揭秘Transformer:AI变革的核心引擎
🤵♂️ 个人主页:小李同学_LSH的主页
✍🏻 作者简介:LLM学习者
🐋 希望大家多多支持,我们一起进步!😄
如果文章对你有帮助的话,
欢迎评论 💬点赞👍🏻 收藏 📂加关注+
目录
多头自注意力机制--Multi-Head Self-Attention
Step1:Query, Key, and Value Matrices
什么是Transformer?(不多赘述)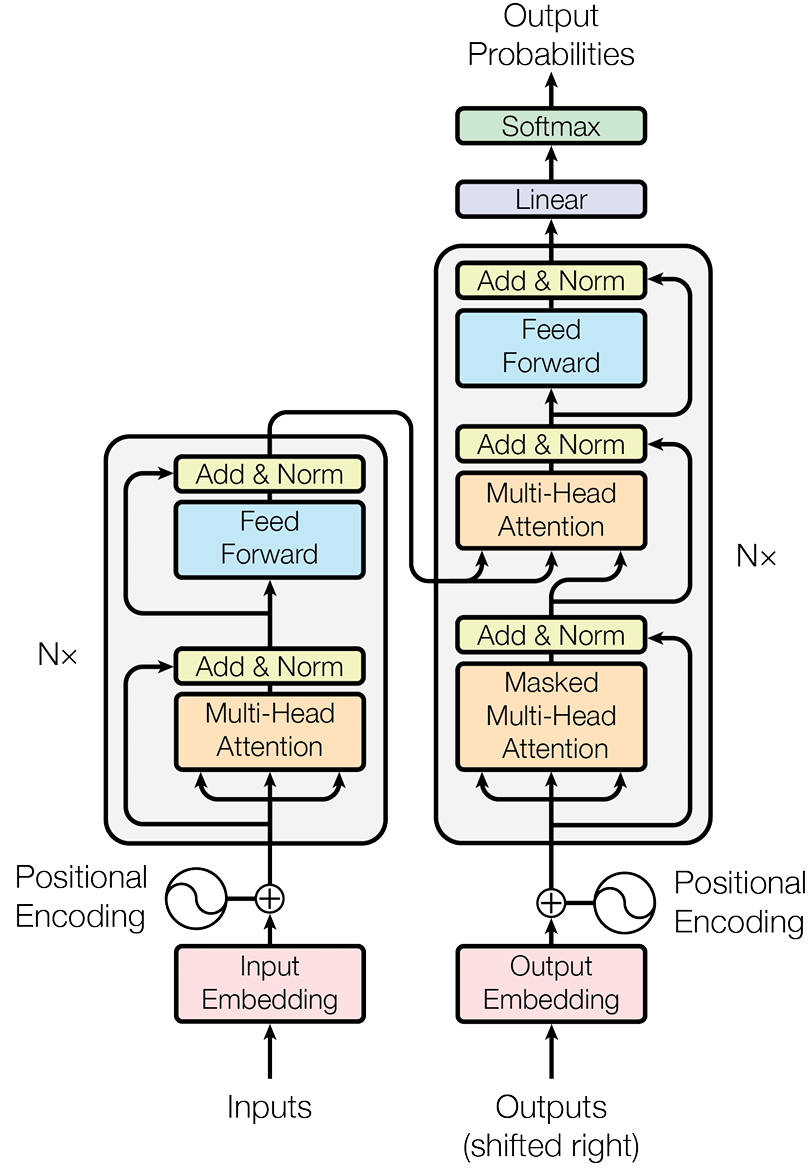
Transformer 从根本上改变了人工智能的方法。Transformer 首次出现于 2017 年的开创性论文 《Attention is All You Need》 中,此后成为深度学习模型的首选架构,除了文本之外,Transformer 还被应用于 音频生成, 图像识别, 蛋白质结构预测, 甚至 游戏, 证明了其在众多领域的广泛适用性。
从根本上说,Transformer 模型基于下一个词预测的原则运作:给定用户的文本提示,最有可能出现在该输入之后的下一个词是什么? Transformer 的核心创新和强大之处在于其对自注意力机制的使用,能够比以前的架构更有效地处理整个序列并捕获远程依赖关系。
GPT-2模型系列是文本生成 Transformer 的杰出代表。Transformer 解释器 由具有 1.24 亿个参数的 GPT-2(小型)模型提供支持,它与当前最强大的大语音模型共享许多相同的架构组件和原理,使其成为理解基础知识的理想起点。
本文以GPT-2为例对Transformer的运行流程进行可视化分析与详解。
Transformer 架构
每一个文本生成式 Transformer 包含如下 三个关键部分:
- Embedding: 文本输入被分成称为“token”的更小的单元, 可以是单词或子词。这些标记被转换为称为“Embedding”的数字向量,它们捕捉单词的语义。
- Transformer Block是模型的基本构建块,用于处理和转换输入数据。每个块包括:
- 注意力机制是 Transformer 块的核心组件。它允许Token与其他Token进行通信,捕获上下文信息和词语之间的关系。
- MLP(多层感知机)层是一个前馈神经网络,独立地对每个Token进行操作。注意力层的目标是在Token之间路由信息,而 MLP 的目标是完善每个Token的表示。
- 输出概率:最终的线性层和 softmax 层将处理后的嵌入转换为概率,使模型能够对序列中的下一个Token进行预测。
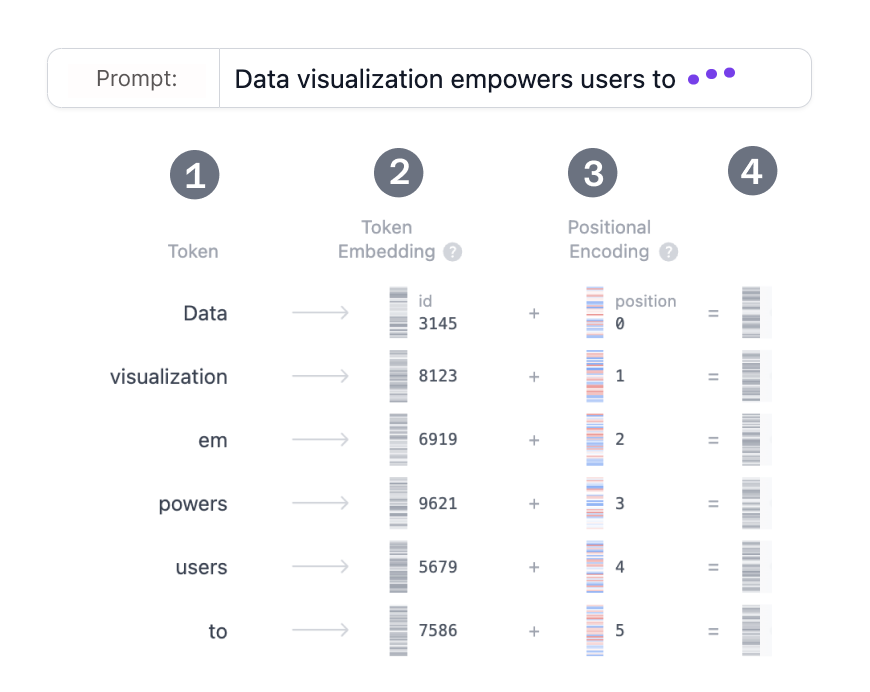
Prompt:Data visualization empowers users to
Embedding
假设你想使用 Transformer 模型生成文本。 输入需要转换为模型可以理解和处理的格式。 嵌入将文本转换为模型可以处理的数字表示。 要将提示转换为嵌入,我们需要
- 对输入进行Token化
- 获取Token Embedding
- 添加位置信息
- 将Token和位置编码相加得到最终嵌入。
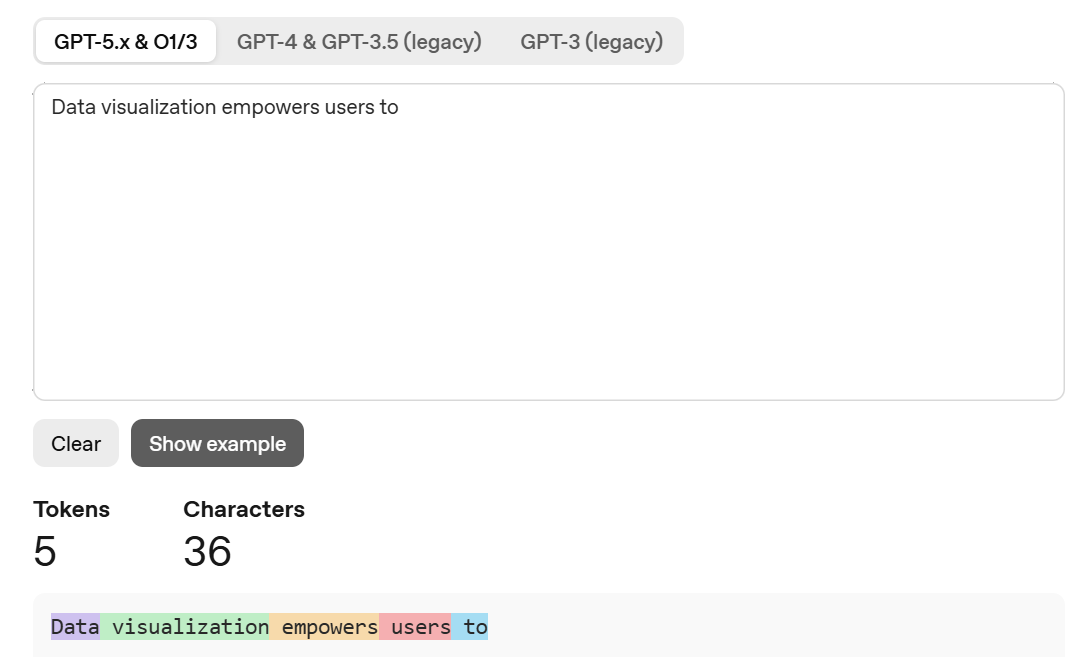
Step1:Token化
Token化是将输入文本分解成更小、更易于管理的部分的过程。 这些Token可以是一个词或一个子词。 单词 "Data" 和 "vizualization" 对应于唯一的Token,而单词 "empowers" 被拆分为两个Token。 词元的完整词汇表是在训练模型之前决定的:GPT-2 的词汇表有 50,257 个唯一的Token。 现在我们已经将输入文本拆分为具有不同 ID 的Token,我们可以从Embedding中获取它们的向量表示。
推荐使用https://platform.openai.com/tokenizer尝试词表分词
分词器示例
Step2:Token embedding
词汇表中的每个Token表示为一个 768 维的向量;向量的维度取决于模型。 这些嵌入向量存储在一个形状为 (50,257, 768) 的矩阵中,包含大约 3900 万个参数。
Step3:位置编码
Embedding层对每个Token在输入提示中的位置信息进行编码。 不同的模型使用不同的位置编码方法。 GPT-2 从头开始训练自己的位置编码矩阵,并将其直接集成到训练过程中。
Step4: 最终嵌入
最后,我们将Token编码和位置编码相加,得到最终的Embedding表示。
Transformer Block
Transformer 处理的核心在于 Transformer 块,它由多头自注意力机制和多层感知机层组成。这些块按顺序依次堆叠,Token表示从第一个块到第十二个块逐层演化,使模型能够对每个Token建立起复杂的理解。
多头自注意力机制--Multi-Head Self-Attention
自注意力机制使模型专注于输入序列的相关部分,使其能够捕获数据中的复杂关系和依赖关系。
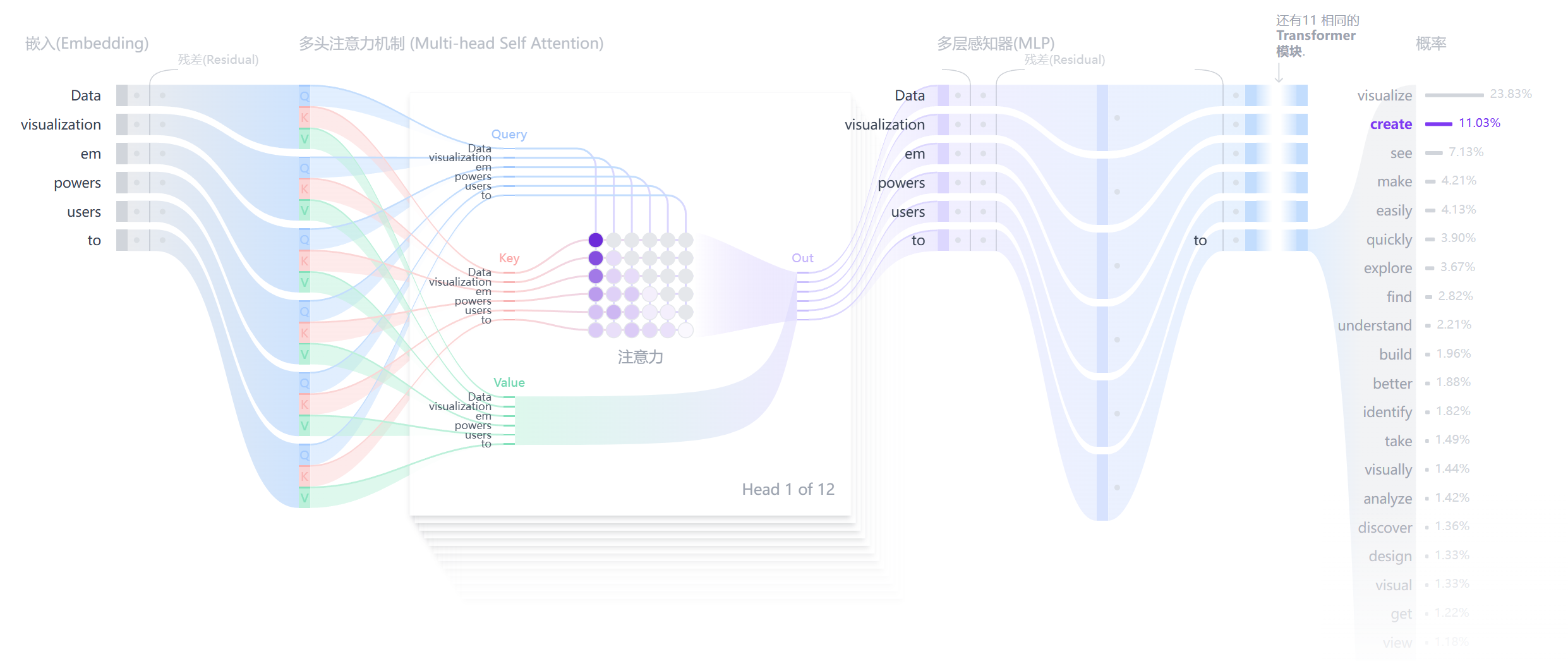
Step1:Query, Key, and Value Matrices

每个词符的嵌入向量都被转换为三个向量:Query(Q) Key(K) 和 Value(V)。 这些向量是通过将输入嵌入矩阵与 Q K 和 V 的学习权重矩阵相乘得到的。
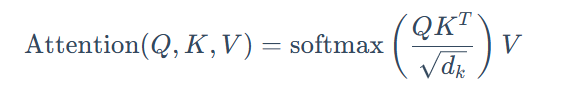
- Query (Q)是你在搜索引擎栏中输入的搜索文本。
- Key (K) 是搜索结果窗口中每个网页的标题。 它代表了Query可以关注的可能的token。
- Value (V) 是显示的网页的实际内容。 一旦我们将适当的搜索词(Query)与相关结果(Key)匹配, 我们希望获得最相关页面的内容(Value)。
通过使用这些 QKV 值,模型计算注意力分数,决定了每个词符在生成预测时应该获得多少关注。
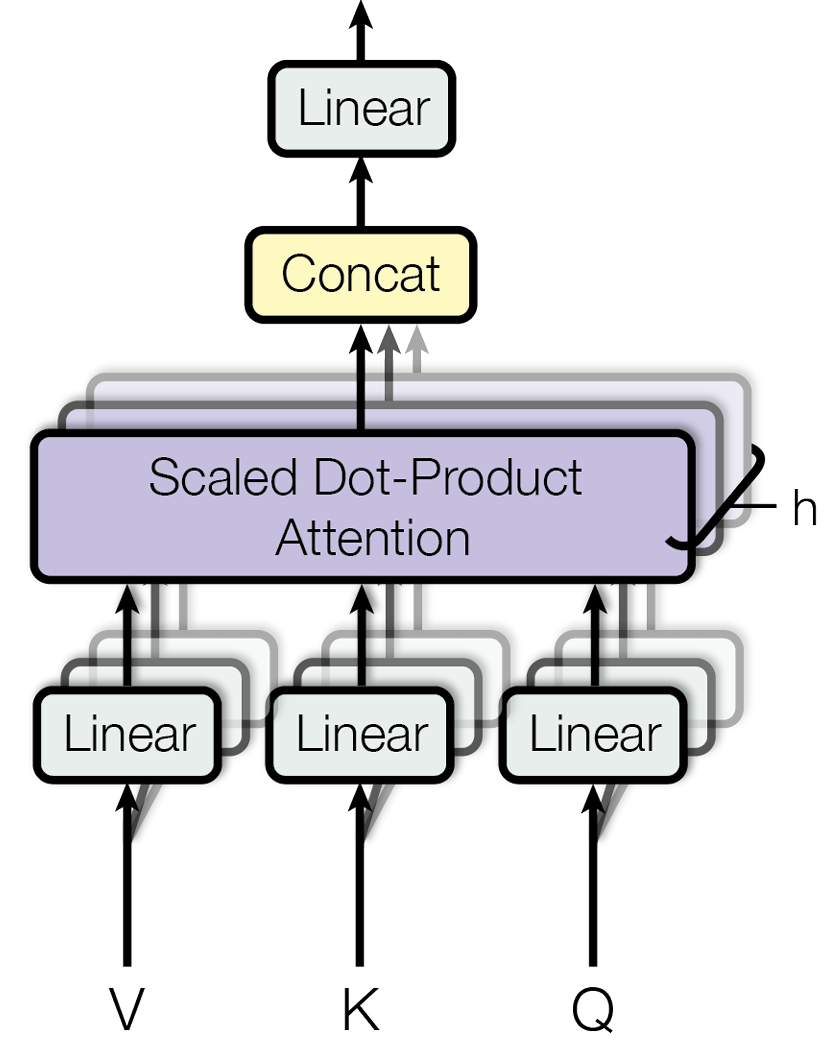
它将原始的 Q, K, V 向量在维度上切分成 h 份(h 就是“头”数),每一份都独立地进行一次单头注意力的计算。这就好比让 h 个不同的“专家”从不同的角度去审视句子,每个专家都能捕捉到一种不同的特征关系。最后,将这 h 个专家的“意见”(即输出向量)拼接起来,再通过一个线性变换进行整合,就得到了最终的输出。
Step2: 掩码自注意力
掩码自注意力机制专注于输入的相关部分,同时阻止访问未来的Token。
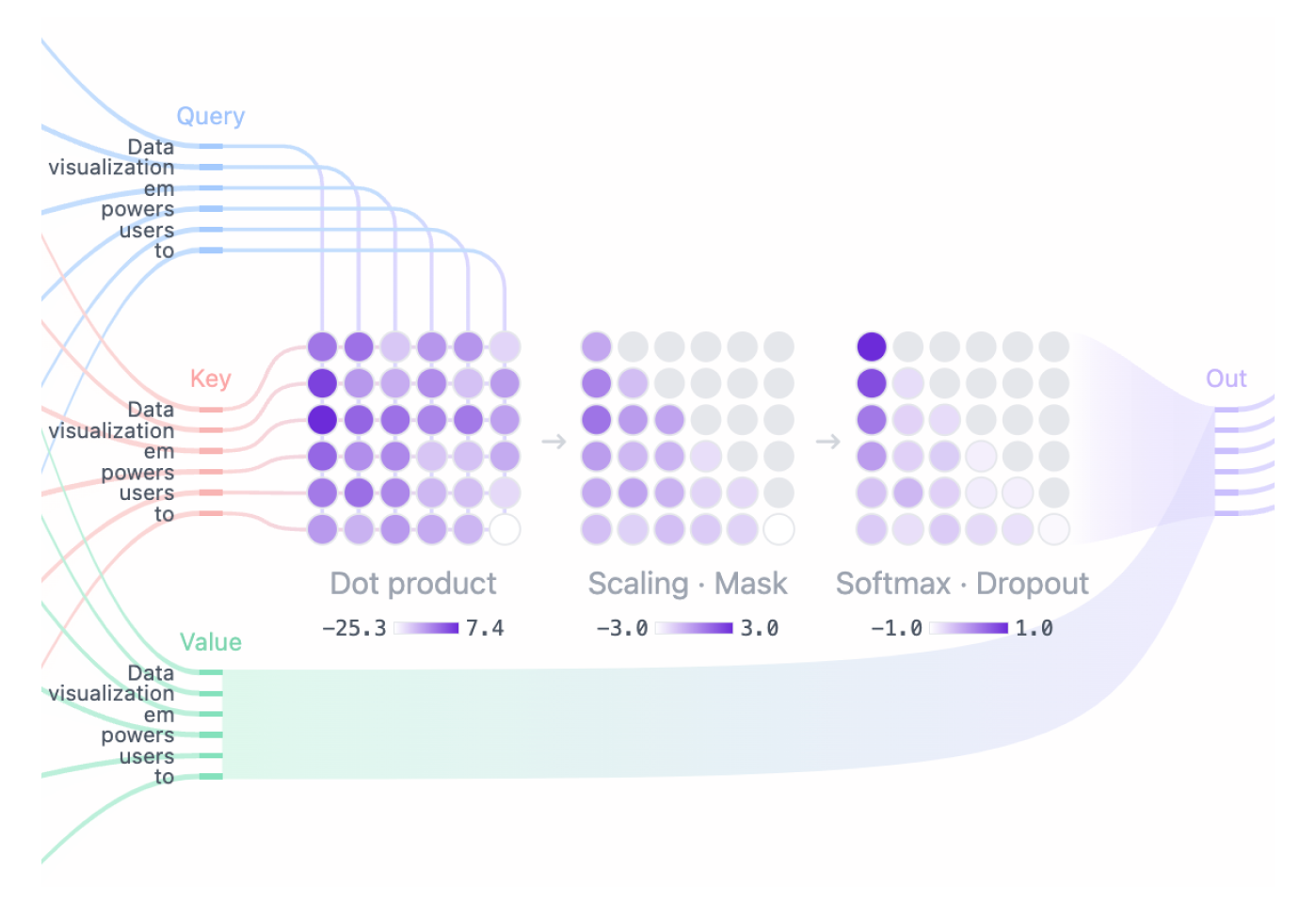
- 注意力分数 Attention Score:Query 和 Key 矩阵的点积决定了每个Query与每个Key的对齐,生成一个反映所有输入词元之间关系的方阵。
- 掩码:对注意力矩阵的上三角应用掩码,以防止模型访问未来的Token,将这些值设置为负无穷大。 模型需要学习如何在不“窥视”未来的情况下预测下一个Token。
- Softmax:掩码后,注意力分数通过 softmax 操作转换为概率,该操作取每个注意力分数的指数。 矩阵的每一行总和为 1,表示该行Token左侧所有其他Token的相关性。
Step3:输出(全连接)
模型使用掩码自注意力分数并将其与 Value 矩阵相乘,得到自注意力机制的最终输出。 GPT-2 有 12个自注意力头,每个头捕捉Token之间不同的关系。 这些头的输出被连接起来,并穿过一个线性投影。
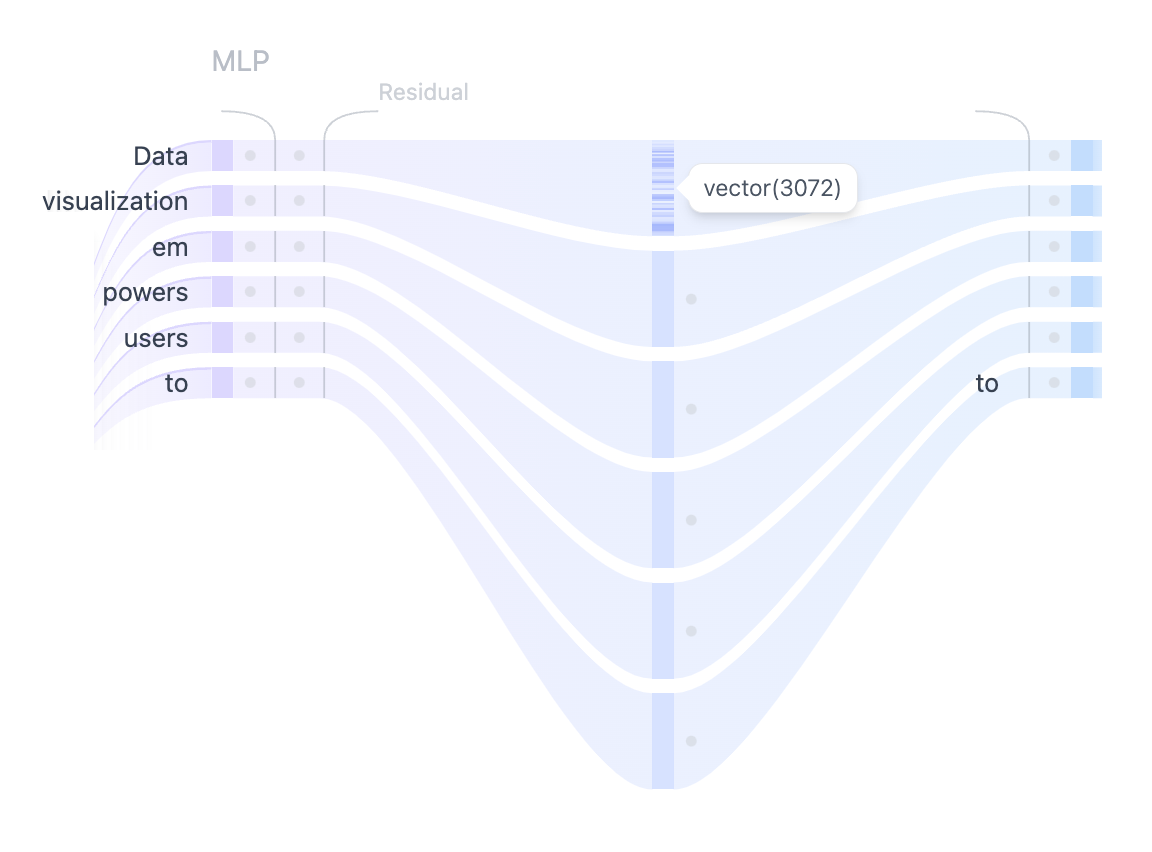
使用 MLP 层将自注意力表示投影到更高维度,以增强模型的表示能力
在多头自注意力机制捕获了输入Token之间的各种关系之后,连接后的输出会传递给多层感知机 (MLP) 层,以增强模型的表示能力。 MLP 块由两个线性变换组成,中间有一个 GELU 激活函数。第一个线性变换将输入的维度增加了四倍, 从 768 增加到 3072。第二个线性变换将维度减少回原来的大小 768,确保后续层接收维度一致的输入。
与自注意力机制不同,MLP 独立处理Token, 只是简单地将它们从一种表示映射到另一种表示。
这种“先扩大再缩小”的模式,被认为有助于模型学习更丰富的特征表示。
输出概率
在输入经过所有 Transformer 块处理之后,输出会被传递到最终的线性层,以便为Token预测做好准备。 该层将最终表示投影到一个 50,257 维的空间中,词汇表中的每个词元在这个空间中都有一个对应的值,称为 logit。 任何词元都可以是下一个词,因此此过程允许我们简单地根据词元成为下一个词的可能性对它们进行排序。 然后,我们应用 softmax 函数将 logits 转换为总和为 1 的概率分布。 这将允许我们根据词元的可能性对下一个词元进行采样。
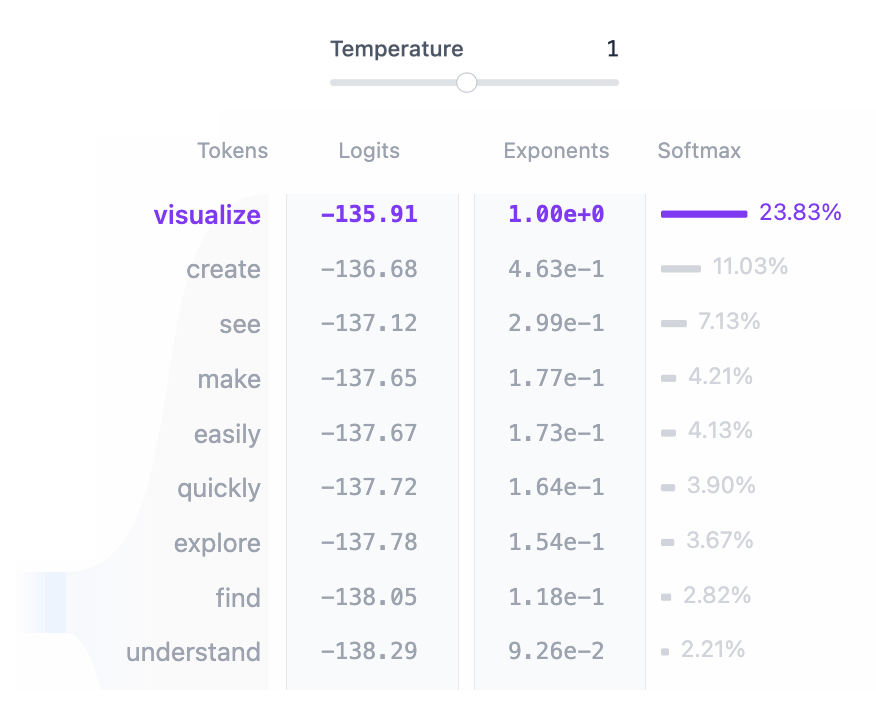
最后一步是通过从这个分布中采样来生成下一个Token。temperature 超参数在这个过程中起着至关重要的作用。 从数学上讲,这是一个非常简单的操作:模型输出 logits 只是简单地除以 temperature:
temperature = 1:将 logits 除以 1 对 softmax 输出没有影响。temperature < 1:较低的temperature通过锐化概率分布使模型更加自信和确定性,从而导致更可预测的输出。temperature > 1:较高的temperature会创建更柔和的概率分布,从而在生成的文本中允许更多的随机性——有些人将其称为模型的“创造力”。
本文不对三大参数:Temperature、Top-K、Top-P详解

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 24
24 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)