DepthVLA:赋予机器人精确空间感知的视觉-语言-动作模型
0. 引言
在过去几年中,视觉-语言-动作(Vision-Language-Action, VLA)模型在机器人操作领域取得了令人瞩目的成就。这些模型建立在大规模预训练的视觉-语言模型(VLM)基础之上,继承了网络数据中蕴含的丰富语义知识,能够理解自然语言指令并执行相应的操作任务。从理论上讲,这种语言理解与视觉感知的结合应该能够让机器人完成各种复杂的操作。然而,在实际应用中,研究者们发现了一个根本性的问题:现有的VLA模型在需要精确空间推理的任务上表现不佳。当机器人需要抓取细小物体、执行精确定位操作或在复杂环境中避免碰撞时,这些基于语言-视觉的模型往往会失败。这个问题的根源在于,虽然VLM擅长理解语义内容和图像中的高级特征,但对于物体的三维形状、空间关系和精细几何结构的感知能力存在天生的缺陷。换句话说,VLM看到的是"是什么",而不是"在哪里"以及"有多远"。
1. 现有方案的局限性与挑战
为了弥补这一缺陷,前期的研究工作采取了不同的策略。一种方案是依赖大规模的机器人操作数据进行预训练,试图通过数据和计算的堆砌来让VLM间接学习三维空间关系。但这种方法存在显著的问题:首先,获取大规模高质量的机器人操作数据成本极高,这限制了模型的可扩展性;其次,即使经过大量操作数据的预训练,模型仍然无法稳定地实现精确的空间理解。另一种尝试是直接将额外的3D传感器信息(如LiDAR或RGB-D相机)输入到VLA模型中。然而,这种方法降低了模型在不同机器人平台间的可迁移性,因为不同平台的传感器配置差异很大。近期,一些工作开始探索使用链式思维(Chain-of-Thought)推理来自动回归地生成空间token,但这导致了严重的推理延迟问题——需要生成数百个spatial token才能进行动作预测,这在实时机器人控制中是不可接受的。
在这样的背景下,清华大学和Galaxea AI的研究团队提出了一个新的思路:与其尝试从有限的机器人数据中学习空间知识,不如直接利用近年来在3D视觉领域取得的突破。这正是DepthVLA模型的核心创新所在。
2. DepthVLA的核心设计理念
DepthVLA采用了一种优雅而有效的架构设计——混合Transformer(Mixture-of-Transformers, MoT)框架,该框架集成了三个专家模块,每个模块各司其职。这个设计的妙处在于,它不是简单地堆砌不同的模块,而是通过精心设计的注意力机制,让各个专家既能独立发挥作用,又能有效地共享信息。
视觉-语言模型(VLM)专家继续承担其传统的职责:将原始图像和自然语言指令编码为语义特征。这个专家负责理解"用户说的是什么",以及图像中出现了哪些物体和它们的语义类别。研究者们使用了Paligemma-3B作为VLM骨干,这个模型在泛化能力和指令理解上都有很好的表现。
深度预测专家是DepthVLA的创新核心。与传统方法不同的是,这个专家不仅仅输出一个深度图,而是在所有中间层都进行空间推理。深度专家采用编码器-解码器的架构,其中编码器基于DINOv2,能够捕获图像中的细粒度几何特征。更重要的是,这个深度专家的初始化使用了Depth Anything V2的预训练权重。
动作专家是最后一环,它整合来自VLM和深度专家的多模态特征,生成连续的机器人动作。这个专家采用了流匹配(Flow Matching)的方法来建模动作,相比于自回归生成,这种方法对于连续且多样化的动作轨迹有更好的建模能力。
# 伪代码:DepthVLA的多专家融合流程
class DepthVLA(nn.Module):
def __init__(self):
self.vlm_expert = PaliGemma3B() # 视觉-语言专家
self.depth_expert = DepthExpert() # 深度专家
self.action_expert = ActionExpert() # 动作专家
self.shared_attention_layers = SharedAttention() # 共享注意力层
def forward(self, image, instruction, proprioceptive_state):
# VLM处理图像和指令
vlm_features = self.vlm_expert(image, instruction)
# 深度专家处理图像并输出多层特征
depth_features = self.depth_expert(image)
depth_map = depth_features['final_output']
# 三个专家的token通过共享注意力层交互
# 块级掩码确保VLM和深度token只关注自身
# 而动作token可以关注所有信息流
fused_features = self.shared_attention_layers(
vlm_tokens=vlm_features,
depth_tokens=depth_features,
action_tokens=proprioceptive_state
)
# 动作专家基于融合特征生成动作
action = self.action_expert(fused_features)
return action, depth_map
3. 架构可视化
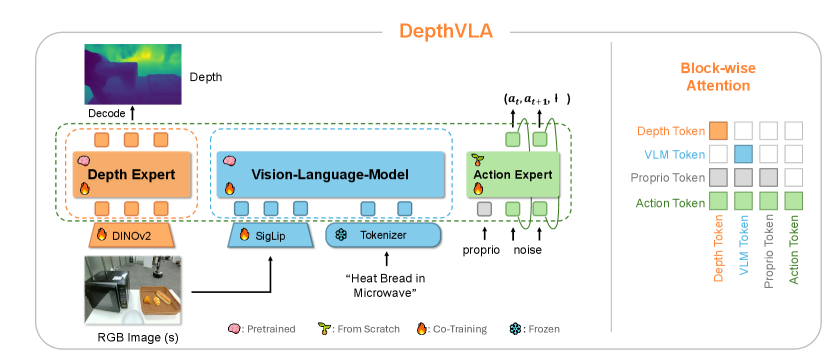
该图展示了三个专家模块如何通过共享注意力层(带有块级掩码)进行通信。RGB图像、语言指令和本体感觉状态作为输入,经过各专家处理后,在融合特征层统一,最终生成机器人动作。
3.1 注意力共享与模块独立的微妙平衡
DepthVLA的架构设计体现了一个关键的工程洞察:特征融合与模块独立性并非对立关系,而可以通过精巧的机制达到平衡。这个平衡通过"块级掩码"(Block-wise Masking)机制来实现。
在标准的多头自注意力机制中,所有token都可以相互关注。但在DepthVLA中,通过掩码限制了信息流向。具体地说,VLM的token只能关注VLM自身内的token;深度专家的token只能关注深度专家内部的token;而动作相关的token则可以关注所有信息流。这种设计的深层意义在于:它保护了VLM和深度模块在预训练阶段学到的知识不被破坏,同时又允许动作专家充分利用来自两个专家的信息做出决策。
3.2 块级掩码机制详解
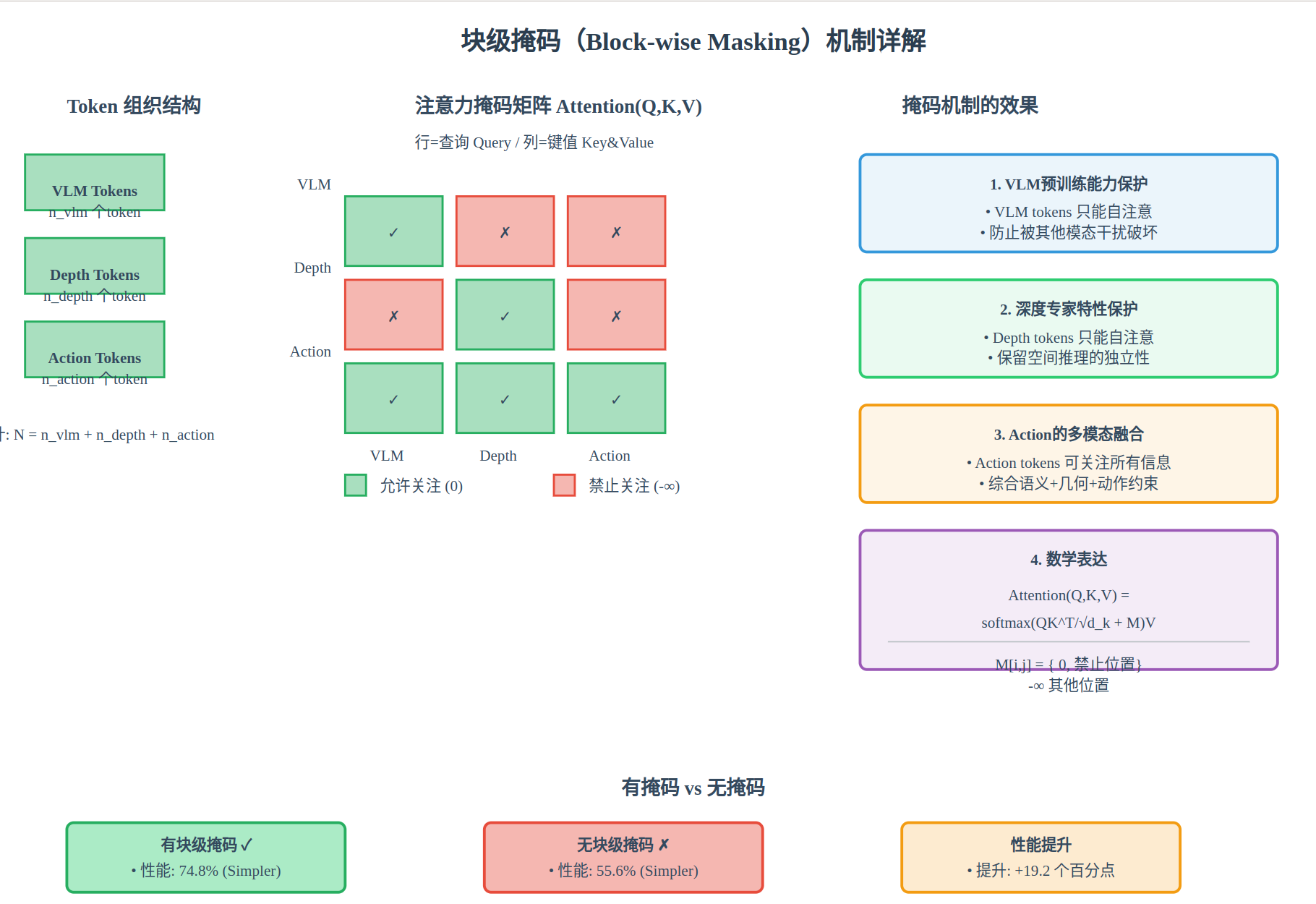
该图详细展示了注意力掩码矩阵的构造方式。注意力矩阵被分为9个子块,其中绿色区域(允许)表示该token可以关注对方,红色区域(禁止)表示禁止关注,这种设计确保了模块独立性和信息融合的完美平衡。
从数学角度看,掩码的应用通过以下方式进行:
MaskedAttention ( Q , K , V ) = softmax ( Q K T d k + M ) V \text{MaskedAttention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + M\right)V MaskedAttention(Q,K,V)=softmax(dkQKT+M)V
其中 M M M 是掩码矩阵,对于被禁止的连接位置设为 − ∞ -\infty −∞。这个简单的修改具有深远的影响,它在保持预训练能力的同时,创造了一个多模态融合的有效途径。消融实验表明,如果移除块级掩码(允许所有token相互关注),Simpler基准的性能从74.8%下降到55.6%,损失高达19.2个百分点,验证了这个设计的必要性。
# 块级掩码的实现示例
def create_block_mask(vlm_tokens, depth_tokens, action_tokens):
"""
创建块级掩码矩阵
- VLM tokens 只能自注意
- Depth tokens 只能自注意
- Action tokens 可以关注所有
"""
num_vlm = vlm_tokens.shape[1]
num_depth = depth_tokens.shape[1]
num_action = action_tokens.shape[1]
total_tokens = num_vlm + num_depth + num_action
# 初始化掩码矩阵(0表示允许,-inf表示禁止)
mask = torch.zeros(total_tokens, total_tokens)
# VLM tokens 自注意
mask[num_vlm:, :num_vlm] = float('-inf')
mask[:num_vlm, num_vlm:] = float('-inf')
# Depth tokens 自注意
mask[:num_vlm + num_depth, num_vlm:num_vlm + num_depth] = float('-inf')
mask[num_vlm + num_depth:, num_vlm:num_vlm + num_depth] = float('-inf')
# Action tokens 可以看到所有内容
# 保持对应位置为0
return mask
4. 深度专家:空间感知的基础
深度专家是DepthVLA模型中最具创新性的组件。它不仅仅是一个深度估计的黑盒子,而是一个精心设计的空间推理系统。深度专家采用编码器-解码器架构,这个选择很有讲究。编码器基于DINOv2,这是一个在自监督学习框架下训练的视觉模型,具有很强的特征提取能力。更关键的是,深度专家的初始化使用了Depth Anything V2的预训练权重。
Depth Anything V2的出现标志着单目深度估计领域的重大突破。这个模型在包括室内场景(ScanNet)、室外场景(KITTI)和其他多样化数据集上都进行了训练,学到了通用的深度估计能力。通过使用这样的预训练权重初始化深度专家,DepthVLA得以继承这些成熟的3D视觉先验。
在整合到VLA模型之前,深度专家在大规模3D数据集上进行了独立的预训练。这些数据集包括WildRGB-D、ScanNet、ScanNet++和HyperSim。深度专家的预训练使用了尺度不变对数损失:
L si ( d ^ , d ) = 1 n ∑ i y 2 − λ ( 1 n ∑ i y ) 2 \mathcal{L}_{\text{si}}(\hat{d}, d) = \sqrt{\frac{1}{n}\sum_{i}y^2 - \lambda\left(\frac{1}{n}\sum_{i}y\right)^2} Lsi(d^,d)=n1i∑y2−λ(n1i∑y)2
…详情请参照古月居

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 1
1 0
0- 0



 已为社区贡献56条内容
已为社区贡献56条内容

所有评论(0)