大语言模型从头造适配体:InstructNA 让功能核酸设计告别盲目筛选
本文为《De novo design of functional nucleic acids of aptamers》的阅读笔记,原文链接:https://www.nature.com/articles/s43588-026-00965-3。
本文解读Nature Computational Science 2026的研究《 De novo design of functional nucleic acids of aptamers 》,提出InstructNA 框架,将核酸大语言模型(NA-LLMs)与高通量 SELEX 实验结合,在不依赖三维结构的情况下,直接从头设计高活性、高多样性的功能核酸(适配体、转录因子结合 DNA)。相比传统筛选,强结合适配体产出最多提升200%,最低序列相似度仅38%,为分子诊断、靶向治疗提供全新设计范式。

功能核酸(FNA)是生命科学的 “万能分子工具”—— 既能像抗体一样精准抓蛋白(适配体),又能调控基因、催化反应,在诊断、靶向药、分子器件里无处不在。
但想 “设计” 一个好用的功能核酸,一直是世界级难题:
序列空间大到爆炸、实验筛选又贵又慢、传统 AI 只会抄现有序列、还必须依赖蛋白结构…… 很多靶点根本做不了。
现在,一项发表在Nature Computational Science的研究彻底破局:
InstructNA—— 用核酸大语言模型,直接从零设计高活性功能核酸。
不需要蛋白结构、不需要已知配体、不需要手动优化,给它测序数据,它就能批量造出比实验筛选更好的适配体。
这一次,功能核酸终于从 “大海捞针” 变成 “精准制造”。
一、功能核酸设计:卡了十几年的三大死结
功能核酸虽好用,但传统研发路线处处是坑。
序列空间过于庞大,短短几十 bp 的核酸序列组合数就远超天文数字,靠实验筛遍所有可能完全不可能。传统实验筛选 HT-SELEX 周期长、成本高,还会被 PCR 偏差带偏,容易漏掉真正高活性的序列。
现有的计算方法要么严重依赖蛋白质三维结构,要么只能在小数据集上训练,学不到通用规律,生成的分子活性低、长得像、难突破。
在适配体这种需要高亲和力的分子上,传统方法更是经常 “筛不出、用不了、做不出”。
二、AI 破局:InstructNA 大语言模型驱动的从头设计
InstructNA 的核心思路,是把大语言模型和高通量筛选数据结合,让 AI 先学会功能核酸的 “语法”,再按功能直接生成。
2.1 整体框架:五步法全自动设计
整个流程干净利落,完全自动化:
1.收集 HT-SELEX 筛选序列,构建高质量训练数据;
2.用功能核酸数据继续预训练核酸大语言模型,让它更懂适配体;
3.训练轻量解码器,把向量稳定还原成真实核酸序列;
4.在隐空间用 HC-HEBO 算法做定向进化,越优化活性越高;
5.实验验证,再把结果喂回 AI,形成闭环迭代。
它不依赖任何蛋白结构信息,只看序列就能设计高活性分子。
2.2 核心创新:HC-HEBO 定向进化算法
普通贝叶斯优化容易乱跑,InstructNA 专门提出HC-HEBO:
把爬山法(HC)和进化贝叶斯优化(HEBO)合体,既保证多样性,又能在有效区域内精细搜索,让序列朝着 “高亲和力” 快速进化。
2.3 关键公式:结合特异性打分
研究用两个核心公式量化功能,保证生成质量:
总结合特异性打分:
![]()
归一化相对特异性:
![]()
分数越高,代表 DNA / 适配体结合越强、越精准。
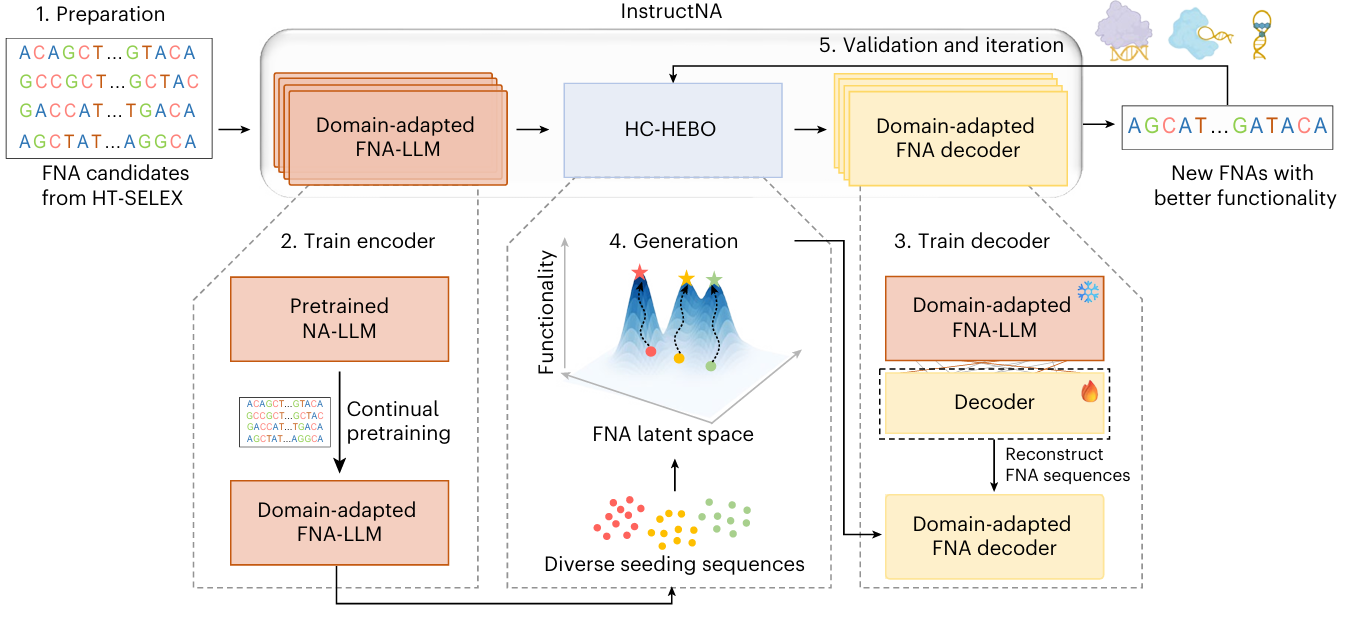
图1 InstructNA 功能核酸从头设计框架
三、关键结果:AI 造的适配体,完胜实验筛选
3.1 转录因子结合 DNA:更高特异性、更多新序列
在 10 种转录因子上测试,InstructNA 表现全面领先:
序列语义表示更准确,与真实序列相关性更高;
结合特异性分类 AUROC、F1 等指标全面超越基线模型;
在 Ar、Dbp、Srebf1 上,高特异性序列比例远超传统方法。
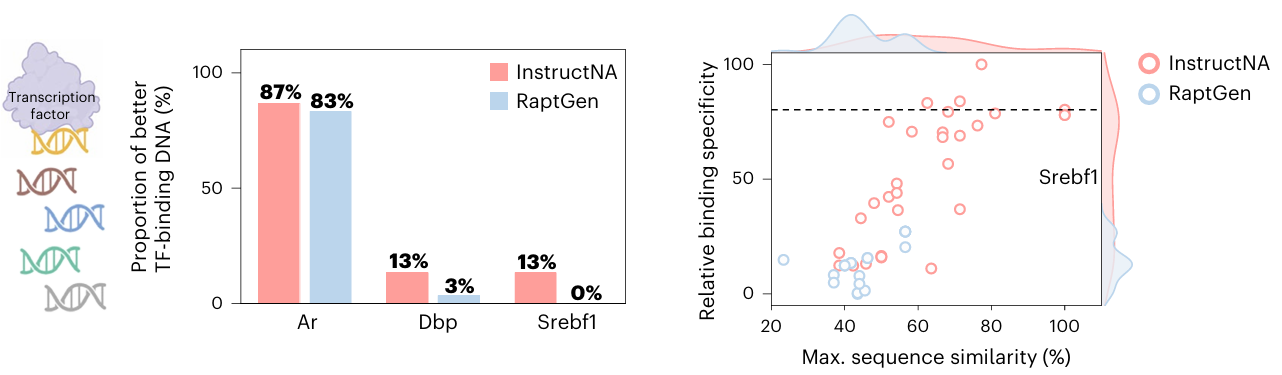
图2 InstructNA 生成高特异性 DNA 序列
3.2 蛋白适配体:强结合体数量暴涨 200%
研究在LOX1、CXCL5两个重要蛋白靶点做实验验证:
传统 HT-SELEX 只筛出 2 个和 1 个强结合适配体;
InstructNA 直接造出4 个和 3 个,数量分别提升100%、200%;
最优亲和力达到6.6 nM,比实验筛出来的还要强;
最优序列与原始序列相似度低至 38%,是全新骨架。
3.3 结构与机理:全新折叠、更强相互作用
AI 设计的 G1ᴸ适配体,结构比实验筛选的更复杂、结合更牢:
形成更精巧的环区折叠;
与蛋白界面形成更多氢键;
结合自由能更优;
结合区域完全不一样,开辟全新结合模式。
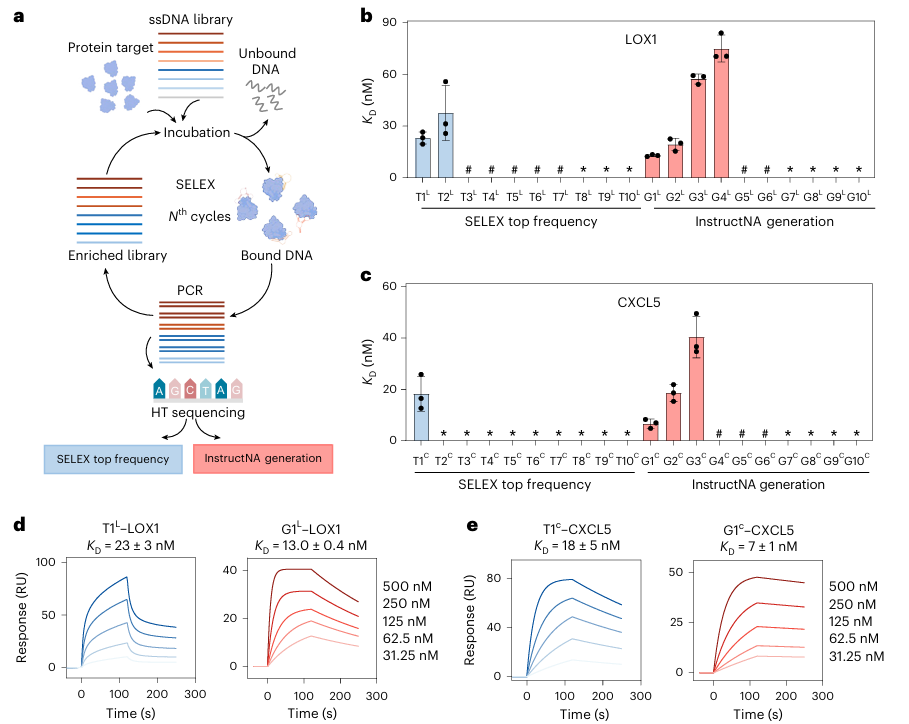
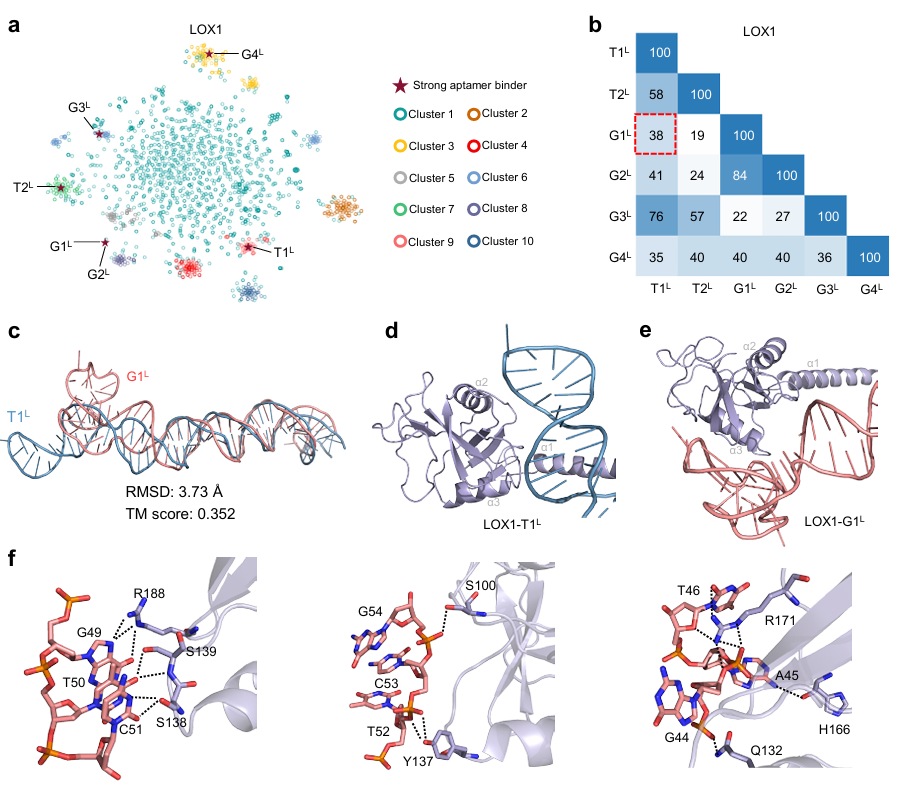
图3 AI 生成适配体的超高亲和力与全新结构
四、科学意义:功能核酸设计进入大模型时代
InstructNA 的突破,是整个功能核酸领域的范式转变。
它第一次证明:核酸大语言模型可以不依赖结构,直接从头设计高活性功能核酸。
它第一次实现:从序列数据到高活性适配体的全自动闭环设计。
它第一次做到:AI 生成分子比实验筛选的更好、更多、更新颖。
未来,适配体、核酶、DNAzyme、调控元件都可以用这种方式快速设计,诊断与靶向药的研发速度会被重新定义。
五、总结
InstructNA 用大语言模型重新定义了功能核酸的研发方式。它不需要蛋白结构、不需要先验配体,只靠 HT-SELEX 数据,就能批量生成高活性、高多样性的适配体与功能 DNA。在 LOX1 与 CXCL5 上,它把强结合适配体产量提升数倍,亲和力达到纳摩尔级,序列相似度低至 38%,实验与计算完全互相验证。
这标志着功能核酸不再靠筛,而是靠 AI 设计。一个更高效、更低成本、更快落地的核酸分子工具时代,已经到来。
点击更多,学习更多精彩内容。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 8
8 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)