Fast-dVLA:加速离散扩散VLA到实时
26年3月来自香港科大(广州)、上海科大、中科院上海技术物理所、清华、西湖大学和浙大的论文“Fast-dVLA: Accelerating Discrete Diffusion VLA to Real-Time Performance”。
本文提出了一种方法,旨在解决预训练的VLA模型在标准监督微调(SFT)过程中通常无法有效提升性能和降低适应成本的挑战。一些带有辅助训练目标的高级微调方法可以提升性能并减少收敛步骤。然而,由于辅助任务带来的额外损失,这些方法通常会产生显著的计算开销。为了在保持标准SFT简洁性的同时,兼顾辅助训练的增强能力,将辅助任务训练的两个目标(即增强通用能力和拟合特定任务的动作分布)在参数空间中解耦。
为了实现这一目标,只需使用两种不同的训练策略,使模型在一个小型任务集上收敛即可。由此得到的模型参数差异可以解释为辅助任务提供的能力向量。然后,将这些向量与预训练参数合并,形成一个能力增强的元模型。此外,当标准SFT与轻量级正则化损失相结合时,合并后的模型在降低计算开销的同时,达到与辅助微调基线模型相当的性能。
近年来,基于扩散大语言模型(dLLM)的离散扩散VLA,即dVLA(Liang et al., 2025b; Wen et al., 2025a,c; Chen et al., 2025; Ye et al., 2025b),已成为现有VLA架构的有力挑战者。这些模型以并行迭代去噪的方式输出动作,且不依赖于流匹配头。因此,与流匹配架构相比,它们在统一的多模态对齐和理解方面展现出固有优势(Chen et al., 2025; Wen et al., 2025a),同时更好地保留VLM的预训练知识(Liang et al., 2025b)。
PD-VLA(Song,2025b)首先采用雅可比解码,使AR VLA无需训练即可并行预测动作token。然后,DD-VLA(Liang,2025b)和LLADA-VLA(Wen,2025c)遵循BERT风格的掩码预测策略(Devlin,2019),其中选定的动作token被替换为特殊的掩码token,模型直接学习预测这些掩码位置的原始token。 Dream-VLA(Ye,2025a)对扩散视觉语言模型进行大规模机器人预训练,以注入具身能力。UD-VLA(Chen,2025)、MM-ACT(Liang,2025a)和dVLA(Wen,2025a)将视觉CoT或文本CoT集成到离散的基于扩散VLA模型中,并在一个统一的框架内联合扩散未来帧、文本推理轨迹和动作。
然而,目前的dVLA仍然存在一个根本性的局限性。它们的推理速度较慢,执行频率远低于物理机器人系统的实时性要求(通常约为 30 Hz)。这种巨大的差距极大地限制了它们在实际应用中的可行性。如图所示,尽管 dVLA 通过实现并行解码显著减少了生成完整动作序列所需的前向传递次数(与离散自回归 (AR) VLA 相比)(图(a) 所示),但其双向注意机制阻碍对先前生成token的KV缓存重用,导致每次前向传递的效率非常低(图 (b)所示)。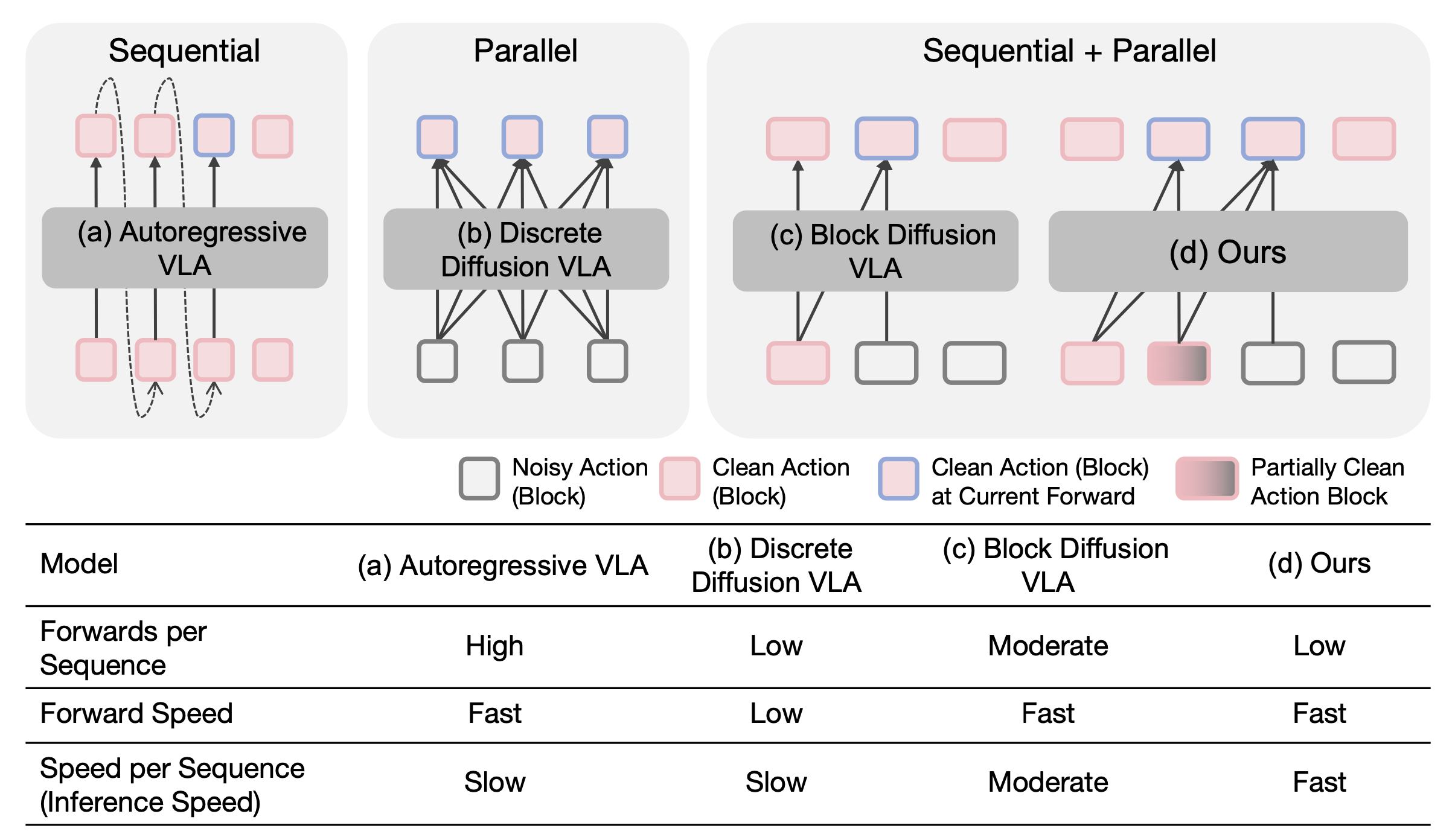
本文提出一种分块扩散策略 Fast-dVLA,实现将 dVLA 加速到实时水平的突破。在概念上,利用分块顺序生成来提高KV缓存的利用率,同时消除后续块等待先前块完成去噪的要求。具体而言,将每个时间步的完整动作token序列(即动作的维度)及其倍数视为一个动作块。然后,Fast-dVLA 学习并行地对一系列具有单调递增掩码比例的块进行去噪。自然地,前面的块可以比后面的块更早完成,从而允许缓存它们的KV状态以供后续计算使用。需要注意的是,将注意机制限制为分块因果关系,以确保KV缓存保持不变。为了提高训练效率,受 (Wang et al., 2026) 的启发,用非对称蒸馏损失从经过双向注意机制微调的 dVLA 中提炼出 Fast-dVLA。在推理过程中,设计一种流水线并行解码算法,该算法能够实现块间并行,并允许不同块之间存在不同噪声水平,如上图(d)所示。
为了探索利用 KV 缓存的可行性,研究 dVLA 中的动作解码顺序(如下图所示)。尽管采用双向注意机制,dVLA 仍然遵循从左到右的解码模式。这种分块解码行为表明,一个有前景的方向是应用块扩散(Arriola,2025)(上图©),它原生地使用分块注意机制训练dVLA,并行解码动作token块,在完成该块解码后缓存相应的KV状态,然后以AR方式继续处理下一个块。这种设计通过平衡部分KV缓存重用和块内并行解码,实现适中的推理速度。然而,它本质上排除块间并行,而块间并行是实现高吞吐量和低延迟推理的关键因素。
离散扩散 VLA(例如 Dream-VLA (Ye,2025a) 和 DD-VLA (Liang,2025b))输出离散的动作token,这些token是通过均匀分箱 (Kim,2025b) 或量化token化器 (Pertsch,2025) 获得的,而不是直接处理连续控制。动作表示为长度为 L 的离散token序列 a_0 = (ai_0, . . . , aL_0),其中每个token ai_0 对应于离散的底层机器人动作,并且词汇表中添加一个特殊的掩码token M,以实现扩散式的干扰。
前向扩散过程根据一个随时间变化的掩码比例,独立地将一部分动作token替换为 M。逆过程学习如何在未掩码的上下文和多模态输入 c(例如,语言和视觉观察)的条件下恢复被掩码的token。在每个去噪步骤中,未掩码的标记被原封不动地复制,而掩码的位置则根据模型参数化的类别分布进行预测。
在训练过程中,对掩码比例 γ_t ∈ (0, 1] 进行采样,并将相应的动作token替换为 M,从而得到一个损坏的序列 a ̃_t。然后,使用只在掩码位置计算的交叉熵 L_act(θ) 来训练模型以重建原始token。该目标保留离散扩散的核心去噪原理,同时能够使用标准的离散VLA架构进行高效训练。
UD-VLA(Chen,2025)通过引入未来视觉预测,将此框架扩展到统一VLA模型(Wang,2025b)。具体而言,使用VQ-VAE(Zheng,2022)编码器将未来的图像观测值编码为离散token序列v_0 = (v1_0, . . . , vL_0),并与动作token连接起来形成统一序列。然后,将扩散过程联合应用于视觉token和动作token,从而以统一的方式学习未来的视觉推理和动作生成。
动机
如上图所示,记录并可视化代表性 dVLA(即 Dream-VLA)在去噪过程中不同位置的解码频率。有趣的是,尽管 dVLA 采用双向注意机制,但该模型在全局层面上仍然表现出明显的从左到右的解码模式。具体而言,时间维度上较早出现的动作块往往在较早的去噪迭代中被解码。这可以归因于:1)现有 dVLA 的主干网络(Ye,2025b)通常基于自回归视觉-语言模型 (AR VLM) 初始化,并以离散扩散的方式进行训练,从而保留一定的自回归特性。2)不同时间步的动作表现出固有的时间依赖性。这种分块的自回归解码行为表明,经过微调的双向 dVLA 可以直接被强制遵循分块扩散的解码方式。
目标模型的关键设计
用于块间KV缓存重用的分块注意机制。如图 a 所示,当前的 dVLA 模型(Chen,2025;Liang,2025b;Ye,2025a)使用双向注意机制生成部分或完整序列,这导致KV表示在每次去噪迭代中都会发生变化。因此,AR 模型中使用的传统 KV 机制无法直接重用以加速推理。
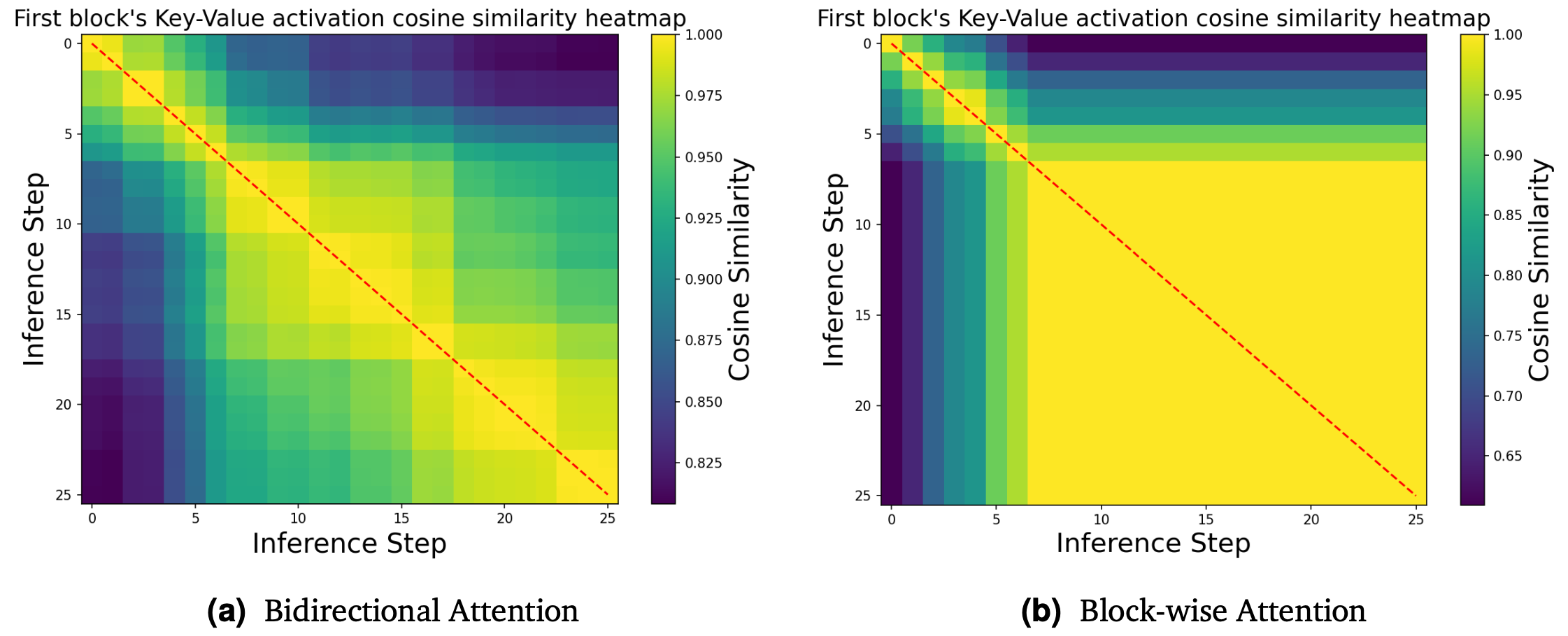
在每个块内,KV 表示仅受前缀token和当前块内 token的影响。如上图 b 所示,一旦某个数据块的解码完成,该数据块的 KV 值在后续步骤中保持不变,从而能够有效地重用缓存以进行后续的解码过程。
为了解决(传统 KV 机制无法直接重用以加速推理)这一限制,采用一种结合分块注意机制(见下图)的块扩散解码策略,该策略通过在顺序依赖和并行生成之间进行插值,将自回归解码和离散扩散连接起来。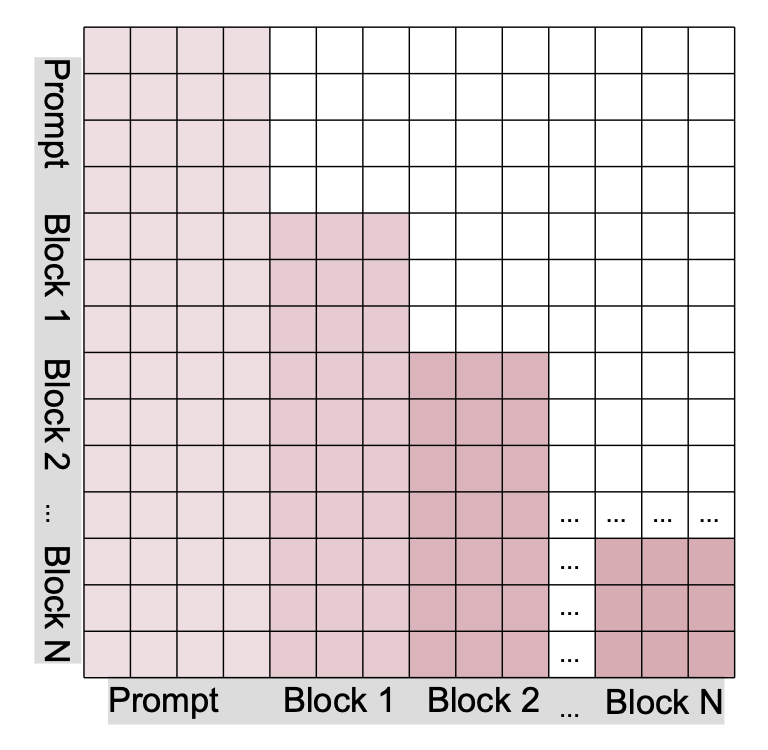
用于块间并行解码的扩散强制。受 mimic-video(Pai,2025)方法中观察的动作token无需关注先前时间步干净token的启发,构建一个类似于扩散强制的渐进衰减噪声序列(Chen,2024;Yin,2025;Li,2026)。令第 i 个块的索引集定义为 B_i = {(i−1)k, …, i k−1},并用 Y_B_i 表示对应的token子序列。
在前向扩散过程中,根据单调递增的顺序 t_1 < t_2 < · · · < t_N 为不同的块分配逐渐增加的噪声水平。形式上,噪声序列可以表示为 Yt_1:N = {Yt_1_B_1, . . . ,Yt_N_B_N}。在这种设计下,较早的数据块受到的噪声影响较小,因此保留更完整的信息,而较晚的数据块则受到更严重的噪声掩码,不确定性也更高。
对于逆过程,学习一个θ-参数化的模型,该模型以分块自回归的方式分解条件分布。这种形式使得模型能够逐步细化较早的数据块,同时对较晚的数据块进行去噪,从而自然地实现跨数据块的并行解码,而不会牺牲时间一致性。
训练:非对称蒸馏实现高效的后训练
为了训练Fast-dVLA,一种直接的方法是在其保持分块注意机制和扩散强制目标的前提下从头开始训练,即损失L_BD。然而,直接从开源双向 dVLA(Chen,2025;Zhang,2025c;Liang,2025b)(作为教师模型)继承解码特性可能是一种更高效且成本更低的方法。
具体而言,受 (Wang,2026) 的启发,设计一种非对称蒸馏方法,其中具有分块注意机制的 Fast-dVLA(作为学生模型)被强制与具有双向注意机制教师模型的输出对齐,同时它们共享相同的架构,并且都以单调噪声调度对分块进行条件化,即蒸馏损失L_AD。这种蒸馏过程是不对称的,教师模型 p_φ − 利用全局视角预测每个块 Y0_B_i,而学生模型 p_θ 仅利用因果受限的视角进行近似学习。
以从头开始训练 dVLA 所需的训练预算为参考,基于微调权重(L_AD)的非对称蒸馏仅需 1/10 的步数即可收敛,这比基于微调权重或从头开始使用 L_BD 进行训练效率高得多。因此,将非对称蒸馏作为默认的训练目标。
推理:流水线并行解码
如图所示,与传统的块扩散方法(Arriola,2025)不同,后者仅在每个块内进行并行解码,且严格按照顺序解码不同的块,而本文方法能够跨多个块进行并行预测。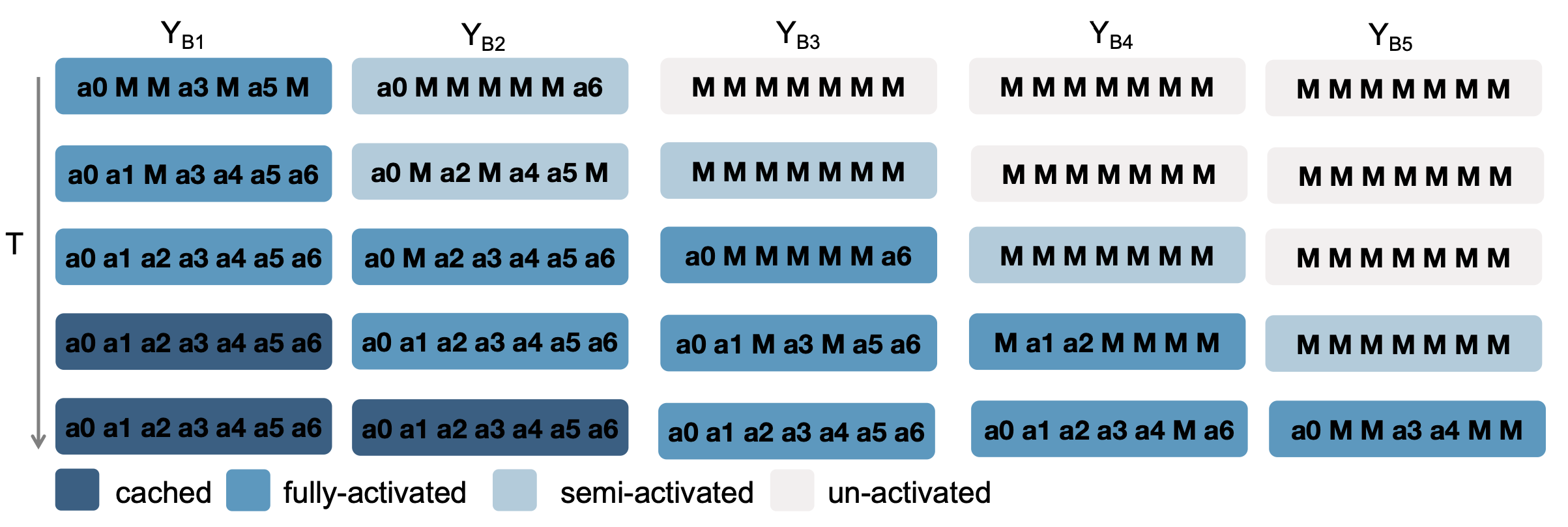
具体而言,将激活的块(即当前正在解码的块)分为两种状态:半激活和完全激活。这两种状态之间的转换取决于前一个块的完成率,并分别与阈值 τ_add 和 τ_act 进行比较。当前一个块的完成率超过 τ_add 时,后续块被定义为半激活块。采用置信度-觉察解码策略(Wu,2025)来选择性地解码预测置信度超过阈值 τ_conf 的token。一旦完成率超过 τ_act,该块将进入完全激活状态,此时,根据置信度排序,每一步至少保证剩余token的 1/n 被解码。
这种多状态块并行解码机制在效率和性能之间实现了良好的平衡。同时,它确保较早执行的动作token在早期迭代中被解码,从而保留动作执行中固有的时间因果关系。推理算法总结的伪代码如下:

全面实验评估 Fast-dVLA 在模拟和真实机器人操作任务中的有效性。
模型设置
选择 Dream-VLA 和 DD-VLA 作为 dVLA 模型的代表,选择 UD-VLA 作为统一 dVLA 模型的代表。对于 Dream-VLA,执行 4k 步的蒸馏,这大约相当于原始微调预算的 1/5。对于 DD-VLA,将蒸馏步数设置为 4k,这大约相当于原始微调步数的 1/8。将块大小设置为 7。对于 UD-VLA,执行 3k 步的蒸馏,这大约相当于原始 UD-VLA 微调步数的 1/8,批大小为 12。由于 UD-VLA 的输出序列相对较长(625 个 token),将块大小设置为 32 的倍数。所有其他训练超参数均遵循原始模型配置。
模拟环境基准测试。对三个常用的基准测试集(CALVIN (Mees et al., 2022)、LIBERO (Liu et al., 2023) 和 SimplerEnv (Li et al., 2024))进行大量的模拟实验,以提供全面的结果。
真实世界实验设置。真实世界实验在AgileX双臂机械臂平台上进行,该平台每个6自由度机械臂均配备一个夹爪。传感系统包括一个高位安装的顶置摄像头,用于提供全局视角;以及两个腕部安装的摄像头,用于提供局部视角。
真实世界任务设置。设计三个不同的任务:(1)传送带拣选,即从移动的传送带上拣选方块并将其放入托盘中。(2)蔬菜存放,即根据容器中的文字标签对蔬菜进行分类。(3)蔬菜取放,即根据特定的语言指令抓取目标蔬菜并将其放入花盆中。对于每个任务,收集100个专家演示用于训练。为了进行评估,对每个任务进行了40次试验,并记录了成功率和平均完成时间。具体而言,对于传送带任务,使用每分钟成功抓取次数作为量化性能的主要评估指标。此外,还记录真实机器人平台上的执行频率,以量化实时性能。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 26
26 0
0- 0



 已为社区贡献106条内容
已为社区贡献106条内容

所有评论(0)