TPAMI 2026 | DFormer++ 横空出世!深度引导注意力,破解 RGB-D 语义分割模态失配难题
在自动驾驶、机器人导航的世界里,机器要像人一样看懂三维世界,RGB-D数据是核心——RGB图像给色彩纹理,深度图给空间几何。但过去的算法总在"偏科":要么用仅训练过RGB的模型硬解深度图,要么双分支架构又重又慢。
今天要聊的这篇顶刊论文,提出的DFormer++框架,把RGB-D语义分割的性能和效率拉到了新高度,还能轻松适配RGB-T等多模态场景。看完你会发现,原来让机器读懂三维场景,还能这么高效!
论文信息
题目: DFormer++: Improving RGBD Representation Learning for Semantic Segmentation
DFormer++:提升RGB-D语义分割的表征学习
作者:Bo-Wen Yin, Jiao-Long Cao, Dan Xu, Ming-Ming Cheng, Qibin Hou
先聊聊:过去的RGB-D分割为啥总差口气?
我们先看一张图(图1),左边是传统RGB-D处理流程:用两个独立的、只训过RGB图像的主干网络,分别处理RGB图和深度图,再让两者特征交互。
这种模式看着合理,却藏着三个大问题:
-
预训练和实际任务"对不上":预训练只喂RGB图,实际用RGB-深度对,特征分布差太远,就像用学语文的方法去解数学题;
-
容易"打乱"原有能力:微调时RGB和深度分支频繁交互,反而破坏了RGB预训练模型原本的优势;
-
又重又慢:双主干架构参数多、计算量大,部署到边缘设备(比如机器人、车载终端)根本不现实。
说白了,核心问题就是:深度信息在模型预训练阶段,压根没被真正重视过。
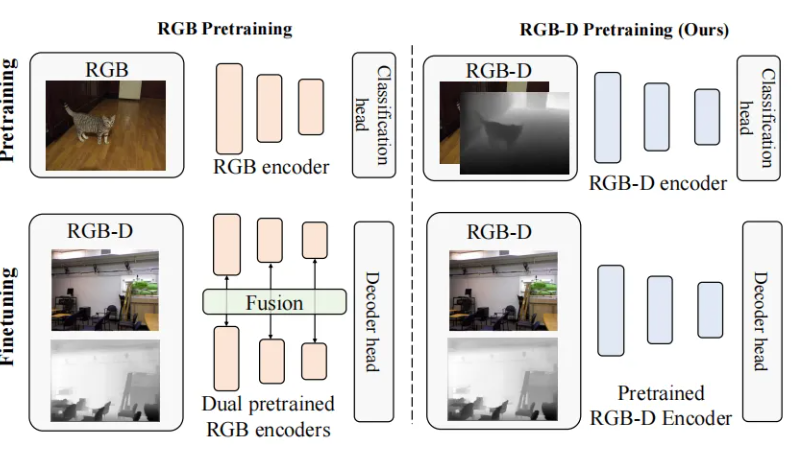
DFormer++的核心思路:从源头解决问题
这篇论文的核心逻辑很简单:既然要处理RGB-D数据,那模型从预训练开始,就该同时见RGB图和深度图。在此基础上,再设计高效的特征融合方式,砍掉冗余参数。
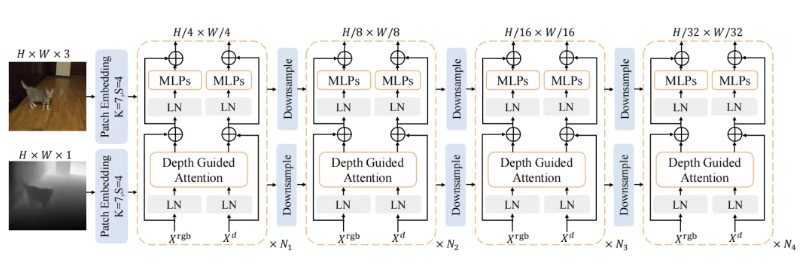
我们先看DFormer++的整体架构(图5),一眼就能看懂它的设计巧思:
-
输入层:RGB图和深度图各走一个轻量stem层,初步提取基础特征;
-
编码器:四阶段分层结构,每个阶段堆着"深度引导注意力块"——这是核心,后面细说;
-
预训练:用ImageNet-1K的RGB-深度对预训练,让模型从小就懂"色彩+几何";
-
解码器:只拿增强后的RGB特征做预测,深度特征的作用早就在编码器里融透了,不用多此一举。

创新点1:RGB-D预训练,从源头消除"能力偏差"
传统模型预训练只认RGB,处理深度图时就像"半路出家"。DFormer++直接在ImageNet-1K上,用RGB-深度图像对做预训练。
简单说,就是让模型从学习的第一天起,就同时接触色彩信息和空间几何信息。这样一来,预训练和下游RGB-D任务的输入完全匹配,不会再出现"分布偏移"——模型不用再花力气适配两种模态的差异,能把全部能力用在分割上。
实验里能明显看到(表5/图7):只用RGB预训练的模型,处理深度图时提取的特征杂乱无章;而RGB-D预训练的模型,能精准抓住深度图里的几何边界和空间结构。哪怕是轻量级的DFormer++-Tiny,仅靠这个预训练策略,就能在NYU Depth v2上多拿2.8%的mIoU(分割精度核心指标)。

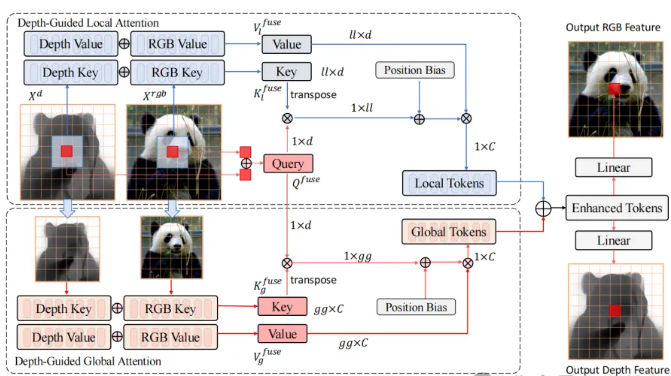
创新点2:深度引导注意力,让特征融合又精又省
这是DFormer++最亮眼的设计——把传统的多分支融合,改成了统一的"深度引导注意力模块"(图4),核心是让深度信息在"局部"和"全局"两个维度,精准引导RGB特征增强。
局部层面:抓细节,辨边界
深度图能精准告诉你"这个物体的边缘在哪"、"两个相邻物体谁在前谁在后"。DFormer++在局部窗口里,把RGB和深度特征融合成查询、键、值,让模型聚焦每个像素周围的几何细节。比如区分"墙面"和"桌子",靠RGB可能分不清,但深度的局部几何线索能一眼辨明。
全局层面:懂布局,明场景
深度图还能告诉你"整个房间的布局是怎样的"、"大的物体在哪个位置"。DFormer++把RGB和深度特征下采样成粗粒度标记,做全局交互,让模型理解整体场景结构——比如知道"客厅里,沙发该在茶几后面",避免分割时的类别混淆。
关键是,这个注意力模块的计算量是线性的(不是传统自注意力的二次方),还砍掉了单独的RGB分支,参数少了,效率却更高。
创新点3:单分支+少通道,效率拉满
研究团队发现了一个关键规律:深度信息的语义含量远少于RGB,根本不用给它分配和RGB一样多的通道。
于是DFormer++做了两个优化:
-
编码器只用单分支架构,深度特征只占少量通道,相比双分支,参数和计算量大幅下降;
-
解码器只使用增强后的RGB特征(图6右)——因为深度的几何信息,早就通过注意力模块融到RGB特征里了,不用再额外处理深度特征,进一步简化设计。
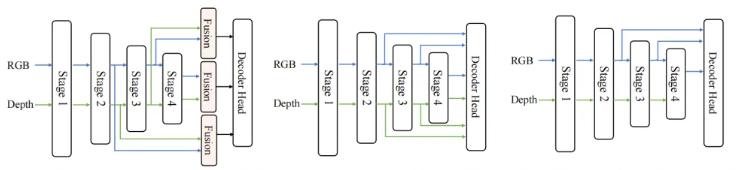
图6:三种解码范式对比,DFormer++(右)仅用RGB特征,效率最高
创新点4:通用多模态基础模型,不止于RGB-D
DFormer++的设计不是"专才",而是"通才"。因为它从预训练阶段就学会了多模态特征融合的核心逻辑,所以不仅能处理RGB-D,还能轻松适配RGB-热成像(RGB-T)、RGB-LiDAR等场景。
在KITTI-360(室外自动驾驶)、MFNet(热成像)、Cityscapes(城市场景)等数据集上,DFormer++都能保持高性能——这说明它学到的不是"处理RGB-D的技巧",而是多模态融合的通用能力。
实测效果:性能和效率,鱼和熊掌兼得
光说不练假把式,我们看几组关键结果:
1. 精度登顶
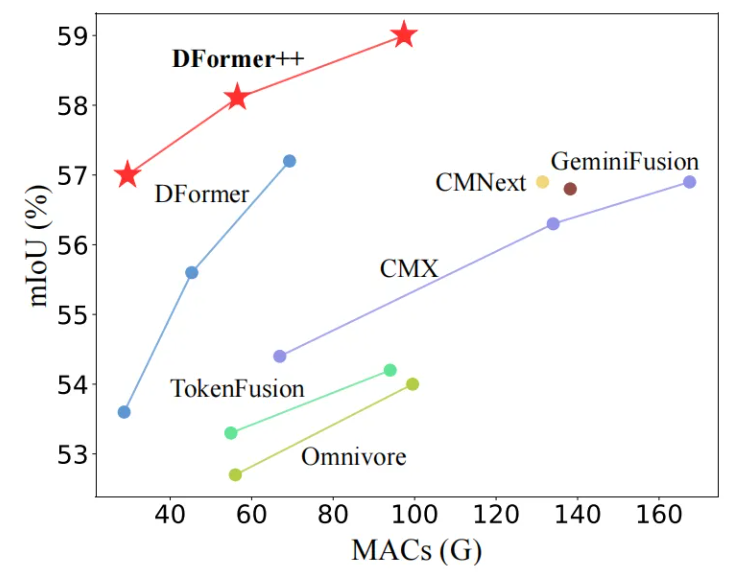
在NYU Depth v2、SUN-RGBD、Stanford2D3D三大主流RGB-D分割数据集上,DFormer++全拿了SOTA(当前最优)。比如DFormer++-Base在NYU Depth v2上达到59.0% mIoU,远超之前的算法。
2. 效率拉满
轻量级的DFormer++-Tiny,仅用17.3M参数、29.5G MACs(计算量),就实现了57.0% mIoU——参数只有很多SOTA模型的一半,精度却没降多少。
3. 部署友好
在边缘设备上的表现更惊艳(表4):iPhone 15 ProMax、Jetson Orin(车载/机器人常用芯片)上,DFormer++的推理延迟远低于其他算法。比如在Jetson Orin上,它能快速响应,完全满足实时场景的需求。
为什么这些创新这么重要?
对做计算机视觉的研究者来说,DFormer++解决了RGB-D领域长期存在的"预训练失配"问题,还给出了高效的多模态融合范式;
对产业界来说,它的高效性和部署友好性,让RGB-D语义分割能真正落地——不管是自动驾驶的环境感知,还是服务机器人的场景理解,都需要又快又准的算法,DFormer++正好踩中了这个需求。
更关键的是,它证明了一个核心思路:处理多模态数据,要从预训练阶段就"对齐"模态特征,而不是后期硬凑。这个思路不仅适用于RGB-D,也给其他多模态任务(比如RGB-T、多传感器融合)提供了参考。
总结
DFormer++没有搞复杂的花活,而是抓住了RGB-D分割的核心痛点:预训练失配、特征融合冗余、模型效率低。
它用RGB-D预训练从源头解决分布偏移,用深度引导注意力实现精准融合,用单分支+少通道设计降低成本,最终实现了"精度更高、速度更快、泛化性更强"的目标。
这篇论文不仅刷新了RGB-D语义分割的SOTA,更重要的是,它给多模态表征学习提供了一个简洁、高效的新范式——有时候,好的算法不是越复杂越好,而是能精准解决核心问题。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)