变分自编码器(VAE)原理应用完整指南
目录
这篇文章会从最基础的地方出发,一路推到 ELBO、重参数化技巧,再到 β-VAE、VQ-VAE,最后聊到 VAE 在 Stable Diffusion、视频生成等现代系统里扮演的角色。文章会尽量把公式推完整,但每一步都会配上直觉解释。
一、从普通 Autoencoder 说起
编解码的基本思想
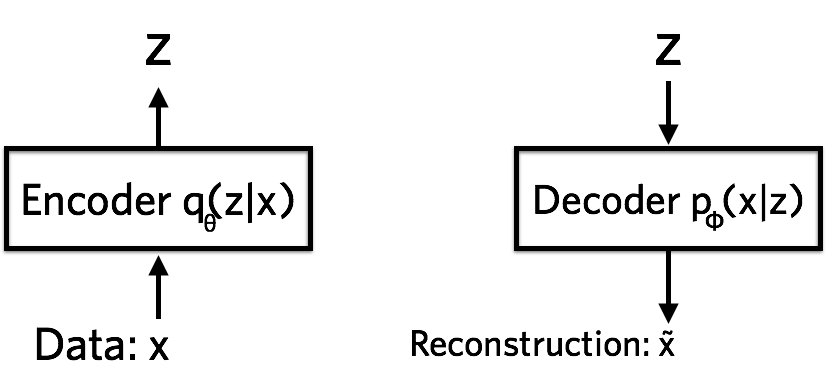
自编码器(Autoencoder, AE)的结构非常朴素:一个编码器(Encoder)把输入 x x x 压缩成一个低维向量 z z z,一个解码器(Decoder)再把 z z z 还原回 x ^ \hat{x} x^,然后我们最小化 x x x 和 x ^ \hat{x} x^ 之间的重建误差。
L AE = ∥ x − x ^ ∥ 2 \mathcal{L}_{\text{AE}} = \|x - \hat{x}\|^2 LAE=∥x−x^∥2
它的目的不是生成,是压缩表示。训练好之后,潜空间(latent space)里的向量 z z z 理论上捕捉了数据的核心结构。
普通 AE 的硬伤
问题来了:如果你在潜空间里随机采一个点 z ′ z' z′,然后送进解码器,解码出来的东西十有八九是乱七八糟的噪声。
原因是:普通 AE 的编码器输出的是一个固定的点(deterministic point),训练过程没有任何机制保证潜空间的连续性和结构性。相邻的两个 z z z 可以解码出完全不相关的内容,潜空间里存在大量"空洞"——那些位置没有对应任何有意义的数据。
这意味着你拿 AE 做生成是很困难的,因为你不知道"合法"的 z z z 到底在哪里。
VAE 就是来解决这个问题的。
二、概率视角:我们真正想做什么?
生成模型的目标
生成模型的核心目标是学习数据的分布 p ( x ) p(x) p(x)。一旦学会了,你就可以从里面采样,生成新的数据。
直接对复杂的高维分布建模是困难的,所以一个经典的思路是引入潜变量(latent variable) z z z,通过边缘化来建模数据:
p θ ( x ) = ∫ p θ ( x ∣ z ) p ( z ) d z p_\theta(x) = \int p_\theta(x|z) \, p(z) \, dz pθ(x)=∫pθ(x∣z)p(z)dz
这里:
- p ( z ) p(z) p(z) 是潜变量的先验分布,通常取标准正态 N ( 0 , I ) \mathcal{N}(0, I) N(0,I)
- p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 是由参数 θ \theta θ 控制的条件似然,用神经网络来参数化——这就是解码器
生成过程:先从 p ( z ) p(z) p(z) 采一个 z z z,再从 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 采一个 x x x。
这个模型非常直觉,但有一个核心难题:
后验概率不可算
如果你想用最大似然法训练这个模型,你需要最大化:
log p θ ( x ) = log ∫ p θ ( x ∣ z ) p ( z ) d z \log p_\theta(x) = \log \int p_\theta(x|z) p(z) \, dz logpθ(x)=log∫pθ(x∣z)p(z)dz
这个积分对于复杂的神经网络是解析上不可解的(intractable)。
更大的问题是,如果你想做推断——给定 x x x,问"这个 x x x 来自哪个 z z z"——你需要计算后验 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x),由贝叶斯公式:
p θ ( z ∣ x ) = p θ ( x ∣ z ) p ( z ) p θ ( x ) p_\theta(z|x) = \frac{p_\theta(x|z) p(z)}{p_\theta(x)} pθ(z∣x)=pθ(x)pθ(x∣z)p(z)
分母 p θ ( x ) p_\theta(x) pθ(x) 就是那个不可算的积分,所以后验也不可算。
VAE 的核心贡献是:用变分推断(Variational Inference)来绕过这个问题。
三、变分推断:近似那个难以计算的后验
引入近似后验
变分推断的思路很简单:既然真实后验 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x) 算不出来,我们就用一个参数化的分布 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 来近似它。这里 ϕ \phi ϕ 是近似分布的参数,同样用神经网络来学习——这就是编码器。
问题变成:我们怎么衡量 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 与 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x) 之间的距离?
标准答案是 KL 散度(Kullback-Leibler Divergence):
D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = E q ϕ ( z ∣ x ) [ log q ϕ ( z ∣ x ) p θ ( z ∣ x ) ] ≥ 0 D_{\text{KL}}(q_\phi(z|x) \| p_\theta(z|x)) = \mathbb{E}_{q_\phi(z|x)}\left[\log \frac{q_\phi(z|x)}{p_\theta(z|x)}\right] \geq 0 DKL(qϕ(z∣x)∥pθ(z∣x))=Eqϕ(z∣x)[logpθ(z∣x)qϕ(z∣x)]≥0
我们希望最小化这个量,但里面有 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x),还是算不了。
推导 ELBO
用贝叶斯公式把 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x) 展开:
D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = E q ϕ [ log q ϕ ( z ∣ x ) − log p θ ( x ∣ z ) − log p ( z ) + log p θ ( x ) ] D_{\text{KL}}(q_\phi(z|x) \| p_\theta(z|x)) = \mathbb{E}_{q_\phi}\left[\log q_\phi(z|x) - \log p_\theta(x|z) - \log p(z) + \log p_\theta(x)\right] DKL(qϕ(z∣x)∥pθ(z∣x))=Eqϕ[logqϕ(z∣x)−logpθ(x∣z)−logp(z)+logpθ(x)]
注意 log p θ ( x ) \log p_\theta(x) logpθ(x) 与 z z z 无关,可以提出来:
D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) = E q ϕ [ log q ϕ ( z ∣ x ) − log p θ ( x ∣ z ) − log p ( z ) ] + log p θ ( x ) D_{\text{KL}}(q_\phi(z|x) \| p_\theta(z|x)) = \mathbb{E}_{q_\phi}\left[\log q_\phi(z|x) - \log p_\theta(x|z) - \log p(z)\right] + \log p_\theta(x) DKL(qϕ(z∣x)∥pθ(z∣x))=Eqϕ[logqϕ(z∣x)−logpθ(x∣z)−logp(z)]+logpθ(x)
整理一下:
log p θ ( x ) = D KL ( q ϕ ( z ∣ x ) ∥ p θ ( z ∣ x ) ) + E q ϕ [ log p θ ( x ∣ z ) ] − D KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) ⏟ L ( θ , ϕ ; x ) \log p_\theta(x) = D_{\text{KL}}(q_\phi(z|x) \| p_\theta(z|x)) + \underbrace{\mathbb{E}_{q_\phi}\left[\log p_\theta(x|z)\right] - D_{\text{KL}}(q_\phi(z|x) \| p(z))}_{\mathcal{L}(\theta, \phi; x)} logpθ(x)=DKL(qϕ(z∣x)∥pθ(z∣x))+L(θ,ϕ;x) Eqϕ[logpθ(x∣z)]−DKL(qϕ(z∣x)∥p(z))
由于 KL 散度 ≥ 0 \geq 0 ≥0,所以:
log p θ ( x ) ≥ L ( θ , ϕ ; x ) \log p_\theta(x) \geq \mathcal{L}(\theta, \phi; x) logpθ(x)≥L(θ,ϕ;x)
L ( θ , ϕ ; x ) \mathcal{L}(\theta, \phi; x) L(θ,ϕ;x) 被称为证据下界(Evidence Lower BOund, ELBO)。它是 log p θ ( x ) \log p_\theta(x) logpθ(x) 的一个下界,等号当且仅当 q ϕ ( z ∣ x ) = p θ ( z ∣ x ) q_\phi(z|x) = p_\theta(z|x) qϕ(z∣x)=pθ(z∣x) 时成立。
关键洞见:最大化 ELBO,就同时在做两件事——
- 最大化数据的对数似然 log p θ ( x ) \log p_\theta(x) logpθ(x)(让模型更好地解释数据)
- 最小化近似后验与真实后验的 KL 散度(让近似越来越精准)
ELBO 的分解形式
ELBO 可以写成更直觉的形式:
L ( θ , ϕ ; x ) = E q ϕ ( z ∣ x ) [ log p θ ( x ∣ z ) ] ⏟ 重建项(Reconstruction Term) − D KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) ⏟ 正则项(Regularization Term) \mathcal{L}(\theta, \phi; x) = \underbrace{\mathbb{E}_{q_\phi(z|x)}\left[\log p_\theta(x|z)\right]}_{\text{重建项(Reconstruction Term)}} - \underbrace{D_{\text{KL}}(q_\phi(z|x) \| p(z))}_{\text{正则项(Regularization Term)}} L(θ,ϕ;x)=重建项(Reconstruction Term) Eqϕ(z∣x)[logpθ(x∣z)]−正则项(Regularization Term) DKL(qϕ(z∣x)∥p(z))
- 重建项:编码器把 x x x 编到 z z z,再由解码器重建回来,这一项衡量重建质量
- 正则项:把近似后验 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 往先验 p ( z ) = N ( 0 , I ) p(z) = \mathcal{N}(0, I) p(z)=N(0,I) 上拉,防止潜空间"乱来"
这两项之间存在张力(tension):重建项希望编码器把每个 x x x 映射到尽可能独特的 z z z(以便精确重建),而正则项希望所有 z z z 都靠近原点高斯分布。最终达到的平衡,正是一个结构良好、连续的潜空间。
四、神经网络的实现:VAE 的具体设计
分布的参数化
假设近似后验是对角高斯:
q ϕ ( z ∣ x ) = N ( z ; μ ϕ ( x ) , σ ϕ 2 ( x ) ⋅ I ) q_\phi(z|x) = \mathcal{N}(z; \mu_\phi(x), \sigma_\phi^2(x) \cdot I) qϕ(z∣x)=N(z;μϕ(x),σϕ2(x)⋅I)
编码器网络输出两个向量:均值 μ ϕ ( x ) \mu_\phi(x) μϕ(x) 和方差 σ ϕ 2 ( x ) \sigma_\phi^2(x) σϕ2(x)(实践中通常输出 log σ 2 \log \sigma^2 logσ2 以保证数值稳定性)。
解码器 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z) 通常也是高斯或伯努利分布,用神经网络输出参数(比如对图像像素,用伯努利就是输出每个像素为 1 的概率)。
重参数化技巧(Reparameterization Trick)
这里有一个很微妙的问题。我们需要对 z ∼ q ϕ ( z ∣ x ) z \sim q_\phi(z|x) z∼qϕ(z∣x) 做采样,然后通过 z z z 计算重建项,进而对 ϕ \phi ϕ 求梯度。但采样操作本身是不可微的——你不能对一个随机过程求梯度。
这是 VAE 最聪明的地方之一:重参数化技巧(Reparameterization Trick)。
不直接从 N ( μ , σ 2 ) \mathcal{N}(\mu, \sigma^2) N(μ,σ2) 采样,而是把采样过程拆开:
z = μ ϕ ( x ) + σ ϕ ( x ) ⊙ ε , ε ∼ N ( 0 , I ) z = \mu_\phi(x) + \sigma_\phi(x) \odot \varepsilon, \quad \varepsilon \sim \mathcal{N}(0, I) z=μϕ(x)+σϕ(x)⊙ε,ε∼N(0,I)
这样,随机性被隔离到了 ε \varepsilon ε 上,而 ε \varepsilon ε 与模型参数无关。梯度可以通过 μ ϕ \mu_\phi μϕ 和 σ ϕ \sigma_\phi σϕ 正常反传。
几何直觉:原来是"在一个随机的地方采样",现在变成"在一个固定的地方,加一个随机扰动"。扰动本身不可导没关系,因为我们不需要对它求梯度。
KL 散度的解析解
当 q ϕ ( z ∣ x ) = N ( μ , σ 2 I ) q_\phi(z|x) = \mathcal{N}(\mu, \sigma^2 I) qϕ(z∣x)=N(μ,σ2I), p ( z ) = N ( 0 , I ) p(z) = \mathcal{N}(0, I) p(z)=N(0,I) 时,KL 散度有解析解(Kingma & Welling 论文附录 B):
D KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) = − 1 2 ∑ j = 1 J ( 1 + log σ j 2 − μ j 2 − σ j 2 ) D_{\text{KL}}(q_\phi(z|x) \| p(z)) = -\frac{1}{2} \sum_{j=1}^{J} \left(1 + \log \sigma_j^2 - \mu_j^2 - \sigma_j^2\right) DKL(qϕ(z∣x)∥p(z))=−21j=1∑J(1+logσj2−μj2−σj2)
其中 J J J 是潜变量的维度。这个解析式避免了用蒙特卡洛估计 KL 散度,减少了训练方差。
最终的训练目标
综合以上,对于第 i i i 个数据点 x ( i ) x^{(i)} x(i),VAE 的损失函数(最大化 ELBO 等价于最小化其负值)为:
L VAE = − E ε ∼ N ( 0 , I ) [ log p θ ( x ( i ) ∣ μ ϕ + σ ϕ ⊙ ε ) ] + D KL ( q ϕ ( z ∣ x ( i ) ) ∥ p ( z ) ) \mathcal{L}_{\text{VAE}} = -\mathbb{E}_{\varepsilon \sim \mathcal{N}(0,I)}\left[\log p_\theta(x^{(i)} | \mu_\phi + \sigma_\phi \odot \varepsilon)\right] + D_{\text{KL}}(q_\phi(z|x^{(i)}) \| p(z)) LVAE=−Eε∼N(0,I)[logpθ(x(i)∣μϕ+σϕ⊙ε)]+DKL(qϕ(z∣x(i))∥p(z))
第一项是重建损失(对连续数据用 MSE,对二值数据用交叉熵),第二项是 KL 正则。
五、潜空间的几何:为什么 VAE 生成的图像有点模糊?
训练好 VAE 之后,潜空间变得结构良好:相似的数据点在潜空间里靠得近,可以做插值,不同类别之间有平滑过渡。
但 VAE 生成图像有一个出了名的问题:输出偏模糊(blurry)。
原因有几个层面:
从优化的角度看:重建损失用的是像素级 MSE(或 BCE),这本质上是在最大化一个高斯或伯努利似然。这种似然对所有像素赋予相同权重,而生成模型在"不确定"某个像素值时,倾向于输出各种可能值的平均,从而产生模糊感。高频细节(边缘、纹理)恰恰是最难预测的,于是就被抹掉了。
从信息论的角度看:KL 正则项迫使编码器"压缩"信息,将后验拉向各向同性的高斯球。这种强制均匀化必然丢失一些高频细节。
这个问题驱动了后来大量的改进工作。
六、VAE 的变体:沿两条主线演进
理解了原始 VAE 的局限之后,它的演进路径就很清晰了。主要沿两条线走:对 ELBO 本身动手(改变目标函数),以及改变潜变量的性质(从连续到离散)。
6.1 β-VAE:学会解耦
β-VAE(Higgins et al., 2017)是最简单也是影响最深远的变体之一。改动只有一行:
L β -VAE = E [ log p θ ( x ∣ z ) ] − β ⋅ D KL ( q ϕ ( z ∣ x ) ∥ p ( z ) ) \mathcal{L}_{\beta\text{-VAE}} = \mathbb{E}\left[\log p_\theta(x|z)\right] - \beta \cdot D_{\text{KL}}(q_\phi(z|x) \| p(z)) Lβ-VAE=E[logpθ(x∣z)]−β⋅DKL(qϕ(z∣x)∥p(z))
当 β > 1 \beta > 1 β>1 时,正则项被放大,迫使潜空间更靠近各向同性高斯,从而促使不同维度之间解耦(disentanglement)——即每个潜变量维度独立地对应一个可解释的数据生成因子(比如人脸的方向、光照、是否戴眼镜等)。
代价是重建质量的下降。 β \beta β 是一个需要手动调的超参数,控制"解耦程度"和"重建质量"之间的权衡。
为什么 β > 1 \beta > 1 β>1 会带来解耦?直觉上,强正则迫使编码器把每个 x x x 的信息高效地分配到尽量少的维度里,这种"信息压力"会自然地导致独立因子被分离到不同维度。更严格的理论解释至今仍有争议(Li & Liu, 2023 指出 β-VAE 有时表现得像 PCA,有时像 ICA,取决于训练细节),但实验结果是真实的。
6.2 CVAE:有条件地生成
条件 VAE(Conditional VAE, CVAE)在编码器和解码器中都引入了一个条件标签 c c c:
q ϕ ( z ∣ x , c ) , p θ ( x ∣ z , c ) q_\phi(z|x, c), \quad p_\theta(x|z, c) qϕ(z∣x,c),pθ(x∣z,c)
这让 VAE 可以做有条件生成——比如"给我生成一个数字 7",或者"给这张图加上晴天滤镜"。实现上, c c c 通常被拼接到输入或者通过 FiLM(Feature-wise Linear Modulation)等方式注入网络。
CVAE 在医学图像生成、数据增强、图像补全等任务上有大量应用。
6.3 VAE-GAN 及感知损失
直接解决模糊问题的思路是改掉 MSE 重建损失。一个经典做法是引入 GAN 的判别器,让重建损失变成感知损失:
L = L ELBO + λ ⋅ L GAN \mathcal{L} = \mathcal{L}_{\text{ELBO}} + \lambda \cdot \mathcal{L}_{\text{GAN}} L=LELBO+λ⋅LGAN
判别器学会区分真实图像和重建图像,编码器和解码器必须骗过判别器。这个思路催生了 VQGAN(后面会讲到),是现代高分辨率图像生成的基础组件之一。
另一种思路是用预训练的感知网络(比如 VGG)提取特征,在特征空间而非像素空间计算重建损失,俗称"感知损失(perceptual loss)"。
七、VQ-VAE:把连续潜空间换成离散码本
为什么需要离散潜变量?
连续的高斯潜空间在处理自然语言、语音、逻辑推理等任务时显得力不从心——这些模态天然是离散的。另外,连续潜空间有一个臭名昭著的问题叫后验崩塌(Posterior Collapse):当解码器足够强(比如强自回归模型)时,它会直接忽略 z z z,导致编码器输出的后验退化成先验,潜变量完全失效。
VQ-VAE(van den Oord et al., 2017)用一个根本性的设计改变解决了这些问题:把潜空间的连续向量替换成**向量量化(Vector Quantization)**得到的离散码。
VQ-VAE 的工作原理
VQ-VAE 维护一个码本(Codebook) { e 1 , e 2 , … , e K } ⊂ R D \{e_1, e_2, \ldots, e_K\} \subset \mathbb{R}^D {e1,e2,…,eK}⊂RD,其中 K K K 是码本大小, D D D 是向量维度。
编码器输出一个连续向量 z e ( x ) z_e(x) ze(x),然后通过最近邻查找把它量化到码本里最近的向量:
z q ( x ) = e k ∗ , k ∗ = arg min k ∥ z e ( x ) − e k ∥ 2 z_q(x) = e_{k^*}, \quad k^* = \arg\min_k \|z_e(x) - e_k\|_2 zq(x)=ek∗,k∗=argkmin∥ze(x)−ek∥2
解码器接收的是 z q ( x ) z_q(x) zq(x) 而不是 z e ( x ) z_e(x) ze(x)。
训练损失有三项:
L VQ-VAE = log p θ ( x ∣ z q ) ⏟ 重建 + ∥ z e ( x ) − sg [ z q ( x ) ] ∥ 2 2 ⏟ 码本损失 + β ∥ sg [ z e ( x ) ] − z q ( x ) ∥ 2 2 ⏟ commitment loss \mathcal{L}_{\text{VQ-VAE}} = \underbrace{\log p_\theta(x|z_q)}_{\text{重建}} + \underbrace{\|z_e(x) - \text{sg}[z_q(x)]\|_2^2}_{\text{码本损失}} + \underbrace{\beta\|\text{sg}[z_e(x)] - z_q(x)\|_2^2}_{\text{commitment loss}} LVQ-VAE=重建 logpθ(x∣zq)+码本损失 ∥ze(x)−sg[zq(x)]∥22+commitment loss β∥sg[ze(x)]−zq(x)∥22
其中 sg [ ⋅ ] \text{sg}[\cdot] sg[⋅] 是 stop-gradient 操作,阻断梯度传递。
量化操作本身是不可微的(argmin 没有梯度),VQ-VAE 用了一个叫**直通估计器(Straight-Through Estimator)**的技巧:前向传播时用 z q z_q zq,反向传播时把 z q z_q zq 的梯度直接复制给 z e z_e ze。随着训练进行, z e z_e ze 和 z q z_q zq 越来越近,这个近似越来越准确。
注意 VQ-VAE 没有 KL 散度项——码本相当于一个隐式的均匀分类先验,后验崩塌自然就消失了。
用自回归模型作为先验
VQ-VAE 生成的流程分两阶段:
- 训练 VQ-VAE,学会把图像压缩成离散码序列
- 用 PixelCNN 等自回归模型学习这些离散码的分布(先验)
生成时,先从自回归模型采样一串离散码,再送进解码器还原图像。把生成的困难问题转化到了低维离散空间,自回归模型在这里效果很好。
VQ-VAE-2:层次化扩展
VQ-VAE-2(Razavi et al., 2019)引入了层次化结构——用两层(或更多层)码本分别捕捉不同粒度的信息:
- 顶层码本(top-level codebook):低分辨率,捕捉全局语义(形状、姿态)
- 底层码本(bottom-level codebook):高分辨率,捕捉局部细节(纹理)
底层的解码还条件于顶层的码,保证局部和全局的一致性。先验用带多头自注意力的 PixelSNAIL 来建模,能捕捉长程依赖。
结果:在 ImageNet 上生成质量可以和当时最好的 GAN 媲美,同时没有 GAN 的训练不稳定和模式崩塌问题。
VQGAN 与现代 Tokenizer
2021 年的 VQGAN(Esser et al.)在 VQ-VAE 的基础上加入了 GAN 判别器和感知损失,大幅提升了重建质量。这个架构后来成为很多图像生成系统的"视觉 tokenizer"——DALL-E 的 dVAE 就是其近亲。
八、层次 VAE:更深的潜变量结构
原始 VAE 只有一层潜变量。但数据的生成过程往往是多层次的——比如人脸,有高层次的"是否戴眼镜",有中层次的"眼睛形状",还有低层次的"皮肤纹理"。
**层次 VAE(Hierarchical VAE)**把潜变量组织成多层,每层的后验依赖于上层和数据:
p θ ( x , z 1 , z 2 , … , z L ) = p θ ( x ∣ z 1 ) ∏ l = 1 L p θ ( z l ∣ z l + 1 ) p_\theta(x, z_1, z_2, \ldots, z_L) = p_\theta(x|z_1) \prod_{l=1}^{L} p_\theta(z_l | z_{l+1}) pθ(x,z1,z2,…,zL)=pθ(x∣z1)l=1∏Lpθ(zl∣zl+1)
推断网络也相应地变成层次化的。代表工作包括 LVAE(Sønderby et al., 2016)、BIVA(Maaløe et al., 2019)、NVAE(Vahdat & Kautz, 2020)。其中 NVAE 用了精心设计的残差网络和批归一化方案,在 CIFAR-10 等数据集上取得了当时最好的生成质量。
层次 VAE 的一个理论好处是:深层的 KL 散度(对应高层次的语义因子)通常比较小,不容易后验崩塌;浅层的 KL(对应低层次的细节)对重建质量起关键作用。合理的层次设计可以在解耦与重建之间达到更好的平衡。
九、VAE 与 Diffusion Model:一对奇妙的搭档
Diffusion 从 VAE 继承了什么
2020 年代之后,扩散模型(Diffusion Model)逐渐成为图像生成的主流范式。从数学上看,DDPM 可以被理解为一个特殊的层次 VAE:
- 前向过程(forward process):对应 VAE 的近似后验 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x),但不用神经网络参数化,而是固定的逐步加噪过程
- 反向过程(reverse process):对应解码器 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z),是学习的去噪网络
- 训练目标:同样是 ELBO 的变形,只是跑 T T T 步而非一步
DDPM 的变分下界可以写成:
log p θ ( x ) ≥ E q [ − 1 2 ∑ t = 1 T L t − L 0 ] \log p_\theta(x) \geq \mathbb{E}_q\left[-\frac{1}{2}\sum_{t=1}^T \mathcal{L}_t - \mathcal{L}_0\right] logpθ(x)≥Eq[−21t=1∑TLt−L0]
各项 L t \mathcal{L}_t Lt 对应不同噪声水平下的 KL 散度,而 L 0 \mathcal{L}_0 L0 是最终的重建损失——结构上和 VAE 完全同构,只是前向过程不需要学习。
这也是为什么研究者说"diffusion 就是一个非常深的 VAE"——这不是比喻,是数学等价。
Latent Diffusion Model(LDM):VAE 作为压缩器
Stable Diffusion 背后的核心架构叫潜在扩散模型(Latent Diffusion Model, LDM),它做了一个非常聪明的分工:
- 先用一个预训练的 VAE(KL 正则化的 AE)把图像从像素空间压缩到潜空间: 512 × 512 × 3 → 64 × 64 × 4 512 \times 512 \times 3 \rightarrow 64 \times 64 \times 4 512×512×3→64×64×4
- 在这个低维潜空间上训练扩散模型
VAE 在这里扮演的是"感知压缩(perceptual compression)"的角色——去掉高频的视觉冗余,保留语义结构。扩散模型则在语义层面做生成。
这个设计的好处是显而易见的:在 64 × 64 64 \times 64 64×64 的潜空间而非 512 × 512 512 \times 512 512×512 的像素空间做扩散,计算量下降了约 48 倍,同时生成质量基本不受损。
在推断时:扩散模型输出一个潜向量,VAE 解码器把它还原成像素图像。VAE 的权重在扩散训练阶段是冻结的。
视频生成中的 3D VAE
视频生成(Sora、CogVideoX、HunyuanVideo 等)在此基础上进一步扩展,用 3D 因果卷积的 VAE 同时在空间和时间维度做压缩,把视频压缩成时空潜向量。
一个典型做法是先训练 2D 图像 VAE,然后用它的权重初始化 3D VAE,在时序维度上额外学习时间压缩。这样可以减少从头训练的计算开销,同时利用图像 VAE 已经学到的空间感知能力。
十、后验崩塌问题:深入分析与解决方案
后验崩塌(Posterior Collapse)是 VAE 训练中最常见的失败模式,值得单独拎出来讲。
什么是后验崩塌
后验崩塌指的是训练完成后,编码器的输出后验 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 退化为先验 p ( z ) = N ( 0 , I ) p(z) = \mathcal{N}(0, I) p(z)=N(0,I),即 μ ϕ ( x ) ≈ 0 , σ ϕ ( x ) ≈ 1 \mu_\phi(x) \approx 0, \sigma_\phi(x) \approx 1 μϕ(x)≈0,σϕ(x)≈1,对所有 x x x 如此。这意味着潜变量不携带任何关于输入的信息,解码器完全忽略 z z z,直接生成"平均数据"。
为什么会发生:当解码器足够强(比如基于 Transformer 的自回归解码器)时,它可以不依赖 z z z 就能拟合训练数据。这样的话,KL 项变成了纯粹的惩罚,优化器会选择让 KL 降为零。
主要解决方案
KL 退火(KL Annealing):训练初期把 KL 权重设为 0,然后逐渐增大到 1。这给解码器时间先学会用 z z z,再逐渐被正则化。
Free Bits / KL Thresholding:对每个潜变量维度设置一个最小 KL 值,只有超过这个阈值的 KL 才纳入优化,等效地保护每个维度至少携带一定量的信息。
L KL = ∑ j max ( λ , D KL ( q j ∥ p j ) ) \mathcal{L}_{\text{KL}} = \sum_j \max(\lambda, D_{\text{KL}}(q_j \| p_j)) LKL=j∑max(λ,DKL(qj∥pj))
用 VQ-VAE:如前所述,离散化本身就解决了后验崩塌。
改变先验(Richer Priors):用混合高斯先验、VampPrior(用训练数据的伪输入来构建先验)等更复杂的先验,让先验更接近实际的聚合后验,减少 KL 正则的"拉力"。
十一、如何在代码里实现一个 VAE
为了接地气,这里用伪代码描述关键步骤。
编码器输出均值和对数方差:
mu, log_var = encoder(x)
# log_var 而非 var,确保数值稳定性
重参数化:
std = torch.exp(0.5 * log_var)
eps = torch.randn_like(std)
z = mu + std * eps
解码:
x_recon = decoder(z)
损失计算:
# 重建损失(二值数据用 BCE,连续用 MSE)
recon_loss = F.binary_cross_entropy(x_recon, x, reduction='sum')
# KL 散度的解析解
kl_loss = -0.5 * torch.sum(1 + log_var - mu.pow(2) - log_var.exp())
loss = recon_loss + kl_weight * kl_loss
几个实践中的注意事项:
- 通常不在 VAE 里用 Batch Normalization,因为 mini-batch 的额外随机性叠加在采样的随机性上会加剧训练不稳定
log_var要做 clamp,防止方差爆炸或消失(通常 clip 到 [ − 10 , 10 ] [-10, 10] [−10,10])- KL 权重(β)的调节非常关键,β=1 是理论正确值,但实践中经常需要根据任务调整
- 潜变量维度的选择对生成质量影响很大,太小欠容量,太大容易后验崩塌
十二、应用领域扫描
图像生成与编辑
这是最显眼的应用。从最早的 VAE 在 MNIST 上生成手写数字,到 VQ-VAE-2 在 ImageNet 上生成多样且高保真的图像,再到作为 Stable Diffusion 基础组件的 KL-VAE,VAE 贯穿了近十年图像生成的发展史。
在图像编辑领域,VAE 的潜空间可以做语义插值——在两张图的潜向量之间线性插值,解码出的图像会平滑地在两者之间过渡。β-VAE 的解耦潜空间还支持属性编辑——只改变代表某一属性的维度,其他属性保持不变。
分子生成与药物发现
化学分子的离散、非欧几里得结构让普通生成模型难以处理,但 VAE 可以把分子的图结构或 SMILES 字符串编码进连续潜空间,然后通过在潜空间里做贝叶斯优化来搜索具有特定性质(高药效、低毒性)的分子。
这是 VAE 在科学领域最重要的应用之一,2018 年的 Gómez-Bombarelli 等人的工作奠定了基础,此后衍生出大量针对蛋白质、材料、RNA 的变体。
异常检测
VAE 学会了正常数据的分布。对于异常样本,编码器无法找到一个好的 z z z 来重建它,重建误差就会很大,或者 q ϕ ( z ∣ x ) q_\phi(z|x) qϕ(z∣x) 与先验相差很远(KL 很大)。因此可以用重建误差和 KL 散度的组合作为异常分数。
这种方法的优势是不需要异常样本的标注,完全无监督。在工业质检、网络入侵检测、医疗影像等领域有大量应用。
自然语言处理
文本 VAE 的挑战比图像大得多,主要是后验崩塌和离散 token 不可微两个问题。
Bowman et al.(2016)首次把 VAE 用于句子生成,用 LSTM 作为解码器,配合 KL 退火来缓解后验崩塌。之后有大量改进工作,包括用更强的先验(如 VampPrior)、改用 Transformer 架构等。
VQ-VAE 在文本领域也有应用——把句子表示成离散码序列,然后用自回归模型建模,本质上和 BPE tokenization 的思路有相通之处。
语音与音乐
VAE 在语音合成(TTS)、语音转换(Voice Conversion)、音乐生成等任务上也有大量应用。代表工作 VITS(Kim et al., 2021)把 VAE 和 Flow 结合,实现了端到端的高质量语音合成。
十三、VAE 与其他生成模型的比较
这是个经常被问到的问题,简单梳理一下:
VAE vs. GAN:GAN 的生成质量(特别是高频细节)通常优于 VAE,但训练极不稳定,容易模式崩塌(mode collapse)。VAE 训练稳定,有明确的潜空间,但生成图像偏模糊。VQGAN 等工作是两者的结合。
VAE vs. 扩散模型:扩散模型在生成质量上目前碾压 VAE,但推断速度慢(需要多步去噪)。VAE 只需要一次前向传播。现代系统(LDM)把两者结合:VAE 做压缩,扩散模型做生成。
VAE vs. 归一化流(Normalizing Flows):归一化流要求编码器是精确可逆的双射,可以计算精确的似然,但架构受限。VAE 的编码器不需要可逆,更灵活,但只能得到 ELBO 而非精确似然。
VAE vs. 自回归模型(AR):自回归模型可以计算精确的对数似然,生成质量很高,但无法做高效的潜空间表示(没有显式的 z z z)。VQ-VAE + AR Prior 的组合试图结合两者的优势。
十四、近年的重要进展(2022 至今)
Consistency VAE 与 Stable VAE
随着 LDM 系列的成功,如何训练一个"对扩散模型友好"的 VAE 变成了新的研究方向。研究者发现,VAE 的 KL 正则强度对下游扩散模型的收敛速度有显著影响——KL 太弱,潜空间的分布离高斯太远,扩散模型难以拟合;KL 太强,重建质量下降,信息损失太大。
VA-VAE 与视觉基础模型对齐
2025 年的 VA-VAE 提出把 VAE 的潜空间与 DINOv2 等预训练视觉基础模型的特征对齐,让 VAE 的潜向量不仅重建质量好,还携带更丰富的语义信息,从而加快下游扩散模型的训练收敛。
Video VAE 的系统化
CogVideoX、HunyuanVideo、Wan 等视频生成模型都有专门为时序数据设计的 3D VAE。如前所述,这些 3D VAE 通常从 2D 图像 VAE 初始化,然后在时间维度上额外学习,用分组因果卷积来平衡不同帧之间的性能。
编解码架构的现代化
早期 VAE 用 MLP 或简单 CNN;现在的 VAE(比如 Stable Diffusion 里的 AutoencoderKL)用多层残差卷积配上注意力机制,encoder 和 decoder 都是 UNet 风格的,能处理高分辨率图像( 1024 × 1024 1024 \times 1024 1024×1024 甚至更高)。
结语:VAE 的历史地位
从 2013 年 Kingma 和 Welling 的那篇 “Auto-Encoding Variational Bayes” 算起,VAE 已经有十多年历史。它不是那种出来一两年就被遗忘的技术——相反,它成为了现代生成 AI 底层架构中不可缺少的一块砖。
Stable Diffusion 在用它,Sora 在用它,DALL-E 在用它,每一个现代文生图系统的底部,几乎都有一个 VAE 安静地做着"把像素压缩成语义向量,再把语义向量还原成像素"这件事。
它的广泛使用在于数学的完整性:从贝叶斯推断出发,到 ELBO,到重参数化技巧,每一步都有清晰的概率论依据,不是拍脑袋拼出来的。理解 VAE,你就同时理解了变分推断、潜变量模型、和现代生成模型的底层逻辑。
参考文献
- Kingma, D.P. & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv:1312.6114
- Higgins, I. et al. (2017). β-VAE: Learning Basic Visual Concepts with a Constrained Variational Framework. ICLR 2017
- van den Oord, A. et al. (2017). Neural Discrete Representation Learning (VQ-VAE). NeurIPS 2017
- Razavi, A. et al. (2019). Generating Diverse High-Fidelity Images with VQ-VAE-2. NeurIPS 2019
- Rombach, R. et al. (2022). High-Resolution Image Synthesis with Latent Diffusion Models. CVPR 2022
- Ho, J. et al. (2020). Denoising Diffusion Probabilistic Models. NeurIPS 2020
- Vahdat, A. & Kautz, J. (2020). NVAE: A Deep Hierarchical Variational Autoencoder. NeurIPS 2020
- Esser, P. et al. (2021). Taming Transformers for High-Resolution Image Synthesis (VQGAN). CVPR 2021
- Yao, Y. et al. (2025). VA-VAE: Vision Foundation Model Aligned Variational Autoencoder. arXiv 2025

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 7
7 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)