CVPR 2024 | GM-DETR:基于高效融合编码器的广义多光谱检测 Transformer,适用于可见光 - 红外检测

01 论文信息
论文题目: GM-DETR: Generalized Muiltispectral DEtection TRansformer with Efficient Fusion Encoder for Visible-Infrared Detection
论文作者: Yiming Xiao, Fanman Meng, Qingbo Wu, Linfeng Xu, Mingzhou He, Hongliang Li
发表单位: University of Electronic Science and Technology of China
发表会议\期刊: CVPR 2024
代码链接: https://github.com/yiming-shaw/GM-DETR
02 论文主要贡献
本文针对多光谱目标检测提出了一种 两阶段训练策略 和 高效融合编码器,主要贡献如下:
- 两阶段训练策略:
隔离阶段:利用独立的 IR 或 RGB 数据增强各模态特征提取能力;
融合阶段:利用配对对齐数据进行跨模态特征融合训练,提高检测性能。 - GM-DETR 模型设计:
Modality-Specific Feature Interaction (MSFI) 模块:用于提取不同模态的全局信息;
Cross-Modality-Scale Feature Fusion (CMSF) 模块:实现跨模态与多尺度特征的高效融合。 - 实验验证:
在 FLIR 和 LLVIP 数据集上,GM-DETR 在 mAP 与 AP 等指标上均超过现有最先进方法(SOTA)。
03 论文创新点
- 两阶段训练策略提升泛化能力:即便在模态缺失的场景下,模型仍能保持高性能。
- 高效融合编码器:MSFI + CMSF 模块实现跨模态全局信息提取与多尺度融合,提高检测精度与效率。
- 端到端实时检测:基于 RT-DETR,保持高帧率 (218 FPS) 的同时加入高效融合机制。
04 方法
4.1整体框架
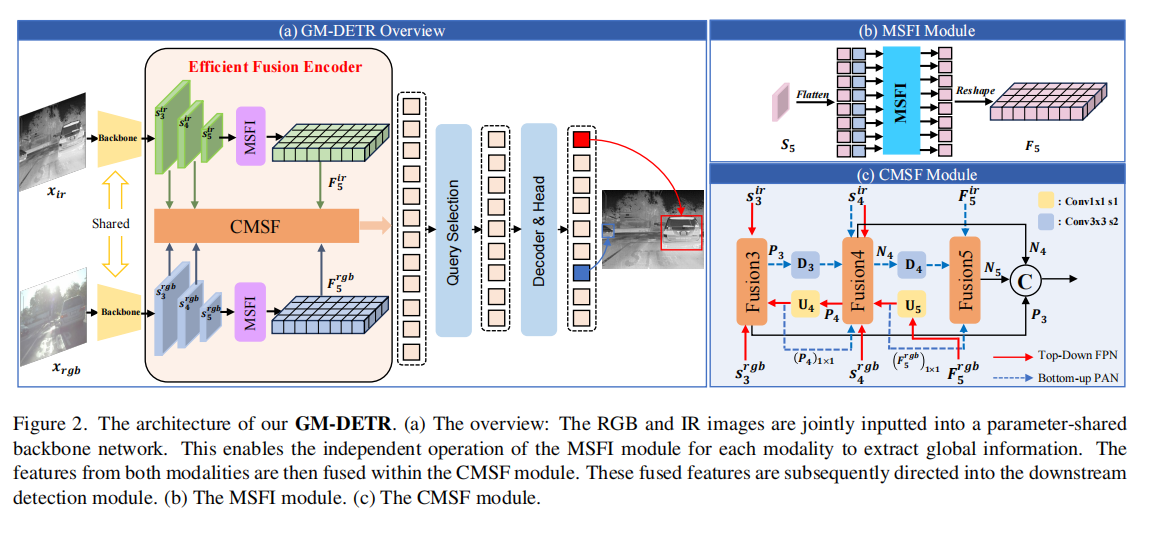
(a) 整体架构:RGB与红外图像共同输入参数共享的主干网络,使 MSFI 模块能独立处理两种模态以提取全局信息。随后在 CMSF 模块中融合两种模态的特征,最终将融合后的特征导向下游检测模块。(b) MSFI 模块。© CMSF模块。
具体而言,提出了一种基于DETR的新型多光谱目标检测器。
GM-DETR架构包含两个参数共享的骨干网络、高效的融合编码器,以及配备预测头的Transformer解码器。特别值得注意的是,该模型基于实时检测Transformer(RT-DETR)构建,这是首个实时端到端目标检测系统。
编码器以 { S 3 i r , S 4 i r , S 5 i r ; S 3 r g b , S 4 r g b , S 5 r g b } \{ S_3^{\mathrm{ir}}, S_4^{\mathrm{ir}}, S_5^{\mathrm{ir}};\; S_3^{\mathrm{rgb}}, S_4^{\mathrm{rgb}}, S_5^{\mathrm{rgb}} \} {S3ir,S4ir,S5ir;S3rgb,S4rgb,S5rgb}作为输入,通过高效融合编码器将多尺度多光谱特征进行整合与转换,生成图像特征序列。随后通过查询选择机制,从编码器输出序列中选取固定数量的图像特征作为初始目标查询。这些查询最终被输入解码器,通过迭代优化过程持续提升检测结果的精确度。
该模型的两阶段训练流程分为隔离阶段和融合阶段,分别使用两种数据类型。在融合阶段采用配对的红外(IR)与RGB数据集 { x i r , x r g b , y } \{ x_{ir}, x_{rgb}, y \} {xir,xrgb,y},其中标签y在两个图像之间共享。此外,还包含独立标注的红外数据集 { x i r , y i r } \{ x_{ir}, y_{ir} \} {xir,yir}和RGB数据集 { x r g b , y r g b } \{ x_{rgb}, y_{rgb} \} {xrgb,yrgb},分别对应独立的红外图像 和RGB图像 的标注信息和 。
4.2预处理
在 GM-DETR 中,预处理模块负责处理输入的 RGB 与 IR 图像,并为后续高效融合编码器提供高质量、多尺度特征。输入为配对的可见光(RGB)与红外(IR)图像,在隔离阶段,单模态图像会复制为两通道输入,例如 x ir , x ir { x_{\text{ir}}, x_{\text{ir}} } xir,xir 或 x rgb , x rgb { x_{\text{rgb}}, x_{\text{rgb}} } xrgb,xrgb,以提升各模态特征提取能力;在融合阶段,则输入对齐的 RGB + IR 图像以保证模态对应关系。所有图像首先被缩放至统一尺寸 640 × 640 640 \times 640 640×640 并进行归一化处理,同时对 RGB 和 IR 模态分别应用数据增强策略,包括随机水平翻转、裁剪、RGB 颜色扰动及 IR 热红外亮度增强等,以提升模型对光照变化、天气条件及复杂背景的鲁棒性。随后,输入图像通过参数共享的 CNN Backbone提取多尺度特征,得到 S 3 rgb , S 4 rgb , S 5 rgb ; S 3 ir , S 4 ir , S 5 ir { S_3^{\text{rgb}}, S_4^{\text{rgb}}, S_5^{\text{rgb}}; S_3^{\text{ir}}, S_4^{\text{ir}}, S_5^{\text{ir}} } S3rgb,S4rgb,S5rgb;S3ir,S4ir,S5ir,每个尺度特征同时保留低层细节和高层语义信息,为高效融合编码器提供充分信息。在隔离阶段,Backbone 提取的单模态特征增强了模型对 RGB 或 IR 特征的表示能力,而在融合阶段,Backbone 提取的双模态特征被送入 MSFI 和 CMSF 模块进行跨模态多尺度融合,最终生成输入 Transformer 解码器的特征序列,从而保证模型在目标检测任务中能够充分利用两种模态的互补信息,并提高检测精度与鲁棒性。
4.3高效融合编码器
4.3.1模态特异性特征交互(MSFI)
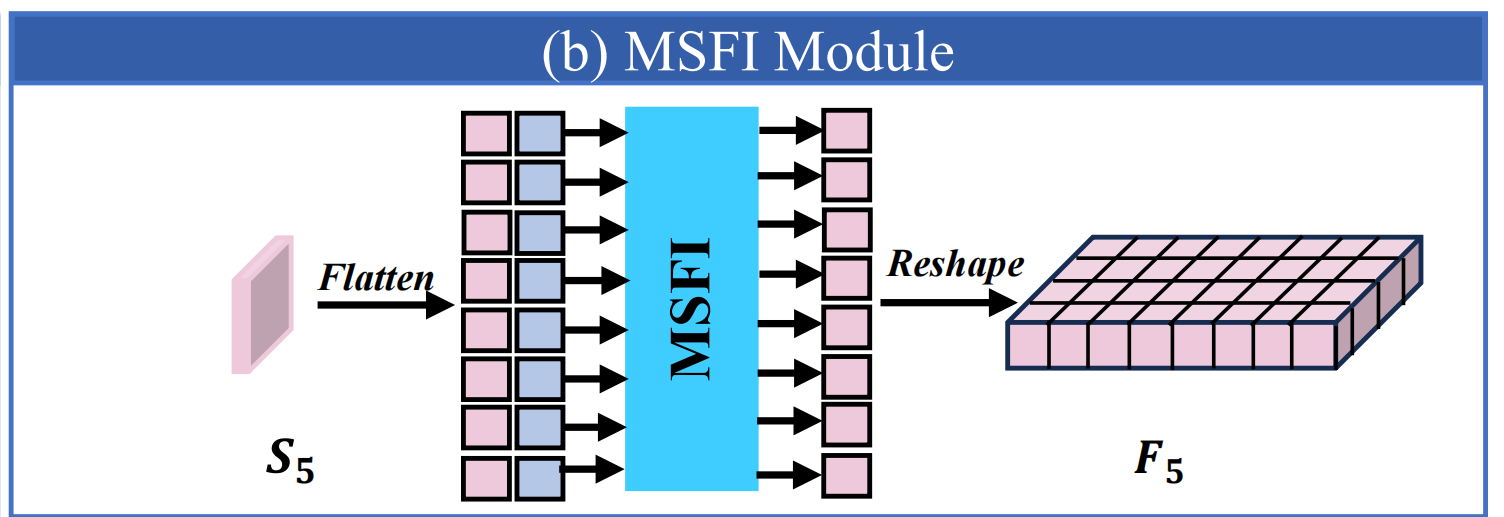
该模块专门应用于包含丰富语义信息的高级特征层 { S 5 i r , S 5 r g b } \{ S_5^{\mathrm{ir}}, S_5^{\mathrm{rgb}} \} {S5ir,S5rgb}。通过在这些高级层应用自注意力机制,可有效提升捕捉图像中实体间的关系的能力,从而为后续的物体检测与识别模块提供支持。
Q = K = V = F l a t t e n ( S 5 ) F 5 = R e s h a p e ( A t t n ( Q , K , V ) ) Q = K = V = \mathrm{Flatten}(S_5) \\ F_5 = \mathrm{Reshape}(\mathrm{Attn}(Q, K, V))\\ Q=K=V=Flatten(S5)F5=Reshape(Attn(Q,K,V))
其中Atten表示多头自注意力,Reshape是Flatten 的逆运算, F 5 {F_5} F5的形状与 S 5 {S_5} S5 相同。
4.3.2跨模态尺度特征融合(CMSF)模块
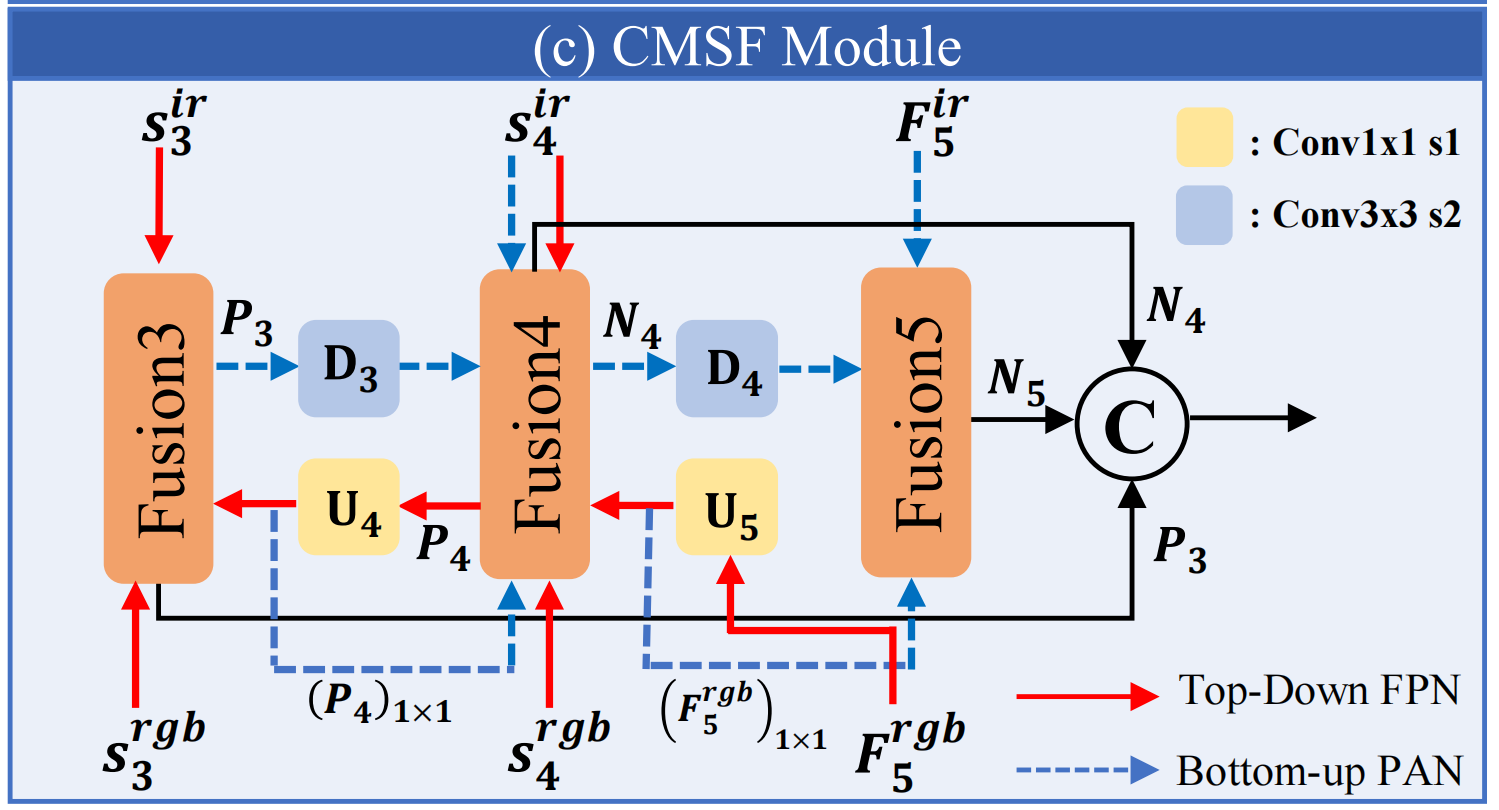
该模块包含两个分支:自上而下的 FPN 分支和自下而上的PAN分支。
FPN
我们利用具有丰富特征连接信息的 F 5 r g b F_5^{\mathrm{rgb}} F5rgb进行自上而下的上采样,从而获取富含语义信息的高分辨率特征
P 4 = F 4 ( U 5 ( F 5 r g b ) , S 4 r g b , S 4 i r ) P 3 = F 3 ( U 4 ( P 4 ) , S 3 r g b , S 3 i r ) P_4 = F_4\big(U_5(F_5^{\mathrm{rgb}}), S_4^{\mathrm{rgb}}, S_4^{\mathrm{ir}}\big) \\ P_3 = F_3\big(U_4(P_4), S_3^{\mathrm{rgb}}, S_3^{\mathrm{ir}}\big) P4=F4(U5(F5rgb),S4rgb,S4ir)P3=F3(U4(P4),S3rgb,S3ir)
其中 U 5 ( . ) U_5(.) U5(.)和 U 4 ( . ) U_4(.) U4(.)均由1 × 1卷积层后接上采样操作构成。 F 4 ( ⋅ , ⋅ , ⋅ ) F_4(·,·,·) F4(⋅,⋅,⋅)是 FPN 融合模块,用于拼接多层级特征。
fusion模块通过两个1 × 1卷积层分别生成两条独立的输出路径:其中一条特征分支经过N个RepBlocks模块处理,两条路径的输出最终通过元素级加法运算进行融合。
PAN
N 4 = A 4 ( D 3 ( P 3 ) , ( P 4 ) 1 × 1 , S 4 i r ) N 5 = A 5 ( D 4 ( N 4 ) , ( F 5 r g b ) 1 × 1 , F 5 i r ) N_4 = A_4\big(D_3(P_3), (P_4)_{1\times 1}, S_4^{\mathrm{ir}}\big)\\ N_5 = A_5\big(D_4(N_4), (F_5^{\mathrm{rgb}})_{1\times 1}, F_5^{\mathrm{ir}}\big) N4=A4(D3(P3),(P4)1×1,S4ir)N5=A5(D4(N4),(F5rgb)1×1,F5ir)
其中 D 3 ( . ) D_3(.) D3(.)作为步长为2的3 × 3卷积层执行下采样操作。 ( . ) 1 × 1 (.)_{1×1} (.)1×1是1 × 1卷积层后的输出,和 A 4 ( . , . , . ) A_4(.,.,.) A4(.,.,.)是PAN融合块,其结构类似于前述的 FPN 融合块
高效融合编码器输出的最终多尺度融合特征为 { P 3 , N 4 , N 5 } \{ P_3, N_4, N_5 \} {P3,N4,N5},这些特征被输入到RT-DETR的Transformer解码器中,通过预测头获得检测结果。
4.4两阶段训练
DETR框架对数据资源需求极大[25]。当前多光谱目标检测可用数据集在数量上已显不足。受[13]研究启发,我们提出在先前融合训练的基础上,通过隔离阶段提升目标检测模型对红外(IR)和可见光(RGB)模态的特征提取能力。完整训练策略如图1©所示。
隔离阶段。
在隔离阶段,我们将IR和RGB数据集合并为一个合并数据集。该模型的双通道输入数据由两幅完全相同的红外线 { x i r , x i r } \{ x_{ir}, x_{ir} \} {xir,xir}或可见光 { x r g b , x r g b } \{ x_{rgb}, x_{rgb} \} {xrgb,xrgb}复现图像构成。在目标检测训练阶段,模型通过对应标注数据 y i r { y_{ir}} yir或 y r g b {y_{rgb} } yrgb进行监督学习。这一阶段旨在提升模型对红外线与红绿蓝图像的特征提取能力。分离阶段可采用与最初用于融合阶段训练的对齐数据独立分离的数据进行。此外,还可选择使用其他合并后的分离IR或RGB数据集进行训练。
融合阶段。
在该阶段,模型接收经过时空对齐的红外与可见光数据 { x i r , x r g b } {\{x_{ir},x_{rgb}\} } {xir,xrgb}进行训练。模型在训练过程中通过共享标签 { y } {\{y\}} {y}进行监督学习。该阶段的架构设计参考了先前多光谱目标检测算法的训练流程,旨在帮助模型有效学习红外与可见光特征的融合,从而提升目标检测性能。
4.5损失函数
训练损失。在分离阶段和融合阶段,唯一区别在于两个数据流的输入,两个阶段的任务都涉及目标检测,因此我们使用相同的检测损失函数, L total \mathcal{L}_{\text{total}} Ltotal为:
L total = L box + L cls \mathcal{L}_{\text{total}} = \mathcal{L}_{\text{box}} + \mathcal{L}_{\text{cls}} Ltotal=Lbox+Lcls
其中为 L box \mathcal{L}_{\text{box}} Lbox边框回归损失,为 L cls \mathcal{L}_{\text{cls}} Lcls分类损失,整体损失函数与先前研究一致。
05 实验
5.1实验设置
数据集
我们在两个常用数据集上评估了所提出的方法,即对齐的**FLIR **和 LLVIP。此外,在隔离阶段,我们从对齐的 FLIR 和 LLVIP 中分离和组合IR和RGB数据进行训练,以证实两阶段方法的好处。
模型训练共60个周期,采用分两阶段训练方案:先用原始数据进行10个周期的分离阶段训练,再进行50个周期的融合阶段训练。训练参数设置为批量大小4,图像尺寸为640 × 640。
与先进方法的比较
鉴于训练数据的多样性,我们为本方法设计了两种训练策略。第一种策略沿用先前研究的设计,仅包含融合阶段,记为Ours(fus)。第二种策略分为两个阶段:在隔离阶段将IR和RGB数据合并进行训练,随后在融合阶段进行训练,记为Ours(iso+fus)。
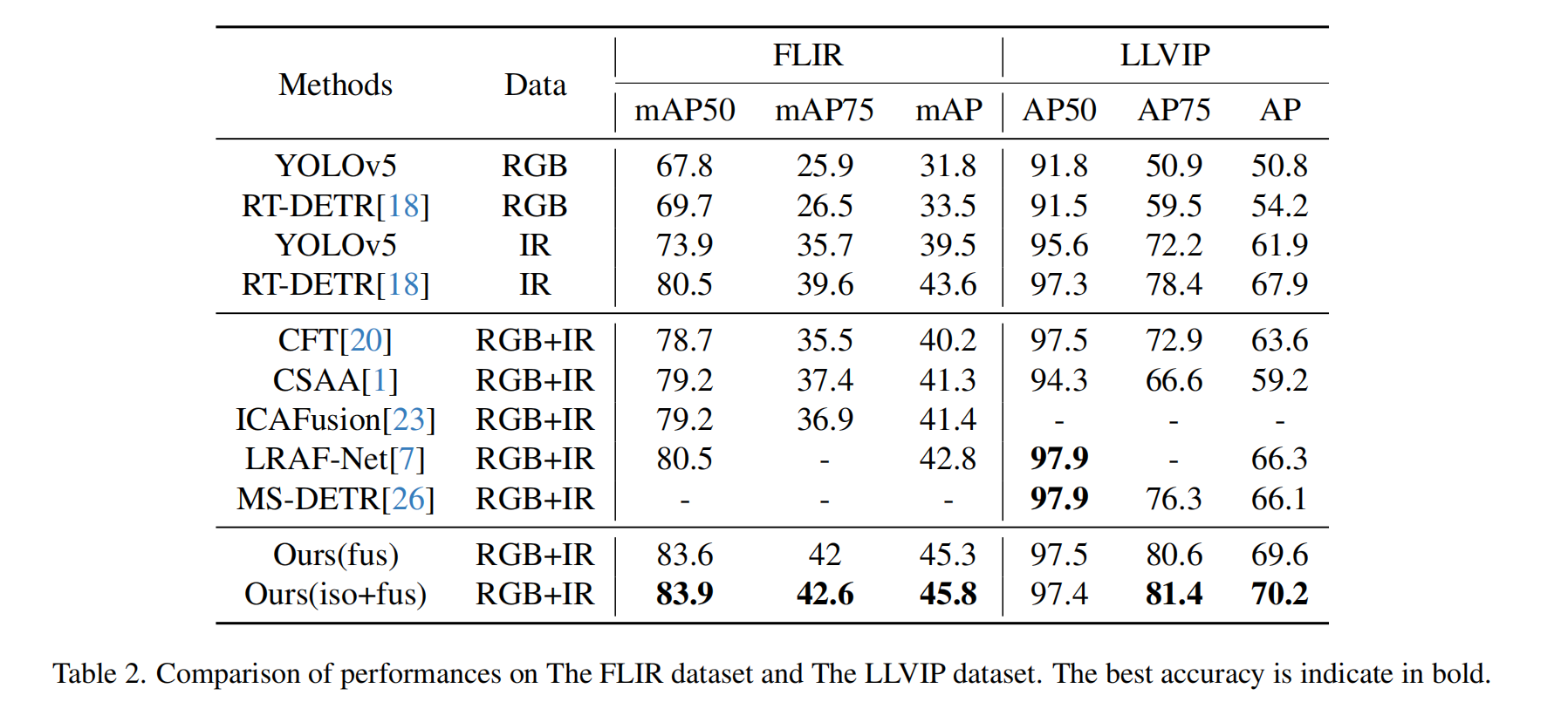
FLIR
- 单模态检测方法:RT-DETR*[18],在合并的 FLIR 数据集上进行训练。
- 多模态检测方法:CFT [20]、 CSAA [1]、ICAFusion[23] 和 LRAF -Net[7]。
实验数据显示,RT-DETR单模态红外基线模型的平均精度(mAP)显著优于现有多模态融合检测方法。这表明在多光谱目标检测任务中,基线模型的改进带来了显著提升。仅在融合阶段训练的模型,其mAP较前人最优方法提升了2.5%,同时在红外模态上比RT-DETR基线模型高出1.3%。这说明我们的模型能有效整合红外与RGB双模态信息。采用两阶段训练策略时,与仅在融合阶段训练相比,平均精度(mAP)可额外提升0.5%。这表明,在不引入新训练数据的情况下,改用两阶段训练策略能使模型获得更强的性能表现。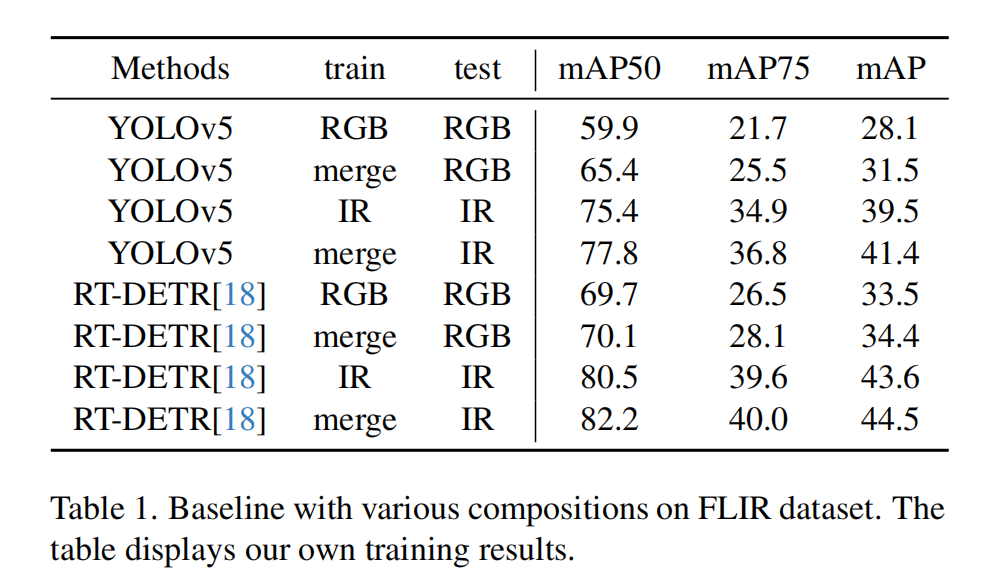
LLVIP
- 在我们的 LLVIP 数据集实验中,下面展示的基线数据仍然遵循先前工作的设置和结果,基线是在它们各自的模态(IR或RGB)上进行训练和测试的。我们还将本方法与基于可变形DETR的多光谱行人检测方法MS-DETR[26]进行了对比。
与单模态RT-DETR相比,我们采用两阶段训练的模型将平均精度(AP)提升了2.3%。相较于当前最先进的多模态目标检测方法,AP值进一步提高了3.9%。虽然在AP50指标上略逊于顶尖方法,但我们的方案在高交并比(IoU)AP指标上展现出显著优势,这表明其在人体检测方面具有更高的精确度。
5.2消融实验
输入消融研究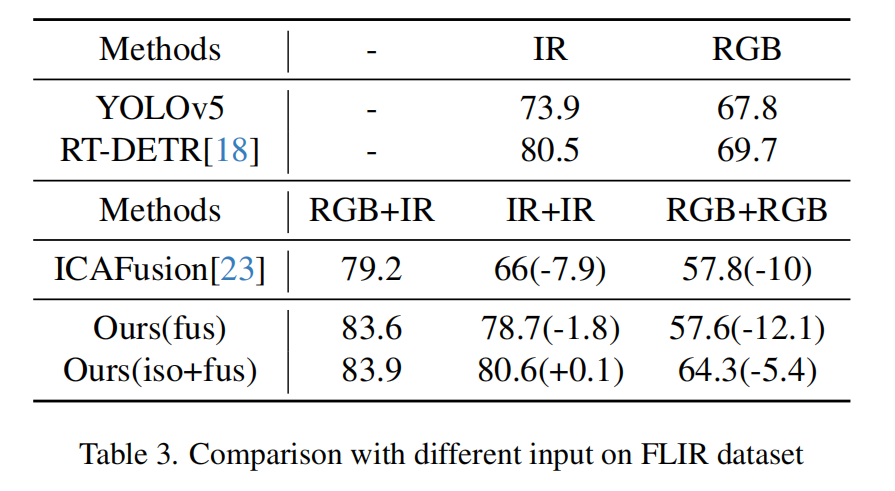
在多光谱目标检测的实际应用场景中,常会遇到模态缺失的情况,即无法直接输入单一模态的数据。这导致输入数据仅来自单一模态。我们在此场景下对比了不同模型的性能表现。对于我们的模型而言,当发生模态缺失时,输入数据会被转换为两个完全相同的单模态数据副本。
实验结果表明,基于单模态数据训练的基线网络在各自模态上均能取得最优效果。在多光谱检测模型中处理模态缺失时,ICAFusion相较于其基线网络Yolov5会出现显著性能下降。对于我们的模型,采用两阶段训练策略后,当仅使用红外输入时,模型性能与基线RT-DETR相当;而仅使用RGB输入时,模型性能仅下降5.4%,融合训练策略则下降12.1%。这不仅验证了两阶段训练策略的有效性,更表明我们的模型在模态缺失场景下仍能保持良好泛化能力,展现出强大的适应性。
模块消融研究
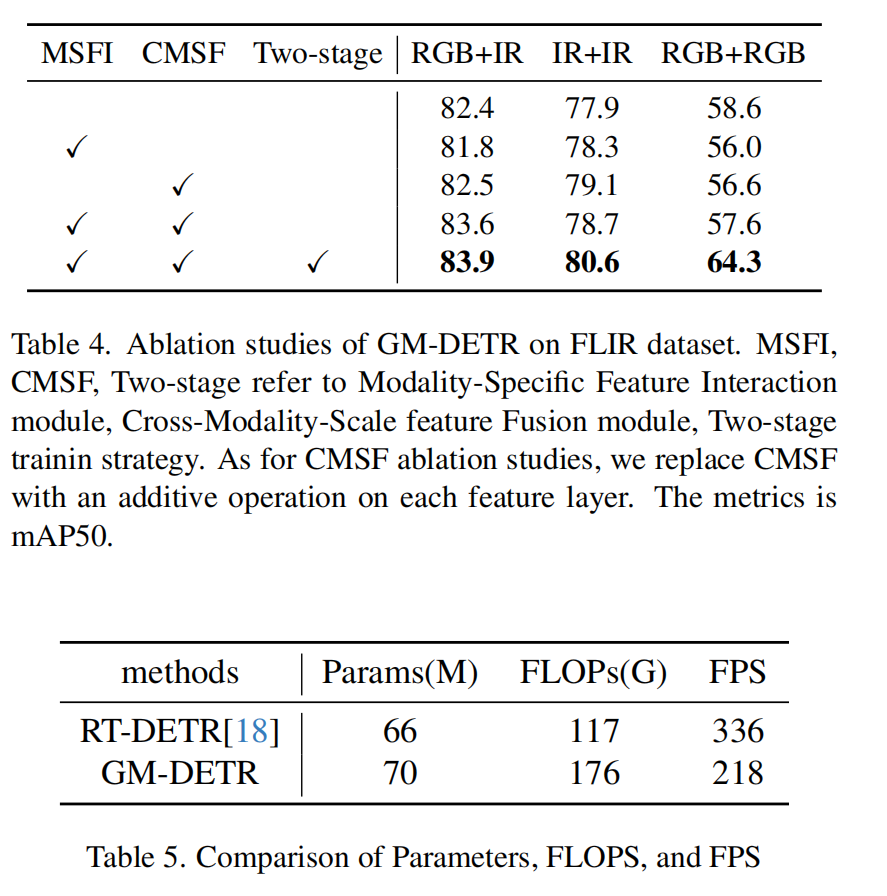
模型在 FLIR 数据集上的mAP50性能,分别使用RGB+IR、IR+IR、RGB+RGB数据输入。对于RGB+IR数据输入,从82.4%的基线开始,加入 MSFI 模块后性能下降了0.6%。这表明直接对仅由主干网络提取的特征进行加权求和是直观且效果良好的。在基线上加入CMSF 模块后,IR+IR数据集上的mAP50提高了1.2%,但在RGB+RGB数据输入上下降了2%。此外,由于MSFI 和 CMSF 的设计是集成的,模型利用 MSFI 提取的全局信息来指导 CMSF 模块融合两种模态的信息。在同时集成 MSFI 和 CMSF 后,模型相比基线表现出了1.2%的性能提升。然而,这种同时集成也导致了RGB+IR数据类型过拟合。随着两阶段训练策略的实施,该模型在IR+IR和RGB+RGB数据输入中均表现出显著改进,在所有三种输入类型中均达到最优性能。
06 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)