模型剪枝方法全解
目录
三、非结构化剪枝(Unstructured Pruning)
6.1 训练后剪枝(Post-Training Pruning)
6.2 训练中剪枝(Pruning During Training)
6.3 稀疏化训练(Training with Sparsity Regularization)
6.4 初始化时剪枝(Pruning at Initialization)
做模型压缩,剪枝往往是最先被提到的技术,但也是最容易被讲浅的一个。很多教程只说"把权重小的去掉",然后贴一段 torch.nn.utils.prune 的代码就算完事了。这篇文章希望把剪枝讲透——从动机、数学直觉、各类方法,一直到 LLM 时代的新挑战和新方案(SparseGPT、Wanda)——把整条脉络梳理清楚。
一、需要剪枝的原因:过参数化
深度学习有一个几乎反直觉的特点:过参数化(over-parameterization)对训练有好处,但对推理是负担。
训练一个大模型,参数越多越容易收敛、越不容易陷入糟糕的局部极值。然而,训练完成后,这些参数里有相当一部分实际上对模型的输出贡献很小,甚至几乎为零。把它们留着不过是在推理时浪费计算和内存。
有多浪费?Han et al. (2015) 的经典工作《Learning both Weights and Connections for Efficient Neural Networks》里发现,AlexNet 和 VGG 这些早期大模型有高达 80% 以上的权重可以被移除,而性能下降几乎可以忽略不计。这个观察启发了整个剪枝研究领域。
更有理论支撑的是 Frankle 和 Carlin 在 2019 年提出的彩票假说(Lottery Ticket Hypothesis):一个大的随机初始化网络里,存在一个小得多的子网络(中奖票),如果用相同的初始权重单独训练这个子网络,它能达到和完整网络相当的性能。剪枝的本质,就是找到这张"中奖票"。
剪枝的实际价值体现在三个方向:减小模型体积(存储)、加速推理(计算量)、降低内存占用(带宽)。在边缘部署、移动端、实时推理等场景下,这三点都直接关系到能不能用。
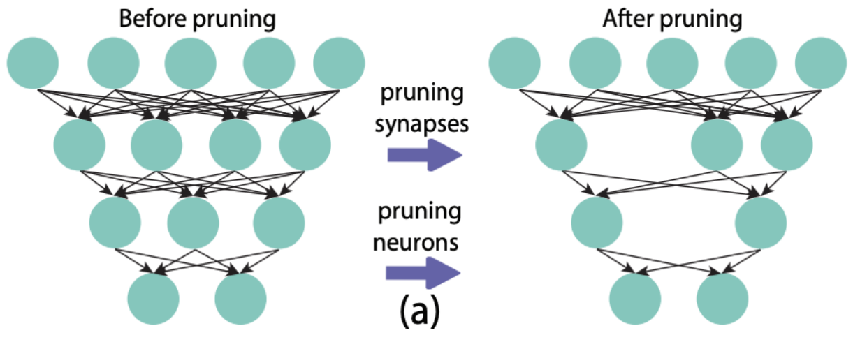
二、剪枝的基本流程
在深入各种具体方法之前,先把标准的剪枝流程讲清楚,后面所有内容都是在这个框架里做变体。
训练 → 剪枝 → 微调(Fine-tune) 是最经典的三阶段范式:
第一步,在完整数据集上正常训练一个大模型,让它充分收敛。
第二步,按照某种重要性判据(importance criterion),把不重要的参数移除或置为零,得到一个稀疏化的模型。这个步骤会导致精度下降。
第三步,对剪枝后的模型做微调(也叫 fine-tune 或 recovery training),在数据集上继续训练若干 epoch,让剩余的权重重新调整适应,把精度恢复回来。
在 PyTorch 里,剪枝通常不是真的删掉参数,而是给参数打一个二值 mask:mask 为 1 的位置权重保留,mask 为 0 的位置权重被遮盖(等效于置零)。这样做的好处是剪枝可逆,可以随时改变 mask 重新选择被剪的参数,适合迭代式剪枝。
import torch
import torch.nn as nn
import torch.nn.utils.prune as prune
# 一个简单的全连接层
layer = nn.Linear(100, 50)
# 对这一层的 weight 做 L1 非结构化剪枝,去掉幅值最小的 30%
prune.l1_unstructured(layer, name='weight', amount=0.3)
# 查看稀疏度
sparsity = float(torch.sum(layer.weight == 0)) / layer.weight.nelement()
print(f"Sparsity: {sparsity * 100:.1f}%") # 约 30%
# 把 mask 永久固化(真正删除被剪的连接)
prune.remove(layer, 'weight')
PyTorch 的实现细节值得说一下:调用 prune.l1_unstructured 之后,模块会多出两个属性——weight_orig(原始权重)和 weight_mask(二值掩码)。在 forward pass 里实际用的是 weight = weight_orig * weight_mask。只有调用 prune.remove 之后,才会把这个遮盖操作固化,真正修改 weight 参数。
三、非结构化剪枝(Unstructured Pruning)
非结构化剪枝是最细粒度的剪枝方式:独立地看待每一个权重,根据它的重要性决定是否保留,不考虑它在矩阵里的位置关系。
3.1 幅值剪枝(Magnitude Pruning)
最简单也是最广泛使用的重要性判据:权重的绝对值越小,说明它对输出的贡献越小,应当优先被剪掉。
直觉上这很合理——如果一个权重接近于零,把它真的置为零,前向传播的输出几乎不会变化。形式上,对于权重矩阵 ,重要性分数就是
,然后找一个阈值
,把所有
的权重置零。
# 全局幅值剪枝:对整个模型的所有层统一设置稀疏度
parameters_to_prune = [
(model.fc1, 'weight'),
(model.fc2, 'weight'),
(model.fc3, 'weight'),
]
prune.global_unstructured(
parameters_to_prune,
pruning_method=prune.L1Unstructured,
amount=0.5, # 全局移除 50% 的权重
)
注意这里用的是 global 剪枝,而不是每层独立地剪 50%。全局剪枝的意思是把所有层的权重放在一起排序,找到全局的第 50% 分位数作为阈值,统一决定哪些权重被剪。这比每层独立剪枝(local pruning)效果通常更好,因为不同层对精度的贡献差异很大——靠近输出的层往往更敏感,不应该和靠近输入的层一视同仁地各剪 50%。
3.2 非结构化剪枝的硬件问题
非结构化剪枝有一个根本性的工程困境:它产生的稀疏矩阵在标准硬件上并不能直接加速。
CUDA 的矩阵乘法 kernel 是专门针对稠密矩阵优化的。一个 70% 稀疏的矩阵,在 GPU 上做矩阵乘法,实际消耗的时间和一个稠密矩阵几乎没有区别——因为 GPU 仍然要把那些零值的位置也处理完,而不是自动跳过它们。
要真正利用稀疏性加速,有两条路:一是用专门的稀疏矩阵运算库(如 NVIDIA 的 cuSPARSE),在稀疏度足够高(通常 >90%)时才有实际加速效果;二是使用 NVIDIA 在 Ampere 架构引入的 2:4 结构化稀疏(N:M sparsity)——后面会讲到。
这个问题是非结构化剪枝最大的局限:参数数量确实降下去了,但延迟往往没有同比例改善。
四、结构化剪枝(Structured Pruning)
既然非结构化剪枝产生的稀疏矩阵不友好,更激进的方案是直接删除整个结构单元——结构化剪枝。
结构化剪枝不是移除单个权重,而是移除完整的 filter(卷积核)、channel(通道)、attention head、甚至整层。一旦某个结构被移除,对应的矩阵维度直接减小,模型天然变成一个更小的稠密网络,标准硬件可以直接加速,不需要任何稀疏矩阵支持。
4.1 卷积网络的 Filter / Channel 剪枝
对于卷积网络,最常见的结构化剪枝单位是 filter(输出 channel)。
每个卷积层有若干个 filter,每个 filter 负责提取一种特征。如果某个 filter 的权重整体都比较小,或者它的输出激活值绝大多数时候接近零,那这个 filter 的贡献很有限,可以整体移除。
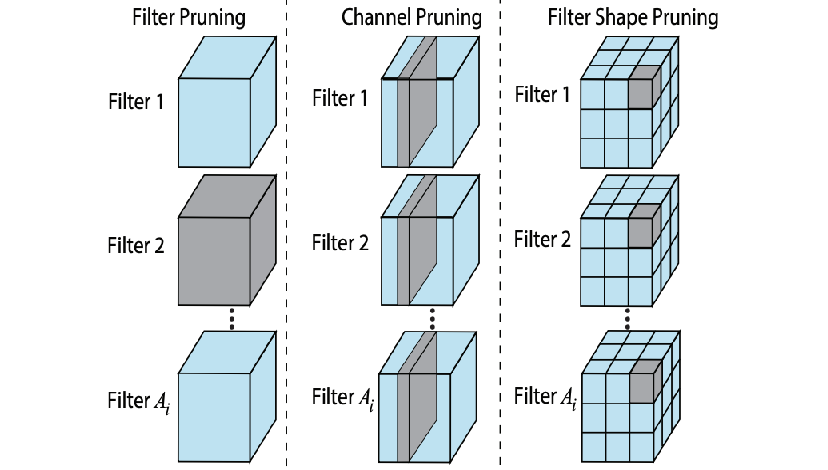
判据一:L1/L2 Norm
计算每个 filter 的权重向量的 L2 范数作为重要性分数,去掉范数最小的若干个 filter。
# 对卷积层做 L2 结构化剪枝,按 dim=0(输出通道维度)去掉 25% 的 filter
prune.ln_structured(conv_layer, name='weight', amount=0.25, n=2, dim=0)
判据二:基于 Batch Normalization 的 scaling 因子
BN 层对每个通道学习一个缩放因子 γ(gamma)。如果某个通道的 γ 很小,说明这个通道在整个网络里被压制了,相当于这个 filter 的输出被 BN 主动抑制。这个方法不需要单独计算重要性,直接复用 BN 的 γ 参数作为剪枝信号,非常自然。
判据三:基于激活值的 APoZ
APoZ(Average Percentage of Zero activations)统计一个 filter 的输出激活值中有多少比例接近零(通常是过 ReLU 之后为零的比例)。一个经常输出全零的 filter 实际上什么也没做,可以安全移除。
4.2 Transformer 的结构化剪枝
对于 Transformer 系模型(BERT、LLaMA 等),结构化剪枝的目标变成 attention head、FFN 的神经元、甚至整个 Transformer 层。
Attention Head 剪枝:每个多头注意力层有若干个 head,可以通过测量每个 head 对模型输出的影响(比如对 loss 的梯度信号,或者直接把某个 head 掩掉看精度下降多少)来判断它的重要性,去掉不重要的 head。微软的 FAR 和 Michel et al. 2019 的工作都在这个方向做了系统研究,发现大量 Transformer 模型里很多 head 几乎可以被移除而不影响性能。
FFN 维度剪枝:Transformer 的前馈网络有一个先扩展(通常 4x)再压缩的结构,中间层的神经元也可以被结构化地剪掉,直接减小 FFN 的中间维度。
层剪枝(Layer Pruning):最粗粒度的结构化剪枝,直接去掉整个 Transformer block。研究发现,深层模型(如 BERT-Large 的 24 层)里靠近输出的若干层对最终性能贡献相对较小,可以被整体移除。这是目前对 LLM 做结构化压缩最直接的手段之一。
4.3 结构化 vs 非结构化的权衡
这两种剪枝方式各有优劣,选择哪一种主要取决于部署场景:
非结构化剪枝的优点是灵活,可以达到非常高的稀疏度(80%+)而不显著损失精度,因为它以最精细的粒度保留了最重要的权重;缺点是产生的稀疏矩阵在标准 GPU 上难以加速。
结构化剪枝的优点是产物是一个更小的稠密模型,可以在任何硬件上直接加速,工程友好;缺点是粒度粗,在相同精度损失下能达到的压缩率通常低于非结构化剪枝。
五、重要性判据:判断"谁该被剪"是剪枝的核心
剪枝的质量在很大程度上取决于如何衡量参数的重要性。上面提到的幅值、L2 norm 都是比较朴素的方法,研究者们提出了越来越精细的判据。
5.1 基于梯度的方法
参数的重要性不只看它的值,还要看改变它对损失函数的影响。一阶梯度 ∂L/∂w 反映的是将某个权重增大一点点时 loss 的变化率,可以用来衡量权重的重要程度。
Optimal Brain Damage(OBD,LeCun et al. 1990)是这个方向的经典工作,利用损失函数对权重的二阶偏导(Hessian 矩阵对角元素)来更准确地估计删除某个权重对 loss 的影响。其后继工作 Optimal Brain Surgeon(OBS)进一步考虑了 Hessian 的非对角元素,并在删除某个权重后对其他权重做补偿更新,理论上更精确。
这类方法的精度更高,但计算 Hessian 或其近似的代价相当高,限制了它在大模型上的直接应用——直到后来被 SparseGPT 以近似的方式带回了 LLM 剪枝领域(后面详述)。
5.2 基于 Taylor 展开的方法
Molchanov et al. (2017) 提出了一个实用的近似方法:用 Taylor 展开来估计移除参数 w_i 对损失的影响:
这个乘积同时考虑了权重的幅值和梯度,比单纯用幅值更准确。直觉上:一个权重很大但梯度为零,说明当前 loss 对它不敏感,可以剪;一个权重很小但梯度很大,说明改变它会显著影响 loss,应该保留。
5.3 基于激活值的方法
另一条思路是不看权重本身,而是看权重对应的输出激活值。如果一个神经元的输出在大量样本上都接近零,说明它在实际推理中几乎没有被激活,可以被移除。这种方法不依赖梯度,只需要跑一遍前向传播统计激活分布,计算非常高效。
六、剪枝的时机:什么时候剪
除了"剪什么","什么时候剪"也是影响最终效果的重要因素。
6.1 训练后剪枝(Post-Training Pruning)
最直接:模型训练完了,直接在上面做剪枝。优点是不需要修改训练流程,可以对任何现成的预训练模型应用;缺点是训练时模型不知道自己将来要被剪,剪完之后精度下降可能比较大,需要微调来恢复。
6.2 训练中剪枝(Pruning During Training)
在训练过程中动态地剪枝,让模型在稀疏状态下继续学习。最经典的是 Gradual Magnitude Pruning(GMP)(Zhu and Gupta, 2018):从一个小的初始稀疏度开始,随着训练的进行,按照一个调度策略(通常是三次函数曲线)逐渐提高稀疏度,最终达到目标稀疏度。这个过程让模型有时间"适应"稀疏化,比一次性剪掉效果好很多。
6.3 稀疏化训练(Training with Sparsity Regularization)
在 loss 函数里加入 L1 正则项来惩罚权重的绝对值之和,L1 正则化天然会把很多权重推向零,让模型主动学会稀疏化。这和剪枝有相通之处,但更柔和——它不强制置零,而是让模型在训练中自然形成稀疏结构。
6.4 初始化时剪枝(Pruning at Initialization)
SNIP(Lee et al. 2019)等工作尝试在训练一开始就判断哪些连接是重要的,直接从一个稀疏子网络开始训练。这条路最理想,但判断"还没训练的模型哪些参数是重要的"本身就很困难,实际效果不如先训练后剪枝稳定。
6.5 迭代剪枝(Iterative Pruning)
不论在哪个时间点剪,迭代剪枝往往比一次性剪(one-shot pruning)效果更好。具体做法:每次只剪一小部分(比如剩余权重的 10%),然后微调恢复精度,再剪,再微调……反复迭代直到达到目标稀疏度。
这符合直觉:每次只做小幅度的改变,给模型时间适应,避免精度断崖式下跌。彩票假说的实验里用的就是迭代幅值剪枝(Iterative Magnitude Pruning, IMP),在高稀疏度下效果远好于一次性剪枝。
七、2:4 结构化稀疏:NVIDIA 的硬件友好方案
非结构化剪枝的硬件困境促使了一种折中方案的出现:N:M 稀疏(N:M sparsity),特别是 2:4 稀疏。
NVIDIA 在 Ampere 架构(A100)中专门引入了对 2:4 稀疏的硬件加速支持。2:4 稀疏的规则是:在每连续 4 个权重里,最多保留 2 个非零值(另外 2 个必须为零)。这不是完全的结构化剪枝(没有删整行或整列),但也不是完全随机的非结构化剪枝——它有一个局部的规律性,硬件可以针对这个规律设计专门的 sparse tensor core。
2:4 稀疏的好处是:理论上能达到 2x 的矩阵乘法加速,同时因为仍然有一定的权重选择灵活性,精度损失比完全结构化剪枝小。Wanda 等方法也支持 2:4 稀疏模式的生成。
八、LLM 时代的剪枝:为什么旧方法不够用
当模型规模从 BERT 的 1 亿参数膨胀到 LLaMA 的 700 亿甚至更大,传统剪枝方法遇到了一个严峻的新挑战:没法微调。
传统剪枝的三段式流程(训练 → 剪枝 → 微调)在小模型上可行,是因为微调的成本可以接受。但对一个 700 亿参数的模型,哪怕是在少量数据上做几个 epoch 的微调,也需要数十甚至数百张高端 GPU,对绝大多数团队和个人来说是完全不现实的。
更糟糕的是,Frantar 和 Alistarh 在 SparseGPT 的工作里发现,对 LLM 直接做朴素的幅值剪枝效果很差——把 LLaMA-7B 剪到 50% 稀疏度,幅值剪枝会让困惑度(perplexity)从 6.3 暴涨到 17.3,几乎不可用。这和小模型上幅值剪枝可以轻松剪掉 90% 而精度基本不损失的经验完全相反。
为什么 LLM 对幅值剪枝这么脆弱?
原因之一来自一个有趣的现象:LLM 的激活值里会出现大量级特征(large magnitude features)。在某些特定维度(channel)上,激活值会比其他维度大出 10 到 100 倍。LLM 严重依赖这些大幅值特征来做预测,而大幅值特征对应的权重往往也比较大——所以纯粹基于权重幅值排序,可能会保留一些权重值不小但对应的激活值微小的权重,同时删掉一些权重值适中但连接到大激活特征的关键权重。这种判断失误在小模型上后果有限,但在 LLM 里会造成精度急剧下滑。
九、SparseGPT:用二阶信息做训练后剪枝
SparseGPT(Frantar 和 Alistarh, 2023)是第一个实现了对十亿级 LLM 做高质量剪枝的方法,它把 OBS 系列的二阶思路带回了现代大模型。
核心思路:不只是把不重要的权重置零,在置零之后还对剩余权重做补偿更新,让剩余权重调整来弥补被删权重留下的"坑"。(可参考我的模型量化相关文章有所介绍)
形式上,对于一层权重矩阵 W 和对应的输入 X,SparseGPT 把剪枝问题建模为一个最小化重建误差的优化问题:
即找到一个满足稀疏约束的 ,使得它的输出和原来的
的输出尽可能相同。这个问题的求解利用了 Hessian 矩阵(
)的近似逆矩阵来进行高效的逐列求解。
SparseGPT 的结果令人印象深刻:LLaMA-7B 在 50% 非结构化稀疏度下困惑度只从 6.3 升至约 6.9,保住了绝大多数性能——而幅值剪枝在同等稀疏度下会到 17.3。对 OPT-175B 和 BLOOM-176B 这样的更大模型,SparseGPT 可以在单台服务器上不到 4.5 小时完成剪枝。
不过 SparseGPT 也有代价:需要计算 Hessian 近似,有一定的内存和计算开销。
十、Wanda:更简单、同样有效
Wanda(Sun et al. 2023,arxiv:2306.11695)在 SparseGPT 之后提出了一个更轻量级的方案,切入点正是那个"大量级激活特征"的现象。
核心思路:权重的重要性分数 = 权重幅值 × 对应输入激活值的 L2 范数。
其中 是第
个输入神经元的激活值(在一批校准数据上统计的)。
这个分数同时考虑了两件事:一是权重本身够不够大,二是这个权重对应的输入通道是不是那种大量级特征。只有两个条件都满足才值得保留——一个权重本身很大,但它接收的输入通道激活值很小,贡献也不大;反之一个权重值适中,但它连接的是大激活特征通道,那它其实很重要。
Wanda 的 PyTorch 实现极为简洁:
def prune_wanda(W, X, sparsity_ratio):
# W: 权重矩阵 (C_out, C_in)
# X: 校准数据的输入激活 (N*L, C_in)
# 计算每个输入神经元的激活 L2 范数
input_norms = X.norm(p=2, dim=0) # (C_in,)
# 重要性分数 = 权重幅值 × 对应输入范数
score = W.abs() * input_norms.unsqueeze(0) # (C_out, C_in)
# 每行独立排序(per-output basis)
_, sorted_idx = torch.sort(score, dim=1)
# 把分数最低的 sparsity_ratio 比例的权重置零
pruned_idx = sorted_idx[:, :int(W.shape[1] * sparsity_ratio)]
W.scatter_(dim=1, index=pruned_idx, src=torch.zeros_like(W))
return W
Wanda 有几个值得注意的特点:
无需权重更新:剪完直接用,不需要像 SparseGPT 那样对剩余权重做补偿更新。论文里给出了一个有趣的解释——他们的实验发现,当用 Wanda 的度量找到最优稀疏子网络时,额外的权重更新并不能显著改善结果,这暗示 LLM 本身就存在"精确的稀疏子网络",Wanda 能直接找到它。
Per-output 粒度:每行独立地找最不重要的权重来剪,而不是全局排序。这避免了某些输出神经元被过度剪枝而另一些几乎不被剪枝的不平衡情况。
效果对比:LLaMA-7B,50% 非结构化稀疏,Wanda 的困惑度是 7.26,而纯幅值剪枝是 17.29,SparseGPT 是约 6.9。Wanda 在几乎不引入额外计算开销的情况下,效果接近 SparseGPT,远好于幅值剪枝。
Wanda 还支持 2:4 N:M 结构化稀疏模式,只需要修改排序的方式:在每 4 个连续权重里找分数最低的 2 个剪掉,就能生成 NVIDIA 硬件友好的稀疏格式。
十一、剪枝与其他压缩技术的关系
剪枝不是孤立的,在实际工程里通常和其他压缩手段组合使用。
剪枝 + 量化(Quantization):剪枝减少权重数量,量化降低每个权重的精度(比如从 FP32 → INT8)。两者正交,可以叠加。Han et al. 2016 的 Deep Compression 工作就是把剪枝、量化、Huffman 编码三管齐下,实现了对 AlexNet 约 40× 的压缩。SparseGPT 的后续工作也探索了在稀疏化的同时对剩余权重做量化。
剪枝 + 知识蒸馏(Knowledge Distillation):用大模型作为教师,在剪枝后的小模型微调阶段用教师模型的 soft logits 作为训练信号,能比直接用 hard label 微调恢复更多精度。这在 BERT 压缩系列工作里被广泛使用。
剪枝 vs 低秩分解(Low-Rank Factorization):低秩分解把权重矩阵分解为两个更小矩阵的乘积,LoRA 是其在微调里的应用。两种方法都在减少"有效参数量",但思路不同:剪枝是稀疏化(保留部分权重置零其余),低秩分解是压缩(用更少的信息来近似整个矩阵)。
十二、细节讨论
高稀疏度下大稀疏模型 vs 小稠密模型,谁更好?
Wanda 的论文里有一组有趣的对比:50% 稀疏的 LLaMA-65B,在零样本精度上优于同参数量的稠密 LLaMA-30B。这个结论并不是放之四海皆准——对于结构化稀疏,结论相反(无微调情况下小稠密模型更好)。这暗示非结构化稀疏在大模型上存在"规模红利":大模型本身携带的信息更丰富,稀疏化只是丢掉了冗余,保留了密度更高的信息核心。
为什么不同层的稀疏度应该不同?
全局剪枝(给所有层统一设置相同稀疏度)是一个粗放的策略。实际上,不同层对最终性能的敏感度差异非常大。通常第一层和最后一层比中间层更敏感;注意力层中的某些权重矩阵(如 Query、Key)比 Value 更敏感;FFN 层通常比注意力层更能承受高稀疏度。让不同层用不同的稀疏度,是进一步提升剪枝效果的重要方向。
彩票假说的真正含义是什么?
彩票假说意味着大网络里存在"天然的"小子网络,这个子网络用原始初始化权重训练就能达到大网络的精度。这个假说如果成立,意味着我们不需要先训练大网络、再剪枝——理论上应该可以找到那张"中奖票"直接从头训练。但实践中,找到"中奖票"本身就依赖大网络的训练结果(否则你怎么知道哪些权重是重要的),所以绕不过去。它更多的意义是从理论上解释了为什么神经网络可以被高度稀疏化而精度不降。
最后
模型剪枝从 1990 年代 OBD/OBS 的理论探索,到 2015 年 Song Han 的幅值剪枝实验,到 2019 年彩票假说的理论洞见,再到 2023 年 SparseGPT 和 Wanda 为 LLM 量身定制的训练后方案,走了将近三十年。每一代的进步都在解决上一代的局限:从只能剪小模型到能剪百亿参数的 LLM,从需要微调到训练后一步到位,从忽略硬件到与 NVIDIA 稀疏加速硬件协同设计。
学剪枝,最值得记住的几个核心认知:非结构化剪枝灵活但硬件不友好,结构化剪枝硬件友好但精度有代价;幅值在小模型上够用,但 LLM 需要考虑激活值;迭代剪枝好于一次性剪枝;剪完通常需要微调,除非你用了 SparseGPT/Wanda 这类专门为免微调设计的方法。
参考资料:
- Learning both Weights and Connections for Efficient Neural Networks,Han et al., NeurIPS 2015
- Deep Compression,Han et al., ICLR 2016
- The Lottery Ticket Hypothesis,Frankle & Carlin, ICLR 2019
- SparseGPT: Massive Language Models Can be Accurately Pruned in One Shot,Frantar & Alistarh, ICML 2023
- A Simple and Effective Pruning Approach for Large Language Models (Wanda),Sun et al., ICLR 2024
- PyTorch Pruning Tutorial: https://pytorch.org/tutorials/intermediate/pruning_tutorial.html

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 11
11 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)