从“会算”到“会查”:读懂 DeepSeek 的 Engram
DeepSeek的工作
DeepSeek 在 2026 年 1 月提出的 Engram,针对的是一个很基础、但过去常被埋在模型细节里的问题:现在的大语言模型已经很擅长 computation(计算),却没有一种原生的 knowledge lookup(知识查表) 能力。论文把这个问题直接写成一句话:“Transformers lack a native primitive for knowledge lookup.”(Transformer 缺少一种原生的知识查表原语。)意思是,很多本来更适合直接“取出来”的局部静态模式,例如固定短语、常见实体名、重复出现的代码模板,最后还是被迫交给网络一层一层重新算出来。为了解决这件事,论文提出了 conditional memory(条件记忆) 这条新路线,而 Engram 就是这种路线的具体实现。
找到“二级结论”
先看它为什么会成为问题。传统 Transformer(转换器架构) 的强项是用 attention(注意力机制) 和前馈层不断组合上下文,逐步形成更抽象的表示;这很适合处理动态推理,但不等于它擅长处理“本来就很固定”的局部模式。假设模型读到一句话:“Only Alexander the Great could tame the horse Bucephalus.”(只有亚历山大大帝才能驯服那匹名叫布西法拉斯的马。)对人来说,“Alexander the Great”通常会被直接当作一个整体概念来识别;但对标准 Transformer 来说,它往往还是先把这几个 token(词元) 分别编码成 embedding(嵌入表示),再依靠多层 attention(注意力机制) 和前馈网络,在当前上下文里逐步恢复出“这是一个固定历史人物名称”的整体含义。也就是说,本来更像“整体调取”的工作,被迫走了一遍“拆开编码—再重新拼合”的流程。论文的 mechanistic analysis(机制分析) 也明确指出,模型早层确实承担了很多 static reconstruction(静态模式重建) 的工作。
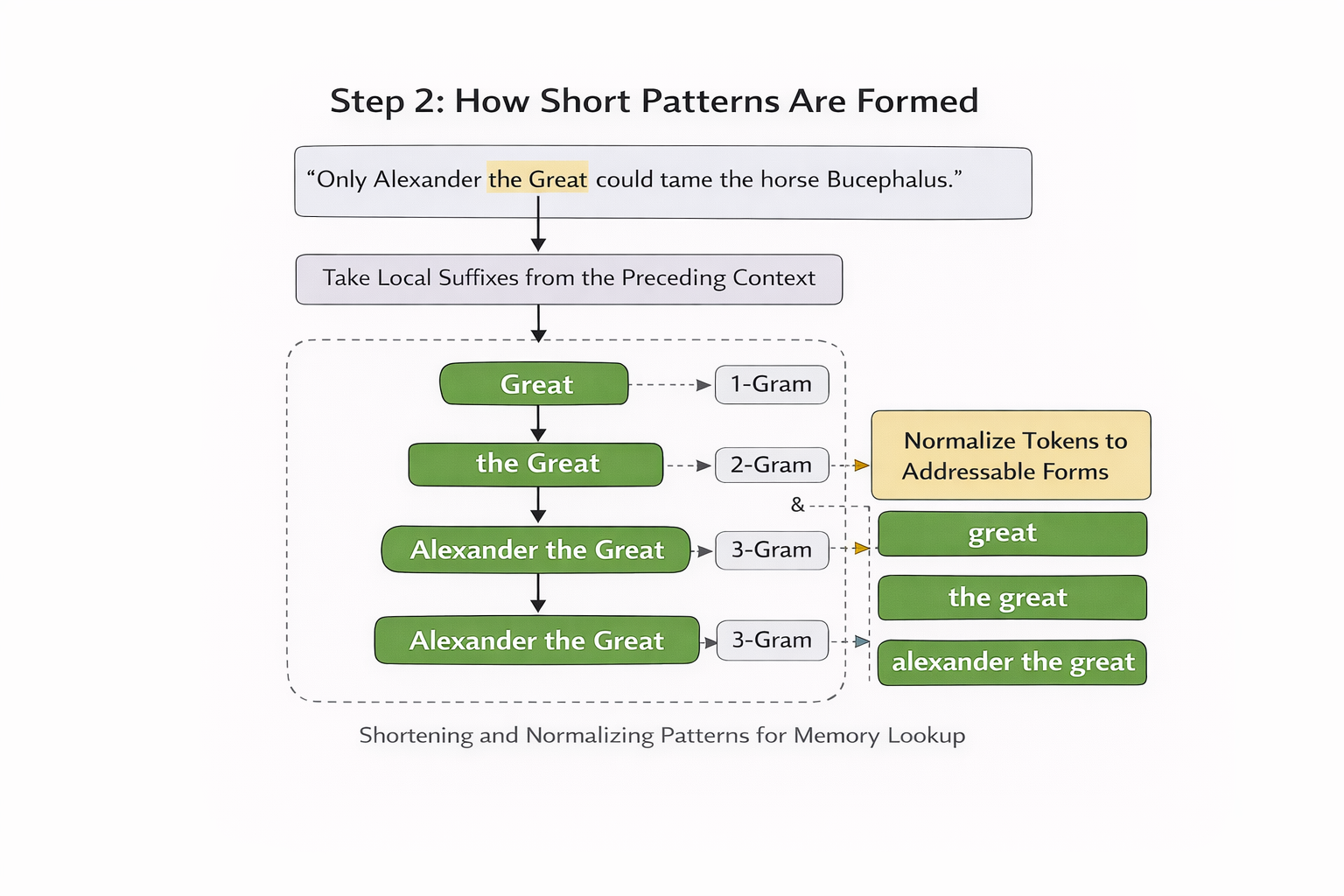
Engram 的切入点,就是把这条链改掉。它不是让模型完全不算,而是把“局部且稳定”的那一部分先交给查表。还是以上面的实体名为例:当模型处理到当前位置时,Engram 会先从当前位置前面的局部上下文里抽取 suffix n-gram(后缀 N 元片段),也就是取连续的几个 token 组成一个短模式;然后把这个短模式压缩、规范化,再通过 hashing(哈希映射) 去静态 memory table(记忆表) 里查出一个候选向量。这样一来,模型就不必每次都靠主干网络从零重建“Alexander the Great”这种局部固定模式,而是先得到一个可复用的候选表示,再看当前上下文是否支持它。论文把整个过程拆成 retrieval(检索) 和 fusion(融合) 两步,并说明 Engram 的作用就是“retrieving static N-gram memory and fusing it with dynamic hidden states”(检索静态 N 元片段记忆,并把它与动态隐藏状态融合)。

代码场景下,这条逻辑会更明显。比如模型看到 for i in range(len(x)): 或 try: ... except: 时,真正重要的往往不是单个 token,而是这整段局部组合已经形成了一个高度稳定的语法模板。标准 Transformer 仍然要逐个 token 编码,再依赖多层 attention 去恢复“这是循环头”“这是异常处理结构”这样的整体意义;Engram 则把这类高频、局部、重复出现的模板,当作适合直接调用的静态模式。它先把局部上下文映射为 suffix n-gram,再通过 deterministic hashing(确定性哈希) 从嵌入表里取回候选记忆,后续由当前上下文决定是否采纳。于是,Engram 不是替代 reasoning(推理),而是先接走那些本来更像“查表”的工作,把主干网络的计算预算留给真正需要跨句、跨段整合的复杂推理。
注意力的节流
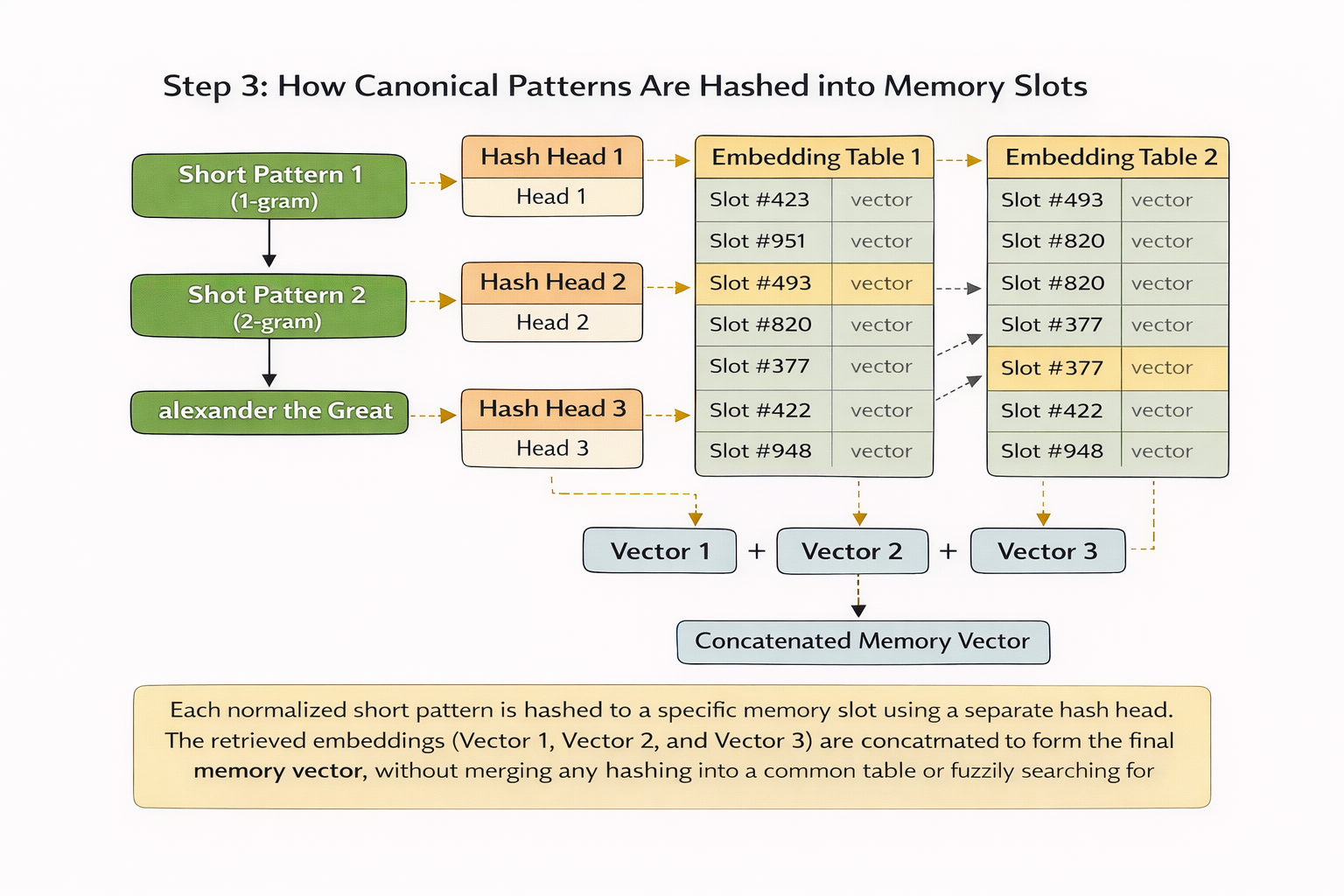
Engram 的第一阶段,本质上是在做“把局部短模式变成可查表的记忆线索”。它不会直接拿原始分词结果去拼 n-gram,因为同一个意思可能会被分成不同的 token。比如 Apple 和带前导空格的 apple,在普通分词器里可能是不同 ID,但它们的语义其实很接近。Engram 会先做 tokenizer compression(分词压缩) 和 vocabulary projection(词表投影),把这些表面不同但意义接近的 token 尽量压到更统一的表示上,再从当前位置前面的局部上下文中抽出几个短模式,用 multi-head hashing(多头哈希) 分别算出地址,去嵌入表里直接取回对应的 embedding vector(嵌入向量)。取回来的不是具体文本,而是模型内部可以直接参与后续计算的向量表示;不同长度短模式取回的向量再被拼接起来,形成最终的 memory vector(记忆向量)。
但“取到了记忆”不等于“这段记忆现在就一定对”。因为这些向量是静态的,只反映这个短模式通常意味着什么,却不知道当前句子到底在表达什么,所以它们可能因为 hash collision(哈希冲突) 带来错误信息,也可能因为 polysemy(一词多义) 和当前语境不一致。为了解决这个问题,Engram 在第二阶段加入了 context-aware gating(上下文感知门控):它用当前 hidden state(隐藏状态) 去判断取回来的记忆和当前上下文是否匹配。匹配的,就放大它的作用;不匹配的,就把它压低,甚至接近不用。也就是说,Engram 不是“查到什么就直接塞回模型”,而是“先查,再由当前上下文决定该用多少”。
这也解释了为什么 Engram 不是“死记硬背”。还是以“apple”为例,如果一句话是 “Apple released a new phone.”(Apple 发布了新手机。)那么静态记忆里可能同时存在与水果和公司相关的局部模式;真正决定该选哪一边的,不是记忆表本身,而是当前 hidden state(隐藏状态) 已经聚合起来的上下文信息。因为句子里有 “released” 和 “phone” 这样的线索,context-aware gating(上下文感知门控) 就更可能放大“Apple 公司”相关的记忆,压低“水果”相关的噪声。换句话说,Engram 的完整链条不是“看见局部模式就直接套用记忆”,而是“先查到候选记忆,再由当前上下文做筛选和调制”。
理解了这条链之后,就更容易明白一个看似反直觉的实验结果:为什么一个 memory module(记忆模块) 不只提升知识题,反而对 reasoning(推理)、code(代码)、math(数学) 也帮助很大。论文在 iso-parameter and iso-FLOPs(等参数量、等计算量) 的对照下报告,Engram-27B 相比 MoE 基线在 MMLU 上提升 3.4 分、CMMLU 提升 4.0 分,而在 BBH、ARC-Challenge、HumanEval、MATH 等推理、代码和数学任务上也出现了明显收益。论文给出的解释不是“它背了更多知识”,而是它减轻了主干早层的 static reconstruction(静态模式重建) 负担,因此“effectively deepening the network for complex reasoning”(在功能上让网络对复杂推理显得更深)。这里的意思不是物理层数增加了,而是说:原来前几层要分出很多能力去重建局部静态模式;现在这部分工作被条件记忆接走,主干层就能更早把容量投入真正复杂的抽象与推理。
同样的分工变化,也解释了它在长上下文上的提升。论文写得很直接:by delegating local dependencies to lookups, Engram frees up attention capacity to focus on global context(把局部依赖交给查表后,Engram 释放了注意力容量,使其更专注于全局上下文)。这句话背后的逻辑是,attention(注意力机制) 的能力本来就有限;如果它既要重复处理很多固定局部模式,又要负责远距离信息整合,那么全局建模会被局部负担挤压。Engram 接走一部分局部依赖后,attention 就能把更多精力花在长距离关联上。论文给出的结果是,Multi-Query NIAH 从 84.2 提升到 97.0,Variable Tracking 也有明显提升。
与其余工作的区分
再往外看,Engram 真正新颖的地方,还在于它把“稀疏化”多拆出了一条轴。以前谈 sparse models(稀疏模型),很多人首先想到的是 MoE(Mixture-of-Experts,专家混合模型),因为它通过只激活少数专家来节省每步计算;而这篇论文提出,除了 conditional computation(条件计算),还可以有 conditional memory(条件记忆)。于是就出现了一个新的问题:在总参数量和总计算量固定时,到底该把多少稀疏容量分给 neural computation(神经计算),多少分给 static memory(静态记忆)?论文把它称为 Sparsity Allocation(稀疏分配) 问题,并报告了一个 U-shaped scaling law(U 形缩放规律):容量全压在 MoE 上未必最优,全压在 Engram 上也未必最优,中间存在更好的平衡点。
因此,Engram 与几种常见概念必须分开看。它不是 MoE 的替代品。MoE 解决的是“怎样更高效地算”,Engram 解决的是“哪些东西本来就不该反复算,而该直接查”。它也不是 RAG(Retrieval-Augmented Generation,检索增强生成) 的变体。RAG 去的是模型外部的文档库、数据库、网页;Engram 查的是模型内部训练出来的静态记忆表。前者更像“翻资料”,后者更像“脑内固定模式的快速调用”。它同样也不是 KV cache(键值缓存);KV cache 是推理阶段缓存已经算过的注意力键值,优化的是“同一段上下文别重复算”,而 Engram 优化的是“有些局部模式本来就更适合查表,不必每次都靠主干重建”。这些区别虽然有一部分是推论,但都直接建立在论文对 Engram、MoE 和内部静态记忆机制的定义之上。
向工程的一些探索
除了建模意义,Engram 还有很强的工程意义。论文和官方 README 都强调,它使用 deterministic addressing(确定性寻址)。这意味着,对于给定的局部片段,系统可以提前知道需要访问哪些 memory slot(记忆槽位),从而进行 runtime prefetching(运行时预取):在 GPU 计算之前或同时,先从 host memory(主机内存) 把相关嵌入拉过来。论文给出的结论是,把一个 100B 参数量级的表下放到主机内存,额外开销仍然可以做到很小;README 也把这一点总结为可以将 massive embedding tables(大规模嵌入表) offload(下放) 到 host memory(通常指CPU内存),并保持 minimal inference overhead(很小的推理额外开销)。这说明 Engram 不只是理论上增加了一块静态记忆,它连系统层面的访问方式也一并设计了。
不过,现阶段它更像一个很清晰的架构方向,而不是现成可直接工业部署的完整方案。DeepSeek 官方仓库已经公开了 demo implementation(演示版实现),但 README 和示例代码都明确说明,这份实现主要用于说明 core logic and data flow(核心逻辑和数据流),很多标准组件被 mock(模拟) 或简化,真正的 production use(生产使用) 还需要进一步优化,例如自定义 CUDA kernel、分布式训练支持等。也就是说,Engram 的思想已经很完整,但它距离通用高性能工程化,还有一段实现工作。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 13
13 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)