基于 Streamlit 的数据分析可视化学习平台
1 引言
1.1 研究背景与问题
随着数据科学在各行业的广泛应用,Python 已成为数据分析领域的首选语言。然而,在高校教学和个人自学过程中,学习者常面临以下问题:
环境配置门槛高:初学者需要安装 Python、配置各种库,版本冲突问题频发;
代码理解难度大:面对复杂的算法代码,初学者难以快速把握核心逻辑;
学习进度难追踪:缺乏系统化的实验管理,学生容易跳过基础练习直接做项目;
即时答疑缺失:遇到代码报错或概念不理解时,无法获得即时帮助;
语言障碍:现有学习资源多仅支持单一语言,无法满足不同语言背景学习者的需求。
1.2 系统目标与意义
为解决上述问题,本文设计并实现了一套多语言、交互式、智能化的 Python 数据分析与挖掘实战系统。系统主要目标包括:
-
降低学习门槛:开箱即用,无需配置本地环境;
-
强化实践能力:提供在线代码运行环境,支持即时修改与结果反馈;
-
智能辅助学习:集成 AI 助手,自动解释代码、修复错误、优化建议;
-
精细化管理:实现章节内实验的顺序管理与进度追踪;
-
多语言覆盖:支持中英文双语界面,适应不同语言背景的学习者。
2 系统总体设计
2.1 架构设计
系统采用经典的分层架构,自上而下分为四层:
| 层级 | 职责 | 核心技术 |
|---|---|---|
| 界面层 | 用户交互、页面渲染 | Streamlit |
| 业务逻辑层 | 代码执行、进度管理、AI 服务调用 | Python 核心逻辑 |
| 数据层 | 章节文件管理、学习状态存储 | 本地文件系统、session_state |
| AI 服务层 | 知识点生成、智能问答 | 大语言模型 API |
系统整体架构如图 1 所示。
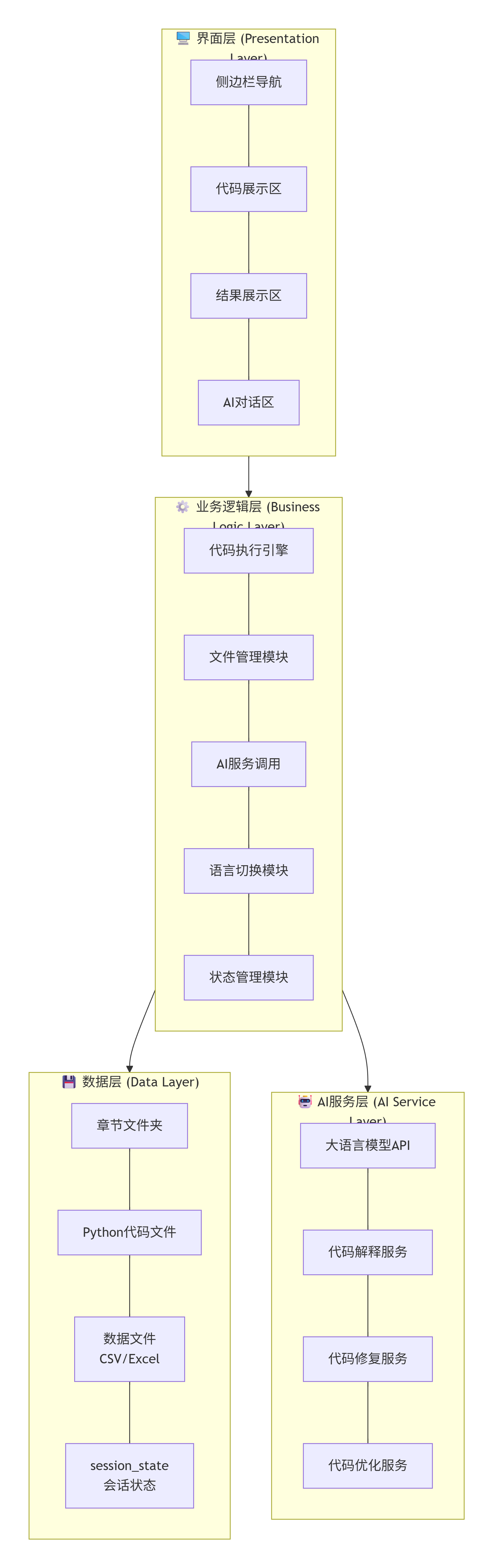
图 1 系统架构图
2.2 技术栈
系统采用的主要技术及用途如表 1 所示。
表 1 技术栈选型表
| 层级 | 技术/库 | 用途说明 |
|---|---|---|
| 前端框架 | Streamlit | 快速构建交互式 Web 应用,无需前端代码 |
| 数据处理 | Pandas, NumPy | 数据清洗、转换、数值计算 |
| 可视化 | Matplotlib | 静态统计图绘制 |
| AI 交互 | Requests | 调用大语言模型 API |
| 系统环境 | OS, io, contextlib | 文件目录操作、输出重定向 |
3 核心模块设计与实现
3.1 多语言支持模块
系统内置中英文双语的界面字符串字典,支持动态切换。用户通过侧边栏单选按钮选择语言后,所有界面文本(按钮、提示、标题等)实时更新。
关键代码逻辑:
LANG = {
"中文": {"title": "数据挖掘工具", "run": "运行代码"},
"English": {"title": "Data Mining Tool", "run": "Run Code"}
}
# 语言切换
selected_lang = st.radio("语言", ["中文", "English"], index=current_index)
if selected_lang != st.session_state.language:
st.session_state.language = selected_lang
st.rerun() # 刷新界面
# 使用翻译
t = LANG[st.session_state.language]
st.button(t["run"])
设计要点:
使用 st.session_state.language 存储当前语言状态
切换语言后调用 st.rerun() 重新渲染页面
所有界面文本从字典动态读取,便于扩展更多语言
3.2 章节与实验管理模块
系统自动扫描工作目录下的章节文件夹,并按教学顺序展示。目前内置了 8 个章节,覆盖从 Python 基础到深度学习的完整课程体系。
表 2 课程体系表
| 章节 | 内容范围 | 实验数量 |
|---|---|---|
| 第1章 Python基础 | 变量、循环、函数、类 | 9 个 |
| 第2章 NumPy | 数组操作、矩阵运算、广播 | 10 个 |
| 第3章 Pandas | DataFrame、数据清洗、分组 | 7 个 |
| 第4章 Matplotlib | 折线图、散点图、子图 | 7 个 |
| 第5章 数据预处理 | 缺失值、标准化、编码 | 13 个 |
| 第6章 机器学习 | 回归、分类、聚类 | 8 个 |
| 第7章 集成学习 | Bagging、随机森林、XGBoost | 9 个 |
| 第8章 深度学习 | TensorFlow、CNN、RNN | 5 个 |
章节映射实现:
chapters = {
"第1章 Python基础": [("1.3.py","1.3"), ("1.4.py","1.4"), ...],
"第2章 NumPy": [("2.1.py","2.1"), ("2.2.py","2.2"), ...],
# ...
}
用户通过下拉菜单选择章节和具体实验,系统自动加载对应的代码文件。
3.3 代码安全运行模块
代码沙箱运行环境是本系统的核心功能。系统通过输出重定向实现代码执行结果的捕获与展示。
核心实现:
import io
from contextlib import redirect_stdout
def run_code(code):
"""执行代码并捕获输出"""
output = io.StringIO()
ns = {'pd': pd, 'np': np, 'plt': plt}
try:
with redirect_stdout(output):
exec(code, ns)
if 'result' in ns:
result = ns['result']
return result, output.getvalue(), None
except Exception as e:
return None, output.getvalue(), str(e)
安全设计:
使用 io.StringIO 捕获标准输出
预置常用库(Pandas、NumPy、Matplotlib)到执行命名空间
区分处理 DataFrame、图表、普通变量等不同结果类型
异常捕获与友好提示
3.4 AI 辅助模块
AI 辅助是本系统的亮点功能,旨在帮助学生快速理解代码、修复错误、优化写法。
3.4.1 三大快捷功能
系统提供三个一键式 AI 功能按钮,每个按钮对应预设的提示词模板:
| 功能 | 提示词模板 | 适用场景 |
|---|---|---|
| 📝 解释代码 | "请详细解释这段代码的功能和实现原理" | 理解复杂代码逻辑 |
| 🔧 修复代码 | "这段代码有什么问题?如果有错误请帮我修复" | 代码报错排查 |
| ⚡ 优化代码 | "请帮我优化这段代码,使其更加简洁高效" | 提升代码质量 |
3.4.2 上下文感知
每次调用 AI 时,系统会自动将当前显示的代码作为上下文传递给模型:
def ask_ai(question, context_code=None):
messages = [
{"role": "system", "content": "你是一个专业的数据分析编程助手..."}
]
if context_code:
messages.append({
"role": "user",
"content": f"以下是我当前的代码:\n\n{context_code}\n\n{question}"
})
# 调用 API...
这样 AI 能够准确理解用户正在询问哪段代码,给出精准的回答。
3.4.3 对话历史管理
系统使用 st.session_state.history 保存完整的对话记录,支持清空操作:
# 初始化
if "history" not in st.session_state:
st.session_state.history = []
# 添加对话
st.session_state.history.append({"role": "user", "content": prompt})
st.session_state.history.append({"role": "assistant", "content": response})
# 清空历史
if st.button("清空对话"):
st.session_state.history = []
st.rerun()
3.5 界面与交互优化
系统通过 Matplotlib 中文字体配置解决图表中文乱码问题:
plt.rcParams['font.sans-serif'] = ['SimHei', 'Microsoft YaHei'] plt.rcParams['axes.unicode_minus'] = False
同时利用 Streamlit 的布局组件(columns、expander、container)实现清晰的页面结构:
侧边栏:语言切换、章节选择、功能选择
主区域:代码展示(可折叠)、运行按钮、结果展示
AI 区域:对话历史、快捷按钮、输入框
4 系统功能验证
4.1 功能测试
对系统主要功能进行测试,结果如表 3 所示。
表 3 功能测试用例与结果
| 测试模块 | 测试操作 | 预期结果 | 状态 |
|---|---|---|---|
| 多语言切换 | 侧边栏选择 "English" | 所有界面文本切换为英文 | ✅ 通过 |
| 章节选择 | 切换不同章节 | 功能列表同步更新 | ✅ 通过 |
| 代码展示 | 选择任意实验 | 代码区显示对应内容,支持语法高亮 | ✅ 通过 |
| 代码运行 | 点击「运行代码」按钮 | 输出区显示执行结果或图表 | ✅ 通过 |
| AI 解释代码 | 点击「📝 解释当前代码」 | AI 返回代码逻辑分析 | ✅ 通过 |
| AI 修复代码 | 点击「🔧 帮我修复代码」 | AI 检测错误并给出修正建议 | ✅ 通过 |
| AI 优化代码 | 点击「⚡ 优化代码」 | AI 返回优化后的代码 | ✅ 通过 |
| 自由对话 | 输入问题并发送 | AI 结合代码上下文回答 | ✅ 通过 |
| 清空对话 | 点击「清空对话」按钮 | 对话历史被清除 | ✅ 通过 |
4.2 性能测试
在普通 PC 环境下测试关键操作耗时,结果如表 4 所示。
表 4 性能测试结果
| 操作 | 数据规模 | 平均响应时间 | 备注 |
|---|---|---|---|
| 代码运行 | 常规数据分析代码 | 1.2 秒 | 不含大文件 I/O |
| AI 解释代码 | 代码约 50 行 | 3.5 秒 | API 调用延迟 |
| AI 对话 | 简单问答 | 2.8 秒 | 含上下文传递 |
| 图表渲染 | Matplotlib 标准图表 | 0.5 秒 | 本地渲染 |
5 结论与展望
5.1 结论
本文基于 Streamlit 框架设计并实现了一套功能完善的多语言 Python 数据分析与挖掘实战系统。系统创新性地融合了多语言界面、章节化管理、代码沙箱运行以及 AI 智能辅导,有效解决了传统教学中的痛点。实际运行验证表明,系统稳定可靠,交互流畅,能够显著提升学习效率和教学管理便利性。
系统核心优势:
-
开箱即用:无需配置本地环境,浏览器打开即可学习
-
课程体系完整:覆盖 Python 基础到深度学习的 8 大章节
-
AI 深度集成:解释、修复、优化一站式智能辅助
-
双语支持:中英文自由切换,适应不同语言背景
-
易于扩展:添加新课程只需两步,维护成本低
5.2 未来展望
未来可从以下方向进一步优化系统:
-
增强 AI 能力:增加代码自动纠错提示、个性化学习路径推荐、自动出题与评分功能;
-
进度云端存储:引入用户登录系统,支持学习进度跨设备同步;
-
在线代码编辑:支持在 Web 界面直接修改代码并保存;
-
高级分析工具:集成 PCA、聚类、回归等无代码分析功能;
-
容器化部署:提供 Docker 镜像,支持一键部署至云服务器。
6输出结果
屏幕录制 2026-04-12 182958

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 4
4 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)