进程的控制
本篇目标:
• 学习进程创建(fork)
• 学习到进程终止,认识$?
一.进程创建
1.再识fork函数
从我们之前学的进程中,我们已经知道,fork函数的作用是从已存在进程中创建⼀个新进程,新进程为子进程,而原进程为父进程,同时fork函数会有两个返回值,子进程中返回 0 ,父进程返回子进程 id ,出错则返回-1。
我之前已经讲了:1.为什么要给子进程返回 0 ,父进程返回子进程 pid?
2.为什么⼀个函数 fork 会有两个返回值?
3.为什么⼀个 id 即等于 0 ,又大于 0
进程调用fork,当控制转移到内核中的 fork 代码后,内核做:
• 分配新的内存块和内核数据结构给子进程
• 将父进程部分数据结构内容拷贝至子进程
• 为子进程创建虚拟地址空间和页表,与父进程共享物理内存
相当于子进程有自己的pid,task_struct,mm_struct,虚拟内存空间,页表等内容,与父进程是相互独立的。
2.写时拷贝
提前说明一些东西:
- 父进程创建子进程前,其可写数据区(数据段、堆、栈)对应的页表项 PTE,是可读可写权限;
- fork 创建子进程后,父子进程中,这些可写数据区对应的所有页表项 PTE,都会被内核统一临时标记为只读权限。
如图所示:
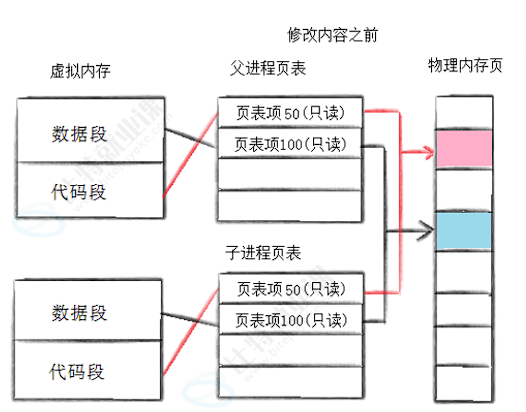
把页表项修改为只读的核心目的也是为了防止父子进程直接修改共享内存,破坏进程间相互独立。
通常,父子代码共享,父子再不写⼊时,数据也是共享的,当任意一方试图写入,便以写时拷贝的方式各自⼀份副本。具体见下图:
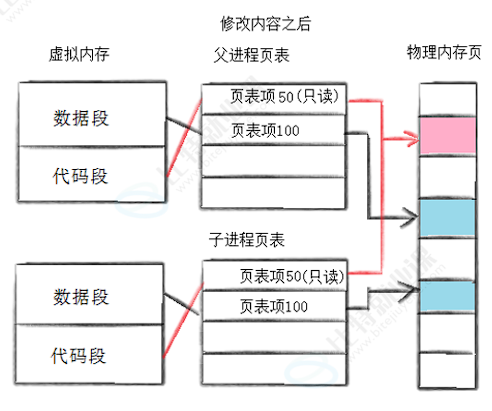
也就是说当子进程想要修改某个数据时,系统会触发写时拷贝机制,为该数据开辟专属的独立内存,让子进程在这块新内存上完成数据修改,但是对于未被修改的其他数据,父子进程仍然保持共享状态,下面举个例子:
- 父进程有一个全局变量
gval,存在物理内存中。 - 父进程 fork 出子进程后,父子的虚拟地址空间里都有 gval。
- 一开始,父子页表中 gval 的虚拟地址,都指向同一块物理内存里的 gval。
- 当子进程尝试修改
gval时,会触发写时复制(COW)。 - 内核会为子进程在物理内存中开辟一块新空间,复制原来的 gval。
- 之后,子进程的页表指向新物理页,父进程仍然指向原来的物理页。
- 所以父子进程的 gval 彻底独立,修改互不影响。
注意:此时如果没有其他的子进程,那么父进程的gval是可读可写的,但是如果还有其他的子进程,那么父进程的gval任然是只读的吧,而我上面举的所有的例子都是只有一个父进程与一个子进程
这时可能就会有人为什么要有写时拷贝呢?为什么子进程不直接拷贝父进程的数据区,而代码区是只读的,可以共享?
其实答案也很简单:首先绝大多数子进程根本用不上父进程的数据,直接拷贝不是会造成空间浪费,数据重复吗?而且拷贝也是要时间的,这也会浪费大量的时间。
结论:写时拷贝是为了减少空间浪费,减少创建时间。
二.进程终止
1.基本概念
进程终止的本质是释放系统资源,就是释放进程申请的相关内核数据结构和对应的数据和代码。
我们要知道的是,父进程创建子进程肯定是有一定的目的的,所以一般情况下,子进程结束时,父进程要拿到子进程的执行结果,而进程的推出场景分为以下几个:
• 代码运行完毕,结果正确
例如这个代码:
#include<stdio.h>
int main()
{
printf("Hello World\n");
return 0;
}这个程序返回值为0时,就代表着得到了我们预期的结果。
• 代码运行完毕,结果不正确
例如这个代码:
#include<stdio.h>
int main()
{
FILE*fp=fopen("text.log","r");
if(fp==NULL) return 1;
//其他的内容
...
fclose(fp);
return 0;
}这个程序返回值为1时,就代表着运行成功,但是没有得到了我们预期的结果。
• 代码异常终止
这里先提一下,进程一般出现异常,一般是进程收到了信号
其实此时我们就可以明白,main函数的返回值就代表程序的执行情况,return 0表示成功,而返回的是其他的值就代表着不同的出错原因。
这里就可以输出一个结论:main 函数的返回值,就是进程退出码,这个退出码是写到我进程的task_struct内部的,我们可以通过echo $?来打印最近的一个进程的退出码,以上面的打开一个不存在的文件为例:
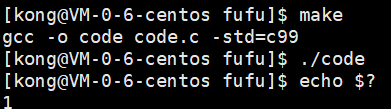 ,这个一就是退出码。
,这个一就是退出码。
不过我们自己设置的退出码比较难了解具体错误的原因是什么,只可以表示成功 or 失败,
其实真正的错误原因是存在 errno 里的,下面有一个代码演示所有的具体错误原因:
strerror () 就是把 errno 数字 → 翻译成人类能看懂的文字,如图所示:
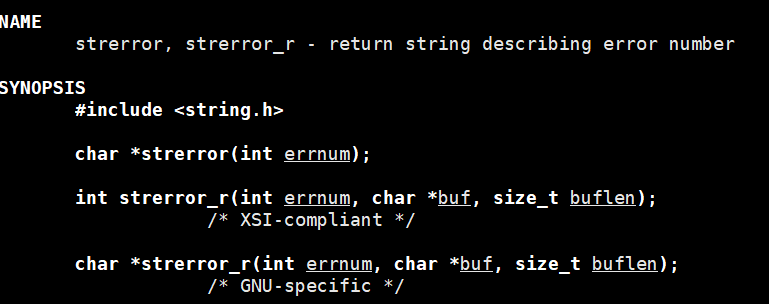
可以看出strerror(i)返回的是对错误码的描述
#include <stdio.h>
#include <string.h> // strerror
#include <errno.h>
// 大多数 Linux 系统错误码最多到 134
#define MAX_ERRNO 134
int main()
{
for (int i = 0; i < 135; i++)
{
printf("%d→%s\n", i, strerror(i));
}
return 0;
}输出结果: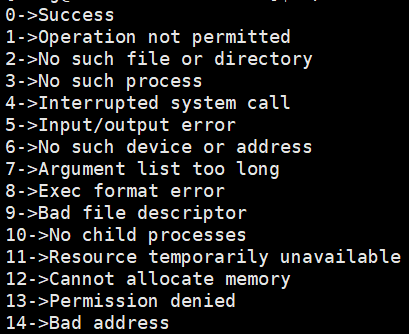
其实当我们自己操作时,就会发现有134个退出码,认识errno退出f码后,再回到之前的打开不存在的文件的代码,我们将return 1;修改为return errno;此时的输出结果:
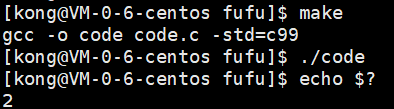
而这个2就代表着文件并不存在。
2.进程常见退出方法
2.1.从main返回
注意:main函数的返回值代表进程的结束,而其他函数的返回代表这个函数的调用结束
2.2.调用exit
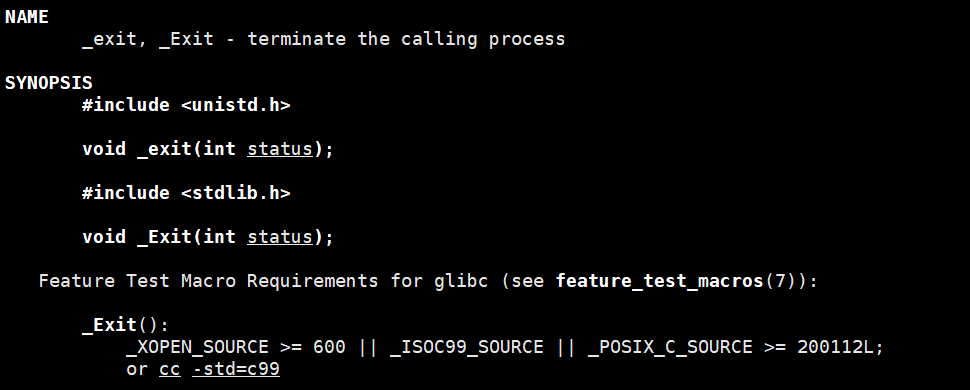
注意:exit (status) 里的 status = 进程退出码,与main函数里的返回值几乎一模一样
代码演示:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
void fun()
{
printf("fun begin\n");
exit(1);
printf("fun end\n");
}
int main()
{
fun();
printf("main\n");
return 0;
}输出结果: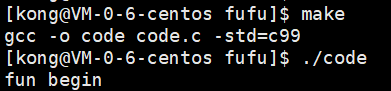
可以看出main函数里的printf与fun函数里的exit后面的printf都没有打印,仅打印了exit前面的printf的内容。
结论:任何地方调用exit,均表示该进程的结束,进程的退出码返回给父进程
2.3._exit函数
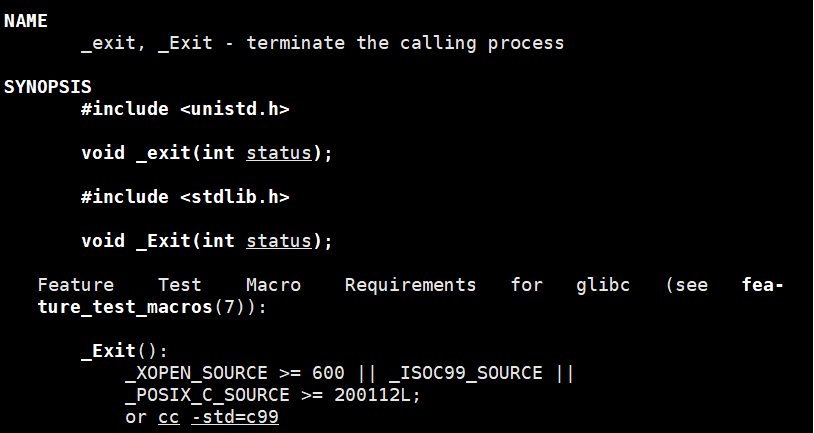
注意:_exit (status) 里的 status = 进程退出码
代码演示:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
void fun()
{
printf("fun begin\n");
_exit(1);
printf("fun end\n");
}
int main()
{
fun();
printf("main\n");
return 0;
}输出结果: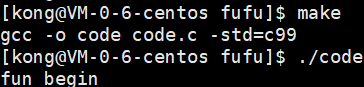
结论:任何地方调用_exit,均表示该进程的结束,进程的退出码返回给父进程
2.4.两个函数的区别
通过上面的代码结果,我们可以看出exit函数与_exit函数几乎一样,那是否两者有区别呢?
答案是有的!!!
代码演示:
#include<stdio.h>
#include<unistd.h>
#include<stdlib.h>
int main()
{
printf("hello world");
sleep(2);
exit(1);
}我们之前已经知道没有\n时,会先将打印出来的内容放到缓冲区里,而不是先打印内容,直到进程即将结束时,会自动刷新缓冲区,才打印内容。
输出结果: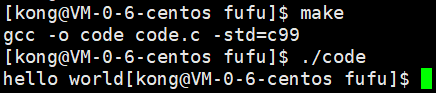
可以看出符合预期。
#include<stdio.h>
#include<unistd.h>
#incllude<stdlib.h>
int main()
{
printf("hello world");
sleep(2);
_exit(1);
}输出结果: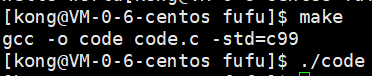
可是用_exit却发现我要打印的内容呢?
此时可以得出结论:
用exit函数退出进程时,会刷新缓冲区,用_exit函数退出进程时,不会刷新缓冲区。
其实这里还要补充一些内容:exit() 是 C 标准库函数;_exit() 才是 Linux / Unix 系统提供的系统调用,进程是由系统管理的,你一个库函数凭什么终止进程呢?所以应该是exit最后也会调用_exit,但在调用_exit之前,还做了其他工作。
这里还需抛出一些问题:我们之前说的缓冲区应该在哪里呢或者不应该在哪里呢?
答案是:我们之前说的缓冲区一定不是操作系统内部的缓冲区,而是库缓冲区,还是由C语言提供的缓冲区。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 14
14 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)