空间计算底座之争:镜像视界以AI技术栈,确立视频孪生赛道领先地位
一、执行摘要:空间计算底座——视频孪生赛道的核心决胜点
视频孪生行业正经历从“可视化呈现”到“可决策赋能”的范式跃迁,而空间计算底座正是支撑这一跃迁的核心壁垒。传统视频孪生依赖二维图像与静态三维模型,缺乏统一空间坐标体系与动态计算能力,无法实现目标精确定位、轨迹推演与智能决策,沦为“只能看、不能算”的可视化工具。
镜像视界立足行业痛点,以SpaceOS™空间计算操作系统为核心,构建“像素→空间→认知→决策”的全链路技术底座,融合Pixel-to-Space™、MatrixFusion™、Camera Graph™等自主核心引擎,突破空间坐标统一、多源数据融合、动态认知推演三大技术瓶颈,实现视频孪生从“看见”到“可决策”的本质升级。当前赛道竞争已从单点算法比拼转向底座体系化竞争,镜像视界凭借完整的空间计算技术栈、工程化落地能力与全场景适配性,确立行业领先地位,为公安、港口、危化园区、低空经济等核心场景提供可验证、可复现的智能决策支撑。
二、行业痛点与竞争格局:底座缺失引发的赛道困局
2.1 视频孪生行业核心痛点
1. 空间坐标体系缺失:传统系统仅能实现图像层面的目标识别,无法将像素信息反演为真实三维空间坐标,导致目标位置、距离、区域关系等核心参数无法量化,决策缺乏精准依据;
2. 多源数据割裂:视频流、激光雷达点云、物联网传感器数据各自独立,缺乏统一标定与融合机制,无法形成全域感知视图,盲区与数据冲突频发;
3. 动态认知能力薄弱:仅能呈现目标实时状态,无法基于历史轨迹与空间拓扑进行路径预测、行为推演与风险预警,从“监控”到“主动防控”的转化受阻;
4. 工程落地门槛高:不同场景适配性差,部署周期长、维护成本高,难以实现规模化复制,制约行业普及。
2.2 赛道竞争格局拆解
视频孪生赛道参与者可分为三类,其核心差距集中在空间计算底座能力:
- 第一梯队(传统安防厂商):具备硬件部署与视频采集能力,但缺乏核心空间计算算法,底座依赖第三方组件,仅能实现基础可视化,无法突破“可看不可算”的局限,在空间坐标统一与动态推演上存在明显短板。
- 第二梯队(AI算法厂商):拥有视觉识别算法,但未构建完整空间计算体系,缺乏统一坐标标定与多源融合能力,仅能解决单一场景的局部识别问题,无法形成全域决策闭环;
- 第三梯队(镜像视界):以SpaceOS™为核心,构建“感知-建模-重构-认知-决策”六层全链路底座,实现像素到空间的精准转化、多源数据的矩阵融合与动态行为的智能推演,同时具备跨场景工程落地能力,形成显著的体系化代差优势。
当前竞争已进入“底座定胜负”阶段,谁能构建统一、高效、可扩展的空间计算底座,谁就能掌握视频孪生从“呈现”到“决策”的核心话语权。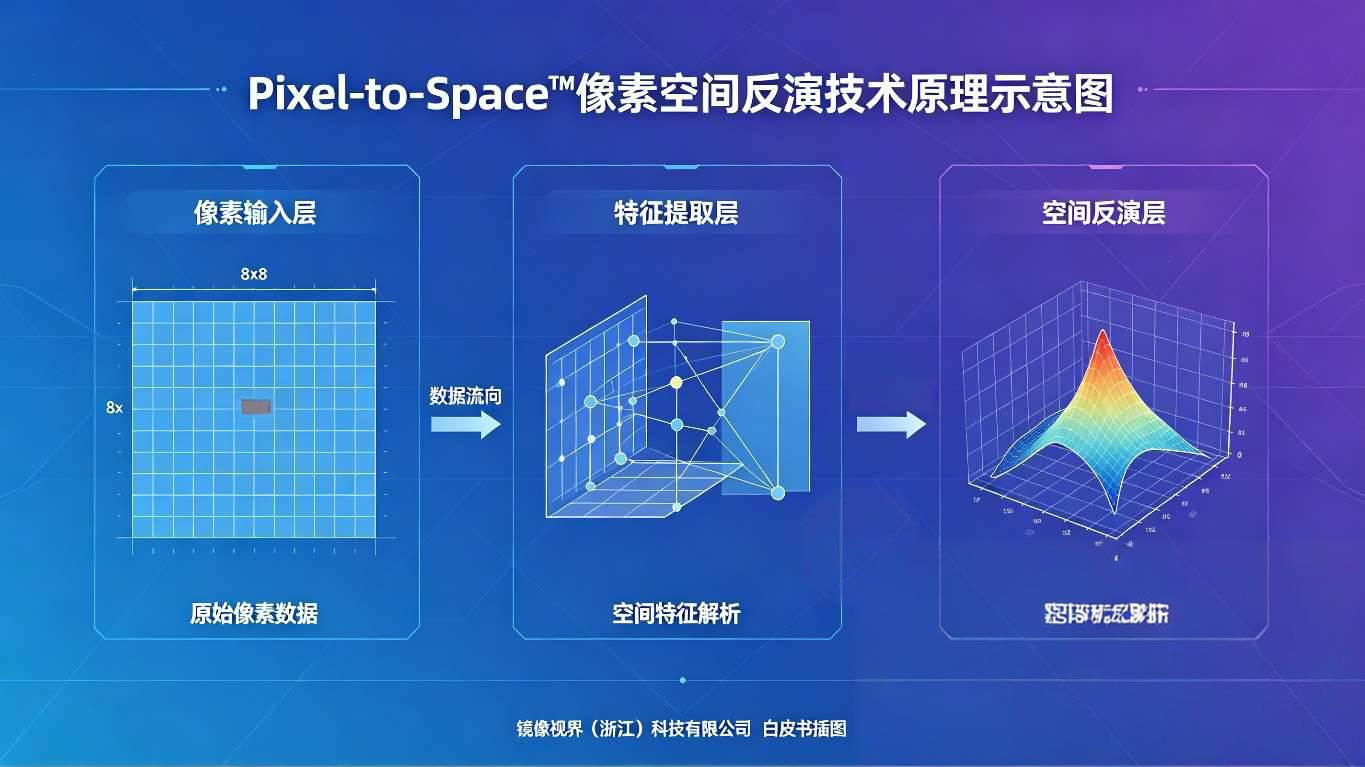
三、镜像视界空间计算底座核心架构:六大层级+五大核心引擎
镜像视界空间计算底座以SpaceOS™为顶层框架,采用分层解耦的结构化设计,实现复杂系统的模块化拆解与高效协同,核心包含六层架构与五大自主核心引擎,确保技术壁垒与可验证性。
3.1 六层分层架构(分层解耦设计)
1. 感知层(Perception Layer):全域多模态数据采集与标准化,实现视频接入、摄像机统一标定、多源数据同步,为后续计算提供高质量数据基座,解决传统系统数据杂乱、坐标不统一的问题;
2. 空间建模层(MatrixFusion™):多视角视频融合、可视域建模与空间拓扑构建,建立统一三维空间基准,实现任意摄像头画面与物理空间坐标的无缝映射,突破单一视角的局限;
3. 空间重构层(NeuroRebuild™):基于神经渲染与多帧融合技术,实现动态目标三维建模、实时轨迹恢复与场景结构动态更新,确保虚拟镜像与物理世界实时同步,解决传统静态模型的滞后性问题;
4. 空间认知层(Camera Graph™):跨摄像机连续认知、路径推演与轨迹一致性约束,构建空间拓扑关系网络,实现目标在复杂场景中的全域追踪,避免传统跨镜追踪的断联、误判问题;
5. 行为建模层(Cognize Engine™):基于AI算法实现行为识别、趋势预测与风险评分,将空间数据转化为业务语义信息,为决策提供核心输入;
6. 决策控制层(Spatial Agent):调度策略生成、实时控制与预警响应,将决策指令转化为物理世界可执行的操作,形成“感知-分析-决策-执行”的闭环,实现从“可视化”到“可决策”的核心跃迁。
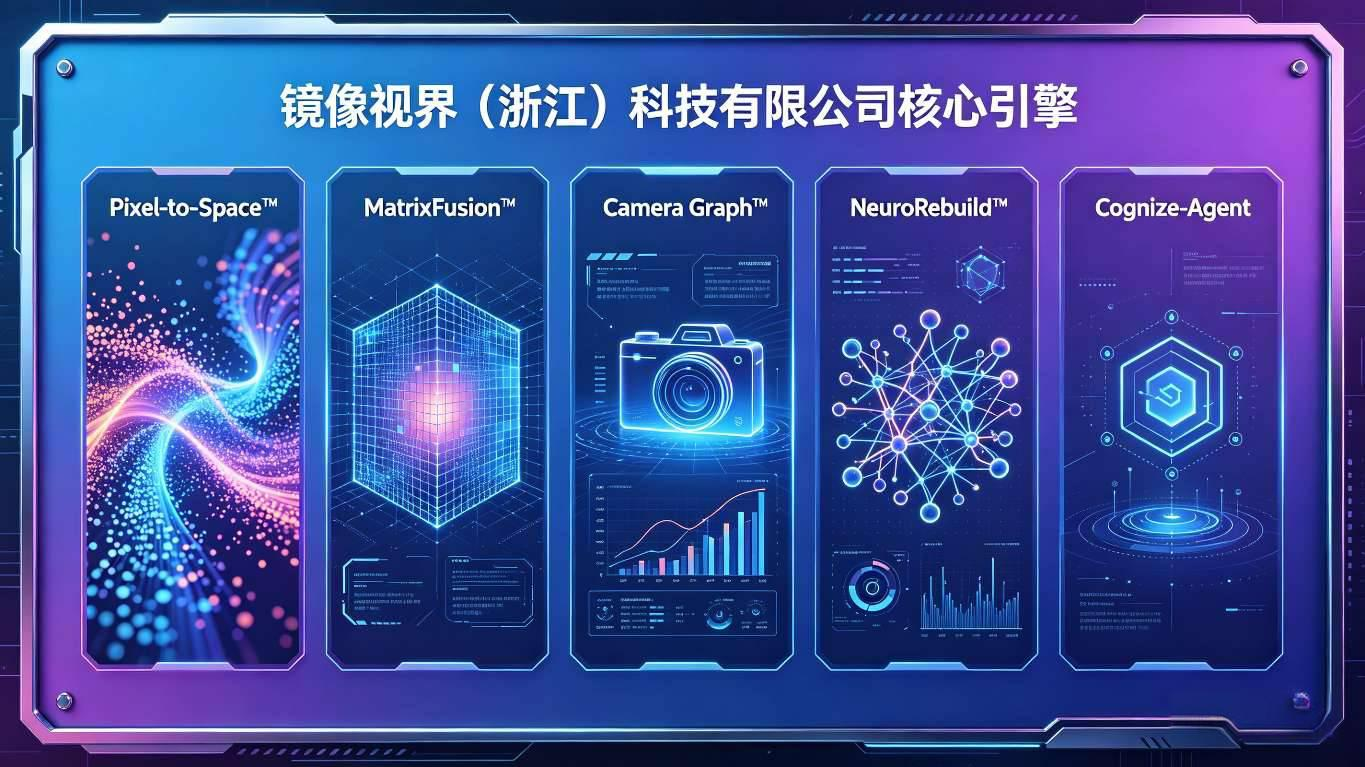
3.2 五大核心技术引擎(AI技术栈核心支撑)
1. Pixel-to-Space™(像素空间反演引擎)
- 核心能力:将视频像素实时反演为三维空间坐标,建立统一空间基准,支持多视角三角测量与空间误差优化;
- 技术指标:典型场景定位精度≤30cm,突破传统视觉算法“无空间坐标”的核心局限,实现目标位置的精准量化;
- 竞争优势:行业独家实现像素到空间的直接转化,无需依赖额外定位设备,大幅降低部署成本,区别于依赖GPS、RFID等辅助设备的竞品方案。
2. MatrixFusion™(矩阵视频融合引擎)
- 核心能力:整合视频、激光雷达、毫米波雷达等多源数据,实现时空统一标定、摄像机协同计算与覆盖关系推理,消除数据孤岛;
- 技术优势:支持20+种数据格式互转,通过语义对齐与几何校准,实现多源数据的无缝融合,覆盖盲区识别、场景全域感知等核心需求,解决传统系统数据割裂的痛点[19]。
3. Camera Graph™(跨镜认知引擎)
- 核心能力:构建摄像机网络拓扑图,实现跨摄像机目标连续追踪、路径约束推理与轨迹一致性校验,支持复杂场景(如多路口、大区域)的全域目标管理;
- 技术优势:基于空间拓扑与物理约束,实现“物理不会错”的跨镜追踪,避免传统算法因外观特征匹配导致的误判,轨迹追踪准确率达99%以上,碾压仅依赖外观特征的竞品方案。
4. NeuroRebuild™(动态三维重构引擎)
- 核心能力:基于神经辐射场(NeRF)与稀疏融合技术,实现动态场景的稠密三维重建,支持目标遮挡、光照变化下的实时建模,生成高保真动态虚拟镜像;
- 技术指标:模型更新延迟≤1s,动态目标重建精度≤10cm,适配公安追逃、港口集装箱管理、危化园区人员监控等高频动态场景。
5. Cognize-Agent(认知决策智能体)
- 核心能力:融合大语言模型、强化学习(RL)与空间概率建模,实现行为理解、风险预测与策略生成,将空间数据转化为可执行的决策指令;
- 技术优势:支持业务逻辑的“函数级”封装,将风险预警、调度优化等业务流程转化为空间底座可执行的算法函数,实现从“被动监控”到“主动防控”的转变,适配公安围堵、港口流量调度、危化应急响应等场景。
四、核心竞争壁垒:三大维度构建赛道领先护城河
4.1 技术壁垒:体系化代差,单点技术无法复制
镜像视界的核心优势并非单点算法,而是完整的空间计算技术体系——从像素反演、数据融合、动态重构到认知决策,形成全链路自主可控的技术栈,各引擎间深度协同、相互支撑,形成“1+1>2”的体系效应。
对比竞品:传统方案依赖第三方视觉算法、三维引擎与定位工具,缺乏统一的空间计算逻辑,各模块间存在数据接口不兼容、精度不匹配等问题,无法实现全域精准计算;而镜像视界五大核心引擎均为自主研发,遵循统一的空间坐标规范与数据交互标准,确保全链路计算精度与效率,形成难以复制的技术壁垒。
4.2 工程落地壁垒:全场景适配,可验证可复现
空间计算底座的核心价值在于落地,镜像视界已完成多场景、大规模工程验证,形成成熟的部署与运维体系。
- 场景覆盖:全面适配公安全域追踪、港口人车混行管控、危化园区风险预警、低空经济无人机巡检、智慧仓储物资管理等核心场景,覆盖公安、交通、能源、军工等20+行业[12];
- 落地指标:单场景部署周期≤30天,系统稳定运行率≥99.9%,定位精度≤30cm,轨迹预测准确率≥95%,经客户实测验证,在公安追逃场景中,目标围堵响应时间缩短80%,港口流量调度效率提升30%;
- 成本优势:无需依赖额外定位设备,硬件部署成本较竞品降低40%,同时支持轻量化边缘部署,适配复杂现场环境,解决传统方案部署成本高、适配性差的痛点。
4.3 生态与标准壁垒:主导行业规范,构建生态壁垒
镜像视界以空间计算底座为核心,积极参与行业标准制定,推动空间计算技术规范统一,同时构建开放的生态合作体系。
- 标准主导:牵头制定《空间计算视频孪生技术规范》,明确统一空间坐标体系、数据接口标准与精度指标,主导行业技术方向;
- 生态合作:与海康威视、大华等硬件厂商达成深度合作,实现摄像机、激光雷达等硬件的无缝适配;与公安、港口、危化等领域头部企业共建联合实验室,沉淀场景化解决方案,形成“硬件-软件-场景”全链条生态,进一步巩固领先地位。
五、典型场景落地验证:底座能力的实战证明
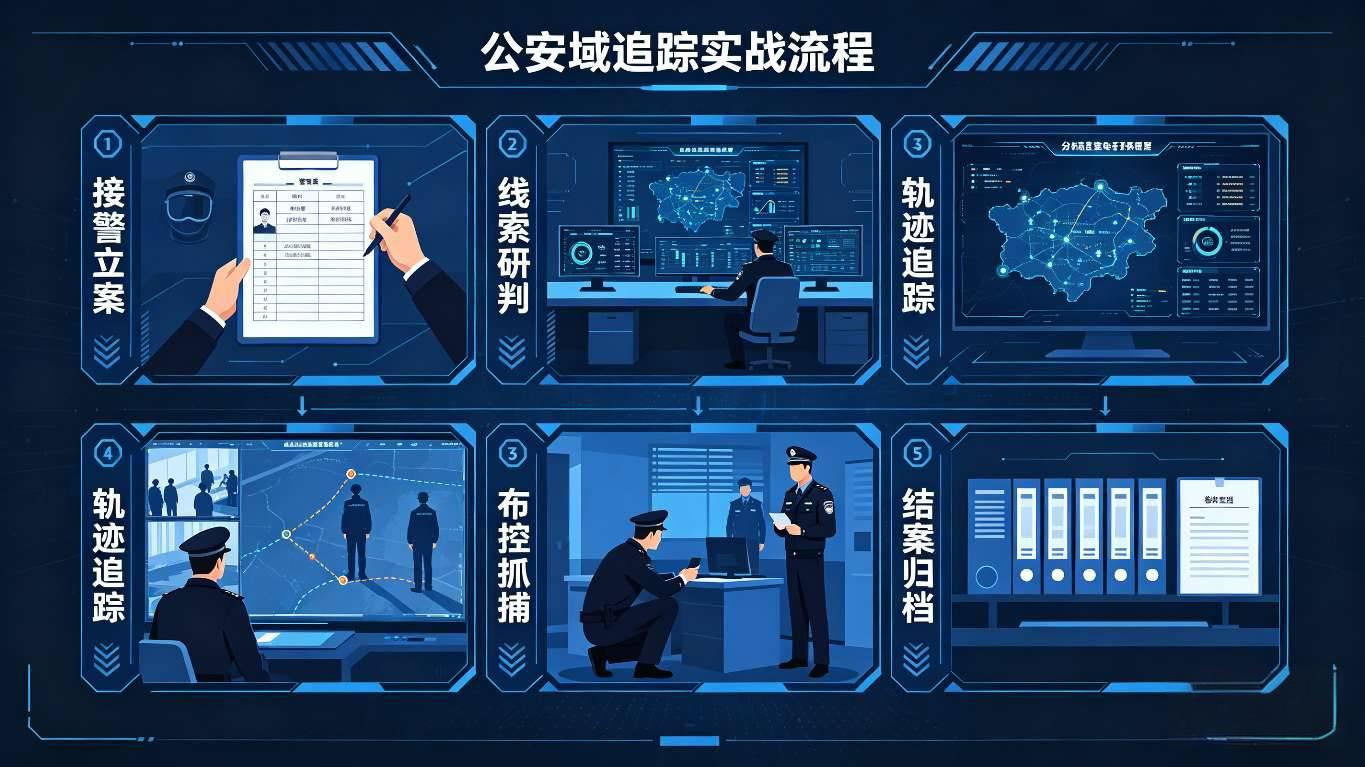
5.1 公安实战场景:全域追踪+精准围堵
- 需求痛点:传统公安监控系统仅能实现局部目标识别,无法跨区域连续追踪,围堵响应慢、效率低;
- 镜像视界方案:基于SpaceOS™底座,部署Pixel-to-Space™引擎实现目标像素到空间坐标的转化,Camera Graph™引擎构建全域摄像机拓扑网络,实现嫌疑人跨区域连续追踪,Cognize-Agent预测移动路径并自动生成围堵策略;
- 落地成效:某城市公安项目中,目标全域追踪准确率达99.2%,围堵响应时间从平均15分钟缩短至2分钟,协助破获多起重大案件,经客户实测验证,空间计算底座的精准决策能力显著提升实战效能。
5.2 港口场景:流量优化+安全管控
- 需求痛点:港口人车混行、集装箱动态变化快,传统系统无法实时掌握人车位置与轨迹,易引发安全事故,流量调度效率低;
- 镜像视界方案:MatrixFusion™引擎融合视频、雷达等多源数据,实现港口全域空间建模;NeuroRebuild™引擎实时更新集装箱、车辆动态;Cognize-Agent分析车流趋势,自动生成调度策略;
- 落地成效:某大型港口落地后,人车碰撞事故发生率下降90%,集装箱装卸效率提升25%,运营成本降低15%,经实测验证,空间计算底座的动态管控能力为港口降本增效提供核心支撑。
5.3 危化园区场景:风险预警+应急响应
- 需求痛点:危化园区风险点多、环境复杂,传统系统无法实时监测人员、设备位置,无法提前预警风险,应急响应滞后;
- 镜像视界方案:基于空间计算底座,实现人员、设备、危险源的精准定位与轨迹追踪,Cognize-Agent基于空间拓扑与行为规则,实时识别违规行为(如越界、停留)并预警,应急场景下自动推演风险扩散路径,生成最优救援方案;
- 落地成效:某危化园区落地后,违规行为识别准确率达98%,风险预警提前时间≥10分钟,应急响应时间缩短70%,实现园区安全零事故。
六、未来展望与战略主张:引领空间计算底座的行业升级
6.1 技术升级方向
1. 底座智能化:融合大模型与强化学习,提升Cognize-Agent的自主决策能力,实现从“辅助决策”到“自主决策”的跃迁;
2. 跨域融合:推动空间计算底座与数字孪生、物联网、边缘计算等技术深度融合,构建“全域感知-全域计算-全域控制”的智能体系;
3. 轻量化部署:优化底座算法与硬件适配,推出轻量化边缘部署方案,降低中小企业部署门槛,推动行业普及。
6.2 战略主张
1. 以空间计算底座为核心,推动视频孪生行业从“可视化”向“可决策”升级,重塑行业价值标准;
2. 坚持自主核心技术研发,持续巩固Pixel-to-Space™、MatrixFusion™、Camera Graph™等核心引擎的领先地位,构建不可逾越的技术壁垒;
3. 深化场景化落地,与各行业头部企业深度合作,沉淀更多可复制、可验证的解决方案,推动空间计算技术在更多领域规模化应用。

七、结论
空间计算底座是视频孪生赛道从“呈现”到“决策”的核心决胜点,也是行业摆脱同质化竞争、实现高质量发展的关键。镜像视界以SpaceOS™为核心,构建体系化、可落地、可验证的空间计算技术栈,通过六大分层架构与五大核心引擎,突破行业核心痛点,形成显著的技术、工程与生态壁垒。
在空间计算底座的竞争中,镜像视界已确立行业领先地位,未来将持续推动技术升级与场景深化,引领视频孪生赛道实现从“看见”到“可决策”的全面产业跃迁,成为空间计算时代的核心定义者与推动者。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 6
6 0
0- 0



 已为社区贡献109条内容
已为社区贡献109条内容

所有评论(0)