【python因果库实战29】LaLonde 数据集2

评估模型和数据
%matplotlib inline
from causallib.evaluation import evaluate
from matplotlib import pyplot as plt
plots = ["covariate_balance_love", "weight_distribution"]
evaluation_results = evaluate(ipw, X, a, y)
f, [a0, a1] = plt.subplots(2, 1, figsize=(10, 12))
evaluation_results.plot_covariate_balance(kind="love", ax=a0)
evaluation_results.plot_weight_distribution(ax=a1)
plt.suptitle("Evaluation on train phase")
Text(0.5, 0.98, 'Evaluation on train phase')
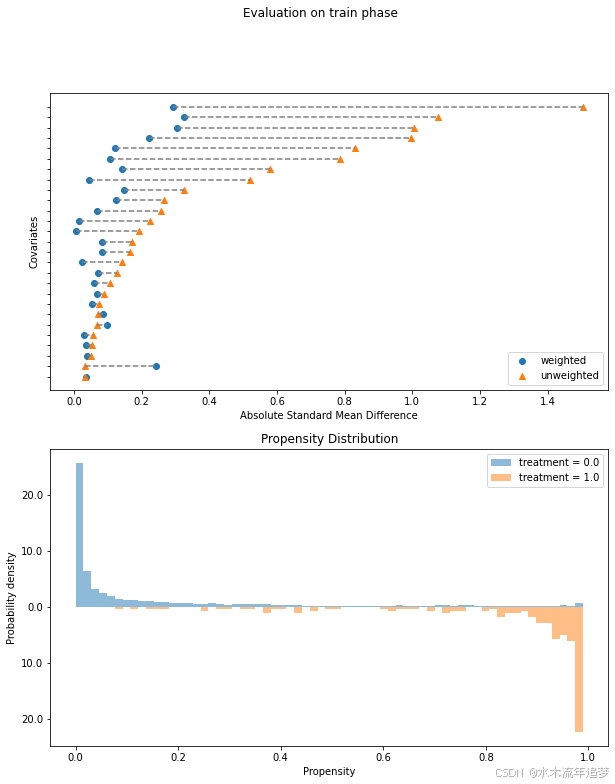
从协变量平衡图(顶部)我们可以看出许多特征在经过处理组和未经处理组之间存在严重的偏差,特别是黑人、1974年的收入、1975年的收入和婚姻状况。
从倾向分布图(底部)我们可以看到模型几乎能够确定谁将接受培训,谁将不会接受培训。这表明存在正则性问题,即存在无法比较的人群,因为他们实际上从未有机会接受其他处理。
解决正则性违规
在这种情况下,我们需要调查是什么原因导致正则性的缺失,并相应地调整数据。在 Dehejia 等人的原始论文中,他们简单地去除了低倾向性的个体,那里明显缺乏正则性(完全没有经过处理的个体)。这种方法的问题在于我们正在去除数据的一部分,而不了解这部分数据的特点。值得注意的是,通过去除部分数据,我们的结果仅限于剩余的数据,但如果不对去除的部分进行特征描述,我们可能会错误地认为我们的结论适用于整个群体,而实际上并非如此。
因此,让我们首先尝试识别这些个体可能是谁,并以一种能够说明谁被去除的方式来修正数据。
为此,我们可以使用决策树来分类我们希望去除的对象:
min_val = min(ipw.compute_propensity_matrix(X[a==1])[1])
violating = pd.Series(ipw.compute_propensity_matrix(X)[1] < min_val).rename("")
min_val
0.08907564222882582
from sklearn import tree
import matplotlib.pyplot as plt
plt.figure(figsize=(20,5))
dtc = tree.DecisionTreeClassifier(max_depth=3)
dtc.fit(X, violating)
details = tree.plot_tree(dtc, filled=True, feature_names=X.columns, impurity=False)

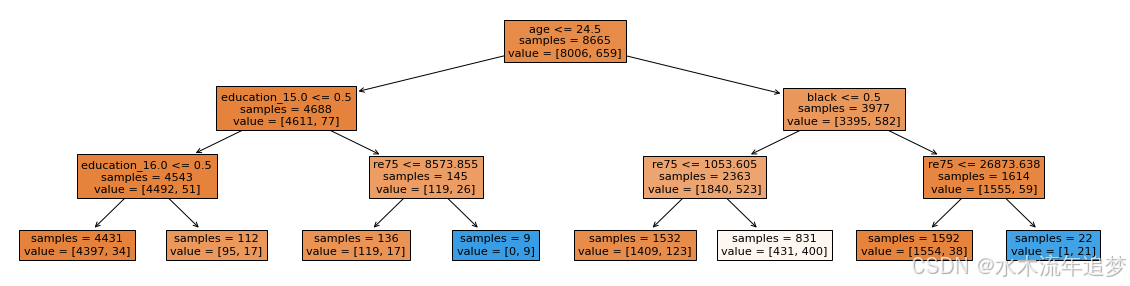
在决策树的根节点,我们可以看到有13704个个体被正确识别为永远不会接受培训的人。尽可能多的这类个体应当从分析中去除。其中一大类个体(蓝色矩形)是那些1975年收入超过8263美元、不是黑人、年龄大于21岁的人。
new_a = (X["re75"]>8263) & (X["black"]==0) & (X["age"] > 21)
new_a = pd.Series(new_a, name="to_remove")
pd.concat({
"violation": pd.crosstab(new_a, violating),
"treated": pd.crosstab(new_a, a)},
axis="columns"
)
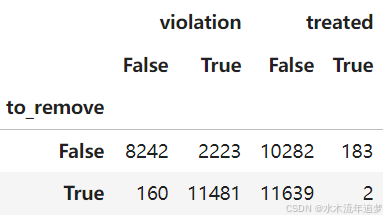
确实,使用这种分类方法,我们将正确地去除11641个人。其中只有2个人接受了培训,11481人属于正则性违规的人群,但也去除了160个不属于该人群的人。
通过调整阈值(我们使用的决策树针对基尼指数进行了优化,而不是针对正则性识别,因此我们有权进行调整),我们可以得到更具体的去除。通过重复这一分析(这里没有显示),我们确定了几个可以去除的额外人群。下面是将不会纳入分析的人群总结: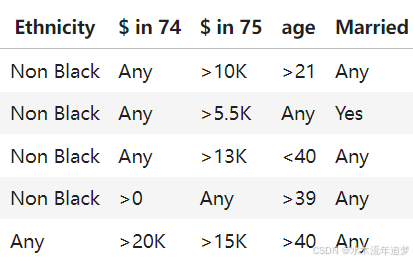
这些规则可能是由于接受人们进入 NSW 计划的指导方针或是因为申请此类计划的人们固有的差异。无论如何,使用一般调查的全体人口进行比较并不公平。让我们据此减少样本队列:
new_a = (X["re75"]>10000) & (X["black"]==0) & (X["age"] > 21)
new_a = new_a | ((X["re75"]>5500) & (X["black"]==0) & (X["married"]==1))
new_a = new_a | ((X["age"]<40) & (X["black"]==0) & (X["re75"]>13000))
new_a = new_a | ((X["age"]>=40) & (X["black"]==0) & (X["re74"]>0))
new_a = new_a | ((X["age"]>40) & (X["re74"]>20000) & (X["re75"]>15000))
new_a = pd.Series(new_a, name="to_remove")
pd.concat({
"violation": pd.crosstab(new_a, violating),
"treated": pd.crosstab(new_a, a)},
axis="columns"
)
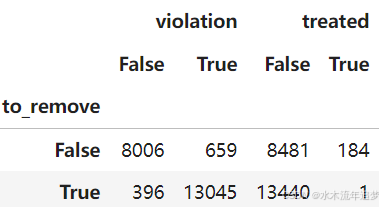
因此,我们能够去除13704个似乎属于正则性违规人群中的13045人,而误去除了396个不属于该人群的人。此外,我们只去除了一个真正接受了培训的人。最终,仍有659人属于正则性违规人群并且没有被去除。
因此,我们定义了一个基于规则的模型,该模型以95.2%的召回率和97%的精确度表征了正则性违规的人群。
尽管这可以进一步改进,但我们将继续使用这个模型。
X2, a2, y2 = X.loc[~new_a, :], a[~new_a], y[~new_a]
violating2 = pd.Series(ipw.compute_propensity_matrix(X2)[1] < min_val).rename("")
plt.figure(figsize=(20,5))
dtc = tree.DecisionTreeClassifier(max_depth=3)
dtc.fit(X2, violating2)
details = tree.plot_tree(dtc, filled=True, feature_names=X2.columns, impurity=False)
更多的轮次并没有提供大量可以去除的具体人群,因此我们将在这里停止迭代,并重新运行分析。
X2, a2, y2 = X2.loc[~violating2, :], a2[~violating2], y2[~violating2]
ipw2 = IPW(learner)
ipw2.fit(X2, a2)
outcomes2 = ipw2.estimate_population_outcome(X2, a2, y2)
effect2 = ipw2.estimate_effect(outcomes2[1], outcomes2[0])
print(f"The average earnings with training are ${outcomes2[1]:.2f}", \
f"and without training ${outcomes2[0]:.2f}.")
print(f"This translates to an effect of ${effect2[0]:.2f}")
plots = ["covariate_balance_love", "weight_distribution", "roc_curve"]
evaluation_results2 = evaluate(ipw2, X2, a2, y2, plots=plots)
evaluation_results2.plot_all()
plt.tight_layout()
The average earnings with training are $6894.84 and without training $6367.23.
This translates to an effect of $527.60
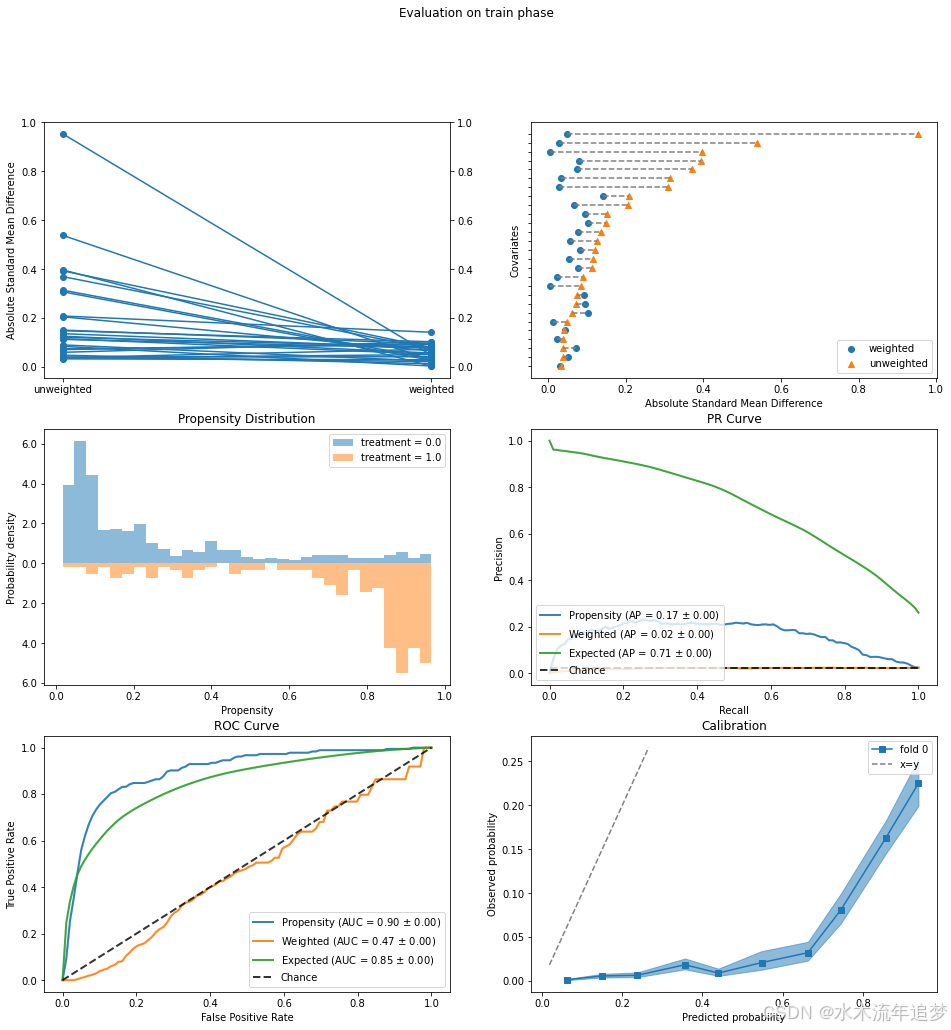
这样看起来好多了。现在我们能够平衡所有特征(左上角)。倾向分布(右上角)没有显示出严重的正则性违规(尽管我们知道从前一分析中仍有一些违规存在)。ROC曲线(左下角)显示仍然有一点正则性违规,因为AUC略高,但重要的是,加权曲线显示总体平衡相当好,因为它接近于所需的随机对角线。
此外,我们现在可以看到培训有一个微小的正面效果。
结论
我们看到,在分析中添加大量数据不一定有助于分析,事实上存在不应包括在分析中的数据。倾向性评估允许识别哪些数据应包括在内,哪些不应包括在内。
最终,我们使用全部数据集得到的估计结果显示,培训对学员的收入潜力影响很小。
与 Dehejia 和 Wahba 的论文相比,他们在论文中识别出约1700美元的影响(使用 causallib 重现他们的结果可在此处找到),我们只能得出结论,他们使用的对照组并不代表总体人群,并且包含了收入极低的人。有可能对被他们移除以得出结论的人群进行进一步的特征描述将有助于更好地理解差异。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 2
2 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)