Ai通识与基础-认识人工智能

认识人工智能
智能产生的要素
影响大模型智能的核心要素有三点:
-
模型算法。首先是模型算法,现在的AI都是采用神经网络架构,你可以把它看做是AI的大脑,是决定AI是否”聪明”的基础。
-
海量数据。AI也是一样,要想让AI产生智慧,就必须用海量的数据来训练它。上个世纪,互联网不够发达,可以用来训练的数据也比较少。
-
超级算力。大模型训练的数据规模庞大,神经网络架构复杂,因此训练时的计算量都是天文数字。需要成千上万的顶级GPU一起,不间断的工作数周,甚至数月才行,这背后是巨大的电力消耗和硬件成本。
大模型原理
前面我们说过,AI的神经网络模型就是在模仿人类的神经元:
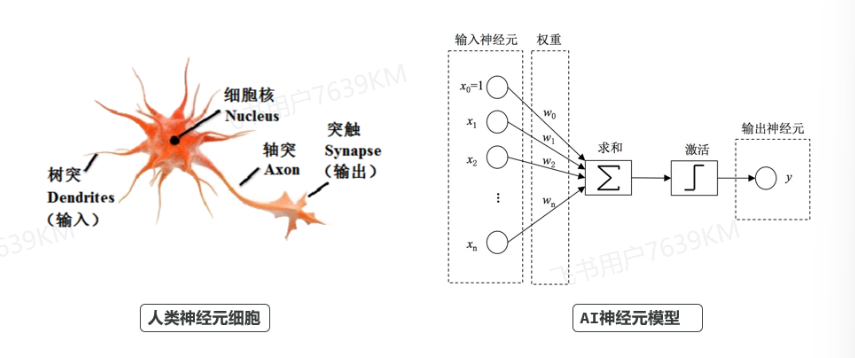
神经网络结构
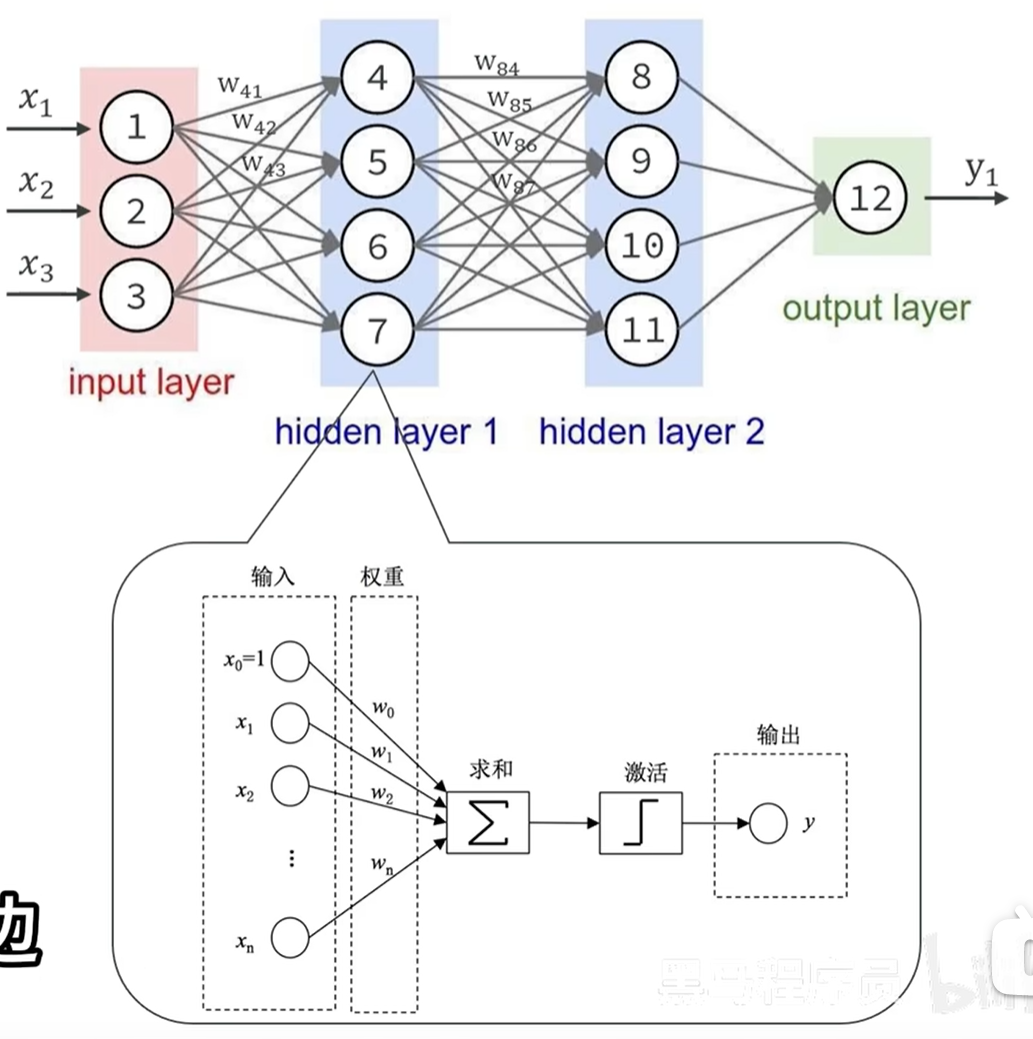
深度神经网络分为很多层(Layer),是神经网络基本的计算单元,分为:
- 输入层:入口,接收数据
- 隐藏层:信息处理与学习。可以有很多层。
- 输出层:出口,产生结果。
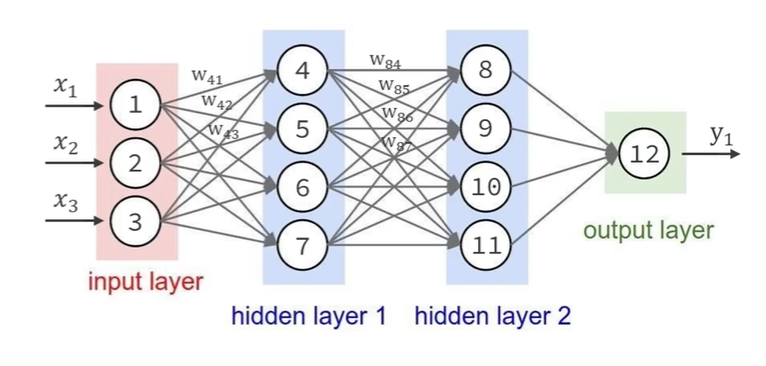
整个神经元的工程流程是可以用一个公式去表达的。
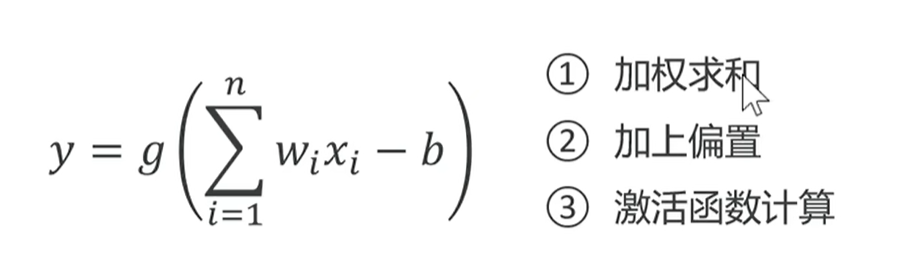
括号里面有个wi*xi,w是权重,x是输入,它俩相乘是在对输入参数进行加权,从1到n表示从第一个参数到第n个参数进行求和,所以先加权在求和,-b被成为“偏置量”,有的时候我们加权求和完,得到这个结果,我期望它必须得达到一定的阈值,超过这个阈值以后,它的作用才会生效。所以在这里-b,其实就是减去阈值,把得到的结果再去交给激活函数进行处理,所以这个括号外边的g其实就是激活函数,最终就能得到结果。
反向传播:教这个复杂神经网络学习的高效方法。
基本流程如下:
- 前向传播:数据逐层加工,直到输出层产出结果。
- 计算误差:计算产出结果与正确结果的误差。
- 反向追责:倒退计算每一层的每个连接对误差的贡献。
- 调整权重:根据每个连接的误差贡献比例,调整其权重参数,使误差变小。
大语言模型
在2003年,图灵奖得主约书亚·本吉奥(Yoshua Bengio)的一篇名为《A neural probabilistic language model》的论文开创了神经网络语言模型(Neural Network Language Model,NNLM)的先河。
这篇文章中首次提到了词向量(Word Embedding)的概念雏形,这为神经网络训练学习自然语言打下了坚实的基础。
词向量就是把词转为多为空间向量的一种技术、
首先,将人类自然语言文字拆分为一个个片段,称为Token(词)。
每个Token都经过模型计算转为一个浮点数数组,称为向量坐标、

我们现在看到的这个例子,它在拆分时,把一个个单词拆分成一个的Token,但是在真实中,它不一定是这个样子,真实中拆分的Token可以是单词,汉字,标点符号,还可以是一个很长单词的一部分,这里是为了方便理解,就当成一个个的单词或汉字了。
假如我们有一个数组,里面有3个浮点数,我们就可以把这3个浮点数分别作为一个三维空间的x,y和z轴上的一个坐标,这样就得到了一个三维空间的向量,由此可见,数组里面有几个数字,就能转为几维空间的向量坐标。那么我们的词向量,它里面有几个浮点数呢,如果它转化成一个向量的话,那就是12288维空间的向量,在数学中理论上是可以有任意维度的空间的,因此这个12288个数组就可以表示12288维空间中的向量。最后我们人类中的所有词汇都可以转成这个一万多维空间的一个向量,而且我们最终要通过训练模型,就是要不断的去调整这些词在向量空间中的坐标位置,最终使这个词向量在多维空间中不同方向能够去表达不同的语义。
-
每个词语都可以经过模型运算转化为一个多维向量(也就是一个浮点数数组,GPT3采用12288维向量)
-
通过训练使模型计算出的多维向量与文字语义产生关联,使多维空间中的不同方向表示不同语义
自注意力机制:使模型能更高效的根据上下文信息处理token,理解token含义。
比如说我现在有一句话“有一个知名男艺人,___”,如果只给你这一句话,这个艺人是谁,你肯定不知道,所以此时模型去处理的话,那么它生成出来的向量,肯定在向量空间中仅仅表示的是艺人本身
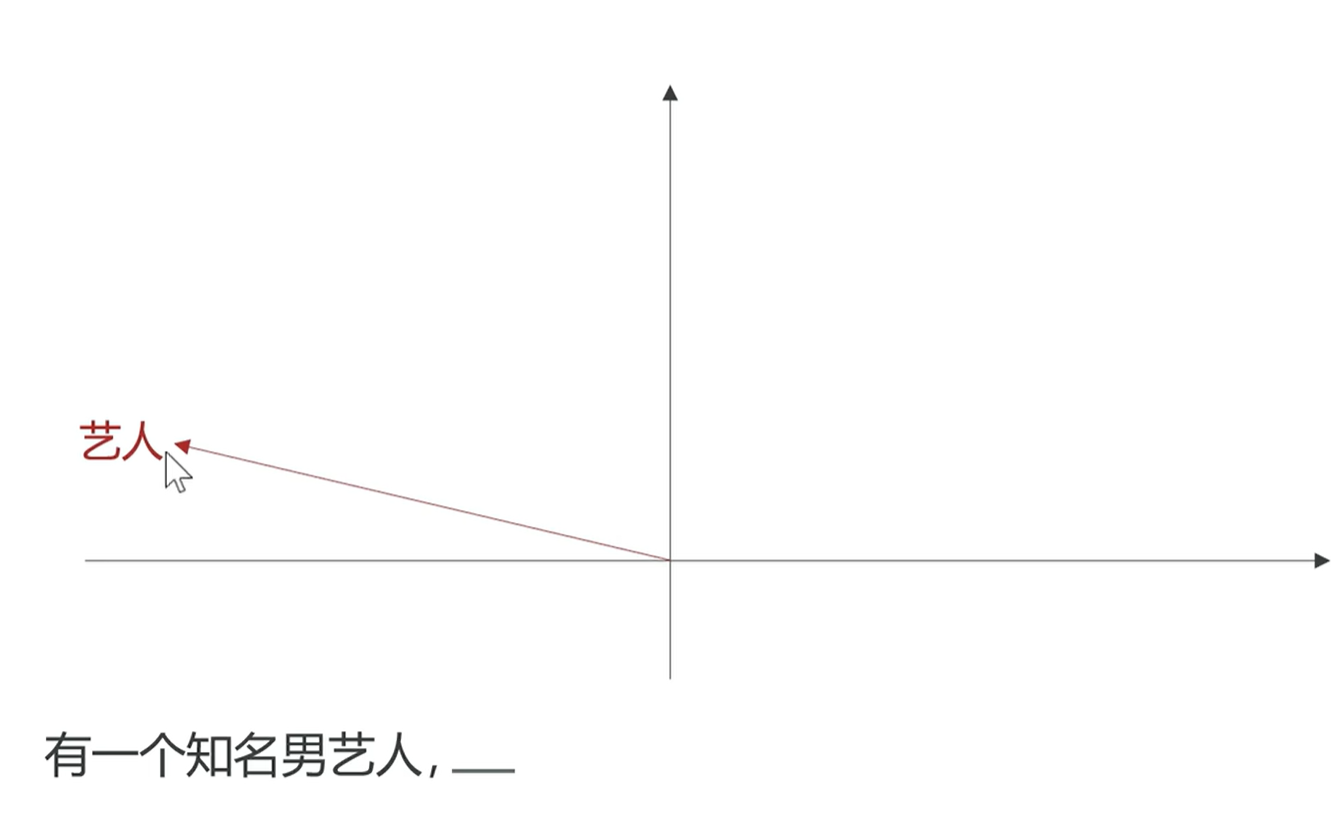
现在如果我们进一步的去提供上下文,比如说我告诉它“有一个知名男艺人,擅长唱歌___”,这个时候自注意机制就会根据上下文来对当前的这个向量进行调整,在向量的不同方向上表达不同的含义,那就看一下这个向量空间中哪个方向表示的是唱歌这个含义,然后它就把艺人这个方向朝着唱歌这个方向调整。

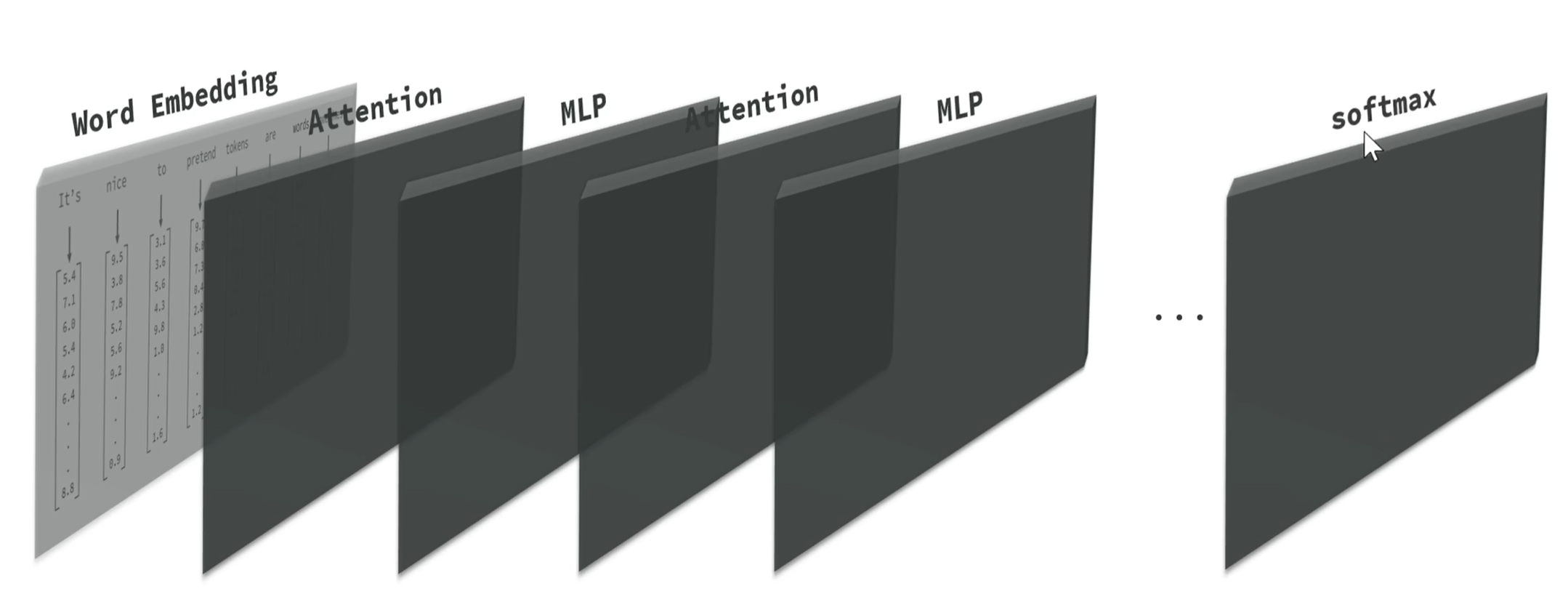
词向量只是第一步,接下来它还有很多步骤需要去做,接着我们就需要有一个Attention层,负责基于上下文来对这个里面的向量进行进一步的调整,接下来MLP层,也叫多层感知机,它负责基于前面的分析在进一步做深度的推理分析,来去进一步调整向量值。再往后就是不断的去重复前面的过程,再跟上Attention层,MLP层,等等...直到得到最终的结果,也就是向量坐标值。最终还需要把计算出的向量再转成Token,也就是反向量化,这个工作是叫做softmax来完成的。
大模型应用
什么是大模型应用
大模型应用是基于大模型的推理,分析,生成能力,结合传统编程精确计算控制能力,开发出的各种应用。
对话机器人(ChatBot)是指可以与用户聊天,答疑,而且具有记忆的大模型应用。例如:ChatGpt,通义千问。
GPT是大模型,而ChatGpt则是基于大模型的一种对话的产品。
怎么把一个大模型变成一个对话机器人?
大模型应用的结构
一个对话的机器人,由大模型和传统应用去结合的。大模型负责对话,思考;传统编程负责实现一些传统的图形界面,用户登录和身份校验,和一些数据的存储记忆这些功能。所以ChatPgt就是一种把传统应用和大模型结合的一种应用,也就是大模型应用
模型部署
大模型API

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)