【说话人日志】从固定输出到可变说话人数:EEND-EDA
论文:Encoder-Decoder Based Attractors for End-to-End Neural Diarization
简称:EEND-EDA
作者:Shota Horiguchi, Yusuke Fujita, Shinji Watanabe, Yawen Xue, Paola Garcia
时间:2021 arXiv v1,2022 期刊版整理
任务:Speaker Diarization,回答“谁在什么时候说话”
前言
本文拓展了 EEND,解决可变说话人数问题:推理前不知道录音里有多少个说话人。
原始 EEND 和 SA-EEND,有一个共同限制:它们可以很好地处理重叠说话,但它们的输出维度通常是固定的,模型在回答“这段音频里预设好的这几个 speaker 槽位谁在说话”,而不是回答“这段音频里到底有几个人,以及每个人何时在说话”。
一、EEND
1.1 EEND 的数学表达
给定一段音频提取出来的声学特征序列
x 1 , x 2 , … , x T , x t ∈ R F , \mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_T, \quad \mathbf{x}_t \in \mathbb{R}^{F}, x1,x2,…,xT,xt∈RF,
EEND 要估计每一帧上每个 speaker 的说话状态。
假设有 S S S 个 speaker,那么第 t t t 帧的标签可以写成
y t = [ y 1 , t , y 2 , t , … , y S , t ] ⊤ , \mathbf{y}_t = [y_{1,t}, y_{2,t}, \ldots, y_{S,t}]^{\top}, yt=[y1,t,y2,t,…,yS,t]⊤,
其中
y s , t = { 0 , speaker s 在 t 时刻不说话 , 1 , speaker s 在 t 时刻说话 . y_{s,t} = \begin{cases} 0, & \text{speaker } s \text{ 在 } t \text{ 时刻不说话}, \\ 1, & \text{speaker } s \text{ 在 } t \text{ 时刻说话}. \end{cases} ys,t={0,1,speaker s 在 t 时刻不说话,speaker s 在 t 时刻说话.
于是,speaker diarization 被改写成逐帧多标签分类。
论文采用的条件独立假设是:
P ( y 1 , … , y T ∣ x 1 , … , x T ) = ∏ t = 1 T ∏ s = 1 S P ( y s , t ∣ x 1 , … , x T ) . P(\mathbf{y}_1, \ldots, \mathbf{y}_T \mid \mathbf{x}_1, \ldots, \mathbf{x}_T) = \prod_{t=1}^{T} \prod_{s=1}^{S} P(y_{s,t} \mid \mathbf{x}_1, \ldots, \mathbf{x}_T). P(y1,…,yT∣x1,…,xT)=t=1∏Ts=1∏SP(ys,t∣x1,…,xT).
于是网络输出可以写成
( p 1 , … , p T ) = f E E N D ( x 1 , … , x T ) , (\mathbf{p}_1, \ldots, \mathbf{p}_T) = f_{\mathrm{EEND}}(\mathbf{x}_1, \ldots, \mathbf{x}_T), (p1,…,pT)=fEEND(x1,…,xT),
其中
p t = [ p 1 , t , p 2 , t , … , p S , t ] ⊤ ∈ ( 0 , 1 ) S . \mathbf{p}_t = [p_{1,t}, p_{2,t}, \ldots, p_{S,t}]^{\top} \in (0,1)^{S}. pt=[p1,t,p2,t,…,pS,t]⊤∈(0,1)S.
最终用阈值得到预测标签:
y ^ s , t = 1 ( p s , t > 0.5 ) . \hat{y}_{s,t} = \mathbf{1}(p_{s,t} > 0.5). y^s,t=1(ps,t>0.5).
EEND 不是先算 speaker embedding 再聚类,而是直接输出“每一帧谁在说话”的后验概率。
1.2 EEND 卡在固定说话人数
EEND 可以写成
f E E N D = h ∘ g , f_{\mathrm{EEND}} = h \circ g, fEEND=h∘g,
其中:
- g g g 是 embedding part,把输入特征编码成 frame-wise embeddings
- h h h 是 classification part,把 embeddings 映射成每一帧每个 speaker 的 posterior
embedding 部分可写成
e t ( 0 ) = x t , \mathbf{e}_t^{(0)} = \mathbf{x}_t, et(0)=xt,
( e 1 ( n ) , … , e T ( n ) ) = g ( n ) ( e 1 ( n − 1 ) , … , e T ( n − 1 ) ) , (\mathbf{e}_1^{(n)}, \ldots, \mathbf{e}_T^{(n)}) = g^{(n)}(\mathbf{e}_1^{(n-1)}, \ldots, \mathbf{e}_T^{(n-1)}), (e1(n),…,eT(n))=g(n)(e1(n−1),…,eT(n−1)),
最后一层输出记作
e t : = e t ( N ) . \mathbf{e}_t := \mathbf{e}_t^{(N)}. et:=et(N).
问题出在分类头:
[ p 1 , … , p T ] = σ ( W c l s ⊤ [ e 1 , … , e T ] + b c l s 1 T ⊤ ) . (1) [\mathbf{p}_1, \ldots, \mathbf{p}_T] = \sigma\!\left( \mathbf{W}_{\mathrm{cls}}^{\top} [\mathbf{e}_1, \ldots, \mathbf{e}_T] + \mathbf{b}_{\mathrm{cls}} \mathbf{1}_T^{\top} \right). \tag1 [p1,…,pT]=σ(Wcls⊤[e1,…,eT]+bcls1T⊤).(1)
这里的
W c l s ∈ R D × S W_{\mathrm{cls}} \in \mathbb{R}^{D \times S} Wcls∈RD×S
直接把输出 speaker 槽位数定成了 S S S。这意味着模型不是根据音频内容“发现有几个人”,而是根据网络结构“被规定输出几个 speaker”。
1.3 PIT 损失
因为输出的 speaker 顺序没有语义,比如第 1 路输出不一定真对应“张三”,第 2 路也不一定真对应“李四”,所以训练时必须消除 permutation 的影响。
EEND 用的是 permutation-free objective:
L d i a r = 1 T S min ϕ ∈ Φ ( S ) ∑ t = 1 T H ( y t ϕ , p t ) , L_{\mathrm{diar}} = \frac{1}{TS} \min_{\phi \in \Phi(S)} \sum_{t=1}^{T} H(\mathbf{y}_t^{\phi}, \mathbf{p}_t), Ldiar=TS1ϕ∈Φ(S)mint=1∑TH(ytϕ,pt),
其中:
- Φ ( S ) \Phi(S) Φ(S) 表示 S S S 个 speaker 的所有排列
- y t ϕ \mathbf{y}_t^{\phi} ytϕ 表示在排列 ϕ \phi ϕ 下重排后的参考标签
- H ( ⋅ , ⋅ ) H(\cdot,\cdot) H(⋅,⋅) 是逐帧二元交叉熵
其具体形式为
H ( y t , p t ) = ∑ s = 1 S ( − y s , t log p s , t − ( 1 − y s , t ) log ( 1 − p s , t ) ) . H(\mathbf{y}_t, \mathbf{p}_t) = \sum_{s=1}^{S} \left( - y_{s,t} \log p_{s,t} - (1-y_{s,t}) \log (1-p_{s,t}) \right). H(yt,pt)=s=1∑S(−ys,tlogps,t−(1−ys,t)log(1−ps,t)).
PIT 解决的是“输出槽位没有固定身份”的问题,但公式中的槽位数 S S S 是预先确定的。
一种解决思路是将 S S S 设的非常大,以基本包括真实使用场景的人数。但有论文证实,这会使得模型性能下降,且 PIT 的排列数增加导致计算开销增大。
二、EEND-EDA
2.1 总览
原始 EEND 用固定分类权重去定义 speaker 槽位;EEND-EDA 则改成从当前这段录音自己的 embeddings 里,动态生成 speaker attractors。
然后再用 attractor 和每一帧 embedding 的相似度,得到该帧属于哪个 speaker。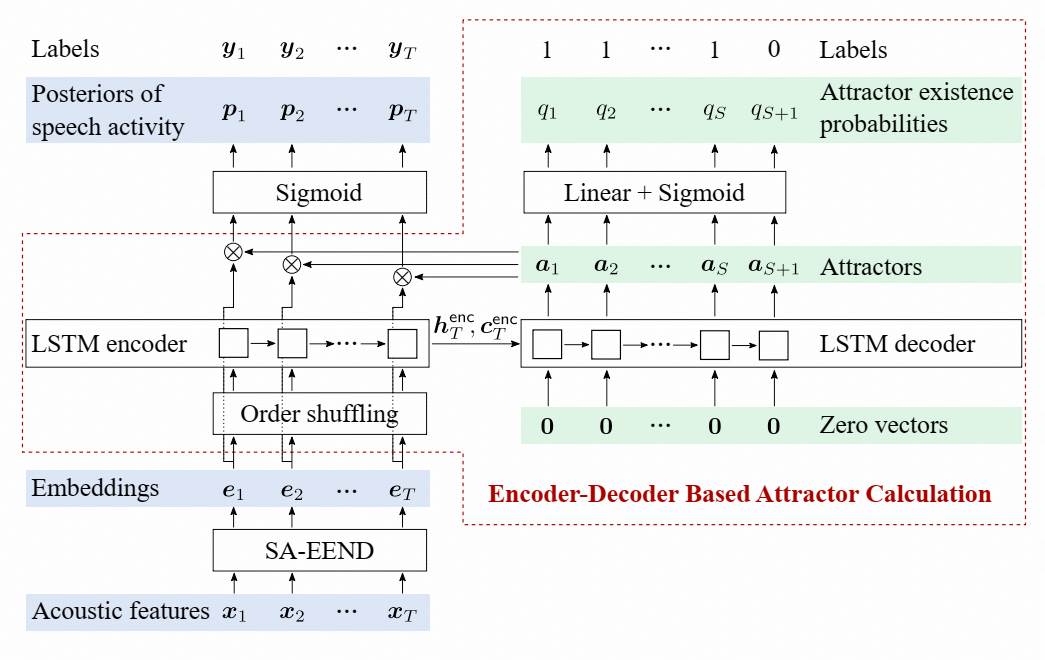
图 1 EEND-EDA 计算流程
从图1 可以看到,相比 SA-EEND,模型在提取 embeddings 后,增加了 EDA 模块,即用 LSTM encoder-decoder 生成 attractors,然后用 attractor 与 embedding 点积,sigmoid 计算每帧每 speaker 后验概率。
SA-EEND 还是和之前一样,不加位置编码。
2.2 LSTM encoder-decoder 生成 attractors
2.2.1 编码器
给定前面得到的 frame-wise embeddings
e 1 , e 2 , … , e T , \mathbf{e}_1, \mathbf{e}_2, \ldots, \mathbf{e}_T, e1,e2,…,eT,
LSTM encoder 逐帧读入它们:
h t e n c , c t e n c = h e n c ( e t , h t − 1 e n c , c t − 1 e n c ) , t = 1 , … , T . \mathbf{h}_t^{\mathrm{enc}}, \mathbf{c}_t^{\mathrm{enc}} = h^{\mathrm{enc}}( \mathbf{e}_t, \mathbf{h}_{t-1}^{\mathrm{enc}}, \mathbf{c}_{t-1}^{\mathrm{enc}} ), \quad t=1,\ldots,T. htenc,ctenc=henc(et,ht−1enc,ct−1enc),t=1,…,T.
其初始状态为
h 0 e n c = 0 , c 0 e n c = 0. \mathbf{h}_0^{\mathrm{enc}} = \mathbf{0}, \quad \mathbf{c}_0^{\mathrm{enc}} = \mathbf{0}. h0enc=0,c0enc=0.
2.2.2 解码器
decoder 的递推形式是
h s d e c , c s d e c = h d e c ( 0 , h s − 1 d e c , c s − 1 d e c ) , s = 1 , 2 , … (2) \mathbf{h}_s^{\mathrm{dec}}, \mathbf{c}_s^{\mathrm{dec}} = h^{\mathrm{dec}}( \mathbf{0}, \mathbf{h}_{s-1}^{\mathrm{dec}}, \mathbf{c}_{s-1}^{\mathrm{dec}} ), \quad s = 1,2,\ldots \tag2 hsdec,csdec=hdec(0,hs−1dec,cs−1dec),s=1,2,…(2)
注意这里每一步的输入都是零向量 0 \mathbf{0} 0。
初始状态由 encoder 的最终状态给出:
h 0 d e c = h T e n c , \mathbf{h}_0^{\mathrm{dec}} = \mathbf{h}_T^{\mathrm{enc}}, h0dec=hTenc,
c 0 d e c = c T e n c . \mathbf{c}_0^{\mathrm{dec}} = \mathbf{c}_T^{\mathrm{enc}}. c0dec=cTenc.
第 s s s 步 decoder 的隐藏状态就被当作第 s s s 个 attractor:
a s : = h s d e c . \mathbf{a}_s := \mathbf{h}_s^{\mathrm{dec}}. as:=hsdec.
注意 decoder 输入是零向量。
在一般的 sequence-to-sequence 任务里,比如机器翻译/ASR,decoder 往往会用 teacher forcing,因为输出序列的顺序是有意义的。
但在 EEND-EDA 里,输出的是 speaker attractor,而 speaker 本身没有天然顺序:
- 第一个 attractor 不一定对应“第一个人”
- 第二个 attractor 也不一定对应“第二个人”
所以无法事先规定正确输出顺序,也无法对 decoder 做常规 teacher forcing。论文就每一步都喂零向量,只让 decoder 根据自身状态递推地产生下一个 attractor。
2.3 用 attractor 和 embedding 计算说话后验
把所有 attractor 组成矩阵
A = [ a 1 , a 2 , … , a S ] , A = [\mathbf{a}_1, \mathbf{a}_2, \ldots, \mathbf{a}_S], A=[a1,a2,…,aS],
那么第 t t t 帧的说话后验就是
p t = σ ( A ⊤ e t ) . (3) \mathbf{p}_t = \sigma(A^{\top}\mathbf{e}_t). \tag3 pt=σ(A⊤et).(3)
- 如果某一帧 embedding 和某个 attractor 更接近,那么该 speaker 的 posterior 更高
- 如果某一帧是 overlap,它可能同时和多个 attractor 都比较接近
- 于是多个 speaker 的 posterior 都会高,所以 overlap 能被自然表示出来
式(1)像是式(3)的特殊情况,式(1)是固定了 attractors ( W c l s \mathbf{W}_{\mathrm{cls}} Wcls 和 b c l s \mathbf{b}_{\mathrm{cls}} bcls)的 EDA 情形。EEND-EDA 是为未知说话人数设计的,但在固定说话人数实验里会更强。
三、模型训练/推理
3.1 训练 existence head 的标签
观察式(2),理论上 decoder 可以一直往下生成 attractor。 那什么时候停止呢?
论文给每个 attractor 接了一个 existence head:
q s = σ ( w e x i s t ⊤ a s + b e x i s t ) , (4) q_s = \sigma(\mathbf{w}_{\mathrm{exist}}^{\top}\mathbf{a}_s + b_{\mathrm{exist}}), \tag 4 qs=σ(wexist⊤as+bexist),(4)
其中:
- a s \mathbf{a}_s as 是第 s s s 个 attractor
- q s q_s qs 表示“这个 attractor 是否真的对应一个 speaker”的概率
如果当前录音里真实有 S S S 个 speaker,那么论文构造的标签就是:
l = [ 1 , … , 1 , 0 ] ⊤ , \mathbf{l} = [1, \ldots, 1, 0]^{\top}, l=[1,…,1,0]⊤,
前 S S S 个位置是 1,第 S + 1 S+1 S+1 个位置是 0。
对应预测向量写成
q = [ q 1 , q 2 , … , q S + 1 ] ⊤ . \mathbf{q} = [q_1, q_2, \ldots, q_{S+1}]^{\top}. q=[q1,q2,…,qS+1]⊤.
于是 existence loss 为
L e x i s t = 1 S + 1 H ( l , q ) , (5) L_{\mathrm{exist}} = \frac{1}{S+1} H(\mathbf{l}, \mathbf{q}), \tag 5 Lexist=S+11H(l,q),(5)
总损失则写成
L = L d i a r + α L e x i s t . L = L_{\mathrm{diar}} + \alpha L_{\mathrm{exist}}. L=Ldiar+αLexist.
论文中使用
α = 1. \alpha = 1. α=1.
这一部分对应图 1 的右上角。
第一次看论文的读者可能会不自觉将 EDA 模块当做神经网络版的聚类模块,认为 L e x i s t L_{\mathrm{exist}} Lexist 是与 speaker 特征聚类相关的损失函数。这里要说明的是, L e x i s t L_{\mathrm{exist}} Lexist 的作用不是学“每个 speaker 是谁”,而是学“解码器在第几步该停下来”。
式(4)里的 q s q_s qs 不是第 s s s 个 speaker 的说话概率,而是第 s 个 attractor 是否真的对应一个存在的 speaker 的概率。这样标签设置为 l = [ 1 , … , 1 , 0 ] ⊤ ( s 个 1 ) , \mathbf{l} = [1, \ldots, 1, 0]^{\top}(s 个 1), l=[1,…,1,0]⊤(s个1), 希望模型学到的是
- 前 s s s 个 attractor 都应该是“有效 attractor”
- 第 s + 1 s +1 s+1 个 attractor 应该是“无效 attractor”,也就是该停了
这样再看 existence loss 就很自然了。
3.2 推理时估计说话人数
推理时没有真实说话人数,于是用 existence probability 直接决定:
S ^ = min { s ∣ q s + 1 < τ } , \hat{S} = \min \{ s \mid q_{s+1} < \tau \}, S^=min{s∣qs+1<τ},
其中阈值在论文里固定为 τ = 0.5. \tau = 0.5. τ=0.5.
即若下一个 attractor 的 existence probability 低于阈值,就认为 speaker 已经生成完了。
3.3 实验 tricks
3.3.1 chronological order 和 shuffled order
实验发现 encoder 输入顺序会影响 attractor。因为 EDA 用的是 LSTM encoder-decoder,它本质上是一个 sequence-to-sequence 模型,所以输入顺序会影响最终状态,也就会影响 attractor。
论文测试了两种顺序:
- chronological order:按时间顺序输入 embeddings
- shuffled order:先随机打乱帧顺序,再输入 embeddings
如果使用 shuffled order,encoder 看的是
h t e n c , c t e n c = h e n c ( e ψ t , h t − 1 e n c , c t − 1 e n c ) , t = 1 , … , T , \mathbf{h}_t^{\mathrm{enc}}, \mathbf{c}_t^{\mathrm{enc}} = h^{\mathrm{enc}}( \mathbf{e}_{\psi_t}, \mathbf{h}_{t-1}^{\mathrm{enc}}, \mathbf{c}_{t-1}^{\mathrm{enc}} ), \quad t=1,\ldots,T, htenc,ctenc=henc(eψt,ht−1enc,ct−1enc),t=1,…,T,
其中 ( ψ 1 , … , ψ T ) (\psi_1,\ldots,\psi_T) (ψ1,…,ψT) 是对 ( 1 , … , T ) (1,\ldots,T) (1,…,T) 的一个随机排列。
论文实验的结论是 shuffled order 基本 consistently 优于 chronological order。
这反映了如果按时间顺序输入,LSTM 更容易受到局部时序结构、句子长短、停顿位置等因素影响。 但 attractor 真正应该捕捉的是整段录音里 embedding 的全局分布结构。
- attractor 要代表“这个录音里有哪些 speaker 原型”
- 而不是“这段录音按时间顺序发生了什么”
shuffled order 更接近“从一个集合里抽取 speaker 原型”的目标,所以效果好。
3.3.2 L e x i s t L_{\mathrm{exist}} Lexist 局部回传
实验发现当用可变说话人数数据训练时,直接让 L e x i s t L_{\mathrm{exist}} Lexist 回传到整个网络,会干扰 L d i a r L_{\mathrm{diar}} Ldiar 的优化。
更好的策略是:
- L d i a r L_{\mathrm{diar}} Ldiar 仍然更新整个网络
- 但 L e x i s t L_{\mathrm{exist}} Lexist 只更新 existence head 的参数
也就是只更新:
w e x i s t , b e x i s t . \mathbf{w}_{\mathrm{exist}}, \quad b_{\mathrm{exist}}. wexist,bexist.
3.4 推理增强
3.4.1 SAD post-processing
传统 cascaded diarization 在很多论文里经常会用 oracle SAD 或外部 SAD。
而 EEND 类方法往往是“自己同时做 SAD + diarization”。
这样直接比较就不公平,因为误差来源不一样。
所以论文提出先让 EEND-EDA 输出 diarization 结果,再用外部 SAD 结果做后处理对齐。
设外部 SAD 结果是
z 1 , z 2 , … , z T , z t ∈ { 0 , 1 } , z_1, z_2, \ldots, z_T, \quad z_t \in \{0,1\}, z1,z2,…,zT,zt∈{0,1},
(1) 去掉 false alarm
如果某一帧 EEND 认为有人说话,但 SAD 认为没有语音,即
∥ y ^ t ∥ 1 > 0 , z t = 0 , \|\hat{\mathbf{y}}_t\|_1 > 0, \quad z_t = 0, ∥y^t∥1>0,zt=0,
就把这一帧直接改成全零:
y ^ t ← 0. \hat{\mathbf{y}}_t \leftarrow \mathbf{0}. y^t←0.
(2) 补回 missed speech
如果某一帧 EEND 没检出任何 speaker,但 SAD 认为有语音,即
∥ y ^ t ∥ 1 = 0 , z t = 1 , \|\hat{\mathbf{y}}_t\|_1 = 0, \quad z_t = 1, ∥y^t∥1=0,zt=1,
那么就把 posterior 最大的那个 speaker 拉起来:
s ∗ = arg max s p s , t . s^{\ast} = \arg\max_{s} p_{s,t}. s∗=argsmaxps,t.
然后设置
y ^ s ∗ , t = 1. \hat{y}_{s^{\ast},t} = 1. y^s∗,t=1.
这个后处理的意义有两个:
- 从评测角度,它让 EEND 和 cascaded 方法能在同一 SAD 条件下公平比较
- 从应用角度,如果外部 SAD 很强,也能直接帮 EEND 降低 FA 和 MI
3.4.2 iterative inference
虽然 EEND-EDA 从结构上支持可变人数,但论文发现它在经验上还是受训练集最大说话人数限制。
比如:
- 如果你训练时只见过最多 5 个人
- 推理时要它直接输出 8 个人
它通常只能稳定输出训练中见过范围内的人数,也就是说EEND-EDA 的“可变人数”是相对训练分布而言的,不是无限制的。
假设你训练时最多只见过 4 人说话。
那训练样本里最大的情况就是:
l = [ 1 , 1 , 1 , 1 , 0 ] \mathbf{l} = [1,1,1,1,0] l=[1,1,1,1,0]
这意味着模型被反复教的是:
- 第 1 个 attractor 有效
- 第 2 个 attractor 有效
- 第 3 个 attractor 有效
- 第 4 个 attractor 有效
- 第 5 个 attractor 应该停止
如果训练里从来没见过 5 人样本,那么模型从来没有被教过“第 5 个 attractor 也可能是有效的”。
也就是说:
- 对它来说,q_5 经常应该是 0
- 它会形成一个很强的偏置:4 个已经够了,第 5 个该停了
所以虽然结构允许继续往后解码,模型本身却没有学会如何稳定地产生第 5 个、第 6 个有效 attractor。也就是结构上灵活,经验上有限。
于是论文提出 iterative inference: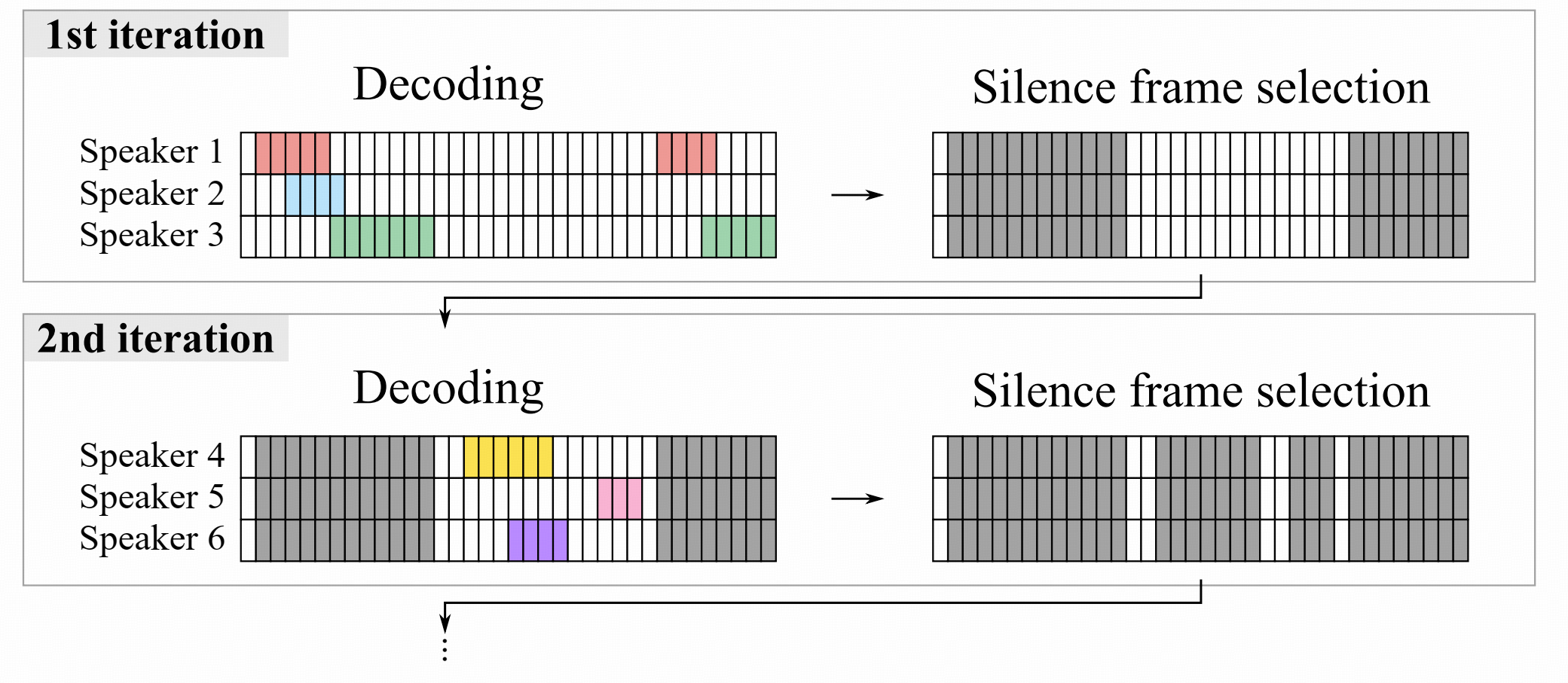
图 2 iterative inference
如图 2 所示,每次只解码一批 speaker,解码完之后,把这些 speaker 已经说话的帧去掉,再在剩下的“静音帧集合”里继续找后面的 speaker。
设当前还要处理的帧集合是 T \mathcal{T} T,第 n n n 轮解码为:
( p t ( n ) ) t ∈ T ← f E E N D ( ( x t ) t ∈ T ) , (\mathbf{p}_t^{(n)})_{t \in \mathcal{T}} \leftarrow f_{\mathrm{EEND}}\big((\mathbf{x}_t)_{t \in \mathcal{T}}\big), (pt(n))t∈T←fEEND((xt)t∈T),
而不在集合里的帧直接补零:
p t ( n ) ← 0 , t ∈ { 1 , … , T } ∖ T . \mathbf{p}_t^{(n)} \leftarrow \mathbf{0}, \quad t \in \{1,\ldots,T\} \setminus \mathcal{T}. pt(n)←0,t∈{1,…,T}∖T.
得到第 n n n 轮 diarization 结果后,只保留那些当前仍然没有 speaker 激活的帧:
T ← { t ∣ t ∈ T , ∥ y ^ t ( n ) ∥ 1 = 0 } . \mathcal{T} \leftarrow \{ t \mid t \in \mathcal{T}, \ \|\hat{\mathbf{y}}_t^{(n)}\|_1 = 0 \}. T←{t∣t∈T, ∥y^t(n)∥1=0}.
这样一轮一轮往下做,直到:
- 当前轮输出 speaker 数不足模型上限
- 或者剩余帧集合为空
iterative inference 有一个缺陷:
不同迭代轮次解出来的 speaker 之间,没法天然产生 overlap。
因为第二轮只看第一轮没人说话的帧,第一轮和第二轮的 speaker 自然不会重叠。
3.4.3 iterative inference+
为了缓解上面的问题,论文在 iterative inference 上又套了一层 DOVER-Lap。
做法是:
- 不只用一个固定的首轮 speaker 限制
- 而是令 S l i m i t = 1 , 2 , … , S max S_{\mathrm{limit}} = 1,2,\ldots,S_{\max} Slimit=1,2,…,Smax
- 跑出多组不同的 diarization 假设
- 最后用 DOVER-Lap 做 overlap-aware 的融合
四、实验结果
4.1 训练数据
4.1.1 模拟数据
论文用下面这些单说话人语料合成多说话人混合:
- Switchboard-2
- Switchboard Cellular
- NIST SRE 2004/2005/2006/2008
然后按如下流程做模拟:
- 先随机选 N N N 个 speaker
- 每个 speaker 拼接自己的语音段和静音段
- 随机加房间脉冲响应
- 多路混合再加噪声
论文构造了 Sim1spk 到 Sim5spk 的训练/测试集。
其中 overlap ratio 通过静音间隔参数 β \beta β 控制。
4.1.2 真实数据
真实评测集包括:
- CALLHOME
- CSJ
- AMI headset mix
- DIHARD II
- DIHARD III
这几个数据集覆盖了:
- 电话对话
- 日语对话
- 会议录音
- 多域困难场景
4.2 模型配置
论文中 EEND-EDA 的主要配置是:
- 4 层 Transformer encoder
- 每层 4 个 attention heads
- embedding 维度 256
- 输入特征是 23 维 log Mel filterbank
- 再拼接前后 7 帧
- 最终每 100 ms 得到一个 345 维特征
在训练策略上:
- 先在模拟数据上预训练
- 再在目标真实数据集上做 adaptation
评测指标是 DER 和 JER。
4.3 固定两人、三人场景下,EEND-EDA 也更强
| 场景 | SA-EEND | EEND-EDA(Chronol.) | EEND-EDA(Shuffled) | 结论 |
|---|---|---|---|---|
Sim2spk (β=2) |
4.56 | 3.07 | 2.69 | 两人模拟场景,EDA 明显优于 SA-EEND |
| CALLHOME-2spk | 9.54 | 8.24 | 8.07 | 真实电话双人对话,EDA 依然更强 |
| CSJ | 20.48 | 18.89 | 16.27 | 跨语言、长录音条件下仍有优势 |
Sim3spk (β=5) |
6.92 | 10.41 | 6.21 | 三人模拟场景下,Shuffled EDA 最好 |
| CALLHOME-3spk | 14.00 | 15.86 | 13.92 | 三人真实电话场景也略优于 SA-EEND |
4.4 shuffled order 比 chronological order 更好
论文专门分析了 EDA 对输入顺序的敏感性:
| 训练顺序 | 整段-按时序测试 | 整段-打乱测试 | 子采样 1/32 |
仅保留最后 1/32 |
|---|---|---|---|---|
| Chronological 训练 | 3.07 | 30.04 | 27.18 | 7.68 |
| Shuffled 训练 | 2.69 | 2.69 | 5.08 | 10.65 |
这里的数据来自 Sim2spk (β=2)。
- 如果模型按时间顺序训练,它在“按时间顺序输入”时还行,但一旦换成 shuffled 输入,DER 直接飙到
30.04 - 而 shuffled 训练的模型,对 chronological 和 shuffled 测试都基本稳定在
2.69 - 在强子采样时,shuffled 训练也明显更稳
4.5 在未知说话人数训练里, L e x i s t L_{\mathrm{exist}} Lexist 不能全量回传
论文在 Sim1spk 到 Sim5spk 上做了逐步改进:
| 训练设置 | 训练 speaker 数 | Epoch | L_exist 更新范围 |
Sim4spk DER | Sim5spk DER |
|---|---|---|---|---|---|
| 原始 EEND-EDA 设定 | k∈{1,2,3,4} |
25 | 更新整个网络 | 13.76 | N/A |
| 改进 1 | k∈{1,2,3,4} |
25 | 只更新 existence head | 10.12 | 23.08 |
| 改进 2 | k∈{1,2,3,4,5} |
25 | 只更新 existence head | 10.75 | 13.70 |
| 改进 3 | k∈{1,2,3,4,5} |
50 | 只更新 existence head | 9.97 | 11.95 |
| SA-EEND(可变人数训练) | k∈{1,2,3,4,5} |
50 | 不适用 | 12.24 | 17.42 |
两个结论:
- 第一, L e x i s t L_{\mathrm{exist}} Lexist 如果直接回传到整个网络,会干扰 diarization 主任务;只更新 existence head 更好
- 第二,EEND-EDA 虽然结构上支持可变人数,但经验上仍然受训练数据最大 speaker 数限制
4.6 在 CALLHOME 上,EEND-EDA 明显优于此前 EEND 变体
| CALLHOME 交叉验证 | 最强 x-vector 系 | SA-EEND | EEND-EDA | 结论 |
|---|---|---|---|---|
| 不用外部 SAD | - | 19.82 | 14.81 | 纯端到端条件下,EDA 明显优于 SA-EEND |
| TDNN-SAD | 17.80 | 17.41 | 13.36 | 同一外部 SAD 下,EDA 明显更强 |
| Oracle SAD | 14.21 | 15.90 | 11.72 | 即使用 oracle SAD,EDA 仍然最好 |
论文最常被引用的 CALLHOME Part 2 对比。
| CALLHOME Part 2 | DER |
|---|---|
| SC-EEND | 15.75 |
| SAD-OD-fiert SC-EEND | 15.32 |
| EEND-EDA(旧版设定) | 15.29 |
| EEND-EDA(本文) | 12.88 |
speaker counting:
| 方法 | CALLHOME Part 2 说话人数计数准确率 |
|---|---|
| x-vector + AHC | 56.4% |
| x-vector + AHC + VBx | 72.0% |
| SC-EEND | 76.4% |
| EEND-EDA | 84.4% |
4.7 在 AMI 上,EEND-EDA 能泛化到长会议
AMI 是长会议录音,域差异明显。
| AMI headset mix(Eval) | 无外部 SAD DER | Oracle SAD DER | 结论 |
|---|---|---|---|
| SA-EEND | 27.70 | 20.88 | 固定人数 EEND 基线 |
| 最强 x-vector 系(VBx) | - | 18.99 | 强传统基线 |
| EEND-EDA | 21.56 | 15.80 | 无外部 SAD、Oracle SAD 下更强 |
- EEND-EDA 对 30 分钟量级的长会议录音也能较好泛化
4.8 在 DIHARD 上,iterative inference+ 有帮助,但大人数仍然难
DIHARD 是更难的多域场景,表中指标是DER / JER 。
| 数据集 | 设置 | Plain EEND-EDA | EEND-EDA + Iterative+ | 最强 x-vector 系 | 结论 |
|---|---|---|---|---|---|
| DIHARD II | Oracle SAD | 20.54 / 46.92 | 20.24 / 45.62 | 18.21 / N/A | Iterative+ 有帮助,但传统系统仍更强 |
| DIHARD III Core | Oracle SAD | 18.38 / 43.69 | 17.86 / 41.69 | 16.56 / 38.72 | Core 条件下仍落后于最强 x-vector |
| DIHARD III Full | Oracle SAD | 14.91 / 36.93 | 14.42 / 35.30 | 15.65 / 33.71 | Full 条件下 EEND-EDA 在 DER 上反超 |
| DIHARD III Full | 无外部 SAD | 21.55 / 41.15 | 20.69 / 39.07 | 21.48 / 37.83 | Iterative+ 稳定提升,且 DER 已有竞争力 |
iterative inference+确实有效,尤其对 JER 更稳定- EEND-EDA 在
DIHARD III Full这类更复杂、更长尾的场景里有竞争力 - 但在大人数、多域、超难场景上,它还没有完全超越强 x-vector/VBx 系统
五、局限与后续
- 大人数场景仍然困难,即使有 iterative inference,模型表现仍然会受到训练分布限制。
- 训练大人数模拟数据成本很高,想让 EEND-EDA 更好处理 6 人、8 人、10 人场景,就得构造更多人数模拟混合。
- 现在的 EDA 用的是 vanilla LSTM encoder-decoder,未来可以探索更强的 attention-based 结构。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 4
4 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)