【晓天衡宇·评测社区】HLE Verified榜单正式发布
【榜单简介】
随着大模型在复杂推理任务上的竞争日益激烈,HLE作为衡量深层推理能力的高难度基准,其数据质量成为影响测量有效性的关键。但当前部分题目存在质量与准确性的问题,是否正在系统性扭曲模型排名并降低评测的可信度?
本榜单以HLE-Verified 为核心评测基准,探索8个主流大语言模型在复杂推理任务上的真实能力边界。
HLE-Verified 是基于 Humanity’s Last Exam(HLE)构建的系统验证与修订版本评测基准。我们对原始 2,500 道跨学科高难度问题进行系统审计,建立透明的验证流程与细粒度缺陷分类体系,对问题陈述、参考推理与最终答案分别进行独立核查与保守修订。数据被划分为 Gold(668)、Revision(1,143) 与 Uncertain(689) 三个子集,并提供完整的验证元数据与错误类型标注。HLE-Verified 旨在提升高难度推理评测的数据可靠性与验证透明度,为更稳健的能力测量提供基础设施支持。
【查看完整榜单】👉🏻 https://skylenage.net/sla/leaderboard
【参评模型】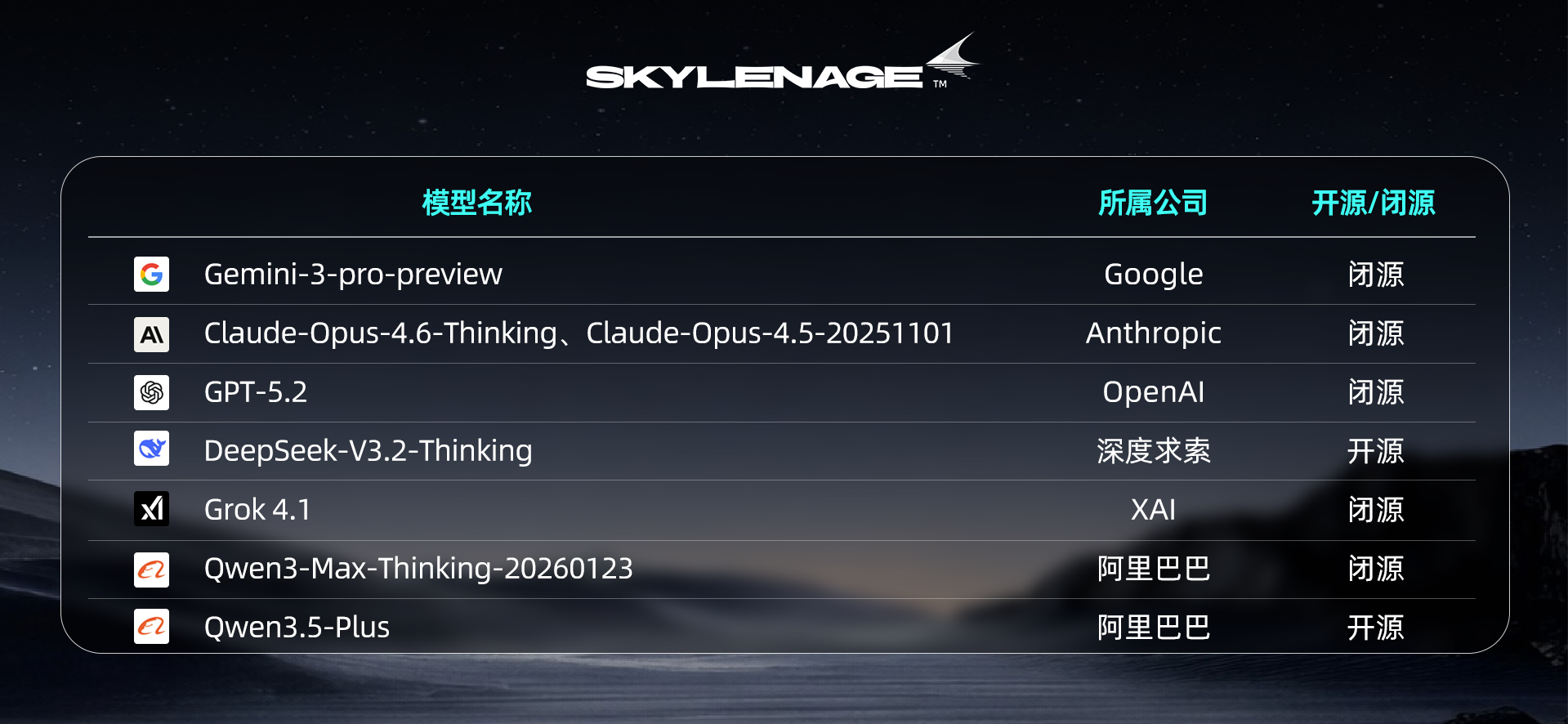
【评测集解读】
评测维度
HLE-Verified是HLE的验证与修订版本,建立了透明的验证流程与细粒度缺陷分类体系。HLE-Verified的构建遵循“验证 - 修复”两阶段工作流,最终形成一个统一的认证基准,以提升测量稳定性与评测公信力。
一、精细化缺陷分类:
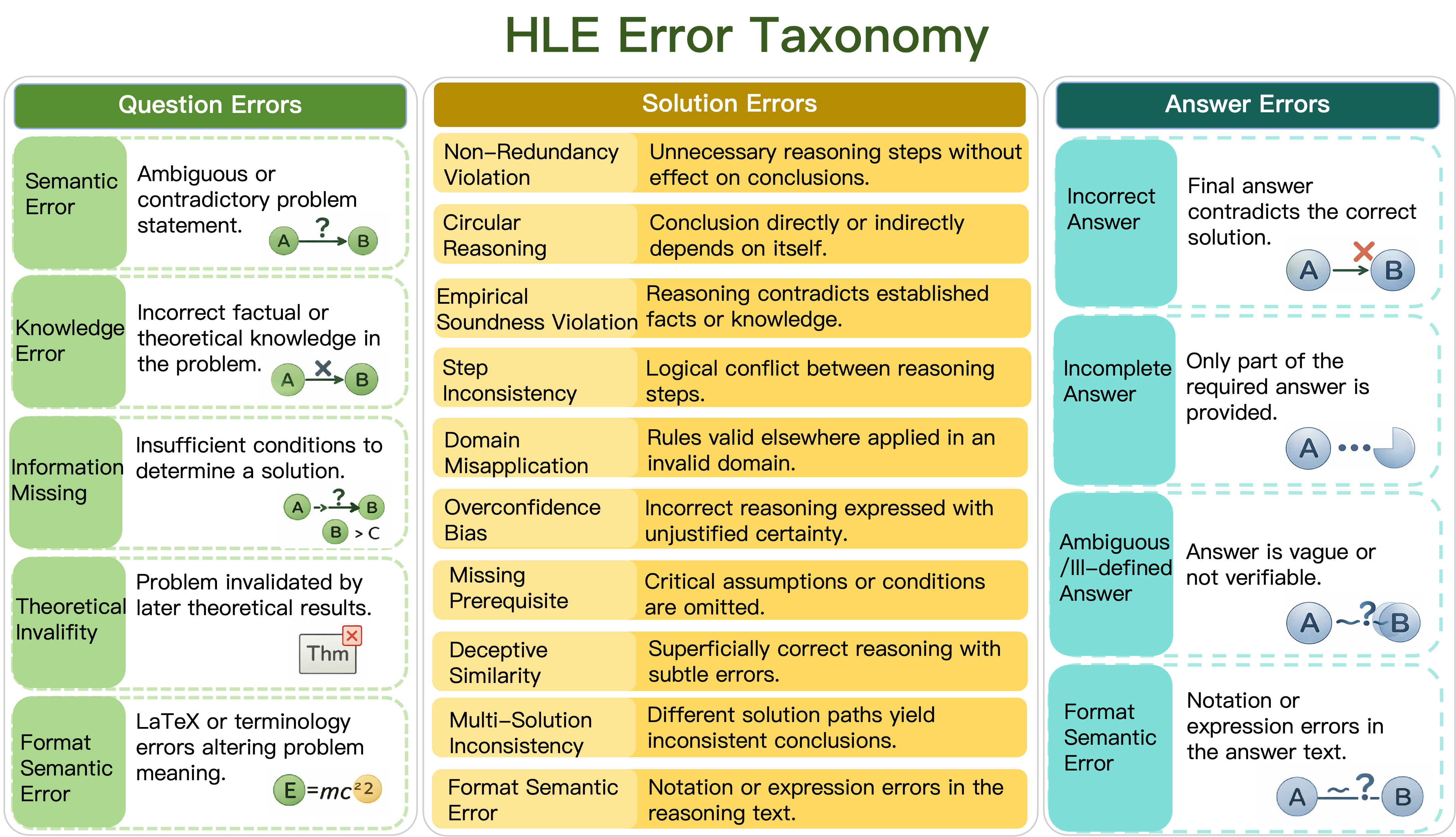
二阶段的每条样本均提供验证信息,涵盖题干、解题过程及答案的有效性判断与缺陷类别编号,确保评测结果具备可解释性与可复现性。该体系划分为问题层(语义错误、知识性错误等 5 类)、推理层(循环论证、领域误用等 10 类)及答案层(错误答案、表达不明确等 4 类)三个维度。
这种超越简单“对/错”标签的多维度错误分类,为模型能力评估提供了细粒度的洞察依据。
二、保守裁决原则:
1、保守纳入原则
进入 Gold 或 Revision 子集的前提是获得充分的组件级有效性证据。仅当题目陈述与最终答案均被专家确认正确、定义明确且在审查下保持稳定时,样本才会被纳入。其中“未发现错误”并不等同于“确认有效”,有效性必须得到正向支持。
推理(rationale)层面的缺陷本身不会自动导致样本剔除,因为评测通常基于最终答案。然而,当推理缺陷暗示存在隐含假设、歧义或与最终答案不一致时,该样本将被升级复审或进入修订流程。
2、模型辅助检查的角色
模型复现结果(如 pass@k 成功率)仅作为诊断信号,而非裁决依据。
-
多个强模型的系统性失败触发专家复审;
-
高一致率并不被视为正确性的充分证明,同样最后由领域专家复审。
3、Uncertain 子集的形成
当现有证据不足以确认正确性时,样本将被保留至 Uncertain 子集,而非强行修订或纳入有效集合。
这一策略优先保障 benchmark 的测量稳定性,避免因过度修订引入新的评测偏差。
数据标准
数据集包含 668 条黄金样本、1,143 条修订样本以及 689 条保守保留的不确定样本,有效提升了评测集的可靠性与完整性。
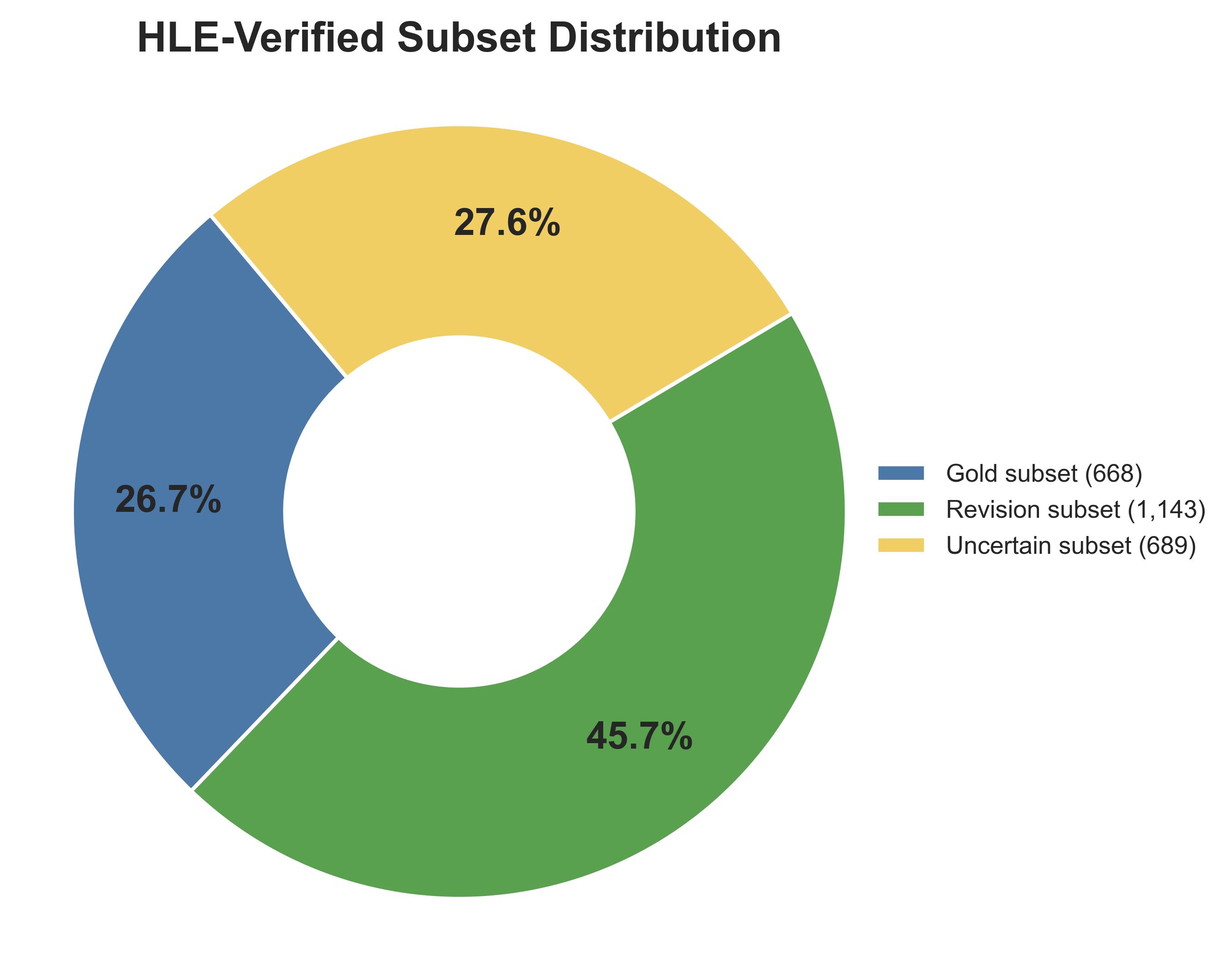
HLE验证子集的数据分布
通过两阶段工作流程完成数据构建:
-
第一阶段:聚焦模型复现与专家交叉验证,通过统一求解提示模板、系统化答案抽取及数学等价判断,经专家与模型多方比对,确认了 668 条黄金样本;
-
第二阶段:实施系统化修订与保守裁决,经由双专家独立修订、多模型一致性辅助校验及终审裁决,修订产出了1,143条修订样本;其余的689条样本划分为不确定样本,最终整合产出 2,500 条数据。
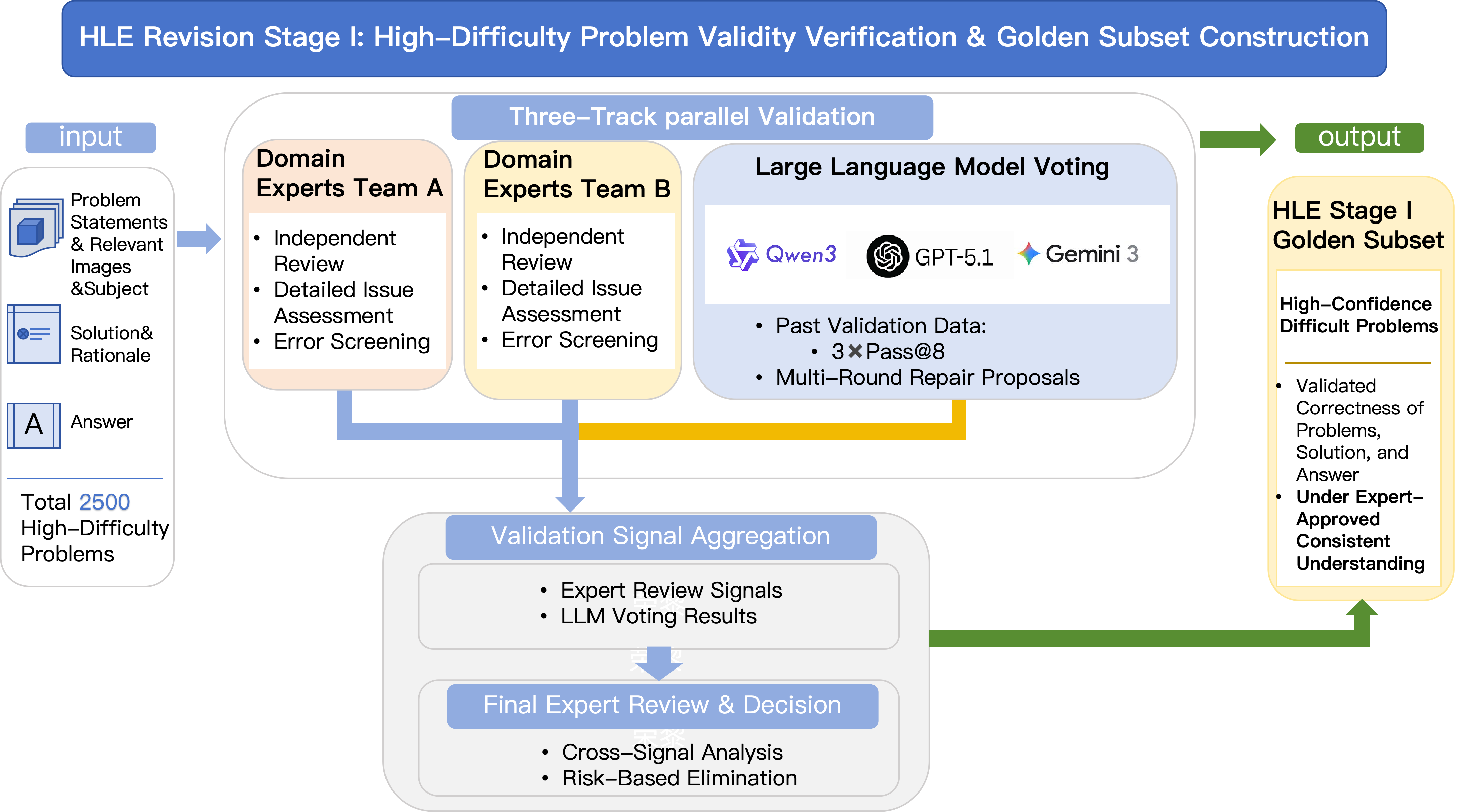
HLE 修订第一阶段:高难题目有效性验证与黄金子集构建
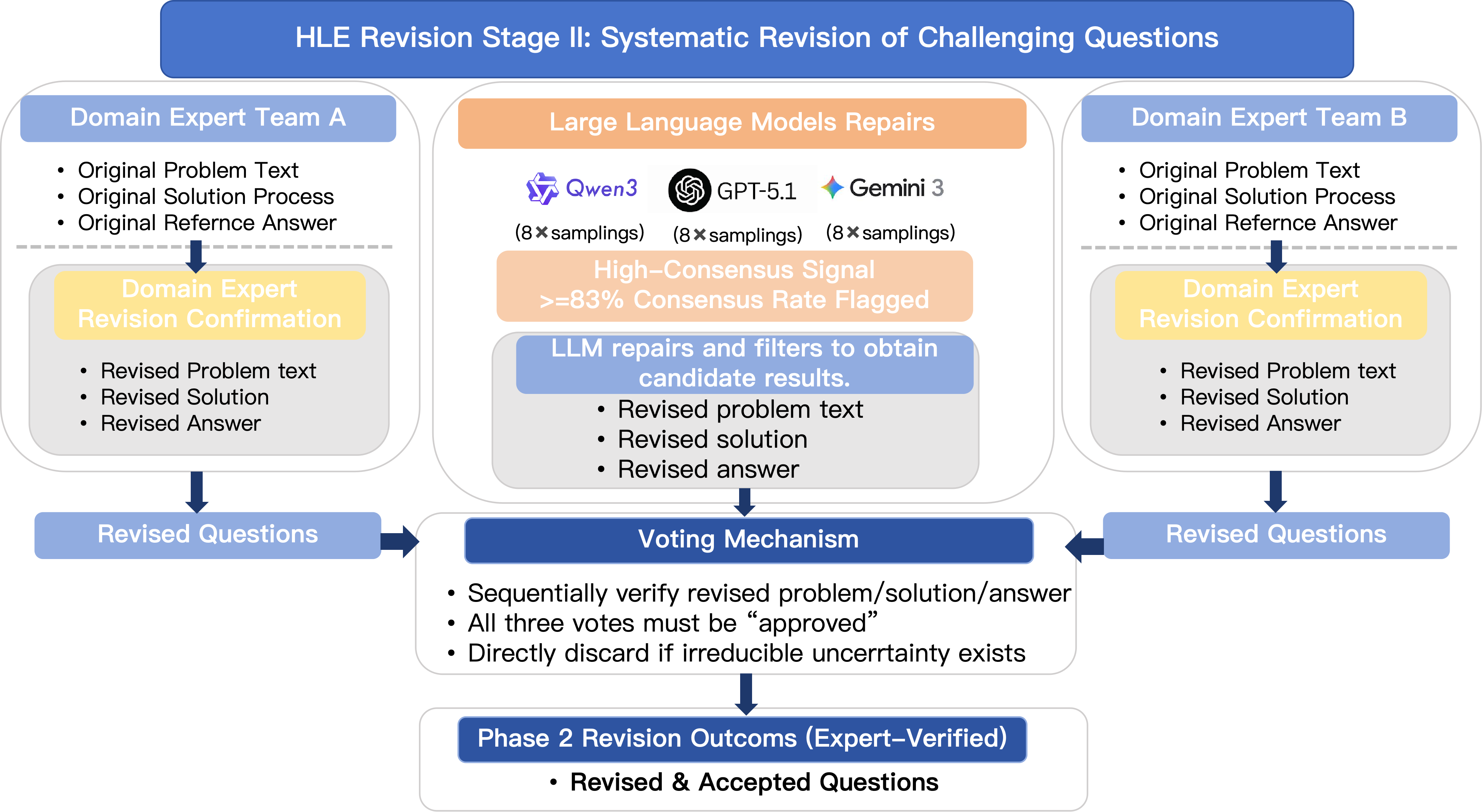
HLE 修订第二阶段:挑战性题目系统性修订
【评分标准】
为保证 HLE-Raw 与 HLE-Verified 的对比具备可复现性与公平性,我们采用统一评测流程对模型进行系统评测:
-
统一输入与提示:所有模型使用同一套评测提示词与输出格式约束(要求给出最终答案的规范表达),避免因 prompt 差异引入额外偏差。
-
标准化答案抽取与等价判定:对模型输出进行答案抽取,并按固定规则进行答案归一化与等价判定(如数值容差、格式归一、多答案顺序处理等),确保“对/错”判定一致。
-
一致的指标体系:
-
Accuracy (Acc):最终正确率;
-
Calibration Error (Cali Err):基于模型自报置信度与正确性的校准误差,用于衡量“置信度—正确率”的一致性。
-
-
对比维度分解:除全量对比外,额外在“被修订子集 / 原题存在题面或答案缺陷子集”上做对比分析,用于隔离噪声项对整体评测结论的影响。
【榜单速览】
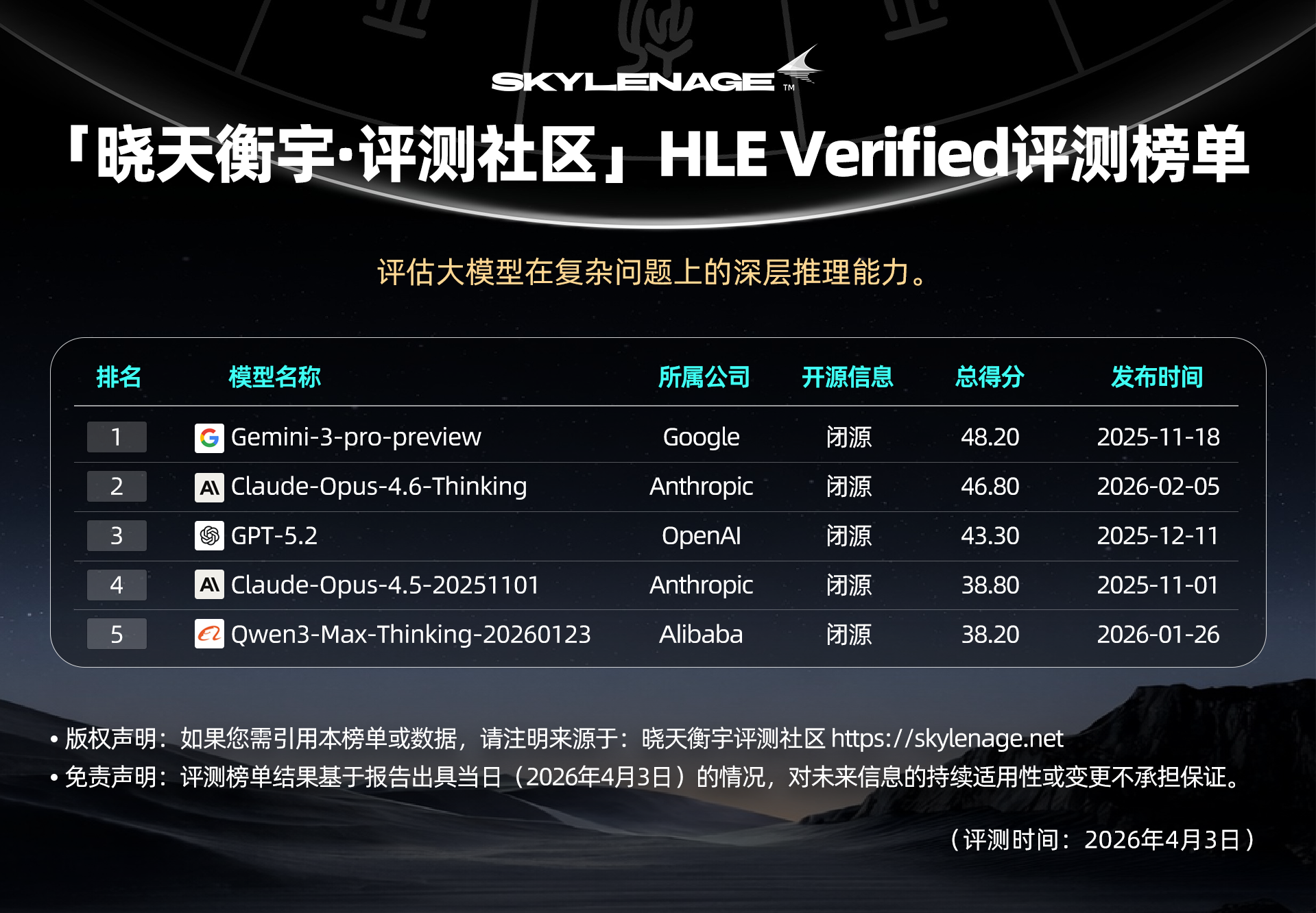
第一梯队:Gemini 与 Claude 的双雄争霸
Gemini-3-pro-preview (48.2分):这表明 Google 在超长上下文理解和复杂逻辑推理(尤其是科学领域)上,目前确实做到了行业领先水平。
Claude-Opus-4.6-Thinking (46.8分):Claude 的逻辑严谨性在这份Verified 榜单中得到了证明,Thinking模式也是它能拿高分的一个关键因素。
第二梯队:GPT 与 Qwen 是中坚力量
GPT-5.2 (43.3分):OpenAI 的这款模型排在第三,虽然依然是顶级水平,但与 Gemini 3 和 Claude 4.6 相比,有一定的差距,这意味着在这一特定领域,GPT-5.2 的推理深度略逊一筹,或者它更擅长通用任务而非专项的科学推理。
Qwen3-Max-Thinking (38.2分) :Qwen在这个榜单中与海外模型的分数非常接近(仅差 0.6 分),表现也可圈可点。
👉【获取完整榜单】
此处仅展示综合评分前五名预览,查看完整排名以及细分维度的详细对比数据,请访问晓天衡宇•评测社区官网:https://skylenage.net/sla/leaderboard
【榜单结论】
-
在 HLE-Verified 上,模型平均绝对准确率提升 7–10 个百分点
-
在原题存在错误的子集中,模型平均提升幅度达到 30–40 个百分点
表明部分“模型能力差异”实际上来源于数据噪声,而非模型本身能力差距。
HLE-Verified 并非单纯的数据修订,而是一项面向前沿大模型评测可靠性的系统性工程。在模型能力快速演进的时代,“评测本身的可信度”正在成为新的核心问题。我们将 HLE-Verified 视为一个“持续演进的评测基础设施”。
【了解更多】
HLE-Verified评测榜单已同步上线至晓天衡宇•评测社区官网,欢迎大家访问查看更详细的评测数据:https://skylenage.net/sla/home
👇关注晓天衡宇•评测社区官方社区,获取更多大模型相关知识~

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 12
12 0
0- 0



 已为社区贡献16条内容
已为社区贡献16条内容

所有评论(0)