生产级Harness的12大组件以及主流框架对比
很多人做 Agent,卡住以后第一反应是模型不够强。我自己这两年看下来,大多数生产问题,真正出错的地方都在模型外面那层 harness。
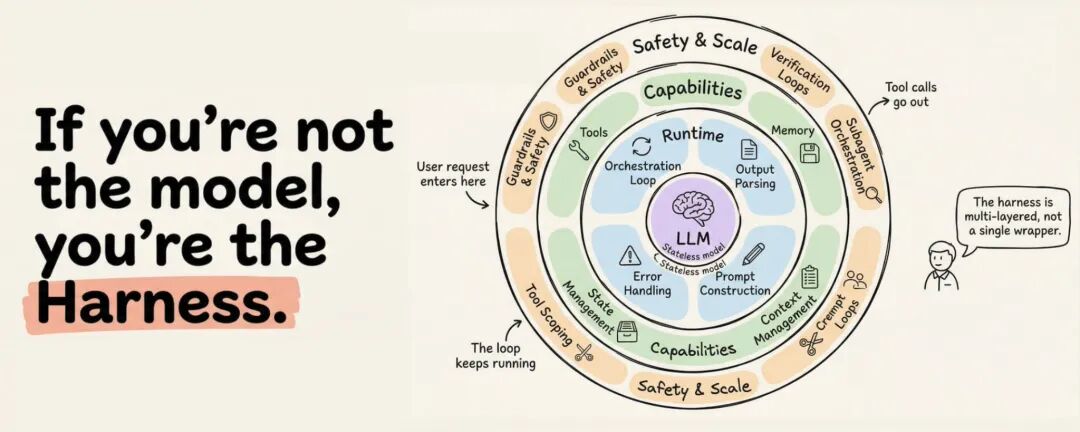
你可以把 harness 理解成一整套运行时基础设施。它负责 orchestration loop、tools、memory、context management、state persistence、error handling、guardrails,以及验证闭环。一个只会对话的 LLM,挂上这套东西以后,才开始像一个真的能干活的 Agent。
1. 为什么问题通常不在模型
你也许已经做过一个 chatbot,或者搭过一个带几个工具的 ReAct loop。拿来做 demo 没问题。可一旦进入生产环境,问题会连续冒出来:模型会忘掉三步之前刚做过什么,tool call 失败了没人知道,上下文窗口很快被噪声塞满。
这里最容易误判的地方是,把问题全归到模型头上。
现实往往不是这样。LangChain 只调整了包在 LLM 外面的那层基础设施,在模型和权重不变的前提下,TerminalBench 2.0 的排名就从 30 名开外跳到第 5。还有研究项目让 LLM 反过来优化基础设施本身,最后跑出的通过率甚至超过人工设计系统。
这层基础设施,现在有了一个更准确的名字:agent harness。
2. 什么是 Agent Harness
2.1 它不只是 prompt 外壳,更是一整套运行时
这个词是 2026 年初才被正式叫开的,但东西本身早就有了。Anthropic 在 Claude Code 文档里,直接把 SDK 叫成“驱动 Claude Code 的 agent harness”。OpenAI 的 Codex 团队也是类似说法,把 “agent” 和 “harness” 放进同一个语境里,指的都是那套让模型真正可用的非模型基础设施。
LangChain 的 Vivek Trivedy 有一句我很喜欢的话:“If you’re not the model, you’re the harness.”
2.2 Agent 是行为,Harness 是产出这种行为的机械结构
这两个词特别容易混着用。
“Agent” 说的是用户看到的那层行为:它有目标,会调用工具,能自我修正,看起来像一个一直在工作的实体。
“Harness” 说的是后面那套机械结构:循环怎么跑、工具怎么注册、上下文怎么裁剪、状态怎么保存、权限怎么校验、失败后怎么恢复。
所以一个人说“我做了一个 Agent”,更准确的说法通常是:他做了一套 harness,然后把模型接了进去。
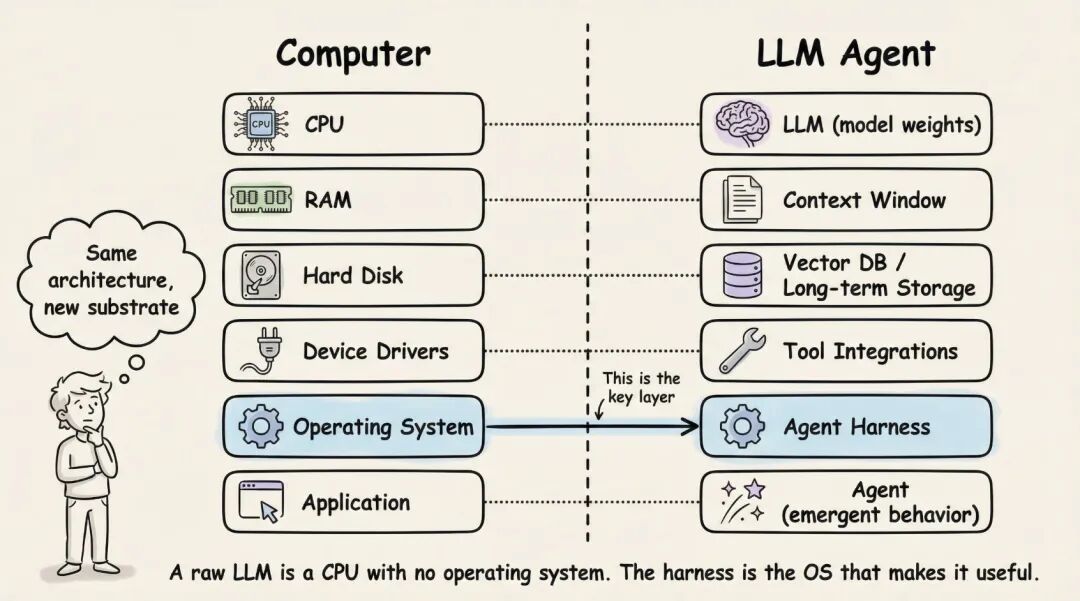
2.3 把它理解成操作系统,会更容易
这个比喻很准确。原始 LLM 像一颗 CPU,没有 RAM、没有磁盘、没有 I/O。上下文窗口相当于 RAM,速度快但容量有限;外部数据库像磁盘,容量大但访问更慢;工具集成像设备驱动;harness 则像操作系统。
围绕模型,其实有三层同心圆工程:
- Prompt engineering:写清楚模型收到什么指令。
- Context engineering:决定模型在什么时候看到哪些信息。
- Harness engineering:把前两者连同 tools、state、error recovery、safety、lifecycle 一起纳入系统设计。
把这些东西放在一起看,harness 更像一台完整的机器。没有它,自主 Agent 很难稳定跑起来。
3. 生产级 Harness 的 12 个组件
把 Anthropic、OpenAI、LangChain 和一线实践社区的做法放在一起看,一个生产级 harness,大概逃不开下面这 12 个组件。
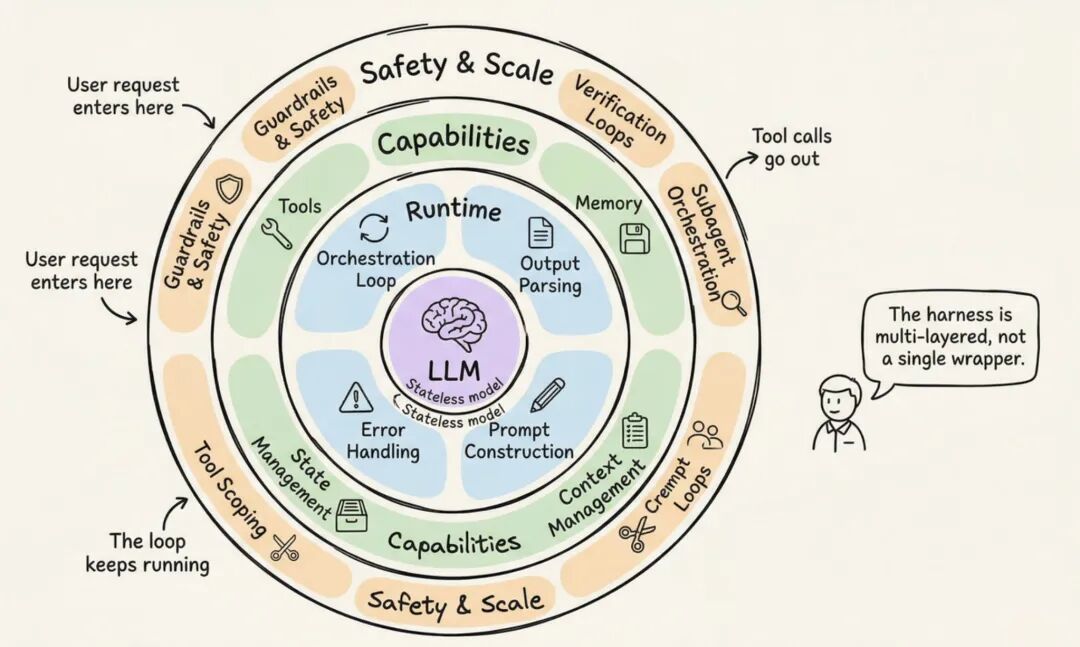
3.1 编排循环(Orchestration Loop)
这是整个系统的心跳。最常见的形态就是 Thought-Action-Observation,也就是大家熟悉的 ReAct loop。
它的执行顺序通常是:
- 组装 prompt。
- 调模型。
- 解析输出。
- 执行 tool call。
- 把结果塞回上下文。
- 继续下一轮,直到结束。
真落到代码里,它经常就只是一个 while 循环。麻烦的地方不在循环本身,在这轮里要管的那些东西。
3.2 工具系统(Tools)
工具这一层很好理解。Agent 真要干活,总得先有手。
工具一般会以 schema 的形式注入上下文,包括名称、描述、参数类型,让模型知道“当前有哪些能力可用”。但工具这层真正麻烦的,通常不是 schema 本身,而是后面的运行时细节:注册、校验、参数提取、沙箱执行、结果采集,再格式化成模型能读的 observation。
像 Claude Code 这类系统,工具通常覆盖文件操作、搜索、执行、Web 访问、代码智能、sub-agent 调度这些大类。OpenAI 的 Agents SDK 也区分了 function tools、hosted tools,以及 MCP server tools。
3.3 记忆系统(Memory)
记忆这件事,肯定不能只靠当前会话那点上下文。
短期记忆是当前会话里的对话历史。长期记忆要跨会话保留,通常落在项目文件、结构化 store、数据库 session 或本地持久层里。
Claude Code 的做法我很认同,是三层结构:
- 轻量索引:很短,始终加载。
- 主题文件:按需拉进来。
- 原始记录:只在搜索时触达。
这里有一个很重要的设计原则:Agent 对自己的记忆只能当成提示,不能当成事实。 真要执行动作之前,还是得回到真实状态再核对一次。
3.4 上下文管理(Context Management)
很多 Agent 到后面会失灵,往往不是能力不够,而是上下文已经乱了,关键信号被噪声盖住了。
上下文一长,模型表现会明显下滑。中间位置的信息尤其容易被忽略,“Lost in the Middle” 这类研究已经把这个问题讲得很清楚了。上下文窗口再大,也不代表 instruction following 会线性变好。
生产里常见的处理办法有四种:
- 压缩(compaction):会话过长时,把历史压成高密度摘要。
- 观察遮罩(observation masking):旧 tool output 隐掉,只保留必要痕迹。
- 即时检索(just-in-time retrieval):靠轻量索引和局部读取,避免整份大文件一次性塞进来。
- 子 Agent 委派:让子 Agent 展开探索,只返回 1000 到 2000 token 的浓缩结果。
生产里的重点,从来都不是一味往里塞 token。更稳的做法是把高信号信息挑出来,只给模型当前真正需要的那部分。
3.5 Prompt 组装(Prompt Assembly)
每一轮里,真正送进模型的内容,都是 harness 当场组装出来的。
这通常是一个分层栈:
- system prompt
- tool definitions
- memory files
- conversation history
- current user message
OpenAI 的 Codex 还有一套更严格的优先级:服务端 system message 最高,其次是工具定义、developer instructions、级联指令文件,再往后才是会话历史。
3.6 输出解析与结构化返回(Output Parsing)
现代 harness 越来越依赖 native tool calling。也就是模型直接返回结构化的 tool_calls,而不是先吐一段自然语言,再让系统去猜它到底是不是想调工具。
判断逻辑通常很简单:
- 有
tool_calls,那就执行并继续循环。 - 没有
tool_calls,那就把当前输出视为最终答案。
如果还需要结构化响应,OpenAI 和 LangChain 一类框架一般会配合 schema 约束或 Pydantic 模型,让返回值尽量稳定。
3.7 状态持久化与 Checkpoint(State Persistence)
多步任务如果没有状态保存,任何中断都会把整个过程打回起点。
不同系统的实现路径不一样:
- LangGraph 把状态建模成带类型的字典,在图节点之间流转,并在关键边界打 checkpoint。
- OpenAI 提供了应用层 memory、SDK session、服务端 conversation,以及更轻量的 response chaining。
- Claude Code 更偏工程化,直接把 git commit 当 checkpoint,把进度文件当结构化 scratchpad。
这层设计的价值很直接:任务可以恢复,可以回溯,也能做 time-travel debugging。
3.8 错误恢复与重试(Error Handling)
多步流程里,错误叠起来会很快。
一个 10 步流程,如果每一步成功率都是 99%,端到端成功率也只有大约 90.4%。算一下就知道,错误不能只记录日志,得被设计成系统能力。
实践里,常见的错误类型大概有四类:
- 瞬时错误:重试加退避。
- LLM 可恢复错误:把错误作为 tool message 回传,让模型自己修正。
- 用户可修复错误:中断并请求人工输入。
- 非预期错误:向上抛出,进入调试链路。
比较成熟的 harness,不会让 tool handler 一报错就把整轮循环打断,而是尽量把失败变成模型可理解、可处理的反馈。
3.9 权限与 Guardrails(Permissions and Safety)
模型负责决定“想做什么”,工具系统负责决定“允不允许做”。
这两个职责最好分开。因为一旦混在一起,模型就会同时承担推理和权限判断,风险会上升。
像 Claude Code 这种系统,会把工具能力切成很多离散权限,再分三层处理:
- 项目加载时建立信任边界。
- 每次 tool call 前做权限检查。
- 对高风险操作触发明确的人类确认。
OpenAI 的 SDK 也把 guardrail 分成输入、输出、工具三个层级,并支持 tripwire 直接中止 Agent。
3.10 验证闭环(Verification Loop)
这是我区分生产级 Agent 和玩具 demo 时,最先会看的一层。
Anthropic 提的三类验证手段,我觉得是靠谱的:
- 规则型反馈:tests、linters、type checkers。
- 视觉型反馈:例如用 Playwright 截图检查 UI。
- LLM-as-judge:让另一个模型或子 Agent 来做评审。
这层设计更像是在补“验收能力”。模型未必要更聪明,但它得有办法检查自己刚才那一步到底做没做对。Claude Code 团队提过一个很实用的判断:只要给模型足够好的验证路径,质量通常能提升 2 到 3 倍。
3.11 Sub-agent 与执行模型(Execution Models)
当任务足够复杂时,单个上下文窗口会很快失控,这时候就会用到 sub-agent。
Claude Code 给了三种很有代表性的执行模型:
- Fork:父上下文的字节级复制。
- Teammate:单独终端,用文件或消息做通信。
- Worktree:独立 git worktree,隔离分支执行。
OpenAI 也支持把 specialist agent 当工具调用,或者把控制权 handoff 给另一个 agent。LangGraph 则更像把 sub-agent 建成嵌套状态图。
3.12 终止条件与生命周期(Termination and Lifecycle)
一个循环什么时候该停,不能只靠模型“自己感觉做完了”。
常见终止条件至少包括:
- 模型输出里没有 tool call。
- 最大轮次超限。
- token budget 耗尽。
- tripwire 触发。
- 用户主动中断。
- 安全拒答返回。
简单问题也许 1 到 2 轮就结束,复杂重构任务可能要跨几十轮,串起大量 tool call。生命周期设计不清楚,系统很快就会出现失控、卡死或无意义循环。
4. 一次完整循环到底怎么跑
前面的零件知道了,再回头看完整一轮怎么跑,就没那么抽象了。
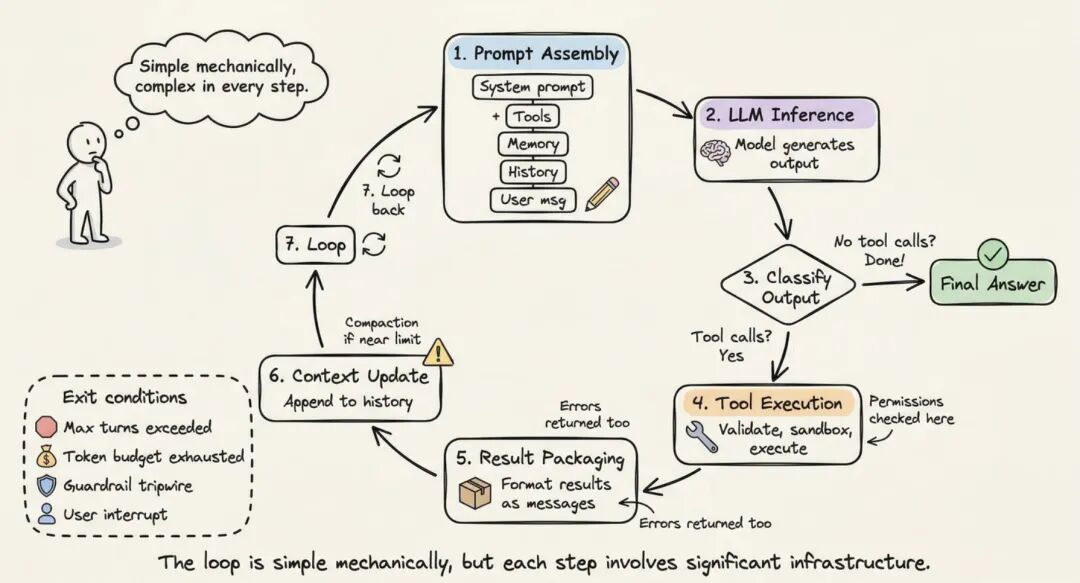
4.1 七个步骤
- Prompt Assembly:系统把 system prompt、tool schema、memory、history、用户消息拼成当前轮输入。重要信息优先放在开头和结尾,尽量避开“中间被吃掉”的位置。
- LLM Inference:请求发给模型,模型返回文本、tool call,或者两者都有。
- Output Classification:如果只有文本、没有 tool call,循环结束;如果有 tool call,进入执行;如果是 handoff,就切换当前 agent。
- Tool Execution:校验参数、检查权限、在沙箱里执行,采集结果。只读操作可以并行,改写类操作更适合串行。
- Result Packaging:把成功结果或错误结果重新包装成模型能读懂的 observation。
- Context Update:把结果追加到历史;如果快到窗口上限,就触发 compaction。
- Loop:回到下一轮,继续重复。
4.2 为什么要把文件系统也纳入 Harness
有些系统会把整个工作流拆成长期协作角色:初始化 Agent 负责准备环境、落初始进度文件、做第一次提交;后续 Coding Agent 每次开工先读 git log 和 progress file,再把最高优先级的未完成任务接着做。
这样一来,文件系统就成了跨上下文窗口的连续性载体。
5. 几家主流框架,其实都在做同一件事
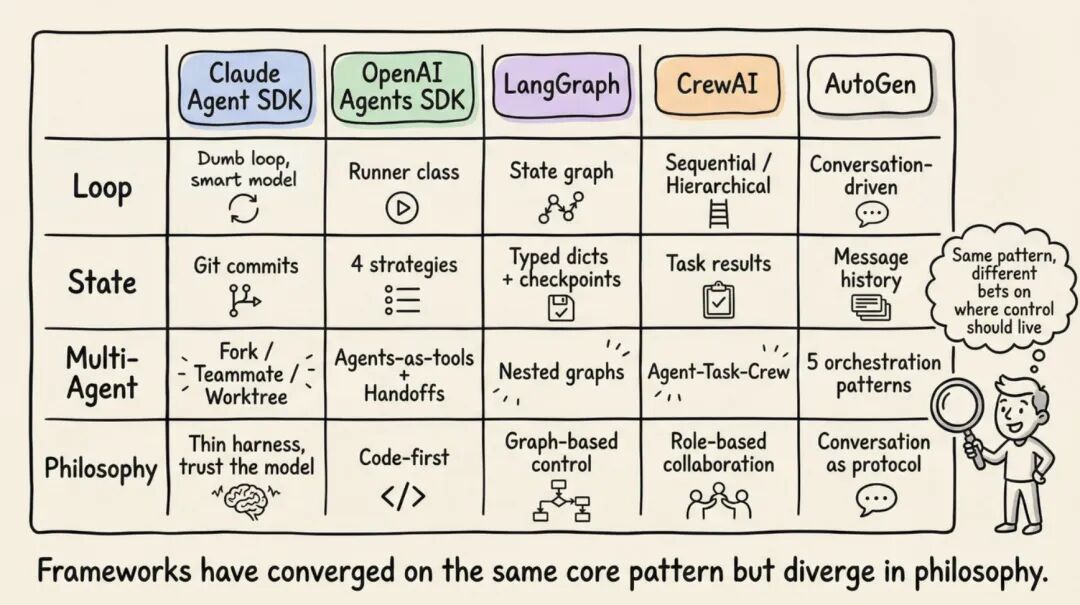
5.1 Anthropic:薄 Harness,智能尽量留给模型
Anthropic 的 Claude Agent SDK 给我的感觉一直很克制,核心入口就是一个 query(),底层启动 agentic loop,然后用 async iterator 持续流出消息。
它的路子很清楚:runtime 保持薄,智能尽量留在模型里。Claude Code 的工作节奏也很统一,就是 Gather、Act、Verify 三步反复循环。
5.2 OpenAI:Code-first,Runner 是核心
OpenAI 这边更像是在给工程师一套顺手的工作流工具,核心是 Runner,支持 async、sync、streamed 三种模式。它强调的是“工作流逻辑直接写在 Python 里”,不用先被迫进入图 DSL。
Codex 在这个基础上又做了三层拆分:
- Codex Core:agent code 和 runtime。
- App Server:双向 JSON-RPC API。
- Client Surfaces:CLI、VS Code、Web。
也因为这三层共用同一套 harness,所以同一个模型放到 Codex 自己的表面层里,体验会明显比“普通聊天窗口”更像一个真正的 Agent。
5.3 LangGraph / LangChain:把 Harness 显式建模成状态图
LangGraph 这条路线的特点,就是把很多东西摊开给你看。它通常把主流程建成两个核心节点:
llm_calltool_node
然后靠条件边决定:有 tool call 就走 tool_node,没有就结束。
LangChain 后来把早期的 AgentExecutor 弃用了,一个重要原因就是它不够好扩展,也不适合 multi-agent。现在的 Deep Agents 已经直接把自己描述成 agent harness,内建 tools、planning、context management、subagent spawning 和 persistent memory。
5.4 CrewAI / AutoGen:把多 Agent 协作作为第一公民
CrewAI 更强调角色分工,把 Agent、Task、Crew 这些对象拆得很清楚,再由 Flows 层提供一条相对确定的骨架。
AutoGen 则很早就把“对话驱动编排”做成了体系化方法,后来逐渐演进为微软的 Agent Framework。它支持顺序、并发、group chat、handoff、manager-ledger 这些不同编排模式。
虽然形态差很多,但底层在解决的是同一个问题:怎么让模型、工具、状态和验证闭环稳定地一起工作。
6. 为什么说它像脚手架
我觉得这个比喻挺到位,不是修辞上的好听,而是真的能帮你理解这层东西。
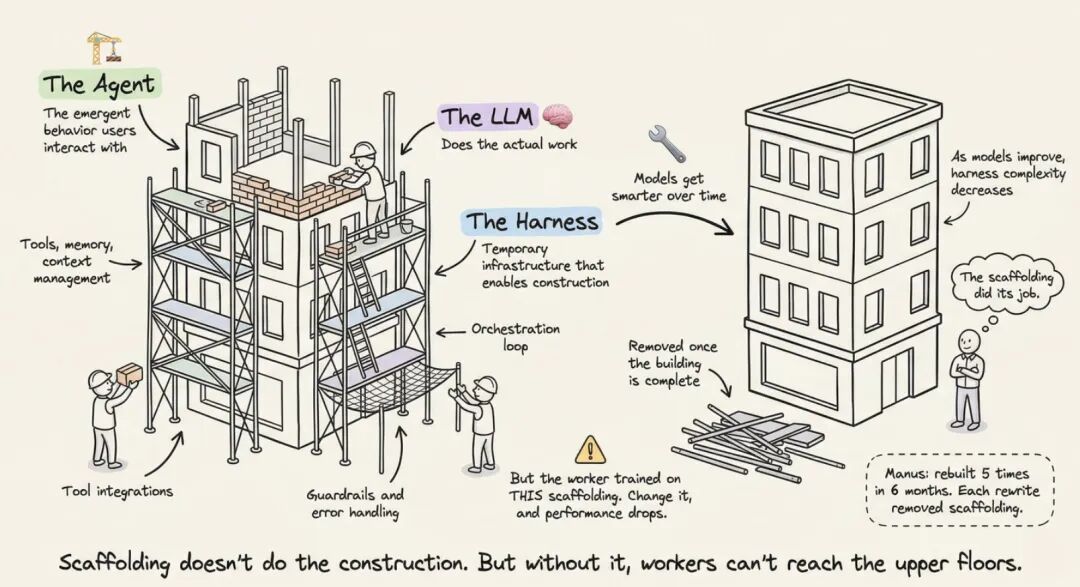
脚手架本身不会盖楼,但没有脚手架,工人也够不到高处。Harness 也是同样的角色。它不直接产出智能行为,却决定智能行为能不能稳定发生。
6.1 好的 Harness,应该随着模型增强而变薄
这里有一个很关键的判断标准:模型变强以后,你是不是还得不停给 harness 增加复杂度?
如果答案是肯定的,这套设计多半有问题。更健康的状态是,模型越强,harness 里的补丁逻辑越少,系统反而更简单。
有团队在半年里把系统重写了五次,每重写一次都在删复杂度:复杂工具定义被更通用的 shell execution 替代,所谓“management agents” 也被更直接的 structured handoff 替代。
6.2 模型和 Harness 已经开始共同进化
现在的模型,不再只是“会调工具”这么简单。很多模型在后训练阶段,就是带着特定 harness 一起学出来的。
这意味着一个现实问题:工具实现一改,性能可能就掉。 因为模型并不是在抽象意义上学会了“任意 harness”,它学会的,往往是某一套具体 harness。
一个很实用的 future-proofing test 是:如果换上更强模型,你的系统能在不继续变厚的前提下自然变好,这套 harness 才算设计得稳。
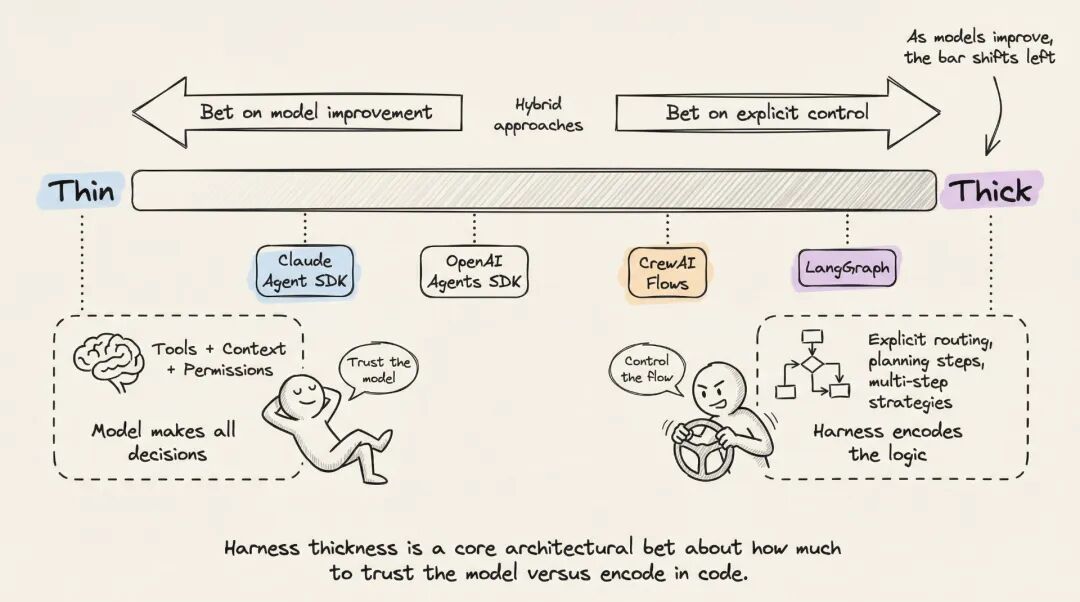
7. 每个 Harness 架构师都绕不过去的 7 个选择
做到这一步,基本每个做 harness 的人都会碰上下面这七道题。没有标准答案,但每一道都会直接影响性能、成本和可维护性。
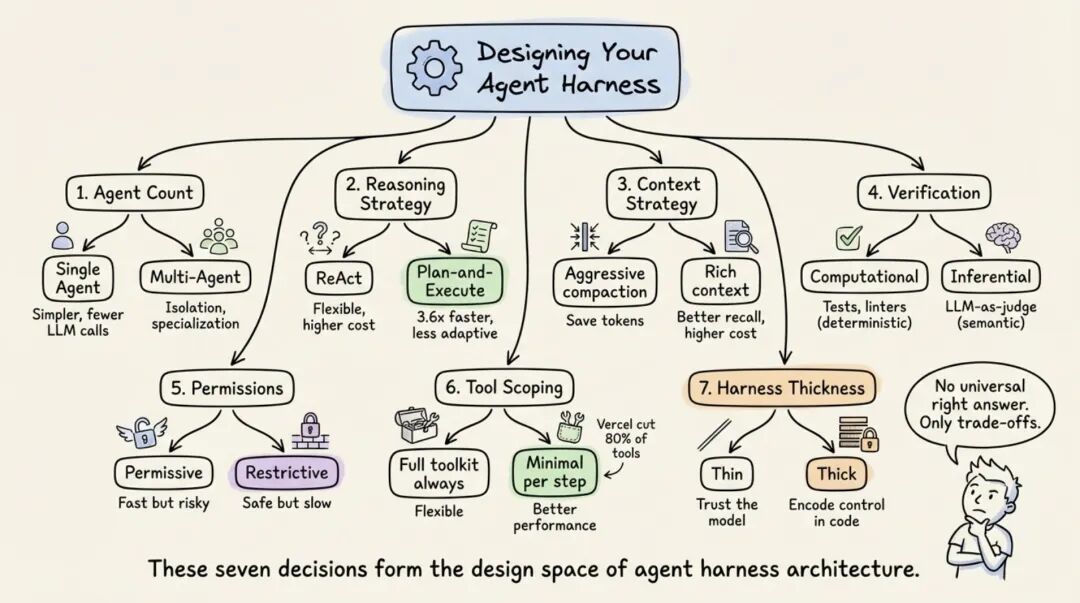
7.1 单 Agent 还是 Multi-Agent
Anthropic 和 OpenAI 的建议都很一致:先把单 Agent 做到极限。
Multi-Agent 会带来额外路由开销、更多 LLM 调用,以及 handoff 过程中的上下文损失。通常要等到工具数已经多到互相干扰,或者任务域确实天然分离时,拆开才更划算。
7.2 ReAct 还是 Plan-and-Execute
ReAct 的优点是灵活,每一步都能边想边做;代价是每一步都要付推理成本。
Plan-and-Execute 把规划和执行拆开,路径更稳定,吞吐也可能更高。有研究报告过,相比顺序 ReAct,这条路线能拿到 3.6 倍的速度提升。
7.3 上下文窗口怎么管
常见做法包括定时清空、会话摘要、observation masking、结构化笔记、sub-agent delegation。
这里没有万能方案。你得先想清楚当前任务更怕什么,是 token 成本太高,还是关键信息在压缩过程中丢掉。
7.4 验证闭环怎么搭
计算型验证,比如 tests、linters,优点是确定性强;推断型验证,比如 LLM-as-judge,优点是能发现语义层问题,但会带来延迟和额外成本。
实际落地时,通常还是两种一起上。先用 tests、linters 兜住确定性问题,再让 LLM-as-judge 去补语义层检查。
7.5 权限要放宽还是收紧
宽松权限跑得快,但风险高。严格权限更安全,但人类确认会拖慢节奏。
这不是体验偏好的问题,跟部署场景直接相关。开发沙箱、个人环境、生产系统,默认策略本来就应该完全不同。
7.6 工具要暴露多少
工具不是越多越好。工具一多,模型选择成本会升高,误用概率也会上来。
更稳的做法是按步骤懒加载,或者在当前阶段只暴露最小必要工具集。说白了,只给当下任务真正需要的那几把刀。
7.7 Harness 应该多厚
说到底,这是一个很现实的架构取舍:到底把多少控制逻辑写死在 harness 里,多少交给模型自己消化。
Anthropic 更偏薄 harness,赌模型会越来越会做规划和控制。图式框架则更偏显式控制,把很多行为写死在图上。
两边没有绝对对错,但趋势已经很明显:随着模型能力增强,很多以前要写在 harness 里的 planning 逻辑,会慢慢被删掉。
8. 我的结论
两套产品就算用的是同一个模型,最后表现也可能差很多。差距往往不在权重,而在 harness。
Harness 远没到“已经做成标准件”的阶段。真正难的工程,很多都堆在这里:上下文要当稀缺资源管,verification loop 要在失败放大前把问题拦住,memory system 要给连续性但别顺手制造幻觉,最后还得在“脚手架做到什么程度”和“把多少能力留给模型”之间做判断。
可以预见的一个趋势:模型会继续变强,harness 大概率会慢慢变薄。但这层东西不会消失。再强的模型,也还是需要一套机制去管理上下文、执行工具、保存状态、验证结果。
学AI大模型的正确顺序,千万不要搞错了
🤔2026年AI风口已来!各行各业的AI渗透肉眼可见,超多公司要么转型做AI相关产品,要么高薪挖AI技术人才,机遇直接摆在眼前!
有往AI方向发展,或者本身有后端编程基础的朋友,直接冲AI大模型应用开发转岗超合适!
就算暂时不打算转岗,了解大模型、RAG、Prompt、Agent这些热门概念,能上手做简单项目,也绝对是求职加分王🔋

📝给大家整理了超全最新的AI大模型应用开发学习清单和资料,手把手帮你快速入门!👇👇
学习路线:
✅大模型基础认知—大模型核心原理、发展历程、主流模型(GPT、文心一言等)特点解析
✅核心技术模块—RAG检索增强生成、Prompt工程实战、Agent智能体开发逻辑
✅开发基础能力—Python进阶、API接口调用、大模型开发框架(LangChain等)实操
✅应用场景开发—智能问答系统、企业知识库、AIGC内容生成工具、行业定制化大模型应用
✅项目落地流程—需求拆解、技术选型、模型调优、测试上线、运维迭代
✅面试求职冲刺—岗位JD解析、简历AI项目包装、高频面试题汇总、模拟面经
以上6大模块,看似清晰好上手,实则每个部分都有扎实的核心内容需要吃透!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】


AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 10
10 0
0- 0



 已为社区贡献218条内容
已为社区贡献218条内容

所有评论(0)