IF 2026 | SPGFusion:基于预训练视觉模型的语义先验引导红外与可见光图像融合
IF 2026 | SPGFusion:基于预训练视觉模型的语义先验引导红外与可见光图像融合

1 论文信息
- 论文题目:SPGFusion:基于预训练视觉模型的语义先验引导红外与可见光图像融合
- 论文作者:Huiqin Zhang a, Shihan Yao a, Jiayi Ma , Junjun Jiang c, Yanduo Zhang a, Huabing Zhou a ,
- 发表单位:湖北智能机器人重点实验室,武汉理工大学,武汉大学电子信息学院,哈尔滨工业大学人工智能学院,
- 发表会议\期刊:IF2026
- 代码链接:https://github.com/Huiqin-Zhang/SPGFusion
2 论文主要贡献
图像融合将同一场景的多幅图像合成为单幅增强图像,提升视觉清晰度并支撑高级视觉任务。现有红外‑可见光图像融合方法虽能增加语义细节,但高度依赖标注数据,灵活性受限,且无法捕捉跨模态不同目标的独有特征——这些特征对人类感知至关重要。上述局限阻碍了有效自适应融合。为此,本文提出SPGFusion:一种无需人工标注的语义先验引导红外‑可见光图像融合方法。
SPGFusion利用CLIP的全局语义对齐能力,将视觉特征与人类自然语言知识关联,实现图像全局语义结构的全面理解。同时,借助DINO对语义相似特征的聚类能力,捕捉细粒度局部语义细节。全局与局部语义先验互补结合,使模型在无标注条件下对源图像实现全面、精细的语义理解,有效克服现有方法的标注依赖问题。
这些先验通过专门设计的语义自适应融合网络引导融合过程,实现自适应、语义感知的融合,突出模态独有特征。最后,视觉特征解码器合成融合图像,保留各源图像的关键语义细节。凭借鲁棒的无标注语义先验,SPGFusion对红外与可见光源图像实现更深度理解,可自适应融合跨模态核心特征。在公开数据集上的大量实验表明,SPGFusion在视觉质量与语义精度上均超越当前最优方法。
3 论文创新点
本文主要贡献总结如下:
- 提出SPGFusion,一种创新图像融合方法,将CLIP与DINO等预训练视觉模型引入图像融合领域,引入鲁棒的无标注语义先验。该方法克服传统融合方法依赖人工标签、难以对多样语义目标自适应融合的局限。
- 为有效利用新型复合语义先验,设计语义自适应融合网络,包含C/PSAF模块。这些模块通过空间调制与跨模态注意力动态调整模态特有信息,实现上下文感知、语义自适应融合,突出各模态独有特征。
- 大量实验表明,SPGFusion显著超越当前最优融合算法,在视觉质量与高级视觉任务效果上表现更优,且显著降低对人工标注的依赖。
4 方法
4.1 整体框架
SPGFusion整体框架如图所示,包含三大组件:语义先验生成、语义自适应融合网络与视觉特征解码器。
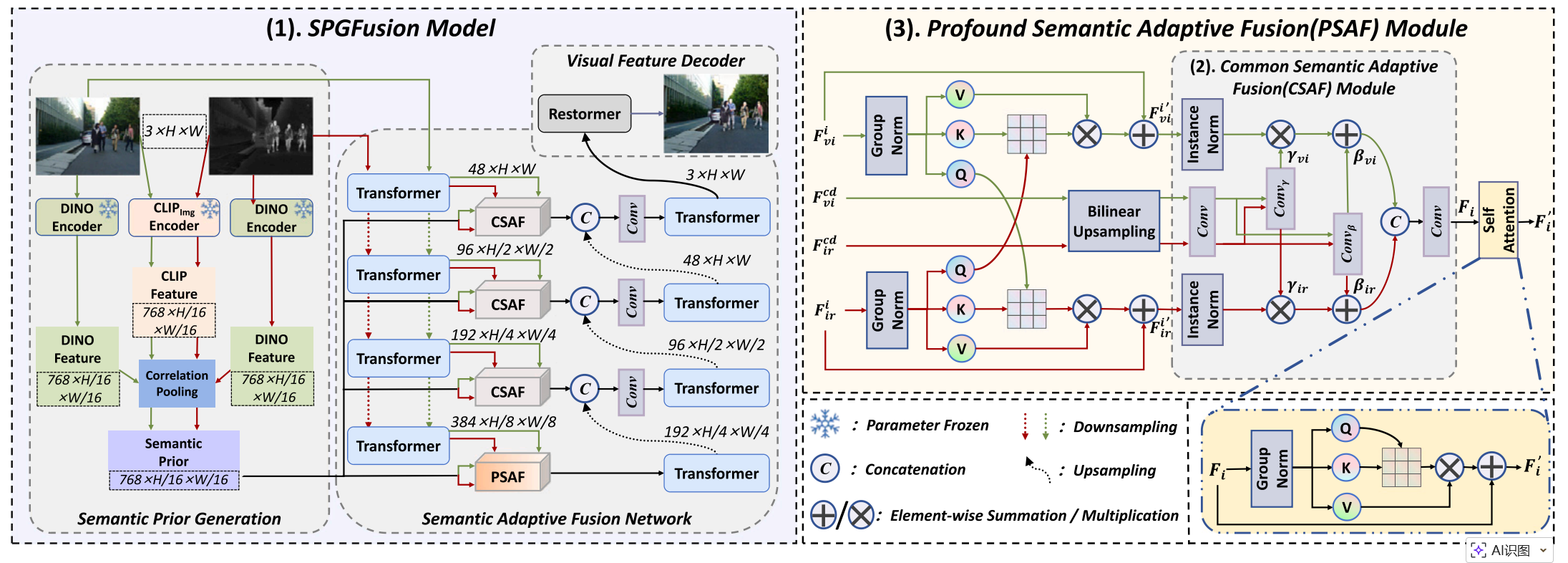
首先,在语义先验生成阶段,SPGFusion利用预训练CLIP与DINO特征提取器处理红外与可见光图像,得到两组语义特征。基于DINO提取的特征块间相似度计算亲和图,并用该亲和图对CLIP特征执行关联池化,得到融合全局与局部线索的语义先验。
随后,这些先验被用于语义自适应融合网络,其中 通用语义自适应融合(CSAF) 模块与 深度语义自适应融合(PSAF) 模块引导融合过程,自适应调制红外与可见光输入的模态特有特征。
这种自适应融合增强融合图像的语义连贯性与细节保留度。最后,视觉特征解码器将融合特征重建为最终输出图像。各组件将在后续章节详细阐述。
4.2 SPGFusion模型
语义先验生成
该组件负责从配对的可见光与红外图像生成语义先验。具体而言,本文使用参数冻结的预训练视觉模型CLIP与DINO,独立提取可见光与红外输入的视觉特征。过程如下:
{ F v i c , F i r c } = { θ c ( I v i ) , θ c ( I i r ) } (1) \left\{ F_{vi}^{c}, F_{ir}^{c}\right\} =\left\{ \theta _{c}\left( I_{vi}\right) , \theta_{c}\left( I_{ir}\right) \right\} \tag{1} {Fvic,Firc}={θc(Ivi),θc(Iir)}(1)
{ F v i d , F i r d } = { θ d ( I v i ) , θ d ( I i r ) } (2) \left\{F_{vi}^{d}, F_{ir}^{d}\right\}=\left\{\theta_{d}\left(I_{vi}\right), \theta_{d}\left(I_{ir}\right)\right\} \tag{2} {Fvid,Fird}={θd(Ivi),θd(Iir)}(2)
其中 θ c \theta_{c} θc与 θ d \theta_{d} θd分别表示CLIP与DINO的图像编码器, I v i I_{vi} Ivi与 I i r I_{ir} Iir分别表示可见光与红外图像。
特征 F v i c F_{vi}^{c} Fvic与 F i r c F_{ir}^{c} Firc提取自CLIP最后一个注意力层的value嵌入,从query、key、value三类嵌入中剔除CLS token后选取。同理, F v i d F_{vi}^{d} Fvid与 F i r d F_{ir}^{d} Fird提取自DINO最后一个注意力层的value嵌入,同样剔除CLS token。
所有提取的语义特征统一维度为 768 × H / 16 × W / 16 768 × H/16 × W/16 768×H/16×W/16,其中 H H H与 W W W为输入图像的空间尺寸。
本文提出通过关联池化融合CLIP与DINO的语义特征。为清晰描述与公式表达,将CLIP的可见光与红外特征统一记为 F c F^{c} Fc(包含 F v i c F_{vi}^{c} Fvic与 F i r c F_{ir}^{c} Firc),DINO的特征统一记为 F d F^{d} Fd(包含 F v i d F_{vi}^{d} Fvid与 F i r d F_{ir}^{d} Fird)。
为融合DINO特征 F d F^{d} Fd与CLIP特征 F c F^{c} Fc,首先计算 F d F^{d} Fd中每对patch的余弦相似度,生成亲和图 ξ \xi ξ,量化局部区域间的语义一致性。
在该亲和图引导下,对空间patch上的 F c F^{c} Fc特征执行概念感知线性组合。该关联池化策略充当投票机制,强制语义相似patch间特征一致,抑制噪声响应,生成融合全局上下文与局部空间感知的新型语义特征 F c d F^{cd} Fcd。
关联池化操作形式化定义为:
F c d = ∑ i , j ξ i , j ⋅ F i , j c ∑ i , j ξ i , j + ϵ (3) F^{cd}=\frac{\sum_{i, j} \xi_{i, j} \cdot F_{i, j}^{c}}{\sum_{i, j} \xi_{i, j}+\epsilon} \tag{3} Fcd=∑i,jξi,j+ϵ∑i,jξi,j⋅Fi,jc(3)
其中 F i , j c F_{i, j}^{c} Fi,jc表示 F v i c F_{vi}^{c} Fvic或 F i r c F_{ir}^{c} Firc在空间位置 ( i , j ) (i,j) (i,j)处的值, ξ i , j \xi_{i,j} ξi,j表示 F v i d F_{vi}^{d} Fvid或 F i r d F_{ir}^{d} Fird在同一位置的亲和权重。该权重反映索引为 ( i , j ) (i,j) (i,j)的patch间语义相似度。 ϵ \epsilon ϵ为小常数,防止除零。
CLIP特征对整体语义目标(如人、植被)呈现类别级响应,激活区域分布松散但目标覆盖完整。相反,DINO特征聚焦语义实体内部的目标边界与连接点,激活更密集且局部化。
关联池化融合特征实现全局类别语义与局部细节的互补融合,有效结合CLIP的全局语义对齐与DINO的细粒度判别能力。因此,它们为后续融合步骤建立模态自适应基础,引导模型在无显式标签条件下选择性强调融合图像中的纹理细节与热强度信息。
语义自适应融合网络
在该组件中,配对的可见光与红外图像被送入图像编码器。本文采用基于Transformer的模块作为基础特征提取器。特征提取过程可公式化为:
{ F v i 1 , F i r 1 } = { T v i 1 ( I v i ) , T i r 1 ( I i r ) } (4) \left\{F_{vi}^{1}, F_{ir}^{1}\right\}=\left\{T_{vi}^{1}\left(I_{vi}\right), T_{ir}^{1}\left(I_{ir}\right)\right\} \tag{4} {Fvi1,Fir1}={Tvi1(Ivi),Tir1(Iir)}(4)
{ F v i i , F i r i } = { T v i i ( F v i i − 1 ) , T i r i ( F i r i − 1 ) } (5) \left\{F_{vi}^{i}, F_{ir}^{i}\right\}=\left\{T_{vi}^{i}\left(F_{vi}^{i-1}\right), T_{ir}^{i}\left(F_{ir}^{i-1}\right)\right\} \tag{5} {Fvii,Firi}={Tvii(Fvii−1),Tiri(Firi−1)}(5)
其中 i = 2 , 3 , 4 i=2,3,4 i=2,3,4。 T v i i T_{vi}^{i} Tvii与 T i r i T_{ir}^{i} Tiri分别表示可见光与红外图像的特征提取器。
当 i = 1 , 2 , 3 i=1,2,3 i=1,2,3时, F v i i F_{vi}^{i} Fvii与 F i r i F_{ir}^{i} Firi直接通过CSAF模块融合。而当 i = 4 i=4 i=4时,通过本文提出的PSAF模块执行融合,该模块在CSAF模块之前加入跨注意力、之后加入自注意力,如图(2)所示。
鉴于深度特征封装丰富的上下文语义信息,PSAF引入跨注意力,通过交换两种模态的查询 Q Q Q增强模态间交互。这促进空间交互,最大化利用多模态设置下的互补属性:
{ Q v i , K v i , V v i } = P r o j v i ( G N ( F v i i ) ) (6) \left\{Q_{vi}, K_{vi}, V_{vi}\right\}=Proj_{vi}\left(GN\left(F_{vi}^{i}\right)\right) \tag{6} {Qvi,Kvi,Vvi}=Projvi(GN(Fvii))(6)
{ Q i r , K i r , V i r } = P r o j i r ( G N ( F i r i ) ) (7) \left\{ Q_{ir},K_{ir},V_{ir}\right\} =Proj_{ir}(GN(F_{ir}^{i})) \tag{7} {Qir,Kir,Vir}=Projir(GN(Firi))(7)
F v i ′ ′ = C r o s s A t t n ( Q i r , K v i , V v i ) (8) F_{vi}''=CrossAttn(Q_{ir},K_{vi},V_{vi}) \tag{8} Fvi′′=CrossAttn(Qir,Kvi,Vvi)(8)
F i r ′ ′ = C r o s s A t t n ( Q v i , K i r , V i r ) (9) F_{ir}''=CrossAttn(Q_{vi}, K_{ir}, V_{ir}) \tag{9} Fir′′=CrossAttn(Qvi,Kir,Vir)(9)
其中 G N ( ⋅ ) GN(·) GN(⋅)表示组归一化, P r o j ( ⋅ ) Proj(·) Proj(⋅)表示投影操作,将输入特征转换为适合注意力计算的嵌入空间, C r o s s A t t n ( ⋅ ) CrossAttn(·) CrossAttn(⋅)表示跨注意力机制,实现不同输入源间的特征交互与选择性强调。
接下来,在CSAF模块中,输入特征图 F v i i F_{vi}^{i} Fvii与 F i r i F_{ir}^{i} Firi首先经过无参数实例归一化(IN),消除模态特有幅值差异,为语义调制建立通用统计空间。
受空间自适应归一化启发,预训练视觉模型生成的语义先验 F v i c d F_{vi}^{cd} Fvicd与 F i r c d F_{ir}^{cd} Fircd首先通过双线性插值上采样,与主干特征图空间分辨率匹配,建立每个像素与其对齐先验向量的一一对应。
随后,如公式(10)与(11)所示,两种语义先验依次通过两层卷积,生成空间‑通道缩放因子 γ \gamma γ与平移偏移 β \beta β。
γ \gamma γ张量在空间位置与通道间动态调整特征幅值,数值越大则语义关键区域增强、非重要区域抑制,有效充当自适应融合权重。同时, β \beta β提供像素级偏移校准,优化细粒度语义细节。
这些空间自适应参数增强低对比度红外目标的边缘纹理,同时抑制可见光分支的高频噪声,使显著目标更突出。
最后,如公式(12)所示,归一化特征图首先使用这些调制张量执行逐像素仿射变换,自适应放大关键信息(如热显著目标与纹理细节)并抑制无关分量。
变换后的特征图沿通道维度拼接,送入卷积层生成融合特征 F i F_{i} Fi。最终, F i F_{i} Fi通过Proj变换得到查询、键、值矩阵,随后经自注意力得到精炼输出特征 F i ′ F_{i}' Fi′。整个过程可表示为:
{ γ v i , γ i r } = C o n v γ ( C o n v ( { F v i c d , F i r c d } ) ) (10) \left\{\gamma_{vi}, \gamma_{ir}\right\}=Conv_{\gamma}\left(Conv\left(\left\{F_{vi}^{cd}, F_{ir}^{cd}\right\}\right)\right) \tag{10} {γvi,γir}=Convγ(Conv({Fvicd,Fircd}))(10)
{ β v i , β i r } = C o n v β ( C o n v ( { F v i c d , F i r c d } ) ) (11) \left\{\beta_{vi}, \beta_{ir}\right\}=Conv_{\beta}\left(Conv\left(\left\{F_{vi}^{cd}, F_{ir}^{cd}\right\}\right)\right) \tag{11} {βvi,βir}=Convβ(Conv({Fvicd,Fircd}))(11)
F i = C o n v ( C ( γ v i ⊗ I N ( F v i i ) ⊕ β v i , γ i r ⊗ I N ( F i r ′ ′ ) ⊕ β i r ) ) (12) \begin{aligned} F_{i}=Conv\big( C\big( \gamma_{vi}\otimes IN(F_{vi}^{i})\oplus \beta_{vi}, \\ \gamma_{ir}\otimes IN(F_{ir}'')\oplus \beta_{ir}\big) \big) \end{aligned} \tag{12} Fi=Conv(C(γvi⊗IN(Fvii)⊕βvi,γir⊗IN(Fir′′)⊕βir))(12)
{ Q i , K i , V i } = P r o j ( F i ) (13) \left\{Q_{i}, K_{i}, V_{i}\right\}=Proj\left(F_{i}\right) \tag{13} {Qi,Ki,Vi}=Proj(Fi)(13)
F i ′ = S e l f A t t n ( Q i , K i , V i ) (14) F_{i}'=SelfAttn(Q_{i},K_{i},V_{i}) \tag{14} Fi′=SelfAttn(Qi,Ki,Vi)(14)
其中 C ( ⋅ ) C(·) C(⋅)表示沿通道维度的拼接操作。值得注意的是,当 F v i i F_{vi}^{i} Fvii与 F i r i F_{ir}^{i} Firi直接通过CSAF模块融合时( i = 1 , 2 , 3 i=1,2,3 i=1,2,3),输入为 F v i i F_{vi}^{i} Fvii与 F i r i F_{ir}^{i} Firi,输出为 F i F^{i} Fi,如图(3)所示。
随后,PSAF的输出 F i ′ F_{i}' Fi′由基于Transformer模块的特征解码器处理。所得特征与上一层CSAF输出的特征图 F i − 1 F_{i-1} Fi−1拼接,随后卷积。该序列重复多次,最终整合得到融合视觉特征 F f u F_{fu} Ffu:
F f u = { C o n v ( C ( T f ( F i ′ ) , F i − 1 ) ) } r (15) F_{fu}=\left\{ Conv\left(C\left(T_{f}\left(F_{i}'\right), F_{i-1}\right)\right)\right\}_{r} \tag{15} Ffu={Conv(C(Tf(Fi′),Fi−1))}r(15)
其中 T f T_{f} Tf表示特征解码器, C ( ⋅ ) C(·) C(⋅)表示沿通道维度拼接, { ⋅ } r \{·\}_{r} {⋅}r表示多级重复。注意,经 T f T_{f} Tf处理的特征需要上采样,以匹配特征提取阶段的下采样。
视觉特征解码器
最终,融合视觉特征通过Restormer解码器,生成融合图像 I f I_{f} If,即SPGFusion的最终输出。
4.3 损失函数
在SPGFusion框架中,本文使用源可见光图像 I v i I_{vi} Ivi、红外图像 I i r I_{ir} Iir与融合结果 I f I_{f} If作为融合损失函数 L f \mathcal{L}_{f} Lf的输入。该损失包含多个分量:结构相似性(SSIM)损失、最大梯度损失、强度损失与色彩一致性损失。各损失分量详述如下。
结构相似性损失
采用结构相似性损失衡量融合图像与原始源图像的相似度,确保融合图像保留输入图像的结构完整性。表达式为:
L s = ( 1 − S S I M ( I f , I v i ) ) + ( 1 − S S I M ( I f , I i r ) ) (16) \mathcal{L}_{s}=(1-SSIM(I_{f},I_{vi}))+(1-SSIM(I_{f},I_{ir})) \tag{16} Ls=(1−SSIM(If,Ivi))+(1−SSIM(If,Iir))(16)
色彩损失
色彩损失确保融合图像与源可见光图像保持色彩信息一致。这对保留融合图像色彩的自然性与准确性至关重要,尤其在色彩丰富场景中。表达式为:
L c = 1 H W ∥ T C b C r ( I f ) − T C b C r ( I v i ) ∥ 1 (17) \mathcal{L}_{c}=\frac{1}{H W}\left\| \mathcal{T}_{CbCr}\left(I_{f}\right)-\mathcal{T}_{CbCr}\left(I_{vi}\right)\right\| _{1} \tag{17} Lc=HW1∥TCbCr(If)−TCbCr(Ivi)∥1(17)
其中 T C b C r \mathcal{T}_{CbCr} TCbCr表示RGB到CbCr的转换函数。本文提出的色彩损失仅约束可见光图像的Cb与Cr分量,通过不受约束的亮度(Y)通道保留红外强度信息。
尽管红外图像无色彩信息,色彩损失在以往融合研究中并不常见,但近期工作[21]表明,该损失不仅保留红外的亮度贡献,还能有效抑制红外对可见光光谱的色彩干扰。该损失最终从色彩角度提升视觉感知,同时保持热保真度。
强度损失
该损失衡量融合图像与源图像间的像素级差异。因此,强度损失定义为:
L i = 1 H W ∥ I f − max ( I v i , I i r ) ∥ 1 (18) \mathcal{L}_{i}=\frac{1}{H W}\left\| I_{f}-\max\left(I_{vi}, I_{ir}\right)\right\| _{1} \tag{18} Li=HW1∥If−max(Ivi,Iir)∥1(18)
梯度损失
梯度损失旨在保留两幅源图像的最大边缘,确保融合图像包含丰富纹理信息。表达式为:
L g = 1 H W ∥ ∇ I f − max ( ∇ I v i , ∇ I i r ) ∥ 1 (19) \mathcal{L}_{g}=\frac{1}{H W}\left\| \nabla I_{f}-\max\left(\nabla I_{vi}, \nabla I_{ir}\right)\right\| _{1} \tag{19} Lg=HW1∥∇If−max(∇Ivi,∇Iir)∥1(19)
总损失
整体损失函数为上述损失项的加权和,公式为:
L f = α s ⋅ L s + α c ⋅ L c + α i ⋅ L i + α g ⋅ L g (20) \mathcal{L}_{f}=\alpha_{s} \cdot \mathcal{L}_{s}+\alpha_{c} \cdot \mathcal{L}_{c}+\alpha_{i} \cdot \mathcal{L}_{i}+\alpha_{g} \cdot \mathcal{L}_{g} \tag{20} Lf=αs⋅Ls+αc⋅Lc+αi⋅Li+αg⋅Lg(20)
其中 α s \alpha_{s} αs、 α c \alpha_{c} αc、 α i \alpha_{i} αi与 α g \alpha_{g} αg为控制损失函数权衡的超参数。
5 实验分析
4 实验验证
本节首先概述实现细节与相关配置,随后从定性与定量角度,在多个数据集上对比各算法的融合性能。接着开展任务驱动评估,衡量不同融合方法支撑高级视觉任务的效果。最后开展一系列消融实验,分析各组件的贡献。
4.1 配置与实现细节
数据集
为验证泛化性,本文在广泛使用的公开红外‑可见光图像融合数据集上全面评估SPGFusion的融合性能,包括:
- M 3 F D M^{3}FD M3FD(包含白天、阴天、夜晚及遮挡、烟雾、强光照等复杂场景)
- MSRS(聚焦复杂城市交通场景)
- LLVIP(以低光道路环境为主)
- FMB(包含14类语义目标、多样光照条件)
此外,在MSRS与FMB数据集上评估SPGFusion在语义分割任务中的性能,在LLVIP数据集上测试目标检测任务性能。这些数据集的测试图像对数量分别为300、361、300、280。MSRS数据集包含1083对图像用于模型训练。
为进一步探索SPGFusion在红外‑可见光融合之外的泛化能力,在MFI‑WHU多聚焦数据集上评估,该数据集包含120幅图像,验证其处理多聚焦图像融合任务的潜力。
实现细节
SPGFusion基于PyTorch框架训练120个epoch。采用四级结构相同的编码器处理两路输入图像,每级包含两个Transformer模块,注意力头数递增(1/2/4/8)。解码器包含两个Restormer模块,重建最终融合图像。
控制各损失项权衡的超参数经验性设置为: α s = 1 \alpha_{s}=1 αs=1, α c = 12 \alpha_{c}=12 αc=12, α i = 4 \alpha_{i}=4 αi=4, α g = 10 \alpha_{g}=10 αg=10。初始学习率设为0.0001,批次大小为4,使用AdamW优化器。源图像裁剪为224×224。
CLIP与DINO均使用冻结的ViT‑B/16模型,训练与推理阶段均剔除最后一个注意力层的CLS token后使用其value嵌入。模型分别按照OpenCLIP与DINO方法预训练。
所有实验在NVIDIA A800 PCIe GPU(80GB显存)上运行,训练时显存消耗约22.9GB。
评估指标
使用6种统计评估指标定量评估融合性能,包括熵(EN)、空间频率(SF)、平均梯度(AG)、标准差(SD)、视觉信息保真度(VIF)与相关系数(CC)。指标值越高表示融合效果越好。
对比方法
将本文方法与多种当前最优方法对比。图像融合与高级任务实验对比TarDAL、DATFuse、SegMiF、CDDFuse、PSFusion、SHIP、DIFF‑IF、MRFS、FILM、Text‑IF、SAGE、LFDTFuse。
值得注意的是,由于FILM缺少LLVIP与FMB的文本数据集,为保持一致性,在无法直接对比FILM的实验中选用PSFusion作为替代基线。多聚焦融合对比U2Fusion、YDTR、SwinFusion。
4.2 融合定量对比
在四个数据集上使用六种指标的定量结果如图8–11所示。在 M 3 F D M^{3}FD M3FD、LLVIP、FMB数据集上,本文方法在全部六项指标上均表现最优,尤其在SF、AG、SD、VIF上优势显著。在MSRS数据集上,本文方法在六项指标中的五项上同样最优。
SD指标的优异结果表明本文输出对比度高,视觉效果好。SF与AG指标的突出表现说明融合结果包含丰富纹理细节。此外,EN与VIF的良好结果表明融合图像信息充足、保留源图像结构完整性,且更符合人类视觉系统。
CC指标最优意味着融合图像与源图像相关性最高。从指标角度,本文方法在多指标上的优势体现其图像融合的综合性能。从数据集角度,方法在多数据集上的优越性说明其在多样场景类型与数据分布上的泛化能力。
4.3 高级任务性能
4.3.1 分割性能
与分割网络联合训练的融合方法展现出优异的分割性能[12]。但该方法将分割视为子任务,直接从源图像特征得到分割结果。相比之下,本文工作聚焦融合图像的分割效果。
为公平评估所有模型生成的融合图像的分割性能,首先使用所有评估融合方法生成MSRS与FMB数据集训练集的融合图像。随后在这些融合图像训练集上,以相同训练配置训练11种分割模型[71]。
为客观对比,本文提供可视化结果(图12)。第一组分割结果中,本文方法保留最多停车让行标志信息,同时保留行人腿部精细轮廓。其他方法仅保留有限停车让行信息与行人粗略轮廓。
第二组分割结果中,仅本文方法有效分割地面人行道,边缘轮廓效果最优。
此外,定量结果如表1、表2所示。受篇幅限制,仅展示MSRS与FMB数据集上八个类别的交并比(IoU)。最终平均交并比(mIoU)使用所有类别的IoU计算。
可见SPGFusion在两个数据集上均取得最高mIoU。尽管与次优方法的整体提升仅约1 mIoU,但该差距主要受限于现有红外‑可见光数据集的分割训练数据规模与多样性,导致分割网络无法完全捕捉融合质量差异带来的性能变化。这使得观察到的分割性能提升合理。
值得注意的是,本文融合结果在几乎所有语义类别上均取得最高IoU,且作为无标注方法,SPGFusion与基于标注的TarDAL、SegMiF、MRFS相比仍具竞争力。
同时,SPGFusion在减速带、电线杆等难分割目标上表现优异,这些目标的精准分割对下游感知任务至关重要。这主要得益于基于PVM的全局‑局部语义先验。这些先验引导语义自适应融合网络关注人工标注忽略的关键语义信息。
4.3.2 检测性能
与分割评估类似,首先使用多种融合方法在LLVIP数据集上生成融合结果。随后使用这些融合图像微调YOLOv5[72]检测器。定量实验结果所示。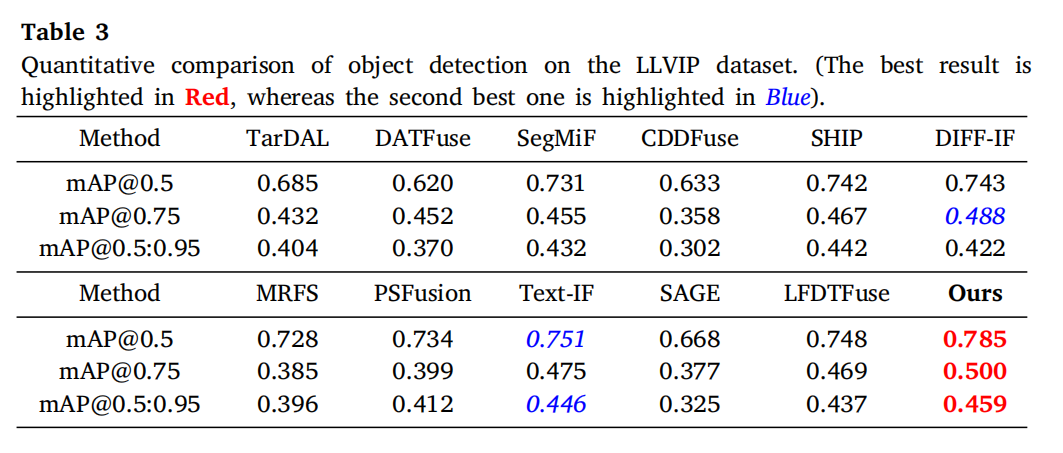
定量对比中,SPGFusion取得最优检测性能。
总体而言,语义分割与目标检测实验证实,本文方法SPGFusion不仅保持优异视觉质量,还展现出更优的语义性能。这种双重优势凸显其在其他高级语义任务应用中的潜在价值。
4.5 消融实验
为验证本文方法的有效性,在LLVIP数据集上开展五组消融实验:
- 模型I:移除所有语义先验及对应C/PSAF模块
- 模型II:将所有CSAF替换为传统注意力机制
- 模型III:将PSAF替换为CSAF(因PSAF中跨注意力机制带来高内存消耗,无法执行反向替换)
- 模型IV:移除DINO
- 模型V:移除CLIP
图15与表5展示这些组件对图像融合性能的影响。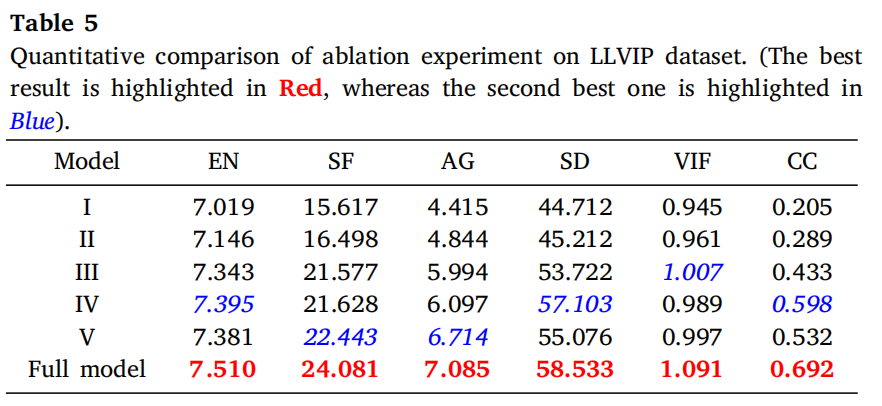
在模型I–III对比实验中,移除全局与局部语义先验并剔除本文提出的语义自适应融合网络,导致融合质量显著下降,可视化效果变差、定量指标大幅降低。该结果表明仅依靠低级特征不足以捕捉关键语义线索,最终降低整体融合性能。
此外,将C/PSAF模块替换为传统注意力机制无法充分利用现有语义先验实现有效特征对齐与整合,凸显本文语义自适应融合网络在注入更深层语义信息中的重要性。
此外,深度特征融合网络中缺少跨注意力机制也限制模型整体效果。如图15、表5所示,模型IV中移除DINO的局部聚类能力,使模型在提取细粒度纹理时更易受红外干扰信息影响。
因此,行人(红框)与文字区域(绿框)的纹理细节恶化,局部特征指标(如SF、AG)明显下降。尽管模型V可部分保留局部细节,但缺少CLIP提供的全局语义对齐与上下文理解。
结果导致融合图像整体对比度降低,像素强度欠佳、EN得分下降,共同表明信息总量减少。总体而言,本文方法在定性与定量评估上均超越所有消融变体,验证其有效性。
6 个人声明
本文为作者对原论文的学习笔记与心得分享,受个人学识与理解所限,文中对论文内容的解读或有不够周全之处,一切以原论文正式表述为准。本文仅用于学术交流与传播,内容均由作者独立整理完成,不代表本公众号立场。如文中所涉文字、图片等内容存在版权争议,请及时与作者联系,作者将在第一时间核实并妥善处理。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)