【AI前沿】BLIP-2图像分析实战:用Python让AI看懂图片并回答问题
引言:BLIP-2为何如此强大?

想象一下:你上传一张图片,AI不仅能描述图片内容,还能回答你关于图片的各种问题,比如"沙发是什么颜色的?"、“图片中有几只猫?”,甚至更复杂的问题。
这就是BLIP-2的魔力!作为一款先进的多模态AI模型,它打破了图像和语言之间的界限,让计算机能够像人类一样理解和交流视觉信息。
BLIP-2的核心优势在于:
- 多任务能力:一个模型同时支持图像描述、视觉问答等多种任务
- 灵活交互:使用自然语言与图像进行对话
- 开箱即用:无需自定义训练,直接使用预训练模型
- 计算高效:采用冻结视觉编码器+语言模型的设计,平衡性能和速度
今天,我将带你从零开始,用Python实现BLIP-2的图像分析功能,从环境搭建到模型推理,每一步都有详细的代码和说明。
BLIP-2:如何让AI理解图像?
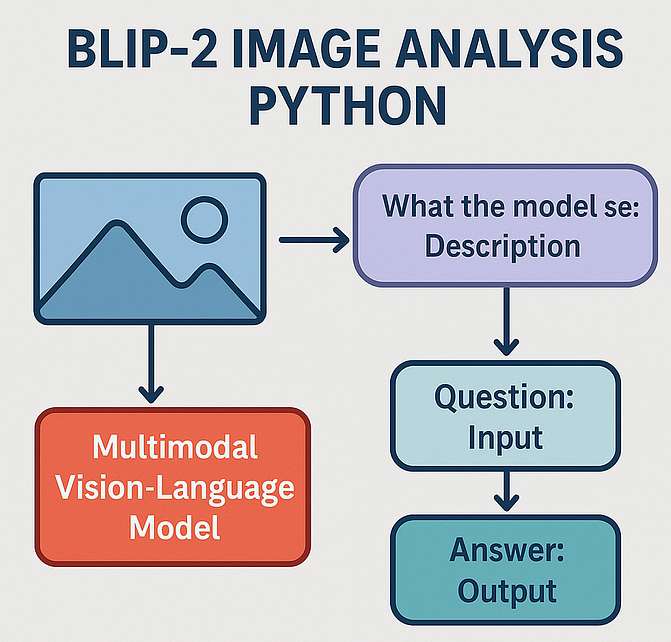
工作原理
BLIP-2的工作流程非常直观:
- 视觉编码:使用预训练的视觉编码器处理图像,提取视觉特征
- 特征桥接:将视觉特征转换为语言模型可理解的表示
- 语言生成:基于视觉特征和文本提示,生成自然语言输出
应用场景
BLIP-2的应用场景非常广泛:
- AI助手:理解用户上传的图片并回答相关问题
- 内容审核:自动分析图像内容,识别违规信息
- 无障碍工具:为视障人士描述图像内容
- 视觉搜索:通过自然语言查询图像内容
- 教育辅助:分析教学图片,回答学生问题
环境搭建:为BLIP-2做好准备
步骤1:创建conda环境
# 创建环境
conda create -n BLIP-2 python=3.11
# 激活环境
conda activate BLIP-2
# 检查CUDA版本
nvcc --version
步骤2:安装核心依赖
# 安装PyTorch(带CUDA支持)
conda install pytorch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0 pytorch-cuda=12.4 -c pytorch -c nvidia
# 安装SymPy
pip install sympy==1.13.1
# 安装Hugging Face Transformers
pip install transformers==4.46.2
# 如果遇到token长度错误,升级Transformers
pip install --upgrade git+https://github.com/huggingface/transformers.git
加载BLIP-2模型
from transformers import Blip2ForConditionalGeneration, Blip2Processor
import torch
from PIL import Image
import requests
# 选择设备(GPU优先)
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 加载处理器和模型
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained("Salesforce/blip2-opt-2.7b")
model.to(device)
模型选择小贴士
- blip2-opt-2.7b:平衡性能和速度
- blip2-opt-6.7b:更高的性能,但需要更多GPU内存
- blip2-flan-t5-xl:基于T5的版本,适合某些特定任务
图像分析:让AI描述图片

# 加载测试图片
url = "pexels-photo-12426042.jpeg"
image = Image.open(requests.get(url, stream=True).raw)
# 准备输入(无文本提示)
inputs = processor(images=image, return_tensors='pt', text="")
inputs.to(device)
# 生成描述
generate_ids = model.generate(**inputs, max_new_tokens=50)
generated_text = processor.batch_decode(generate_ids, skip_special_tokens=True)[0].strip()
print("✨ AI看到了什么:", generated_text)
输出示例
✨ AI看到了什么: a living room with a gray couch, a coffee table, and a cat sitting on the couch
视觉问答:与图片对话
# 问第一个问题
prompt = "Question: What is the color of the couch? Answer:"
inputs = processor(images=image, return_tensors='pt', text=prompt)
inputs.to(device)
generate_ids = model.generate(**inputs, max_new_tokens=50)
generated_text = processor.batch_decode(generate_ids, skip_special_tokens=True)[0].strip()
print("🛋️ 沙发是什么颜色的?", generated_text)
# 问第二个问题
prompt = "Question: How many cats? Answer:"
inputs = processor(images=image, return_tensors='pt', text=prompt)
inputs.to(device)
generate_ids = model.generate(**inputs, max_new_tokens=50)
generated_text = processor.batch_decode(generate_ids, skip_special_tokens=True)[0].strip()
print("🐱 有几只猫?", generated_text)
输出示例
🛋️ 沙发是什么颜色的? gray
🐱 有几只猫? 1
常见问题解答
Q:BLIP-2需要GPU吗?
A:虽然可以在CPU上运行,但GPU会显著提高速度。对于blip2-opt-2.7b,建议至少8GB GPU内存。
Q:BLIP-2的回答准确吗?
A:准确性取决于图像质量和问题复杂度。对于清晰的图像和明确的问题,BLIP-2通常能给出准确的回答。
Q:可以分析本地图片吗?
A:当然!只需要将Image.open(requests.get(url, stream=True).raw)改为Image.open("本地图片路径")。
Q:BLIP-2支持哪些图像格式?
A:支持PIL库能处理的所有格式,如JPG、PNG、BMP等。
Q:可以问多复杂的问题?
A:BLIP-2可以处理相当复杂的问题,比如"图片中左边的人在做什么?"、"背景中的建筑是什么风格?"等。
Q:BLIP-2适合生产环境吗?
A:是的,通过适当的优化和监控,BLIP-2可以在生产环境中使用。
Q:如何提高BLIP-2的性能?
A:使用更大的模型版本、优化批处理大小、使用GPU加速等。
Q:BLIP-2有什么局限性?
A:对于非常模糊或低质量的图像,表现可能不佳;对于复杂的推理问题,可能会出现错误。
实际应用示例
1. 智能相册管理
# 分析相册中的图片
def analyze_photo(image_path):
image = Image.open(image_path)
inputs = processor(images=image, return_tensors='pt', text="")
inputs.to(device)
generate_ids = model.generate(**inputs, max_new_tokens=100)
return processor.batch_decode(generate_ids, skip_special_tokens=True)[0].strip()
# 批量分析
for photo in photo_list:
description = analyze_photo(photo)
print(f"📷 {photo}: {description}")
2. 教育辅助工具
# 分析教学图片并回答问题
def teach_with_image(image_path, question):
image = Image.open(image_path)
prompt = f"Question: {question} Answer:"
inputs = processor(images=image, return_tensors='pt', text=prompt)
inputs.to(device)
generate_ids = model.generate(**inputs, max_new_tokens=100)
return processor.batch_decode(generate_ids, skip_special_tokens=True)[0].strip()
# 使用示例
answer = teach_with_image("cell.jpg", "这个细胞的结构是什么?")
print(f"🧬 答案:{answer}")
总结
BLIP-2代表了多模态AI的重要进展,它让计算机能够真正"理解"图像并通过自然语言进行交流。通过本教程,你已经掌握了:
- 环境搭建:创建适合BLIP-2运行的Python环境
- 模型加载:加载预训练的BLIP-2模型和处理器
- 图像分析:让AI描述图片内容
- 视觉问答:与图片进行自然语言对话
- 实际应用:将BLIP-2应用到智能相册、教育等场景
BLIP-2的出现,为我们打开了一扇通向更智能、更自然的人机交互的大门。无论是开发AI助手、无障碍工具,还是构建视觉搜索系统,BLIP-2都能提供强大的支持。
随着多模态AI技术的不断发展,我们可以期待未来的模型会有更强大的理解能力和更自然的交互方式。现在,就用BLIP-2开始你的多模态AI之旅吧!
好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)