OpenClaw、Skills-高频面试题
写在前面
🔥我把后端Java面试题做了一个汇总,有兴趣大家可以看看!这里👉
⭐️在反复复习面试题时,我发现不同资料的解释五花八门,容易造成概念混淆。尤其是很多总结性的文章和视频,要么冗长难记,要么过于简略,导致关键知识点含糊不清。
⭐️为了系统梳理知识,我决定撰写一份面试指南,不只是简单汇总,而是融入个人理解,层层拆解复杂概念,构建完整的知识体系。我希望它不仅帮助自己更自信地应对面试,也能为同行提供清晰、实用的参考。
OpenClaw、Skills相关面试题
⾯试官:什么是 OpenClaw?(高频)
候选人:
OpenClaw 是一个开源的、可自托管的自主 AI Agent 框架。它能让 AI Agent 持续运行、跨会话记住上下文,并对外部服务执行操作,而且所有数据都跑在你自己的机器或服务器上,不依赖第三方云平台。
用一句话概括:OpenClaw 不是聊天机器人,而是一个 7×24 小时不间断工作、能主动行动的 AI 助手操作系统。
它的本质是一个本地网关进程,连接你日常使用的各种消息平台(飞书企微、WhatsApp、Slack 等),并把每一条消息路由给一个由 LLM 驱动的 Agent 来处理和回复。
⾯试官:OpenClaw 核心亮点是什么?(高频)
候选人:
OpenClaw 有以下几个核心亮点:
① 模型无关(Model-Agnostic)
支持接入任意 LLM:Claude、GPT、Ollama、本地模型等,切换模型无需改代码。
② 数据完全自主
所有记忆和上下文都存储在本地 Markdown 文件里,不需要第三方数据库,除非你主动配置,否则数据不会离开你的机器。
③ 多平台消息接入
已集成 50+ 个消息渠道和服务,从 WhatsApp、飞书企微 到智能家居设备都支持。
④ 主动行动,而非被动回复
内置心跳(Heartbeat)系统,每隔一定时间自动检查任务列表并主动执行,Skills 可以监控网站、发通知、处理邮件、管理日历,全程不需要你手动输入任何命令。
⑤ 社区生态丰富
已积累 163,000 GitHub Stars,ClawHub 上有 5,700+ 个社区贡献的 Skills(技能包)。
⾯试官:OpenClaw 文件目录结构是怎样的?
候选人:
OpenClaw 的智能体本质上就是一个普通的文件夹。采用纯文本 Markdown 文件来管理 Agent 的各种"设定"。典型的目录结构如下:
~/.openclaw/workspace/
├── AGENTS.md # Agent 的启动规则、操作手册(决定了它怎么做事)
├── SOUL.md # Agent 的人格、语气、价值观(决定了它怎么说话)
├── TOOLS.md # 环境配置(SSH Host、摄像头ID等)
├── HEARTBEAT.md # 定时任务指令(每次心跳时间一到,系统会优先读取里面的任务清单)
├── MEMORY.md # 长期记忆(铁律级别的规则)
└── sessions/
├── 2026-03-10.md # 每日会话日志
└── 2026-03-11.md # 每日会话日志
这些文件都存放在 Agent 工作区里,MEMORY.md 保存持久的长期记忆,每日的 sessions/YYYY-MM-DD.md 则是当天的运行日志,每次会话启动时会自动加载今天和昨天的日志。
⾯试官:OpenClaw 与传统 Agent 有什么区别?(高频)
候选人:
传统 Agent 框架(如 LangChain、AutoGPT)更像是一个"工具库",需要开发者自己搭建流程;而 OpenClaw 更像是一个"已经装好的 Agent 操作系统",核心差异体现在以下几点:
| 对比维度 | 传统 Agent | OpenClaw |
|---|---|---|
| 运行方式 | 按需调用,用完即停 | 持久守护进程,7×24 运行 |
| 记忆能力 | 会话结束即遗忘 | Markdown 文件持久化记忆 |
| 主动性 | 被动等待指令 | 心跳机制主动执行任务 |
| 消息渠道 | 通常只有一个入口 | 同时接入 50+ 消息平台 |
| Skills | 代码形式编写 | Markdown 文件,可自然语言编写 |
| 部署门槛 | 需大量集成开发 | 开箱即用 |
⾯试官:OpenClaw 记忆机制是怎么实现的?(高频)
候选人:
OpenClaw 的记忆机制是它最有特色的设计之一,核心思路是:“写进磁盘的才算记住了”。
分为两层记忆:
- 短期记忆(日志层):
sessions/YYYY-MM-DD.md,是当天发生事情的原始流水账,随时追加,捕捉当下上下文。 - 长期记忆(沉淀层):
MEMORY.md,更精炼稳定,存放需要长期保留的事实、偏好和规则。
检索方式:
提供 memory_search 工具,对 Markdown 文件进行语义分块(约 400 token 一块,80 token 重叠),通过向量检索找到最相关的内容返回给 Agent。
开发者可以直接用文本编辑器打开这些 Markdown 文件,查看、编辑、删减 Agent 的记忆内容,提炼长期原则,清楚地知道 AI 到底"记得什么"——没有任何黑箱。
⾯试官:OpenClaw 到底解决了什么痛点?
候选人:
OpenClaw 主要解决了以下几个行业痛点:
① 传统 Agent 没有持久记忆:对话结束就全忘了,每次都要重新交代背景。OpenClaw 用 Markdown 文件彻底解决了跨会话记忆的问题。
② 数据主权丧失:云原生 Agent 平台虽然上手快,但你的数据、提示词、对话历史全部流经别人的服务器。 OpenClaw 让数据完全跑在自己机器上。
③ 传统 Agent 是"被动响应"的:必须等你发消息才工作。OpenClaw 的心跳机制让 Agent 可以像员工一样主动巡检、执行任务。
④ 自建 Agent 成本极高:自己用 LangChain 等框架从零搭建一个支持多渠道、有记忆、有调度的 Agent,需要大量集成开发工作。 OpenClaw 把这些全部内置好了。
⑤ 记忆系统是黑箱:大多数框架的记忆存在向量数据库里,人看不懂也改不了。OpenClaw 的 Markdown 记忆文件完全透明。
⾯试官:OpenClaw 有什么缺点?(高频)
候选人:
OpenClaw 也有明显的短板,面试时坦诚说出这些会加分:
① 安全风险
2026 年初,安全研究人员发现了 CVE-2026-25253 漏洞,这是一个严重级别的安全问题。 自托管意味着安全维护全靠自己,没有企业级安全团队兜底。
② 上下文消耗大、成本高
OpenClaw 在每次推理前需要组装大量 prompt:系统指令、对话历史、工具定义、Skills 内容、记忆片段,这导致 token 消耗量很高,大多数部署会用高端模型做主调度。
③ 记忆文件会越来越膨胀
每日日志和会话记录会不断积累,长期使用可能产生大量文件,需要手动归档或配置保留策略。
④ 学习成本和运维负担
OpenClaw 给你最大的控制权和灵活性,但安装、安全配置、维护、运行时间、成本管理全都由你自己负责,学习曲线是真实存在的。
⑤ 编码能力是"技能增强"而非"原生理解"
OpenClaw 的编码能力来自 Skills(Markdown 指令文件),而不是对代码库的原生理解,无法像 Claude Code 那样真正读懂你的整个项目文件树、import 链和测试模式。
⾯试官:什么是 OpenClaw 的 Skills?(高频)
候选人:
传统用法是:
- 每次写一大段 Prompt
- 把规则、步骤、输出格式都塞进去
这样的话,会存在重复、不稳定、难复用、难组合等问题。
Skills 是包含指令的 Markdown 文件,用来告诉 Agent 如何完成某项特定任务、使用哪些工具。你可以把它理解成给 Agent 配发的"操作手册"。
每个 Skill 就是一个文件夹,里面有一个必须的 SKILL.md 文件,以及可选的附属资源:
my-skill/
├── SKILL.md # 必须,核心指令文件
├── scripts/ # 可选,Python/Bash 等脚本
├── references/ # 可选,参考文档
└── assets/ # 可选,模板/图标等资源
SKILL.md 的内部格式分两部分:
- YAML 头部:写名称、描述(Agent 靠这个判断"该不该用这个技能")
- Markdown 正文:写具体的执行步骤和规则
举个例子:
---
name: "Meeting Notes Processor"
description: "把原始会议记录转成结构化摘要,含行动项和决策"
version: "1.0.0"
tags: ["productivity", "meetings"]
---
## 用途
接收原始会议记录,输出四个部分:摘要、决策、行动项、后续跟进。
## 执行步骤
1. 读取输入的会议记录文本
2. 识别所有决策点
3. 提取所有行动项并标注责任人
...
## 限制
- 不得修改原始记录内容
- 行动项必须有明确的截止时间
⾯试官:Skills 是怎么工作的?
当某个 Skill 符合当前任务条件时,OpenClaw 会把该技能的内容以 XML 格式注入到系统 Prompt 里,Agent 就"学会"了这个技能,并按照里面的指令执行。
流程大致是:
用户发来消息
↓
Agent 判断:这个任务需要哪个 Skill?
↓
自动加载对应的 SKILL.md 注入上下文
↓
按 Skill 里的步骤执行任务
↓
返回结果
⚠️需要注意的安全风险:
OpenClaw 允许任何开发者在 ClawHub 上发布 Skill,这也意味着恶意指令可能被注入到 Markdown
文件里。安装第三方技能前,务必检查来源、审核权限范围,并在隔离环境中先测试。
⾯试官:Skills 和 MCP的区别?(高频)
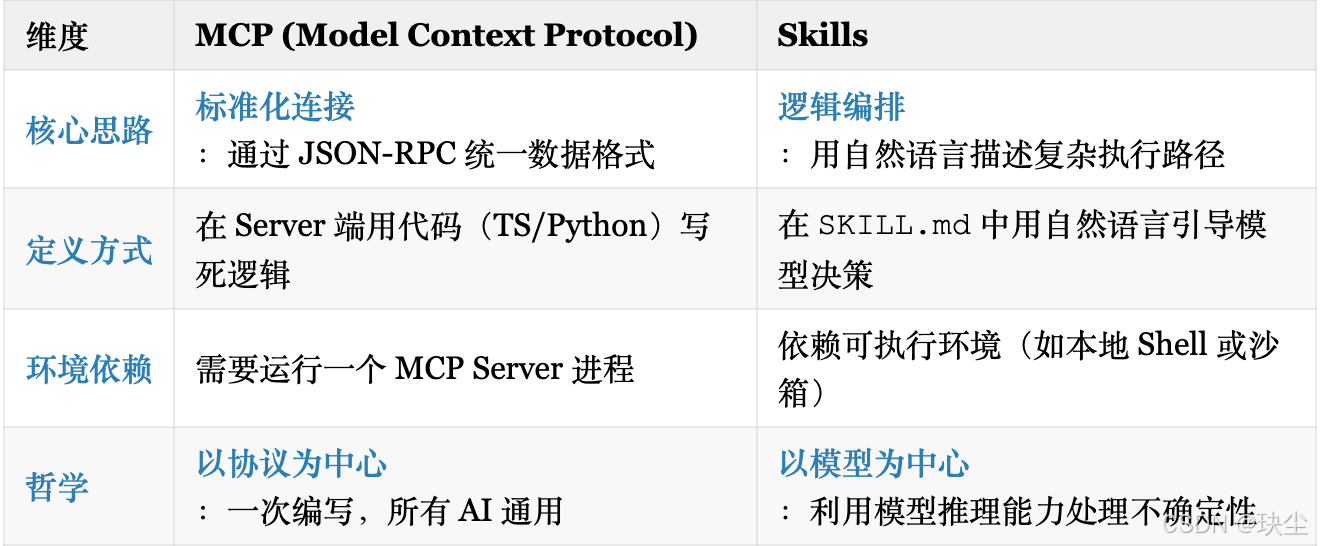
- MCP 解决的是连通性:它像 USB-C,让 AI 能以统一格式读文件、查数据库。
- Skills 解决的是编排逻辑:它像一份说明书,告诉 AI 如何执行复杂任务流——这些任务完全可以包括调用多个 MCP 工具。
- 两者的关系:它们
不是竞争关系,而是解决不同层面的问题。MCP 负责把外部系统接入进来,Skills 负责决定什么时候用、怎么组合这些能力。一个高级 Skill 的底层往往就是调用多个 MCP 工具。
⾯试官:Skills 和普通提示词工程(Prompt)的区别?
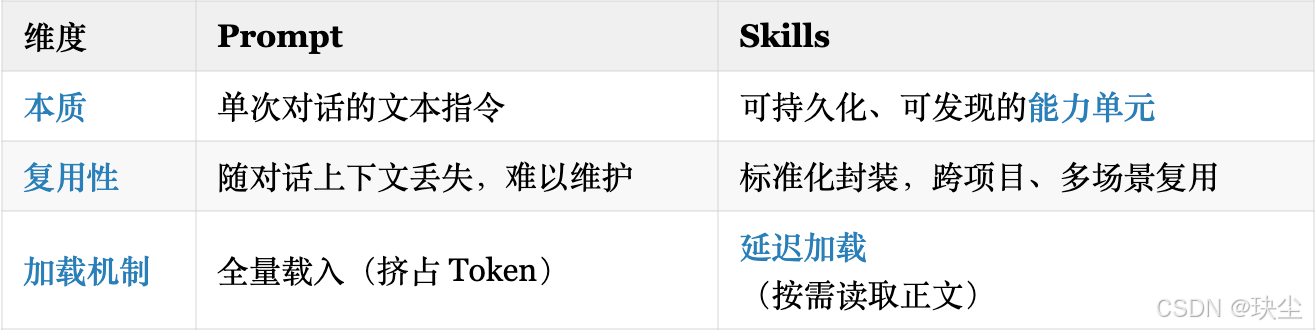
- Prompt:用户即时表达意图的载体(如"分析这份报表")。
- Skills:包含 元数据(何时使用)+ 正文(如何执行) 的完整方案,通过
load_skill()机制按需加载到上下文。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)