第二章:统计学习的崛起
第二章:让数据说话——统计学习的崛起
[!前情提要]
在第一章的结尾,我们提到,符号主义走到了它的认知边界:人类的大量隐性知识无法被写成规则,真实世界的复杂性也无法被穷举。虽然专家系统在受控环境里的表现令人印象深刻,但每当走出那个精心划定的领域,它就像踏空了一样——没有规则,不知所措。1980 年代末,AI 研究的资助机构开始失去耐心,AI 寒冬随之到来。在这段寒冬期间,反而促使一些研究者回头问了一个更根本的问题:如果知识不能被专家"说出来",那能不能从数据里自己"学出来"?
[!question]
用统计方法替代规则,机器能学到什么、学不到什么?这条路是否也有上限,上限在哪里?
2.1、范式转移:从"告诉"到"展示"
2.1.1、寒冬里的转向
1987 年秋天,美国国防高级研究计划局(DARPA)内部流传着一份令人沮丧的评估报告。
报告的结论并不隐晦:在过去十年里,AI 领域拿走了数以亿计的研究经费,但产出却远低于预期。符号主义曾经许诺的"通用智能",一再跳票。专家系统确实能解决一些具体问题,但它们太脆弱——稍微超出设计范围,就会给出荒谬的回答或直接崩溃。而维护这些系统的成本也越来越高,更新规则的速度永远跟不上现实世界的变化。
次年,DARPA 大幅削减了对 AI 研究的投资。这一消息传遍整个领域,大量项目被叫停,不少研究者转行。那些坚守下来的人,则必须面对一个迫切的问题:符号主义的路走不通了,下一步是什么?
这次的退场在全球范围内都是迅速而现实的。到 1990 年,美国多所顶级大学的 AI 实验室都在缩编:预算削减、研究生毕业后转投金融和工业界、许多做了十年专家系统的资深研究者重新包装自己去找"软件工程师"或"知识工程师"的职位。英国的情况则更早:1973 年的"莱特希尔报告"(Lighthill Report)就已经重创了英国 AI 资助,许多学者干脆离开了这个方向。日本通产省在 1980 年代斥巨资推进的"第五代计算机"计划,在十年后宣告基本失败,成了政府主导科技研发风险的典型案例。
留下来的研究者们,不得不用一种更谦逊的姿态重新定义"AI 能做什么"。他们不再追求"通用智能",而是用来解决"某一类具体任务"。AI 也不再是"模拟人类推理",而是用来"解决一个可以量化评估的预测问题"。这种务实化,听起来像是退步,却恰恰是一种关键的转变——把 AI 研究从哲学上的宏大愿景,拉回到了工程上的可操作问题。
答案,出现在一个看起来不那么"AI"的地方:统计学。
2.1.2 一个根本性的转变
符号主义的逻辑是:找领域专家,问他们"你是怎么做这个决定的",把答案写成规则,让计算机执行。
这个逻辑的问题,正如我们在上一章中曾说过:专家他自己也说不清楚。不是他们不愿意说,而是大量知识以隐性的方式存在于他们的经验里,无法被语言完整捕捉——医生看一眼 X 光片就知道"有问题",但他说不清楚自己是看到了什么、如何做出判断的。
于是,统计学习的研究者们换了一个思路:
不要问专家这个问题怎么做。而是给机器提供大量示例,让它自己从中找规律。
这个转变看起来简单,但影响深远。它把 AI 的工作从"编程"(把知识写进代码)变成了"学习"(从数据中提取知识)。知识的来源,从专家的头脑,转移到了数据里隐藏的统计规律。
这个转变还有一个更微妙的地方:它改变了"正确"的定义方式。在符号主义里,一个系统是否正确,取决于它的规则是否准确——需要和领域专家对照,规则有没有写错。在统计学习里,一个系统好不好,取决于它在数据上的预测准确率——不需要知道模型内部发生了什么,只需要在一批测试数据上验证它的输出是否正确。
这个"用数据来评估好坏"的框架,是机器学习能够系统化发展的基础。它让研究者可以对不同方法进行客观比较——不再依赖专家的主观判断,而是用实验结果说话。
这个评估框架的建立,标志着 AI 从一门"思辨学科"向"实验学科"的转型。在符号主义时代,判断一个 AI 系统好不好,很大程度上取决于创造者的自我陈述和同行的主观印象。统计学习引入的评估体系——保留一部分数据作为"测试集",用准确率、精确率、召回率等数字衡量性能——第一次让 AI 的"好坏"变成了客观、可重复的判断。这让不同方法之间的比较成为可能,也让研究进步可以被量化追踪。这种竞争性的基准文化由此逐渐成型:研究者不再只是发表一个新方法,而是要在公共数据集上证明它比所有已知方法更好。UCI 机器学习仓库、后来的 MNIST、最终是 ImageNet——这些公开基准测试,成了整个领域进步的可量化标尺,一直延续至今。
当然,这个框架也带来了它自己的问题:当模型在测试集上表现优异,但在真实世界中却一塌糊涂,我们该怎么解释?这些问题,我们在本章末尾会再次看到。
2.1.3 先驱者:在寒冬中坚持的人们
统计学习的崛起,并不是在某一天突然发生的。它的根源可以追溯到比 AI 更早的数学和统计学传统,在符号主义最辉煌的那些年里,它一直以相对低调的方式存在。
例如,贝叶斯统计的历史甚至比计算机更古老。18 世纪的托马斯·贝叶斯(Thomas Bayes,1701-1761,英国牧师兼数学家)在去世后留下了一篇未发表的手稿,描述了如何根据新的观测证据更新对某件事的概率判断。这个思想被他的朋友整理发表,200 年后成了机器学习的重要基础。
1960 年代,统计决策理论和模式识别(Pattern Recognition)已经有了相当成熟的数学基础。研究者们知道怎么用统计方法把图像中的字符分类,怎么识别简单的手写数字。但这些工作都处于边缘位置——符号主义是主流,拿到的资金最多。
真正的转机出现在 1990 年代,随着互联网的兴起,数据开始爆炸式增长。垃圾邮件、网页分类、搜索引擎排名……这些问题都有大量的训练数据,都需要"从例子中学习"的能力,而符号主义的规则系统对这些问题几乎无能为力。
于是,统计学习,找到了自己的舞台。
这个舞台上的第一批胜利任务,是看起来不那么令人兴奋的任务——邮政编码识别、信用评分、电话语音质量检测。这些成功,没有媒体报道,没有学术轰动,它们只是安静地跑在数以百万计的信件和交易背后的数学模型,一封一封地识别,一笔一笔地判断。
但这些不起眼的应用,积累了统计学习最需要的东西:真实数据、真实反馈、真实的工程经验。和专家系统不同,统计学习的效果是可以直接用数字衡量的——美国邮政局的手写邮编识别准确率从 80% 提升到 99%,信用卡欺诈检测的召回率提高了几倍。数字不撒谎。研究者们第一次有了一种量化的感觉:这条路是走得通的。

图 2.1:两种 AI 范式的对比。左边是"符号主义"的流程(领域专家 → 知识工程师提取 → 规则库 → 推理引擎 → 答案),右边是"统计学习"的流程(数据 + 标签 → 学习算法 → 统计模型 → 预测)。
2.2、贝叶斯方法:用概率描述不确定性
2.2.1 一封电子邮件和一个改变世界的想法
1990 年代末,有一个让所有上网用户都感同身受的问题变得越来越严重:垃圾邮件。
互联网的普及带来了电子邮件的爆炸式使用,随之而来的,是垃圾邮件的洪水。促销广告、诈骗信息、色情内容……这些邮件大量涌入每个人的收件箱。到 2000 年前后,一些重度用户的收件箱里,垃圾邮件的比例已经超过了 50%。
早期的垃圾邮件过滤系统,用的是符号主义的思路:手写规则。例如包含’免费领取’词汇的就是垃圾邮件、来自某些特定域名的是垃圾邮件……可这种方法很快就失效了。垃圾邮件发送者会故意把关键词变形——例如用,“fr3e” 代替 “free”(免费),“V1agra” 代替 “Viagra”(伟哥)——绕过规则过滤。这是一场永无止境的猫鼠游戏,而规则维护者总是会落后一步。
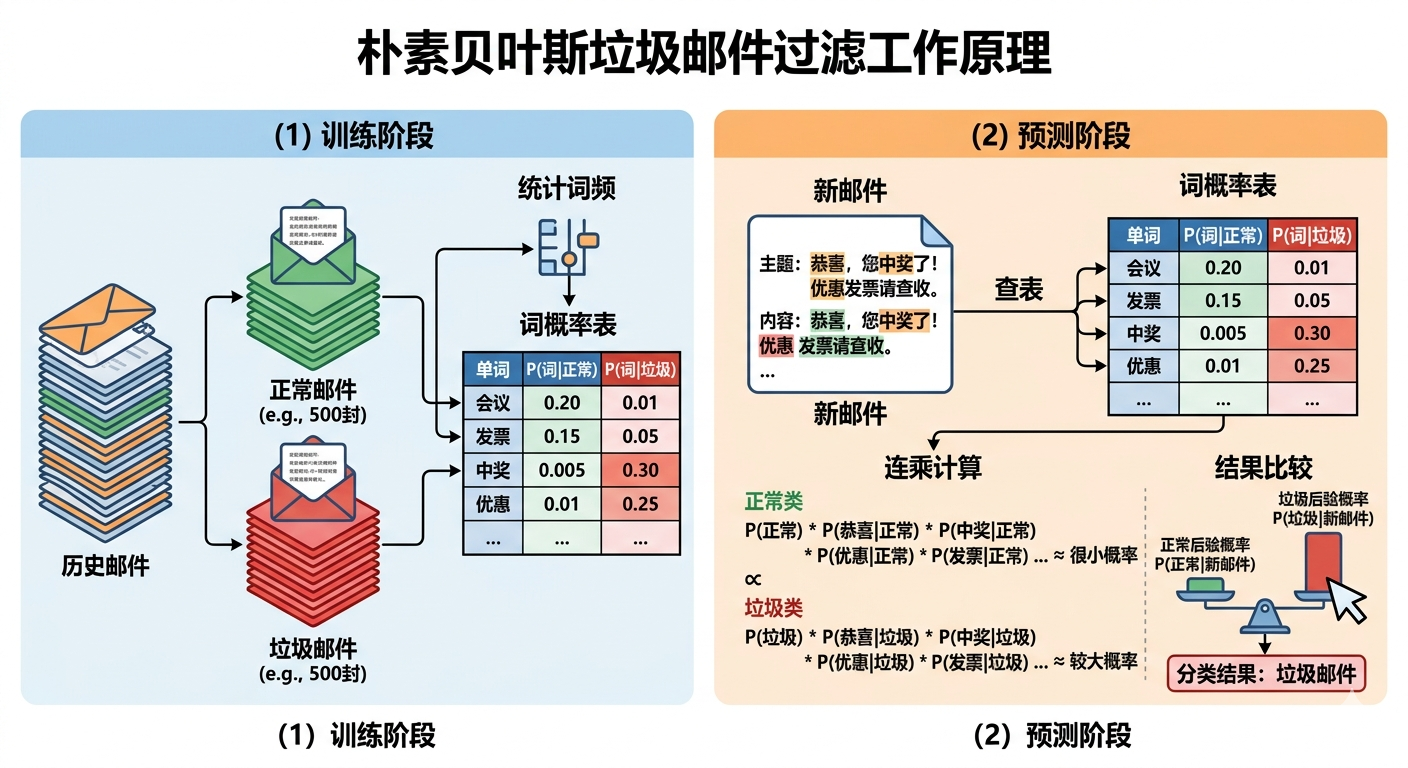
图 2.2:朴素贝叶斯垃圾邮件过滤的工作原理
1998 年,微软研究院的梅赫兰·萨哈米(Mehran Sahami)等人发表了一篇技术报告,提出了一个完全不同的思路:用朴素贝叶斯分类器(Naive Bayes Classifier)过滤垃圾邮件。但这篇报告在当时并没有引起太大的轰动,直到四年后,一篇出人意料的文章把这个想法带到了大众面前。
2002 年,一个名叫保罗·格雷厄姆(Paul Graham)的程序员和创业者,在自己的网站上发布了一篇题为《A Plan for Spam》的文章。这不是学术论文,而是一篇写给程序员同行的技术随笔。格雷厄姆用清晰的文字描述了他实现的朴素贝叶斯垃圾邮件过滤器,并分享了代码。这篇文章在 Slashdot(当时最重要的程序员社区)上被疯狂转发。在那之前,对大多数程序员来说,"机器学习"是一个遥远的学术概念,而这篇文章第一次让他们感受到:用几十行代码,用概率统计的方法,就可以做出一个比规则系统强得多的垃圾邮件过滤器。它不是论文,是可以直接跑起来的程序。
这个朴素贝叶斯分类器,后来被集成进了大量邮件客户端,成了互联网基础设施的一部分。Mozilla Thunderbird、苹果 Mail、微软 Outlook……在接下来几年里,主流邮件客户端纷纷集成了某种形式的贝叶斯过滤器。全球垃圾邮件比例在 2000 年代初一度超过 70%,朴素贝叶斯是阻止这个数字继续上升的主要防线之一。它让数以亿计的普通用户,在毫不知情的情况下,每天受益于统计学习。
更重要的是,格雷厄姆的这篇文章改变了许多程序员对"机器学习"的认知:它不是只有博士才能触碰的学术神器,而是可以用几十行代码实现、部署在真实应用里的工具。这种"机器学习是务实工程"的认知,在后来 scikit-learn、XGBoost 这类工具库的流行中得到了延续。
2.2 贝叶斯定理的直觉
贝叶斯定理(Bayes’ Theorem)告诉我们的是,如何怎么根据新的证据更新我们对某件事的判断。
如果我们用日常语言来表达:
- 你在街上看到一个人穿着白大褂。那他是医生吗?
- 你的初始判断可能是:可能是,因为一般医生才穿白大褂。
- 但如果你是在美容院门口,那穿白大褂是医生的概率就要修正——因为美容师也常穿白大褂。
- 但如果他手里还拿着听诊器,"他是医生"的概率就会大幅上升——听诊器和美容工作没有关系。
贝叶斯定理,就是将这个"根据新证据更新判断"的过程,形式化成数学公式:
P(医生∣白大褂,听诊器)=P(白大褂,听诊器∣医生)×P(医生)P(白大褂,听诊器)P(\text{医生} | \text{白大褂}, \text{听诊器}) = \frac{P(\text{白大褂}, \text{听诊器} | \text{医生}) \times P(\text{医生})}{P(\text{白大褂}, \text{听诊器})}P(医生∣白大褂,听诊器)=P(白大褂,听诊器)P(白大褂,听诊器∣医生)×P(医生)
而如果用在垃圾邮件上:
P(垃圾邮件∣包含"免费")=P(包含"免费"∣垃圾邮件)×P(垃圾邮件)P(包含"免费")P(\text{垃圾邮件} | \text{包含"免费"}) = \frac{P(\text{包含"免费"} | \text{垃圾邮件}) \times P(\text{垃圾邮件})}{P(\text{包含"免费"})}P(垃圾邮件∣包含"免费")=P(包含"免费")P(包含"免费"∣垃圾邮件)×P(垃圾邮件)
公式等号右侧的每一个概率,都可以从历史数据中统计出来:
- 在收到的所有邮件中,有多少比例的邮件是垃圾邮件?(先验概率,P(垃圾邮件)P(\text{垃圾邮件})P(垃圾邮件))
- 在所有垃圾邮件中,"免费"这个词出现的频率有多高?(似然概率,P(包含"免费"∣垃圾邮件)P(\text{包含"免费"} | \text{垃圾邮件})P(包含"免费"∣垃圾邮件))
- 在所有的邮件中,"免费"这个词出现的频率是多少?
有了这些统计数字,就可以计算出:当看到"免费"这个词时,这封邮件是垃圾邮件的概率(后验概率,P(垃圾邮件∣包含"免费")P(\text{垃圾邮件} | \text{包含"免费"})P(垃圾邮件∣包含"免费"))是多少。如果邮件里同时出现了"免费"、“领取”、“点击这里”、“限时优惠”……就把每个词的概率乘起来。这就是"朴素贝叶斯"——"朴素"的含义,是假设每个词的出现是互相独立的,虽然这个假设往往是相当草率的(例如"限时"和"优惠"往往一起出现),但数学上这可以使计算变得简单,而且实践中效果也出奇地好。
那为什么独立性假设虽然是不精准的,但管用呢?这是统计学习里一个深刻的工程智慧:模型的假设不需要在物理上精准,只需要在统计上有足够的判别力。朴素贝叶斯的独立性假设虽然低估了词之间的相关性,但这个"低估"对不同类别的影响是对称的——垃圾邮件和普通邮件的词都被同样地"独立化"了,所以相对的概率判断依然可信。
2.3 为什么这比规则好
朴素贝叶斯的优势,在对比手写规则时最为清晰:
- 规则系统的问题:垃圾邮件发送者学会了变形关键词,例如 “Fr33 V1agra” 可以绕过检测 “Free Viagra” 的规则。如果要更新这些规则,就需要人工察觉这个新变形,然后手动添加——永远处于被动状态。
- 朴素贝叶斯的优势:我们不再需要针对每个敏感词逐一编写变体规则。用户只需在邮件维度上进行标注(垃圾/非垃圾),工程师即可基于这些标注数据全量更新词频统计(如 P(词∣垃圾)P(\text{词} \mid \text{垃圾})P(词∣垃圾) 和 P(垃圾)P(\text{垃圾})P(垃圾))。这种数据驱动的更新方式,远比手动维护和测试规则列表更易规模化。
虽然这种“对抗性的韧性”一再被验证,但垃圾邮件发送者也开发了新的绕过手段:他们在邮件正文末尾藏入随机的小说节选或新闻文字,试图用大量无害词语稀释垃圾词汇的统计显著性。朴素贝叶斯模型在面对这种“稀释攻击”时,准确率确实出现了显著下滑。然而,防御方的应对机制依然占据优势:只需将这类邮件纳入训练集重新训练,模型便能逐步学习到这种“高噪声混合模式”的特征。虽然实践中往往辅以特征权重调整,但总体而言,垃圾邮件发送者每开发一种新策略,过滤器通过数据迭代更新的成本,远低于攻击方改变策略的成本。这场猫鼠游戏持续多年,主动权最终向过滤器一侧倾斜。
尽管这个"自动更新"的特性,在今天看来理所当然,但在 1990 年代的的确确是一个真实的突破。朴素贝叶斯给统计学习立下了一个范本,这个范本的核心特性也在后续所有的机器学习方法里反复出现:
- 从数据中估计参数,而不是手写规则
- 用概率表示不确定性,而不是非此即彼的二值逻辑
- 随新数据自动更新,而不是依赖人工维护
2.3、决策树与集成:多数投票的智慧
2.3.1 从概率到决策路径
贝叶斯方法擅长处理"概率性的是/否判断",但现实的预测问题往往更复杂——不只是判断一件事,而是需要在多个条件的交叉组合下做决策。
我们可以想象一个银行的信贷审批场景。银行要判断是否给一个客户发放贷款。判断依据不是单一的"这个人的收入高不高",而是需要考虑多个因素的组合:月收入是多少、现有债务是多少、信用历史如何、工作稳定性、年龄……,这些因素之间还有交互关系:一个月收入 3 万但已有 200 万债务的人,和月收入 8 千但没有任何债务的人,哪个更容易还款?
面对这类问题,我们需要一种能够捕捉特征之间复杂交互关系的模型。而决策树(Decision Tree)提供了一种直觉上非常接近人类思考过程的方式:
月收入 > 1万元?
├── 是 → 现有债务/月收入 < 40%?
│ ├── 是 → 信用历史良好?
│ │ ├── 是 → 批准贷款(低风险)
│ │ └── 否 → 需要抵押(中等风险)
│ └── 否 → 拒绝贷款(高风险)
└── 否 → 工作年限 > 3年?
├── 是 → 批准小额贷款(中等风险)
└── 否 → 拒绝贷款(高风险)
决策树的构建过程,是从数据中自动找到"哪个特征最能区分不同结果",然后以此为节点,递归地把数据分割成越来越纯净的子集。这个"最能区分"的标准,通常用信息增益(Information Gain)或基尼不纯度(Gini Impurity)来衡量。
决策树有几个显著的优点:可解释性强(每一个决策路径都是清晰可见的)、处理非线性关系(不假设特征和结果之间是线性关系)、对异常值鲁棒(树的分裂基于排序,不是数值计算)。
2.3.2 过拟合:决策树的致命弱点
尽管决策树有上述多项优点,但它也有一个让研究者非常头疼的问题:过拟合(Overfitting)。
过拟合是机器学习中一个核心概念,值得我们花时间讨论一下。
想象以下,假如你目前正在准备一场考试,通常来说有两种复习策略:
策略 A:把历年考题的所有题目和答案背下来。对历年真题,你能考满分。但如果遇到稍有不同的新题,你就不知道该怎么应对,因为你背的是"答案",不是"原理"。
策略 B:理解每道题背后的原理和解题思路。在历年真题上的成绩可能不如用策略 A 完美,但遇到新题时,你能灵活应对。
机器学习中的过拟合,就像策略 A 中存在的问题:模型只是自以为聪明地"记住"了所有的训练数据,包括数据中的噪声和特例,能够在训练数据自身上完美的解决问题,可一旦将其应用于此前未见过的新数据上,并失去了解决问题的泛化能力。
对于决策树,如果允许它长得足够深——每一片叶子只包含一个训练样本——那它就可以完美的分类所有训练数据(本质上是记住了每个样本)。但这样的树模型在新数据上通常表现较差,因为它学到的只是"这些特定的样本有这个标签",而不是"这类样本一般有这个标签"。
2.3.3 随机森林:集成的智慧
针对决策树过拟合的问题,利奥·布雷曼(Leo Breiman,1928-2005,加州大学伯克利分校统计系教授)提出了一系列的解决思路,并于 2001 年正式将其演化成了随机森林(Random Forest)算法并发表。布雷曼是统计学和机器学习之间的桥梁人物——他一只脚站在严格的数理统计里,另一只脚踏进了当时方兴未艾的算法世界。
随机森林的核心思想,是借用了一个非技术领域的经典智慧:群体的判断往往比个体更准确。
1907 年,英国科学家弗朗西斯·高尔顿(Francis Galton,1822-1911,统计学先驱)在一次乡村集市上观察到一个有趣的现象:有大约 800 个人参加了一场猜牛体重的竞赛。当高尔顿统计所有人的猜测的中位数时,他发现这个中位数是 1207 磅,而牛的实际体重是 1198 磅——误差不到 1%。任何单独参与者的猜测,都不如群体的平均值准确。高尔顿把这个现象发表在《自然》杂志上,题为 “Vox Populi”(人民的声音),后来被称为群体智慧(Wisdom of Crowds)。
随机森林把同样的思路用在了决策树上:
- 从原始训练数据中,随机抽取多份子样本(有放回地抽取,每份子样本大小和原始数据相同)
- 对每份子样本,训练一棵决策树——但在每次分裂节点时,不是从所有特征中选最优,而是随机选取一个特征子集,从这个子集中找最优分裂
- 预测时,把所有树的预测结果收集起来,分类问题投票取多数,回归问题取平均
那为什么这样做比单棵树更好?
因为每棵树的错误是不同的。 单棵树的过拟合,是它"记住"了某些训练样本的特定模式。但如果每棵树都在不同的数据子集和特征子集上训练,它们记住的"错误"是不同的、随机的。当把所有树的预测取平均时,这些不同的错误会互相抵消——而共同的、真实的规律则会被放大。
用统计语言说:随机森林降低了方差(减少了模型因为训练数据的随机性而产生的波动),而不显著增加偏差(不系统性地偏离真实答案)。这就是所谓"偏差-方差权衡"(Bias-Variance Tradeoff)的工程体现。
随机森林在实践中的效果非常强大。在 2000 年代到 2010 年代初,它是处理结构化数据(表格数据)的最强武器之一,被广泛应用于金融风控、医学预测、生物信息学等领域。它的一个重要优点是几乎不需要调参——相比 SVM(支持向量机,将在后文中介绍) 需要仔细选择核函数和正则化参数,随机森林在大多数情况下"开箱即用"就能给出不错的结果。
随机森林还有一个被低估的附赠功能:特征重要性(Feature Importance)的自然计算。在训练完成后,它可以统计每个特征在所有树的所有分裂节点里平均降低了多少不纯度,得到一个"这个特征对预测有多重要"的排名。这在 2000 年代被大量用于高维数据的特征筛选——当一个生物信息学家不确定 2 万个基因里哪些和某种疾病相关时,先用随机森林跑一遍特征重要性排名,是一个既快速又相对可靠的初步筛选方法。统计学习因此也不再只是一个预测工具,也成了一个重要的数据理解工具。
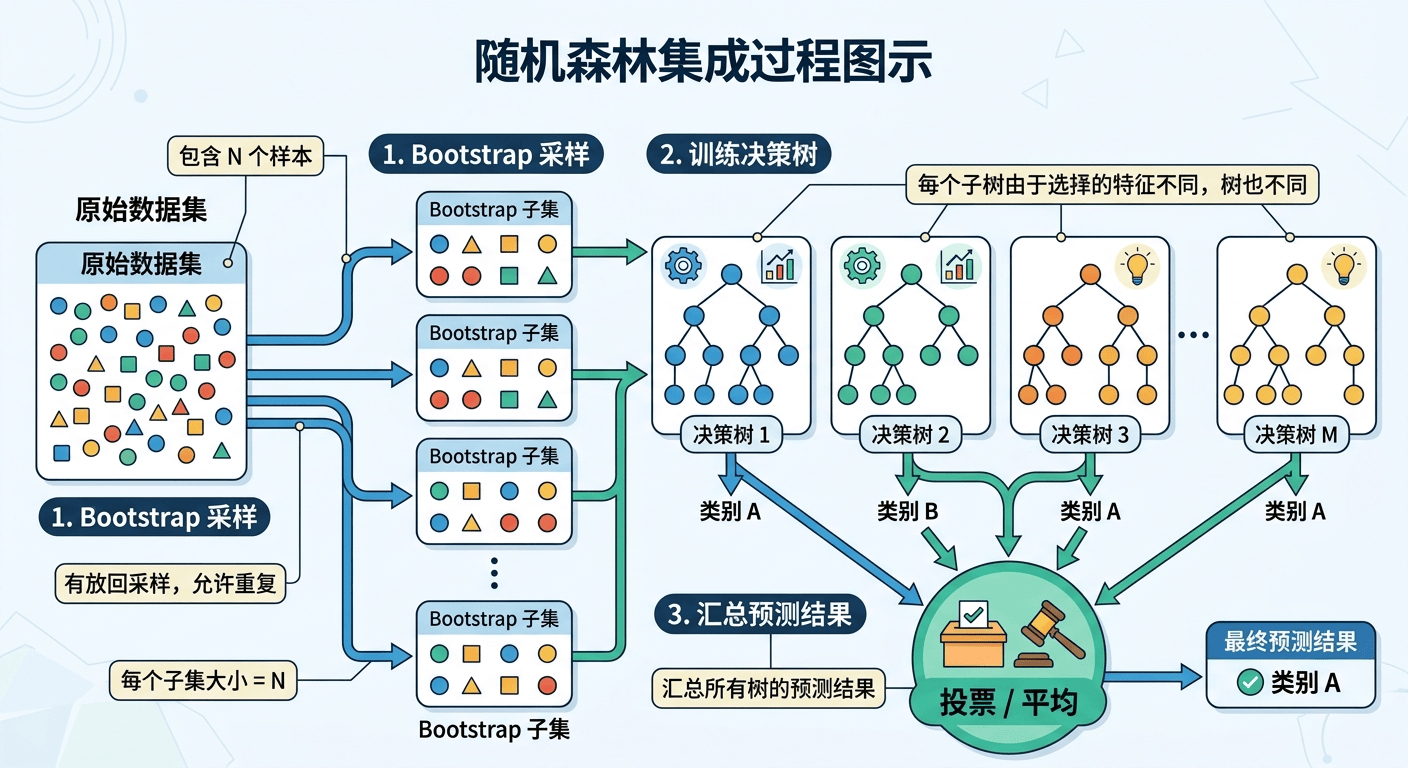
📊 图 2.3:随机森林的集成过程
2.4、支持向量机:几何美学的胜利
2.4.1 从苏联到贝尔实验室
1990 年,一名苏联数学家在苏联解体前夕,带着一个尚未完成的理论移民到了美国。
他叫弗拉基米尔·瓦普尼克(Vladimir Vapnik,1936-,苏联/美国数学家与计算机科学家),曾在苏联科学院工作二十余年,专注于统计学习理论——在当时,这是一个极度小众的领域,在苏联的那段岁月中,他的研究几乎无人知晓。到美国后,他加入了 AT&T Bell Labs,在那里,他终于找到了能理解他工作的同伴,也找到了计算资源来验证他的理论。
1992 年,在蒙特利尔举办的计算学习理论年会(COLT)上,瓦普尼克和他的同事介绍了一种新的分类算法——支持向量机(Support Vector Machine,SVM)。那次演讲对许多参会者来说有些难以消化:瓦普尼克的理论框架——VC 维理论(Vapnik-Chervonenkis Theory)、结构风险最小化、泛化误差上界——是从严密的统计学习理论里一步步推导出来的,需要相当深厚的数学功底才能跟上。但那些真正理解了的人,改变了机器学习的方向。1995 年,他们发表了更完整的版本,加上了核方法(Kernel Method),SVM 的威力开始显现。
接下来的几年里,SVM 开始在机器学习竞赛中横扫对手。它的成功有两个来源:一个是实验结果,另一个同样重要——它有严格的理论保证。瓦普尼克花了二十年建立的 VC 维理论,为 SVM 的泛化误差提供了数学上的上界。这在当时的机器学习领域是罕见的:大多数算法是"凑出来的",而 SVM 是从严密的数学推导里生长出来的。
这让 SVM 成了一种"有品位"的方法:不只是效果好,还说得清楚"为什么好"。
2.4.2 一条线,两个世界
SVM 的核心思路,可以用一个非常干净的几何问题来描述。
想象在一张纸上,有两类点:红点和蓝点。你需要画一条线把它们分开,让红点在线的一侧,蓝点在线的另一侧。
如果这两类点是线性可分的(可以用一条直线分开),你可以画出无数条这样的线。但哪一条是"最好"的呢?
SVM 的答案:找那条让两类点之间的"间隔"(Margin)最大的线。数学上可以证明,这是泛化能力最强的选择——分界线离两类点都尽可能远,意味着新来一个未见过的点,需要偏离得非常远才会被分错类。
这里有一个精妙的地方:真正决定分界线位置的,只与离分界线最近的那几个点相关——这些点就叫做支持向量(Support Vectors)。其他所有的训练样本,对分界线的位置没有任何影响,这也是显而易见的。
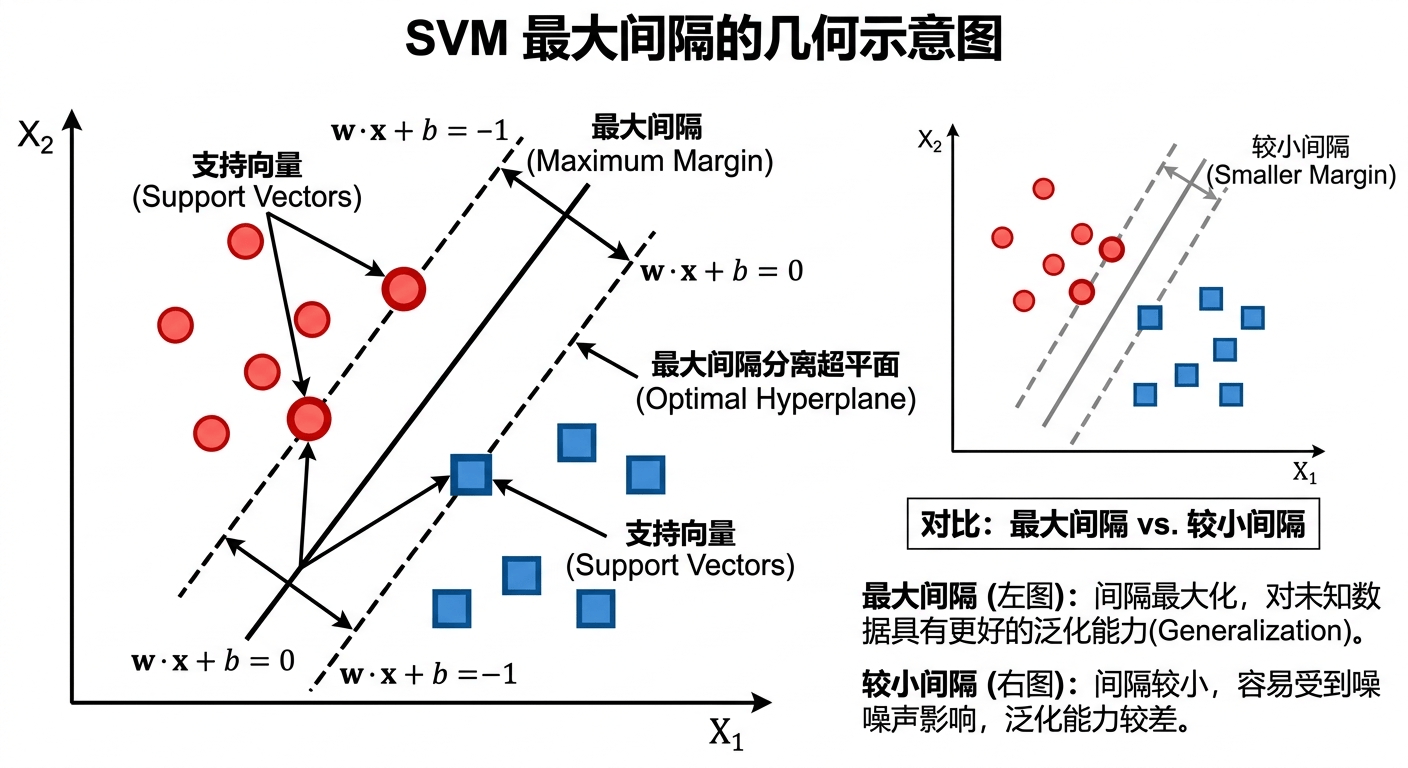
📊 图 2.4:SVM 最大间隔的几何示意图
2.4.3 核方法:把数据送入高维宇宙
SVM 的最大间隔思想很优雅,但有一个明显的限制:它只能分类线性可分的数据。
但真实世界的数据很少是线性可分的。我们来看一个经典例子:在二维空间里,一类点分布在圆环上,另一类点分布在圆的内部。无论怎么画直线,都无法将这两类点分开——它们的分界是圆,不是直线。
核方法(Kernel Method)给出了一个极其精妙的解决方案:
把数据映射到更高维的空间,在那里,它们可能就线性可分了。
还是圆环这个例子。如果给每个点加一个新的维度 z=x2+y2z = x^2 + y^2z=x2+y2(到原点距离的平方),那么圆环上的点 zzz 值大,圆内部的点 zzz 值小——在三维空间里,就可以被一个水平面完美分开。
但问题是:把数据映射到高维空间,计算代价极高。如果映射到数百万维甚至无穷维,计算量会迅速爆炸而不可行。
核方法有一个美妙的数学技巧,叫做核技巧(Kernel Trick):
在 SVM 的数学推导中,数据点只以两两内积的形式出现——即 ⟨xi,xj⟩\langle x_i, x_j \rangle⟨xi,xj⟩。如果能找到一个函数 K(xi,xj)K(x_i, x_j)K(xi,xj),它等于"在高维空间中 ϕ(xi)\phi(x_i)ϕ(xi) 和 ϕ(xj)\phi(x_j)ϕ(xj) 的内积",那么就不需要真正计算高维映射 ϕ\phiϕ,只需要计算这个核函数的值就好了。
历史上有如下几种常见的核函数:
- 线性核:K(xi,xj)=xi⋅xjK(x_i, x_j) = x_i \cdot x_jK(xi,xj)=xi⋅xj(原始 SVM)
- 多项式核:K(xi,xj)=(xi⋅xj+c)dK(x_i, x_j) = (x_i \cdot x_j + c)^dK(xi,xj)=(xi⋅xj+c)d
- 高斯核(RBF 核):K(xi,xj)=exp(−γ∥xi−xj∥2)K(x_i, x_j) = \exp(-\gamma \|x_i - x_j\|^2)K(xi,xj)=exp(−γ∥xi−xj∥2)(隐式映射到无穷维空间!)
使用高斯核的 SVM,相当于把数据映射到了无穷维的特征空间,然后在那里找最大间隔超平面——且计算复杂度和使用线性核差不多。SVM 或许是数学的优雅性与工程的实用性完美结合的最佳示例。
2.4.4 SVM 的统治时代
装备了核方法的 SVM,在 1990 年代末到 2000 年代初,成了机器学习领域的标配利器。
例如,在手写数字识别的标准测试集 MNIST 上,2000 年代初的排行榜被各种 SVM 变体占据。这个数据集有特殊的象征意义——它是贝尔实验室的杨立昆(Yann LeCun,1960-,深度学习领军人物)在 1990 年代用卷积神经网络(CNN,深度神经网络的代表作)打出好成绩时使用的数据集。现在,SVM 在这个数据集上与 CNN 可以平起平坐,甚至在某些变体上超越它——还不需要卷积结构,不需要专门设计的网络架构,只需要核函数和精心选择的超参数即可。
这个时代的顶级 AI 期刊和会议——NIPS、ICML、JMLR——逐渐被 SVM 和核方法的论文主导。SVM 不只是一个算法,它代表了一种研究文化:严格、优雅、有理论保证。在 SVM 的全盛期,一篇关于神经网络的论文,如果没有在同一数据集上和 SVM 进行比较,几乎不可能被顶级会议接收。“你为什么不用 SVM?”——杰弗里·辛顿(Geoffrey Hinton,1947-, 深度学习领军人物)**的学生们在那个年代每次提交论文前都需要预先准备回答的问题。
与此同时,即使是拥有真实工业应用的神经网络,也难以改变学术界的风向。杨立昆在贝尔实验室用 CNN 做支票手写数字识别,每天处理数以千万计的真实支票——这是一个比 MNIST 大得多的工业级应用。但即便如此,在追求严格数学的研究者看来,神经网络是工程师的"黑魔法",不是理论上可以分析的科学对象。没有理论保证的模型,不值得认真对待。
杨立昆曾经描述过这个时代的气氛:SVM 给了神经网络研究者很大的压力。因为 SVM 不只是"效果好",它还有严格的理论保证——统计学习理论提供了 SVM 泛化误差的上界。相比之下,神经网络在当时既没有理论保证,训练也不稳定。
很多研究者在这个时代真心相信:神经网络是一条死路,SVM 才是未来。
这个信念,在大约 2012 年被彻底打碎。但那是后面的故事。
2.5、特征工程的黄金时代
2.5.1 什么是特征?
到目前为止,我们谈到的所有机器学习方法——朴素贝叶斯、决策树、SVM——有一个共同的假设被默默接受了:
特征是需要人来设计的。
“特征”(Feature)是你喂给机器学习模型的输入——你用什么来描述你要分类或预测的对象。判断邮件是否垃圾:特征是每个词出现的次数。判断贷款是否违约:特征是月收入、债务比、信用评分……判断图像里有没有猫:特征是……什么?你需要先能回答"猫的哪些属性是稳定的",才能设计出能捕捉这些属性的特征——猫耳朵的形状?皮毛的纹理?眼睛的比例?每一个候选都需要被翻译成可计算的数字,然后验证在真实数据上是否真的有判别力。
这个问题,在 2000 年代让计算机视觉研究者们花费了大量的精力。你当然可以用原始像素值作为特征——一张 100×100 的灰度图就有 10000 个特征。但原始像素有两个严重的问题:维度太高(需要海量训练样本才能不过拟合)、缺乏语义不变性(猫向左移 10 像素,所有像素值都变了,但还是同一只猫)。
2.5.2 手工特征的巅峰
研究者们花了大量时间,开发出了一套手工设计的图像特征,试图捕捉图像中"稳定的、有语义的"信息:
HOG(Histogram of Oriented Gradients,方向梯度直方图)
该特征由纳夫尼特·达拉尔(Navneet Dalal)和比尔·特里格斯(Bill Triggs)在 2005 年的 CVPR 上提出。HOG 把图像分成小的格子,计算每个格子内边缘的方向分布,然后把所有格子的分布直方图拼起来,作为整张图像的描述符。
HOG 的设计直觉来自一个重要观察:物体的形状,主要由边缘的分布决定,而不是颜色或纹理。一个人形,不管穿什么颜色的衣服,轮廓的边缘分布是相似的。HOG 配合 SVM,在行人检测任务上取得了当时的最好结果,被广泛用于自动驾驶的行人检测系统。

SIFT(Scale-Invariant Feature Transform,尺度不变特征变换)
该特征由大卫·洛维(David Lowe,不列颠哥伦比亚大学教授)在 1999-2004 年开发。SIFT 要解决的问题比 HOG 更难:在图像中找到稳定的关键点,并为每个关键点生成一个描述符,使得同一个物体的关键点,在不同的尺度、旋转、光照条件下,能被识别为同一个点。

SIFT 的工作方式精妙:在多个尺度下检测图像的极值点,过滤掉不稳定的点,为每个稳定的关键点计算一个 128 维的描述符,基于关键点周围区域的梯度方向直方图,并对旋转做归一化。SIFT 关键点匹配在图像拼接(全景照片)、3D 重建、图像检索等任务上取得了当时极好的效果,成了 2000 年代计算机视觉的核心工具之一。
在 2000 年代初期的图像识别项目里,完整的工程流水线大概是这样的:先用 SIFT 或 HOG 提取图像的局部描述符,然后用 k-means 聚类所有描述符建立"视觉词典"(Visual Vocabulary),再把每张图片表示为词典中各"视觉词"出现的频率直方图——这个技术叫词袋模型(Bag of Visual Words),把图像问题转化成了类似文本分类的形式——最后把这个直方图向量喂给 SVM 分类器。这套流水线,需要计算机视觉知识和大量工程经验,是 2000 年代 AI 工程师必需掌握的核心技能。
2.5.3 特征工程是一门艺术,也是一个瓶颈
除了 HOG 和 SIFT,2000 年代的计算机视觉领域还有大量其他手工特征:LBP(局部二进制模式,描述局部纹理)、SURF(SIFT 的更快版本)、Haar 特征(用于人脸检测)、Color Histograms(颜色直方图)……
这些特征的开发,需要深厚的视觉认知知识和大量的工程经验。一个好的特征工程师,是 2000 年代 AI 界最稀缺的人才之一。
但这个现象本身,也是一个警示信号。
想象一个那个时代的 AI 工程师,他可能在汽车检测任务上积累了两年的特征工程经验,手里有一套在路况监控摄像头上表现很好的特征组合。也许未来有一天跳槽到医疗领域行业中,他现在接到了一个新任务:要求在医学 CT 图像里检测肺结节。
他的汽车检测经验,对这个新任务几乎没有任何帮助。道路场景中有意义的边缘方向、纹理梯度,和肺部组织的影像特征之间,没有任何关联。她需要请教放射科医生,从头开始学习"什么是有意义的肺部影像特征",然后再花一年时间把这些新知识转化成特征向量。
而当下一个任务来临——也许是卫星图像的建筑物识别——整个过程又要重来一次。
每个领域,每个新任务,都需要重新设计特征。知识在领域之间无法迁移。 AI 的效果好不好,太依赖于人类工程师的经验和洞察力了。
那个研究者的工作日志,也许是这样的:前两周,和医院的放射科医生反复开会,学习"肺结节在 CT 图像上看起来是什么";接下来一个月,把这些直觉翻译成代码,测试各种特征组合;然后是漫长的调试——某个特征组合的 AUC 从 0.72 提升到了 0.78,但到 0.80 就卡住了。第五个月,他发现之前忽略了 CT 扫描的"层厚"参数,不同层厚会导致结节大小的感知偏差,于是推倒前面的特征设计,从头再来。
这不是失败的项目,这就是那个时代最优秀 AI 工程的正常节奏。最好的特征工程师,是那些磨炼出了"在数据里感知意义"这种直觉的人——这是结合了领域知识、统计感觉和工程经验的罕见技能,在一个领域花几年才能真正熟练。然后换个领域,一切又从零开始积累。
2.6、(选读)模型的考场:让性能数字有意义
特征工程解决的是"输入"的问题——用什么数字描述世界。但还有另一半问题一直潜伏着:当你花了几个月设计出一套完整的特征流水线,怎么知道它真的有效,而不是在自欺欺人?
每个 ML 工程师做完特征工程之后,立刻就要面对这个问题。正如我们前文所言,一个模型在训练集上的高准确率,本身证明不了任何事——它完全可能只是把所有训练样本的答案都"背下来了",遇到新数据就一败涂地。评估一个模型,必须用它从未见过的数据,而如何建立这个公平的"考场",是统计学习时代工程实践的隐性基础设施——它不在论文标题里,但它的严肃程度决定了所有性能数字是否值得信任。
2.6.1 三路切分:训练集、验证集、测试集
正如我们在介绍过拟合概念时所描述的那样,如果我们用手头上所有的数据进行训练,然后在同一批数据上测试准确率。这个想法是错的,而且错得离谱。
用来训练的数据,模型已经"见过"——它已经被反复告知"这张图是猫"、“那封邮件是垃圾”,然后调整自己的参数去拟合这些答案。如果用同样的数据测试它,它当然表现很好——但这和"背了答案来考试"没有本质区别,和它在真实世界里面对新数据时的能力毫无关系。
统计学习的工程实践,发展出了一套标准的数据三路切分方式:
- 训练集(Training Set):用来训练模型,也就是调整模型参数的那批数据,模型直接从它身上进行"学习"。
- 验证集(Validation Set):用来在训练过程中做模型选择和超参数调整(将在后文中解释)。模型不直接从验证集上学习,但工程师会看验证集上的表现来决定调整什么。
- 测试集(Test Set):用来最终报告模型性能的那批数据。关键规则是:在最终决定好模型之前,测试集不能被看。
为什么需要把验证集和测试集分开?这里有一个微妙但关键的地方。假设你在验证集上测了 50 种超参数组合,选了表现最好的那个,这时验证集上的表现已经被"污染"了——你在无意中"拟合"了验证集。
我们可以通过一个形象化的示例来进一步解释这个过程,例如一个班上有 50 名学生(类比为 50 个不同的模型),老师用同样的一摞练习题(训练集)试图来指导这 50 个学生做数据题,这就是模型的训练过程,我们往往会一次性训练多个模型出来,它们的主要差异在于超参数不同(可类比为由于一些因素,每个学生的先天资质不同)。那么如果这个老师想让他的学生们未来代表学校参加一个国际性比赛,这个老师会派谁去呢?
自然的想法是,这位老师自己再模拟出一套试题(验证集),然后选择分数最高(比如 95 分)的那位同学作为代表,然后这位老师就信誓旦旦的对校长承诺,我们的学生已经具备了 95% 的准确率。
如果不巧的是,你恰好是此次测试中成绩第 2 的同学,你有话要说吗?(!@#¥%……)
对,就是这样,如果你把验证集上的最好成绩当成最终性能报告,会系统性地高估模型的真实能力。测试集存在的意义,正是提供一个从未被看过的"干净"评估。这个规则在学术界和工业界都有大量违反的案例。2000 年代有很多竞赛和论文,研究者把测试集的标签泄露进了训练或验证过程,报告了虚高的性能——这种现象后来被称为数据泄露(Data Leakage),是模型评估中最常见也最危险的错误之一。
2.6.2 超参数:调参这件难事
在模型的训练过程中,有两类不同性质的"数字"。
- 模型参数(Parameters)是训练过程中自动学习的:如神经网络的权重、SVM 的支持向量位置、决策树的分裂阈值——这些是模型从数据中直接优化的量。
- 超参数(Hyperparameters)是你在训练之前就必须手动决定的、不被自动优化的设置:如决策树的最大深度、随机森林里树的数量、SVM 的正则化系数 CCC、高斯核的参数 γγγ……这些值不同,学到的模型就完全不同。
超参数调整是统计学习时代最让工程师头疼的日常任务之一,主要原因有:
- 第一,超参数空间很大。 一个 SVM 有两个关键超参数(C 和 γ),即使每个参数各取 10 个候选值,就有 100 种不同的组合。随机森林可能有 4-5 个超参数,如果每个也各取 10 个值,就是 10 万种不同的组合。
- 第二,每次评估都要训练一遍模型。 这意味着评估 100 种超参数组合,就要训练 100 个模型,每次可能需要几分钟到几小时,即使考虑并行训练,也可能需要额外大量的硬件资源。
- 第三,超参数之间往往有交互效应。 SVM 的 CCC 和 γγγ 不是独立的:某个 CCC 值在 γγγ 很小时表现好,换一个 γγγ 就完全不同。你无法通过单独优化每个超参数找到最优组合。
最朴素的方法是网格搜索(Grid Search):把每个超参数的候选值列出来,穷举所有组合,在验证集上测试,选最好的。这个方法简单、可靠,但计算代价大。更聪明的方法是随机搜索(Random Search):在超参数空间里随机采样若干组合测试,研究表明在大多数情况下,随机采样 60-100 次的效果接近穷举所有组合,计算量却少得多。
这里有一个关键的纪律性要求:所有超参数调整必须在验证集上进行,测试集在整个调参过程中保持封存。违反这个规则,调出来的超参数是为测试集量身定制的,报告的性能数字则毫无意义。这个规则在实际工程中被反复违反,也是论文结果无法复现的常见原因之一。
2.6.3 交叉验证:小数据集的救星
三路切分有一个明显的问题:当数据量很小时,拿出 20-30% 做验证和测试集,留给训练的数据就明显不足了,当训练样本不充足,模型可能学不好。而且,验证集只有几百个样本时,验证集上的性能数字本身就有很大的随机波动——调出来的超参数,可能只是恰好在这几百个样本上表现好,而不是真正的泛化最优。
K 折交叉验证(K-Fold Cross-Validation)是解决这个问题的常见解决方案:
- 把数据随机打乱,分成 KKK 份(通常 K=5K=5K=5 或 K=10K=10K=10)
- 做 KKK 次实验:每次用其中 K−1K-1K−1 份作为训练集,剩下 1 份作为验证集
- KKK 次实验的验证集性能取平均,作为这组超参数的评估分数
这样,每个样本都有机会作为一次验证集,评估结果利用了所有的数据,且统计上更可靠。代价是计算量变成了 KKK 倍——K=10K=10K=10 意味着要训练 10 个模型才能评估一组超参数。
这些工具——如三路切分法、超参数搜索、交叉验证等,共同构成了统计机器学习时代的评估基础设施。它们都是从工程实践中磨砺出来的方法论。一个统计学习时代的 ML 工程师,不管用什么算法,都要在这套基础设施上工作。理解这套基础设施,也是理解"为什么深度学习的出现不只是换了个算法,而是整个工作流程的变革"的前提。
2.7、统计学习的天花板
2.7.1 天花板一:特征设计的人力瓶颈
统计学习能学到什么,其上限主要由特征工程能发现什么来决定。如果你的特征没有捕捉到任务所需的信息,模型无论多么复杂、训练数据无论多么丰富,都无法弥补这个缺失。
举一个具体的例子。2000 年代中期,有研究团队尝试用机器学习做"情感分析"——判别一段产品的评论是正面还是负面的。用 SVM,用朴素贝叶斯,在英文评论上效果都还不错。然后他们把同样的方法迁移到中文评论上,结果大幅下降——这并不是因为算法不够好,而是因为中文的情感表达方式和英文有根本不同:大量情感信息隐藏在语气词、反讽结构、特定的文化语境里,而这些,之前的英文特征系统中未完全覆盖到。
必须重新请教语言学家,重新设计特征,重新收集标注数据……
这就是特征工程瓶颈的本质:统计学习的上限,不是模型算法的上限,而是人类对这个领域理解的上限。 人类理解不到,机器就学不到。(从这个角度而言,机器学习不妨改名为 Human Learning)
这个局限有一个尖锐的推论:统计学习意味着 AI 的能力,最多只能和领域里最优秀的专家相当,但永远无法真正得超越。因为我们能学到的规律,是我们已经知道应该提取的那些规律。一个人类专家没有察觉的模式——哪怕它明明潜藏在数据里——统计学习也无法发现,因为没有人设计出能表达它的特征。
那能不能让机器自己决定"用什么特征"? 这个问题,要等到 2006 年才有了令人信服的回答。
2.7.2 天花板二:维度灾难
统计学习方法在低维到中维特征空间里工作得很好,但当特征数量增加时,就会遇到一个不可避免的数学问题:维度灾难(Curse of Dimensionality)。
我们来做一个直觉性的计算。假设我们的数据是一维的,范围在 [0, 1] 之间,我们用 10 个样本就能相当均匀地覆盖这个空间。而如果数据是二维的,要达到同样的密度,就需要 102=10010^2 = 100102=100 个样本,扩展到三维需要 103=100010^3 = 1000103=1000 个样本,十维需要 1010=10010^{10} = 1001010=100 亿个样本。
这就是维度灾难:随着维度增加,要想保持同样的样本密度,所需的样本量将以指数级增长。
这在实际问题里有什么含义?我们用基因组学举例:人类基因组有约 2 万个基因,如果想用基因表达量预测某种疾病的风险,模型的特征空间就有 2 万维。在这样高维的空间里,即使我们有 10 万个样本,放置到 2 万维的空间中,呈现出来的也只是极度稀疏的点云——模型几乎无法从中学到有意义的规律。
虽然 SVM 可以通过核方法隐式地在高维空间操作,一定程度上缓解了这个问题,但没有根本解决。统计学习方法在高维、大规模数据上的效果,往往不如在低维、精心设计的特征上好。
数学家对高维空间有一个更刺激的描述,叫做测度集中现象(Concentration of Measure):在低维空间里,“近邻"和"远邻"之间的距离差异是显著的——最近的邻居可能在距离 0.1 处,最远的可能在距离 10 处,差了一百倍。但在 1000 维空间里,一个点的最近邻居和最远邻居的距离,会收缩到几乎没有差别——所有的点,看起来都差不多"近”,也差不多"远"。
这个反直觉的现象,摧毁了很多统计方法的基础。依赖"距离"来判断相似度的算法(比如 k 近邻分类),在高维空间里直接失效。依赖样本覆盖的密度估计,在高维空间里需要的样本量是天文数字。高维几何和低维几何,是两套完全不同的直觉体系——而统计学习的大多数方法,都建立在低维直觉上。这也是为什么 2000 年代的很多 AI 项目,研究者们花了大量时间在"降维"上:主成分分析(PCA)把高维数据压缩到方差最大的几个方向;线性判别分析(LDA)保留对分类最有用的维度……降维,成了统计学习时代的必修课——而这本质上也是在帮模型从高维诅咒的泥沼里爬出来。
2.7.3 天花板三:迁移能力的缺失
统计学习中,每个任务都是一个孤岛。
我们花了大量的精力,在 100 万张猫狗图片上训练了一个非常好的猫狗分类器。但如果现在要求做汽车和卡车的分类,还能用之前的工作吗?
在统计学习时代,基本上不能。猫狗分类器的内部学到的是"怎么区分猫和狗"的规律,这些规律和区分汽车与卡车的规律没有直接关系,一般情况下需要重新收集数据、重新设计特征、重新训练。
这种迁移能力的缺失,从根本上限制了统计学习的效率。每一个新任务,都是从零开始的工程项目。在数据匮乏的领域,统计学习很难工作良好——因为没有足够的数据让我们可以从零开始训练一个好的模型,同时也很难把"其他领域的知识"借过来用。
相比之下,人类是高度迁移的学习者。一个学会了开车的人,学摩托车比一个从未开过任何机动车的人快得多。一个学会了法语的人,学西班牙语比从零开始快得多。这种迁移能力,是人类智能的核心特征之一。在统计学习时代,AI 几乎不具备这种能力。
这三堵天花板,从不同角度指向同一个根本问题:统计学习建立在"人类告诉机器应该关注什么"的基础上。特征设计是人给的,维度处理是人驱动的,任务边界是人划定的。这个框架在数据有限、领域固定的时代做出了卓越的贡献。但随着互联网带来的数据爆炸,随着"跨领域 AI"的需求日益迫切,这个框架的根本局限——知识被封锁在人的理解力里——变得越来越难以接受。打破这个局限,需要一种截然不同的思路。
2.8、转折点:2006 年的序曲
2.8.1 一个人的坚守
在 SVM 如日中天、大多数研究者都已转移阵地的 2000 年代初,蒙特利尔大学的一间办公室里,辛顿仍然在坚持研究神经网络。
这件事在当时是需要相当的勇气——或者说,需要一种特殊的偏执。我们前文提到,辛顿的学生和同事都知道,每次开会讨论他的研究,都要做好被审稿人质疑"为什么不用 SVM"的心理准备。神经网络在当时被很多人认为是一条死路:训练不稳定、没有理论保证、效果也通常不如 SVM。
但辛顿有一个根深蒂固的信念:多层神经网络有某种统计学习方法没有的能力——自动学习特征的层次表示。他相信,当给定足够的计算资源和足够的数据时,一个深度网络应该能够从原始像素出发,自动发现边缘、纹理、形状、物体这样的层次特征——而完全不需要人工设计。
这是一个关于"让机器自己学特征"的承诺。如果这个承诺能兑现,统计学习的三堵天花板,就能被一次性突破。这个想法后来有了一个名字:表示学习(Representation Learning)。它的核心主张是:好的特征不应该由人来设计,而应该由模型从任务和数据中自动发现。在 2006 年,这个主张还只是一种信念;在 2012 年之后,它成了整个 AI 领域的基础共识。
坚持这个信念的代价,是非常现实的。辛顿在多次采访中描述过那段时间的处境:每次向拨款委员会申请经费,都要花大量时间解释 “为什么不用 SVM”。他的学生去工业界面试,有时会被追问"为什么花了几年时间去研究一个几乎已经被否定的方向"。有一段时间,辛顿选择了离开美国学术界,加入英国的研究机构,部分原因正是那里的评审文化不像美国那么被 SVM 的学术规范主导。
但他坚持的理由,有一种不可动摇的内在逻辑:统计学习的天花板,不是数学的天花板,而是表示的天花板。只要特征还是人工设计的,AI 的上限就永远被人类理解力所限制。而改变这一点的方法,他相信,是让多层神经网络自己从数据里发现层次表示——不需要人告诉它"边缘是什么",它应该自己学会。
2.8.2 2006 年:一篇反应温和的论文
2006 年,辛顿和他的学生鲁斯兰·萨拉赫丁诺夫(Ruslan Salakhutdinov)在《科学》杂志上发表了一篇论文《Reducing the Dimensionality of Data with Neural Networks(利用神经网络降低数据维度)》,展示了一种训练多层神经网络的方法。
这篇论文的核心想法,是利用受限玻尔兹曼机(RBM),通过逐层预训练来初始化深层网络的权重,再进行整体的反向传播微调。这绕开了当时深度网络训练的最大障碍——梯度消失导致的训练失败。
但这篇论文在当时的反应,是温和的。大多数人不以为然:“又是神经网络,又在说’深层网络能自动学特征’,这个说法我们已经听了二十年了。效果比 SVM 强多少?” 这篇论文没有配备 ImageNet 那样的大规模数据集,没有 GPU 加速,在当时的数据和计算条件下,效果的提升是有限的。
审稿人和同行的反应,把这项工作定位在了"有趣的理论探索"——而不是"即将改变一切的突破"。
理解这种反应,需要还原当时的处境。研究者们见过太多次神经网络的"复兴宣言":1980 年代反向传播的热潮,1990 年代 CNN 在手写字符上的局部成功,2000 年代初各种变体的反复出现,每次都有人说"这次神经网络真的行了",然后在更大规模的任务上要么训练不稳定,要么效果不如 SVM 显著。辛顿的论文,从表面上看,和这些历史宣言没有根本区别——还是多层网络,还是"如果有足够数据和计算资源"的条件句,但这些条件在几年后真的被满足了。
2.8.3 打破天花板需要的,不只是一个想法
历史回望过去,2006 年的那篇论文,其实是对的。辛顿关于"深度网络自动学特征层次"的直觉,在六年后被完全验证。
但这个验证,需要三个条件同时成熟:
足够多的样本(数据):在 ImageNet 之前,最大的公开标注图像数据集只有几万张图片。李飞飞(Fei-Fei Li)从 2007 年开始构建的 ImageNet 数据集,在 2009 年包含了超过 120 万张人工标注的图片,覆盖 1000 个类别——整整大了两个数量级。得幸于这个数据集,深度网络有了足够的"燃料"可以学习。
足够快的计算(算力):2012 年 AlexNet 的训练,用了两块英伟达 GTX 580 GPU,花了大约五到六天。如果用当时的 CPU,同样的训练则需要几个月时间。因此,如果没有 GPU 加速,想进行如此规模的实验相当耗时,更无法快速优化迭代。
足够好的算法技巧(算法):ReLU 激活函数(解决 sigmoid 的饱和问题,梯度在正区间不衰减)、Dropout 正则化(训练时随机关闭部分神经元,防止过拟合)——这些技巧,2012 年之前大部分还没有被充分验证和推广。
统计学习的三堵天花板,需要一种根本不同的思路来打破——让机器自己从原始数据出发,学会自己提取特征。而这条路,叫做深度学习。它的真正爆发,发生在 2012 年的一个秋天。
2.9、知识自检
读完本章,你应该能做到:
- 解释统计学习和符号主义在"知识从哪里来"上的根本区别,以及为什么这个转变在 AI 寒冬之后显得尤其重要
- 用"医生/白大褂"的类比解释贝叶斯定理的核心直觉,以及"朴素"假设为什么虽然不对但实践中管用
- 说明"过拟合"和"欠拟合"各自是什么,用"背答案 vs 理解原理"的类比解释,并用训练误差和验证误差的对比来诊断两种情况
- 解释偏差和方差的含义,以及为什么它们之间存在根本的权衡关系
- 说清楚训练集、验证集、测试集三者的区别和各自的作用,以及什么是"数据泄露"
- 解释什么是超参数(区别于模型参数),以及为什么超参调整必须在验证集上进行而不能用测试集
- 说明 K 折交叉验证的工作方式,以及在什么场景下应该使用它
- 用几何语言解释 SVM 的"最大间隔"思想,并说明"核方法"用什么技巧解决了非线性问题
- 说出统计学习的三个主要局限,并解释为什么这些局限是"范式本身的问题"而不是"实现细节的问题"
- 解释为什么 2006 年 Hinton 的论文在当时没有引发轰动,需要哪三个条件同时成熟才能真正突破统计学习的天花板
2.10、常见误解
❌ “机器学习就是机器自己从数据里学一切,不需要人参与”
✅ 实际上:在统计学习时代,特征仍然需要人来设计。“学习"发生在"给定特征,学如何做预测"这一步。机器学的是"用特征做判断”,而不是"应该用什么特征"。这是统计学习和深度学习的根本区别——深度学习能端到端地从原始数据(比如像素)直接学到特征。
❌ “数据越多,统计学习效果一定越好”
✅ 实际上:这在特征设计合理的情况下大体成立,但有两个重要限制:第一,维度灾难意味着当特征维度很高时,数据量需求是指数级增长的;第二,如果特征设计本身有缺陷(没有捕捉到任务所需的信息),再多的数据也无法弥补——“垃圾进,垃圾出”(Garbage in, garbage out)。
❌ “SVM 被深度学习替代,说明 SVM 不好用”
✅ 实际上:SVM 至今在很多场景下仍然是优秀的选择,尤其是中小规模的结构化数据(表格数据)、高维小样本场景(基因组学)、以及需要理论保证的场景。深度学习的优势主要在能够端到端学习特征的非结构化数据(图像、语音、文本)上。不同工具有不同的适用范围,不能简单说谁"更好"。
❌ “过拟合只是调参问题,收集更多数据就能解决”
✅ 实际上:更多数据确实可以缓解过拟合(降低方差),但并不总是可行,也不是唯一解。处理过拟合的方法包括:正则化(L1/L2)、Dropout(深度学习中)、集成方法(如随机森林)、降低模型复杂度……而欠拟合(高偏差)的问题,加更多数据完全无效,必须提升模型复杂度或改善特征。诊断清楚是过拟合还是欠拟合,才能对症下药。
❌ “在验证集上调好了超参数,模型就能上线了,测试集只是走个形式”
✅ 实际上:验证集在调参过程中已经被"间接使用"过了——你在无意中选择了对验证集最有利的超参数,验证集上的性能会高估真实泛化能力。测试集的存在是为了提供一次性的、未被污染的最终评估。如果测试集的结果令人不满意,正确的做法不是"拿测试集的结果再调参",而是重新思考数据和方法,否则测试集就失去了意义。
❌ “交叉验证可以代替测试集,不需要单独留测试集了”
✅ 实际上:交叉验证是用来做模型选择和超参数调整的工具(替代固定验证集),但它不能替代测试集。原因与验证集的逻辑一样:如果你基于交叉验证的结果做了很多次模型决策,交叉验证的结论就已经被"使用"过了,需要一个完全独立的测试集来做最终评估。正确的流程是:用交叉验证选超参数 → 在全部训练数据上重新训练 → 在测试集上评估一次。
❌ “特征工程已经过时,深度学习时代用不着了”
✅ 实际上:在结构化数据场景下(大多数商业场景),特征工程仍然极其重要。即使在深度学习主导的场景,特征层面的设计(数据增强、归一化方式、多模态特征融合)也仍然影响最终效果。"特征工程"的定义变了(从手工设计像素级特征,到设计训练策略和数据处理流程),但"人类先验知识指导数据表示"这件事本身,在深度学习时代并没有消失。
本章关键词
| 词汇 | 简明定义 |
|---|---|
| 统计学习(Statistical Learning) | 从数据中学习输入到输出映射关系的方法论,与符号主义的显式规则相对 |
| 朴素贝叶斯(Naive Bayes) | 基于贝叶斯定理、假设特征间条件独立的概率分类器,计算简单,实践效果好 |
| 先验概率(Prior Probability) | 在观察到任何证据之前,对某件事发生概率的初始判断 |
| 决策树(Decision Tree) | 通过一系列条件判断递归分割数据的树状预测模型,天然可解释 |
| 过拟合(Overfitting) | 模型在训练数据上表现很好但在新数据上泛化差,根本原因是"记住"了训练集的噪声(高方差) |
| 欠拟合(Underfitting) | 模型太简单,无法捕捉数据中的真实规律,训练集和验证集上都表现糟糕(高偏差) |
| 偏差(Bias) | 模型系统性地偏离真实答案的程度,模型越简单偏差越高 |
| 方差(Variance) | 模型对训练数据变化的敏感程度,模型越复杂方差越高 |
| 偏差-方差权衡(Bias-Variance Tradeoff) | 模型复杂度与泛化能力之间的根本权衡:降低偏差往往增大方差,降低方差往往增大偏差 |
| 训练集/验证集/测试集 | 三路数据切分:训练集用于学习参数,验证集用于调超参数,测试集仅用于最终一次性评估 |
| 数据泄露(Data Leakage) | 测试集信息在训练/验证阶段被提前使用,导致性能评估虚高的常见错误 |
| 超参数(Hyperparameter) | 训练前手动设定、不被自动优化的模型设置(如树的深度、正则化系数),区别于训练中自动学习的参数 |
| 交叉验证(Cross-Validation) | 把数据分成 K 份轮流作验证集,使每个样本都参与验证,提供比单次验证更可靠的性能估计 |
| 随机森林(Random Forest) | 多棵决策树的集成,通过 Bootstrap 采样和特征随机化降低方差,提升泛化能力 |
| 支持向量机(SVM) | 寻找最大间隔超平面的分类算法,有坚实的统计学习理论保证,由 Vapnik 提出 |
| 支持向量(Support Vectors) | 离分类超平面最近的训练样本点,是唯一决定超平面位置的点 |
| 核方法(Kernel Method) | 通过核函数隐式将数据映射到高维特征空间,使线性模型能处理非线性问题 |
| 特征工程(Feature Engineering) | 利用领域知识将原始数据转化为适合机器学习模型的特征表示,统计学习时代的关键环节 |
| 维度灾难(Curse of Dimensionality) | 随特征维度增加,需要的样本量指数级增长,导致高维空间中统计估计极度困难 |
延伸阅读
-
必读:Domingos, P.(2012). “A Few Useful Things to Know About Machine Learning.” Communications of the ACM, 55(10), 78-87. 非常实用的综述,把统计机器学习中最重要的工程智慧浓缩在一篇文章里,强烈推荐。
-
推荐:Graham, P.(2002). “A Plan for Spam.” 个人网站文章。写朴素贝叶斯的程序员视角,文字清晰易懂,是统计学习走向大众应用的典型案例。
-
推荐:Bishop, C.M.(2006). Pattern Recognition and Machine Learning. Springer. 统计机器学习的经典教材,第一章的绪论非常值得一读,给出了整个框架的清晰鸟瞰。
-
推荐:Vapnik, V.N.(1999). “An Overview of Statistical Learning Theory.” IEEE Transactions on Neural Networks. SVM 的理论基础,Vapnik 本人写的综述,比原始著作更易读。
-
深入:Breiman, L.(2001). “Random Forests.” Machine Learning, 45(1), 5-32. 随机森林的原始论文,写得非常清晰,值得一读。
-
深入:Dalal, N., & Triggs, B.(2005). “Histograms of Oriented Gradients for Human Detection.” CVPR 2005. HOG 特征的原始论文,展示了一个精心设计的手工特征的最高水准。
[!tip]
下一章预告:统计学习一直有一个潜在的竞争者——神经网络。它的历史比统计学习更长,却一再被打入冷宫:感知机被 Minsky 一盆冷水浇熄,多层网络因为梯度消失而无法训练。但在统计学习统治的这些年里,有几个人从没放弃。他们的故事,是整个深度学习革命的前史。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 8
8 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)