OpenClaw(龙虾)保姆级Linux安装
一、OpenClaw基础
1、什么是OpenClaw
OpenClaw是一款开源、可本地私有化部署的、具备执行能力的AI Agent,前身为Clawdbot与Moltbot,核心是通过自然语言指令,实现流程化、重复性任务的自动化执行,能直接接管电脑,替人写邮件、处理文件、甚至完成简单的软件开发。
传统大模型以 “生成内容” 为核心,仅提供建议;OpenClaw 以 “任务执行” 为核心,通过 “意图解析 → 任务规划 → 工具调用 → 结果反馈” 的闭环,直接完成真实操作。是AI从“对话建议”走向“落地执行”的关键一步。
OpenClaw可以部署在个人电脑、云服务器等,通过用户熟悉的聊天软件交互,操作便捷自然;同时具备完整操作权限与超长记忆,成为真正专属于个人的AI助理(龙虾机器人)。
2、OpenClaw适合安装在哪里?
伴随着OpenClaw的爆火,Mac Mini也一举跃升为“理财产品”,最有震撼力的消息就是社区内有非常多的先行者声称购入了大量Mac Mini来运行。不过随着更多人了解到这个项目,也出现了另一种声音:超高权限下,它更适合运行在一个与个人主力电脑相互隔离的环境中,可以是一台旧电脑(MacOS系统目前支持的程度最好),也可以是一台云服务器(通常推荐Linux系统),目前OpenClaw对Linux操作系统同样支持程度较好,并且云端环境也与本地电脑强隔离,不会对保存在本地电脑的数据造成不良影响。
注意:OpenClaw官方社区目前也建议不要把OpenClaw部署在个人的主力电脑中,否则可能对本地电脑数据的安全造成影响。
推荐云端部署,在云服务器中部署OpenClaw的好处不仅在于提供与本地电脑安全隔离的运行环境,保护本地个人数据安全,同时还能实现服务7×24小时随时在线,让您随时随时可以与OpenClaw进行交互。
3、OpenClaw 能做什么
OpenClaw 拥有 “双眼和双手”,可直接操作电脑、浏览器、调用 API,完成各类真实任务。
(1)、系统级操作(强执行能力)
-
文件管理:读写文件、整理文件夹、批量处理文档。
-
终端执行:运行 Shell 命令、执行脚本、管理进程。
-
设备监控:监控电脑电量、网络连接、系统状态。
-
代码开发:本地写代码、调试、生成测试用例、管理项目依赖。
(2)、浏览器自动化
-
控制 Chrome 浏览器,自动浏览网页、填写表单、提取数据。
-
自动办理登机、查找预约、处理医疗报销等网络事务。
-
配置 API 令牌、OAuth,对接云服务。
(3)、 办公自动化
-
邮件处理:清理收件箱、发送邮件、自动回复。
-
日程管理:管理日历、会议提醒、生成周报。
-
文档处理:生成工作总结、会议纪要、格式转换。
-
表格处理:自动处理 Excel、数据统计。
(4)、多渠道交互
-
无需专用 App,通过 WhatsApp、Telegram、Discord、Slack、iMessage 等聊天软件即可控制。
-
支持语音唤醒与对话(macOS、iOS、Android)。
(5)、持久记忆与规划
-
记住你的偏好、历史任务,自动拆解复杂目标并分步执行。
-
24 小时上下文持续,提供个性化服务。
(6)、 可扩展技能生态
-
支持插件(Skills)扩展,社区已有数百种技能(办公、开发、生活等)。
-
官方技能市场有 100 + 预置技能,支持用户自定义技能。
(7)、模型灵活适配
-
支持 Claude、GPT 系列,也可通过 Ollama 接入本地模型。
-
适配不同算力与隐私需求。
二、基于OpenClaw的应用架构
OpenClaw不是孤立存在的,它是作为连接底层能力与前端应用的中间枢纽。本质上是一个 AI Agent 调度中枢,通过解耦“应用端”和“模型端”,实现了业务逻辑的灵活配置。
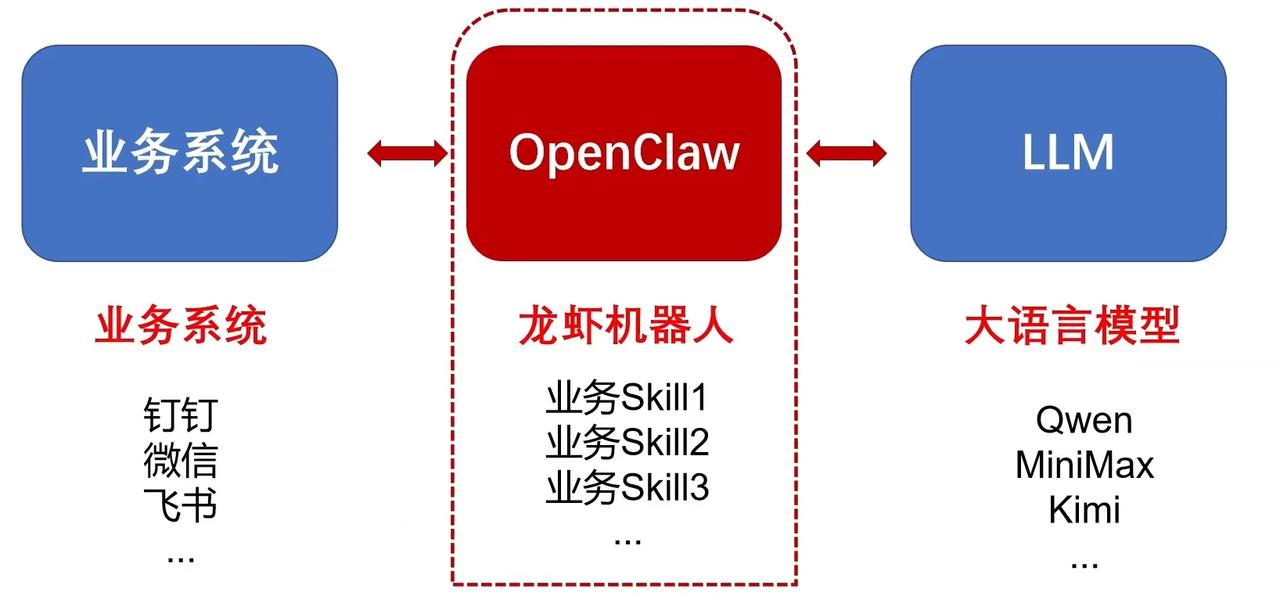
1. 业务系统
这是整个架构的触达层,即用户直接进行交互的平台。
-
功能: 提供交互界面,接收用户的自然语言指令,并将 OpenClaw 处理后的结果反馈给用户。
-
图中示例:钉钉 (DingTalk)、微信 (WeChat)、飞书 :这些都是主流的办公与社交平台。
-
含义: OpenClaw 并不局限于单一的 App,而是通过 API 或插件形式集成进现有的办公生态中,让用户在无需改变习惯的情况下使用 AI 能力。
2. OpenClaw/龙虾机器人
这是架构的核心控制层,也是图中最关键的红色方框部分。
-
功能:
-
中继与路由: 接收来自业务系统的请求,将其转化为模型可理解的提示词(Prompt)。
-
业务 Skill(技能库): 这是 OpenClaw 的灵魂。它将复杂的业务逻辑拆解为一个个具体的“技能点”(Skill 1, Skill 2...)。
-
-
含义: Skill 可以理解为封装好的功能模块,比如“自动报销”、“会议总结”或“查询库存”。
-
OpenClaw 负责识别用户的意图,并调用相应的 Skill,再配合 LLM 的推理能力来完成具体任务。它解决了通用大模型“不懂具体业务规则”的痛点。
-
3. LLM / 大语言模型 (The Intelligence Engine)
这是架构的智力层,负责理解、生成和决策。
-
功能: 提供底层的自然语言处理能力,包括语义理解、逻辑推理、文本生成等。
-
图中示例:
-
Qwen (通义千问)、MiniMax、Kimi:这些是目前国内主流的高性能大语言模型。
-
-
含义: OpenClaw 采用了**模型无关(Model-agnostic)**的设计。这意味着用户可以根据成本、速度或任务复杂度,灵活切换不同的底层模型,而不需要重构整个业务系统。
4. 总结:OpenClaw的执行逻辑
-
输入: 用户在飞书/微信发送一句:“帮我查一下上个月的销售报表”。
-
处理: OpenClaw 接收到指令,通过 LLM 识别出意图是“查询数据”,随后调用对应的 业务Skill 去对接企业的后台数据库。
-
生成: LLM 将查询到的枯燥数据加工成易读的文字。
-
输出: 结果通过 OpenClaw 回传,显示在用户的聊天窗口中。
三、 OpenClaw 本地部署指南
本次安装我是基于本地的ollama来进行部署的,没有调用云端的大模型,因为云端大模型消耗的token是需要消费的
0、ollama安装
首先,我们需要下载一个Ollama的客户端,在官网提供了各种不同版本的Ollama,大家可以根据自己的需要下载。
注意:
Ollama默认安装目录是C盘的用户目录,如果不希望安装在C盘的话(其实C盘如果足够大放C盘也没事),就不能直接双击安装了。需要通过命令行安装。
命令行安装方式如下:
在OllamaSetup.exe所在目录打开cmd命令行,然后命令如下:
.\OllamaSetup.exe /DIR=你要安装的目录位置OK,安装完成后,还需要配置一个环境变量,更改Ollama下载和部署模型的位置。环境变量如下:
OLLAMA_MODELS=你想要保存模型的目录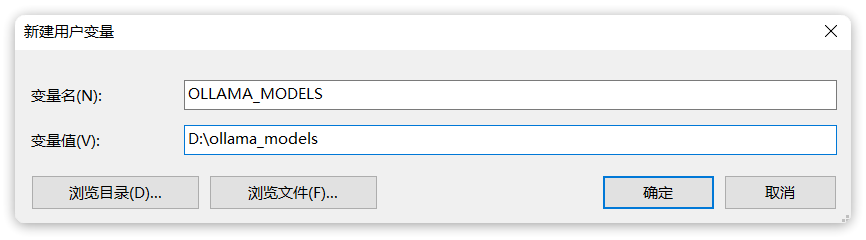
ollama是一个模型管理工具和平台,它提供了很多国内外常见的模型,我们可以在其官网上搜索自己需要的模型:https://ollama.com/search
因为最近4月初,Google开源了一个大模型gemma4,可以进行本地部署。
Gemma 4 是 Google DeepMind 于 2026 年 4 月推出的新一代开源大语言模型系列。它与谷歌的闭源旗舰模型 Gemini 共享底层技术,主打“单位参数智能水平”的极致优化,旨在以更小的模型规模实现媲美甚至超越更大模型的性能。
🚀 核心亮点
极致开放的许可协议:Gemma 4 采用 Apache 2.0 许可证,这是一个极为宽松的协议,允许开发者自由地修改、分发和用于商业用途,极大地降低了技术使用和商业化的门槛。
卓越的性能表现:Gemma 4 在多个基准测试中表现惊人。例如,其 31B 版本在数学竞赛 AIME 2026 中的正确率从上代的 20.8% 飙升至 89.2%,并在 Arena AI 全球开放模型排行榜上位列第三,性能媲美参数规模大得多的模型。
强大的多模态能力:全系列模型均原生支持图像和视频输入,可进行光学字符识别(OCR)、图表理解等复杂任务。其中,面向移动端的轻量级模型还额外集成了音频处理能力,支持离线语音识别与翻译。
先进的推理与智能体功能:模型内置了可开关的“思考模式”(Chain-of-Thought),能显著提升数学、逻辑等复杂任务的表现。同时,它原生支持函数调用和结构化 JSON 输出,可以无缝对接外部工具与 API,构建自主智能体(Agent)。
超长上下文窗口:Gemma 4 支持最高达 256K tokens 的上下文窗口,这意味着它可以处理整本小说、大型代码库或长篇研究报告,实现通盘理解和信息整合。
模型介绍
Gemma 4 并非单一模型,而是由四款不同规格的模型组成,以覆盖从手机到数据中心的全场景部署需求。
| 模型版本 | 核心特点 | 适用场景 |
|---|---|---|
| Gemma 4 E2B | 超轻量级,有效参数仅 23 亿,内存占用可低于 2GB。 | 手机、树莓派等资源受限的边缘设备。 |
| Gemma 4 E4B | 轻量级,有效参数 45 亿,在性能和速度间取得良好平衡。 | 笔记本电脑、平板等移动设备。 |
| Gemma 4 26B MoE | 混合专家(MoE)架构,推理时仅激活约 38 亿参数,效率极高。 | 追求高性能与低延迟平衡的消费级 GPU 部署。 |
| Gemma 4 31B Dense | 性能最强的稠密模型,拥有 310 亿全激活参数。 | 工作站、服务器等需要极致性能的场景。 |
如果有显卡显存6G+16G内存电脑可以推荐e4b,如果有更好的配置更推荐e26b,模型能力更强,这里我所使用的是e4b,用来进行体验OpenClaw完全足够了,如果想让他帮你干事的话,就需要去使用云端大模型了。
接着下载好ollama之后,输入cmd,在cmd中输入以下命令进行模型拉取:
ollama pull gemma4:e4b运行模型使用命令:
ollama run gemma4:e4b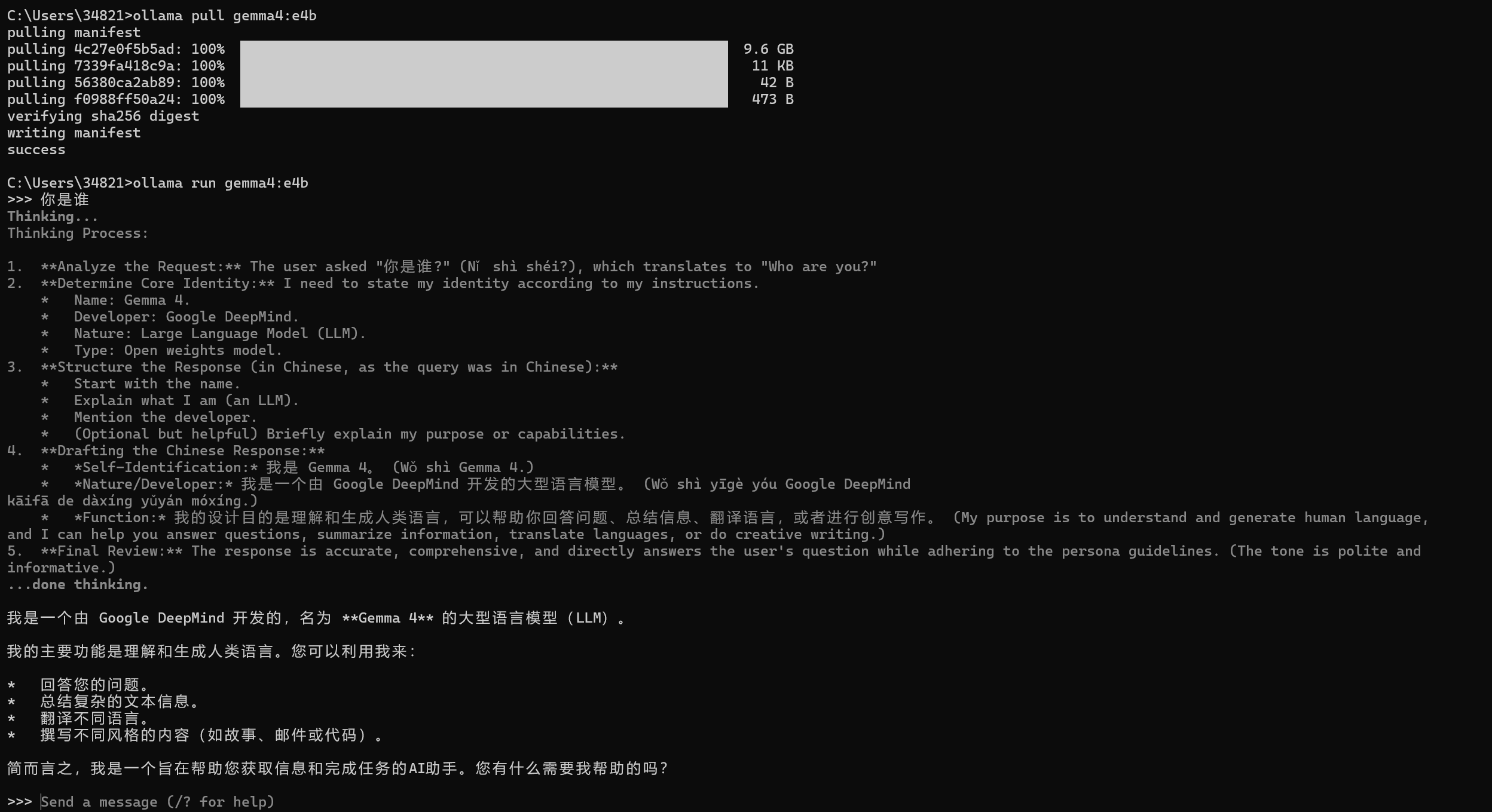
1、系统要求与环境准备
(1)硬件要求
|
配置项 |
最低要求 |
推荐配置 |
⾼性能配置 |
|
CPU |
2 核 |
4 核 |
8 核+ |
|
内存 |
4GB |
8GB |
16GB+ |
|
存储 |
10GB |
50GB SSD |
100GB+ SSD |
|
⽹络 |
1Mbps |
10Mbps |
100Mbps+ |
(2)软件依赖
OpenClaw 需要以下软件环境:
-
Node.js:版本 22 或更⾼
-
npm:Node.js 包管理器
-
Git :版本控制⼯具( 可选)
-
Docker:容器化部署( 可选)
(3)软件版本检查
在安装前 ,检查系统是否满⾜要求:
$ node --version # 应显⽰v22.x .x 或更⾼
$ npm --version # 应显⽰10.x .x 或更⾼
$ git --version # 检查Git版本2、Rockylinux/RHEL/CentOS Stream 9 部署
(1)关闭防火墙和selinux
修改/etc/selinux/config文件,将SELINUX=enforcing修改为SELINUX=disabled,然后执行如下命令:
[root@localhost ~]# grubby --update-kernel ALL --args selinux=0接着,关闭防火墙:
[root@localhost ~]# systemctl stop firewalld.service
[root@localhost ~]# systemctl disable firewalld.service最后,修改rockylinux默认软件源为阿里云地址,安装部署更快:
[root@localhost ~]# sed -e 's|^mirrorlist=|#mirrorlist=|g' -e 's|^#baseurl=http://dl.rockylinux.org/$contentdir|baseurl=https://mirrors.aliyun.com/rockylinux|g' -i.bak /etc/yum.repos.d/rocky*.repo
[root@localhost ~]# dnf makecache 最后,重启reboot服务器。
(2)安装nodejs
这是关键步骤,nidejs版本必须大于22,官方给的方法是:
[root@localhost ~]# curl -fsSL https://rpm.nodesource.com/setup_22.x | sudo bash -
[root@localhost ~]# yum install -y nodejs第一条命令是下载一个nodejs的dnf安装源,但是rpm.nodesource.com地址国内某些用户可能无法访问,大家可自行测试,如何可以正常执行,就按照此方法,如果不行,用下面离线安装方法。
这里使用nodejs的二进制安装包完成安装,从阿里云下载大于等于22版本的nodejs版本即可,地址为:https://mirrors.aliyun.com/nodejs-release/,安装过程如下:
[root@localhost ~]# tar -xJvf node-v24.1.0-linux-x64.tar.xz -C /usr/local --strip-components=1
[root@localhost local]# node -v
v24.1.0其中,--strip-components=1 表示:解压时去掉最外层的 node-v24.1.0-linux-x64 目录,直接把目录内的所有文件子目录(bin、lib 等)放到 /usr/local 下,而不是放到 /usr/local/node-v24.1.0-linux-x64 里。
(3)安装openclaw
此步骤最为关键,坑很多,首先要保证你的机器安装了gcc、glibc、cmake这类基础工具,执行下面命令安装:
[root@localhost ~]# dnf groupinstall -y "Development Tools"
[root@localhost ~]# dnf install -y cmake在使用npm安装openclaw过程中,默认会从github下载一些插件,但 GitHub 在国内连接不稳定,因此会导致openclaw安装失败,这里提供一个github镜像加速的方法,命令如下:
[root@localhost ~]# git config --global url."https://gh-proxy.com/https://github.com/".insteadOf "https://github.com/"然后就可以直接使用原始命令,Git 会自动走加速通道:例如:
[root@localhost ~]# git clone https://github.com/whiskeysockets/libsignal-node.git上面配置完成后,接着就可以愉快的安装openclaw了,命令如下:
[root@localhost ~]# npm config set registry https://registry.npmmirror.com
[root@localhost ~]# npm install -g openclaw@latest --unsafe-perm其中:
npm config set registry是配置npm 国内镜像,提高安装速度。
npm install -g (全局安装)
openclaw@latest (安装最新版)
--unsafe-perm (核心参数:禁用安全限制) ,就是告诉 npm:“不要降权,直接以 root 身份运行安装脚本。,如果是sudo模式安装,需要加上此选项,因为npm 在运行安装脚本(如编译 C++ 插件、下载二进制文件)时,为了安全,会自动降权,切换到一个权限较低的匿名用户(如 nobody)来执行。
注意:上面加速拉取代码是临时使用,当你需要使用git推送代码(push)到国内某仓库时,记得执行下面命令来恢复。
git config --global --unset url."https://gh-proxy.com/https://github.com/".insteadOf上面所有命令执行完成,openclaw就安装完成了。
四、配置openclaw(关键步骤)
安装完成,执行如下命令,进入openclaw 配置过程:
openclaw onboard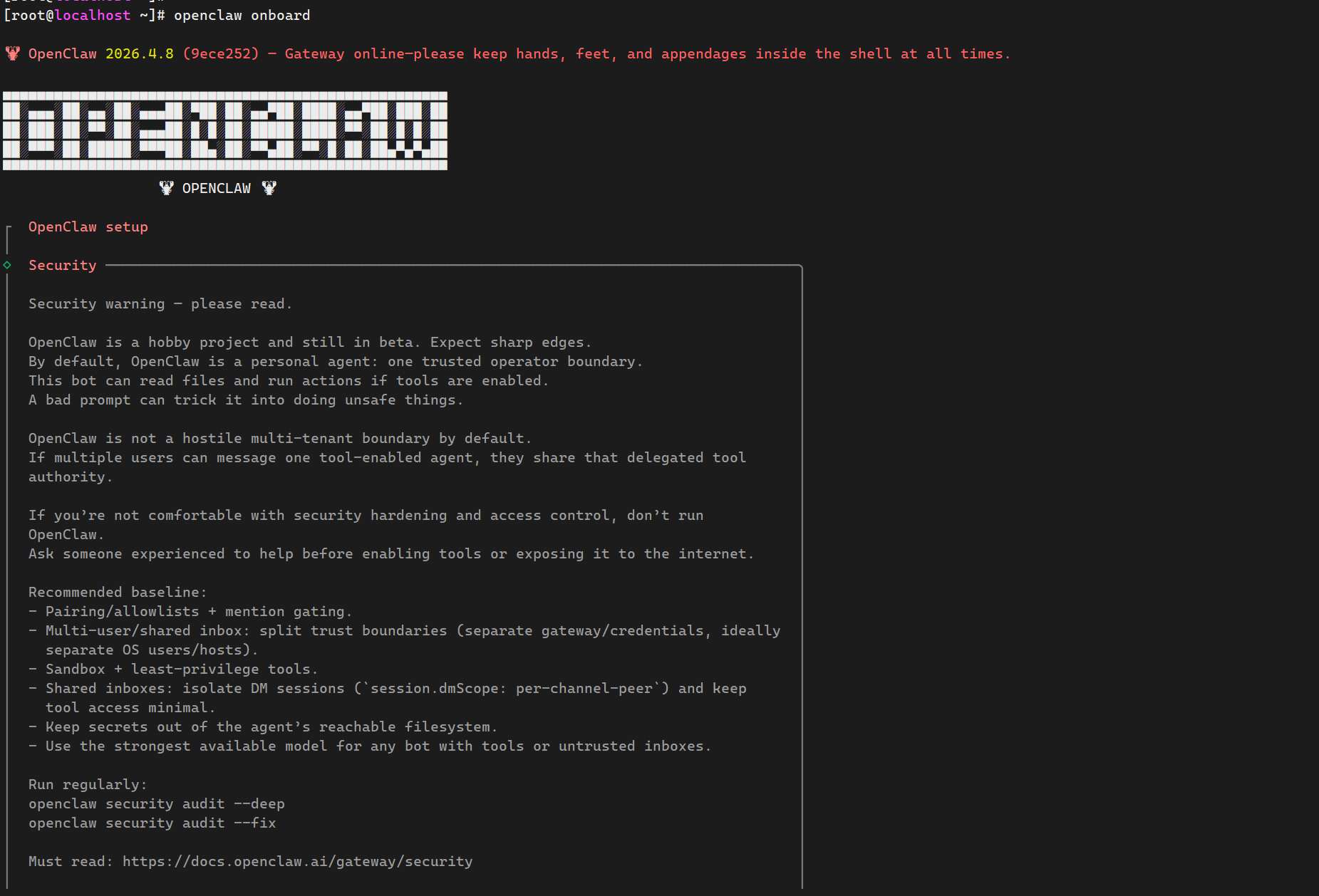
下面是安装提示:软件默认适配单用户,多用户使用需额外做安全配置,询问是否继续安装,选择YES继续:

下面步骤是使用快速配置,还是手动配置,建议选择 QuickStart即可:
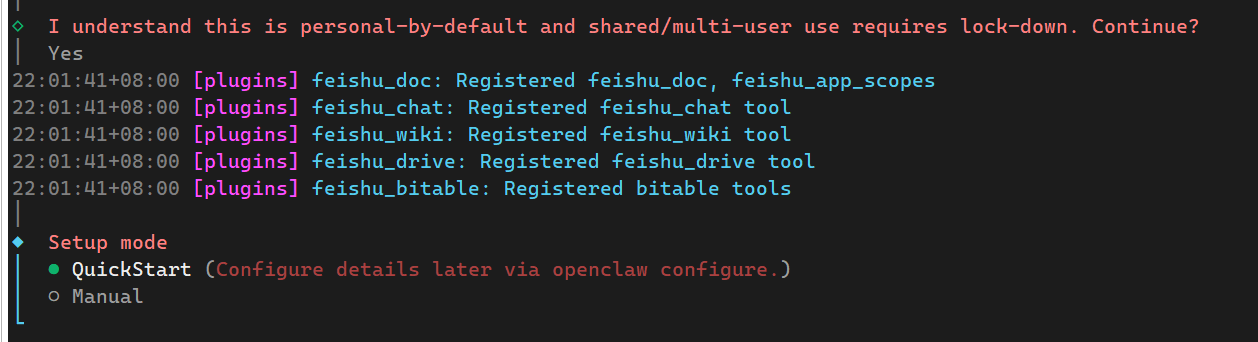
接下来进行模型选择,选择ollama
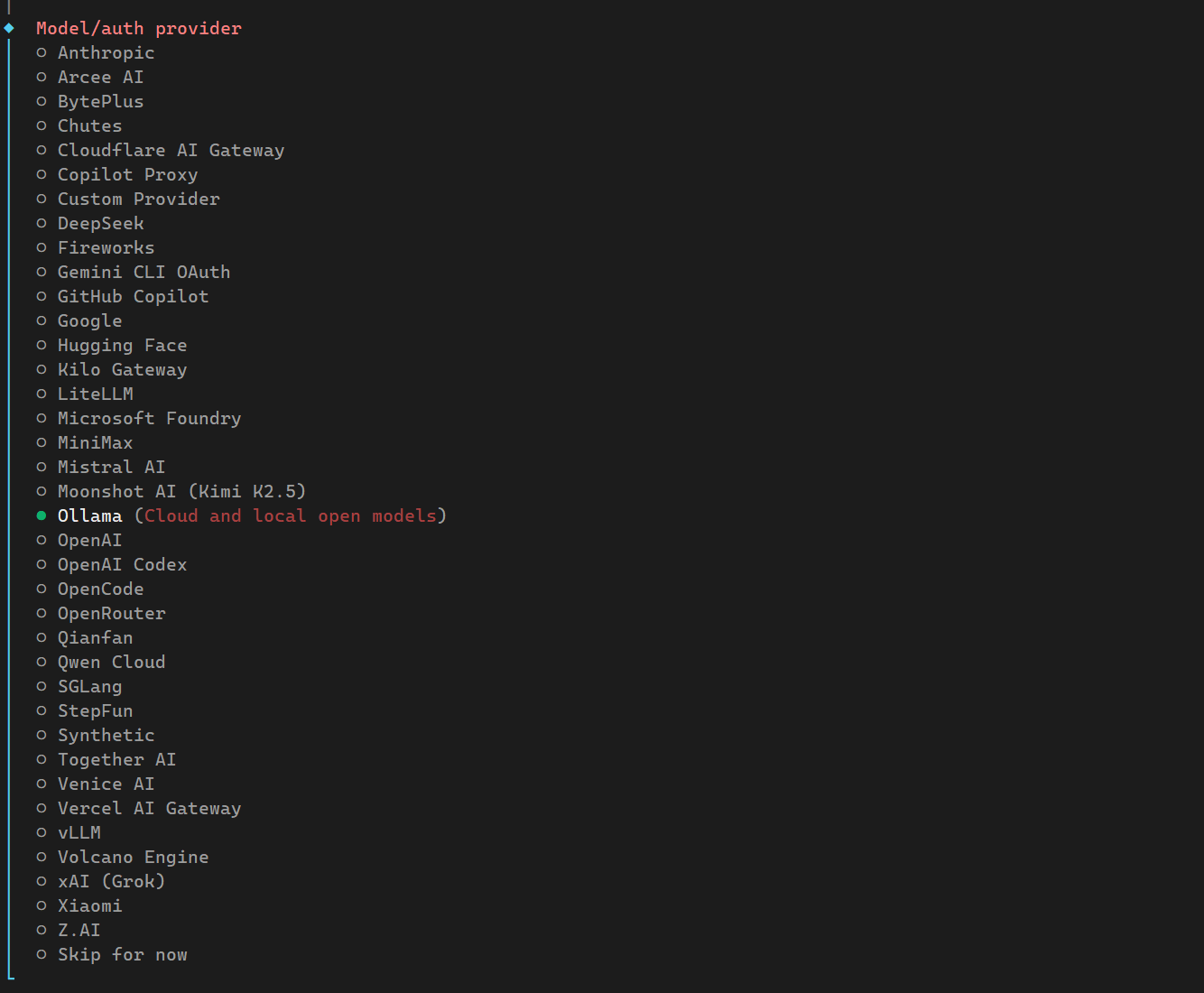
接下来回到Windows进行ollama相关配置
第一步:配置 Windows 端的 Ollama
默认情况下,Ollama 只允许本机(Windows)访问。你需要让它允许外部(Linux 服务器)访问。
设置环境变量:
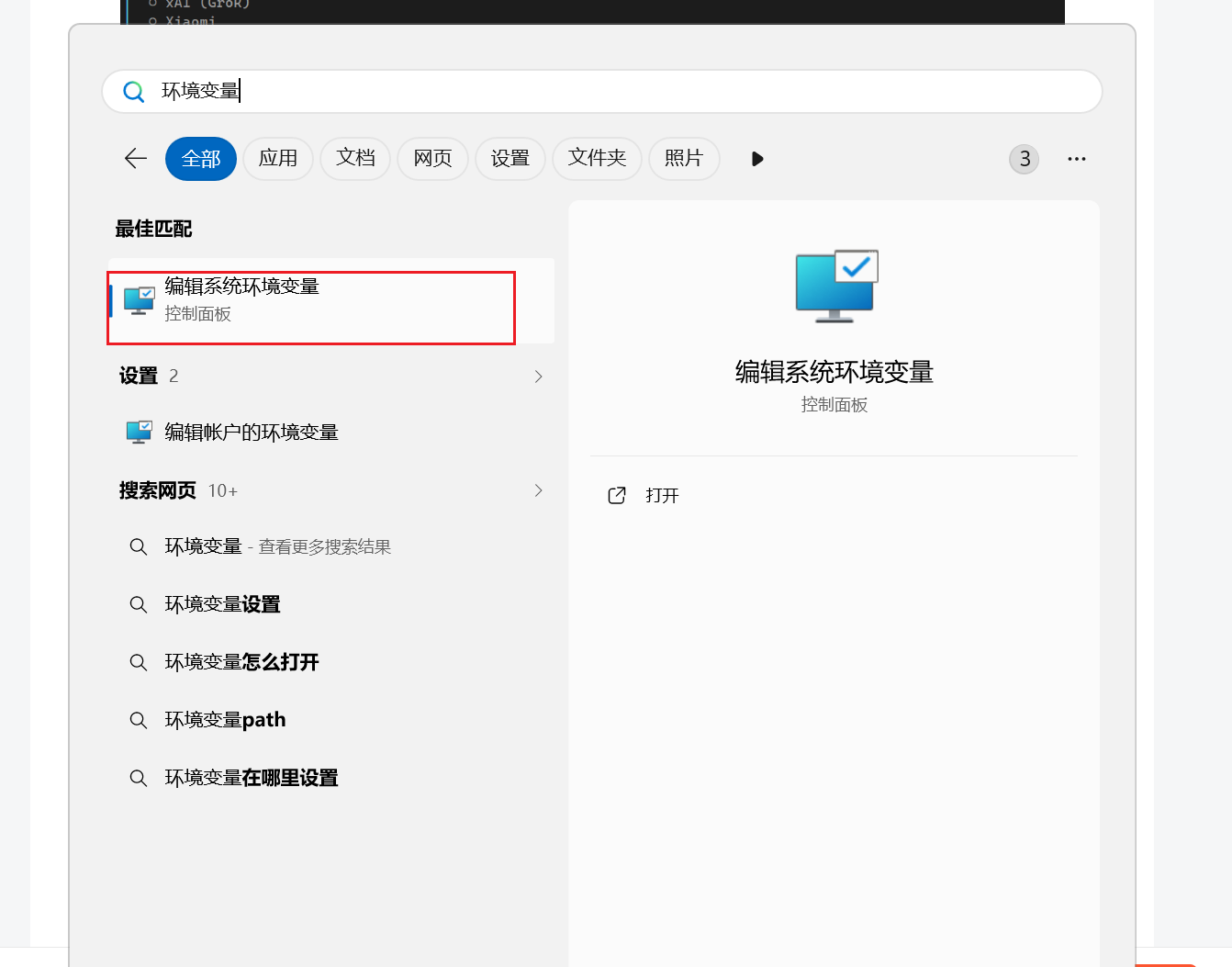
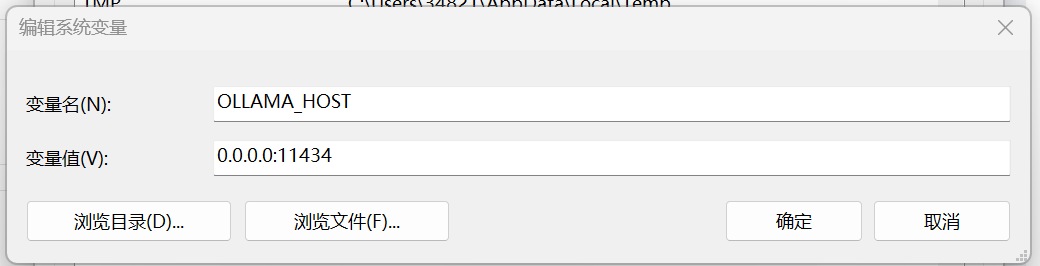
在 Windows 搜索栏输入“环境变量”,选择“编辑系统环境变量”。
点击“环境变量”按钮。
在“用户变量”或“系统变量”中点击“新建”。
变量名:OLLAMA_HOST
变量值:0.0.0.0:11434
点击确定保存。
重启 Ollama:
在 Windows 右下角任务栏找到 Ollama 图标,右键选择“Quit”退出。
重新启动 Ollama(在开始菜单中打开)。
检查 Windows 防火墙(关键):
打开“Windows Defender 防火墙” -> “高级设置”。
点击“入站规则” -> “新建规则”。
选择“端口” -> 下一步 -> 选择“TCP”,特定本地端口填 11434。
选择“允许连接”,一直下一步直到完成。或者也可以直接关闭防火墙
第二步:获取 Windows 的 IP 地址
在 Windows 上按 Win + R,输入 cmd 打开命令提示符。
输入 ipconfig。
找到你正在使用的网络适配器(通常是无线局域网适配器或以太网适配器),记下 IPv4 地址(例如 192.168.1.100)。
第三步:配置 Linux 端的 OpenClaw
回Linux终端,把 Ollama base URL 修改为 Windows 的 IP 地址。
http://你的Windows的IP:11434举例:
如果你的 Windows IP 是 192.168.1.100,那就填:
http://192.168.1.100:11434验证连接
配置完成后,在 Linux 终端里可以用 curl 命令测试一下是否连通:

接着进行一下选择配置
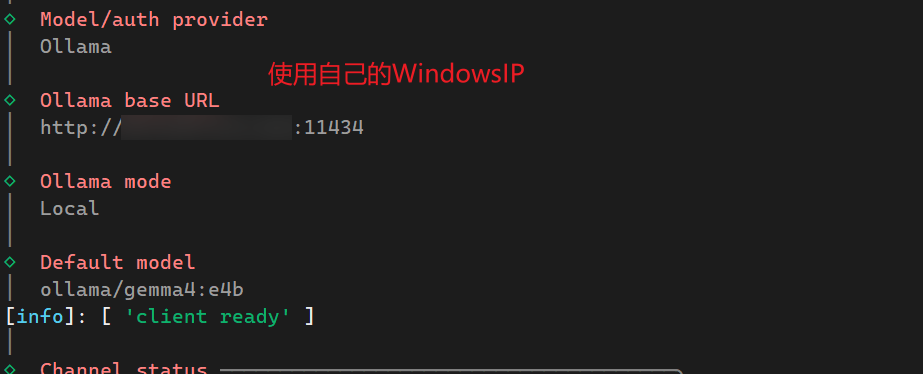
接着选择飞书作为通道
下图是配置飞书的验证信息:

这一步是 OpenClaw 与飞书建立通信的核心配置。可以把此步骤看作是在飞书平台上为 OpenClaw 申请一个“通行证”。
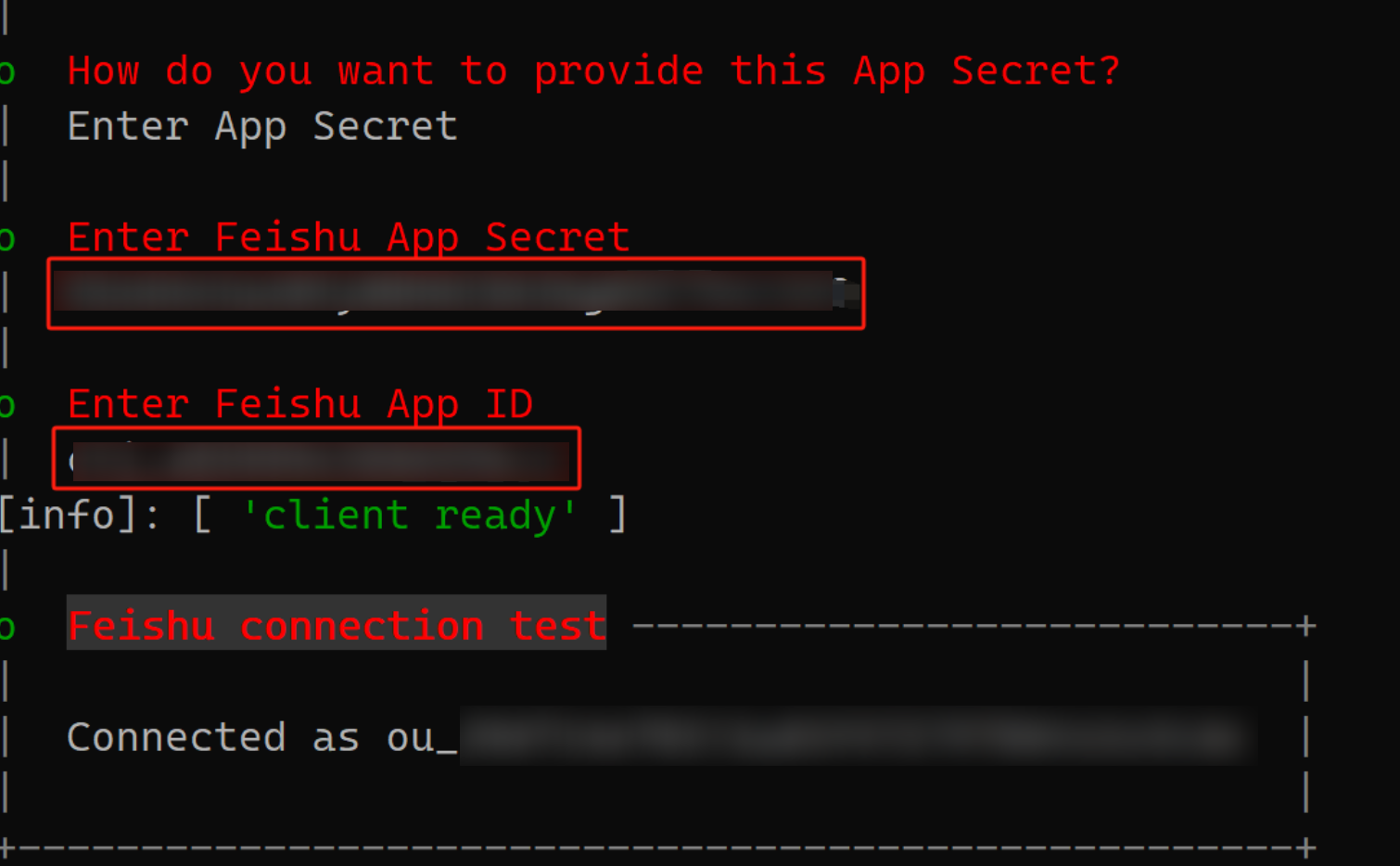
下图书输入飞书的App ID、App Secret。
OpenClaw安装过程中,需要连接渠道,国内常见的可用渠道有飞书、qq、微信等,这里以飞书为例,需要提前在飞书开发中心配置好相关应用。
以下是在飞书https://open.feishu.cn/详细的操作全过程:
1、创建飞书自建应用
登录 飞书开放平台 (https://open.feishu.cn/)。
点击右上角的 “开发者后台”。
点击 “创建企业自建应用”,输入应用名称(如
OpenClaw_Bot)和描述,上传一个图标,点击确认创建。2、获取凭证 (Credentials)
(1)、在左侧菜单栏选择 “凭证与基础信息”。
(2)、你会看到 App ID 和 App Secret。

下图是配置飞书连接模式:
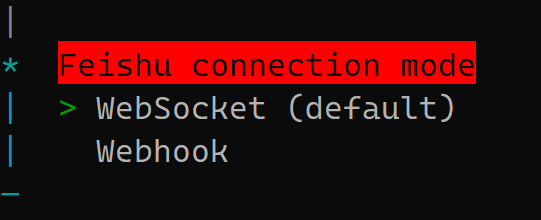
推荐选择WebSocket,因为WebSocket 是由你的服务器主动连接飞书服务器。即使你的服务器在内网、实验室环境或防火墙后,只要能上外网,机器人就能跑通。
为什么通常不选 Webhook?因为此模式要求飞书服务器能够主动访问你的服务器。这意味着你必须拥有公网 IP,并且必须配置 HTTPS(飞书强制要求)。
接下来,选择飞书域名,有国内版和国际版,现在国内版就行。
下图是你的 AI 机器人在飞书群聊里的“社交礼仪”。
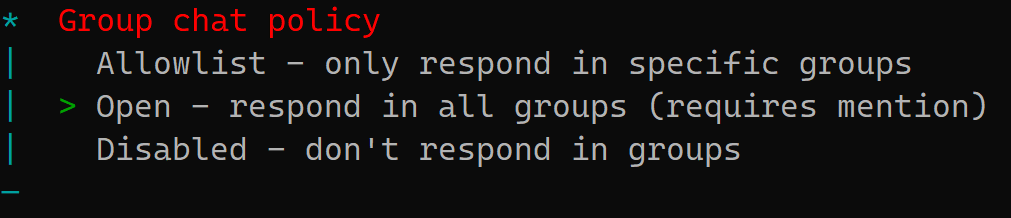
Open - respond in all groups (requires mention) (推荐)
-
含义:只要有人在群里 @机器人,它就会回复。
Allowlist - only respond in specific groups (严谨/生产环境)
-
含义:机器人只在白名单里的特定群聊中说话,哪怕在其他群 @它,它也不理。
Disabled - don't respond in groups (最保守)
-
含义:机器人只支持 1 对 1 私聊。
下图是配置 OpenClaw 机器人联网搜索的能力,当 AI 无法回答实时信息时,它会通过这个插件去网上查。
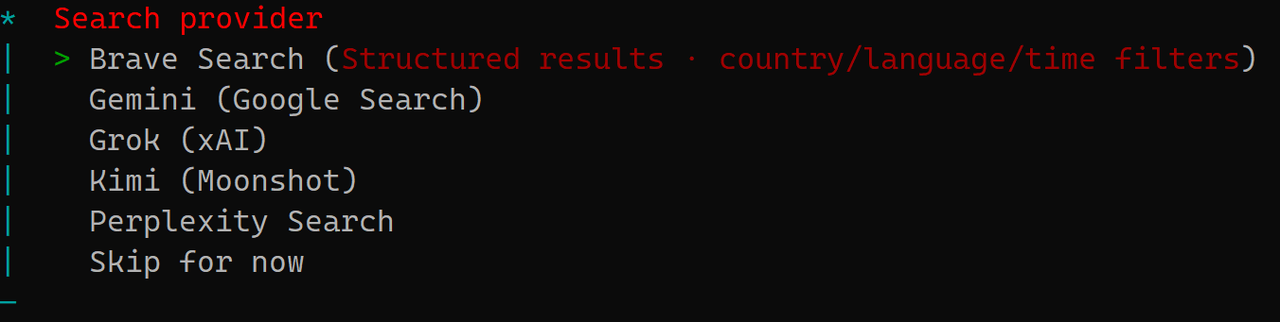
建议:选 Skip for now (推荐) 或 Kimi,这里我选 Skip for now
大多数搜索插件(如 Brave, Google, Perplexity)都需要额外的 API Key(通常是付费的),且国内服务器访问这些国外搜索接口往往需要稳定的代理。
如果你确实需要联网能力,Kimi 是月之暗面提供的国产大模型服务,其搜索接口在国内服务器上访问速度最快、最稳定,且对中文内容的抓取(如 CSDN、知乎、飞书文档)支持最好。接下来跳过,不设置
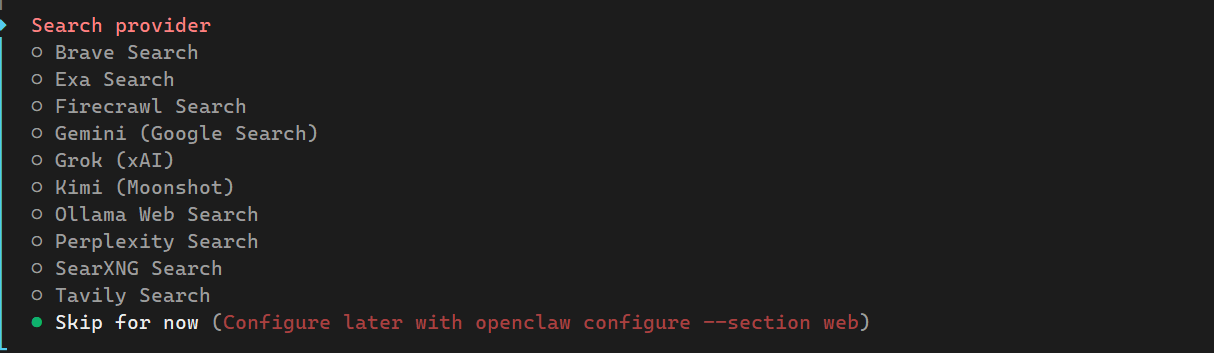
下面开始配置技能,AI 助手不仅能聊天,还能通过这些“技能”去执行任务,选择yes

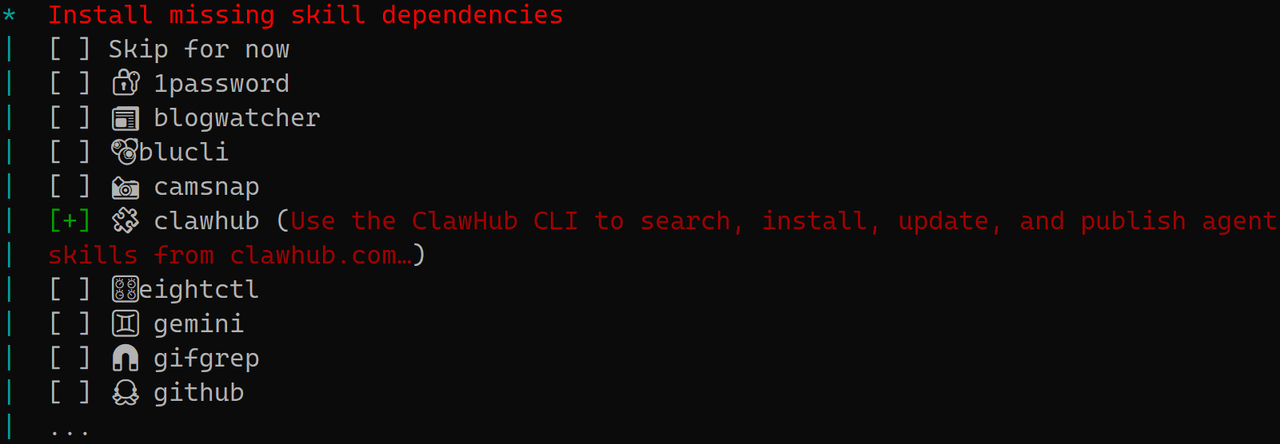
下图是列出了可以直接添加的技能,推荐安装clawhub,这是 OpenClaw 的官方技能库管理器,有了它,以后可以直接在飞书里输入 /install [新技能]。
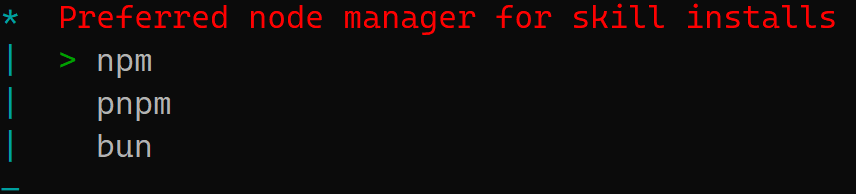
下面是包管理器(Package Manager)的选型,OpenClaw 的各种“技能”(Skills)本质上都是一个个 Node.js 插件。当你以后想给机器人增加新功能(比如让它能查 Jira、监控 Zabbix 或搜索网页)时,OpenClaw 需要调用一个工具去下载并安装这些插件的依赖包。这里选择npm即可。
下面这些步骤都是OpenClaw 插件的特定功能密钥,可暂不配置,都选择NO,这些辅助功能以后随时可以在 openclaw.json 里补上。
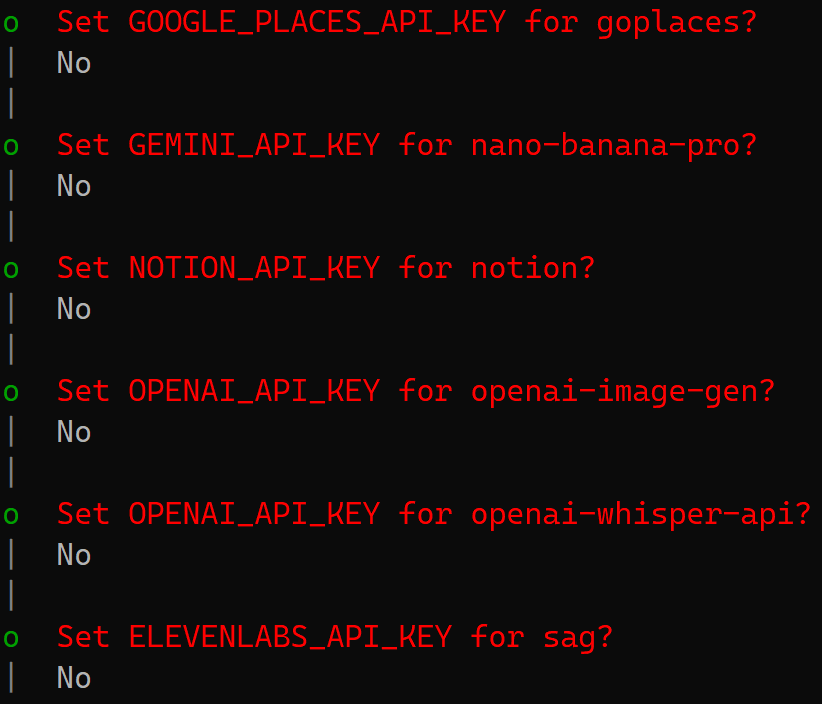
下表是上面选项代表的含义:
|
选项 |
对应功能 |
选 No 的影响 |
|
GOOGLE_PLACES_API_KEY |
地图/地点搜索 |
机器人不能帮你查公司附近哪家外卖好。 |
|
GEMINI_API_KEY |
图像理解/分析 |
暂时不能用 Gemini 的多模态能力分析服务器机房的照片。 |
|
NOTION_API_KEY |
知识库同步 |
机器人暂时无法读写你的 Notion 页面。 |
|
OPENAI_API_KEY (Image/Whisper) |
画图与语音 |
机器人不能发语音消息,也不能根据报错画一张架构图。 |
下图是配置OpenClaw 在执行任务前后的自动化脚本,俗称Hooks(钩子):
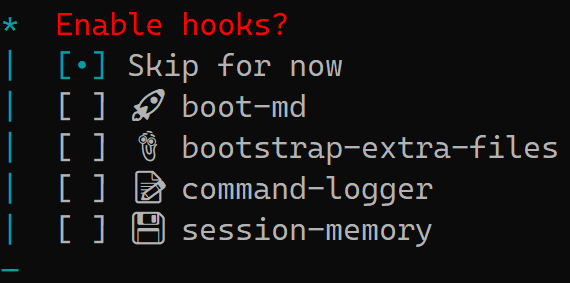
建议使用空格键选中以下两项,然后回车:
📝 command-logger (运维审计必备 - 强烈推荐)
-
含义:记录 AI 执行的所有 Shell 命令。这相当于开启了 操作审计日志,方便事后排查故障。
💾 session-memory (增强对话逻辑 - 推荐)
-
含义:让 AI 更好地记住当前对话的上下文。你在处理复杂的故障时,对话往往很长。开启这个能让 AI 不会“聊着聊着就忘了”前几步的操作结果,保持逻辑连贯。
当你完成这一步,onboard 引导就彻底结束了!你将会看到:
Configuration saved to /root/.openclaw/openclaw.json
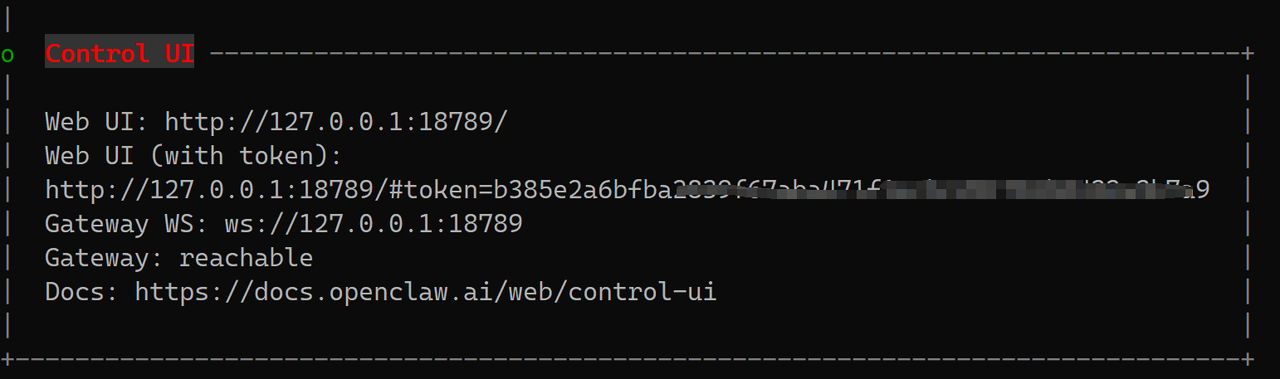
下图是UI访问方式,特别是token,记录下来:
现在OpenClaw 已经收集齐了你的配置信息,下面步骤是问你:你想在哪里看着机器人正式上线?
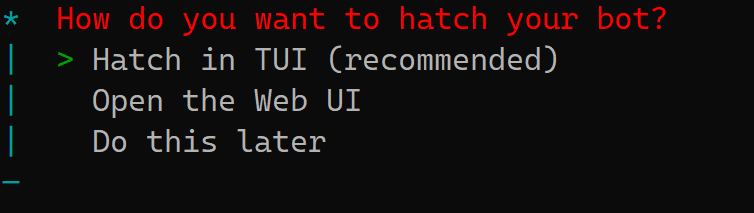
Hatch in TUI (推荐):
-
含义:在当前的命令行(Terminal User Interface)里直接运行初始化。这是最直观的。你可以直接在终端看到实时的运行日志(Logs),如果飞书 API 报错或者 Token 无效,报错信息会立刻刷出来。
Open the Web UI:
-
含义:启动一个网页端的控制台来完成后续步骤。虽然界面漂亮,但如果你是在的openclaw安装早云主机或虚拟机上,可能需要额外配置端口转发(SSH Tunneling)才能看到网页,稍微麻烦一点。
Do this later:
-
含义:仅保存配置并退出,不立即启动。
现在Open the Web UI,会给你访问信息:
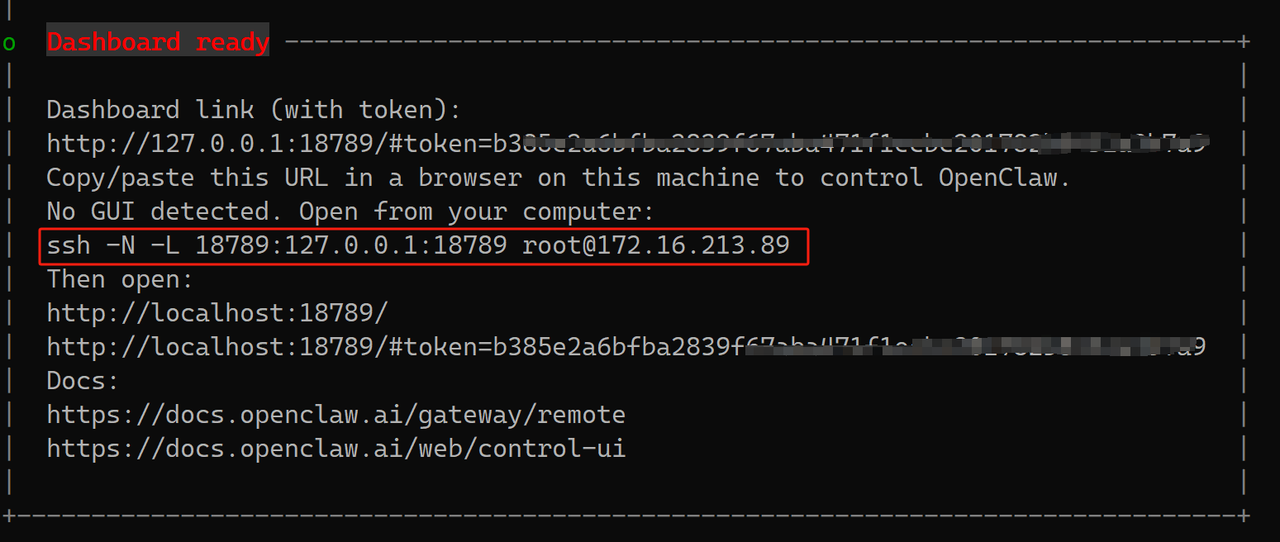
由于安全限制,不能直接ip加端口访问web ui,需要进行一个转发配置,如果openclaw部署在远程主机,你需要在你的笔记本电脑执行如下命令:
ssh -N -L 18789:127.0.0.1:18789 root@192.168.194.5
-N: 告诉 SSH 只要建立隧道,不要执行远程命令(不会跳出终端提示符)。
-L 18789:127.0.0.1:18789: 这就像是在你的笔记本和服务器之间拉了一根虚拟网线。当你访问笔记本的18789端口时,数据会自动“穿梭”到服务器的127.0.0.1:18789上。在笔记本终端(Windows CMD 或 Mac Terminal)运行上面那条
ssh -N -L...命令并保持窗口别关。最后,在浏览器里直接复制粘贴最下面那行带 Token 的链接:http://127.0.0.1:18789/#token=b385e2a6bfxxxxx39f67aba471f1ecbc201782b8432a3b7a9

然后现在就进来了
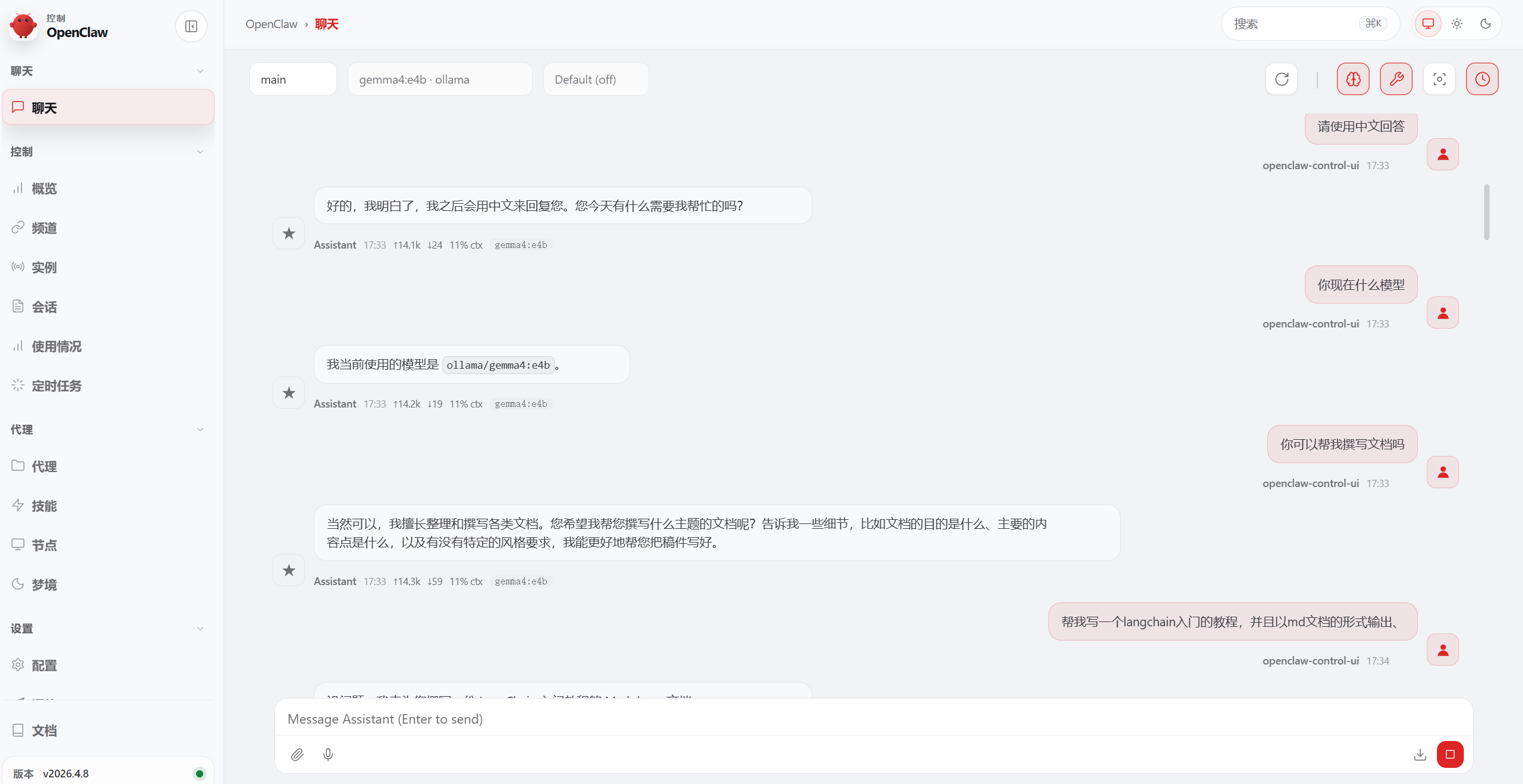
接着我们来开始进行测试

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 17
17 0
0- 0



 已为社区贡献22条内容
已为社区贡献22条内容

所有评论(0)