(快速傅里叶变换)
- 任何复杂信号 = 多个不同频率的正弦波叠加
- FFT 把时域信号转换到频域

通俗理解:
- 时域 = 看一首歌的"剧情发展"(随时间变化)
- 频域 = 看一首歌的"演员阵容"(有哪些频率在"参演")
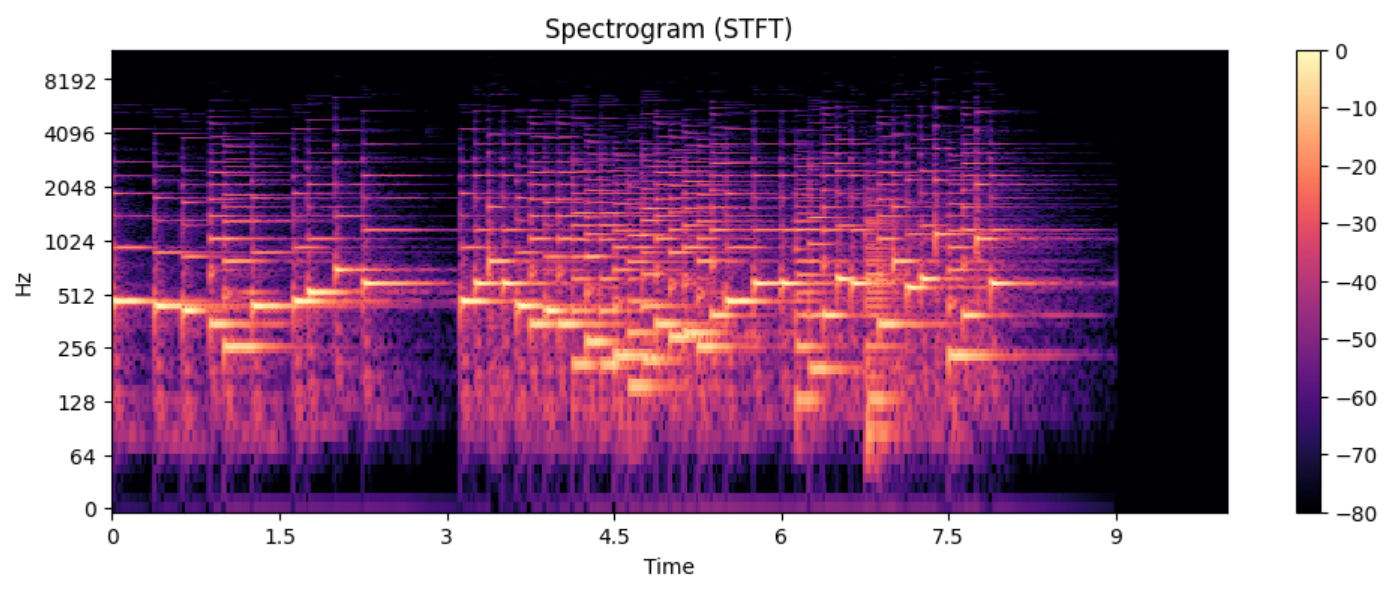
3. 声谱图(Spectrogram)—— 音乐的"照片"
为什么需要声谱图?
普通 FFT 有个致命问题:只能看整体,看不到时间变化。但音乐的频率是随时间变化的!
解决方案:STFT(短时傅里叶变换)
- 把音频切成小段
- 每段分别做 FFT
- 拼起来 = 声谱图
# 计算 STFT
D = librosa.stft(y)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
# 可视化声谱图
plt.figure(figsize=(12, 4))
librosa.display.specshow(S_db, sr=sr, x_axis='time', y_axis='log')
plt.colorbar(format='%+2.0f dB')
plt.title("声谱图 (Spectrogram)")
plt.xlabel("时间")
plt.ylabel("频率 (Hz)")
plt.show()
图示解读:
- 横轴:时间
- 纵轴:频率(对数刻度)
- 颜色深浅:该时刻该频率的能量强度
4. Mel 频谱图(Mel Spectrogram)—— AI 最爱的表示
什么是 Mel 刻度?
关键发现:人耳对低频敏感,对高频不敏感!
Mel 刻度就是模拟人耳听觉特性的频率刻度:
- 低频区域:拉伸(分辨率高)
- 高频区域:压缩(分辨率低)
# 计算 Mel 频谱图
mel = librosa.feature.melspectrogram(y=y, sr=sr, n_mels=128)
mel_db = librosa.power_to_db(mel, ref=np.max)
# 可视化
plt.figure(figsize=(12, 4))
librosa.display.specshow(mel_db, sr=sr, x_axis='time', y_axis='mel')
plt.colorbar(format='%+2.0f dB')
plt.title("Mel 频谱图")
plt.xlabel("时间")
plt.ylabel("Mel 频率")
plt.show()
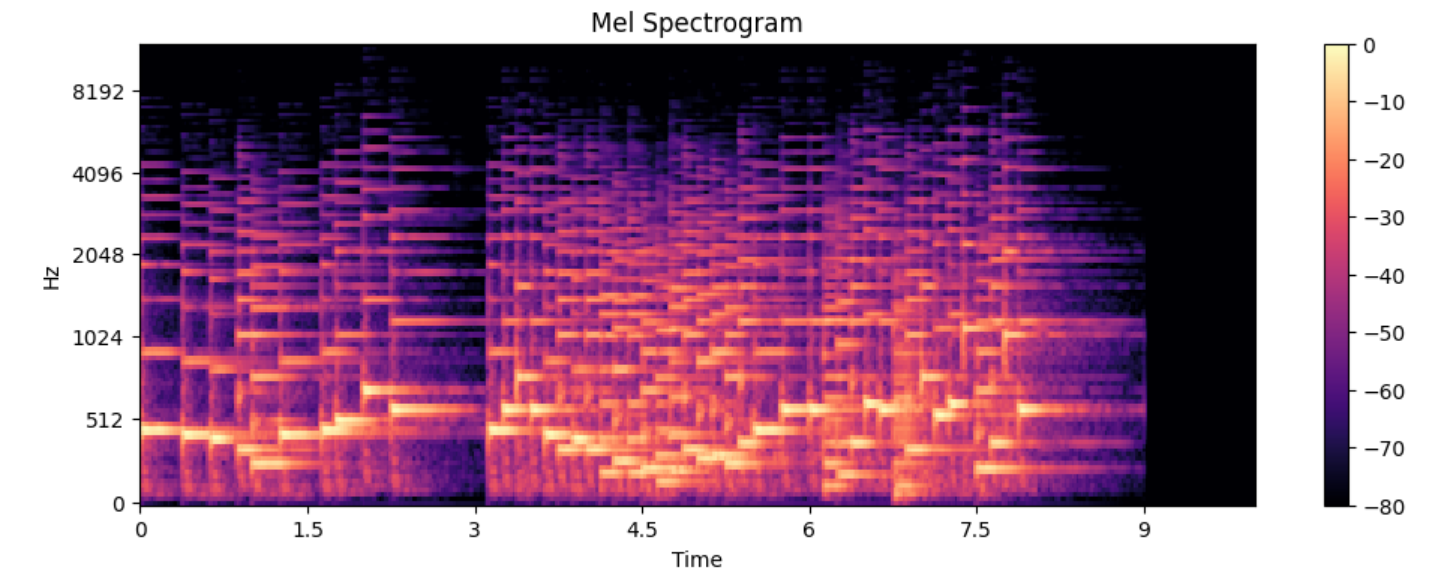
重要应用:
- 语音识别(ASR)
- 语音合成(TTS)
- 音乐分类
- 说话人识别
- 所有语音/音乐大模型的标准输入!
为什么神经网络偏爱 Mel 频谱图?
因为它更符合人耳感知,网络更容易学到有意义的特征!
5. MFCC —— 语音识别的经典特征
什么是 MFCC?
MFCC(Mel Frequency Cepstral Coefficients,Mel 频率倒谱系数)是语音识别领域最经典的特征。
名字拆解:
- Mel:用人耳听觉刻度
- Frequency:来自频域分析
- Cepstral:倒谱(对频谱再做一次变换)
- Coefficients:最终输出一组数字
# 提取 13 维 MFCC
mfcc = librosa.feature.mfcc(y=y, sr=sr, n_mfcc=13)
# 可视化
plt.figure(figsize=(12, 4))
librosa.display.specshow(mfcc, x_axis='time')
plt.title("MFCC 特征")
plt.xlabel("时间")
plt.ylabel("MFCC 系数")
plt.show()
print("MFCC 形状:", mfcc.shape)
Output:
MFCC 形状: (13, 1001) # 13个系数 × 1001个时间帧
MFCC vs Mel 频谱图:
- Mel 频谱图:保留完整的频谱形状
- MFCC:提取频谱的整体形状特征,数据量更小
6. MIDI 符号表示 —— 音乐的"乐谱"
什么是 MIDI?
MIDI(Musical Instrument Digital Interface)不是音频,而是演奏指令!
它记录的是:
- 音高(Pitch):哪个音?(如 C4、A4)
- ️ 起始时间(Onset):什么时候按下的?
- 时值(Duration):按了多久?
- 力度(Velocity):按得多重?
# 加载 MIDI 文件
midi = pretty_midi.PrettyMIDI("657944__lilmati__skeleton-playing-piano-02.mid")
# 查看前 10 个音符
for note in midi.instruments[0].notes[:10]:
print(f"音高: {note.pitch}, 起始: {note.start:.3f}s, 结束: {note.end:.3f}s")
解读:
- 音高 60 = 中央 C(C4)
- 第二行:在 0.384 秒按下 E4 音,持续 0.243 秒
7. 钢琴卷轴(Piano Roll)—— 可视化 MIDI
什么是钢琴卷轴?
钢琴卷轴是 MIDI 的二维可视化表示:
- 横轴:时间
- 纵轴:音高(钢琴键盘)
- 颜色/亮度:音符是否激活
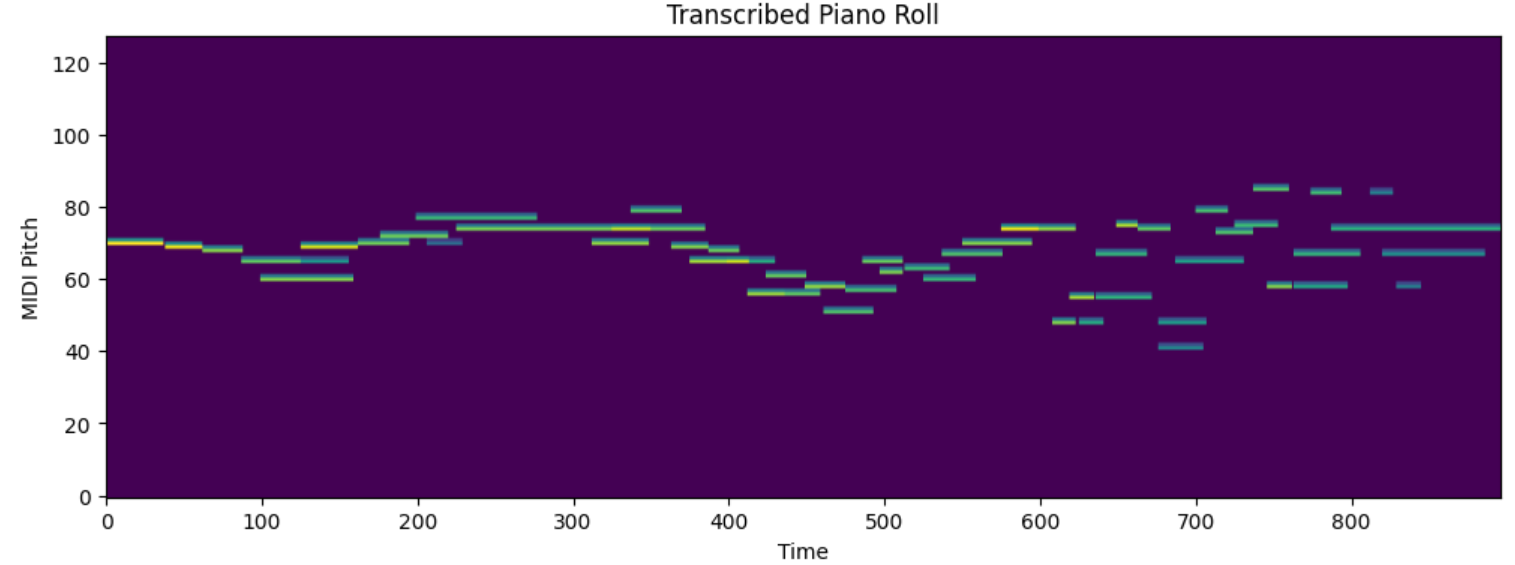
钢琴卷轴的应用:
- AI 作曲模型(如 MuseNet、Music Transformer)
- 音乐生成(Symbolic Music Generation)
- MIDI 编辑软件的标准视图
8. MIDI 回放 —— 从符号到声音
# 将 MIDI 转换为音频
audio = midi.synthesize()
# 播放
ipd.display(ipd.Audio(audio, rate=44100))
神奇之处:虽然原始音频和 MIDI 音频的音色不同,但旋律完全一致!这就是符号表示的魅力——分离了"演奏内容"和"演奏音色"。
七种音乐表示方法对比
| 表示方法 | 数据类型 | 信息内容 | 典型应用 |
|---|---|---|---|
| 波形 | 连续信号 | 振幅随时间变化 | 音频播放、基础处理 |
| FFT | 频域谱 | 整体频率分布 | 音频分析 |
| 声谱图 | 2D 图像 | 频率随时间变化 | 音乐可视化 |
| Mel 频谱图 | 2D 图像 | 人耳感知频率 | 语音/音乐 AI 标准输入 |
| MFCC | 特征向量 | 频谱形状特征 | 语音识别 |
| MIDI | 符号序列 | 音符事件 | AI 作曲、符号音乐生成 |
| 钢琴卷轴 | 2D 矩阵 | 音符时空分布 | Music Transformer 等模型 |
下一步:Encodec Tokens
本文介绍的 7 种表示方法是音乐 AI 的基础。在下一章,我们将学习:
Encodec Tokens —— Meta 提出的神经音频编解码器,它能把音频压缩成离散的 token 序列,让音乐生成模型(如 MusicGen)能像处理文本一样处理音频!
敬请期待下一期:《Audio Tokenizer:让 AI 用"单词"理解音乐》
互动话题
- 你正在学习 AI 音乐生成的哪个方向?
- 对哪种音乐表示方法最感兴趣?
- 你用过哪些 AI 音乐生成工具(Suno、Udio、MusicGen)?
欢迎在评论区留言讨论! 👇
参考资料
- Librosa 官方文档:https://librosa.org/
- MusicLM 论文:https://google-research.github.io/seanet/musiclm/examples/
- MusicGen 论文:https://arxiv.org/abs/2306.05284
- Encodec 论文:https://arxiv.org/abs/2210.13438
最后要感谢Datawhale提供这样一次机会,还有田佳铭、王泊轩、林睿哲、刘秋杰几位老师对创作的努力和贡献,让我们继续为开源做出我们自己的贡献~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献9条内容
已为社区贡献9条内容

所有评论(0)