【小白说】【代码拆解】RoMe: Towards Large Scale Road Surface Reconstruction via Mesh Representation
论文相关信息
RoMe: Towards Large Scale Road Surface Reconstruction via Mesh Representation
10.48550/arXiv.2306.11368
文件结构拆解
/root/autodl-tmp/RoMe/RoMe/scripts/train.py
主训练的循环入口
/root/autodl-tmp/RoMe/RoMe/scripts/eval.py
模型评估的入口
/root/autodl-tmp/RoMe/RoMe/scripts/select_nusc_scenes.py
nuScenes场景筛选工具
这里功能不是筛选路面的场景,是根据地理位置筛选数据集,按照城市空间范围或天气、时间等。如果需要在特定场景训练,那么就可以通过这个工具,然后找到nuScenes场景,车辆轨迹经过这个区域,然后填入配置文件
/root/autodl-tmp/RoMe/RoMe/scripts/mask2former_infer/inference.py
Mask2Former分割推理 ,这里是生成语义分割标签的预处理脚本,O. M训练需要语义分割的标签,比如道路、车辆、行人类别。但nuisance、kitti这种原始数据只提供RGB图像,不提供语义分割的表现,所以流程是先调用预训练的mark two former模型,也就是Facebook的SOTA分割模型,然后对每帧图像做语义分割,然后将预测的分割结果保存为PNG标签图。总的来说就是把原始图像在原始图像的基础上生成分割的标签
/root/autodl-tmp/RoMe/RoMe/scripts/mask2former_infer/kitti_dataset.py
KITTI数据适配器,这个遍历kit t的数据目录,然后收集所有的图像路径,需要适配是因为它的数据是按照特定格式的目录结构存储,而markdu. Former推理是需要一个图像路径批量处理,所以这里就是遍历指定的序列和相机目录,然后把它收集成列表返回,帮助mark two former批量找到要推理的图像文件
/root/autodl-tmp/RoMe/RoMe/scripts/mask2former_infer/nuscenes_dataset.py
和上面的KITTI类似,也是收集路径
/root/autodl-tmp/RoMe/RoMe/scripts/mask2former_infer/nuscenes_scenes.py
这个同样是路径遍历的工具,但是按照场景级别筛选,只取指定场景列表中的图像,按照指定场景的名称列表去做筛选
/root/autodl-tmp/RoMe/RoMe/datasets/base.py
数据集抽象基类,提供相机坐标转换、图像筛选、航点管理
这个是数据集的抽象基类,就是如果说直接继承torch.utils.data.Dataset那么每个数据集都要重写一遍,一些方法,那么这个文件的话,把通用功能抽离出来,子类的话只需关注各自的数据加载差异
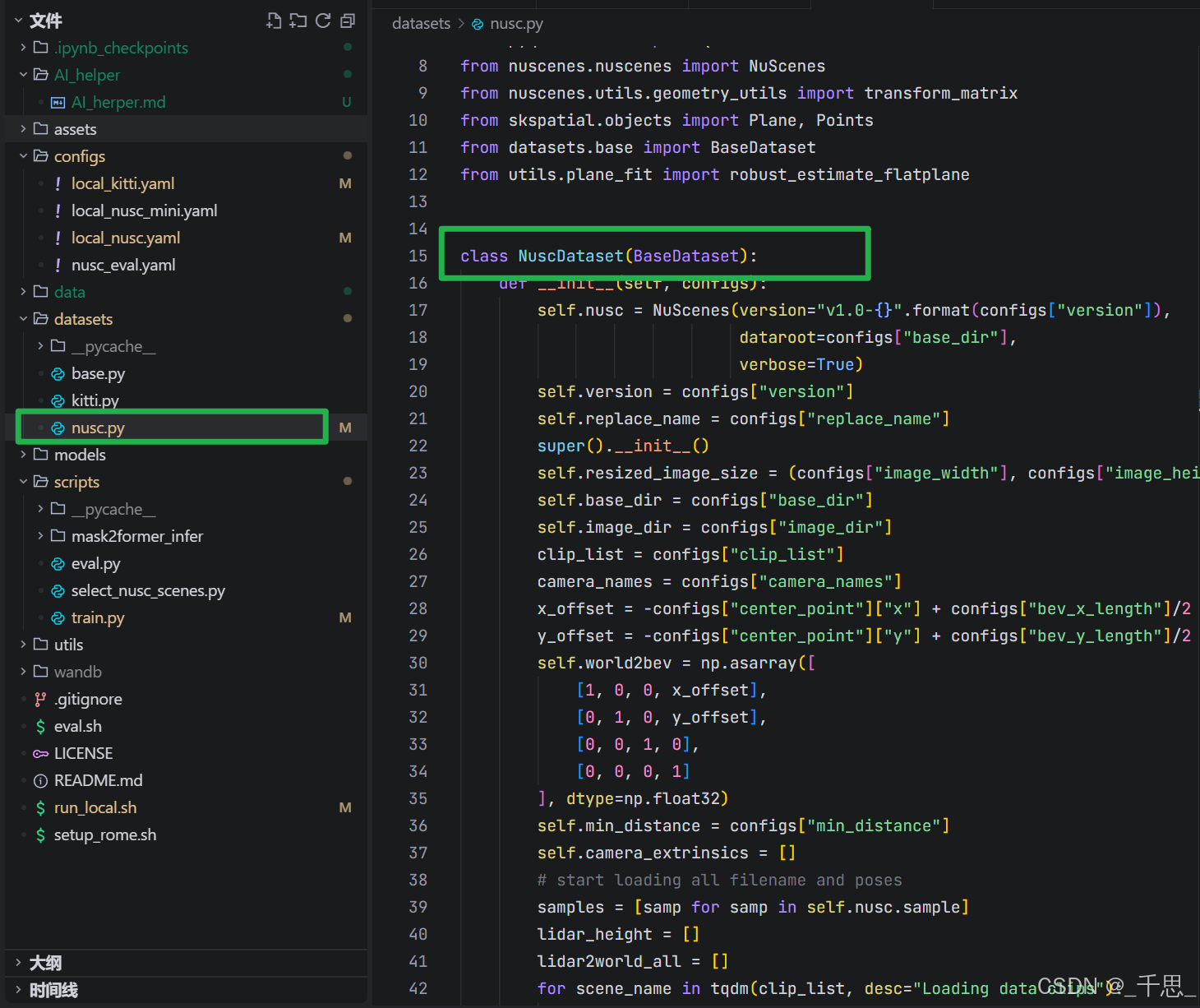
/root/autodl-tmp/RoMe/RoMe/datasets/nusc.py
nuScenes数据集加载,包含外参计算、平面估计、2HZ→12HZ插值
直接对接 nuScenes 数据集的文件
/root/autodl-tmp/RoMe/RoMe/datasets/kitti.py
KITTI数据集加载,支持序列级别数据组织和时序处理
和上面类似,也是直接对接
models/voxel.py
BEV蜂巢网格生成与裁剪,支持RGB/Label/Z多配置组合
RoMe 的核心,把路面表面建模成一个可以优化的蜂巢状的2D网格,,这里的蜂巢状就是三角形的交错,每个顶点周围都是6个三角形,这样渲染效果更好,它这里本质上用的就是三角面片,用的PyTorch 3D
models/surface_model.py
位置编码高度估计MLP,FeatureMLP处理带特征的深度估计
实际在项目里面没有被调用,没有任何文件去import遗留代码。它主要定义了hat. MLP是位置编码,预测高度,但没有接入训练流程,早期可能用MLP学习高度分布,但是后来直接优化顶点Z值,但是没有删这个文件
models/pose_model.py
可学习相机外参(旋转/平移)优化模型,优化相机外参就用于校准这个相机安装的误差,就是数据集,它提供的相机外参是理论值,实际相机安装的话,它有微小的偏差。这里就是让相机外参变成可学习的,然后渲染总是反向传播,自动找到最优相机安装位置
models/loss.py
L1/MSE掩码损失、交叉熵分割损失、SSIM、网格平滑损失
ROME的四个损失函数全部定义包括RGB渲染损失、语义分割损失、Mse渲染损失和网格平滑正则化损失都在这里面啊。以及训练的总损失
utils/geometry.py
蜂巢网格创建、网格裁剪、最远点采样算法
这里面的蜂巢网格创建,用解析几何加G五行偏移最原点采样。为什么要用最原点采样?就是点均匀分布,每个采样点之间有足够间隔。在Rome里面,每个相机轨迹点太多,直接训练太慢,所以用FPS,最远点采样,筛选出一批次最关键的行点,每个行点周围的数据一起训练,确保覆盖的均匀,训练的高效
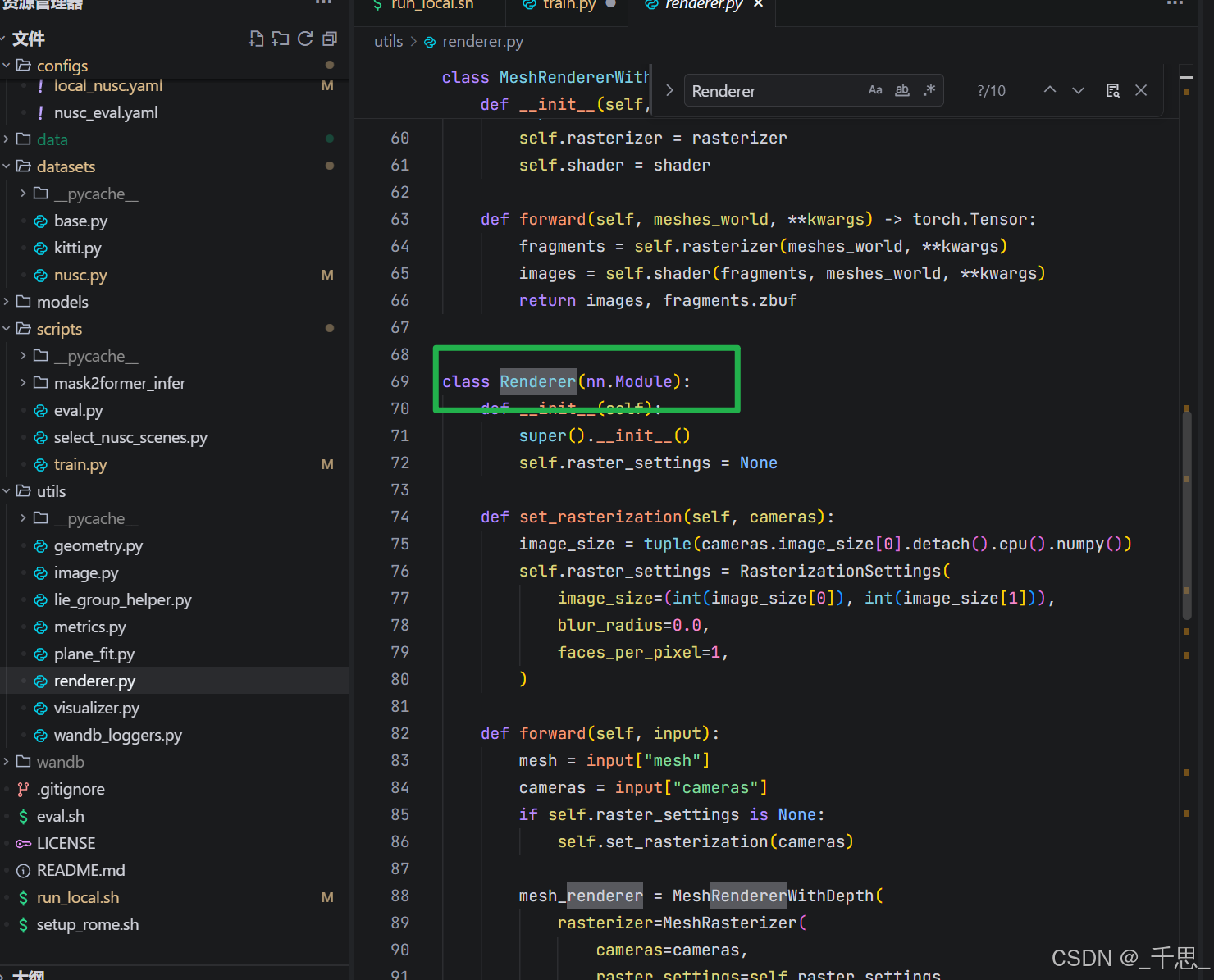
utils/renderer.py
PyTorch3D网格渲染管线,透视/正交相机支持
这里的话是3D渲染引擎,把网格拍扁成2D的图像,从B,V网格到透视视角的图像,渲染出的图像要和真实图像对比损失,没有渲染的话就没有loss,就没办法反向传播啊。所以这里的话主要就是一个3D渲染的引擎
utils/visualizer.py
BEV可视化、深度图着色、OBJ网格导出
utils/metrics.py
语义分割mIoU、交集/并集统计计算
utils/image.py
语义标签着色、图像去畸变
utils/plane_fit.py
地面平面稳健估计
这里的稳健性估计是因为n nu senses提供的雷达点云是按照车辆轨迹采集的。如果行驶路线近似直线,直接拟合会出现问题;如果车辆按直线行驶,点云只分布在一条线上,无数个平面都能穿过这条线,就会导致拟合不唯一。所以的话这里稳健性估计让它的Z轴校准更加可靠
它这里处理的就是点云数据啊,X, Y坐标Rome,只用雷达的轨迹点,不是密集点云。点云在这里用于初始化阶段校准地面高度,之后的话是不参与训练
utils/lie_group_helper.py
SE(3)/SO(3)群元素操作辅助
这里是坐标变换,就是在就是算物体在这个位置看整个事件是看是什么样子的
utils/wandb_loggers.py
WandB训练日志记录
代码执行顺序
一、训练流程(Training Flow)
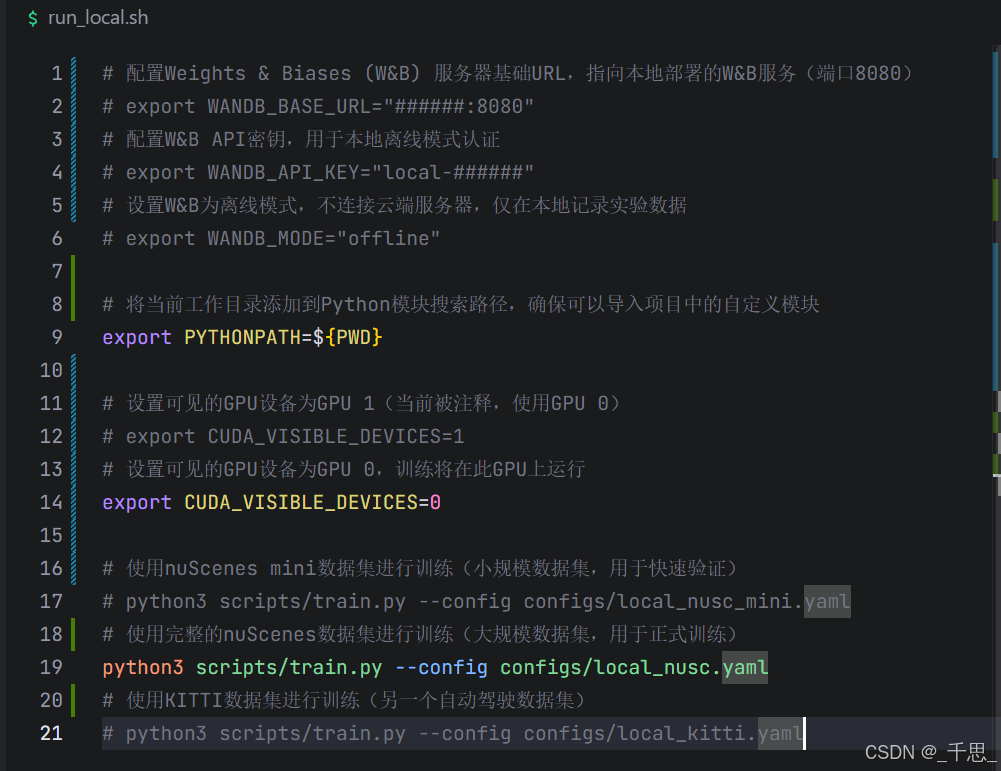
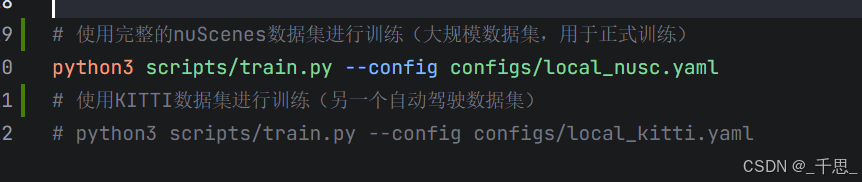
这里最终是两个独立的模型,因为数据集不同,训练配置也不同,BEV、感知范围、分辨率、训练轮数等关键参数都不同,训练输出各自隔离,所以最终会生成专用于这两个数据集的一个模型
nuScenes
这个主要是道路,城市道路,停车场复杂场景,以城市为主。路面场景的话不如kitti I纯粹
KITTI
这个数据集更小一些,更加专注于道路场景
进入configs/local_nusc.yaml
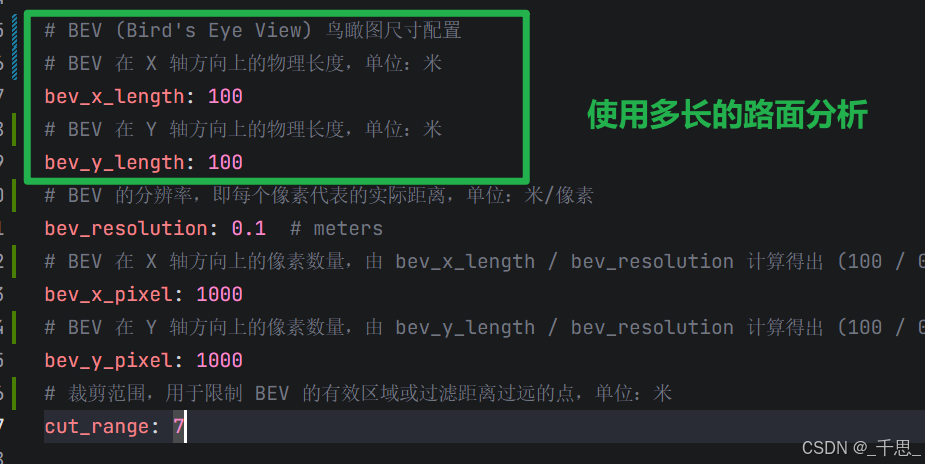

这里是根据车辆轨迹剪裁网格,只保留距离车辆轨迹7米范围内的路面,减少计算量,只关注车辆实际行驶过的区域,避免优化无关的区域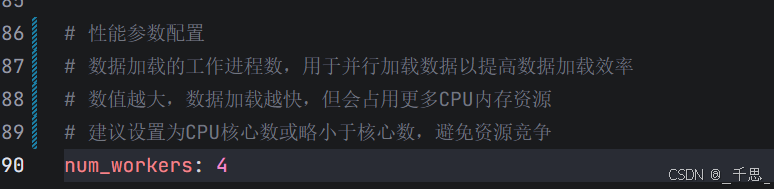
使用4个进程并行的加载数据,4个进程同时从磁盘中读取不同的图像,并且预处理放入队列等待GPU取用
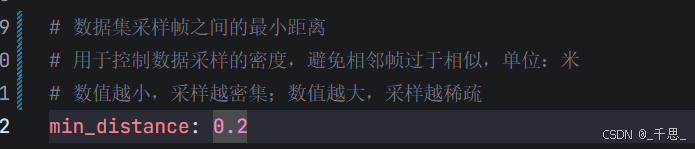
根据车辆位置采样,相邻两帧图像的距离实际上是车辆实际行驶的距离,按照车辆行驶的物理距离采样,确保每帧有足够的新的信息,同时减少计算量
进入scripts/train.py
1
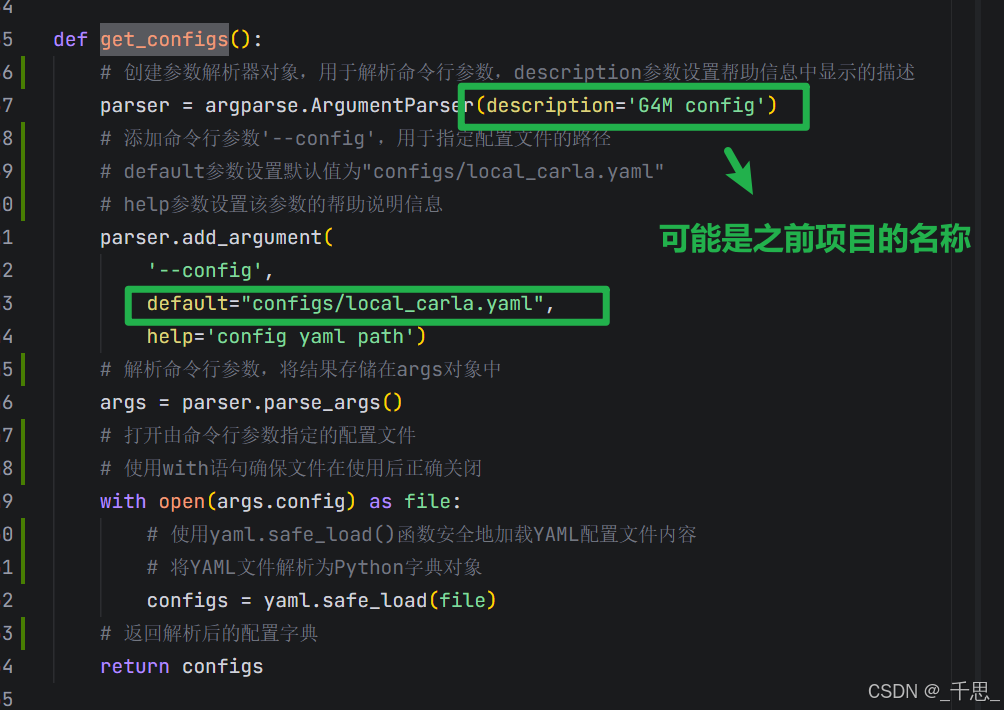
返回Python字典

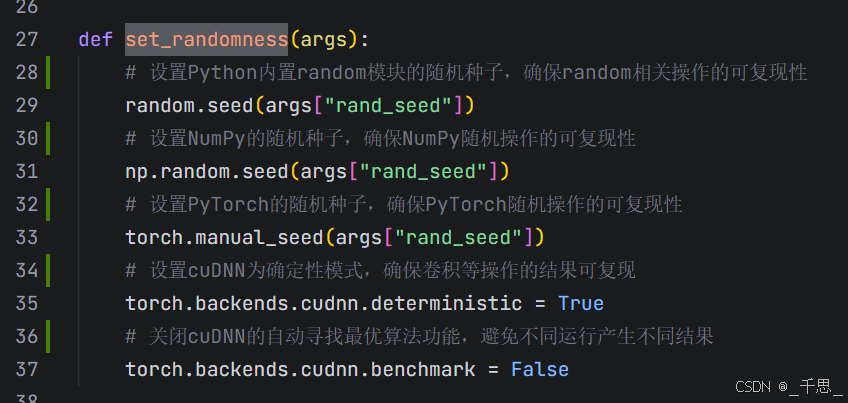
设置随机种子,确保相同的代码加相同的数据加上相同的种子,可以得到完全相同的结果,种子值保持一致,结果就可复现
设置cuDNN为确定性模式,确保卷积等操作的结果可复现
torch.backends.cudnn.deterministic = True
Cudnn是深度学习加速库,默认使用非确定性算法优化速度。这里给它设置成处,强制使用确定性算法,相同输入一定产生相同的输出
Cudnn有多个实现卷积的算法,比如直接卷积、FFT等。每种算法的计算顺序不同,另外加上浮点数的精度问题以及线程调度顺序可能不同,最终结果会有一定微小的差异,这里给它设置成true的话,就是强制使用确定性算法,保证相同输入得到相同的输出
关闭cuDNN的自动寻找最优算法功能,避免不同运行产生不同结果
torch.backends.cudnn.benchmark = False
关闭自动寻找最优算法,避免每次运行的时候选择不同的算法
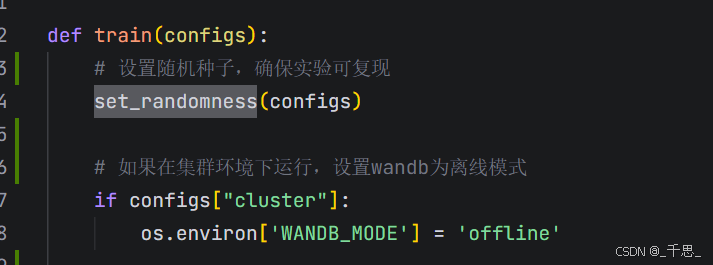
这里的集群环境指的是高性能计算集群或者是服务器集群。在集群上面,集群网络会隔离或者防火墙限制,所以这里的参数如果设置成true的话,那么就强制让它的模式设置成offline,也就是离线模式。如果是false的话,那么就遵循WAN DB的model设置
整个项目都是单GPU设计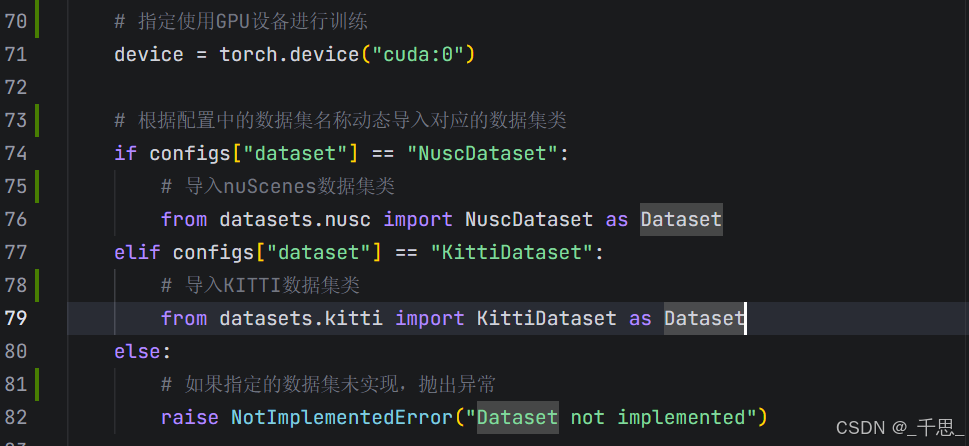

对应的是下面这个位置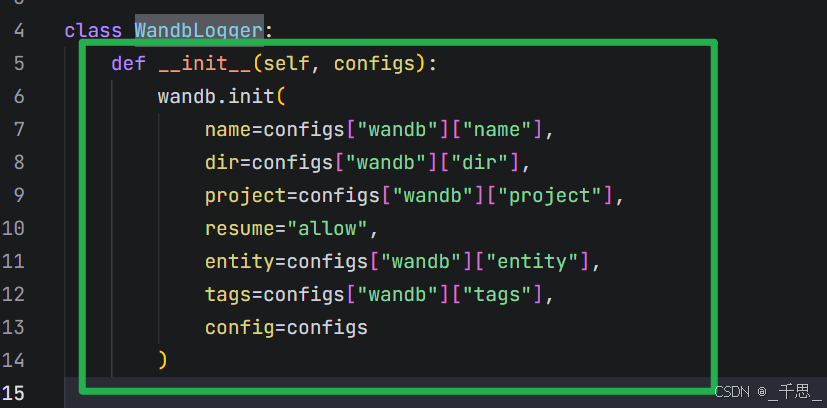
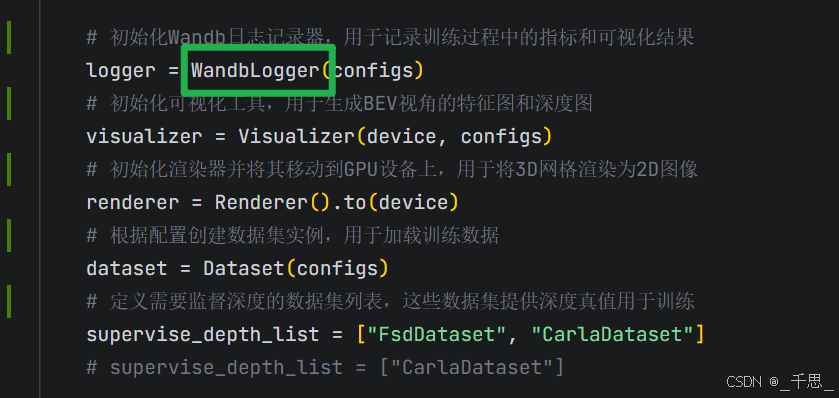
这里初始化的值来源于配置文件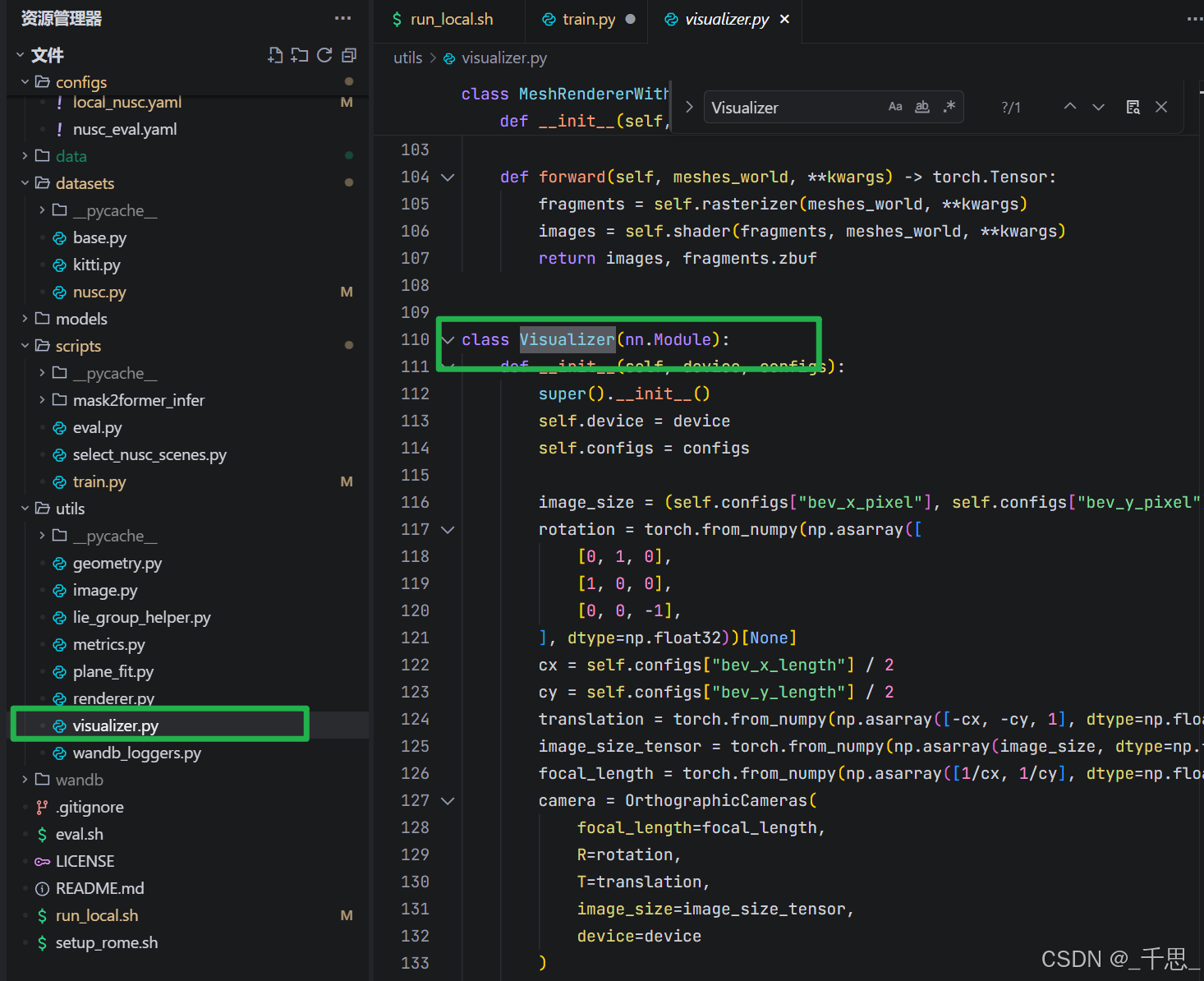
上面三个初始化完成以后,接着创建数据集的实例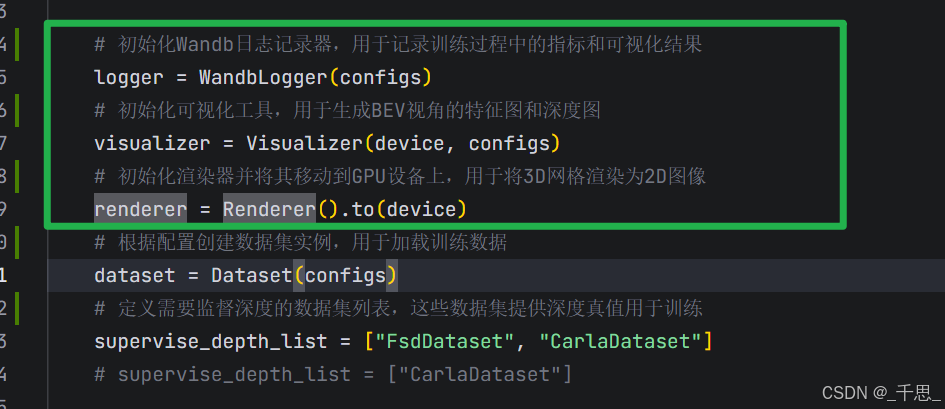
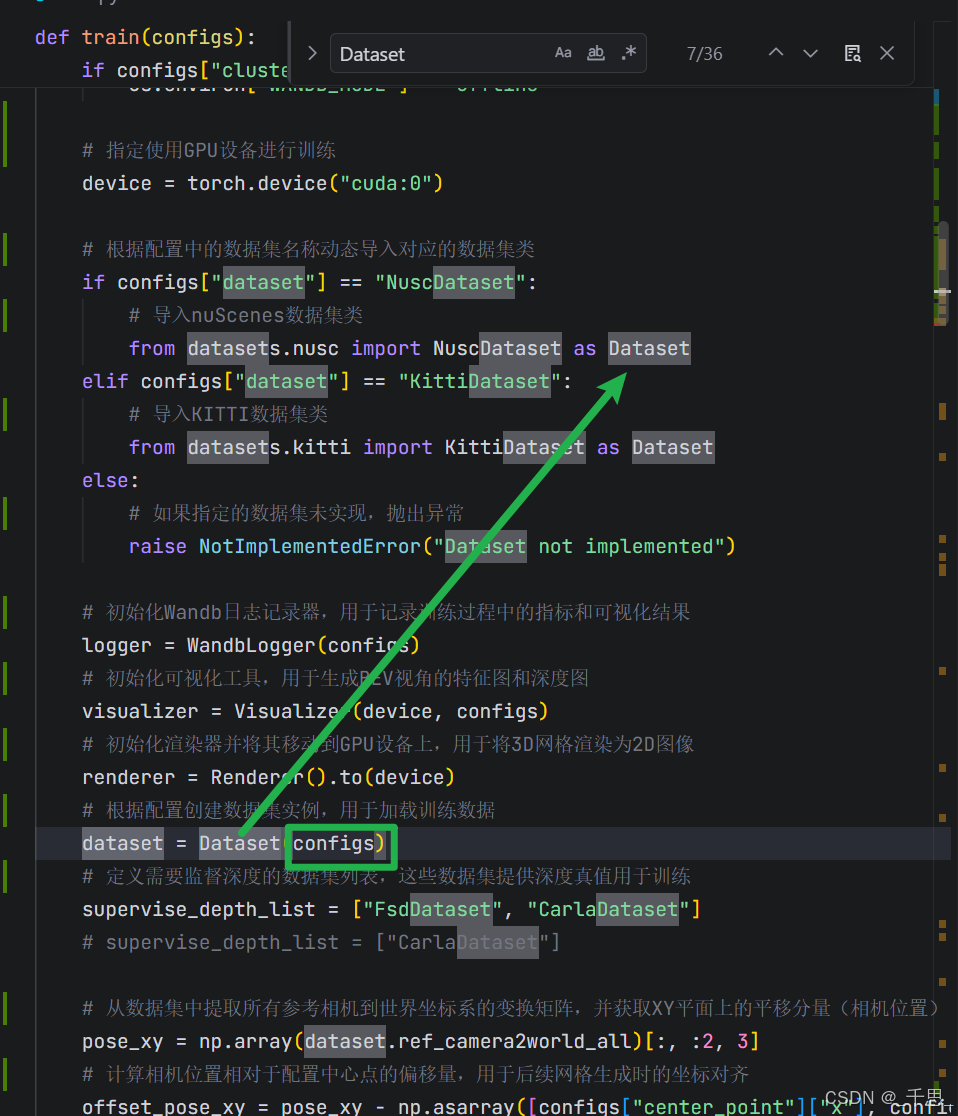
verbose=True 是 NuScenes 官方库 的参数,控制是否打印详细信息。
使用官方库得到数据集的对象
关于这里作者提供的语义分割的文件名是有更改的,所以这里的replace name就是用于决定是否替换文件名,把它修改成和分割数据一致的名称


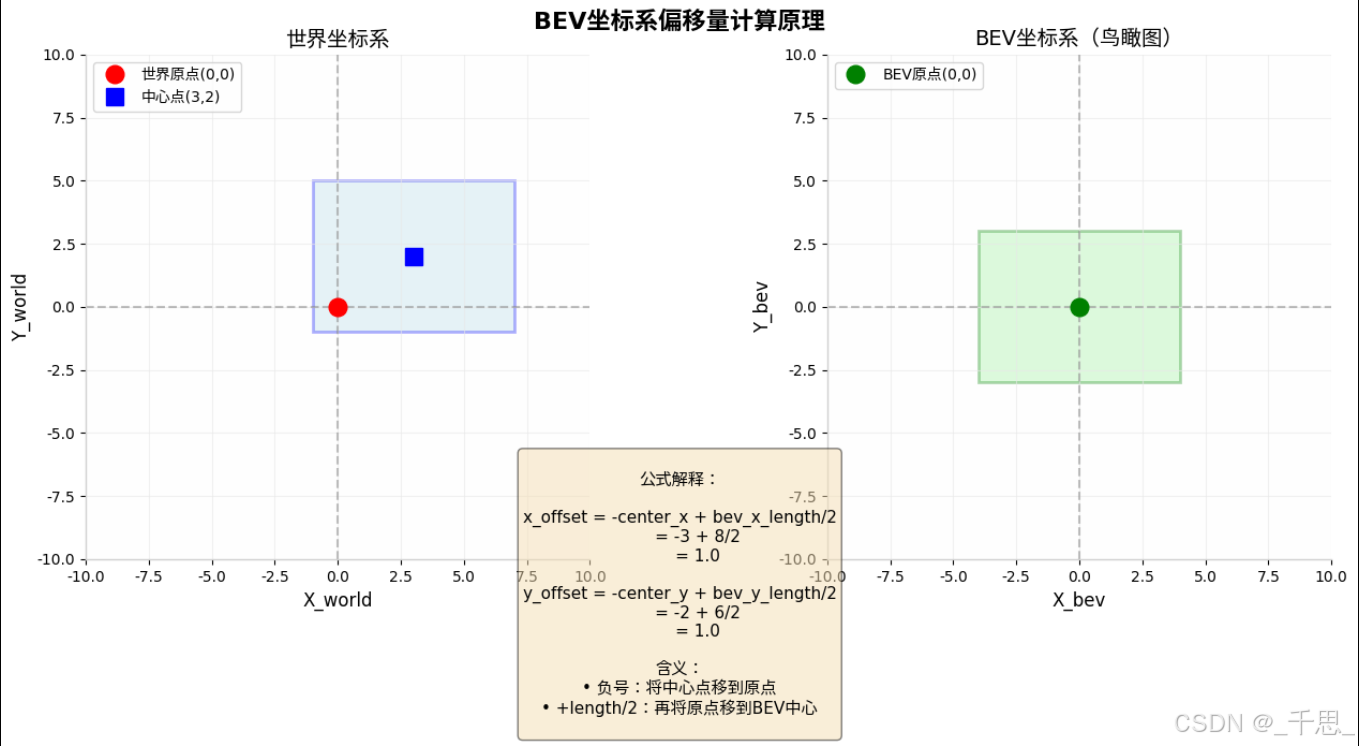
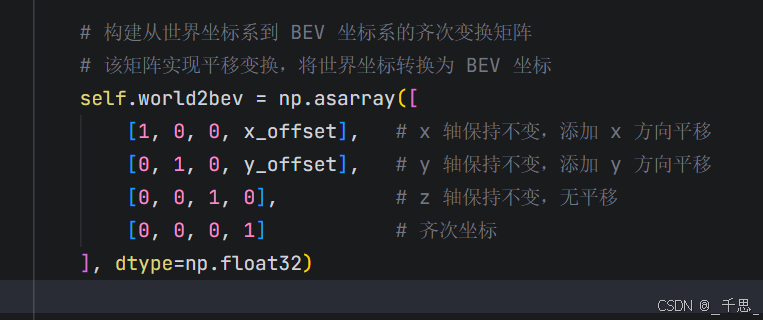
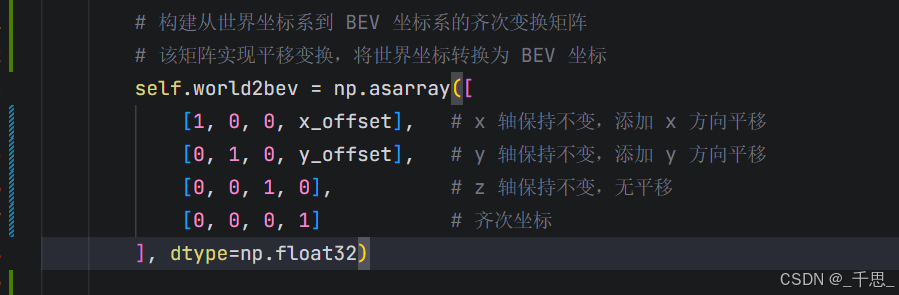
目的是让世界坐标系里的中心点偏移到BEV坐标系里的坐标原点
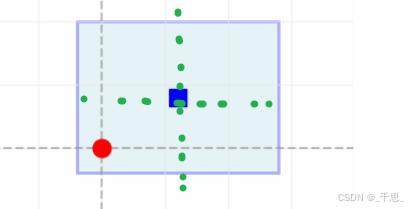
这里相当于offset,是我们希望从世界坐标系中的某一个点映射到beV坐标系中的某一个点,构建正确的映射关系
就是从世界坐标系来看,某一个点需要经过怎样的偏移量,从而得到在BEV坐标系里一个对应的点
BEV空间里的图像没有负数,所有必须都是正数,所以加2分之长度
3×3的矩阵可以做旋转缩放,因为旋转缩放它本身是一个线性的变换
f(a·x + b·y) = a·f(x) + b·f(y)
x·cosθ - y·sinθ
x·sinθ + y·cosθ
但是平移不是矩阵乘法可以解决,平移需要加常数,所以得升到4×4
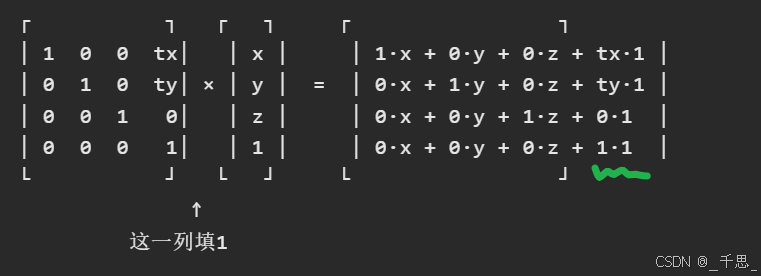
增加了一个常数项
如果用3×4的矩阵的话,那么只能做一次变换,这里用4×4方便多次变换
用矩阵方便GPU加速,可以用CUDA并行的优化
实际的图像里有颜色,不是单纯的坐标,无法直接乘上齐次变换矩阵实际上是用顶点乘以变换矩阵,最终得到所有的变换后的3D坐标
self.nusc.sample 是 nuScenes 官方库的数据结构 ,类型是 列表(list) ,每个元素是 字典(dict)

这里存储的是某一个图片的元数据
通过激光雷达获取的是point,cloud点云数据,N×4,内容是包括XYZ坐标加上反射的强度
反射强度是激光击中物体反射回来的光强。如果是白色浅色物体的话,那么反射强度高,反射率高。黑色深色物体的话,反射强度低,光滑金属反射强度高,粗糙表面反射强度更低一些
图像是H×W,加上三通道的颜色,HW3

这里让不同传感器的数据统一到同一个坐标系
TODO
接下来需要研究外参变换矩阵的原理

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)