体系结构论文(109):UCAgent: An End-to-End Agent for Block-Level Functional Verification
这篇文章研究的是:
能不能用一个 agent,把硬件模块级 functional verification 从头到尾自动做下来。
作者提出的系统叫 `UCAgent`。它想解决的不是 assertion generation、coverage closure、testbench generation 这些单独子任务,而是:
从规格理解、环境搭建、coverage 建模、testcase 生成、执行与分析,一路串起来做 end-to-end verification。
为此,作者提出了三个核心机制:
1. 用纯 Python verification environment 替代让 LLM 去写大量 SystemVerilog/UVM。
2. 用一个 31-stage 的细粒度工作流,把复杂 verification 拆成很多可检查的小步骤。
3. 用 `VCLM`(Verification Consistency Labeling Mechanism)维持 specification、coverage model、testcase 三者之间的一致性和可追踪性。这篇文章的主张很明确:
1. LLM 不是完全不能做 verification。
2. 但如果直接让它一把生成 SV/UVM 验证环境,稳定性会很差。
3. 需要通过语言迁移、工作流拆解、checker 约束和一致性标签,把问题改造成 LLM 更容易做的形式。
一. Introduction
为什么功能验证这么难
Introduction 一开始先重新定义 functional verification:它的本质是确认硬件实现是否正确满足设计规格。作者强调,随着硬件设计复杂度指数增长,验证已经变成时间、人工和可靠性上的“瓶颈”。
这里有几个信息点:
- 验证现在消耗了很大比例的项目周期;
- 验证工程师的需求远高于设计工程师;
- 连设计人员自己也要花很多时间协助验证;
- 即便投入很多人力,first-silicon success 仍不高,逻辑/功能错误依然是重 spin 的主要来源。
这段的逻辑是:
投入很大 → 但结果仍不理想 → 所以需要新的自动化范式。
传统方法为什么“不够用了”
作者接着说,行业长期依赖的还是:
- constrained random verification
- formal verification
- hardware emulation
但这些方法本质上只是“维持平衡”,没有真正缩小“设计复杂度增长”和“验证能力增长”之间的差距。
这里不是说传统方法没用,而是说:
- 它们仍然重要;
- 但靠它们单打独斗,已经越来越难覆盖现代设计的复杂性;
- 所以大家自然会开始关注 AI / LLM 驱动的验证自动化。
现有 LLM 验证研究
工业界和学术界都在做,但 mostly 只做局部
作者指出,Synopsys、Cadence、Siemens 等 EDA 厂商都在把 AI 引入验证流程,典型方向包括:
- assertion generation
- coverage closure
- debug
学术界也在做:
- assertion generation
- automated testbench generation
- coverage improvement
但作者认为,这些工作多数都只是优化验证流程中的一个局部阶段,而不是把整个验证过程自动串起来。
也就是说,人还是那个 orchestration 的核心,并没有真正实现“end-to-end autonomous verification”。
现有端到端尝试,被分成两大类
作者把已有的 LLM 自动验证工作分成两类:
第一类:SystemVerilog / UVM-based
这些方法的共同点是:仍然围绕传统验证语言和验证框架做自动化,比如自动生成 UVM testbench、分多 agent 做规格解析、测试规划、代码生成等。
第二类:Python-based
它采用纯 Python 生成策略,尝试实现 end-to-end RTL 自动验证。
作者这样分类,其实是在给自己的工作铺垫:
UCAgent 明显站在 Python-based 这一侧,但又想比 PRO-V 做得更完整。
三个核心挑战
一个真正的端到端自动验证系统到底会死在哪些地方。
Challenge 1:LLM 生成 Verilog/SystemVerilog 验证代码不够可靠
作者的判断是:
LLM 在 Python 上通常表现不错,但在 Verilog/SystemVerilog 上明显更差。原因有两层。
第一层:训练数据太少
作者引用 The Stack v2 的数据说,Python 数据量极大,而 Verilog 和 SystemVerilog 的数据量小得多。于是模型对 HDL 的掌握天然更弱。
第二层:语言本身难
即使不考虑数据量,SystemVerilog 验证代码本身也更难:
- 语法复杂;
- 时序和并发语义强;
- 容易出现语法正确但语义不一致的问题。
所以作者的一个重要判断是:
如果让 LLM 大量直接生成 SV/UVM 验证代码,那么系统稳定性天花板会很低。
这就是为什么他们后面改用 Python。
Challenge 2:复杂端到端验证流程很难靠 LLM 稳定完成
作者认为,功能验证不是一次性生成一个文件,而是一个很长的流程,要处理:
- 规格文档
- 设计代码
- 验证代码
- 仿真日志
- 测试报告
这些信息量非常大,很容易超出 LLM 的有效处理能力。于是会出现:
- hallucination
- context rot
- instruction following 变弱
作者又把这个挑战拆成两个更具体的问题。
(1)信息丢失和错误累积
验证阶段之间是强依赖的。
如果前面规格分析少理解了一条约束,或者 coverage model 有一个命名错了,后面的 testcase、coverage 报告、bug 分析都会被带偏。
所以作者的观点是:
必须在每个阶段结束后进行自动检查,而不能等到最后统一发现问题。
(2)简单 workflow 无法适应不同模块
有些模块简单,比如 FIFO、算术单元,LLM 直接生成输入输出检查也许还行。
但有些模块交互复杂,比如 bus crossbar,需要 mock、复杂依赖、严格时序和接口约束。这个时候,如果 workflow 太粗糙,就会生成接口不匹配、行为错误的验证实现。
这里的重点是:
验证流程不能只有一个统一粗模板,而要能根据 DUT 复杂性配置。
Challenge 3:整个验证闭环里最难的是“一致性”
这是这篇文章最有辨识度的点。
作者认为,一个健壮的功能验证流程,必须在以下三个东西之间建立严格 traceability:
- functional specification
- coverage model
- testcase implementation
换句话说:
- 规格里提取出来的每个功能点;
- 覆盖模型里的 covergroup / coverpoint;
- 测试里真正执行到的检查点;
三者必须是一一对应、可追踪的。
作者把这种“验证目标、实现方式和最终结果之间的语义闭环”定义为 Verification Consistency。
这是非常重要的一个概念。因为很多自动化工作虽然生成了测试,也跑出了覆盖率,但你很难证明:
- 这个 coverage 到底是不是对应原始 spec;
- 有没有凭空 hallucinate 出不存在的功能点;
- 有没有 spec 里的重要 feature 没被真正覆盖到。
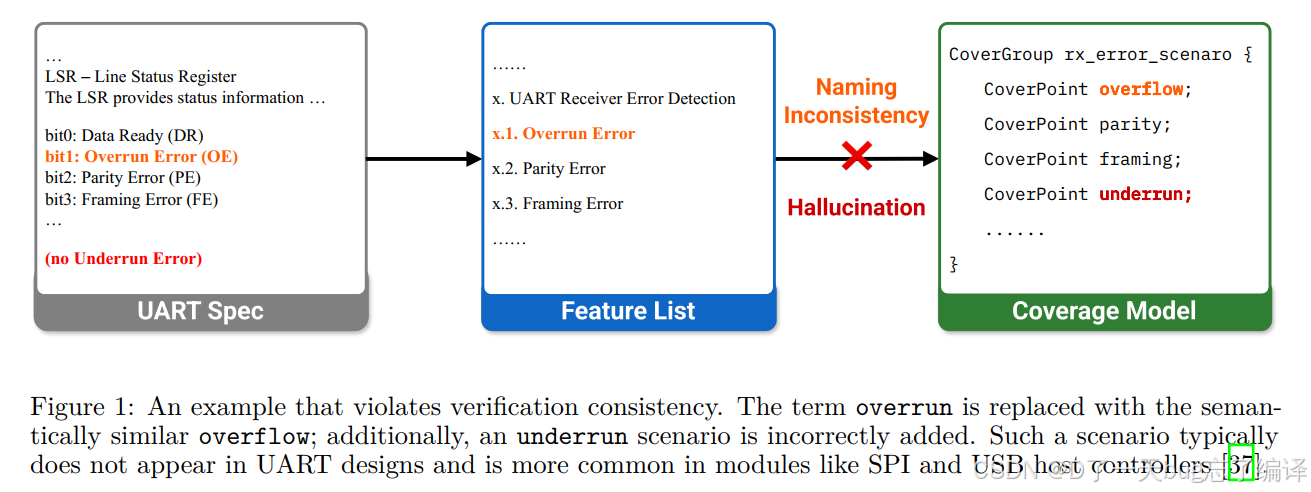
Figure 1 是整段引言里最关键的例子。它直观地说明了“一致性断裂”是怎么发生的。
图里的原始规格
左边 UART Spec 中说的是:
- bit0: Data Ready
- bit1: Overrun Error
- bit2: Parity Error
- bit3: Framing Error
- 没有 Underrun Error
中间的 feature list
LLM 在中间把这个功能总结成:
- UART Receiver Error Detection
- Overrun Error
- Parity Error
- Framing Error
到这一步看起来还没太大问题。
右边 coverage model 出问题了
到了 coverage model 阶段,LLM 把:
- overrun 改成了 overflow
- 又额外加了一个 underrun
这就出现了两种典型错误:
- Naming inconsistency
原始规格里的术语被偷偷替换了,虽然看上去意思接近,但已经不再严格一致。 - Hallucination
LLM 凭空加了规格里根本没有的场景。
作者借这个例子说明:
如果没有专门的机制去维护一致性,那么最后 coverage model 虽然“像那么回事”,但它和真实设计意图已经脱节了,验证结果也就不再可信。
现有方法的不足
在引言后半部分,作者对几个代表性方法做了一个对比性批评:
- PRO-V:没有 functional coverage model,因此没法建立“spec → coverage”的完整 traceability;
- UVM²:主要依赖 prompt 限制,没有显式机制确保跨阶段输出严格一致;
- MAVF:虽然建立了 test point 和 testcase 的 cross-reference matrix,但没有覆盖整个端到端流程的一致性机制。
这段的潜台词是:
现有工作也许能做自动生成,但还不能真正构成完整、闭环、可验证的自动验证系统。
UCAgent 在引言里提出的三大对应解法
在 Figure 1 之后,作者正式提出 UCAgent 的解决思路。
改语言载体——把验证实现转到 Python
作者用 Picker 把 DUT 转成 Python 包 PyDUT,再用 Toffee 引导 LLM 在 Python 中搭建 testbench 和 testcase。
本质逻辑是:
- HDL 验证代码难生成;
- Python 更符合 LLM 的能力边界;
- 所以不要硬让 LLM 在自己不擅长的地方作战。
这不是简单的“换个语言写代码”,而是重新设计 LLM 参与验证的接口层。
改流程组织——31-stage 细粒度 workflow
作者把验证流程拆成 31 个细阶段,每一阶段都要经过 checker 校验。这样可以:
- 降低单步任务复杂度;
- 阻止错误跨阶段扩散;
- 让系统在失败时可以局部修复,而不是整条链重来。
这一点非常像把“大任务 agent”改造成“可验证的阶段化 pipeline”。
改一致性维护方式——VCLM
VCLM 通过层级标签,让 spec、coverage、testcase 三者共享同一套显式标识。这样:
- 每个功能组
- 每个功能点
- 每个检查点
都可以跨阶段被 checker 自动追踪。
也就是说,作者不再只依赖 prompt 说“请保持一致”,而是把一致性变成machine-checkable constraint。
二、方法
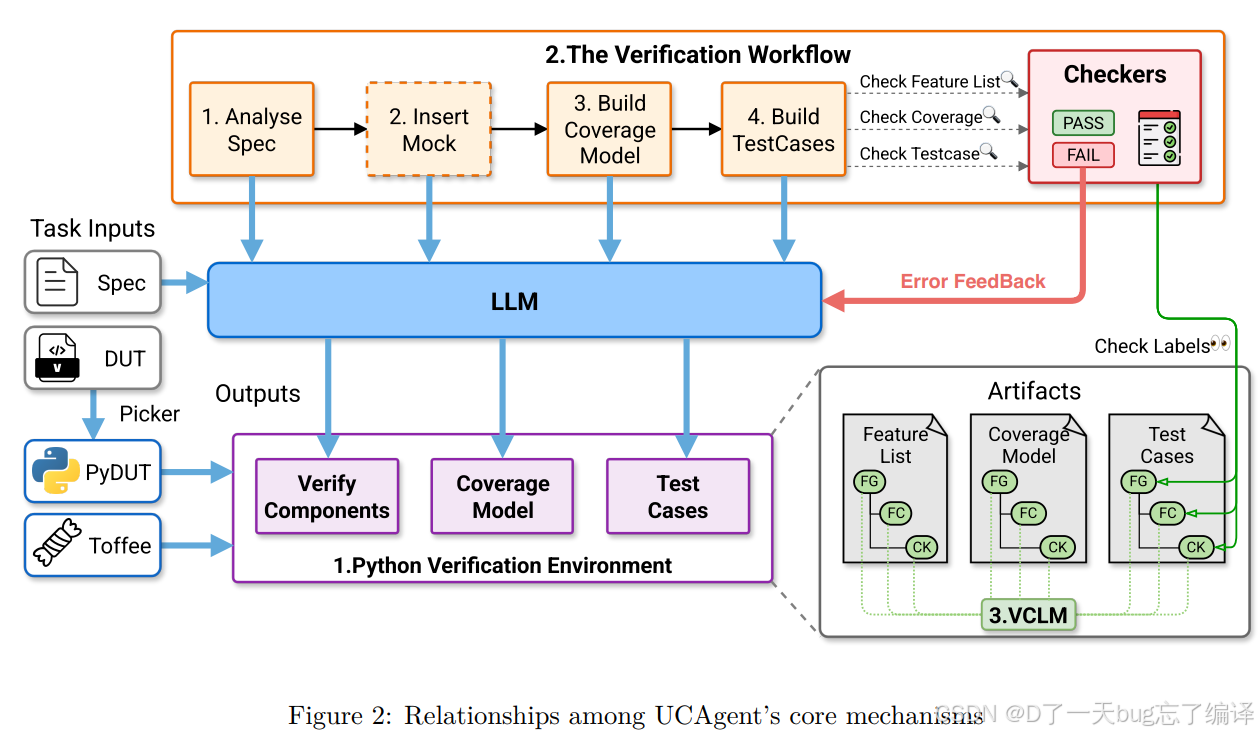
(Figure 2)其实是整篇文章最核心的总览图之一。它想说明:
UCAgent 不是单靠一个 LLM 在自由发挥,而是由三个机制共同约束和支撑。
图里可以拆成四个层次来看。
输入层:Spec 和 DUT
左边的 Task Inputs 是:
- Spec
- DUT
也就是说,这个系统的起点不是“让模型凭空想”,而是让它基于:
- 设计规格文档
- 被测硬件模块
来完成验证任务。
中间核心:LLM
中间是 LLM,它负责贯穿多个阶段地产生工件,包括:
- verify components
- coverage model
- test cases
但这里的 LLM 并不是裸奔的,它上下左右都被机制包住了。
下方机制一:Python Verification Environment
LLM 的输出不是 UVM/SV testbench,而是进入 Python Verification Environment。
也就是:
- DUT 经 Picker 变成
PyDUT - LLM 基于 Toffee 和 Python 抽象构建验证组件、覆盖模型和测试。
这相当于给 LLM 换了一套“更适合它工作的操作系统”。
上方机制二 + 右侧机制三
上方是 Verification Workflow,表示 LLM 不会一次性把所有东西生成完,而是按阶段推进:
- Analyse Spec
- Insert Mock
- Build Coverage Model
- Build TestCases
这些阶段结果都会被 Checkers 检查,如果失败,会形成 Error Feedback 回到 LLM,让它修正。
右下角是 Artifacts + VCLM,表示 feature list、coverage model、test cases 这些工件之间不能各写各的,而要通过 FG / FC / CK 标签建立一致性。checker 还会进一步做 label checking。
2.1 Python Verification Environment
为什么不让 LLM 直接写 SystemVerilog,而要让它生成 Python?
2.1.1 作者的根本判断:HDL 是 LLM 的短板
作者一上来就明确说,之所以建立纯 Python 验证环境,是为了绕开 hardware description language 数据稀缺 这个瓶颈。
他们认为当前 LLM 驱动验证的主要限制之一,就是 LLM 不能稳定地产生高质量 SystemVerilog 验证代码。
这背后的逻辑是:
- SV 在工业里当然是标准;
- 但 LLM 在 SV 上学得不够好;
- Python 才是 LLM 更擅长的语言。
注意这里作者不是在说“Python 更专业”,而是在说:
如果目标是让 LLM 稳定完成自动验证,那么应该把工作语言设计成更符合模型能力边界的形式。
2.1.2 Picker 和 Toffee 各干什么
作者提到两个关键工具:
- Picker:把 Verilog/SystemVerilog 的 DUT 转成 Python package,也就是
PyDUT - Toffee:基于 Picker 之上,提供更高层的 Python 验证抽象。
你可以这样理解:
- Picker 负责“把 RTL 暴露成 Python 可操作对象”
- Toffee 负责“把 testbench 编写提升到更高层”
所以这个体系不是让 Python 取代仿真器,而是让 Python 成为控制、驱动、检查 RTL 的上层接口语言。
2.1.3 解决了什么问题
作者特别强调,这种基础设施会把很多低层硬件交互细节抽象掉,比如:
- 时钟控制
- 仿真调度细节
- delta-cycle 等时序细节依赖
这带来的直接收益是:
- LLM 不用直接处理太底层的硬件验证细节
- testbench/testcase 更容易生成
- 更适合通过少量 in-context learning 驱动硬件
这一步其实非常关键。因为如果让 LLM 直接面对完整的 SV/UVM 语义和事件调度,任务难度会陡增。
作者这里本质上是在做一层 verification abstraction layer。
2.1.4 这一小节最后一句很重要
作者最后说,LLM 通过 Toffee 与 PyDUT 交互来构建 testbench 和 testcase,而整个执行过程又受到:
- fine-grained workflow
- stage-specific checkers
- VCLM
三者共同约束,从而保证:
- syntactic correctness
- 与设计规格的严格对齐。
这说明 Python 环境本身不是完整解决方案,只是三大机制中的第一块地基。
2.2 The Verification Workflow
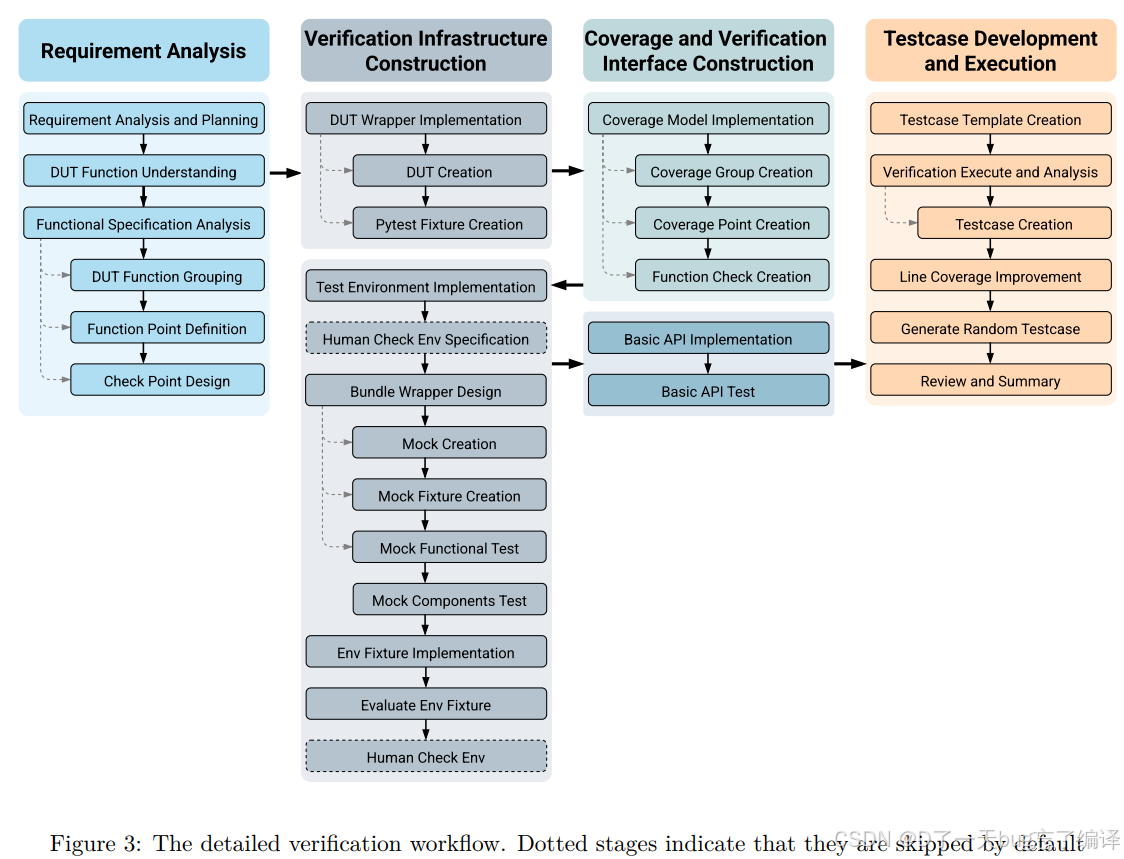
完整工作流图。它把整个验证过程拆成四大块:
- Requirement Analysis
- Verification Infrastructure Construction
- Coverage and Verification Interface Construction
- Testcase Development and Execution
虚线框表示有些阶段默认可跳过。作者强调这是一个可配置 workflow,不是僵硬固定模板。
Requirement Analysis
这一列主要在做“理解任务”的工作,包含:
- Requirement Analysis and Planning
- DUT Function Understanding
- Functional Specification Analysis
- DUT Function Grouping
- Function Point Definition
- Check Point Design
这一步的本质不是写代码,而是把规格转成结构化验证目标。
也就是回答:
- DUT 有哪些功能块?
- 每个功能块有哪些功能点?
- 每个功能点需要哪些检查点?
你可以把它理解成:
把自然语言规格,转成后续 coverage 和 testcase 可以消费的验证语义骨架。
这也是后面 VCLM 的起点。
Verification Infrastructure Construction
这一列是最“验证工程化”的部分,主要是把测试环境真正搭出来,包括:
这部分意思很明确:
先把 DUT 包起来
不是直接拿 RTL 裸跑,而是先包装成可操作的 wrapper / fixture / bundle 接口。
必要时引入 mock
如果 DUT 依赖外部组件,或者交互太复杂,单纯对 DUT 本身施激励不够,那就要生成 mock。
这正是作者前面引言里说的:复杂模块需要更复杂的环境建模,不能套一个简单模板。
先验证环境本身
环境不是搭完就默认对,还要做:
- mock functional test
- basic fixture evaluation
- 必要时 human check
这说明作者并不把“环境代码生成”视作理所当然成功,而是把它也纳入被验证对象。
Coverage and Verification Interface Construction
Coverage group / point 的作用
前面 requirement analysis 得到的是概念上的功能点;
这里要把这些功能点变成:
- 可执行 coverage model
- 可调用检查接口
- 后面 testcase 能实际触发和打点的结构
Basic API 的意义
这相当于先构造一些基础验证原语,例如:
- 某个接口怎么驱动
- 某个功能怎么调用
- 某类状态怎么检查
这会降低后续 testcase 直接生成的复杂度。
换句话说,这一列是在做:
从验证目标建模,过渡到验证执行接口建模。
Testcase Development and Execution
这说明 testcase 并不是一次性生成完事,而是个迭代闭环过程。
先做模板
先有 testcase template,再实例化具体测试。
跑起来再分析
不是“写出来就行”,还要执行并分析结果。
覆盖率驱动补充
如果 line coverage 不够,就继续增强 testcase。
还能做随机 testcase
说明这个流程并不局限于 directed tests,也支持进一步向随机测试扩展。
作者认为功能验证必须通过 structured workflow 来管理复杂性。
它把整个生命周期拆成多个相对独立、输入输出明确、结果可检查的阶段。
比如:
- specification analysis 必须输出有精确 label 结构的文档
- coverage modeling 必须输出可执行 covergroup
- testcase generation 必须产出能通过特定检查的仿真代码。
也就是说,这个工作流不是“为了画图好看”,而是为了把每一步都变成deterministic deliverable。
这是 agent 能稳定工作的关键。
Checker 在这里的真正角色是什么
作者这里对 checker 的定义很值得注意:
checker mechanism encodes expert quality criteria into executable constraint logic.
这句话意思是:
checker 不是简单判个 pass/fail,而是把验证专家对每个阶段产物的质量要求,写成机器可以执行的约束逻辑。
因此,一旦某阶段输出不达标:
- checker 会返回具体错误信息
- LLM 根据这些 error message 自我修正
- 再重新尝试这一阶段
所以 checker 的作用相当于:
- 局部裁判
- 阶段闸门
- 自动反馈器
这也是为什么作者说这个系统能抑制错误累积。
为什么是 31-stage
作者说,这个 31-stage 架构是通过基于 checker 反馈的经验式 refinement 得到的。
他们观察哪些任务容易失败,就继续细分这些任务,最后收敛到一个更细粒度的工作流。
- 工作流设计本身也是实验结果的一部分;
- 作者不是先验地知道“31 是最优”,而是通过失败统计和任务重构逐步打磨出来的。
这是一种很典型的系统工程论文思路。
2.3 VCLM
这一节是整个方法里最有辨识度的部分。
作者说,为了解决多阶段之间 verification consistency 难以维持的问题,他们提出 Verification Consistency Labeling Mechanism (VCLM)。
VCLM 建立了三层标签:
- FG
- FC
- CK
并要求 LLM 在三个关键阶段都持续使用这些标签:
- functional specification analysis
- coverage model construction
- testcase implementation
VCLM 的本质是“把隐式语义变成显式约束”
作者明确说,VCLM 的作用是把原本隐式的设计依赖关系,转化成 structured, machine-checkable data。
以前你只能通过 prompt 说:
- 请保持 coverage model 和 specification 一致;
- 请让 testcase 覆盖这些功能点。
但 prompt 只是自然语言要求,LLM 很容易:
- 改名
- 漏项
- 幻觉出不存在的点
而现在通过标签机制:
- 规格里的功能点有明确 ID
- coverage model 必须复用这些 ID
- testcase 也必须引用这些 ID
- checker 自动核对这些 ID 是否对应正确
于是“保持一致”就从一个软要求,变成了一个硬约束。
VCLM 是怎样和 checker 联动的
作者说,stage-specific checker 会系统性地提取这些标签,验证跨阶段一致性。
如果某个工件:
- 没有带上必须的标签
- 带了错误标签
- 和前一阶段标签不匹配
checker 就会拒绝该输出,并返回明确错误 trace 给 LLM,触发立即自我修正。
为什么“不能只靠 prompt”
作者明确说,只靠自然语言提示,比如“ensure the coverage model is consistent with the specification”,对于复杂硬件设计来说是不可靠的。
这句话其实是在批评很多 LLM 系统论文常见的问题:
- 过度依赖 prompt engineering;
- 缺乏显式结构约束;
- 输出看似合理,实际很难保证可追踪性。
三、部署

Figure 6 用一个 vector floating-point addition module 展示了 VCLM-enabled workflow。
流程很直观:
1. 在 specification 阶段,功能点被标成类似 `<FG-ARITHMETIC>`, `<FC-VFADD>`, `<CK-FP32>` 这样的标签。
2. 到 coverage modeling 阶段,这些标签必须原样复用到 CoverGroup、CoverPoint、Bin。
3. 到 testcase 阶段,测试函数也必须声明自己覆盖哪些 check point。
4. checker 在阶段之间做 cross-reference。
这张图的意义是把 VCLM 从抽象概念变成了可执行机制。
它不是“加几个注释”,而是整个 workflow 的跨阶段语义锚点。
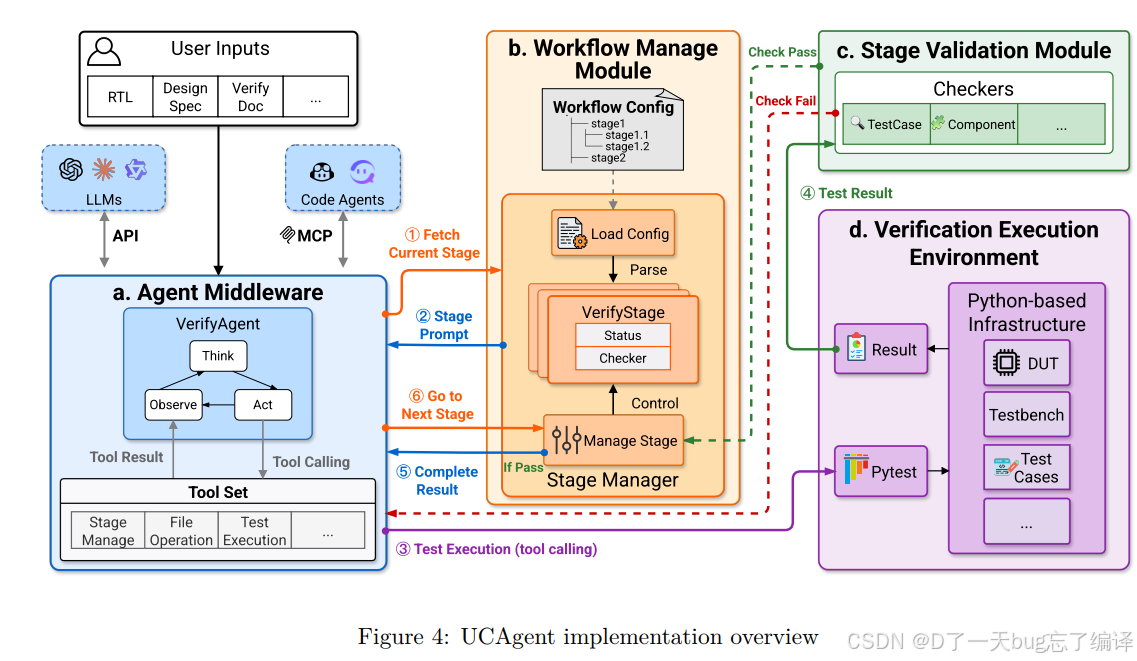
Figure 4 讲的是实现总览,主要包括四个模块:
1. Agent Middleware
2. Workflow Management Module
3. Stage Validation Module
4. Verification Execution Environment
这里最关键的是分层:
1. Middleware 负责 LLM、上下文、工具调用。
2. Workflow manager 决定现在在哪个阶段、下一个阶段是什么。
3. Validation module 负责 checker 和 VCLM。
4. Execution environment 真正跑仿真和测试。
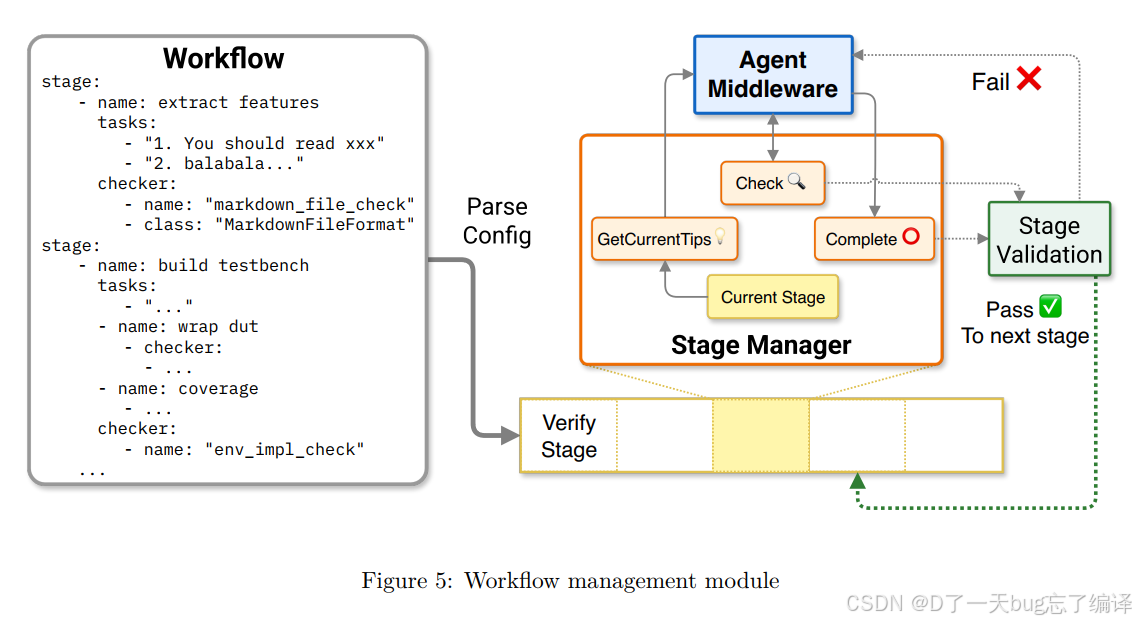
Figure 5 则更细地展示了 workflow management module,包括 YAML 配置、StageManager、checker gating 等。
这两张图说明作者很重视“系统可控性”。不是单纯让 agent 自由发挥,而是:
1. 明确阶段边界。
2. 明确通过条件。
3. 明确失败回路。
这对 verification 任务尤其重要。
四、实验
作者测试了五个模块,包括:
1. UART-16550
2. ALU754
3. IntegerDivider
4. ICache-WayLookup
5. PageTableWalker
其中前几个规模和结构差异明显,而 `PageTableWalker` 已经是很大的设计。
作者用默认 automated workflow 跑这些模块,并比较 Claude-Sonnet-4.5、GPT-5、Qwen3-Coder-Plus 等模型。
这说明实验不是单一模块 demo,而是有一定横向覆盖。

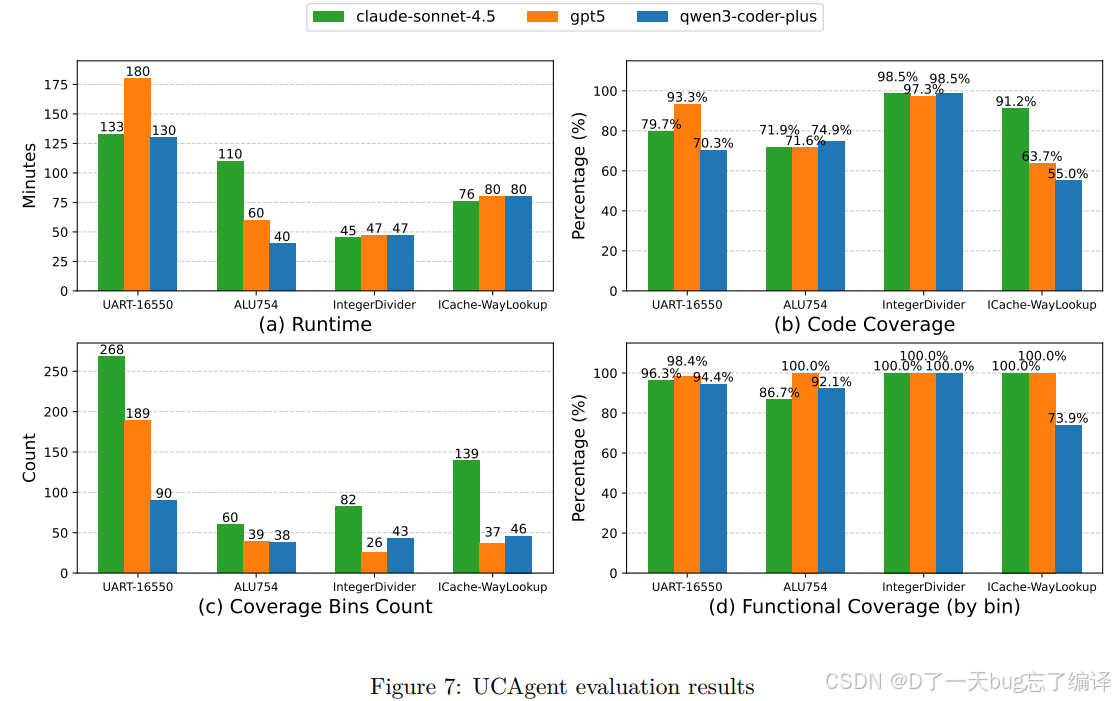
Figure 7 分四块展示:
1. Runtime
2. Code coverage
3. Coverage bins count
4. Functional coverage
从结果看:
1. IntegerDivider 的 functional coverage 可以到 100%。
2. UART 和 ALU754 的 functional coverage 多数也在 86% 以上。
3. UCAgent 在不同模块上能达到最高 98.5% code coverage 和 100% functional coverage。
这对一篇 end-to-end verification agent 论文来说已经是比较扎实的结果。
但图里也显示不同模型风格不同:
1. Claude-Sonnet-4.5 覆盖更高、更细。
2. GPT-5 更稳定。
3. Qwen3-Coder-Plus 更快,但覆盖较低。
这种差异说明 UCAgent 不是“屏蔽了底层模型差异”,而是提供了一个能把不同模型能力放大的流程。
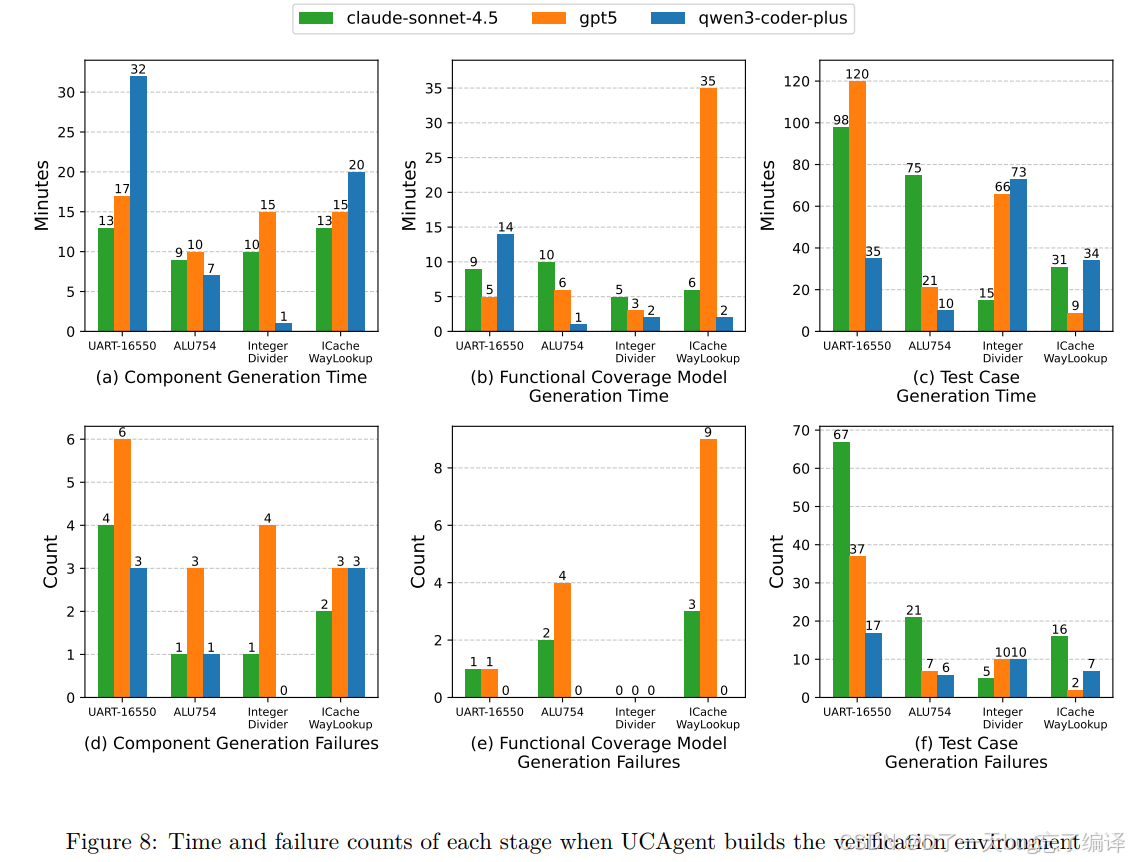
Figure 8 把流程拆成三个大阶段来看:
1. Component generation
2. Coverage-model generation
3. Testcase generation
结果非常有启发性:
1. Component generation 相对稳定,耗时中等,失败少。
2. Coverage-model generation 最快、失败率也最低。
3. Testcase generation 是最难、最慢、失败最多的阶段。
它说明:
verification 自动化里最难的,还是把抽象 intent 落成真正有效的测试刺激。
文章还指出:
1. Claude 在 testcase generation 上试错很多,但最终 coverage 最好。
2. GPT-5更平衡、更稳。
3. Qwen 更快,但因为功能分解更粗,后续 testcase 难度低一些,最终 coverage 也更低。
这让 Figure 8 不只是“耗时图”,而是帮助理解模型行为差异。
Case studies
文章给了三个 case study。
第一,`IntegerDivider`。
Qwen3-Coder-Plus 在 RISC-V 特定边界行为上失败,说明即使有 workflow,模型本身的 domain knowledge 仍然限制 verification completeness。
workflow 能兜住很多过程错误,但兜不住模型对某些领域知识根本不懂。
第二,`LaneFAdd`。
UCAgent 找出了三个之前未发现的边界条件 bug,并且借助 VCLM 把失败追踪回具体 function/check point。
第三,`PageTableWalker`。
这个模块太大,默认 workflow 跑不完,最后需要 human-in-the-loop,8 小时内达成预期结果。
1. UCAgent 对模块级任务有效。
2. 但超大规模设计还不能完全自动化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 10
10 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)