第二篇:为什么AI能“读懂“新闻?——用登月任务讲透文本向量化
-
为什么AI能"读懂"新闻?——用登月任务讲透文本向量化
-
AI是怎么理解文字的?从阿尔忒弥斯2号说起
-
电脑不认识字,但它认识数字——文本向量化入门
-
Go语言实现文本向量化:从原理到代码
-
手把手教你实现文本向量化(Go语言版)
-
文本向量化五步法:Go语言完整实现
-
用阿尔忒弥斯2号讲透AI文本理解原理
-
登月任务背后的AI技术:文本向量化入门
-
从阿尔忒弥斯2号看AI如何理解人类语言
-
文本向量化原理与Go语言实现
-
词频向量与L2归一化:原理、实现与应用
-
基于Go语言的文本向量化算法详解
本文用最通俗的语言,带你理解AI如何将文字变成数字。读完这篇,你也能亲手实现一个简单的文本向量化程序。

一、先问你一个问题
你有没有想过:
为什么你在百度搜"最近的登月计划",它真的能给你推荐阿尔忒弥斯2号的消息?
电脑又不认识汉字,它怎么知道你在问什么?
秘密只有一个:电脑不认识字,但它认识数字。
所以,我们需要把文字变成数字。这个过程,叫做**"文本向量化"**。
听起来很高级?别急,我们用一个真实的登月故事来讲清楚。
二、这个登月任务有多酷?
在讲技术之前,先说说为什么我们用阿尔忒弥斯2号来举例。
你可能觉得:登月?不是几十年前就有人上去过了吗?
但阿尔忒弥斯2号不一样:
它是50多年来,人类第一次飞得这么远。
具体有多远?给你一个直观的感受:
| 目标 | 距离地球 |
|---|---|
| 国际空间站 | 约400公里 |
| 阿尔忒弥斯2号 | 约40万公里 |
差了整整1000倍!
这次任务有几个特别的地方:
第一次有女性宇航员参与绕月飞行
第一次有黑人宇航员参与深空任务
不着陆,只绕着月球飞一圈,为以后着陆做准备
最酷的是:宇航员会从月球背面看地球升起。
想象一下,你站在月球背面,抬头看到一个蓝色的地球,从月球地平线上慢慢升起来。这个画面,人类已经50多年没见过了。
所以网上的新闻才会这么多,大家都在讨论这件事。而我们的任务,就是让AI能够"读懂"这些新闻。
三、向量化的核心思想
在开始写代码之前,我们先理解一个核心概念:
什么是向量?
听起来很高大上,其实就是一串有顺序的数字。
比如:[1, 0, 1, 0, 1] 就是一个向量。
什么是文本向量化?
就是把一段文字,变成一串数字。
比如把"我喜欢吃苹果"变成 [1, 0, 1, 0, 1]。
这串数字代表了什么?我们一步步来看。
四、五步流程详解
我们用一个真实的例子来演示整个流程。
4.1 准备工作:定义知识库和词汇表
// 知识库:关于阿尔忒弥斯2号的新闻片段
var knowledgeBase = []string{
"阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步",
"该任务将使用太空发射系统火箭和猎户座飞船,搭载宇航员进行绕月飞行",
"阿尔忒弥斯2号的主要目标是测试生命支持系统和宇航员在深空环境中的生存能力",
"任务计划在2025年执行,将是自阿波罗17号以来首次载人离开地球轨道的任务",
"此次飞行将为后续的阿尔忒弥斯3号月球着陆任务提供关键数据和技术验证",
"宇航员将在飞行过程中进行科学实验,并测试深空通信和导航系统",
"任务将持续约10天,飞行距离将达到27万英里,是地球到月球距离的10倍以上",
"阿尔忒弥斯2号的成功将为建立月球基地和未来火星探索奠定基础",
}
// 词汇表:我们关心的10个关键词
var vocab = []string{"阿尔忒弥斯", "月球", "任务", "宇航员", "火箭", "飞船", "测试", "系统", "飞行", "轨道"}词汇表的作用:它决定了我们向量的维度。这里有10个词,所以最终的向量有10个数字。
4.2 文本清洗:去掉噪音
// 文本清洗函数(修正版)
func cleanText(text string) string {
// 清洗:只保留中文字符,去掉空格、回车、换行、TAB等
var cleaned strings.Builder
for _, r := range text {
// 只保留中文字符范围
if r >= 0x4e00 && r <= 0x9fff {
cleaned.WriteRune(r)
}
// 空格(0x20)、TAB(0x09)、换行(0x0A)、回车(0x0D)等都不保留
}
return cleaned.String()
}文本清洗就是去掉不需要的字符,如标点符号、数字等"噪音",只保留中文字符。示例如下:
step0:原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
step1:清洗后: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步从上面的示例中,我们看到数字"2"和标点符号(如,)都被去掉了。
4.3 分词处理:找出包含的关键词
// 分词函数(修正版)
func tokenize(text string, vocab []string) []string {
var tokens []string
// 直接在文本中查找词汇表中的词
for _, vocabWord := range vocab {
// 统计该词在文本中出现的次数
count := strings.Count(text, vocabWord)
// 出现几次,就添加几次
for i := 0; i < count; i++ {
tokens = append(tokens, vocabWord)
}
}
return tokens
}分词处理目的:从清洗后的文本中,找出词汇表里包含的关键词。示例结果如下:
step0:原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
step1:清洗后文本: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步
step2:提取关键词: [阿尔忒弥斯 月球 轨道 飞行 任务 月球]上面的示例中与词汇表(vocab)10个关键词相比较,可以找出“阿尔忒弥斯 月球 轨道 飞行 任务 月球”这几个关键词构成的token,其中"月球"出现了2次("月球轨道"和"重返月球")。
4.4 词频统计:统计token出现的次数
// 词频统计函数
func countFrequency(tokens []string) map[string]int {
freq := make(map[string]int)
for _, token := range tokens {
freq[token]++
}
return freq
}词频统计是为了统计每个关键词token出现的次数。根据提取后的关键词结果数组,统计获得“阿尔忒弥斯: 1次”,“月球: 2次”,“任务: 1次”,“飞行: 1次”,“轨道: 1次”,其他的宇航员/火箭/飞船/测试/系统都是零次。
step0:原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
step1:清洗后文本: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步
step2:提取关键词: [阿尔忒弥斯 月球 轨道 飞行 任务 月球]
step3:词汇表: [阿尔忒弥斯, 月球, 任务, 宇航员, 火箭, 飞船, 测试, 系统, 飞行, 轨道]
针对上面的每个关键词,词频统计结果:
阿尔忒弥斯: 1次
月球: 2次
任务: 1次
宇航员: 0次
火箭: 0次
飞船: 0次
测试: 0次
系统: 0次
飞行: 1次
轨道: 1次
4.5 构建向量:把词频按词汇表顺序排成一串数字
// 构建向量函数
func buildVector(freq map[string]int, vocab []string) []float64 {
vector := make([]float64, len(vocab))
for i, word := range vocab {
vector[i] = float64(freq[word])
}
return vector
}词汇表: [阿尔忒弥斯, 月球, 任务, 宇航员, 火箭, 飞船, 测试, 系统, 飞行, 轨道]
针对上面词汇表里面的每个关键词,词频统计结果(每个关键词出现的次数):
阿尔忒弥斯: 1次
月球: 2次
任务: 1次
宇航员: 0次
火箭: 0次
飞船: 0次
测试: 0次
系统: 0次
飞行: 1次
轨道: 1次
按词频统计结果及顺序,将关键词出现的次数和顺序写成一行:
【1:阿尔忒弥斯,2:月球,1:任务,0:宇航员,0:火箭,0飞船,0测试,0系统,1飞行,1轨道】
去掉汉字精简后的向量(即数据集):
[1.0, 2.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0]
向量里面的数据为啥用小数表示(浮点数),因为向量计算时候的数据类型,一般都是浮点型(float)。
step0:原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
step1:清洗后文本: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步
step2:词频统计结果:【1:阿尔忒弥斯,2:月球,1:任务,0:宇航员,0:火箭,0飞船,0测试,0系统,1飞行,1轨道】
step4:词汇表及向量:
词汇表: [阿尔忒弥斯, 月球, 任务, 宇航员, 火箭, 飞船, 测试, 系统, 飞行, 轨道]
向量: [1.0, 2.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0] //出现的次数| 向量索引 | 词汇 | 值 | 含义 |
|---|---|---|---|
| 0 | 阿尔忒弥斯 | 1.0 | 出现1次 |
| 1 | 月球 | 2.0 | 出现2次 |
| 2 | 任务 | 1.0 | 出现1次 |
| 3-7 | 宇航员/火箭/飞船/测试/系统 | 0.0 | 未出现 |
| 8 | 飞行 | 1.0 | 出现1次 |
| 9 | 轨道 | 1.0 | 出现1次 |
| 总和 | 6.0 | ||
4.6 向量归一化
归一化就是让向量"长度"变为1(小于等于1),方便后续比较。
// 向量归一化函数
func normalize(vector []float64) {
sum := 0.0
for _, v := range vector {
sum += v * v
}
if sum == 0 {
return
}
magnitude := math.Sqrt(sum)
for i := range vector {
vector[i] /= magnitude
}
}为什么要归一化?如果一篇文章有1000字,"月球"出现10次;另一篇文章有100字,"月球"出现5次。直接比较的话,第一篇文章的数字更大,但实际上第二篇文章讲月球讲得更多。归一化就是为了解决这个问题:把所有向量"缩放"到同一个标准。归一化的过程是先将原始向量元素进行次方,然后求和后开根,然后拿元素值去除以开根后的结果。
step0:原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
step1:清洗后文本: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步
step2:词频统计结果:【1:阿尔忒弥斯,2:月球,1:任务,0:宇航员,0:火箭,0飞船,0测试,0系统,1飞行,1轨道】
step4:词汇表及向量:
词汇表: [阿尔忒弥斯, 月球, 任务, 宇航员, 火箭, 飞船, 测试, 系统, 飞行, 轨道]
原始向量: [1.0, 2.0, 1.0, 0.0, 0.0, 0.0, 0.0, 0.0, 1.0, 1.0] //出现的次数
模长: √(1² + 2² + 1² +0 +0 +0 +0 +0 + 1² + 1²) = √8 ≈ 2.828
归一化向量: [0.354, 0.707, 0.354, 0, 0, 0, 0, 0, 0.354, 0.354]
4.7 完整代码
package main
import (
"fmt"
"math"
"strings"
)
// ==================== 数据定义 ====================
// 知识库:关于阿尔忒弥斯2号的新闻片段
var knowledgeBase = []string{
"阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步",
"该任务将使用太空发射系统火箭和猎户座飞船,搭载宇航员进行绕月飞行",
"阿尔忒弥斯2号的主要目标是测试生命支持系统和宇航员在深空环境中的生存能力",
"任务计划在2025年执行,将是自阿波罗17号以来首次载人离开地球轨道的任务",
"此次飞行将为后续的阿尔忒弥斯3号月球着陆任务提供关键数据和技术验证",
"宇航员将在飞行过程中进行科学实验,并测试深空通信和导航系统",
"任务将持续约10天,飞行距离将达到27万英里,是地球到月球距离的10倍以上",
"阿尔忒弥斯2号的成功将为建立月球基地和未来火星探索奠定基础",
}
// 词汇表:我们关心的10个关键词
var vocab = []string{"阿尔忒弥斯", "月球", "任务", "宇航员", "火箭", "飞船", "测试", "系统", "飞行", "轨道"}
// ==================== 五个核心函数 ====================
// 文本清洗函数
func cleanText(text string) string {
// 简单清洗:保留中文字符和空格
var cleaned strings.Builder
for _, r := range text {
if (r >= 0x4e00 && r <= 0x9fff) || r == ' ' {
cleaned.WriteRune(r)
}
}
return cleaned.String()
}
// 分词函数
func tokenize(text string, vocab []string) []string {
var tokens []string
// 直接在文本中查找词汇表中的词
for _, vocabWord := range vocab {
count := strings.Count(text, vocabWord)
for i := 0; i < count; i++ {
tokens = append(tokens, vocabWord)
}
}
return tokens
}
// 词频统计函数
func countFrequency(tokens []string) map[string]int {
freq := make(map[string]int)
for _, token := range tokens {
freq[token]++
}
return freq
}
// 构建向量函数
func buildVector(freq map[string]int, vocab []string) []float64 {
vector := make([]float64, len(vocab))
for i, word := range vocab {
vector[i] = float64(freq[word])
}
return vector
}
// 向量归一化函数
func normalize(vector []float64) {
sum := 0.0
for _, v := range vector {
sum += v * v
}
if sum == 0 {
return
}
magnitude := math.Sqrt(sum)
for i := range vector {
vector[i] /= magnitude
}
}
// ==================== 主函数 ====================
func main() {
fmt.Println("词频向量化五步执行流程演示")
fmt.Println("==========================")
// 选择第一个知识片段进行演示
text := knowledgeBase[0]
fmt.Printf("原始文本: %s\n\n", text)
// 步骤1: 文本清洗
cleanedText := cleanText(text)
fmt.Printf("步骤1 - 文本清洗: %s\n", cleanedText)
// 步骤2: 分词处理
tokens := tokenize(cleanedText, vocab)
fmt.Printf("步骤2 - 分词处理: %v\n", tokens)
// 步骤3: 词频统计
freq := countFrequency(tokens)
fmt.Printf("步骤3 - 词频统计: %v\n", freq)
// 步骤4: 向量构建
vector := buildVector(freq, vocab)
fmt.Printf("步骤4 - 向量构建: %v\n", vector)
// 步骤5: 向量归一化
normalize(vector)
fmt.Printf("步骤5 - 向量归一化: %v\n", vector)
fmt.Println("\n词频向量化完成!")
}预估运行结果:
词频向量化五步执行流程演示
==========================
原始文本: 阿尔忒弥斯2号是美国宇航局计划中的载人月球轨道飞行任务,标志着人类重返月球的重要一步
步骤1 - 文本清洗: 阿尔忒弥斯号是美国宇航局计划中的载人月球轨道飞行任务标志着人类重返月球的重要一步
步骤2 - 分词处理: [阿尔忒弥斯 月球 轨道 飞行 任务 月球]
步骤3 - 词频统计: map[月球:2 任务:1 飞行:1 轨道:1 阿尔忒弥斯:1]
步骤4 - 向量构建: [1 2 1 0 0 0 0 0 1 1]
步骤5 - 向量归一化: [0.3535533905932738 0.7071067811865475 0.3535533905932738 0 0 0 0 0 0.3535533905932738 0.3535533905932738]
词频向量化完成!五、后记(有很多图和公式画不出来,最好是不要看这个章节)
5.1 什么是向量归一化?
归一化就是:不管向量多长多短,都把它"缩"到长度为1的标准线上,只保留方向信息。
在深入理解归一化之前,我们先理解什么是向量。向量是什么?向量是一串有顺序的数字,可以表示方向和大小。用一个二维向量 [3, 4] 来举例,它可以在坐标系上画出来:
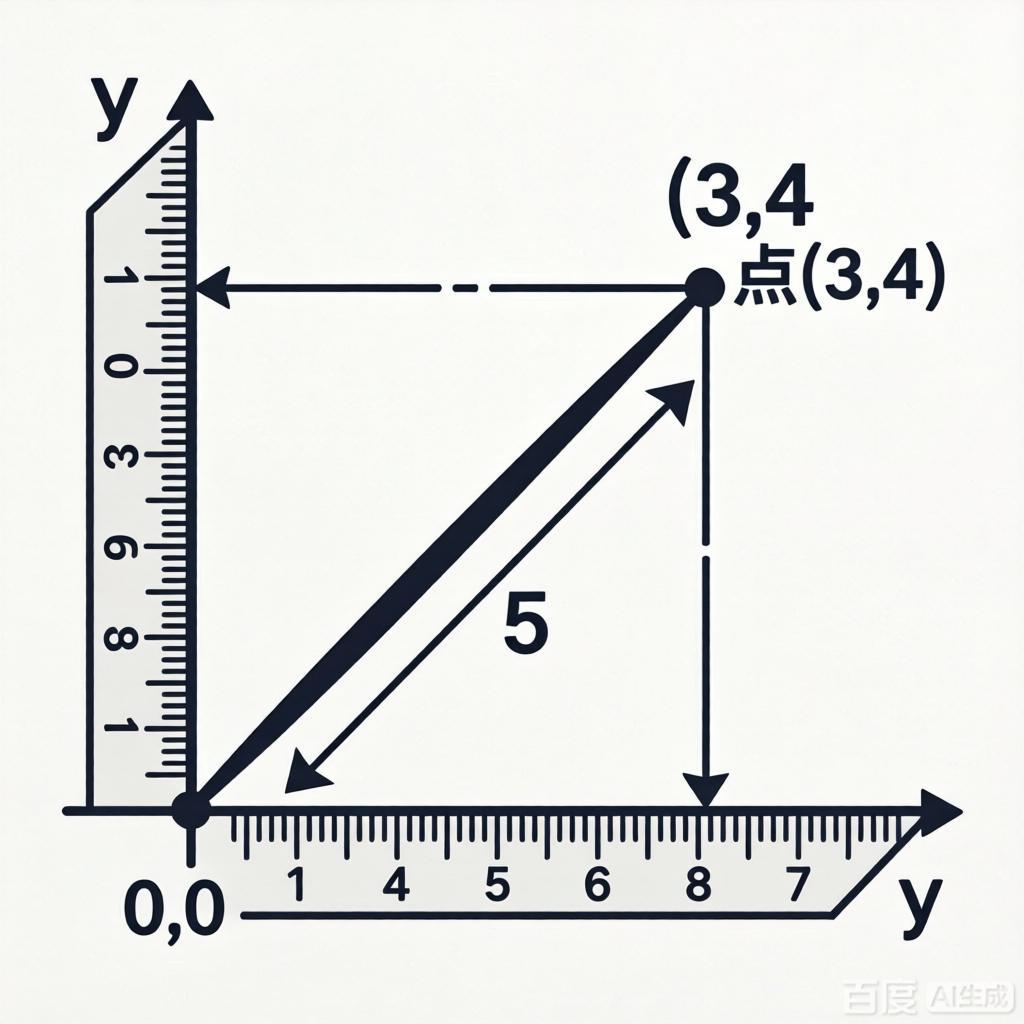
这个向量从原点(0,0)指向点(3,4),它的"长度"是 √(3² + 4²) = 5
5.2 什么是"单位圆"?
单位圆就是半径为1的圆,圆心在原点。
5.3 什么是"缩放到单位圆上"?
就是把向量的"箭头"沿着原来的方向,缩短或拉长,直到它刚好落在单位圆上。
5.4 计算过程
原始向量: [3, 4]
长度: √(3² + 4²) = √25 = 5
归一化:每个元素除以长度
3 ÷ 5 = 0.6
4 ÷ 5 = 0.8
结果: [0.6, 0.8]
验证长度: √(0.6² + 0.8²) = √(0.36 + 0.64) = √1 = 1 ✓5.4 用生活比喻来理解
想象你在拍照:
你站得离相机很远,照片里你很小
你站得离相机很近,照片里你很大
但无论你站多远多近,你都是同一个人,只是"缩放"了。
归一化就是把所有照片"统一缩放"到同一个标准尺寸,这样就可以公平比较谁更高、谁更矮。
5.5 为什么要归一化?
比较两个向量相似度时,我们只关心"方向",不关心"长度"。
向量A: [1, 1] 方向:东北45°
向量B: [100, 100] 方向:东北45°
这两个向量方向完全一样,只是长度不同。归一化后:
A → [0.707, 0.707] 长度=1
B → [0.707, 0.707] 长度=1
两个向量变得一模一样!5.6 L2归一化的数学公式
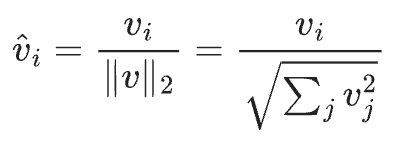
翻译成人话就是:
先算出向量的长度(所有元素的平方和,再开根号)
然后每个元素都除以这个长度
得到的新向量,长度就是1

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)