高阶编程能力又往上顶了一截:Claude Opus 4.7 发布后,Claude Code 也开始更像一套完整工作台
高阶编程能力又往上顶了一截:Claude Opus 4.7 发布后,Claude Code 也开始更像一套完整工作台

写在前面
Anthropic 刚刚发布了最新模型 Claude Opus 4.7。
这一版的重点,不只是常规意义上的“模型更强了”,而是它在高难度编程任务上的稳定性、长任务处理能力和自我校验能力都继续往前推了一步。对开发者来说,这意味着需要人工频繁盯着的地方,可能会比以前更少。
同一时间,Claude Code 这一侧也补上了几项很关键的能力:自动化流程、自动模式,以及更深入的代码审查命令。把这些更新连起来看,Anthropic 现在已经不只是想做一个更会答题的模型,而是在把 Claude 往更完整的任务执行系统上推。
Opus 4.7 先盯上的,是高难度编码任务里的“少监督”问题
Claude Opus 4.7 是 Anthropic 最新面向公众开放的 AI 模型,主打的还是高端软件开发能力。
这一版相较 Opus 4.6,在高级软件工程场景里又往上走了一截,尤其是在超高难度任务上的表现更明显。它现在更强调一件事:处理复杂、耗时长、步骤多的任务时,不只是把答案交出来,还会在输出前自己设计验证机制,先检查结果有没有跑偏。
这件事听起来像是“多做了一遍检查”,但对长链路任务非常关键。过去这类任务最大的问题,不是模型能不能做,而是中间一旦走偏,通常要到最后才暴露出来。现在 Opus 4.7 在这一步上更主动,意味着人工监督的压力会继续往下掉。
除了编码本身,这一版在视觉理解和审美判断上也被特别强调。换句话说,它不只是更会写代码,也更适合处理那些夹杂界面、截图、视觉元素的实际开发任务。
基准测试继续往上抬,但更值得看的还是“怎么变强的”
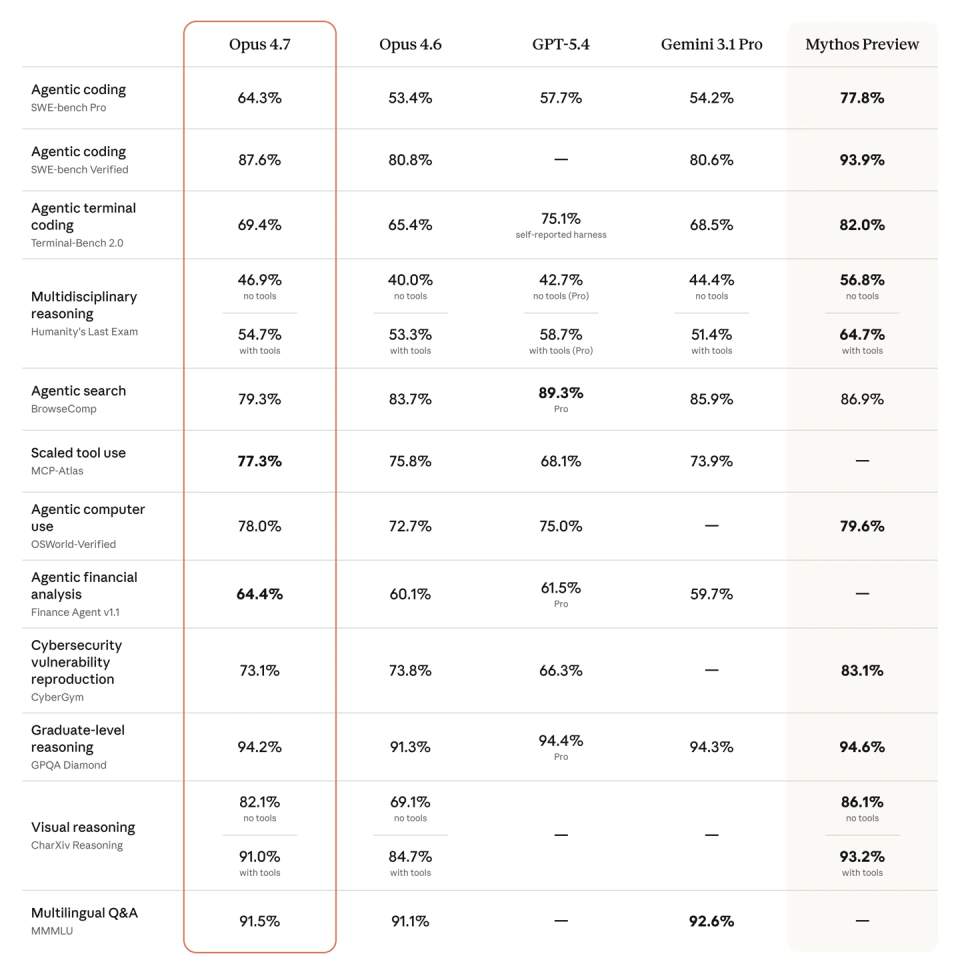
在智能体编码、计算机操作等多项应用场景的基准测试里,Opus 4.7 的表现继续往前走。
按照 Anthropic 给出的说法,它在多个测试中已经高于 Opus 4.6、GPT-5.4 和 Gemini 3.1 Pro,不过仍然低于还处在预览阶段的 Mythos Preview。这个结果本身说明两件事:一是 Opus 4.7 已经把公开可用模型的上限继续抬高了;二是 Anthropic 手里显然还有更激进但暂未全面放开的能力储备。
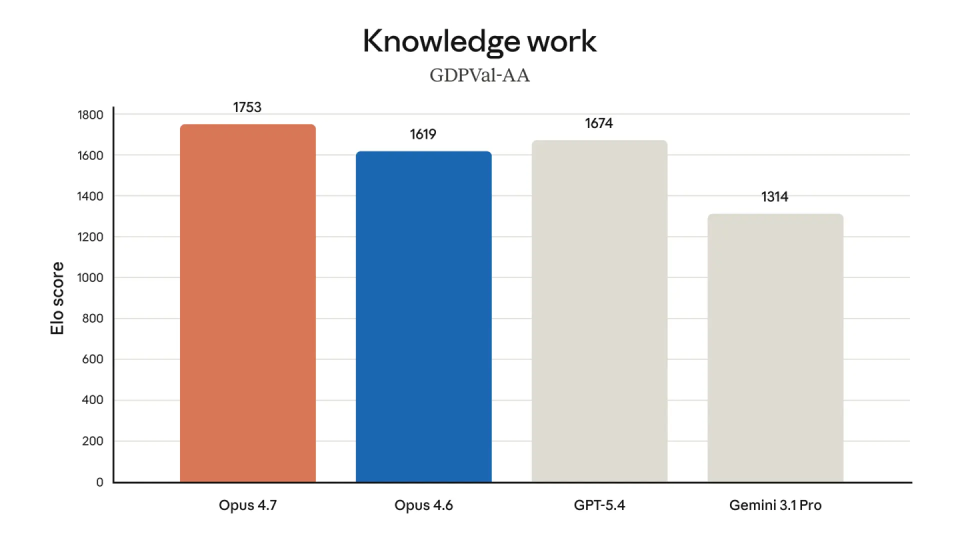
如果只看分数,结论当然是“更强了”;但真正更值得开发者关注的,是它提升的方向。Opus 4.7 不是简单把某一项 benchmark 再刷高一点,而是在指令理解、长任务稳定性、自我验证和实际工作流适配上一起补课。这种提升,往往比单个测试成绩更接近日常使用体验。
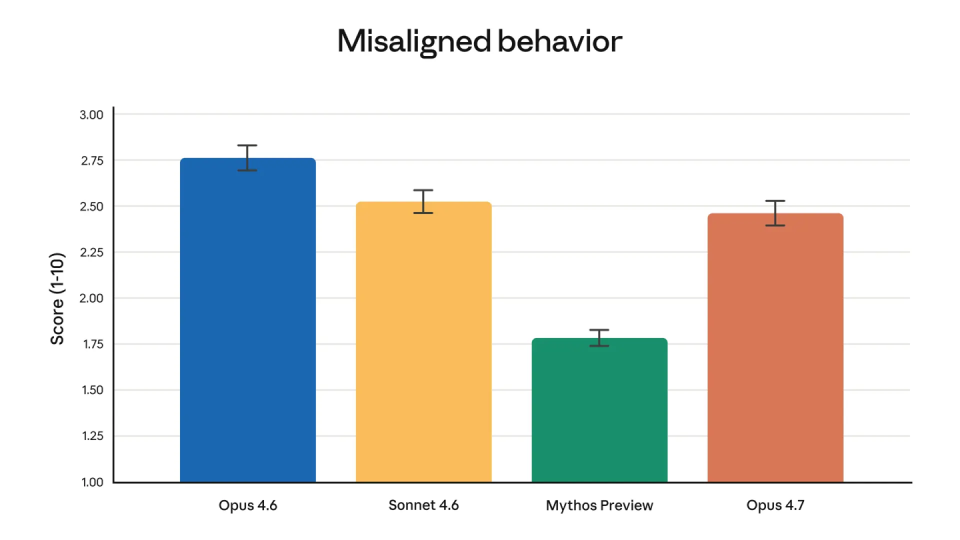
其他核心升级,指向的还是“更适合真实工作”
除了编程能力本身,Opus 4.7 这次还把几个开发者会频繁碰到的能力继续补强了。
一块是指令遵循。模型对要求的理解更稳,执行时不那么容易在细节上跑偏。
一块是多模态。结合前面提到的视觉理解增强,它处理截图、界面、图文混排内容这类任务时会更从容。
还有一块是记忆和实践任务表现。对于长上下文、多步骤、需要持续保持状态的工作,Opus 4.7 现在更像是在朝着“能持续把一件事做完”这个目标推进,而不是只擅长回答某一个局部问题。
这几个点拆开看都不算花哨,但放在一起,其实很像是在补一套长期执行系统的地基。
Anthropic 还想把 Opus 的更新节奏拉快
这次还有一个很值得注意的信号:Anthropic 提到,Claude Opus 系列后续可能按每两个月一次的节奏持续更新。
如果这个频率真的稳定下来,开发者面对的就不再是“隔很久来一代大版本”,而是更连续、更密集的能力迭代。对产品团队和开发团队来说,这会带来一个很现实的变化:你不仅要跟上模型本身的能力变化,还得持续调整工作流、提示词和接入方式。
AI 编程工具的使用习惯,也会越来越像在跟进一套快速更新的基础设施,而不只是偶尔体验一个新功能。
新 tokenizer 带来更完整的理解,也带来了新的成本变量
Opus 4.7 这次还换上了新版 tokenizer。
变化在于,同样的输入内容,分出来的 token 数量可能会和以前不一样。对用户来说,这带来的是两面性:一面是模型对信息的切分和理解可能更完整,尤其在高算力模式下,“思考”会更充分;另一面则是成本和计费习惯需要重新关注。
如果你的工作流本来就对 token 用量比较敏感,这轮切换最好还是盯一下实际消耗。模型更仔细,通常是好事,但更仔细往往也意味着预算和吞吐要重新平衡。
Claude Code 这一刀补得很准:开始从工具变成工作台
这次更新里,另一个开发者很难忽视的部分,是 Claude Code 的功能增强。
首先是它开始具备代用户操作 Mac 的能力。接着,在改版后的 Claude Code 里,Anthropic 又加入了自动化流程 routines,让一些重复、规律、可触发的任务可以更自然地交给 Claude 持续执行。
同时还提供了“自动模式”,作为跳过权限操作的更安全替代方案。换句话说,它不是单纯把限制拿掉,而是在尽量维持安全边界的前提下,把长任务和连续操作变得更顺畅。
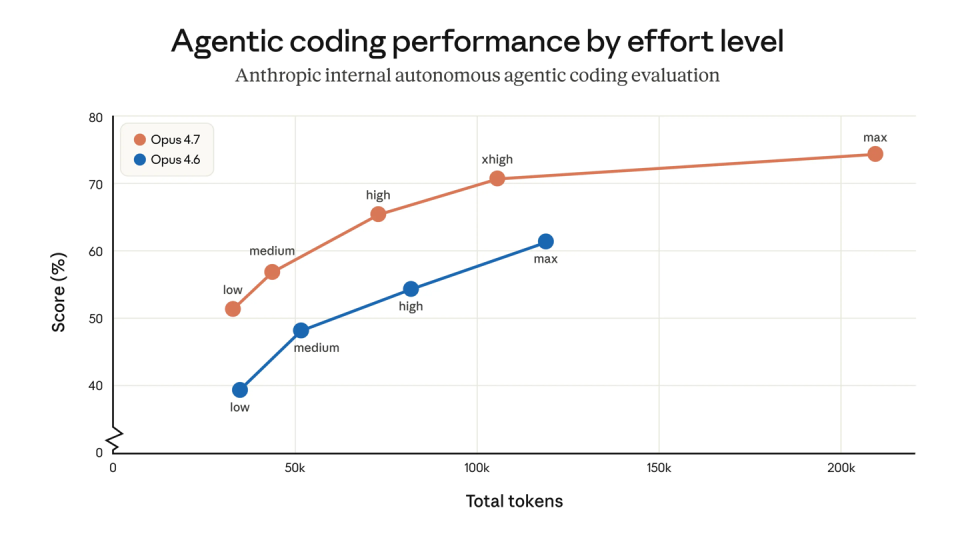
另外,Claude Code 还新增了 /ultrareview 指令,专门跑一轮更深入的代码审查。它想解决的不是“帮你简单扫一眼 diff”,而是尽可能把一位认真 reviewer 会挑出来的问题提前找出来。
把 Mac 操作、routines、自动模式和 /ultrareview 放在一起看,方向已经很清楚了:Claude Code 正在从一个会写代码、会解释错误的工具,继续往任务执行平台靠近。
现在该怎么理解 Claude Code
如果现在还把 Claude Code 理解成“终端里一个会聊天的 Claude”,这个理解已经有点不够了。
更准确地说,它正在变成一个围绕任务执行展开的自主编程 Agent。它不只是补全代码、解释报错,还能读仓库、搜文件、改代码、执行命令、做代码审查,并把这些能力进一步延伸到自动化流程和更长链路的任务处理中。
常见订阅里,Claude Pro 一般是 20 美元/月,Max 会更高;而 Opus 4.7 的 API 定价,这次仍然维持在每百万 token 输入 5 美元、输出 25 美元。
不过说实话,官方订阅对国内用户不太友好——需要海外信用卡,网络环境也得折腾。如果嫌麻烦想找个更省事的渠道,可以看看 Code80,真实订阅帐号转 API,换个 endpoint 就能直接用,体验跟官方一样。详情可以到官网了解:code.ai80.vip
常见问题
1. Claude Opus 4.7 这次最核心的升级是什么?
核心不是单一 benchmark 又涨了多少,而是它在高难度编程任务里的稳定性、自我验证能力和少人工监督方向上继续往前推了一步。
2. 为什么这次一直强调“自我验证”?
因为长任务最怕中间某一步悄悄跑偏,最后才发现结果不对。模型如果能先自己检查、自己修正,就能减少人工反复盯流程的成本。
3. 新 tokenizer 会带来什么影响?
主要是 token 切分方式和消耗习惯可能变化。好处是理解更完整、思考更充分,代价是部分工作流的成本和预算可能要重新评估。
4. Claude Code 这次新增的 routines 更像什么?
更像把一些重复、规律、可触发的开发任务交给 Claude 在后台持续执行,让它不只是回答问题,而是真的参与流程。
5. /ultrareview 是做什么的?
它是一条更深入的代码审查命令,目标是尽量把 reviewer 级别会发现的问题提前找出来,而不是只做一轮浅层 diff 浏览。
6. 国内开发者如果想更方便地使用 Claude 怎么办?
如果走官方路线,通常要处理支付、账号和网络环境这些现实问题。国内用户可以通过 Code80 更方便地使用。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)