TASK01 | Reasoning Kindom
文章目录
https://ai-safety-book.github.io/index.html
https://ai-data-model-safety.github.io/
https://github.com/datawhalechina/reasoning-kingdom
https://github.com/lizixi-0x2F/CocDo
=========
不是因为它违反了第二定律——它没有。一个细胞对抗局部的熵增,是通过向外界排出更多的熵来实现的。它消耗有序的化学能(葡萄糖、ATP),把它降解为无序的废热,向外界排放。从整个系统(细胞+环境)来看,总熵依然在增加。但在细胞内部,维持着惊人的有序性:精确折叠的蛋白质,精确调控的离子梯度,精确转录的遗传信息。
生物体靠吃”负熵”为生。它从环境里摄取低熵的东西,排出高熵的废物,用这个差值来维持自身的秩序
维持内部秩序,只是活着的必要条件,不是充分条件。
一块晶体也是高度有序的。食盐的晶格,雪花的六角形,石英的规则排列。它们在合适的条件下可以无限期地维持自己的结构,不需要消耗能量,不需要排出废热。然而我们不会说晶体在”活着”。
原因在于:晶体的秩序是静态的。它不需要响应外界,不需要对变化做出反应,不需要预测未来。它只是被动地存在着。只要环境不超过它的物理极限(不融化,不破碎),它就能维持。
预测不是奢侈品,是必需品
预测能力的精细程度,和生物的认知复杂度是正相关的。这不是偶然的。能够更好地预测世界的生物,存活得更好,繁殖得更多,把自己的预测机制传递给后代。 进化在某种意义上是一个关于预测能力的筛选过程。
Karl Friston 的自由能原理(Free Energy Principle)把这个直觉形式化了。他的核心论点是:任何能够维持自身存在的系统,在数学上都必须在做某种形式的推断——最小化关于感觉输入的”惊异度”(surprise)。惊异度高,意味着世界和模型的预测差距大,意味着系统没能准确地预测即将发生的事情,意味着危险。所以,存活即推断 → [Friston et al., 2020, arXiv:2002.04501]。
自由能原理是神经科学家 Karl Friston 提出的一个理论框架,试图用一个统一的数学原理解释所有生命系统的行为。
核心思想非常直觉:一个活着的系统,必须不断对抗”被意外击中”——如果世界发生了完全出乎意料的事情,系统就可能无法存活。因此,所有能长期存活的系统,在数学上等价于”不断最小化惊异度”的系统,也就是”不断让世界更符合自己的预期”的系统。
这里的”自由能”是从热力学借来的词,但在这个语境里它是一个信息论量,表示**”模型预测与实际感觉之间的差距上界**”。最小化自由能 ≈ 让预测更准确。
你不需要掌握公式,只需要记住:这个原理说的是,推断和预测不是大脑的奢侈功能,而是任何能维持自身的系统的数学必然。
细菌在做时间差分,青蛙在做轨迹预测,黑猩猩在建意图模型——它们都在"预测",但我们不会说细菌在"思考"。
那么,预测和思考之间,有没有一条清晰的边界?还是说,这只是复杂度的差异,量变引发质变?
还有一个更让人不舒服的问题:【一个系统可以在完全不理解世界的情况下,做出完美的预测吗?】
如果可以——那"理解"这件事,究竟有什么用?
先把这个问题放着。继续往下走。
四、但预测不等于理解
我要在这里停一下,因为有一个陷阱很容易掉进去。
预测能力和理解能力,不是同一件事。
让我给你举一个例子。
一个优秀的气象预报员,可以在看到特定的云层形态、气压分布、风向数据之后,预测明天会下雨。他的预测可能非常准确。但如果你问他”为什么这种云层会导致降雨”,他需要用流体力学、热力学、水汽的相变动力学来回答——这是另一个层次的问题,比”明天会不会下雨”深得多。
或者更极端的例子:一个被训练好的神经网络,可以在大量历史数据上学习到”某种模式出现之后,某种结果会发生”,然后非常准确地预测这个结果。但它理解了”为什么”吗?它知道背后的因果机制吗?这是一个我们到本书结束都不会完全回答的问题,但我们会越来越靠近它。
这个区别很重要,因为它告诉我们:预测的准确性不能作为理解深度的代理指标。
【一个系统可以做到极其准确的预测,同时完全不理解它在预测什么】。它在【统计意义】上捕获了模式,但没有建立关于世界的【因果模型】。当条件改变——当它遇到训练分布之外的情况——它的预测就会崩塌,而且崩塌的方式往往是不可预期的、奇怪的。
那么,什么是真正的”理解”?
这需要我们建立一个层级。
五、从反射到推理:一个层级的故事
我想用一个比喻来引入这个层级。
想象你在学开车。
最开始,你的每一个动作都是有意识的:踩离合、换档、方向盘、油门——你要同时想这四件事,还要看路。这是认知负担极重的阶段。
几个月之后,你开车上下班,同时在想晚饭吃什么。换档、刹车、转弯——这些动作变成了自动的,从有意识的推理降落成了某种反射。
但如果突然出现一个小孩冲出来,你的意识会瞬间切回来,做一个非常不自动的决策——往哪里打方向盘?是硬刹车还是绕过去?这是在毫秒之间发生的高层推理。
这里有三个不同的处理层次在同时运行。它们不是互相替代的,而是共存的,在不同情境下被激活。
现在让我把这个比喻展开。
**第一层:反射。**输入触发输出,没有中间模型,没有关于世界的表征。膝跳反射:医生用小锤敲你的膝盖,你的腿抬起来。你没有想”腿应该抬起来”,整个回路在脊髓层面就闭合了,大脑皮层甚至不需要参与。这里有输入和输出,但没有推理。
**第二层:关联学习。**系统建立了刺激之间的统计关联。巴甫洛夫的狗:铃声响,分泌唾液。这里有学习——关联是通过经历建立起来的,不是硬编码的。但它还是关联,不是模型。狗不知道”铃声意味着食物将要出现”,它只是在执行一个被强化过的映射。如果食物换了地方,或者铃声和食物之间的时间间隔改变了,这个映射会混乱,但狗无法推断出”为什么”。
第三层:生成模型。这是一个根本性的转变。系统不再被动地等待输入然后反应,而是【主动地维护关于世界的内部表征】,持续生成对即将到来的输入的预测。
神经科学家提出的预测性编码框架描述的正是这个层次。大脑的基本工作方式,不是从下到上地处理感觉输入,而是从上到下地不断生成预测,然后只处理预测和实际感觉之间的误差。你走进一个黑暗的房间,你的大脑不是在空白状态下等待光子——它已经在预测这个房间里可能有什么,预测椅子在哪里,预测墙壁的质感。【预测误差才是真正被大量处理的信息】 → [Sennesh et al., 2022, arXiv:2208.10601]。
传统直觉认为大脑像一台相机:光进来,视觉皮层处理,你看到图像。预测性编码颠覆了这个图像。
这个框架认为:大脑的主要工作是自上而下地持续生成预测,然后只把"预测出错的部分"(预测误差)向上传递,供高层更新模型。大部分时候,你"看到"的东西有相当一部分是你的大脑自己脑补出来的。
证据之一:视觉错觉。即使你知道一张图是错觉,你依然无法停止被骗——因为你的高层模型已经固化了预测,它比单次的感觉输入更"顽固"。
这个理论解释了为什么大脑只消耗 20 瓦:它大多数时候只需要处理"出错"的那一小部分信号,而不是【全量的感觉数据】。
第四层:因果模型。生成模型仍然可能只是在捕获统计相关性,而不是因果机制。真正的因果模型能够回答三个层次的问题——Pearl 的因果阶梯:
如果天上有乌云,下雨的概率是多少(观测)?
如果我人工制造乌云会下雨吗(干预)?
如果当时天上没有乌云,昨天那场雨还会下吗(反事实)?
三个问题需要三种完全不同的能力,纯粹的统计相关性只能回答第一个。我们将在第六章深入这个区别。
第五层:元推理。能够【推理关于自身推理的能力】。知道自己的模型在哪里可靠,在哪里不可靠。一个孩子做完数学题觉得不对、重新算一遍——他在监控自己的推理过程。一个科学家问自己”这个实验能排除替代假设吗”——他在推理自己的推理方法是否充分。
六、信息有质量,推理有代价
1961 年,IBM 的物理学家 Rolf Landauer 发表了一篇论文,论证了一件当时听起来很奇怪的事:擦除一比特信息,必然向环境释放至少
kBTln2k_BT\ln2kBTln2 的热量。这里kBk_BkB 是玻尔兹曼常数,TTT是环境温度。
这个结论叫做 Landauer 原理。它的含义是:信息不是免费的。处理信息,尤其是擦除信息,有不可避免的物理代价。信息和热力学之间,有一条深层的联系 → [Chattopadhyay et al., 2025, arXiv:2506.10876]。
Landauer 原理说的是:在物理上,擦除一比特的信息,至少需要向环境释放 kBTln2k_BT\ln2kBTln2焦耳的热量(在室温下约为 3×10−213 \times 10^{-21}3×10−21 焦耳,非常小但不为零)。
kBTln2k_BT\ln2kBTln2 是玻尔兹曼常数(约 1.38×10−231.38 \times 10^{-23}1.38×10−23 J/K),TTT 是绝对温度(单位开尔文),
ln2≈0.693\ln2 \approx 0.693ln2≈0.693。这个公式的具体数值不重要,重要的是:这个数不是零。
为什么这重要?因为它意味着信息处理在物理上有代价,推理不是无消耗的抽象操作,而是真实的物理过程。这个原理后来被实验证实,也解决了困扰物理学家近一百年的"麦克斯韦恶魔"悖论(见正文).快的分子通过到一边,慢的分子留在另一边。
Landauer 指出:恶魔在观察每个分子的过程中,必须把上一个分子的信息擦除,才能处理下一个。而擦除信息必须释放热量。这个热量,精确地补偿了它想要利用的温差。恶魔不是赢家,它只是用一种隐蔽的方式在付账。
任何进行推理的系统,都在物理上付出代价。每一次信息处理,每一次模型更新,每一次预测误差的计算——这些都是真实的物理过程,都有热力学的代价。推理不是免费的,宇宙不允许免费的推理。
一个深远的推论:生物系统的推理架构,在进化压力下应该是高度节能的。大脑的预测性编码架构——只处理预测误差,而不是原始输入——在信息论和热力学上都是接近最优的。你的大脑大约消耗 20 瓦,大约是一个昏暗灯泡的功率,但它在做的计算,是任何现有的 AI 系统都无法以同等能耗复现的。这不是偶然,这是四十亿年进化压力的结果。
七、推理需要一个起点
贝叶斯推断是目前我们有的最精确的”如何根据证据更新信念”的框架: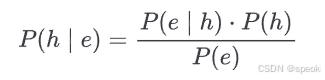
你有一个关于世界的假设 h,你观察到了证据e,然后更新你对h的信念,得到后验概率P(h|e)
但这个公式里有一个 P(h)——先验概率。它是你在看到证据之前,就已经持有的关于
的信念。贝叶斯更新不是从零开始的,它总是从一个先验出发的。
先验从哪里来?
在实践中,先验来自过去的经验,来自之前的推断,来自领域知识,来自——在生物系统的情况下——进化积累下来的内置假设。但如果你一路追溯,总有某个被不加论证地接受的初始信念。
这不是缺陷,这是推理本身的结构性特征:你必须从某个地方开始,而你起步的那个地方,不能被你自己的推理过程所完全证明。
对于生物系统,进化替它们解决了这个问题,至少是部分地解决了:那些持有”关于世界的好的先验”的个体存活下来,繁殖,把自己的神经系统结构传递给后代。自然选择是一个关于先验适配性的元优化过程。
但请注意一个微妙之处:这个优化过程本身不是推理。自然选择是盲目的随机变异加上筛选压力,它不知道自己在做什么,它只是保留了碰巧有效的东西。生物系统推理能力的基础,是被一个不会推理的过程优化出来的。这是一个值得停下来想一想的事情。
对于机器学习系统,训练数据扮演了类似的角色。模型从训练数据中蒸馏出【统计规律】,这些规律成为推理的【隐含先验】。但训练数据本身不是中立的——它来自特定的分布,带有特定的假设,反映了特定的世界。当系统遇到【训练分布之外】的情况,这些隐含先验会在哪里断裂?以什么样的方式断裂?
【任何推理系统都有一个或多个不能被自身推理过程所完全触达的锚点。 你可以更新你的先验。但更新的规则本身,依赖一个更底层的元先验。你可以质疑你的假设。但质疑的方式,依赖一套你没有质疑过的逻辑规则。这是一种有终点的递归——终点是某个被悬置判断的起始信念。】
锚点的好坏,决定了推理能走多远。
我们在第十五章会用更形式化的语言回到这里。现在,先把这句话记住。
=================
我们从热力学第二定律出发:宇宙走向混乱,生物体逆流而上,通过向外界排熵来维持自身秩序。但维持静态秩序是不够的——外界是动态的,变化的,有时是敌对的。所以生物体需要预测,需要在变化发生之前就做出响应。
预测能力有层次:从最简单的时间差分,到关联学习,到生成模型,到因果推理,到元推理。每一层都比上一层更强大,也更代价高昂——Landauer 原理告诉我们,信息处理有物理代价,推理不是免费的。
而所有的推理,都需要一个起点,一个不能被推理本身完全证明的先验锚点。这个锚点的来源,对于生物是进化,对于机器是训练数据——但两者都不是完美的,都带有各自的盲点。
这三个限制——代价、层次、锚点——是理解推理这件事的基础。
接下来,从第二章开始,我们要追溯历史:人类第一次尝试把推理变成一种机械过程,是什么样的?那些早期的尝试,在哪里成功,在哪里失败,又留下了什么?

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)