Agent心智架构:感知一推理一行动循环
Agent心智架构:感知一推理一行动循环
Agent 并非一个“函数”,而是一个“进程”——运行在一个while(alive)的无限循环之中。在这个循环中,感知、推理与行动并非孤立的步骤,而是彼此咬合、协同运转的“齿轮”。基于对 Agent 本体论的认知,我们可以构建出 Agent 心智架构,如图 3-7 所示。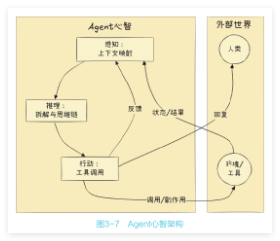
代码如下:
#!/usr/bin/env python3
"""
本示例展示了如何实现一个带有工具调用能力的 AI Agent 循环。
Agent 循环的核心逻辑保持不变,只是在工具数组中添加了工具定义,
并通过一个分发映射表(dispatch map)来路由工具调用请求。
数据流向图:
+----------+ +-------+ +------------------+
| User | ---> | LLM | ---> | Tool Dispatch |
| prompt | | | | { |
+----------+ +---+---+ | bash: run_bash |
^ | read: run_read |
| | write: run_wr |
+----------+ edit: run_edit |
tool_result| } |
+------------------+
"""
# =============================================================================
# 标准库导入
# =============================================================================
import os # 操作系统接口,用于环境变量和路径操作
import subprocess # 子进程管理,用于执行 shell 命令
import json # JSON 解析,用于解析工具调用的参数
from pathlib import Path # 面向对象的路径操作
import logging
# 配置日志格式和级别
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s'
)
logger = logging.getLogger(__name__)
# =============================================================================
# 第三方库导入
# =============================================================================
from openai import OpenAI # OpenAI 官方 Python SDK
from dotenv import load_dotenv # 从 .env 文件加载环境变量
# =============================================================================
# 环境配置
# =============================================================================
# 加载 .env 文件中的环境变量
# override=True 表示即使系统已有同名环境变量,也用 .env 文件中的值覆盖
load_dotenv(override=True)
# 工作目录:当前脚本运行的位置
# 所有文件操作都会相对于这个目录进行
WORKDIR = Path.cwd()
# 初始化 OpenAI 客户端
# 注意:虽然变量名叫 ANTHROPIC_API_KEY,但这里实际是 DashScope 的 API Key
# 这种命名是为了方便切换不同的后端服务
client = OpenAI(
api_key=os.getenv("ANTHROPIC_API_KEY"), # 从环境变量获取 API 密钥
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1", # DashScope 兼容接口地址
)
# 模型配置:从环境变量获取,默认使用 qwen-plus
# 可选值包括:qwen-turbo, qwen-plus, qwen-max 等
MODEL = os.getenv("MODEL_ID", "qwen-plus")
# System Prompt: 定义 Agent 的角色和行为准则
# 这里告诉模型它是一个编码代理,应该使用工具来完成任务,并且行动优于解释
SYSTEM = f"You are a coding agent at {WORKDIR}. Use tools to solve tasks. Act, don't explain."
# =============================================================================
# 安全工具函数
# =============================================================================
def safe_path(p: str) -> Path:
"""
安全路径解析函数 - 防止路径遍历攻击
将用户提供的相对路径转换为绝对路径,并验证该路径是否在允许的工作目录内。
这可以防止恶意用户尝试访问工作目录之外的敏感文件。
参数:
p: 用户提供的文件路径(相对路径)
返回:
Path: 解析后的安全绝对路径对象
异常:
ValueError: 如果路径试图逃逸工作目录
示例:
>>> safe_path("src/main.py") # 正常路径
Path("/home/user/project/src/main.py")
>>> safe_path("../../../etc/passwd") # 恶意路径
ValueError: Path escapes workspace: ../../../etc/passwd
"""
# 将相对路径解析为绝对路径
# WORKDIR / p 会将路径拼接到工作目录
# .resolve() 会解析所有符号链接和相对路径组件(如 ..)
path = (WORKDIR / p).resolve()
# 安全检查:确保解析后的路径仍然是工作目录的子路径
# is_relative_to() 方法检查路径是否在指定目录内
if not path.is_relative_to(WORKDIR):
raise ValueError(f"Path escapes workspace: {p}")
return path
# =============================================================================
# 工具执行函数
# =============================================================================
def run_bash(command: str) -> str:
"""
Bash 命令执行工具
在 shell 中执行指定的命令,并返回输出结果。
包含安全检查,阻止危险命令的执行。
参数:
command: 要执行的 shell 命令字符串
返回:
str: 命令的标准输出和标准错误输出(合并),最多返回 50000 字符
安全措施:
1. 阻止危险命令:rm -rf /, sudo, shutdown, reboot, > /dev/
2. 设置超时限制:120 秒
3. 输出截断:防止返回过多数据
示例:
>>> run_bash("ls -la")
"total 48\ndrwxr-xr-x 2 user user 4096 ..."
>>> run_bash("sudo rm -rf /")
"Error: Dangerous command blocked"
"""
# 危险命令黑名单
# 这些命令可能对系统造成严重损害,因此被完全阻止
dangerous = ["rm -rf /", "sudo", "shutdown", "reboot", "> /dev/"]
# 检查命令是否包含任何危险关键词
if any(d in command for d in dangerous):
return "Error: Dangerous command blocked"
try:
# 执行 shell 命令
# shell=True: 通过 shell 执行命令(支持管道、通配符等 shell 特性)
# cwd=WORKDIR: 在工作目录中执行命令
# capture_output=True: 捕获 stdout 和 stderr
# text=True: 将输出解码为字符串而非字节
# timeout=120: 设置 120 秒超时限制
r = subprocess.run(
command,
shell=True,
cwd=WORKDIR,
capture_output=True,
text=True,
timeout=120
)
# 合并标准输出和标准错误输出
# .strip() 移除首尾空白字符
out = (r.stdout + r.stderr).strip()
# 截断输出,防止返回过多数据
# 如果输出为空,返回提示信息
return out[:50000] if out else "(no output)"
except subprocess.TimeoutExpired:
# 命令执行超时
return "Error: Timeout (120s)"
def run_read(path: str, limit: int = None) -> str:
"""
文件读取工具
读取指定文件的内容,支持限制读取行数。
包含路径安全检查,防止读取工作目录外的文件。
参数:
path: 文件路径(相对于工作目录)
limit: 可选参数,限制读取的行数。如果文件行数超过限制,
会在末尾添加省略提示
返回:
str: 文件内容,最多返回 50000 字符
示例:
>>> run_read("README.md")
"# Project Name\nThis is a readme file..."
>>> run_read("large_file.txt", limit=10)
"Line 1\nLine 2\n... Line 10\n... (990 more lines)"
"""
try:
# 使用 safe_path 进行安全路径解析
# .read_text() 读取整个文件内容为字符串
text = safe_path(path).read_text()
# 按行分割文本
lines = text.splitlines()
# 如果设置了行数限制且文件行数超过限制
if limit and limit < len(lines):
# 截取指定行数
lines = lines[:limit]
# 添加省略提示,显示剩余行数
lines = lines + [f"... ({len(lines) - limit} more lines)"]
# 重新拼接为字符串,并截断到 50000 字符
return "\n".join(lines)[:50000]
except Exception as e:
# 捕获并返回任何错误(如文件不存在、权限不足等)
return f"Error: {e}"
def run_write(path: str, content: str) -> str:
"""
文件写入工具
将内容写入指定文件。如果文件不存在会创建新文件,
如果文件所在目录不存在也会自动创建目录。
参数:
path: 文件路径(相对于工作目录)
content: 要写入的文件内容
返回:
str: 操作结果信息,包含写入的字节数和文件路径
安全措施:
1. 使用 safe_path 防止路径遍历攻击
2. 自动创建父目录
示例:
>>> run_write("output.txt", "Hello, World!")
"Wrote 13 bytes to output.txt"
"""
try:
# 安全路径解析
fp = safe_path(path)
# 创建父目录(如果不存在)
# parents=True: 创建所有必要的父目录
# exist_ok=True: 如果目录已存在不报错
fp.parent.mkdir(parents=True, exist_ok=True)
# 写入文件内容
fp.write_text(content)
# 返回操作结果
return f"Wrote {len(content)} bytes to {path}"
except Exception as e:
return f"Error: {e}"
def run_edit(path: str, old_text: str, new_text: str) -> str:
"""
文件编辑工具
在文件中查找并替换精确匹配的文本。只会替换第一个匹配项。
参数:
path: 文件路径(相对于工作目录)
old_text: 要查找的原始文本(必须精确匹配)
new_text: 替换后的新文本
返回:
str: 操作结果信息
注意:
- 使用精确字符串匹配,区分大小写
- 只替换第一个匹配项,不会替换所有出现
示例:
>>> run_edit("config.py", "DEBUG = False", "DEBUG = True")
"Edited config.py"
>>> run_edit("config.py", "not_exist", "new_value")
"Error: Text not found in config.py"
"""
try:
# 安全路径解析
fp = safe_path(path)
# 读取当前文件内容
content = fp.read_text()
# 检查要替换的文本是否存在
if old_text not in content:
return f"Error: Text not found in {path}"
# 执行替换操作
# .replace(old, new, 1) 中的 1 表示只替换第一个匹配项
fp.write_text(content.replace(old_text, new_text, 1))
return f"Edited {path}"
except Exception as e:
return f"Error: {e}"
# =============================================================================
# 工具分发映射表
# =============================================================================
# 工具名称到处理函数的映射
# 当 LLM 调用某个工具时,通过这个字典找到对应的处理函数
# 使用 lambda 函数来统一参数传递方式(从字典中提取参数)
#
# 工作原理:
# 1. LLM 返回工具调用请求,包含工具名称和参数
# 2. 通过 TOOL_HANDLERS[tool_name] 获取对应的 lambda 函数
# 3. 调用 lambda 函数,传入参数字典 **kwargs
# 4. lambda 函数将参数分发给实际的执行函数
TOOL_HANDLERS = {
"bash": lambda **kw: run_bash(kw["command"]),
"read_file": lambda **kw: run_read(kw["path"], kw.get("limit")),
"write_file": lambda **kw: run_write(kw["path"], kw["content"]),
"edit_file": lambda **kw: run_edit(kw["path"], kw["old_text"], kw["new_text"]),
}
# =============================================================================
# 工具定义 (OpenAI 格式)
# =============================================================================
# OpenAI 工具定义格式说明:
# - 每个工具是一个字典,包含 "type" 和 "function" 两个键
# - "type" 目前只支持 "function"
# - "function" 包含:
# - name: 工具名称(必须与 TOOL_HANDLERS 中的键一致)
# - description: 工具描述(帮助 LLM 理解工具用途)
# - parameters: JSON Schema 格式的参数定义
TOOLS = [
# -------------------------------------------------------------------------
# bash 工具: 执行 shell 命令
# -------------------------------------------------------------------------
{
"type": "function", # 工具类型,OpenAI 目前只支持 "function"
"function": {
"name": "bash", # 工具名称,必须与 TOOL_HANDLERS 中的键匹配
"description": "Run a shell command.", # 工具描述,LLM 会根据这个决定是否使用
"parameters": { # 参数定义,使用 JSON Schema 格式
"type": "object", # 参数必须是一个对象(字典)
"properties": {
"command": {
"type": "string", # 参数类型为字符串
"description": "The shell command to execute" # 参数描述
}
},
"required": ["command"] # 必需参数列表
}
}
},
# -------------------------------------------------------------------------
# read_file 工具: 读取文件内容
# -------------------------------------------------------------------------
{
"type": "function",
"function": {
"name": "read_file",
"description": "Read file contents.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "The file path to read"
},
"limit": {
"type": "integer", # 整数类型
"description": "Maximum number of lines to read"
# 注意: limit 不在 required 中,是可选参数
}
},
"required": ["path"] # 只有 path 是必需的
}
}
},
# -------------------------------------------------------------------------
# write_file 工具: 写入文件
# -------------------------------------------------------------------------
{
"type": "function",
"function": {
"name": "write_file",
"description": "Write content to file.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "The file path to write"
},
"content": {
"type": "string",
"description": "The content to write"
}
},
"required": ["path", "content"] # 两个参数都是必需的
}
}
},
# -------------------------------------------------------------------------
# edit_file 工具: 编辑文件(查找替换)
# -------------------------------------------------------------------------
{
"type": "function",
"function": {
"name": "edit_file",
"description": "Replace exact text in file.",
"parameters": {
"type": "object",
"properties": {
"path": {
"type": "string",
"description": "The file path to edit"
},
"old_text": {
"type": "string",
"description": "The text to replace"
},
"new_text": {
"type": "string",
"description": "The new text"
}
},
"required": ["path", "old_text", "new_text"] # 三个参数都是必需的
}
}
},
]
# =============================================================================
# Agent 循环核心函数
# =============================================================================
def agent_loop(messages: list):
"""
Agent 主循环函数
这是整个系统的核心,实现了 LLM 与工具之间的交互循环:
1. 将对话历史发送给 LLM
2. 检查 LLM 是否需要调用工具
3. 如果需要,执行工具并将结果返回给 LLM
4. 重复直到 LLM 返回最终回复
参数:
messages: 对话历史列表,包含 user 和 assistant 的消息
工作流程:
┌─────────────────────────────────────┐
│ 发送消息给 LLM (包含工具定义) │
└─────────────────┬───────────────────┘
▼
┌─────────────────────────────────────┐
│ LLM 返回响应 │
└─────────────────┬───────────────────┘
▼
┌─────────────────┐
│ 有工具调用? │
└────────┬────────┘
┌────┴────┐
是 否
│ │
▼ ▼
┌──────────────┐ ┌──────────────┐
│ 执行所有工具 │ │ 返回最终回复 │
│ 返回结果给LLM │ │ │
└──────┬───────┘ └──────────────┘
│
└──────► 返回步骤 1 (循环)
OpenAI 特有细节:
- tool_choice="auto": 让模型自动决定是否使用工具
- tool_calls: 包含所有工具调用的列表
- tool_call_id: 每个工具调用都有唯一 ID,结果需要关联
"""
while True:
# =====================================================================
# 步骤 1: 调用 OpenAI API
# =====================================================================
response = client.chat.completions.create(
model=MODEL, # 使用的模型
# 构建消息列表: system prompt + 对话历史
# 注意: OpenAI 将 system 作为 messages 列表的一部分
messages=[{"role": "system", "content": SYSTEM}] + messages,
tools=TOOLS, # 工具定义列表
tool_choice="auto", # 让模型自动决定是否使用工具
max_tokens=8000, # 最大生成 token 数
)
# =====================================================================
# 步骤 2: 获取助手消息并添加到历史
# =====================================================================
# response.choices[0].message 是助手的回复消息对象
assistant_message = response.choices[0].message
# ⚠️ 重要: 必须将 Pydantic 模型对象转换为字典格式
# 如果直接添加 assistant_message 对象,当包含 tool_calls 时,
# 下次 API 调用会报错: TypeError: argument 'by_alias': 'NoneType' object
# 使用 model_dump(exclude_none=True) 序列化为字典
messages.append(assistant_message.model_dump(exclude_none=True))
logger.info(f"当前回应大模型的数据消息: {assistant_message.model_dump(exclude_none=True)}")
# =====================================================================
# 步骤 3: 检查是否需要调用工具
# =====================================================================
# tool_calls 属性为 None 或空列表表示模型不需要调用工具
# 这意味着模型已经生成了最终回复
if not assistant_message.tool_calls:
# 没有工具调用,打印最终回复并返回
if assistant_message.content:
print(assistant_message.content)
return # 退出循环,返回到调用者
# =====================================================================
# 步骤 4: 处理所有工具调用
# =====================================================================
tool_results = [] # 存储所有工具执行结果
# 遍历每个工具调用请求
# 注意: 模型可能一次请求调用多个工具(并行调用)
for tool_call in assistant_message.tool_calls:
# -----------------------------------------------------------------
# 提取工具信息
# -----------------------------------------------------------------
# tool_call.function.name: 工具名称
tool_name = tool_call.function.name
# tool_call.function.arguments: 工具参数(JSON 字符串)
# 需要用 json.loads() 解析为 Python 字典
tool_args = json.loads(tool_call.function.arguments)
# -----------------------------------------------------------------
# 执行工具
# -----------------------------------------------------------------
# 从分发映射表中获取对应的处理函数
handler = TOOL_HANDLERS.get(tool_name)
logger.info(f"工具调用请求: {tool_name} with args {tool_args}")
if handler:
# 调用处理函数,传入参数
# **tool_args 将字典解包为关键字参数
output = handler(**tool_args)
else:
# 未知工具,返回错误信息
output = f"Unknown tool: {tool_name}"
# 打印工具执行结果(截取前 200 字符)
print(f"> {tool_name}: {output[:200]}")
# -----------------------------------------------------------------
# 构建工具结果消息
# -----------------------------------------------------------------
# OpenAI 要求工具结果包含以下字段:
# - tool_call_id: 关联回原始工具调用的唯一 ID
# - role: 必须是 "tool"
# - name: 工具名称(可选但推荐)
# - content: 工具执行的输出结果
tool_results.append({
"tool_call_id": tool_call.id, # 关联 ID,必须与 tool_call.id 匹配
"role": "tool", # 固定为 "tool"
"name": tool_name, # 工具名称
"content": output # 工具输出
})
# =====================================================================
# 步骤 5: 将工具结果添加到对话历史
# =====================================================================
# 将所有工具结果追加到消息列表
# 下一次循环时,这些结果会随对话历史一起发送给 LLM
messages.extend(tool_results)
# 循环继续,返回步骤 1...
# =============================================================================
# 主程序入口
# =============================================================================
if __name__ == "__main__":
# 初始化对话历史列表
# 用于保存完整的对话上下文
history = []
# 主交互循环
while True:
try:
# 获取用户输入
# \033[36m 是 ANSI 颜色代码,显示青色
# \033[0m 重置颜色
query = input("\033[36ms02 >> \033[0m")
except (EOFError, KeyboardInterrupt):
# EOFError: 用户按了 Ctrl+D (Unix) 或 Ctrl+Z (Windows)
# KeyboardInterrupt: 用户按了 Ctrl+C
break
# 检查退出命令
# strip() 移除首尾空白
# lower() 转换为小写
if query.strip().lower() in ("q", "exit", ""):
break
# 将用户消息添加到历史
history.append({"role": "user", "content": query})
# 调用 agent 循环处理请求
# agent_loop 可能会执行多轮工具调用
agent_loop(history)
# 打印空行分隔不同的交互
print()
感知:主动的过滤器
传统程序仅接收数据,而 Agent 则通过感(Perception)来理解世界。传统程序对输入是被动的——用户给什么,它就处理什么。而Agent的感知是主动的:它不仅接收信息,还会主动选择、解读并赋予信息以意义。Agent 的现代感知系统至少包含3个关键机制,分别是注意力、预测和语义化。
注意力:并非所有输入都同等重要
世界充满噪声。如果 Agent 试图处理所有信息,将迅速
陷入过载。感知的核心功能并非“接收”,而是“过滤”—感知即选择,如图3-8 所示。注意力(Attention)是感知的第一道选择器,如同聚光灯一般。模型的注意力机制,结合多模态模型(如GPT-40、Qwen-VL),能够对视觉信息、文本内容和历史上下文进行筛选,判断“哪些信息与任务目标相关”。
■通过注意力机制,Agent 可以忽略无关的HTML标
签,仅聚焦于网页正文内容。
■通过向量检索,Agent 可以过滤掉 99% 的数据库记
录,仅关注与当前任务相关的片段。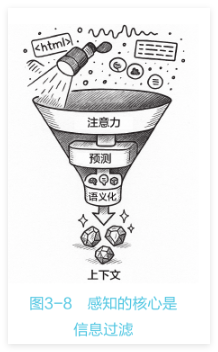
预测:感知并非被动接收,而是带着期望去理解
Agent会基于历史对话、用户偏好和任务背景,构建一个“预测模型”。当现实与预
测发生偏离时,便会产生“惊奇点”(Surprise)。而这些惊奇点往往预示着新的价值、新的问题或新的矛盾。
语义化:从特征到意义
现代多模态模型已不再局限于识别物体,而是能够理解情境。不只是识别“老人”,而是判断其“可能是需要帮助的老人”。不只是识别“文件”,而是意识到其“可能是被用户遗忘的配置文件”。不只是识别“数字”,而是将其理解为“统计趋势的一部分”。
感知已从“是什么”跃迁至“意味着什么”。因此,Agent 的感知是一种“目标驱动的理解”,而非“机械式的输入”。
Agent不仅能识别人,更能理解“需要帮助”这一概念。在感知过程中,它可能会注
意到拄拐杖的老人、迷路的孩子…
推理:快思考与慢思考
传统程序执行逻辑,而Agent 则进行推理(Reasoning)。传统程序中的逻辑是确定性的:若A,则执行X;若B,则执行Y。而Agent的推理则是柔性的、非确定性的,并且与经验紧密相关——它更像人类的思考过程,而非计算图的机械执行。
借鉴丹尼尔·卡尼曼(Daniel Kahneman)的心理学模型,Agent 的推理架构正在向“双系统”演进,如图3-9所示。System1代表直觉式/快思考:基于LLM的概率预测直接生成回答,适用于闲聊、简单问答以及代码补全等场景。其特点是响应迅速、计
算成本低,但容易产生幻觉。System 2代表逻辑式/慢思考:通过思维链,Agent 在输出最终结果前,会强制生成推理步骤、反思路径,甚至伪代码,适用于复杂规划、数学证明、调试等任务。其特点是响应较慢、计算成本较高,但逻辑严密、可靠性强。
架构师面临的挑战在于“路由”:如何设计一种机制,使 Agent 在面对简单问题时调
用System 1,而在遭遇复杂任务时自动切换至 System2?Agent 推理通常包含以下 4个关键层次。
- 情境理解(Situation Awareness)。Agent需要回答:“当前到底发生了什么?”
它会将感知到的信息与长期记忆和短期上下文相结合,构建出一个清晰的“任务 场景”。 - 经验检索(MemoryRetrieval)。Agent 会自问:“我是否曾遇到过类似的问
题?”这是推理过程中的重要加速器。大多数高性能模型(如OPenAlo1、 DeepSeek-R1)依赖策略性记忆检索,以避免重复犯错。 - 心智模拟(Mental Simulation)。Agent 不会立即采取行动,而是先在“脑海
中”进行预演:如果调用这个API,会发生什么?如果读取该文件,能获得哪些
信息?如果执行删除操作,是否会引发风险?推理的关键不仅在于逻辑本身,更 在于其模拟能力。 - 决策与信心(Decision and Confidence)。Agent会对候选行动进行价值评估:
哪个最符合用户目标?哪个最安全?哪个成本最低?同时还会判断:“我对这个
选择有多确定?”Agent的本质不是“计算出唯一结果”,而是“通过思考进行 权衡并作出决定”。
在智能推理的概率性思考过程中,可能包含以下一系列曾被视为人类心智专属的认知特质。
情境理解:这是什么情况? - 记忆检索:我是否曾遇到过类似情况?
- 心智模拟:如果我这样做,会发生什么?
- 因果推理:为什么会这样?
- 反事实思考:如果不这样做,结果会如何?
- 价值评估:哪种选择最符合目标、最安全或成本最低?
- 不确定性量化:我对当前的判断有多确定?
行动:改变与反馈
在Agent架构中,行动则标志着环境改变的开始。Agent的价值在于其能够对现实世界产生切实影响:写入数据库、发送邮件、部署代码··行动是 Agent 的“意图”在物理世界或数字环境中的延伸。而且,通过行动一反馈循环(Action-Feedback Loop),Agent 能够在动态环境中“通过试错”不断调整策略,主动探测世界的边界并逐步适应。
传统程序是独白者,Agent 是互动者。
■脚本:执行命令一结束。若出错,则程序崩溃。
■Agent:执行命令→观察结果一若出错,则调整参数→重试。
在Agent 架构中,行动并非终点,而是改变的起点。Agent 的行动不再是单纯的信息展示,而是对环境的主动介入。它试图通过这些行动来改变世界的状态,并期待从环境中获得反馈(见图3-10)。这种反馈会触发新一轮的感知与推理过程,使
得Agent能够持续适应并影响其所在的环境。这就引出了行动的3个新维度,分别是认识性行动、目的性行动和闭环行动。
认识性行动:行动即实验
这是Agent 最深刻的特征之一。传统程序通常只有在确定无误时才执行操作;而Agent却常常在不确定性中采取行动——因为对它而言,行动本身就是获取信息、消除不确定性的最有效手段。
- 场景:Agent 不确定某个 APl 的参数格式是v1还是v2。
- 推理:“我不知道参数版本是v1还是v2,空想无益。”
- 行动:Agent主动发起一次试探性调用,使用v1 作为参数。
- 观察:收到错误响应“Invalid Parameter”。
结论:V1被排除,因此参数格式应为v2。
这种“为了获取信息而行动”,正是Agent区别于僵化脚本的核心特征。它并非盲目
执行,而是主动以行动为“探针”,去探测世界的边界、规则与反馈机制。
目的性行动:副作用是必需的
在函数式编程中,我们极力避免的“副作用”,在Agent 架构中却成为其存在的核心目标。Agent的本质正是主动制造可控的副作用,以改变现实或数字环境的状态,例如以下动作。
- 修改数据库(改变数据状态)。
- 发送邮件(改变社会或协作状态)。
- 部署代码(改变系统运行状态)。
正因如此,Agent 的行动模块必须内嵌世界模型校验(World Model Checking)
机制:
“在执行此副作用之前,世界处于什么状态?执行之后,世界应变成什么样子?
闭环行动:执行一验证一纠偏
行动不再是一个原子的“发射后不管”(Fire andForget)操作,而是一个微型闭
环结构。每一次行动都必须伴随着一个明确的期望,并据此形成“执行一验证一纠偏”的反馈循环。
- 期望:“我运行了这个脚本,应该生成一个data.csv文件。”
- 执行:运行脚本。
- 验证:检查目标目录,发现data.csv文件未生成。
- 纠偏:分析错误日志,定位问题,修改脚本,并重新尝试。
行动是Agent思维在物理世界(或数字世界)中的投影。它不仅改变外部环境的状态,也反过来重塑Agent 对世界的理解——每一次干预都是一次认知更新的契机,这使Agent 在“做中学”,在交互中进化。
循环的动力学:OODA的软件化
真正的智能,既不存在于感知(那是摄像头的功能),也不存在于推理(那是计算器的专长),更不存在于行动(那是机械臂的职责)。它并不归属于任何一个孤立的模块。智能是一种“流动”的属性。
当我们把感知、推理与行动首尾相连,奇妙的事情便发生了:静态的代码由此获得了动态的“生命感”。在 Agent 的设计中,行动与感知密不可分。
- 行动指导感知:当你决定“寻找钥匙”(行动)时,你的注意力会自动聚焦于桌 面上的物体,而忽略墙上的画(感知)。
- 感知指导行动:当你看到桌子边缘(感知)时,你的手会自然减速,以避免碰倒 水杯(行动)。
因此,在图3-11所示的Agent 认知循环中,行动模块不应仅连接到“环境”,还必须通过一条反馈连线指向记忆/反思模块和推理模块。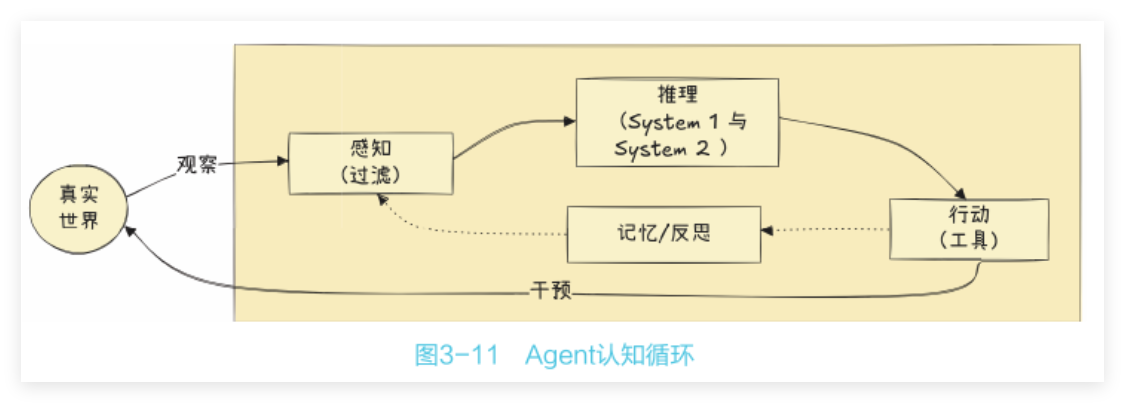
当感知、推理与行动首尾相连,形成闭环时,一种被称为“动力学涌现”的现象便发生了。这个循环不仅仅是简单的重复,而是每一次迭代都伴随着记忆的叠加,因此它在时间轴上呈现出螺旋式的上升过程。
Agent的“神奇效果”并非写在说明书里,而是在闭环运行中“跑”出来的;不是靠静态配置实现的,而是通过动态交互涌现而成的。这正是现代Agent最迷人,也最具工程性挑战的所在。
认知螺旋:OODA的软件化
军事战略家约翰·博伊德(John Boyd)提出了 OODA(Observe-Orient-Decide-
Act)循环,其核心步骤如下。
- Observe(观察):从环境中获取上下文。
- Orient(定位/整合记忆):结合长期记忆与既有认知,理解并判断当前局势。
- Decide(推理):基于当前理解,制订行动计划。
- Act(行动):执行决策,调用相应工具。
- Loop:行动改变了环境,从而触发新一轮的观察,形成持续演进的动态循环。 Agent的架构正是这一理论的软件实现。
而其中的关键在于Orient环节:在每次 OODA循环中,Agent 不仅执行任务,更在持续更新其内部的世界模型。
第一轮:我以为这是一个简单的 Python 脚本任务。
第二轮:运行报错,我发现需要安装依赖。
第三轮:依赖安装失败,我意识到这是环境权限问题。
Agent对世界的理解,随着循环的推进呈螺旋式上升——它在运行过程中“学会”了环境的特性,并据此不断调整策略与行为。
符号接地:治愈幻觉的良药
LLM最大的弱点是幻觉。为什么会产生幻觉?根本原因在于它是离身(Disembodied)的——它只见过“苹果”这个词,却从未真正触摸、观察或与真实的苹果互动过。而感知一行动循环正是解决这一问题的关键机制。
推理:我觉得柜子里有苹果。(这可能是幻觉。)
行动:打开柜子。
感知:柜子内空空如也。
修正:哦,原来没有。
在OODA循环中,现实世界成为最终的校验器。Agent通过与环境的碰撞(friction),将脑中的“符号”锚定于真实的“物理世界或数字状态”之上。循环越快,反馈越频繁,幻觉就越少。
时间的连续性:身份的诞生
传统程序是无时间性的——每次运行都如同第一次,并不携带过往经验。而对Agent而言,循环创造了“历史”:每次交互都累积为记忆,以塑造其后续的感知、推理与行动。
- 上一轮行动的失败,成为本轮感知的上下文。
- 上一轮推理的结论,沉淀为本轮可调用的长期记忆。
正是这种状态的连续累积,使Agent逐渐形成一种“自我感”——“我是在那个时
刻尝试过但失败了的实体”。身份并非预先设计,而是记忆在循环中不断沉淀、演化而生的产物。
代码视角的重构:生命周期的引擎
不要将 Agent 的循环实现为一个简单的whileTrue 死循环,而应将其设计为一个由
状态机驱动的引擎。
从“做完”到“活着”
传统软件的目标是“完成任务”,而Agent 的目标是“持续适应”。感知一推理一行动循环,就是 Agent 的“心跳”。一旦循环停止,Agent便会退化为静态的代码。唯有维持循环,代码才能获得在不确定世界中生存的能力。这正是循环的魔力所在:它将静态的逻辑转化为动态的智能。至此,所有复杂智能的特征——学习、策略调整、预判、意图识别以及自我意识的雏形——并非设计而成,而是通过感知一推理一行动循环,在经历数万次的迭代后,系统内部发生了奇妙的变化,沉淀出了4种“灵魂特质”(见图3-13)。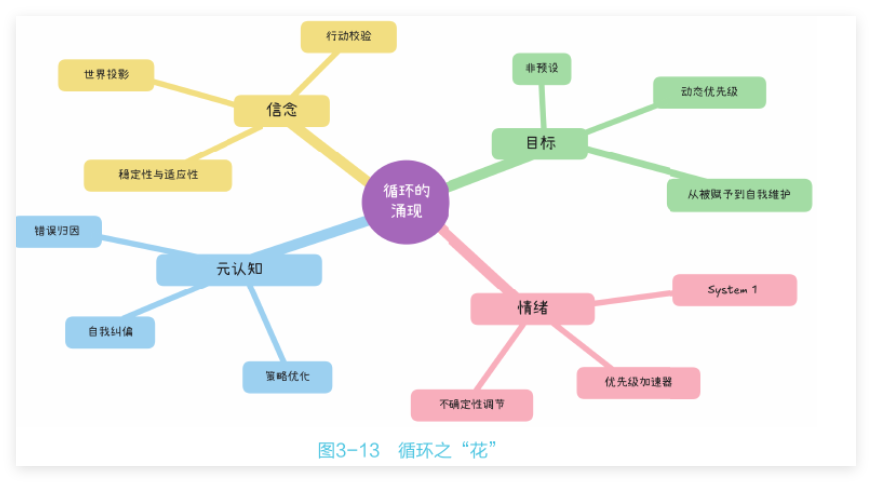
- 信念(Belief):是对世界模型的累积。每一轮感知都会更新 Agent 对世界的认 知缓存;推理依赖这一模型,行动则用于验证它。
- 目标(Goal):将从静态走向动态演化——不再是 Prompt 中的常量,而是一个
动态优先级队列。推理可能提出新目标,行动结果可能淘汰旧目标,情境变化则 会刷新目标的优先级。 - 情绪(Emotion):是 System 1的调节阀,其本质上是一种对环境变化的快速
反应机制,而非多愁善感。当不确定性升高时,触发焦虑(转向保守策略);当 连续成功时,激发自信(增强探索倾向):当遭遇异常输入时,产生惊奇(提升 注意力权重)。 - 元认知(Meta-cognition):是“对思考的思考”,指系统对自身认知过程与历
历史轨迹的审视与优化。经验被写入记忆,并反过来影响下一轮推理。
有趣的是,这里的循环并非简单重复,而是持续生成。正如神经科学所揭示的:智能并非能力的堆砌,而是循环动力学的产物。Agent的认知亦是如此。
当这些循环变得足够复杂、足够精细、足够自主时,我们便不再称其为“程序”,而称之为“心智”。
具身认知:身体塑造心智
感知一推理一行动循环并非在虚空中运行,而是需要依托某种载体,即我们所说的
“身体”(Body)——即便虚拟环境中的身体也是如此。
在认知科学领域,有一个核心观点被称为“具身认知”(EmbodiedCognition),如
图3-14所示。该理论认为,心智不仅是大脑的产物,更是身体与外界环境互动的结果。身体的物理结构、能力边界以及能量消耗等因素,直接塑造了智能的表现形式。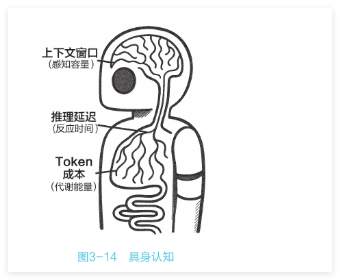
Agent的具身:数字约束
对运行在服务器上的Agent而言,其“身体”由算力、带宽、上下文窗口和资金构
成。这些“数字生理特征”深刻影响着Agent 的思考方式。
上下文窗口是它的“视网膜”:它无法容纳无限的历史信息,必须学会“遗忘”
(Memory Consolidation)和“聚焦”(Attention),将宝贵的 Token 分配给最关键的内容。这正如人类因无法记住所有细节,才演化出“做笔记”的习惯。
- 推理延迟是它的“神经传导速度”:思考需要时间。在实时交互场景(如语音助手)中,Agent 被迫依赖“快思考”(System 1),以快速响应用户需求;而在离线任务(如编写代码)中,Agent则可以启用更深入、更审慎的“慢思考”
(System 2),以确保任务的准确性和完整性。 - Token成本是它的“代谢能量”:每次调用GPT-4都会产生费用。这迫使Agent必须“节能”—能用搜索解决的问题,就不动用推理;能用小型模型完成的任务,就不调用大型模型。
Agent不再是一个单纯的逻辑循环,而是一个资源受限条件下的优化问题。
具身性的哲学意义
之所以强调具身性,是因为限制正是创造力的源泉。倘若一个Agent拥有无限的上下文容量、无限的推理速度和无限的算力,它便不需要发展出真正的“智能”——只需要通过暴力穷举所有可能性即可解决问题。正是因为“身体”的限制,Agent才被迫发展出以下能力。
- 抽象:压缩信息,节省上下文空间。
- 规划:减少冗余步骤,提升行动效率。
- 启发式策略:降低计算开销,在有限算力下快速决策。
身体并非心智的容器,而是心智的模具。它从根本上塑造了Agent感知世界、理解
问题并生成解决方案的方式。
在本节中,我们揭示了Agent的动力学原理。它并非一个静态的输入一输出黑盒,
而是一个随时间持续展开的感知一推理一行动循环。
- 感知让它看见世界。
- 推理让它理解情境。
- 行动让它施加改变。
循环让它持续演化、生生不息。正是这一具身化的循环,正在重新定义软件的未来。感知一推理一行动循环不仅是一种技术架构,更蕴含着深刻的哲学洞见。
- 存在即循环:Agent的存在并非静态的“状态”,而是持续进行的动态过程。它 因循环而存在——一旦循环终止,其存在也随之消解。
- 认知即预测:每一个循环本质上都是对未来的预测。预测与现实之间的误差驱动 学习,而学习又不断优化后续的预测,形成认知演进的核心机制。
- 智能即适应:循环赋予Agent适应环境的能力——环境的变化触发新的感知,新
的感知激发新的推理,新的推理又导向新的行动,从而形成持续演化的适应性 行为。 - 自主即闭环:真正的自主性源于感知一推理一行动的完整闭环。只有当Agent
能够感知自身行动的后果,并据此动态调整未来策略时,才称得上具备自主性。
感知一推理一行动循环是智能的心跳。每一个循环,都是一次微小的觉醒;而无数个循环的累积,则构成了我们所称的“智能”的奇迹。
然而,一个孤立的循环是脆弱的。当任务过于复杂,超出单个循环的承载能力时,仅靠个体已难以为继。此时,我们需要将多个循环连接起来,编织成一张协同的网络。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 5
5 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)