第四十一周周报
摘要
本文针对LSTM模型在洪水预测中缺乏可解释性的问题,提出了一种引入门控模块的改进方法。通过对输入变量及其时间步进行加权,模型能够识别关键影响因素及其作用时间范围,并结合自注意力机制增强变量间关系建模。在531个流域上的实验结果表明,该方法在保持较高预测精度的同时,实现了对时间尺度和变量重要性的有效解释
Abstract
This paper addresses the issue of the lack of interpretability in LSTM models for flood prediction by proposing an improved method that incorporates gating modules. By weighting input variables and their time steps, the model can identify key influencing factors and their temporal ranges of impact, while enhancing the modeling of relationships between variables through a self-attention mechanism. Experimental results on 531 watersheds demonstrate that this method maintains high prediction accuracy while effectively interpreting temporal scales and variable importance.
文献基本信息
标题:《Developing an explainable deep learning module based on the LSTM framework for flood prediction》
作者:Zhi Zhang; Dagang Wang; Yiwen Mei; Jinxin Zhu; Xusha Xiao
链接:Developing an explainable deep learning module based on the LSTM framework for flood prediction
研究背景
背景
随着极端气候事件频发,洪水预测在防灾减灾和水资源管理中具有重要意义。目前,径流预测方法主要包括基于物理过程的水文模型和数据驱动模型。其中,长短期记忆网络(LSTM)由于能够有效捕捉时间序列中的非线性关系和长期依赖,在洪水预测中表现出较高精度 。然而,LSTM模型通常被视为“黑箱”,难以解释模型在预测过程中对不同输入变量及时间信息的依赖程度,限制了其在水文机理分析中的应用价值。同时,现有解释方法多侧重于模型输出或局部特征贡献,缺乏对输入数据与时间维度的直观统一解释。
目的
针对上述问题,本文旨在构建一种具有可解释性的深度学习模型,在保证预测精度的同时,能够揭示不同气象变量及其时间窗口对洪水预测的影响机制。具体目标包括:
1)提高LSTM模型的可解释性;
2)识别关键输入变量及其有效时间范围;
3)从数据驱动角度分析不同流域的洪水形成机制
方法论
本文提出了一种基于LSTM的可解释洪水预测模型,在传统LSTM框架基础上引入门控(Gated)模块,用于显式建模输入变量及时间信息的重要性。整体模型由门控模块、LSTM模块和预测模块三部分组成。模型的核心思想是在进入LSTM之前,对输入数据进行选择性筛选,从而提升模型的可解释性。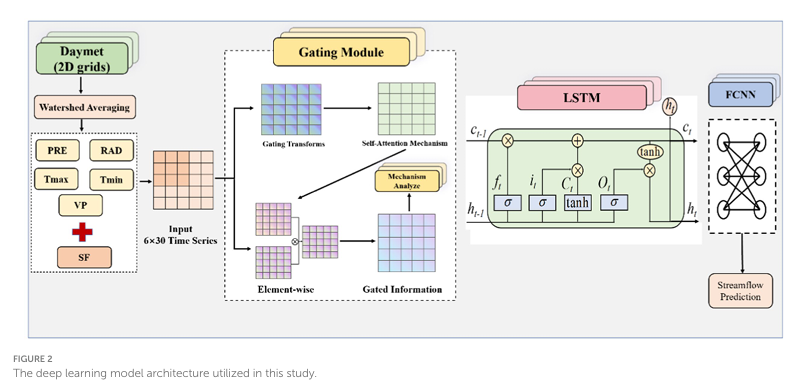
在数据输入阶段,将降水、气温、辐射、水汽压及历史径流等6类变量构建为包含30天历史信息的时间序列作为模型输入。输入数据表示为一个“变量 × 时间”的二维矩阵,这样的结构使模型能够同时学习不同变量之间的关系以及时间变化特征。
在数据输入LSTM之前,引入了门控模块,模型首先通过线性变换并结合Sigmoid函数生成权重矩阵,其计算形式可表示为: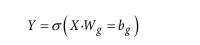 ,为每个变量在每个时间步分配一个0到1之间的权重,来衡量该信息对预测结果的重要性。
,为每个变量在每个时间步分配一个0到1之间的权重,来衡量该信息对预测结果的重要性。
此外,该门控模块还结合了自注意力机制,使模型不仅能够关注单一变量的重要性,还能够捕捉不同变量之间以及不同时间步之间的相互作用关系。最终,经过加权后的输入数据再传递给后续的LSTM模块。
LSTM模块对筛选后的时间序列数据进行建模,主要用于捕捉洪水演化过程中的时间依赖关系和长期动态特征。相比直接输入原始数据,经过门控筛选后的输入能够减少噪声干扰,使LSTM更加专注于关键模式的学习。LSTM单元的更新公式如下: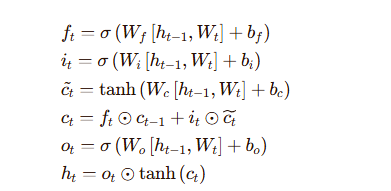
最后,模型通过一个由两层全连接神经网络构成的预测模块,将LSTM提取的特征映射为最终的径流预测结果。整个模型从“输入筛选—时序建模—结果输出”形成一个完整流程。
创新点
- 在传统LSTM模型前增加了一个门控(Gated)模块,用于对输入变量和时间信息进行加权筛选,从而提高模型的可解释性。
- 提出了“有效时间窗口(instructive days)”,用于分析不同变量在预测中实际起作用的时间范围
- 对门控信息进行聚类,将洪水驱动机制划分为不同类型
实验设计与分析
数据集:使用CAMELS数据集进行训练和评估。该数据集包含美国671个参考流域的水文气象时间序列观测数据。由于某些流域的面积差异超过10%,这些流域被排除在分析之外,最终选择了531个流域面积小于2000 km²的流域。
输入数据:输入数据包括过去30天的每日流量、累计降水量、平均短波辐射、最高气温、最低气温和平均水汽压。所有输入数据在模型计算前均进行了归一化处理。
评估指标:使用均方误差(MSE)、皮尔逊相关系数(CC)和Nash-Sutcliffe效率系数(NSE)三个指标评估模型性能。
数据分析
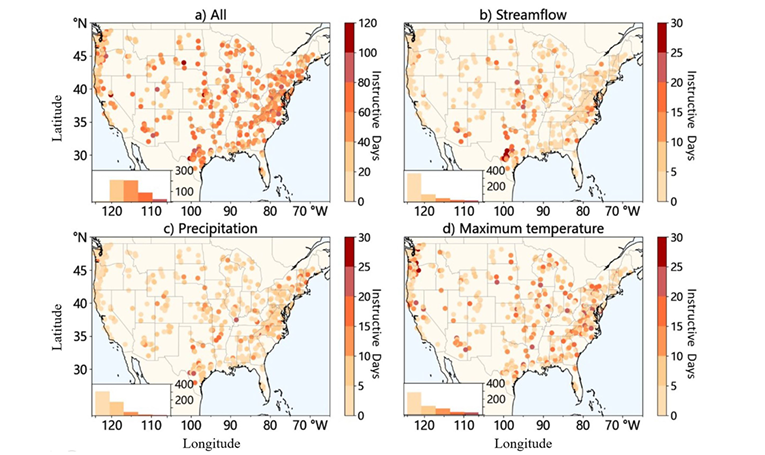
在时间信息分析中,如上图,不同变量的有效时间窗口存在显著差异。例如,降水和径流主要集中在较短时间范围内,而温度的作用时间则更长,可达20天以上 。这一结果表明,模型能够区分不同变量在时间尺度上的作用,即降水主要影响短期洪水变化,而温度更多反映长期水文过程。该结果直接支撑了论文提出的“模型具备时间维度解释能力”的观点。
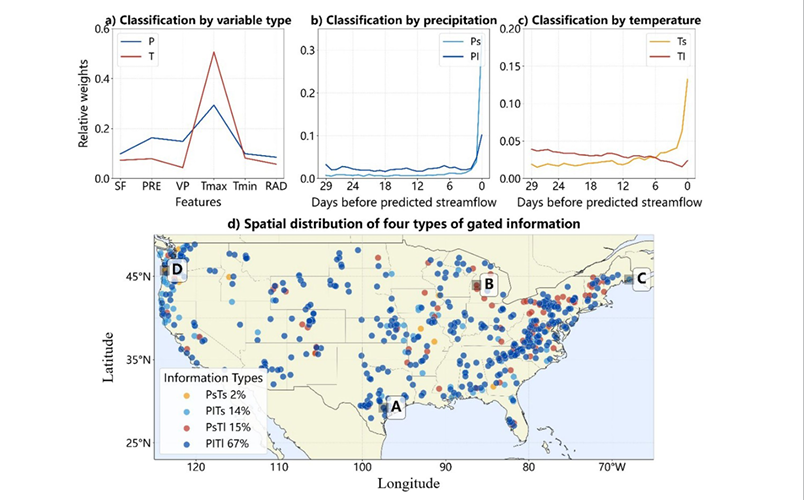
在洪水机制分析中,实验结果显示“短期降水 + 长期温度(PsTl)”类型占比最高,约占全部流域的三分之二 ,这一数据说明,大多数流域的洪水主要由短期降水触发,同时受到长期温度条件的影响。通过这一分类结果,模型不仅能够进行预测,还能够揭示洪水形成的主导机制,从而验证了其在物理意义上的解释能力。
结论
本文提出了一种基于LSTM框架的可解释模块,用于洪水预测。通过引入门控模块和自注意力机制,增强了模型对输入数据的理解和解释能力。实验结果表明,该模块能够有效捕捉时间依赖性和变量间的相互作用,提高了洪水预测的准确性。尽管单站数据可能限制了模型的泛化能力,但该方法为未来的多站分析和模型优化提供了有价值的见解。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 9
9 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)