AI Agent学习日记 Day5(multi agent---handoffs模式实现)
这几天新建了一个专门操作文件的code_agent,和我原有的main_agent相结合,实现了multi agent。
langchain对于multi agent的实现主要有四种方式,subagent、handoofs、skills、router;具体每种方式的结构,优劣以及实现方式可以直接参考官方文档,不再赘述。
Multi-agent - Docs by LangChain
我的构想是,code_agent作为一个完全独立的agent,主要帮助用户做一些写代码、操作文件之类的工作,main_agent则主要完成之前的文档翻译、RAG问答、上网搜索和陪用户聊天等工作。两个agent只有一个入口,但上下文相互隔离,互不干扰,在遇到需要对方解决的问题时自动切换角色。这是典型的handoffs方式,即没有主agent,每个agent都能与用户直接交互,在遇到需要别的agent解决的问题时就将控制权移交出去,结构图如下:
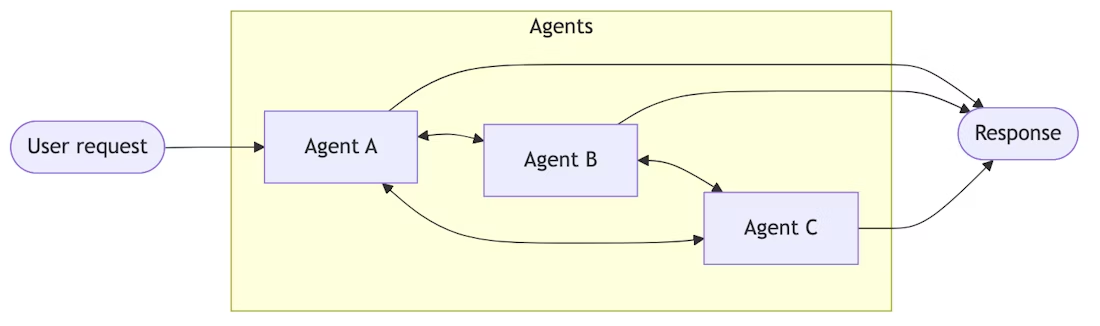
要实现handoffs,需要构建一张父图,将每个agent都作为父图的一个节点(langchain的create_agent方法返回的对象本就是一个 LangGraph 的 CompiledStateGraph,所以可以作为子图无缝添加到LangGraph 的节点),agent之间的交接就能通过控制节点之间的跳转来实现。我们可以通过在父图的state里自定义一个active_agent字段来记录当前活跃的agent,然后给每个agent注册一个交接的工具,当agent判断需要交接时,它就回调用工具跳转到目标节点(agent),同时更新active_agent字段;而每轮对话开始前,可以通过active_agent的值来直接跳转到目标agent。下图是我的架构图
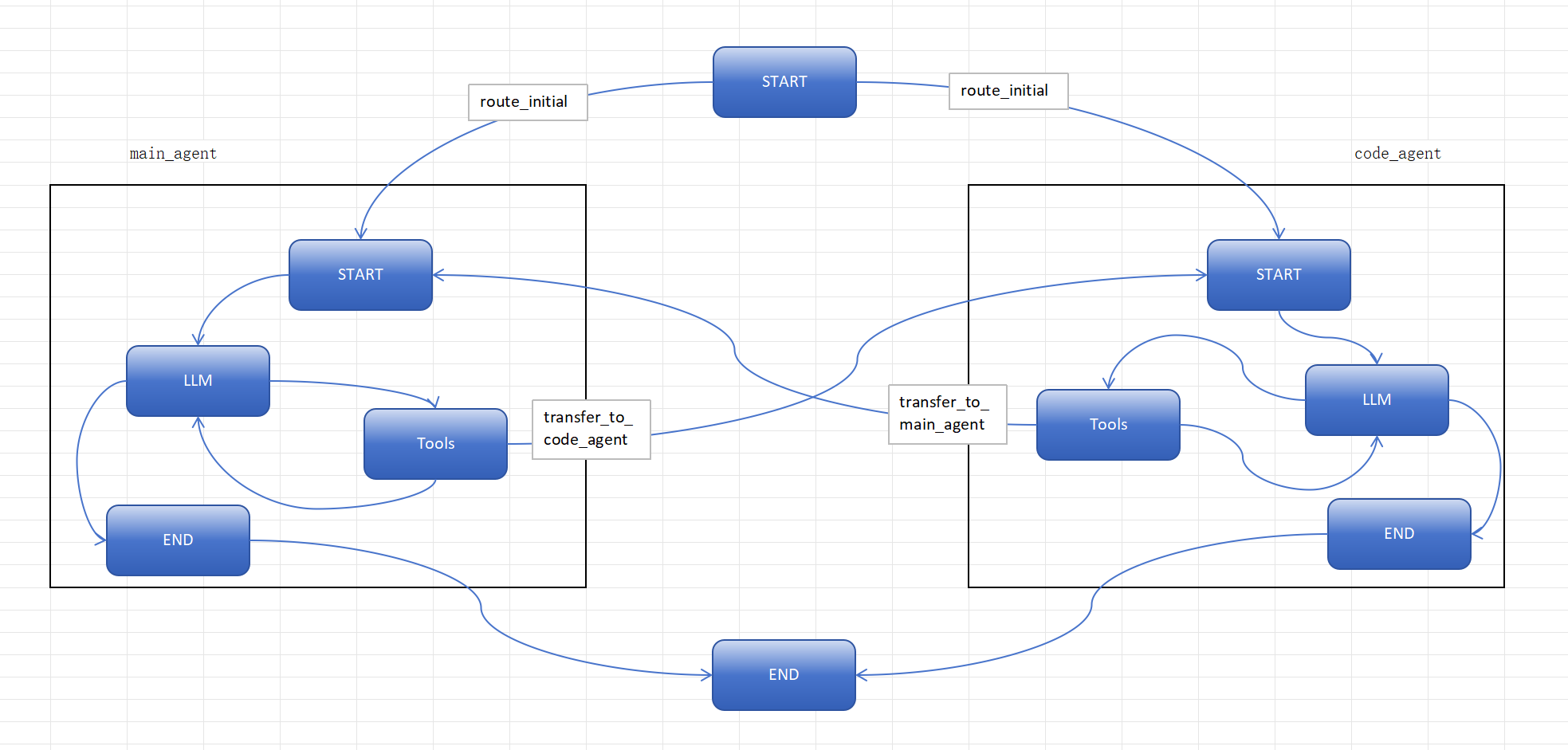
有一点需要特别注意,我之前是用checkpointer和thread id来实现单agent的短期记忆的,现在将两个agent整合到一个父图里,父图本身设置了checkpointer来保存active_agent的状态,那agent就不能再单独设置自己的checkpointer了,否则在交接工具调用时,会因为父、子图的 checkpoint 命名空间冲突,导致无法识别出Command.PARENT,就无法正常跳转。
return Command(goto=code_agent_node_name, update=update_dict, graph=Command.PARENT)在官网的示例代码中,通过在agent节点的节点函数里传入父图的状态来调用agent,由于父图设置了checkpointer,所以agent也能获取到对话历史(message字段)从而实现记忆,但是父图的state保存的是全局的上下文,也就是说连其他的agent的对话记录也被传入了当前agent,这背离了每个agent上下文隔离的初衷。
# 4. Create agent nodes that invoke the agents
def call_sales_agent(state: MultiAgentState) -> Command:
"""Node that calls the sales agent."""
response = sales_agent.invoke(state)
return response要解决这个问题,我踏马真是被豆包坑惨了,放个豆包的回答纪念一下这次周六搞到凌晨4点的痛苦经历吧

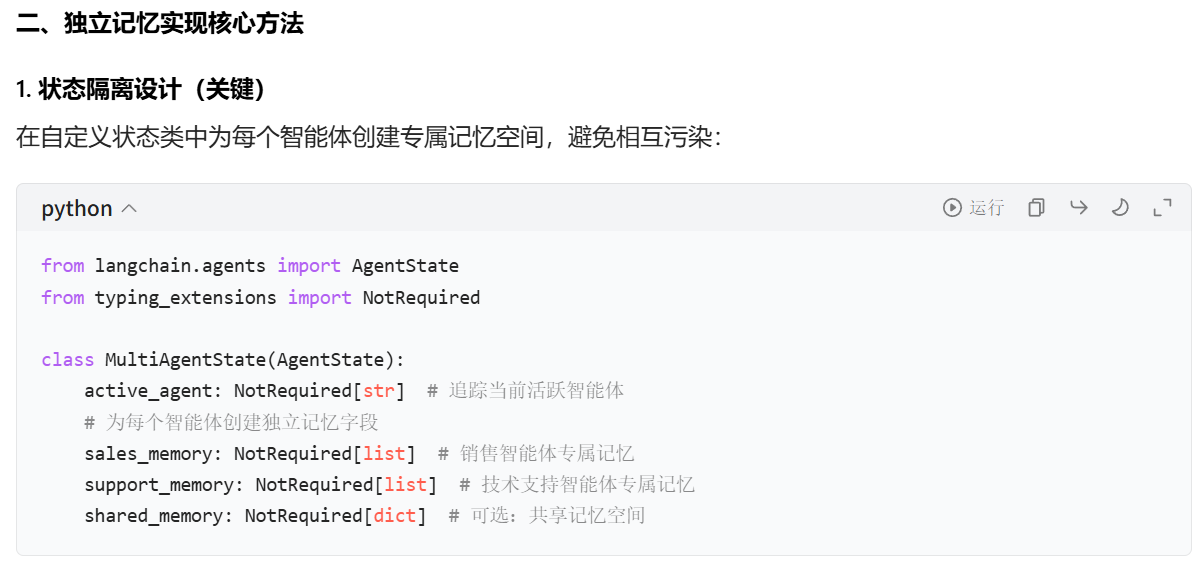
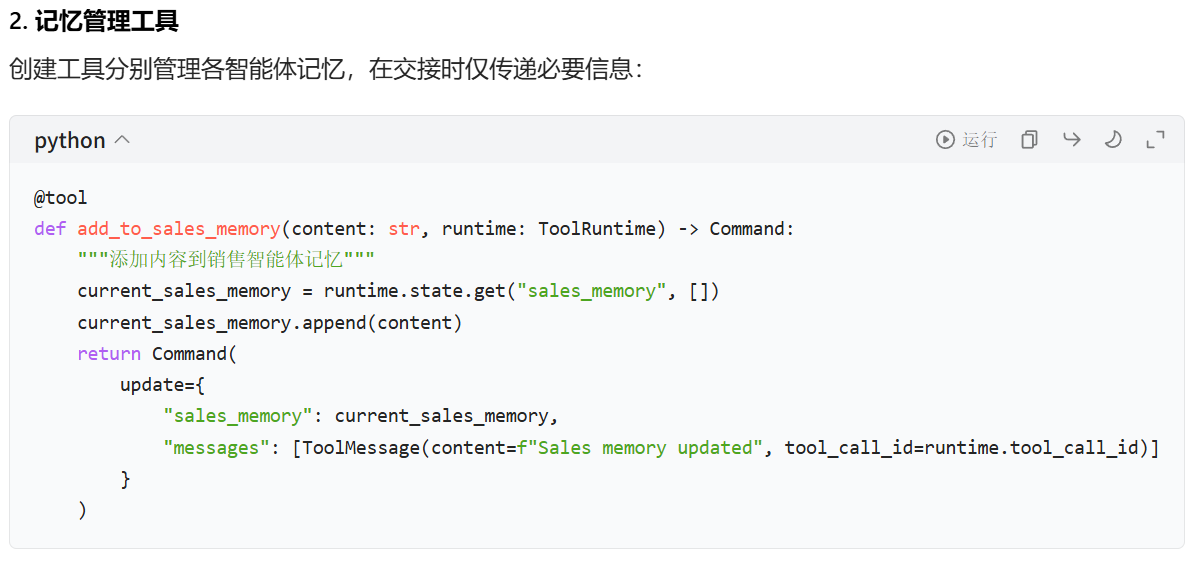
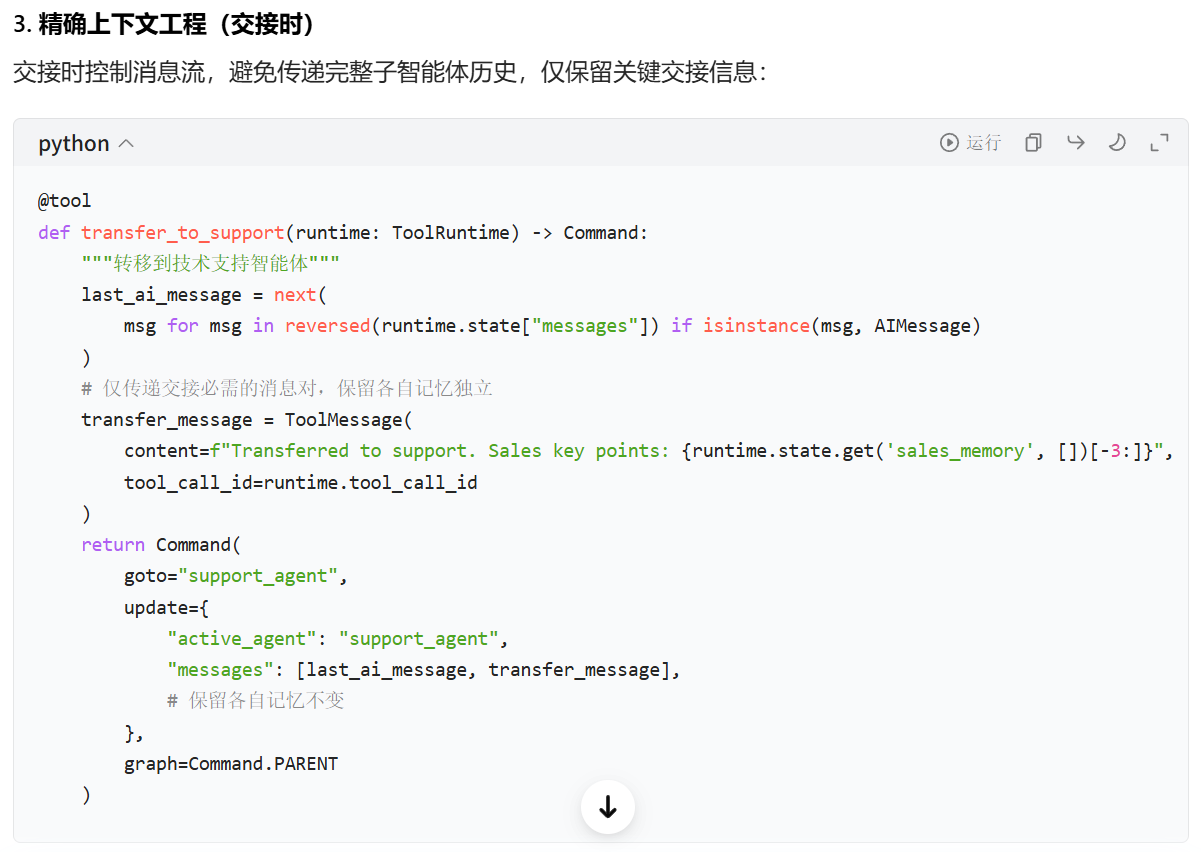

大意就是给state再定义两个字段,用来存储两个agent各自的记忆,然后再给每个agent注册一个追加对话历史的工具,要求它们在每次对话完成之后调用工具更新记忆,在agent节点函数里调用它们的时候不传入父图的state,只传入对应的记忆字段,这样就能实现记忆独立了。卧槽,听起来还挺像回事儿的,实现起来各种坑。首先就是,agent是通过create_agent方法创建的,这个方法内部的跳转逻辑是,model节点调用工具后会从tool节点再次跳转回model节点,也就是说会带着工具消息再次调用大模型,结果就是你会看到AI输出了两遍相似的内容,大致流程就是用户提问→LLM回答完成→LLM调用工具更新记忆→返回工具调用结果给LLM,LLM又回答一遍。当然你可以写工具提示词让AI不要输出任何内容直接结束对话,我试了下还真行,但是本质上还是多调用了一次大模型,消耗的token是实打实的,而且会让整个对话变慢,这绝不是出路。
更好的做法是在更新记忆的时候同时强制跳转到END节点,不过这也是五十步笑百步罢了,因为本质上调用这个更新记忆的工具就会多花时间,而且这个工具的输入参数还是让大模型自己总结的,这就更花时间了,而且也会多消耗token,还不如自己提取对话历史自己更新,这样又快又不花钱。没错,这才是终极答案。不需要额外的工具,甚至连state里新增的字段也不需要,只要在每次调用完agent之后,把它的message字段存在变量里,然后下次调用的时候把这个变量和最新的问题打包一起传给它就行,这不就是最原始的记忆实现方案吗???果然大道至简。
main_context = []
def call_main_agent(state: MultiAgentState):
nonlocal main_context
# 只取最新的用户消息作为本轮输入
last_human = None
for msg in reversed(state.get("messages", [])):
if isinstance(msg, HumanMessage):
last_human = msg
break
# 构造智能体输入:必须是 字典!!!
agent_input = {
"messages": main_context + ([last_human] if last_human else [])
}
# 调用主 Agent,传入独立上下文
response = main_agent.invoke(agent_input)
main_context = response.get("messages", main_context) # 更新主Agent上下文
return response # 可能是 Command 或普通 state更新上了豆包的大当,但是对langchain,langgraph甚至是langsmith的理解都加深了很多,果然困难能驱动人前进。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)