【ElasticSearch】BM25 深度解析:从概率模型到工程实践
一、什么是 BM25?
BM25(Best Matching 25)是目前工业界应用最广泛的信息检索排序函数,也是 ElasticSearch 的默认相似度算法。它诞生于 1994 年,由 Stephen Robertson 和 Karen Spärck Jones 基于概率检索模型(Probabilistic IR)推导而来。
在 ElasticSearch 8.x 中,你不需要任何配置,match 查询默认使用的就是 BM25。它回答的核心问题是:

这个问题看似简单,但 BM25 的优雅之处在于,它用一组紧凑的公式,同时处理了三个关键因素:
- 词频(TF):关键词在文档中出现了多少次?出现越多越相关,但边际收益递减
- 逆文档频率(IDF):关键词有多「稀有」?越稀有区分度越高
- 文档长度归一化:长文档天然会包含更多词,如何消除这个偏差?
二、全文公式拆解
2.1 总分公式
BM25 对查询中的每个词项(term)分别打分,然后求和:

这是一个典型的「各词项独立贡献,加总得出文档相关度」的结构。下面我们拆开看 IDF 和 TF Component 各自长什么样。
2.2 IDF 分量
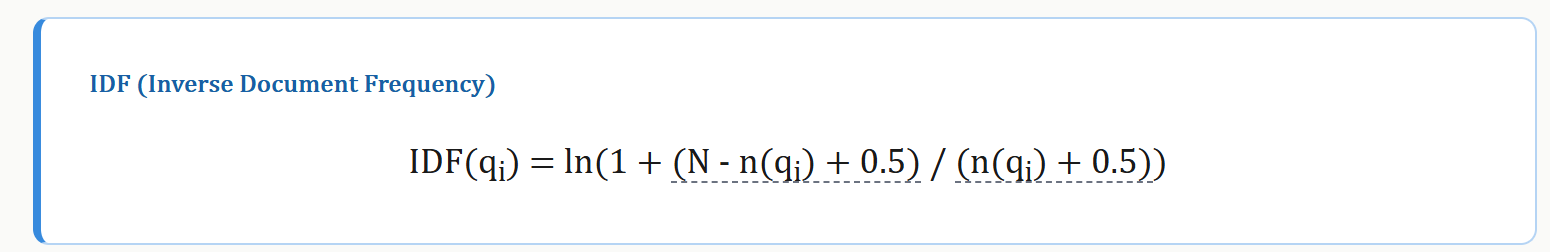
| 符号 | 含义 |
|---|---|
N |
集合中的文档总数 |
n(qi) |
包含词项 qi 的文档数(即 df, document frequency) |
直觉上:包含该词的文档越少(df 越小),IDF 越高,说明这个词越有区分力。比如「增值税」比「的」的 IDF 高得多。
注意平滑项 +0.5:分子和分母各加了 0.5,防止分母为零,同时避免极端值。当某个词出现在所有文档中时(df = N),IDF 不会变成 0 或负数,而是收敛到一个很小的正值。这就是 BM25 对经典 IDF 的平滑改进。
2.3 TF 分量(核心)

其中 K 是长度归一化因子:
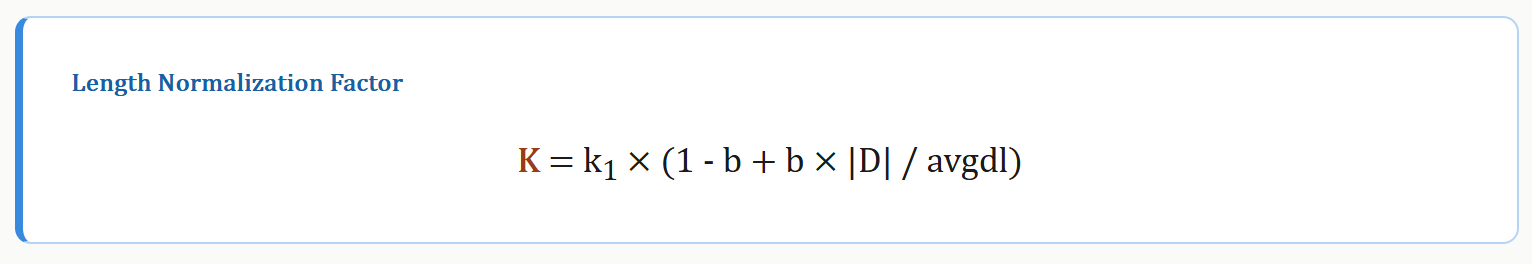
| 符号 | 含义 | 默认值 |
|---|---|---|
f(qi, D) |
词项 qi 在文档 D 中的出现次数 | — |
|D| |
文档 D 的长度(词数) | — |
avgdl |
集合中所有文档的平均长度 | — |
k1 |
TF 饱和参数,控制词频增长的衰减速度 | 1.2 |
b |
长度归一化参数,控制文档长度对评分的影响程度 | 0.75 |

图 1:BM25 公式结构分解 — 从总分到各分量
三、TF 饱和:边际收益递减
理解 BM25 的关键入口是 TF 饱和机制。在朴素 TF 模型中,词频越高分越高——「税务」出现 10 次的文档得分是出现 1 次的 10 倍。但现实中,一个词出现 3 次和出现 10 次的相关度差异远没有这么夸张。
BM25 通过以下结构实现饱和:
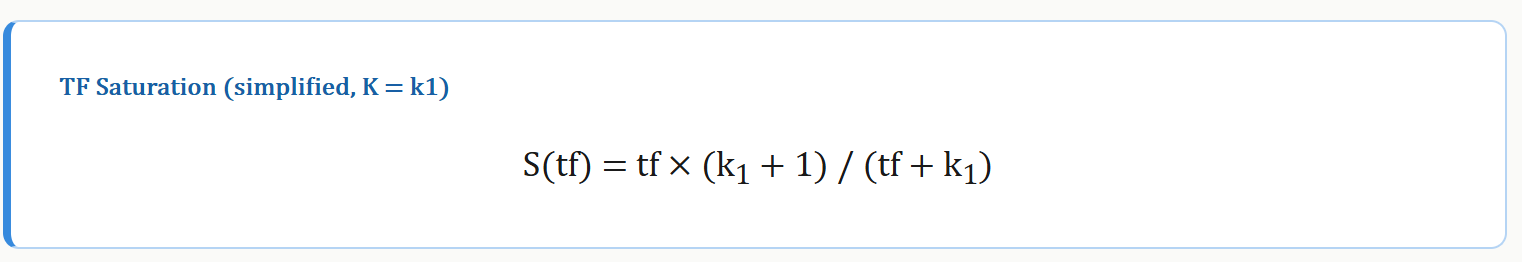
这是一个递增但有上界的函数。当 tf → ∞ 时,分子分母中 tf 的系数抵消,S(tf) → k1 + 1。也就是说,无论关键词出现多少次,TF 分量的贡献永远不会超过 k1 + 1。

k1 控制饱和的速度:
- k1 小(如 0.5):快速饱和,出现两三次后就趋平 → 适合短文本、关键词匹配
- k1 大(如 2.0):缓慢饱和,高频词仍有区分力 → 适合长文档、主题明确的场景
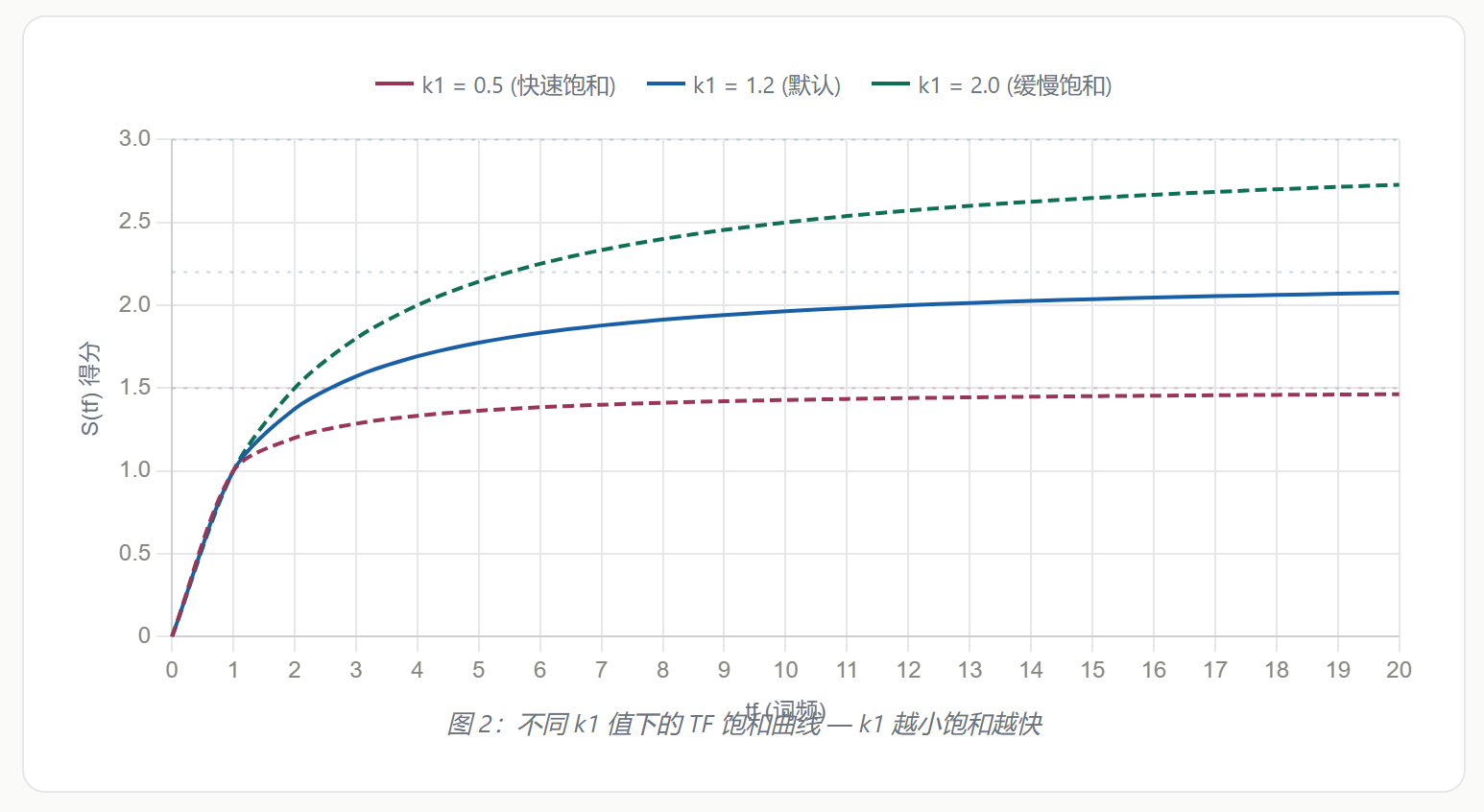
图 2:不同 k1 值下的 TF 饱和曲线 — k1 越小饱和越快
四、b 参数:长度归一化的「调音台」
b 参数控制的是文档长度对评分的影响程度。它通过以下公式发挥作用:

核心结构 (1 - b) + b × |D|/avgdl 是一个凸组合(Convex Combination),也叫线性插值。它在两个极端值之间做加权平均:

b 的影响路径是这样的:
- b 越大 → K 中 |D|/avgdl 的权重越大
- K 越大 → TF 分母越大 → TF Component 越小
- 结果:b 越大,长文档的 TF 得分被压制得越多
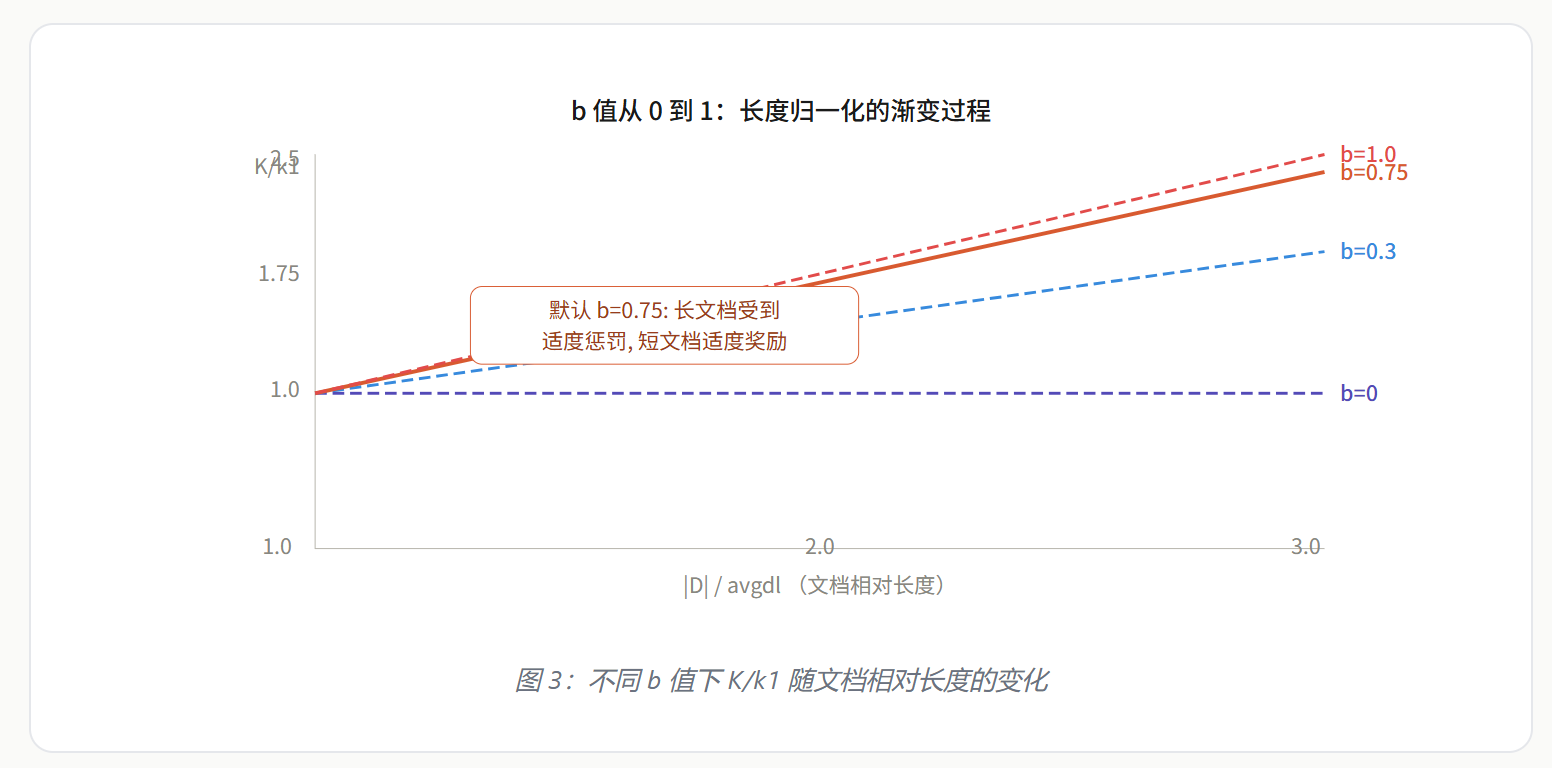
图 3:不同 b 值下 K/k1 随文档相对长度的变化
b = 0.75 意味着75% 的权重给了文档长度,25% 的权重给了常数 1。这是一个经过大量实验验证的「甜点值」——既能有效惩罚过长的文档,又不会过度压制长文档中真正高质量的内容。
五、k1 = 1.2, b = 0.75 的由来
这两个数值不是拍脑袋定的,而是历经近三十年、多轮大规模评测的产物。
5.1 历史脉络
| 年份 | 里程碑 | 关键参数 |
|---|---|---|
| 1976 | Robertson & Spärck Jones 提出二值权重模型 | 无 k1, b(只用 0/1) |
| 1983 | 引入 TF 权重,形成 BM 系列前身 | k1 参数出现 |
| 1994 | Okapi BM25 正式命名(Robertson 等) | k1 ∈ [1.0, 2.0], b ∈ [0.4, 1.0] |
| 2009 | Robertson & Zaragoza 出版 Understanding IR | k1=1.2, b=0.75 被确认为默认推荐值 |
5.2 TREC 评测验证
TREC(Text REtrieval Conference)是信息检索领域的「奥林匹克」。从 1992 年至今,BM25 在 TREC 的 Ad-hoc 任务中持续表现优异。大量研究者对 k1 和 b 进行了网格搜索:
- k1 的敏感范围:在 0.8 ~ 2.0 之间,性能波动约 5-10%。k1=1.2 是这个范围内的中位数偏保守的选择
- b 的敏感范围:在 0.3 ~ 0.9 之间,性能波动约 3-8%。b=0.75 在不同文档集上表现最稳定
实用建议:ElasticSearch 8.x 允许在 mapping 中自定义 k1 和 b:
// 自定义 BM25 参数
{
"mappings": {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
}
}
},
"settings": {
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": 1.5,
"b": 0.6
}
}
}
}六、公式结构指纹:为什么看一眼就知道是 BM25?
这是一个有趣的问题:为什么有经验的算法工程师看一眼公式就能认出这是 BM25?因为 BM25 有三个鲜明的结构指纹,几乎不可能与其他公式混淆。

图 4:BM25 的三个结构指纹 — 组合识别原理
指纹 1:分子分母差 k1
观察 TF 分量的结构:tf × (k1 + 1)(分子)vs tf + k1 × K(分母)。当 tf = 0 时,分子 = 0,整体得分为 0(没有出现就是没有出现)。当 tf > 0 时,分子恒比分母大 k1(因为分子中 tf 的系数是 1 而分母中是 1 乘以归一化因子 K ≤ 1 + b),这正是饱和特性的数学来源。
指纹 2:凸组合 1 - b + b × ...
这种 (1 - weight) + weight × ratio 的写法在统计学和工程中极为常见(凸组合 / 线性插值),但在 IR 公式中,它几乎唯一地指向 BM25 的长度归一化模块。看到这个结构就等于看到了「文档长度调节旋钮」。
指纹 3:平滑 IDF
ln(1 + (N - df + 0.5) / (df + 0.5)) 中的 +0.5 是 BM25 的标识性改动。经典的 Robertson-Spärck Jones IDF 是 log((N - df) / df),BM25 的平滑版本避免了 df = N 时 IDF = 0 的退化问题。
七、BM25 vs 向量检索:两种范式的互补
在 RAG(Retrieval Augmented Generation)时代,BM25 并没有过时。事实上,BM25 + 向量检索的混合搜索(Hybrid Search)已经成为当前检索架构的主流范式。

ElasticSearch 8.x 通过 RRF(Reciprocal Rank Fusion) 实现混合搜索:

RRF 不依赖原始分数的绝对值,只依赖排名序号。这使得 BM25 分数(通常 0~30)和向量相似度分数(通常 0~1)可以在同一框架下公平融合。
税务领域实战经验:在我们的税务合规 AI 应用中,查询「小规模纳税人增值税免税政策」时,BM25 能精确命中包含「小规模纳税人」和「增值税」的法规条款,而向量检索能召回语义相近但用词不同的「小微企业税收优惠」。两者互补,Recall 可提升 15-25%。
八、工程实践建议
8.1 何时调参?
| 场景 | 建议 k1 | 建议 b | 理由 |
|---|---|---|---|
| 短文本(标题、商品名) | 1.2 ~ 1.5 | 0.0 ~ 0.3 | 短文本长度差异小,无需强归一化 |
| 长文档(论文、法规) | 1.2 ~ 2.0 | 0.7 ~ 0.9 | 长文档需惩罚长度偏差,允许 TF 缓慢饱和 |
| 混合长度文档集 | 1.2 | 0.75 | 默认值,最稳定的通用选择 |
| 日志 / 错误信息搜索 | 0.5 ~ 1.0 | 0.1 ~ 0.3 | 快速饱和、精确匹配更重要 |
8.2 ElasticSearch 中的调优流程
- 建立基线:用默认 k1=1.2, b=0.75 跑一批标注数据,记录 MAP/NDCG
- 网格搜索:k1 ∈ {0.8, 1.0, 1.2, 1.5, 2.0},b ∈ {0.3, 0.5, 0.75, 0.9}
- 交叉验证:确保参数泛化能力,避免过拟合特定查询集
- 监控 IDF 异常:关注 df 接近 N 的高频词,考虑加入停用词或使用 synonyms
8.3 常见陷阱
- 中文分词质量直接影响 BM25 效果:IK 分词器的粗细粒度选择、自定义词典维护至关重要
- avgdl 的计算范围:确保 avgdl 是在整个索引上计算的,而不是单个 shard
- BM25 不适合所有场景:对纯语义匹配需求(如问答系统),向量检索可能更优
九、总结
BM25 之所以能统治信息检索领域三十年,不仅因为它的效果经过充分验证,更因为它在简洁性和表达力之间取得了精妙的平衡:
- 一个公式同时处理 TF 饱和、IDF 平滑、长度归一化三个核心问题
- 两个参数(k1, b)提供了足够的调优空间,同时默认值在大多数场景下都足够好
- 三个结构指纹让算法工程师可以一眼识别——这是好的数学设计的标志
- 与向量检索互补,在 RAG 架构中仍然不可或缺
理解 BM25 的每一个分子和分母,不仅能帮你更好地调优 ElasticSearch,更能让你在构建 RAG 系统时做出更明智的检索策略选择。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 3
3 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)