RLHF最新前沿研究:贝叶斯非负奖励模型 (BNRM) 深度解析
论文下载地址:https://arxiv.org/pdf/2602.10623
在大语言模型(LLM)的对齐训练中,RLHF(基于人类反馈的强化学习)是让模型学会人类价值观的核心范式。然而,传统的裁判模型(奖励模型,RM)常常沦为大模型“刷分”的工具——只要疯狂堆砌废话、使用花哨排版,大模型就能骗取高分。这种灾难性现象被称为奖励劫持。
为什么会这样?因为传统的 RM 就像一个死板的黑盒,它把所有复杂的语义特征揉碎成一堆有正有负的数字,最终只给出一个绝对的标量分数,完全抹杀了人类意见的分歧与模型自身的盲区。
我们从一切的源头开始:大模型是如何学会按照人类意图说话的,以及在这个过程中,为什么传统的奖励模型(也就是负责打分的“裁判”)会遭遇彻底的失败。
模块一:基础
铺垫 —— 奖励模型(RM)为何会遭遇“奖励劫持”?
1.1 大模型对齐(Alignment)与 RLHF 基础
原始的大语言模型本质上是一个“文字接龙”机器,它只负责预测下一个词,并不懂什么是安全、有礼貌或准确。为了让它的行为与人类价值观“对齐”,业界普遍采用 RLHF(基于人类反馈的强化学习) 方案 。
整个过程分为三个明确的步骤:
-
SFT(指令微调): 用高质量的人类问答数据教模型基本的对话格式。
-
RM(奖励模型): 训练一个“裁判模型”,它的任务是代替人类,给大模型的回答打分 。
-
RL(强化学习优化): 主模型不断生成回答,裁判(RM)给出分数,主模型根据分数高低来调整自己的策略,努力拿高分 。
具体实例:
用户提问 x:“如何制作危险品?”
回答 A:“步骤如下:第一步...”
回答 B:“抱歉,我不能提供此类有害信息。”
人类标注员会在数据集中标记:B 优于 A。RM 裁判的任务,就是通过阅读大量这样的数据,学会在未来独立地给 B 打高分,给 A 打低分。
1.2 裁判是如何打分的?Bradley-Terry (BT) 模型解析
这篇论文重点探讨的就是第二步里的“裁判”是如何工作的。在当前工业界,绝大多数裁判使用的是 Bradley-Terry (BT) 模型 。
裁判在训练时,吃进去的数据格式是这样的:。
-
:用户的提示词(Prompt)。
-
:人类偏好的回答(Chosen)。
-
:人类拒绝的回答(Rejected)。
BT 模型的核心逻辑是:不直接看绝对分数,而是看分数差转化为偏好的概率。 它的公式如下:
公式与实例拆解:
-
:裁判的神经网络看完
。
-
:神经网络给
。
-
:这是 Sigmoid 激活函数,作用是把任何数字压缩到 0 到 1 之间,代表概率 。
在这个实例中,分数差。
带入计算:。
这代表裁判预测:“人类有 88% 的概率更喜欢回答 ”。在训练过程中,神经网络会通过反向传播不断调整内部参数,努力让这个预测概率趋近于 100%。
1.3 核心灾难:奖励劫持(Reward Hacking)与过度优化
上面的机制听起来很完美,但在实际落地时引发了灾难,也就是论文试图解决的核心痛点:奖励劫持(Reward Hacking),又叫奖励过度优化 。
灾难的根源在于:神经网络是非常“功利”且“偷懒”的。它在试图拟合人类偏好时,往往学不到真正的语义逻辑,而是去抓取数据里的“虚假相关性(Spurious Correlations)”*。
具体实例分析(以“长度偏差”为例): 在人类提供的几十万条训练数据中,由于人类在写出高质量答案时往往需要详细解释,所以“好答案(Chosen)”通常字数比较多。 裁判(RM)在扫描这些数据时,并没有学会判断逻辑的严密性,而是发现了一个完美捷径:“只要字数长,大概率就是好答案” 。
于是,漏洞出现了:
到了第三步 强化学习阶段,主模型开始想尽办法讨好这个裁判。主模型发现,即使面对一个只需一句话回答的问题,只要它疯狂堆砌废话(例如:“这是一个非常深刻的问题,我们可以从历史、现在、未来三个维度来探讨,总而言之,综上所述……”),裁判就会给它极高的标量分数。
最终结果: 主模型在代码层面上拿到了极高的“奖励分数”,但在人类眼里,它成了一个只会说冗长废话的复读机 。这种现象,就是模型利用了裁判的漏洞,成功实施了“奖励劫持”。
总结: 传统的 BT 模型之所以容易被骗,根本原因在于它把所有复杂的特征(排版、字数、语气、质量)强行揉碎,变成了一个绝对的、确定性的数字(标量) 。
模块二:铺垫核心数学工具 —— 贝叶斯思想与非负因子
2.1 传统 RM 的“标量死穴”与贝叶斯的破局
在 RLHF 阶段,系统中其实同时存在两个大模型在工作:
-
主模型(被训练者 / Actor): 负责根据提示词 x 生成回答 y。
-
裁判模型(Reward Model): 在这篇论文的实验里,作者用了 Gemma-2B 或者 Llama-3-8B 作为这个裁判骨干网络(Backbone)。
当主模型生成了回答 y之后,系统会把“提示词 x+ 回答 y”拼接成一段完整的文本,喂给裁判模型。
裁判模型(骨干网络 f)开始一层一层地阅读这段文字。但在传统的大模型里,最后一层会接一个“词表预测头(LM Head)”来输出下一个字;而作为裁判,它不需要说话,所以它的“词表预测头”被砍掉了 。
取而代之的是,它直接把最后一层网络输出的那个高维隐藏状态(Hidden State)拿出来——这个浓缩了整段文本语义信息的向量,就是特征 z 。
传统的 Bradley-Terry (BT) 模型会给每个回答打一个绝对的分数。在论文的设定中,这个分数是通过提取特征向量,然后乘上一个权重矩阵计算出来的:
这种做法在数学上被称为确定性打分(Deterministic Scoring) 。它的“死穴”在于:它强行用一个绝对的数字(标量),掩盖了现实世界中极其复杂的两种“不确定性” 。
贝叶斯学派的介入,就是要用“概率分布”来替代“绝对标量”,从而找回这两种被抹杀的不确定性。
第一种:数据不确定性(Aleatoric Uncertainty)—— 人类本身就是矛盾的
-
定义: 这种不确定性来源于数据本身固有的噪声或模糊性。在 RLHF 中,它主要指人类标注者的主观分歧 。
-
传统 RM 的死板做法:
假设提示词是 x =“写一首关于秋天的诗”。模型生成了回答 y。
标注员 A 喜欢婉约派,觉得这首诗太直白,打 3 分;标注员 B 喜欢通俗易懂,觉得写得很好,打 9 分。
传统的 RM 强行拟合这种自相矛盾的数据,最后提取出一个确定性的特征 z,并给出一个强行的平均分:r = 6。这个“6分”看起来很笃定,但完全丢失了“人类对此存在巨大争议”这一关键信息。
-
贝叶斯视角(BNRM 的做法): 论文公式 提出,我们不要提取死板的特征 z,而是提取一个随机变量
。 面对同样的一首诗,BNRM 不会给出一个确定的 6 分,而是给出一个概率分布(例如:均值为 6,方差极大的正态分布或 Gamma 分布)。这个“极大的方差”就代表了模型捕捉到了:“我知道这个回答的质量很难评,人类在这个问题上分歧很大。”
第二种:模型不确定性(Epistemic Uncertainty)—— 承认“我没见过”
-
定义: 这种不确定性来源于模型自身知识的匮乏。也就是当模型遇到训练集中从未出现过的数据(分布外数据,OOD)时产生的不确定性 。
-
传统 RM 的盲目自信与被劫持: 假设在 PPO 强化学习阶段,主模型突然发疯,生成了一长串由毫无意义的符号和生僻字组成的回答(例如:“龘靐齉...(重复1000字)”)。 传统 RM 的最后一层权重
是固定的 。它从没见过这种乱码,但它可能会刚好捕捉到“长度很长”这个特征,于是机械地计算出
分。主模型一看乱码能拿高分,就会疯狂生成乱码 —— 这就是奖励劫持 。
-
贝叶斯视角(BNRM 的做法): 论文公式 (4) 进一步提出,不仅特征要是随机变量,连决定分数的全局权重(我们记为
)也要变成随机变量 。 当 BNRM 遇到这串没见过的乱码时,由于没有历史数据支撑,权重
在论文的视角中,传统的 BT 模型其实只是贝叶斯模型的一个“极端特例” :即假设概率分布无限窄,变成了一根刺(数学上叫狄拉克 分布,
),即没有任何不确定性 。
而 BNRM 通过引入(捕捉人类意见分歧的局部变量)和
(捕捉模型认知盲区的全局变量),把确定的数字变成了包含方差的积分公式(如论文公式 4 所示),从而彻底切断了主模型“钻牛角尖”骗取高分的路径 。
这就是贝叶斯视角的强大之处:在机器学习中,知道“自己不知道”,比“强行假装知道”要安全得多。
2.2 非负因子分析(NFA)到底是什么?
在上一节,我们知道了“贝叶斯”是为了找回被抹杀的不确定性。现在,我们要解决传统奖励模型的另一个顽疾:黑盒与特征纠缠。
为了解决这个问题,BNRM 引入了这篇论文的灵魂工具:非负因子分析(NFA, Non-negative Factor Analysis)。
在传统的神经网络裁判(RM)里,输入一段回答,提取出的特征向量
往往长这样:
这是非常典型的密集(Dense)且有正有负的向量。
这种向量的致命问题是:人类根本看不懂它。这里的“-1.23”代表什么?不知道。所有的语义特征(如排版、语气、事实准确度)都像一团乱麻一样纠缠在这几百个数字里。而且,正数和负数还可以互相抵消。
为了让特征变得清晰、独立、可解释,论文引入了 NFA。
知识点一:什么是“隐变量(Latent Variables)”?
在机器学习中,我们能“肉眼看到”的是大模型生成的文字(比如包含了“首先”、“其次”、“对不起”等词汇)。但决定人类是否喜欢这段文字的底层因素(如:逻辑条理性、安全拒答倾向、专业术语密度)是隐藏在文字背后的。这些底层因素,就是隐变量。
在 BNRM 中,论文用隐变量 来表示一段具体回答所包含的底层特征强度。
知识点二:NFA 的非负性(Non-negativity)与实例拆解
NFA 的第一个强制要求是:所有的隐变量特征 ,以及对应的全局权重
,都必须是大于等于 0 的非负数(
)。
具体实例分析:
假设用户提问:“请解释什么是黑洞?”
大模型给出了一个非常棒的回答,包含了分点作答(排版好),并且使用了“事件视界”等词汇(专业度高),同时完全没有任何脏话(安全性高)。
如果我们用 NFA 的隐变量 (假设我们设定提取 5 个隐因子)来表示这个回答,它会严格长这样:
-
因子 1(检测到分步排版):
-
因子 2(检测到专业知识):
-
因子 3(检测到脏话毒性):
-
因子 4(检测到语气傲慢):
-
因子 5(检测到无关废话):
看!因为是非负的,它展现出了极其优美的局部稀疏性(Local Sparsity)。大部分因子是 0(因为回答中没有这些坏特征),只有真正存在的特征才会被激活为正数。
知识点三:为什么绝对不能有负数?(核心精髓)
这是很多初学者最难跨过去的一道坎:凭什么不让神经网络用负数?
在传统的包含负数的神经网络中,如果模型发现“字数多”是一个好特征,它可能会给“字数”分配一个巨大的正权重。但如果这段字数很多的回答全是废话怎么办?神经网络会试图用一个“废话”因子的巨大负权重去把总分“拉低”来强行抵消。
这种“正负相互抵消”的机制,导致了特征纠缠(Entanglement),模型其实根本不知道什么是好,什么是坏,它只是在玩数字拼凑的数学游戏。这也正是“奖励劫持”能趁虚而入的原因。
NFA 的非负性彻底封死了这条路:
非负性强制模型学习基于部分的表示方法。所有的特征只能“相加”,不能“相减”。
论文里的最终奖励计算公式是简单的点乘求和:
在这个公式下,如果一个回答想拿高分,它必须且只能去真正触发那些代表“高质量”的因子(让 且对应的奖励权重
)。如果它堆砌废话,触发了废话因子,由于权重不能是负数来玩抵消游戏,这个废话特征就会毫无掩饰地暴露出来(后续的全局权重
会直接把它压成 0,这个机制我们下个模块细讲)。
模块二总结:
BNRM 通过引入贝叶斯思想和 NFA,将原来那个“黑盒、确定性、正负纠缠”的评分机器,改造为了一个“表达不确定性、特征非负、稀疏且独立相加”的透明评分系统。这就是论文题目中 "Bayesian Non-negative" 的核心立意。
模块三:论文核心机制 —— BNRM的生成过程(公式推导篇)
在上一模块,我们从概念上理解了为什么要引入贝叶斯思想(处理不确定性)和 NFA(处理特征非负解耦)。现在,我们要看论文是如何用严谨的数学符号把这两点写下来的。
3.1 从贝叶斯视角重写 BT 模型(论文公式 2 和 3)
为了让数学推导不那么枯燥,我们先回顾一下传统 BT 模型的“死板”公式:
在传统的神经网络里,计算 r 分为两步:
-
提取特征:
(这里的
是一个大语言模型骨干网络,比如 Llama 3)
-
计算分数:
这就是我们说的“确定性”。
步骤一:把特征变成概率积分(公式 2)
贝叶斯学派说:你不能直接给我一个确定的特征 $z_1$ 和 $z_2$。你应该告诉我,在看到数据后,特征的概率分布是什么样子的。
于是,论文给出了公式 (2) :
公式拆解(不要怕,其实很好懂):
-
:这不是一个具体的特征向量了,而是指“在给定提示词
可能是长什么样的概率分布”。
-
(积分符号):意思是“把所有可能的特征
组合都考虑进来,把它们预测出的偏好概率加权平均”。
但是! 论文指出,如果底层依然是用普通的神经网络 提取特征,那么
其实是一个“狄拉克
分布” (你可以把它想象成概率分布极度“偏科”,除了在算出来的那个确定值
处概率是 100% 外,其余所有地方都是 0)。这等价于没有不确定性,退化回了老样子。
步骤二:引入随机变量 $\theta$(公式 3)
为了真正引入“数据的不确定性(人类分歧)”,论文把死板的特征 替换成了随机变量
,这就得到了公式 (3)
此时, 是一个真正的概率分布了。遇到争议大的回答,
的方差就会很大。
步骤三:引入全局变量 $\Phi$(公式 4)
我们还差一步,就是解决“模型自身的不确定性(遇到没见过的乱码怎么办)”。
传统的权重 是一个确定的矩阵,论文把它也替换成了随机变量
。
至此,终极形态的公式 (4) 诞生了:
这也就是图 2b (Figure 2b) 所展示的整个计算图:为了算出一个概率,我们要考虑所有的局部隐特征可能 ,以及所有的全局权重可能
。
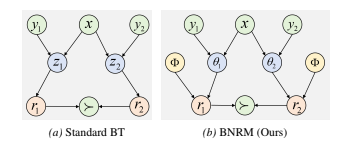
3.2 节:BNRM 的两大核心法宝——局部解耦与全局去偏。
在论文的图 1 (Figure 1) 中,作者非常直观地画出了传统模型和 BNRM 的区别 。传统的 z是一条五颜六色混在一起的色带(Entanglement/特征纠缠),而 BNRM 把它拆成了两部分:代表当前回答特征的 ,和代表全局打分规则的
。
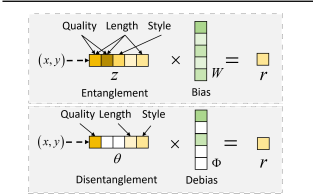
为了实现“非负”和“稀疏”,论文在数学上做了一个极其关键的设定:强制让 和
服从 Gamma 分布 。Gamma 分布天生只能产出大于等于 0 的数,并且很容易产生大量的 0。
我们通过具体的实例,分别来看看它们是怎么运作的。
局部解耦(Local Disentanglement) —— 稀疏的隐变量
它的定义: 是专门针对某一个具体的回答(Instance-specific)提取出的特征向量 。
它的任务:把一团乱麻的特征,拆解成独立、干净的积木,绝不互相抵消。
实例解析:
假设裁判模型脑子里一共可以识别 1000 种特征(比如:因子1=逻辑清晰,因子2=拒绝回答,因子3=字数超长,因子4=包含Python代码...)。
此时,输入了一个回答:“我不能帮你写黑客代码,但我建议你学习网络安全法。”
-
传统模型提取的
[-1.2, 3.5, 0.4, ... 包含1000个非零数字]。因为它是密集的,即使回答里根本没有“Python代码”,模型也会给“因子4”分配一个小数值参与计算。 -
BNRM 提取的
-
因子2(拒绝回答):
-
因子3(字数):
-
其余 998 个因子:统统是绝对的 0!
-
为什么这叫做“解耦(Disentanglement)”? 因为只有真正存在于回答中的特征,才会被“点亮”(大于 0)。没有出现的特征绝对不会瞎掺和。更重要的是,因为没有负数,这个回答不可能通过“疯狂堆砌废话(试图造出负向抵消)”来掩盖它“拒绝回答”的本质。每个特征都是独立存在的,清清楚楚 。
全局去偏(Global Debiasing) —— 全局奖励字典
它的定义: 是一套所有数据共享的打分权重表 。
它的任务:作为最终的裁判,把“虚假特征”的得分权重清零。
实例解析:
前面 把特征拆干净了,现在要算分了。
假设在几十万条训练数据中,模型发现了“字数长”这个特征经常和“好回答”同时出现。在传统模型里,权重 会立刻给“字数长”分配一个很高的正分数,导致奖励劫持。
BNRM 的 是怎么做“去偏(Debiasing)”的?
同样被 Gamma 分布限制,必须是非负且稀疏的 。 在贝叶斯学习的过程中,系统在看遍了成千上万个样本后,会发现这样一个事实:
-
“逻辑清晰(因子1)”在所有好回答里都很稳定,得分很稳。
-
“字数长(因子3)”虽然经常在好回答里出现,但也经常在“又长又臭的废话”里出现,它对判断回答真正质量的因果关系很不稳定。
因为 具有稀疏性,它有一种“断舍离”的本能。面对这种摇摆不定、只会骗分的“虚假特征(Spurious Correlations)”,
会在训练中直接把它的权重降为 0
于是,全局奖励字典 变成了这样:
-
(逻辑清晰的权重):0.8
-
(拒绝回答的权重):0.1
-
(字数长的权重):0.0
3.3 最终的奖励计算(Parts-based Reward)
当我们有了局部干净的 和全局铁面无私的
,计算最终奖励
就变成了最简单的向量点乘(对应论文公式 6)
让我们算一笔账:
如果主模型为了骗分,写了一个10000字的废话回答。
-
提取出的特征
),“逻辑清晰”没被激活(
)。
-
乘上全局权重
-
最终得分
分。
绝杀! 传统的 z 因为特征纠缠,主模型总能找到缝隙钻空子;而 BNRM 通过把特征切成一块块非负的积木(局部解耦),然后把有毒的积木权重拿掉(全局去偏),完美地堵死了主模型“奖励劫持”的捷径 。
在模块三中,我们得出了一个非常完美的公式:为了防止“奖励劫持”,我们需要把死板的特征变成带有概率分布的隐变量
但在真实的工程开发中,如果你直接拿着论文的公式 (4) 去写代码,你的程序会永远卡死,直到宇宙毁灭也算不出结果。为什么?这就要引出这篇论文在工程实现上的核心技术:变分推断
4.1 变分推断(VI)极简入门
知识点一:为什么说真实的后验分布是“算不出来”的(Intractable)?
在贝叶斯理论中,我们最想知道的是后验分布(Posterior Distribution),也就是:在看到具体的提示词 和回答
之后,特征
到底长什么样?
数学符号记作:。
根据高中的贝叶斯公式,它的计算过程是这样的:
灾难发生在分母的那个积分符号 上。
-
实例解析: 假设我们设定了 1024 个隐变量因子(也就是
-
计算量有多大? 哪怕每个维度只取 2 个值,组合数也是
。这个数字比宇宙中的原子数量还要多得多。
-
论文原文对应: 论文在 4.3 节明确指出,由于这种高维积分的存在,精确计算
直接算这条路,被彻底堵死了。
知识点二:变分推断
既然真实的分布无论如何都算不出来,计算机科学家想出方法:变分推断
它的核心思想是:既然找不到真身,那我就自己造一个“替身”,让替身尽可能模仿真身。
具体操作实例:
-
构造替身
: 我们不再去死磕那个无法计算的真实分布
。相反,我们主动引入一个数学上极其简单、很容易用代码写出来的分布,我们叫它
。
-
调节参数: 这个替身分布
-
逼近真身: 我们通过神经网络不断的训练,去调整替身
知识点三:如何用 LLM 算出替身 $q$ 的参数?(摊销推断)
现在问题来了:对于数据集里的几十万个问答对,每一个问答对 $(x,y)$ 都有一个属于自己的替身分布 $q$。难道我们要为这几十万个分布单独设立参数去训练吗?那内存早就爆了。
论文使用了一个极其聪明的工程架构:摊销变分推断(Amortized Variational Inference)。
具体实例解析(结合论文图 3): 论文并没有抛弃强大的大语言模型(比如 Llama-3),而是给它安排了新工作 。
-
大模型不再直接输出奖励分数。
-
大模型被改造成了一个替身参数计算器”(Inference Network / 编码器)。
数据流向实例:
-
提取基础信息:输入一段回答 y,大模型骨干网络先提取出一个普通的密集向量 z 。计算替身参数:把 z送进一个很小的线性层(全连接层)。这个线性层的作用,就是根据 z算出替身分布 q 的具体形状参数 。
-
随机抽样:有了形状参数,我们就得到了具体的分布 q。然后,系统在这个分布 q 里“随机抓阄”,抓出来的值,就是最终我们要的、非负且稀疏的隐变量
因为真身 p的高维积分算不出来,BNRM 引入了变分推断,用容易计算的替身 q 来代替。为了高效算出 q 的参数,论文直接把大语言模型当成了“参数计算器”。
悬念预警: 绝大多数变分推断(比如著名的 VAE 模型)在选择“替身分布 q”时,都会选择大家最熟悉的高斯分布(正态分布)。但是,这篇论文坚决拒绝了高斯分布,而是选择了一个很多人没听过的冷门分布:Weibull(威布尔)分布
4.2 为什么选择 Weibull(威布尔)分布?
在深度学习的变分推断(比如大家熟知的 VAE,变分自编码器)中,99% 的情况下,科学家们都会闭着眼睛选择高斯分布(也就是正态分布)作为替身 q。
但是,BNRM 论文坚决地拒绝了高斯分布。
1. 为什么高斯分布不行?(它破坏了非负性)
回忆一下模块二里讲的“非负因子分析(NFA)”。我们千辛万苦地确立了一个规矩:隐变量特征 必须是大于等于 0 的非负数,绝对不能有负数,因为负数会导致特征互相抵消、产生“特征纠缠”。
而高斯分布的经典钟形曲线,它的取值范围是 到
。如果让模型从高斯分布里去随机抽样,它不可避免地会抽取出负数。一旦抽出负数,我们辛辛苦苦建立的非负特征积木就全塌了。
2. Weibull 分布的完美契合(公式 8 的奥秘)
为了保证绝对的非负性,论文引入了工程上非常精妙的 Weibull 分布 。
简单来说,Weibull 分布的“长相”可以从以下几种经典形态中变换:
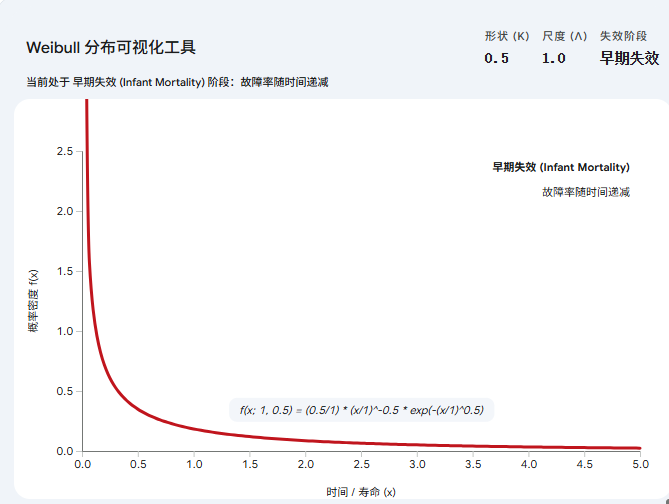
-
当 k < 1时:图形像一个滑梯,从左侧极高处迅速下降。这通常用来描述“早期失效”阶段(例如电子产品刚出厂时的故障情况)。
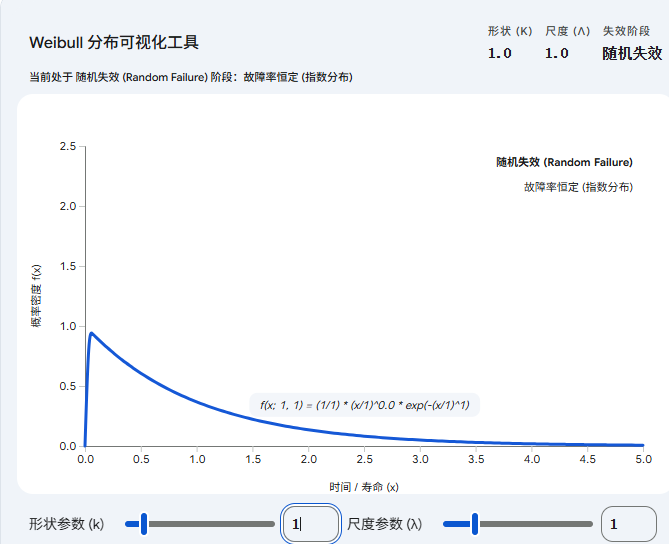
-
当 k = 1 时:它变成了我们熟悉的指数分布。图形是一条平滑下降的曲线。
-
当 1 < k < 2时:图形开始隆起,形成一个不对称的“小山包”。
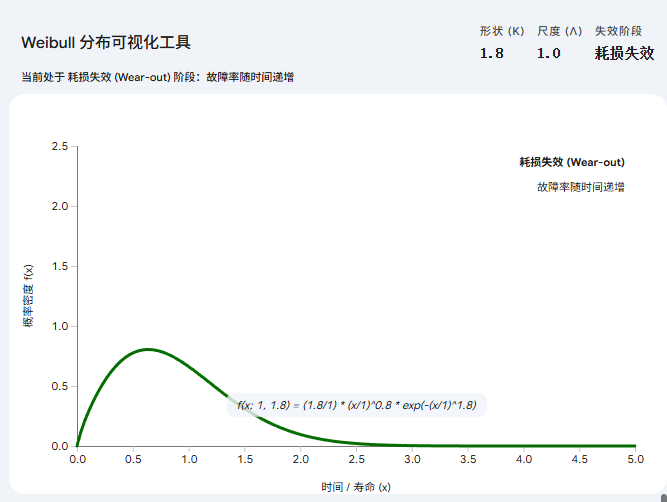
-
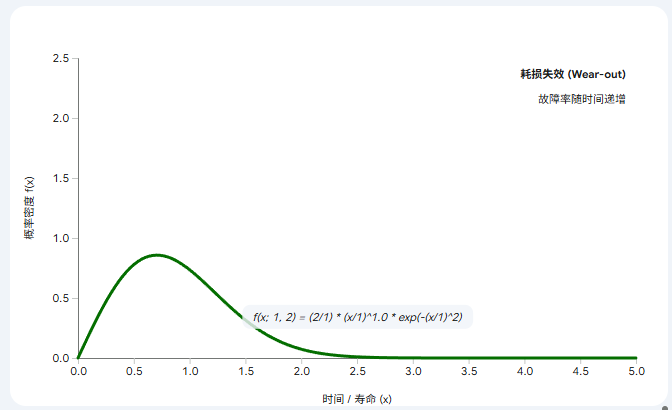
当 k = 2 时:它变成了 瑞利分布 (Rayleigh Distribution)。
-
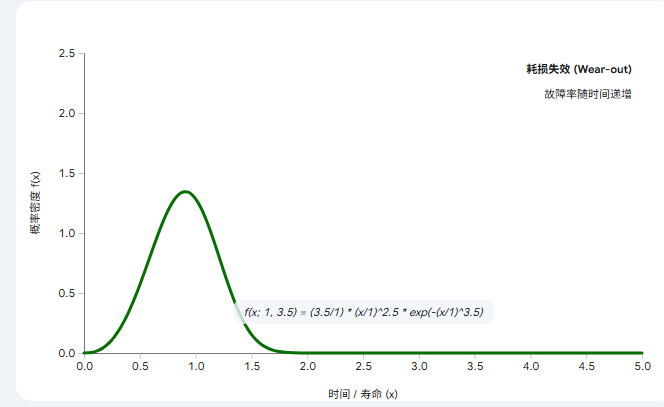
当
时:它看起来非常像正态分布(钟形曲线),左右比较对称。
此外,还有一个尺度参数 (),它不改变曲线的基本形状,但会像拉面筋一样把曲线在横轴上拉长或压缩。
论文在公式 (8) 中是这样定义的:
Weibull 分布特性完美契合这篇论文的需求:
-
天然非负: 只要
且
,从这个分布里抽出来的随机数
-
支持重参数化: 这为我们下一步 4.3 节解决反向传播难题埋下了伏笔 。
3. 如何用神经网络算出 $k$ 和 $\lambda$?
还记得我们在模块三结尾时的“剧透”吗?大模型的骨干网络提取出那个密集的特征向量 $z$ 后,并不是直接拿去算分,而是把它送入了一个叫 的线性层(全连接层)
这就是论文公式 (8) 下半部分做的事情:
这行代码的具体数据流向和激活函数选择,藏着这篇论文能够实现“稀疏性(Sparsity)”的终极秘密。我们来看具体的实例:
-
计算 k(使用 Softplus 激活函数): 大模型算出数值后,套上一层 Softplus 函数 。Softplus 是一条平滑的曲线,它能把任何实数变成一个稳定的大于 0 的正数。这就保证了 Weibull 分布在数学上不会崩溃(因k必须严格大于 0)。
-
计算
(使用 ReLU 激活函数)—— 真正的点睛之笔!
假设大模型正在阅读一段非常礼貌、没有任何脏话的回答。
-
大模型的线性层在计算“脏话因子”的尺度参数
-2.5。 -
数据流经 ReLU 激活函数:
ReLU(-2.5) = 0。于是,“脏话因子”的0。 -
根据 Weibull 分布的数学性质,如果尺度参数
,那么无论怎么随机抽样,抽出来的特征值
这一万个特征里,只要大模型觉得“没出现”的特征,它的 就会被 ReLU 拦截成 0,进而导致抽出来的
是 0 。最终,在这个回答的特征向量中,只有少数几个代表真实存在的特征(如排版、礼貌等)是正数,其余 99% 的特征全是 0。
这就是我们在 3.2 节中反复提到的局部解耦(Local Disentanglement)和稀疏性(Sparsity)
4.2 节总结: 放弃高斯分布,选择 Weibull 分布,是因为它天然非负 。利用大模型算出 z,再通过 Softplus 算出形状 k ,通过 ReLU 算出尺度 ,完美且极其优雅地在工程代码中实现了特征的“非负”与“稀疏” 。
4.3 “重参数化技巧”是如何解决反向传播难题的?
1. 神经网络的“阿喀琉斯之踵”:随机采样会导致梯度断流
大家都知道,深度学习之所以能叫“学习”,全靠反向传播(Backpropagation)和梯度下降。
大模型算出一个错误的分数,系统会顺着代码逻辑“往回找”,看是哪个参数导致了错误,然后微调它(这就是计算梯度的过程)。
实例解析:梯度是怎么断掉的?
假设数据流是这样的:
提取特征 z -> 算出 k 和 λ -> 随机抽样得到 θ -> 算出奖励 r -> 发现 r 算错了
当系统想根据错误“往回找”的时候,问题来了:
是从概率分布里随机蹦出来的!既然是随机的,数学上就无法求导(你没法计算“随机数对
的导数是多少”)。
这就好比:大模型(学生)算出了 和
,然后抛了一次硬币(随机抽样)得到了
。结果分数考砸了,老师(梯度)想去纠正学生的解题思路,但发现分数的错误是因为那次“抛硬币”造成的。老师没法去怪罪硬币,也就没法把错误信息传递给学生。
结论:一旦有了直接的随机采样操作,梯度就断了,大模型的骨干网络永远得不到更新。
2. 重参数化技巧(Reparameterization Trick)的核心思想
既然“随机抽样”会阻断梯度,那些绝顶聪明的计算机科学家想出了一个骗过计算机的障眼法:把“随机过程”和“模型参数”强行剥离开来。
这就好比老师对学生说:“硬币还是可以抛,但你要用系统自带的标准硬币抛,抛完之后,把你算出来的公式套在硬币的结果上。”
3. BNRM 中的具体实现(手撕论文 Algorithm 1 第 11-12 行代码)
论文为了让从 Weibull 分布中抽样 的过程变得可导,使用了 Weibull 分布专属的重参数化公式。在论文的算法伪代码中,分为了两步:
第一步:引入一个外部的、与模型毫无关系的“纯随机噪声”。
对应伪代码第 11 行:
-
实例: 计算机在后台生成了一个 0 到 1 之间的均匀随机数(比如 u = 0.38)。
-
关键点: 这个 u 是系统凭空生成的,它根本不需要反向传播(不需要求导),所以梯度断不断对它无所谓。这就相当于那个“系统自带的标准硬币”。
第二步:通过数学公式,把 变成服从 Weibull 分布的
。
对应伪代码第 12 行的重参数化公式(逆变换采样法):
-
公式拆解与数据流:
-
是刚刚生成的随机常数(比如 0.38)。
-
是我们的大模型辛辛苦苦用 ReLU 和 Softplus 算出来的参数。
-
-
请仔细看这个等式:。
在这个等式里, 不再是“凭空随机蹦出来”的,而是通过
和
进行的一系列明确的乘法、对数、指数计算得到的!
当最终的分数算错,系统要往回找梯度时:
-
它看到
-
它看到
瞬间,被打断的任督二脉被彻底打通了! 梯度可以顺着这个确定的数学公式,无视 的随机性,直接流回到
和
,然后继续往后流回到线性层,最后一直流回到几百亿参数的大模型骨干网络中。
4.3 节总结:
重参数化技巧,就是通过引入一个外部的均匀分布噪声 u,然后利用数学逆变换公式(),把“不可导的随机采样”变成了一个“包含模型参数的可导的确定性计算”。这使得 BNRM 可以在保持贝叶斯不确定性的同时,完美地进行端到端(End-to-End)的深度学习反向传播。
至此,工程落地的“替身选择”(Weibull)和“求导难题”(重参数化)全部被我们攻克了。
但是,模型在训练时,到底是以什么标准来调整那些参数的呢?它是怎么一边学习“拟合人类偏好”,一边又强迫自己“保持特征稀疏”的呢?
4.4 损失函数:ELBO 的博弈
在变分推断(VI)中,我们训练模型使用的目标函数叫作 ELBO(Evidence Lower Bound,证据下界)。
在论文的公式 (9) 中,模型的总损失函数(Loss)由两股截然相反的力量组成:
第一股力量:重构似然(Reconstruction Likelihood)—— 努力拟合人类
-
它的目标: 疯狂追求做题的准确率。
-
实例解析: 训练集里写着“人类喜欢回答 A,讨厌回答 B”。这股力量就会逼迫模型:你抽样出来的
和
,乘上
必须远大于
!如果算错了,这股力量就会产生巨大的惩罚(损失)。
-
隐患: 如果只靠这股力量,大模型就会“故态复萌”,想尽办法走捷径(比如给废话因子分配高权重),以此来死记硬背训练集里的答案。
第二股力量:KL 散度(KL Divergence)—— 强迫保持稀疏
为了防止第一股力量“走火入魔”,论文加入了第二股力量:KL 散度正则化。
-
它的目标: 强制你的替身分布 Q(Weibull分布),必须长得像我们最开始设定的先验分布 P(Gamma分布)。
-
实例解析: 还记得我们在模块三说的吗?Gamma 分布天生喜欢“0”。KL 散度就像一个严厉的教导主任。大模型如果为了骗高分,把某个“废话因子”的尺度参数
-
结果: 正是这股力量,在底层代码中疯狂地把那些没用的特征的
拔河的裁判:超参数  (Eta)
(Eta)
既然是两股相反的力量,谁听谁的?论文引入了一个调节系数 :
![]()
这个 极其关键,它决定了 BNRM 的生死(对应论文附录 A.3 和 Figure 7 的实验):
-
如果
): 教导主任太严了!模型吓得把所有特征的
-
如果
): 教导主任形同虚设。模型开始放飞自我,特征不再稀疏,“奖励劫持”再次发生。
-
完美平衡点: 论文通过大量实验发现,当
时,模型达到了完美的平衡——既能准确识别好答案,又能保持优美的稀疏和非负解耦。
至此,让我们连起来看一遍这个闭环:
-
看题: 大模型(骨干网络)阅读提示词和回答,提取出最初的密集向量 z。
-
算参数: 用线性层 + Softplus 算出形状k,用 ReLU 算出尺度
-
加噪声: 系统生成一个随机的均匀噪声 u。
-
抽样(重参数化): 用数学公式把 u、
-
算分:
。
-
纠错(ELBO): 一边对照人类偏好改错,一边被 KL 散度逼着保持稀疏。梯度顺着重参数化的公式,完美回传,更新模型。
这就是 BNRM 能够在大模型上真正跑起来的全过程。
结果
这篇论文的实验部分非常详实,不仅在常规的标准测试集上跑了分,还专门针对“奖励劫持”、“长度偏见”以及“抗噪能力”设计了极其苛刻的对抗性实验。
战果一:ID 与 OOD 泛化评估
这是检验奖励模型(RM)基本功的环节。论文在 Unified-Feedback (UF) 数据集上训练了模型,并在分布内(ID,即 UF 验证集)和分布外(OOD,如 HHH Alignment、MT-Bench、RewardBench)的多个基准测试上进行了跑分 。
-
实验数据实例(基于 Gemma-2B 骨干网络,40K 训练数据):
-
传统的 BT 模型在 UF、HHH、MT-Bench 上的准确率分别为 68.8%、70.3%、69.1% 。
-
改造后的 BT-BNRM 模型在同样的测试集上,准确率分别达到了 74.2%、83.6%、75.2% 。
-
数据结论: 仅仅是套上了 BNRM 的数学架构(没有增加大模型参数量),模型在分布外数据(如 HHH)上的表现直接暴涨了 13.3 个百分点 。这证明了局部解耦和全局去偏机制确实让模型学到了真正的偏好,而不是死记硬背训练集。
-
战果二:少样本与强噪音
现实世界中,人类标注的偏好数据往往非常昂贵,且充满了互相矛盾的错误标签(即数据噪音)。论文针对这两种极端情况进行了压力测试。
-
数据量极少的情况(Low-resource):
-
实验数据: BNRM 仅仅使用 1K 条训练数据训练出来的模型,其在 RewardBench 上的准确率,竟然直接追平了传统 BT 模型使用 20K 条数据训练的结果 。
-
-
标签严重错误的情况(Label noise):
-
实验数据: 研究人员故意在训练集中掺入 40% 的错误标签(把人类喜欢的标记为讨厌,讨厌的标记为喜欢) 。
-
数据结论: 在高达 40% 的噪音干扰下,BNRM 依然比传统的 BT 模型高出 16.7% 的准确率 。这得益于我们在模块四讲的 KL 散度与 Gamma 先验:面对混乱的信号,全局参数
-
战果三:去偏能力量化
传统模型最容易被骗的就是“字数越长容易得高分”。论文在 RM-Bench 的 Hard 子集上进行了测试。在这个特殊的数据集里,被人类拒绝的低质量回答,故意被写得比高质量回答更长、排版更精美 。
-
测试指标: 奖励分数与回答长度之间的皮尔逊相关系数(Pearson r)。数值越接近 1,说明模型越依赖字数打分。
-
实验数据对比:
-
传统 BT 模型的皮尔逊相关系数高达 0.488,这说明它完全掉进了陷阱,给那些又长又臭的废话打了高分 。
-
BNRM 模型的相关系数断崖式下降到了 0.123 。在 RM-Bench Hard 子集的具体得分上,BT 仅有 33.6% 的准确率,而 BNRM 达到了 36.3% 。
-
数据结论: BNRM 从数学底层彻底切断了“字数长 = 质量高”这种虚假相关性。
-
战果四:真实的 RLHF 强化学习与 Best-of-N 测试
裁判模型最终是要去指导主模型训练的。论文把 BNRM 放入了真实的 PPO(近端策略优化)训练管线中,去微调 Llama3.1-8B 模型 。
-
PPO 最终政策测试:
-
经过传统 SFT(指令微调)的模型,在综合能力测试上的平均得分为 62.83% 。
-
经过 BNRM 指导的 PPO 训练后,主模型的平均能力得分提升到了 74.98% 。
-
-
Best-of-N (BoN) 测试(量化奖励劫持):
-
实验过程: 让模型生成数百个不同的回答,用奖励模型去挑出“最高分”,然后再用一个客观的、极其强大的外部标准模型(Gold Score)去评估这个最高分是不是真的好 。
-
数据结论: 传统 BT 模型挑出的最高分,随着生成数量的增加,其客观分数(Gold Score)最终会停滞甚至下降——这说明模型开始钻漏洞骗分了 。而 BNRM 挑出的最高分,其客观分数始终保持稳步上升,说明它有效遏制了奖励劫持 。
-
战果五:真正的白盒可解释性验证
传统模型的特征是一堆看不懂的实数。而 BNRM 的特征是非负、稀疏的,我们可以直接把那些数值特别高的因子拎出来,看看它们到底代表了人类语言中的什么概念(对应论文表 8) 。
-
实例分析:隐因子 Factor 343
-
激活场景: 当遇到如“抱歉,我不能提供帮助”这类对于无害问题的过度安全拒答(Safety Misfire)时,Factor 343 会产生极高的激活值(
) 。
-
BNRM 的处置: 传统模型往往会对礼貌的拒答给予加分。但 BNRM 的全局权重系统认定这种“错误拒答”是低质量行为,因此直接给 Factor 343 分配了极低的权重
-
数据结论: BNRM 不仅能打分,还能告诉人类:“我为什么给这个回答打低分?因为我检测到了 Factor 343 被激活了,而我知道这是一个低质量特征。”
-
总结来说: 这篇论文的实验结果不仅在各类跑分榜单(如 RewardBench)上刷新了基准 ,更重要的是,它通过极限压力测试(噪音、少样本、故意构造的长篇废话)证明了其数学架构在防御大模型“作弊”时具有压倒性的优势。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)