从零开始构建知识图谱
作者碎碎念
最近研究SmartNotBook的知识图谱功能,昨天让AI进行生成了,运行出来看了效果,可以说是非常一遍,我印象里的知识图谱就是展示物与物的关系,但是实际使用AI给我的介绍感觉不符合我的固有印象,于是我在不了解知识图谱是什么的情况下进行我自己所谓的优化,不过方向大致是对的,
- 首先优化AI提取节点的能力 也就是修改提示词,修改之前一个笔记几句话能产出16个节点虽然细致但是不符合我精简的要求。
- 其次就是节点之间关系的判断测试了 “蛊真人” 和 “蛊虫”两个竟然没有关系,后来发现也正常因为这个是小说里的关系正常语义划分也只有一个字相同,最开始用AI实现的就是单字划分找重合,显然极其无用,目前引入了分词器,在使用向量 + 余弦相似度的计算方式进行计算相似度;哈哈哈哈哈哈哈还是老办法。把单子划分作为降级方案了这样上一个失败了也不算太难看。
于是我今天意识到随后开始了解什么是知识图谱,总的来说是系统的了解一下吧。与我想的差不多。我是看了这个视频,讲的还是可以的,但是像这种的二手知识的质量无法保证全看解说人的知识水平、理解力和表述能力了,但是长篇大论的外文看着不是很方便也懒得看,哈哈哈哈哈哈,如果可以还是推荐大家去看看一手的信息吧,作者偶尔也会看的,到时候和大家分享。
知识图谱
因为作者是通过视频进行的了解简历的大纲就和视频内容类似,我自己也总结了一下,再配合AI辅助。给大家分享一下,可能不太准确大家帮我指正(●'◡'●)
1.什么是知识图谱
简单来说,知识图谱就是把世界上所有的“东西”和它们之间的“关系”,用一张巨大的网连接起来,让机器能像人一样去“理解”世界,而不仅仅是存储数据。
它的核心定义可以总结为:知识图谱本质上是一种语义网络。
-
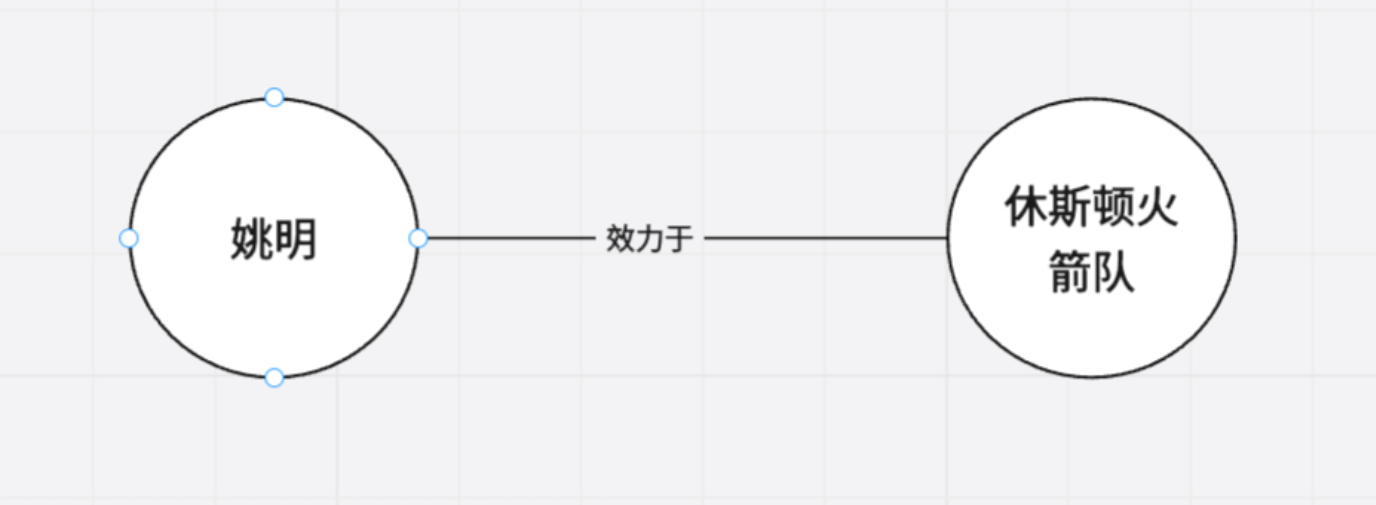
基本单元:三元组 知识图谱的最小单位是
(实体, 关系, 实体)或者(实体, 属性, 属性值)。-
例子:
(姚明, 效力于, 休斯顿火箭队) -
例子:
(姚明, 身高, 2.26米)
-
-
结构形式:图
-
节点:代表实体(如:人、地点、概念)。
-
边:代表实体之间的关系。
-
一句话总结: 列出实体连接他们,让整体看着清楚
2.知识图谱类型
1-LPG(Labelled Property Graph,属性图模型)
-
特点:
-
直观灵活: 节点和边都可以拥有属性(键值对)。
-
工业界主流: 非常适合业务系统,查询速度快,易于理解。
-
存储方式: 就像我们在白板上画图一样,点就是点,线就是线,上面直接贴标签。
-
-
代表数据库: Neo4j(最著名)、Nebula Graph、TigerGraph。
-
适用场景: 社交网络分析、金融反欺诈、推荐系统(因为这些场景关系复杂,且需要快速遍历)。

-
节点:代表实体(小李)
-
边:节点之间的关系(管理)
-
属性:键值对(职位:后端开发)
2-RDF()
-
特点:
-
标准严谨: 由W3C制定,强调语义的标准化和逻辑推理。
-
万物皆三元组: 边(关系)本身不能有属性(除非把边也变成一个节点),数据格式非常统一(Subject-Predicate-Object)。
-
学术界/语义网主流: 擅长处理跨数据源的融合和复杂的逻辑推理。
-
-
代表数据库: Virtuoso, GraphDB, Apache Jena。
-
适用场景: 生命科学、政府公开数据链接、需要高度标准化和互操作性的场景。
-
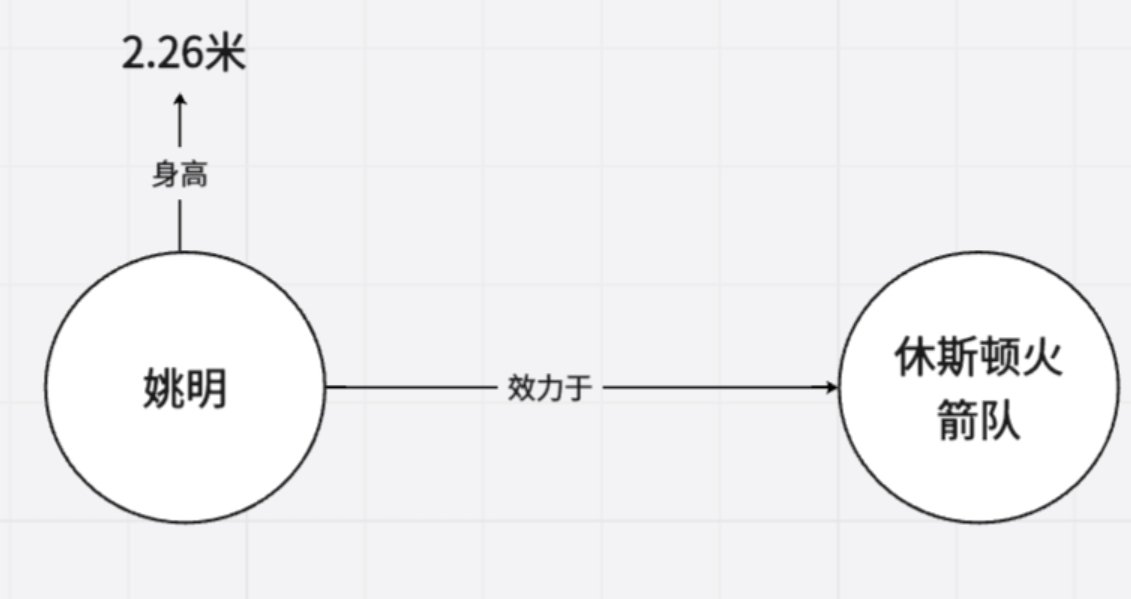
节点:代表实体(姚明)
-
边:节点之间的关系(效力于)
对比:
-
做业务系统、追求性能、开发速度快 -> 选 LPG。
-
做数据融合、追求语义标准、需要复杂推理 -> 选 RDF。
3.构建知识图谱流程
构建图谱是一个类似于从“原材料”到“成品”的加工过程。(●'◡'●)
-
信息抽取 从各种数据源中 识别 。
-
实体识别: 从文本中找出人名、地名、机构名等。
-
关系抽取: 判断两个实体之间是什么关系(如“A 投资了 B”)。
-
属性抽取: 获取实体的具体特征(如“成立时间”、“注册资本”)。
-
-
知识融合 解决“同名异物”和“同物异名”的问题。
-
例子: 数据源A说“苹果”,数据源B说“Apple Inc.”,系统需要知道它们指的都是那家科技公司,而不是水果。这一步叫实体对齐。
-
-
知识加工/推理
-
本体构建: 定义图谱的“骨架”或“模式”,比如规定“公司”只能由“人”创办。
-
质量评估与推理: 利用已有知识推导出新知识(如:A是B的父亲,B是C的父亲 -> 推理出 A是C的祖父)。
-
-
知识存储 将处理好的数据存入图数据库(如Neo4j)或RDF存储中,以便后续查询。
4.Graph RAG
这是目前的前沿技术,是大模型(LLM)与知识图谱的结合。
背景:传统RAG的局限
普通的RAG(检索增强生成)是基于“向量相似度”检索文本块的。
-
缺点: 如果你的问题需要跨越多个文档、通过逻辑关联才能回答,普通RAG往往找不到答案,因为它看不懂文档间的“关系”。
Graph RAG 的核心
利用知识图谱的结构化能力来增强大模型的回答。
-
原理:
-
先构建一个知识图谱(或者利用图数据库)。
-
当用户提问时,不仅搜索相关的文本片段,还在图谱中搜索相关的实体路径和子图。
-
将这些结构化的上下文喂给大模型。
-
-
优势:
-
全局理解能力: 能回答“请总结这两份财报中提到的所有共同风险”这类复杂问题。
-
可解释性: 答案是基于图谱中的事实路径生成的,减少了大模型的“幻觉”(胡说八道)。
-
解决多跳问题: 比如问“A公司的竞争对手的投资人还投资了谁?”,Graph RAG可以通过图谱的跳跃查询精准找到答案,而普通RAG很难做到。
-

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 12
12 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)