Anomaly Detection系列(CVPR2025 MANTA论文解读)
MANTA: A Large-Scale Multi-View and Visual-Text Anomaly Detection Dataset for Tiny Objects
无监督视觉-文本异常检测旨在识别微小物体中的罕见缺陷,尤其适用于农业、医药等领域。当前方法面临三大核心挑战:
- 依赖单视角成像:传统方法仅能从单一角度采集图像,难以覆盖微小物体完整表面;
- 缺乏语义引导的检测能力:现有模型无法结合自然语言描述进行推理,导致对复杂异常特征理解不足;
- 无法处理异构样本和姿态不确定性:由于微小物体形状、颜色、纹理高度可变且姿态不可控,主流方法易产生误检或漏检。

本文提出MANTA数据集,在137K多视角图像基础上引入两类文本组件(声明性知识与建构主义学习),并通过BLIP-2基线模型在视觉-语言任务中实现AUROC达79.3%,显著优于WinCLIP等零样本方法(+3.6%)。
核心贡献
本文核心贡献如下:
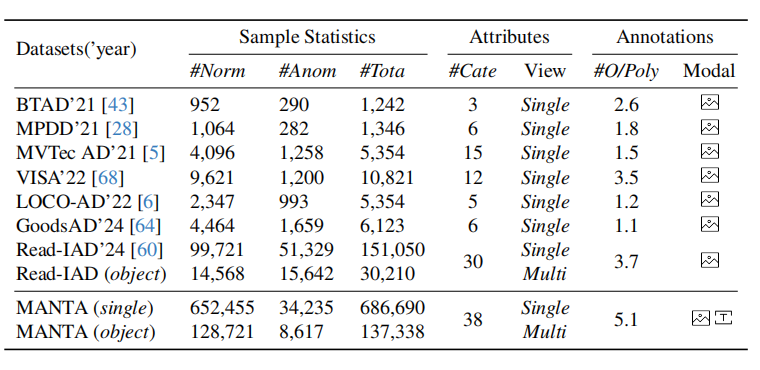
- 首个面向微小对象的大规模多视图视觉-文本异常检测数据集,包含超过137K五视角图像,涵盖五个领域共38类物品;
- 构建两套互补的文本子集:声明性知识提供⟨what, why, how⟩三级异常描述;建构主义学习提供2K带解释的多项选择题,支持细粒度推理;
- 提出基于BLIP-2的视觉-语言基线模型,采用LoRA微调策略,在ConsL任务中达到选项准确率52.7%,高于LLaVA系列模型;
- 系统评估多种设置下的性能表现:包括单视角、多视角、多类别、文本提示及视觉-语言联合训练,揭示当前方法在微小对象异常检测中的瓶颈;
- 量化验证文本增强的有效性:在DeclK文本提示下,WinCLIP平均I-AUROC提升至75.2%,表明文本信息有助于提高检测鲁棒性。
相关工作综述
(一) 数据集局限性
现有方法主要包括:[MVTec AD](如[MVTec]),其核心思想是使用高分辨率工业图像进行缺陷定位,但局限在于仅限于大型规则结构物体及静态图结构无法捕获微小对象多面细节。
→ 本文改进:引入五视角成像系统,确保全面覆盖微小对象表面,同时标注像素级异常区域。
(二) 异常检测设定限制
现有方法主要包括:[PromptAD](如[PromptAD]),其核心思想是利用预训练视觉-语言模型结合文本提示完成少样本检测,但局限在于无法应对自然对象的异质性和尺寸敏感性。
→ 本文改进:通过DeclK提供结构化文本描述,结合ConsL引导模型进行跨模态推理,提升对非标准形态异常的理解力。
(三) 多视角建模缺失
现有方法主要包括:[Real-IAD](如[Real-IAD]),其核心思想是对同一物体多个视角分别建模,但局限在于缺乏统一视角融合机制和未能充分利用空间一致性约束。
→ 本文改进:设计统一的对象级表示方式,整合五个视角的信息,强化全局上下文感知能力。
方法论详解
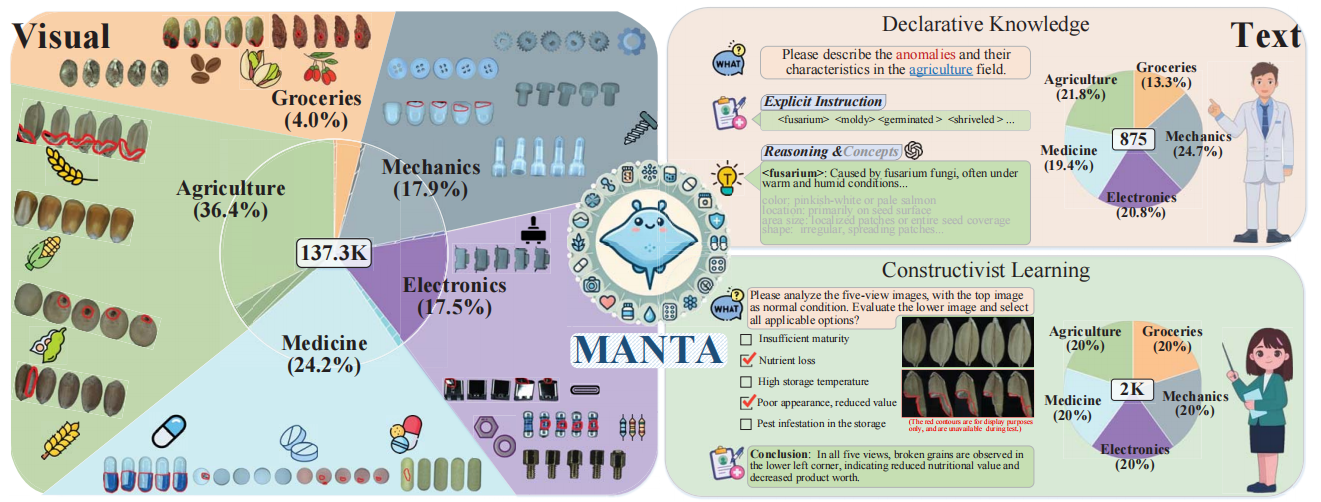
1. 多视角图像采集系统
- - 功能:用于获取微小物体全方位表面信息。
- - 机制:配备五个高分辨率摄像头(四个倾斜俯拍 + 底部仰拍),辅以无影光源保证光照均匀。
- - 动机:相比单视角采集,该系统能够有效规避遮挡问题,提升异常覆盖率,尤其适合表面不规则的小型物体。
推测局限:对于具有复杂几何结构的对象(如螺母六角面),仍可能存在局部盲区。
2. 声明性知识文本库(DeclK)
- - 功能:用于提供结构化的异常定义与因果解释。
- - 机制:按领域划分,每项异常由名词/形容词表示,并配有成因(reasoning)与视觉属性(concepts)说明。
- - 动机:弥补纯视觉方法在语义表达上的短板,使模型具备更强的概念抽象能力和泛化潜力。
推测局限:文本描述虽详尽,但在实际应用中需人工校准与更新,维护成本较高。
3. 建构主义学习模块(ConsL)
- - 功能:用于模拟人类通过比较判断异常的学习过程。
- - 机制:提供成对图像(正常-正常 / 正常-异常)及对应的选择题,要求模型做出判断并给出理由。
- - 动机:契合双编码理论,鼓励模型同步处理视觉与语言信号,增强跨模态关联能力。
推测局限:当前模型在难例上表现不佳,主要受限于预训练视觉编码器与特定领域的分布偏差。
实验与验证
效率分析:
- - 使用LoRA微调后,参数量减少约60%,显著降低计算负担;
- - 在ConsL任务中,基线模型相较LLaVA系列在选项准确率上有明显优势(+5.3pp)。
消融实验:
- - 移除DeclK文本提示 → I-AUROC ↓ 7.9%
- - 移除ConsL问答结构 → 选项准确率 ↓ 12.1%
性能提升归因:
- - 多视角输入增强了空间一致性,提升了小异常的可见性;
- - 文本辅助提高了模型对异常类型的认知精度;
- - ConsL任务促使模型建立更深层次的视觉-语言映射关系。
结论与展望
贡献总结:
- 构建首个大规模多视角视觉-文本异常检测数据集MANTA;
- 提出DeclK与ConsL两种文本形式,丰富异常检测语义层次;
- 验证多视角与文本协同在微小对象检测中的有效性。
未来方向:
- 探索动态阈值自适应调整以优化异常判定边界;
- 发展轻量化多视角特征融合网络,适配边缘部署需求;
- 扩展文本子集规模,引入更多专家知识与交互式标注工具;
- 设计更具挑战性的视觉-语言推理任务,推动通用异常检测模型发展。
局限性:
- 当前原型设备存在部分视角盲区,影响某些几何结构复杂的对象检测完整性;
- 文本数据量相对有限,尚未形成闭环反馈机制,需进一步扩展与迭代优化。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 11
11 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)