贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用
贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。
在时间序列预测任务中,如何自动选择最优的模型超参数一直是提升预测精度的关键挑战。本文介绍一套基于贝叶斯优化(Bayesian Optimization)与长短期记忆网络(LSTM)相结合的自动化预测系统。该系统专为单变量时间序列设计,仅需提供一列原始数据即可完成从数据预处理、参数优化、模型训练到结果评估的完整流程,具备高度的易用性与泛化能力。
系统整体架构
该系统采用模块化设计,主要由以下核心组件构成:
- 数据预处理模块:将原始单列时间序列转换为监督学习格式,通过滑动窗口构建输入-输出样本对;
- 贝叶斯优化模块:自动搜索LSTM网络的关键超参数组合,以最小化训练集上的预测误差;
- LSTM建模与训练模块:基于优化所得参数构建并训练最终预测模型;
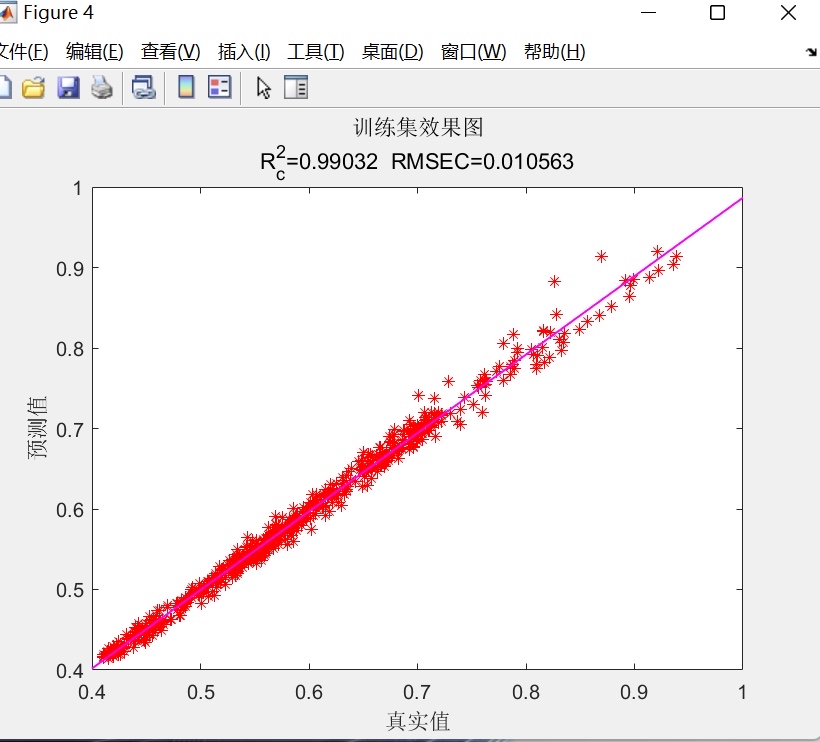
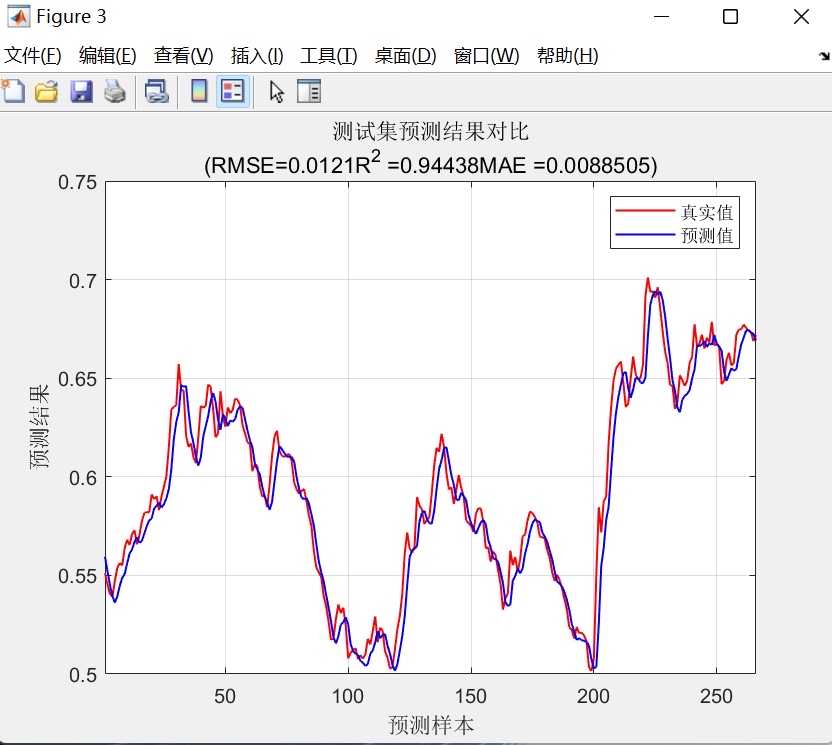
- 评估与可视化模块:全面计算多种误差指标(RMSE、MAE、R²),并生成多维度可视化图表。
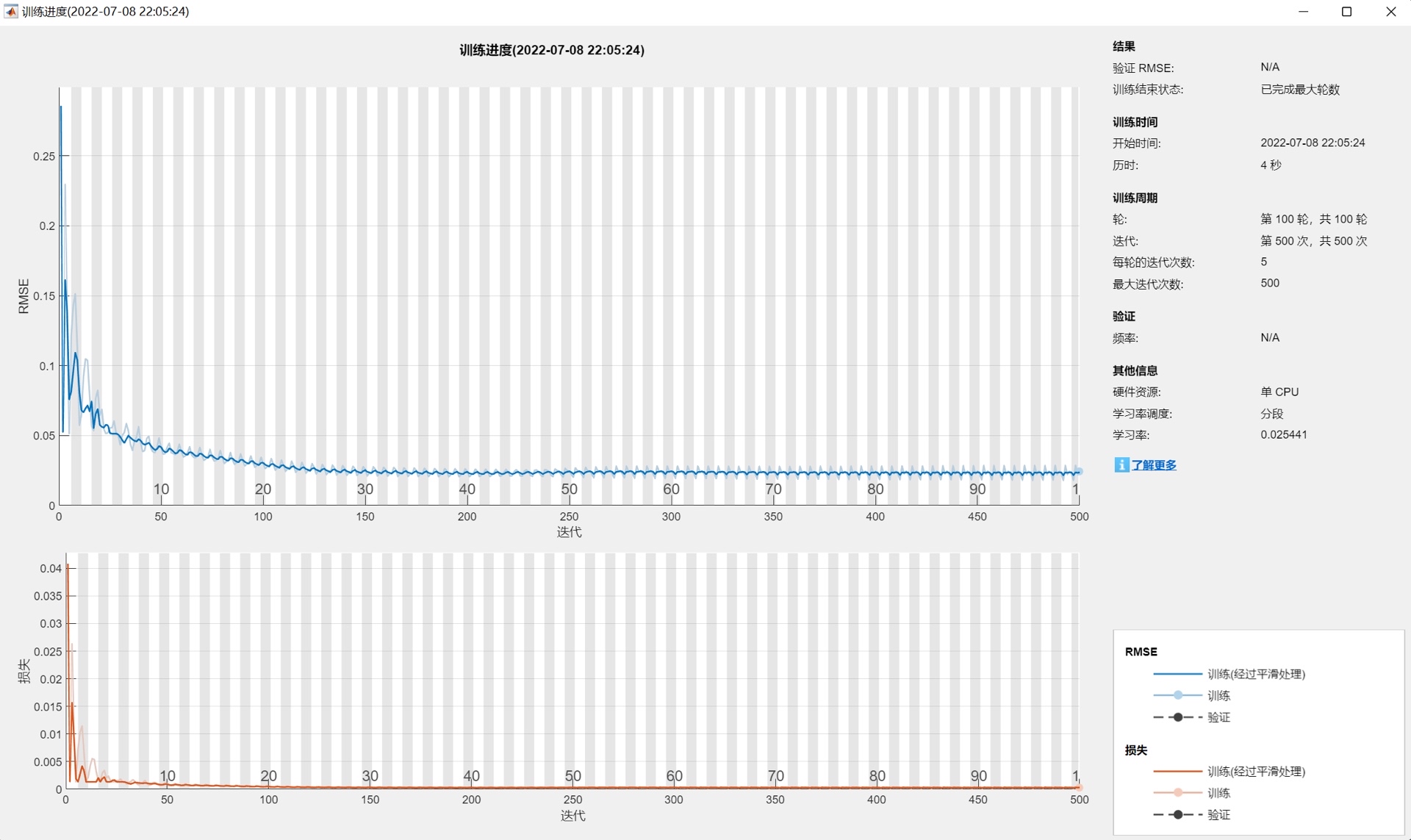
整个流程无需人工干预超参数调优,显著降低了深度学习模型在时间序列预测中的使用门槛。
数据预处理机制
系统首先读取用户提供的单列时间序列数据(如Excel文件中的“数据集.xlsx”)。随后,通过设定历史窗口长度(kim)和预测步长(zim),将原始序列重构为监督学习所需的输入-输出对。例如,若 kim=15、zim=1,则每15个连续历史值用于预测第16个时间点的值。
贝叶斯优化LSTM做时间序列单输入单输出预测模型,要求数据是单列的时间序列数据,直接替换数据就可以用。 程序语言是matlab,需求最低版本为2021及以上。 程序可以出真实值和预测值对比图,线性拟合图,可打印多种评价指标。
数据集按比例(默认70%)划分为训练集与测试集,并对输入与输出分别进行最小-最大归一化(mapminmax),以提升模型收敛速度与数值稳定性。归一化后的数据被转换为MATLAB深度学习工具箱所需的cell数组格式,适配序列输入要求。
贝叶斯优化驱动的超参数自动调优
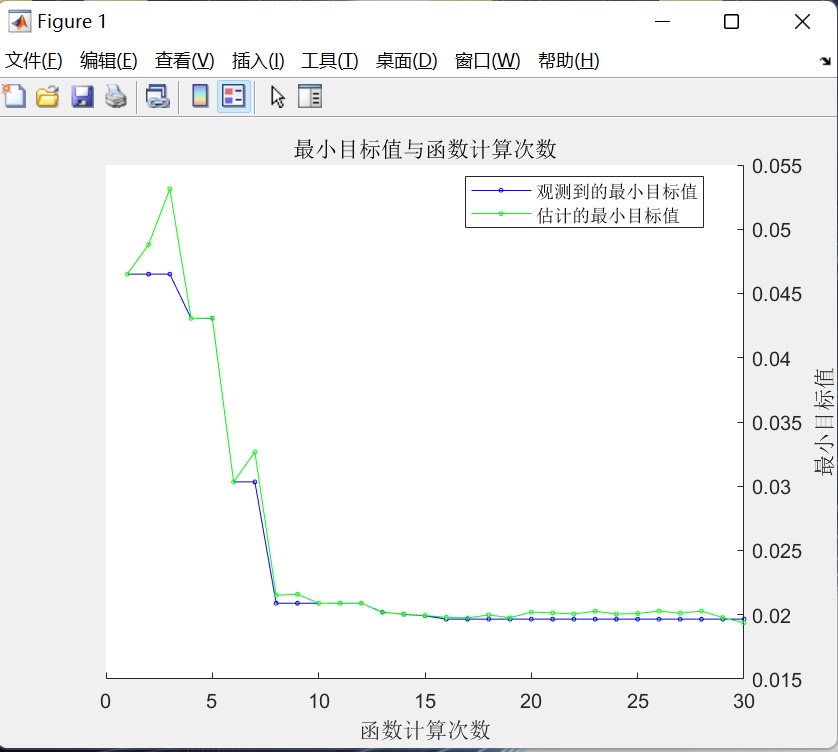
传统LSTM模型性能高度依赖超参数选择,如隐藏单元数、初始学习率和L2正则化强度。本系统引入贝叶斯优化作为自动调参引擎,显著优于网格搜索或随机搜索的效率。
优化目标函数(CostFunction)封装了完整的训练-预测-评估闭环:
- 接收一组候选超参数;
- 构建对应LSTM网络(含输入层、LSTM层、ReLU激活、全连接回归层);
- 在训练集上训练模型(使用Adam优化器,固定训练轮次);
- 计算训练集上的均方根误差(RMSE)作为目标值返回。
贝叶斯优化器在预设搜索空间内迭代30次(可配置),逐步构建代理模型以预测哪些参数组合更可能带来低误差,最终输出全局近似最优参数集。
模型训练与预测
获得最优超参数后,系统重建LSTM网络并执行完整训练流程,同时启用训练进度可视化。训练完成后,模型分别对训练集和测试集进行预测,并将预测结果反归一化至原始数据尺度,确保误差计算与结果解释的准确性。
多维度性能评估与可视化
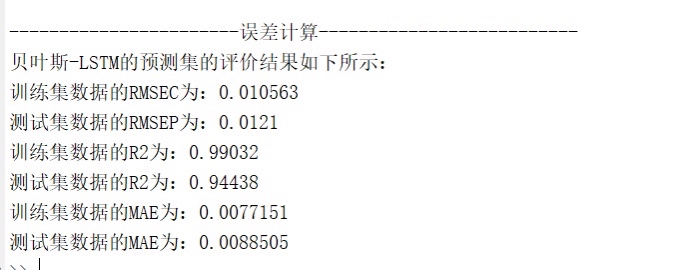
系统不仅计算传统指标(RMSE、MAE、决定系数R²),还提供四类可视化分析:
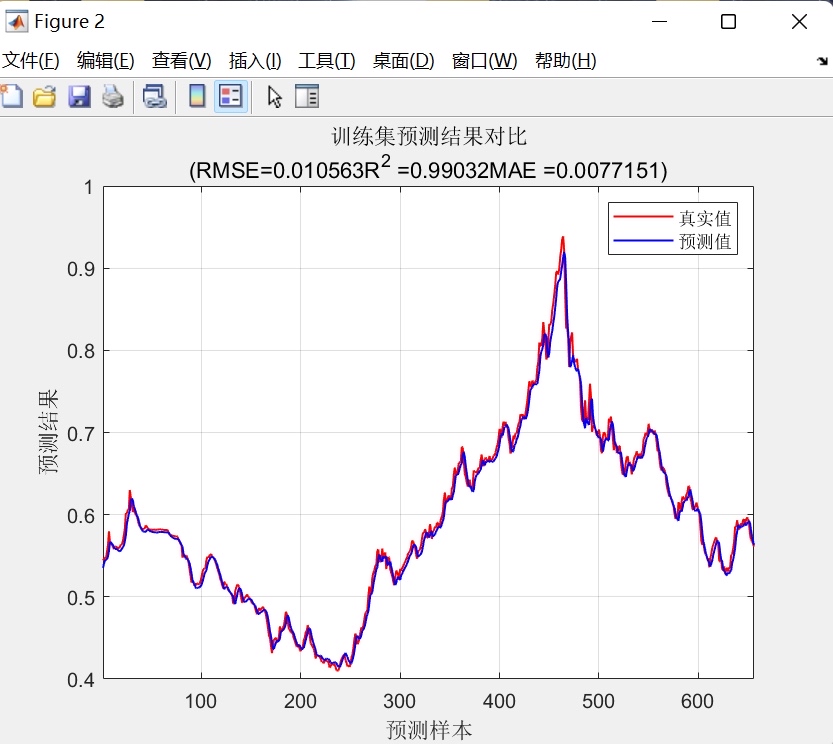
- 时序对比图:展示训练集与测试集上真实值与预测值的逐点对比;
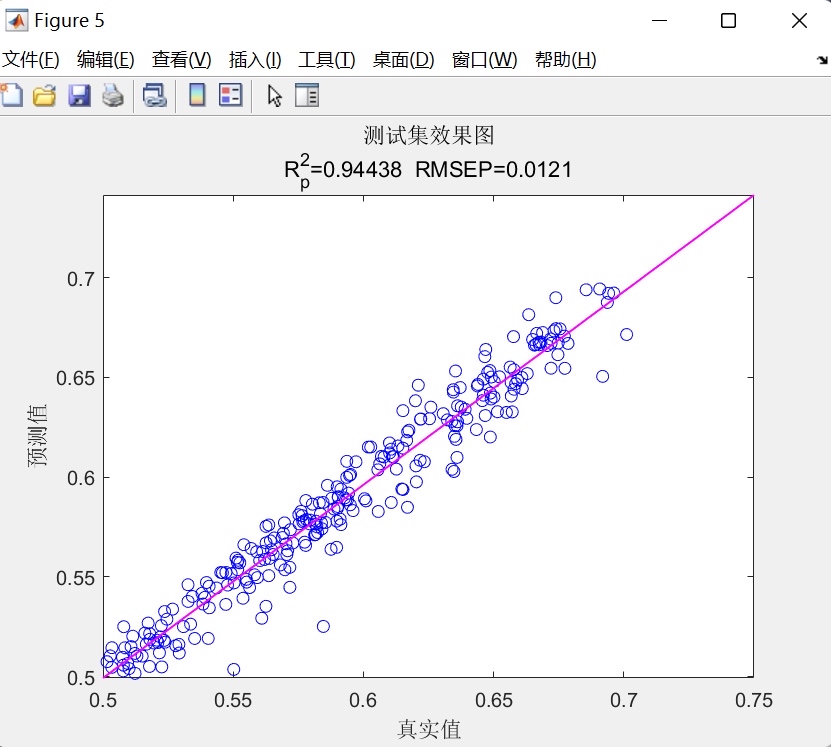
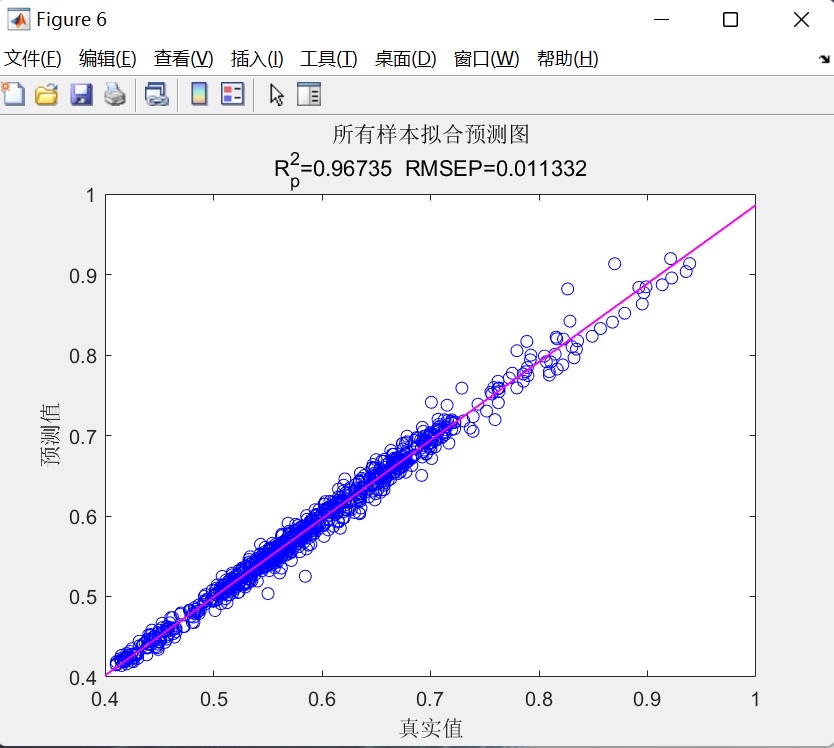
- 线性拟合散点图:分别绘制训练集、测试集及全样本的预测值-真实值散点图,并叠加最小二乘拟合直线,直观反映模型拟合优度;
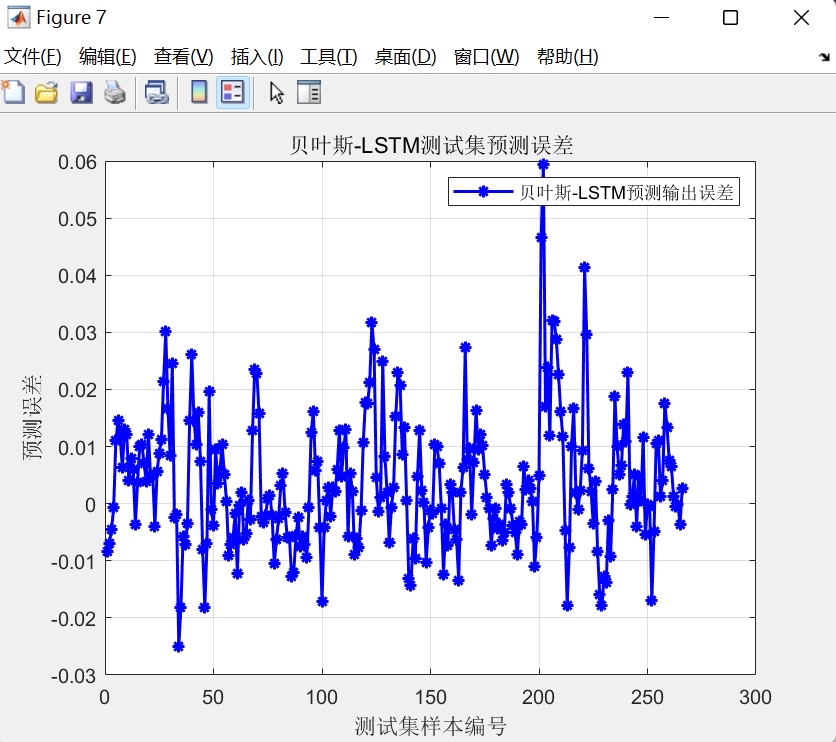
- 误差分布图:展示测试集各样本的预测误差,便于识别异常点或系统性偏差;
- 综合指标汇总:在命令行输出所有关键指标,便于快速评估模型性能。
易用性与扩展性
该系统设计简洁,用户仅需替换“数据集.xlsx”中的单列时间序列数据,即可直接运行。代码结构清晰,参数(如窗口长度、训练比例、优化次数等)均集中定义,便于调整。未来可轻松扩展至多变量输入、多步预测或GPU加速训练等场景。
总结
本系统将贝叶斯优化与LSTM深度结合,实现了时间序列预测任务中“数据进、结果出”的端到端自动化流程。其核心价值在于自动化超参数调优与标准化评估体系,既保证了模型性能,又极大提升了开发效率,适用于金融、气象、能源、工业等多种领域的单变量时间序列预测需求。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 9
9 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)