支持变长序列的Mamba-1训练
作者:FR、XHR、ZJC from HPC Group@ Shanghai AI Lab,WZR、CZ和SP from NDS Group@ Shanghai AI Lab
TL/DR
Mamba 是一种专为处理长序列设计的新型架构,其相对于传统的 Transformer 架构能够显著提高超长序列文本的处理速度。在训练过程中,我们通常通过增加批次大小来提升训练效率。然而,实际应用中,数据序列长度往往分布不均,简单地通过填充(padding)来调整至固定长度可能会引入大量冗余数据,导致拖慢训练速度。为了解决这一问题,我们在 Mamba 框架中引入了一种新的序列处理机制。该机制能够打包(Pack)不同长度的序列,动态地识别和处理不同序列的上下文,避免上下文混淆,保证处理的一致性。这种方法能够减少冗余数据,显著提高训练速度。实验结果表明,在 NVIDIA A100 GPU 上使用 Mamba-1.4B 模型进行预训练时,与传统的单序列处理方案相比,加速比达到了 3.06 倍。这一改进不仅有效解决了变长序列处理的问题,还大幅提高了整体的训练和推理速度,使得模型在各种硬件上都能达到预期的训练效率。
问题背景:Mamba 与变长序列
Mamba-v1[1] 长什么样子
Transformer 模型是最常用的大模型基础模型,但是它有两个天然的劣势:1) 无法对序列之外的 token 进行建模;2)计算复杂度随着序列长度增加呈二次方增长。为了解决这些问题,大量研究提出了多种模型结构,如 H3 [2]、RWKV [3]、TTT [4]等模型结构,其中 Mamba 模型近期引起了广泛关注。关于 Mamba 核心算法和代码实现的解读,这里推荐两篇优秀的博客:
编辑亚东:用代码解读 Mamba,读透读懂最有可能替代 Transformer 的基础架构207 赞同 · 32 评论 ![]() https://zhuanlan.zhihu.com/p/679487178
https://zhuanlan.zhihu.com/p/679487178
此处仅对 Mamba 中涉及变长序列训练的部分做简要分析,Mamba 模型由多个 Mamba block 串联而成,如下图:
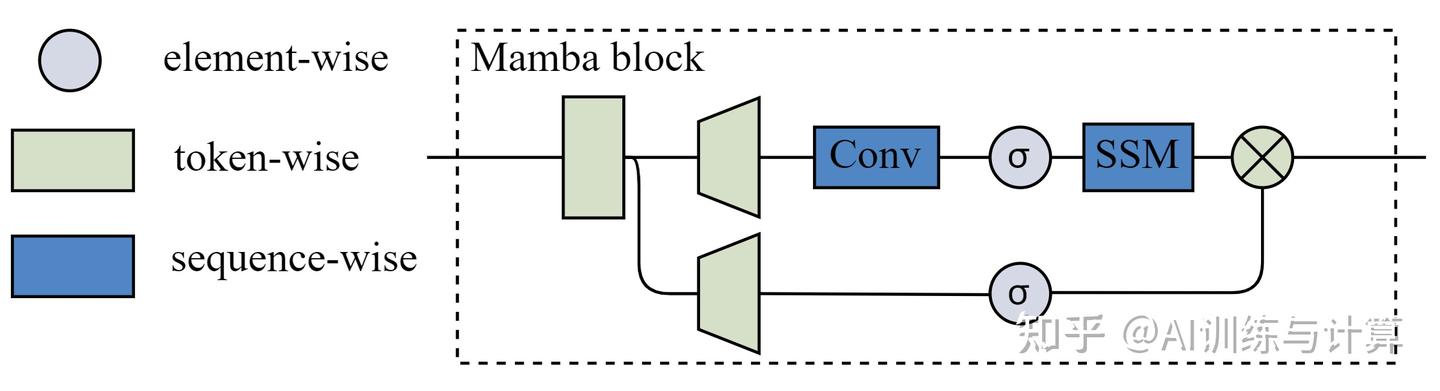
Mamba block中的步骤
Mamba Block 中的计算步骤(fast 实现中,大部分计算步骤都有 cuda 算子实现)共有三类:
其一是 sigmoid,是 element-wise 的。输入 tensor 中的各个 scalar 独立的决定输出结果而互不影响。
其二是 gemm(linear)、MSENorm,是 token-wise 的,不同 token(seqlen 维度)之间互不影响结果。
其三是 conv1d 和 SSM,是 sequence-wise 的,来自同一 sequence 的相邻 token 之间有影响。
Transformer 中对变长序列的支持
在实际训练中,训练语料的长度有时候差异很大,如何使用这些长度不一的数据来训练模型一直是一个备受关注的问题。目前,已经有一些工作集中在 Transformer 中可变长度序列的训练问题上,比如 flash-attn 库有针对变长序列的 API[7]:
- flash_attn_varlen_qkvpacked_func
- flash_attn_varlen_kvpacked_func
- flash_attn_varlen_func
ByteTransformer[8] 提出了一种无填充算法,该算法将输入张量与可变长度序列打包,并以所有 Transformer 的定位偏移向量为索引。同时采用了核融合和 CUTLASS 分组 GEMM 优化等方法来提高整体性能,实现了在可变长度输入下高达 131% 的速度提升。
Mamba1 中面对变长序列的问题
Transformer 可以通过一个特定的 attention mask,实现对 packed 序列进行并行训练的同时,防止不同序列的上下文混淆。与 Transformer 不同,Mamba1 当前并无此结构。当 packed 数据直接输入到 Mamba block 中时,其中 sequence-wise 会产生错误的结果。
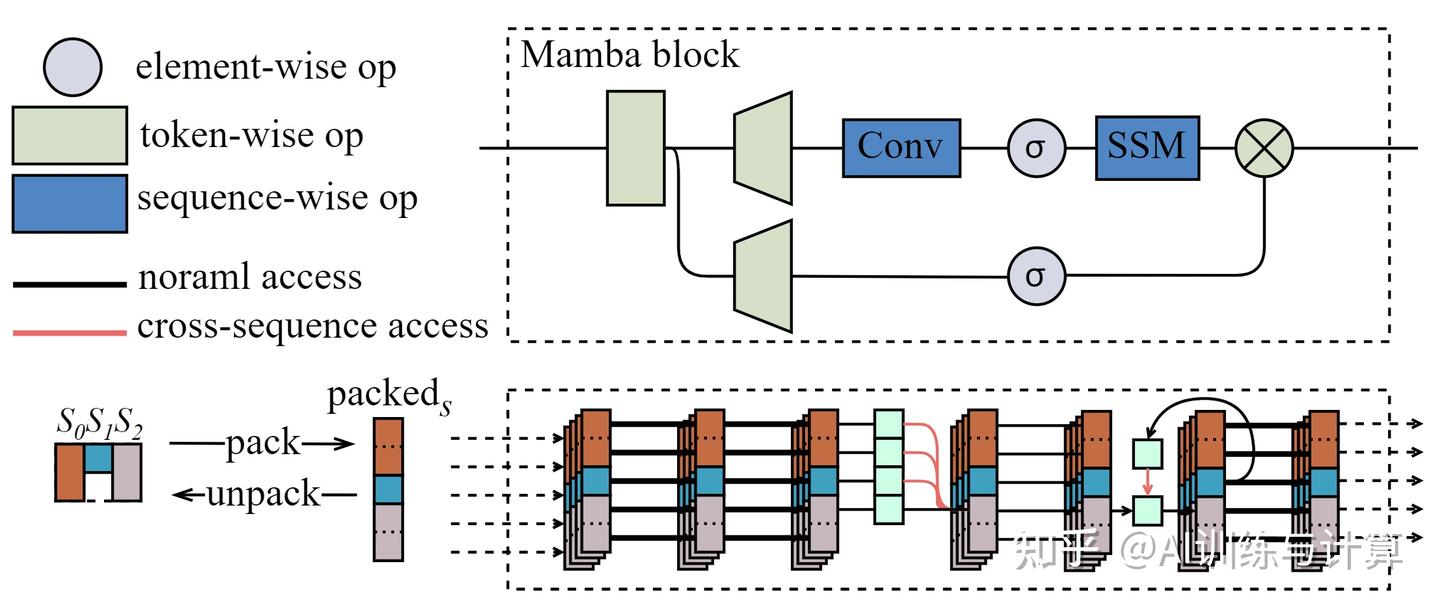
Mamba block 中各步骤处理 packed 输入示意图

目前处理变长序列的方法
简单处理变长序列的方法主要有三种:
1) Padding:将同一批次的数据填充到该批次中最长的序列长度,但是这些 padding 的无效信息会造成额外的计算和显存消耗,造成计算和存储资源的浪费。在训练过程中,通过使用一个掩码(mask)来帮助模型忽略填充的部分。下图展示了右边界填充方案(right padding)的示意图:
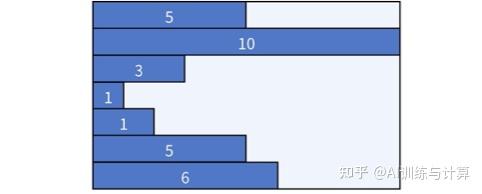
Right padding 的 batch 输入示意图,蓝色块为不等长的序列
2) 梯度累加(Gradient accumulation):梯度累加方案是一种有效的方法,可以优化 Batch 处理,避免过多填充0对训练效率的影响。具体来说,这种方法在不对 Batch 内的序列进行 padding 的前提下,分别对每个序列进行前向和后向运算,将其梯度累加,从而在数学上达到与Batch方法等效的效果。这种方法虽然没有额外的无效数据的开销,但是会存在频繁launch kernel的开销,训练效果大打折扣。
3) 直接拼接序列 (Concat sequences):直接拼接原始序列,不对模型代码进行任何修改或者使用掩码机制,直接输入拼接后的长序列。这种方法虽然训练速度更快,是这些方法的性能上界,但是会导致上下文混淆,潜在影响模型训练效果,实际训练中不会应用这种方法。
不同处理方法的性能对比
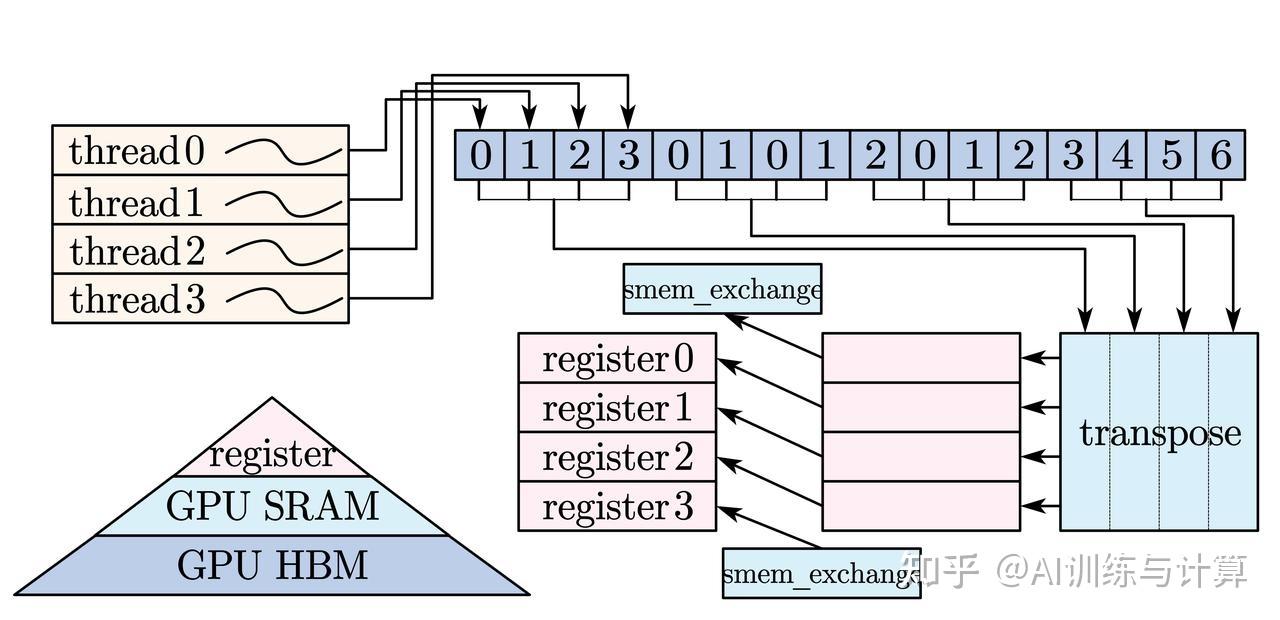
我们在 1.4B 的 Mamba 模型上对上面不同的处理方法使用相同的输入序列(序列长度之和为4096)进行训练,对比训练过程中的tgs(token/GPU/second)。前100个 step 的结果如下:
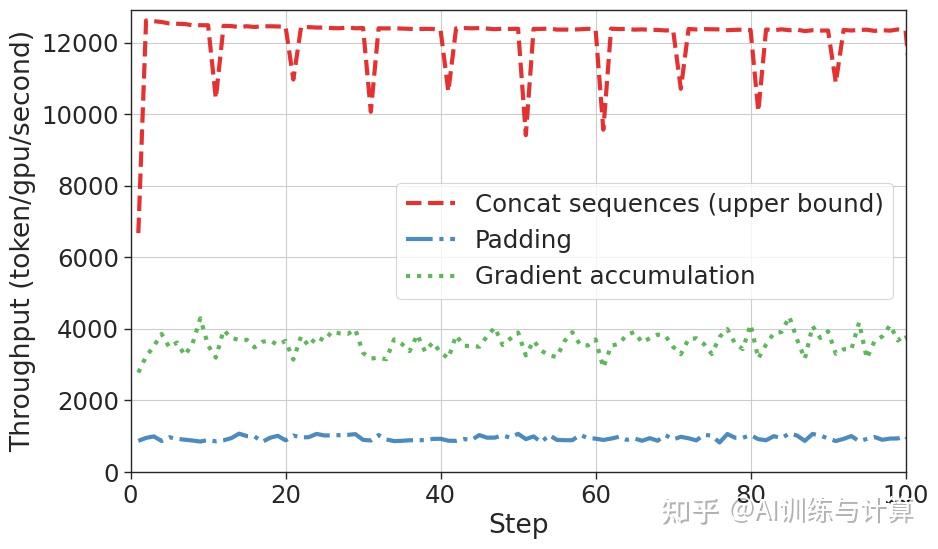
直接拼接序列输入到模型的吞吐量最高,而 Padding 输入最低,这是由于填充了大量0。梯度累加方案 tgs 高于 Padding 方案,表明该方案在避免填充多余0的情况下能够提高训练效率。然而,与拼接序列相比,梯度累加仍未达到高效的水平,tgs 相差接近3倍。
结论:虽然 Padding 方法是普遍采用的方式,但随机堆叠序列导致大量的填充0会显著影响吞吐量和训练速度。而梯度累加方案的性能优于 Batch 方案,但效率仍然偏低。我们希望提出一个更优的变长序列处理方法,保持高吞吐的同时,避免上下文混淆。在接下来的内容中,我们将梯度累加方案作为 baseline 进行讨论。
支持变长序列的 Mamba 模型训练
基本原理
Mamba1 的论文中有一个段落提示了在 Mamba 上的变长序列的实现思路,见下图:

简单来说,在 Mamba 模型的核心模块 Selective SSM 上,对于 Pack 后的序列,信息会在 Pack 序列之间相互渗透,导致无法有效地保持序列间的独立性的问题,为了解决这个问题,我们可以在每个序列的边界处重置 SSM 的中间状态,这可以手动实现,也可以令模型在预训练过程中自己学到。为了避免模型性能损失,同时复用过去以 Attention 为核心的 LLM 的经验,我们希望使用人工实现的方法。
然而,官方代码仓库中目前并未实际支持该方法。同时,社区也有很多用户提了 issue 询问实现的方法,作者均表示目前并未实现,可以使用 Padding 方法进行训练。
https://github.com/state-spaces/mamba/issues/236 [9]

https://github.com/state-spaces/mamba/issues/356 [10]
在这项工作开展初期,我们的同学对这个方法进行了简单实现,引入了一个cu_seqlens 参数,只对原算子做了最小修改并且保证 API 与 FlashAttention 接近,这个实现的的训练速度相比padding方法提高了 2-4 倍。我们在官方仓库提交了一个PR [9],吸引了很多用户进行讨论。
https://github.com/state-spaces/mamba/pull/244 [11]
但是这个方案相比理论最优速度仍然差距较大,我们需要更进一步优化算子。按照上述分析,我们需要修改的是两个 sequence-wise 算子(conv1d 和 ssm),使得不同 sequences 之间互不干扰,则每个 Mamba block 以及整个 Mamba 模型都可满足输入 packed 数据中的每个独立 sequences 之间互不干扰。下面讨论如何修改这两个算子。
conv1d_pack 算子
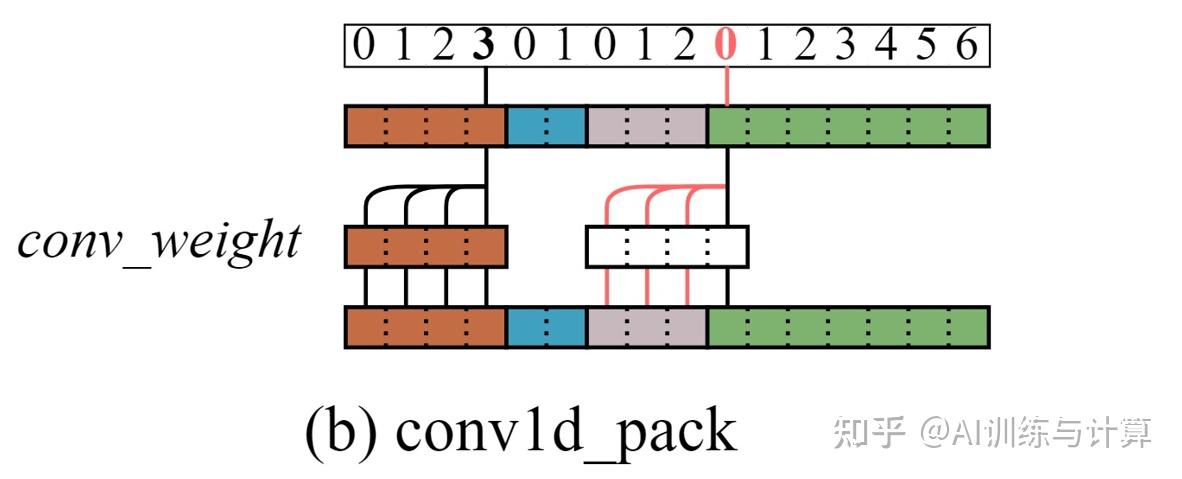
将 conv1d 算子改造为能正确处理 packed 数据的 conv1d_pack,其实只需要在原卷积逻辑基础上增加“识别到 sequence 头部 token 并终止向前卷积”即可。该识别需要用到辅助结构 position_indices,它在 pack() 过程中生成,它保存了对应 token 在被 pack 之前的序列位置信息。如图(a),将4个长度分别为[4,2,3,7]的 sequence 进行 pack,会获得一个长序列及其对应的 position_indices。
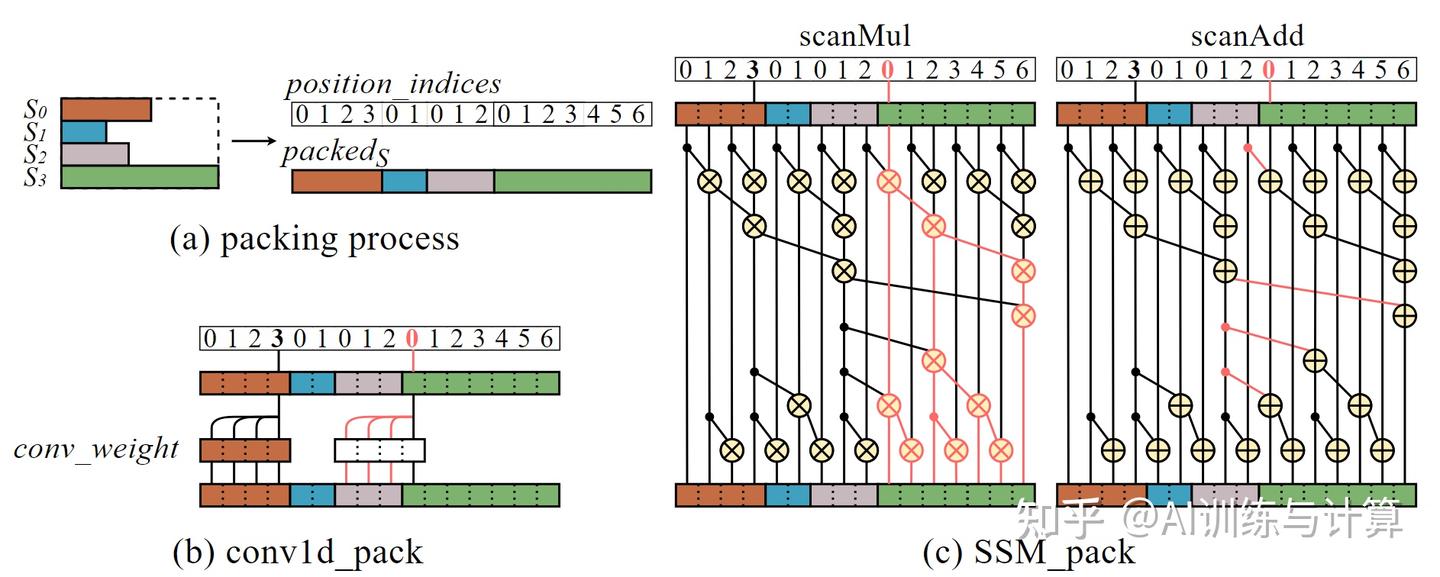
conv 算子固定向前卷积 conv_width-1 项(在Mamba中通常设置 conv_width = 4 ),如图(b) 中 中的末项能正常完成卷积。但对于一个 sequnece 的前 conv_width-1 项,如图(b) 中的首项则出现了跨 sequence 的访问。
如下所示 Algorithm1,标红的 line3~4 是在原本 conv1d 中插入的判断逻辑: 若 position_indices < conv_width,则需要进行卷积提前终止,如此即可完成前向过程的改造。

反向过程的改造同理,不过要额外针对 dx 和 dweight 的计算进行提前终止卷积。由于 position_indices 存储的是对应位置的顺序位置信息,而反向传播时需要的是逆序位置信息,需要通过读取该位置向后 conv_width-1 的 position_indices 的值来获得。
SSM_pack算子
作为 Mamba 中的核心步骤,SSM 算子在处理 packed 数据时的 sequence 间状态传递发生在 (1a) 计算中。
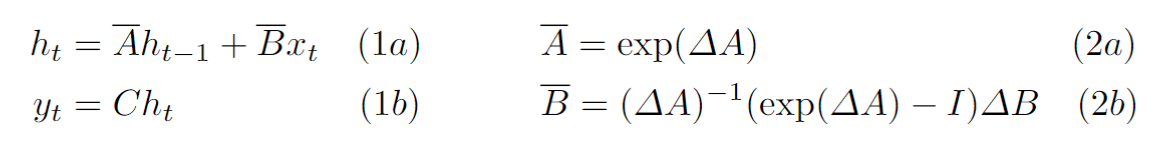



,即




对于第 m(m>a) 个线程处理的被乘数:
- 计算该次乘法前,若当前乘数项 n > a,则该被乘数 m 的值未被置为0
- 计算该次乘法前,若当前乘数项 n <= a,则该被乘数 m 的值已经被置为0
上述两条规律在 ScanAdd 步骤中的表现为:

软硬件协同优化
上述两个算子改造引入了对 position_indices 的额外读写开支,我们优化了其访存逻辑,复用 Mamba 处理 hidden_state 的结构大幅降低额外读写开支以及空间申请开支。
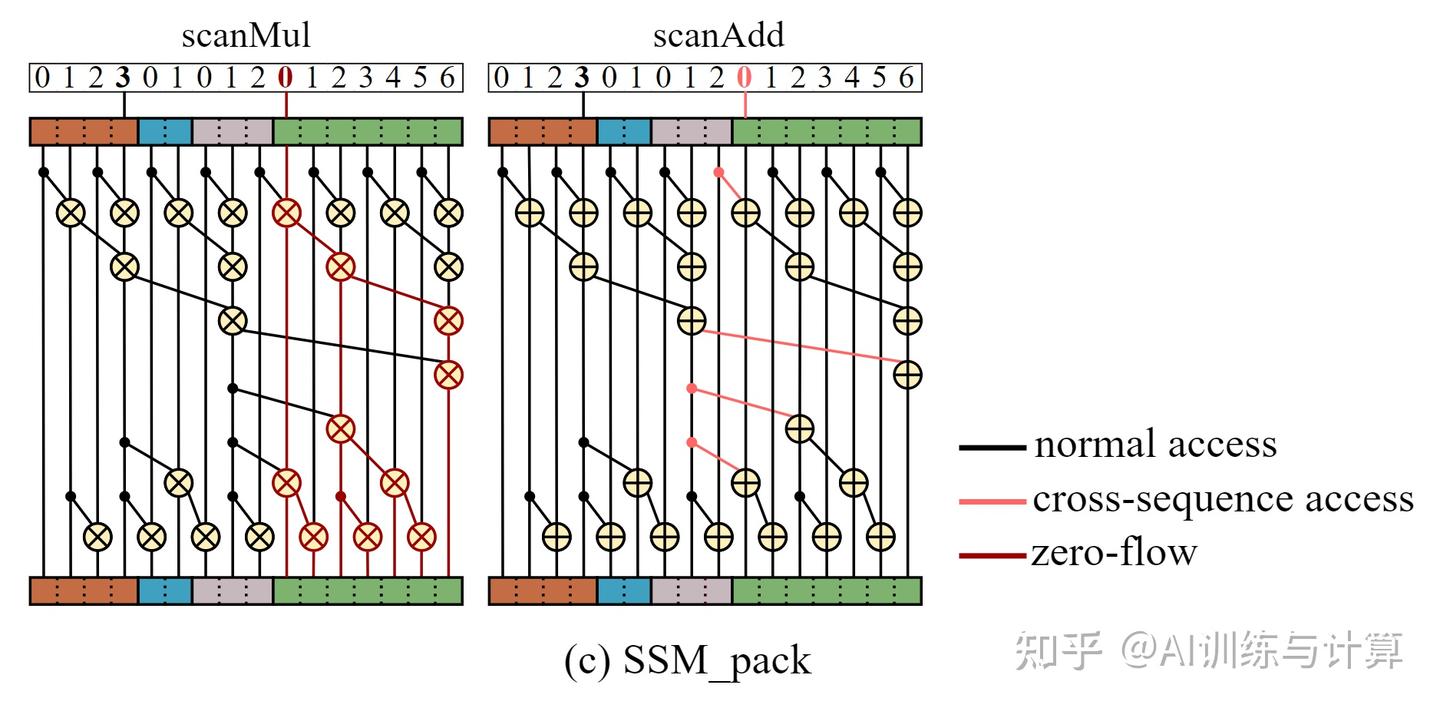
如下图,读入过程,使用连续的 thread 将位于 HBM 上连续的 position_indices 读入到 smem 中,接着在 smem 中将 warp-striped arrangement 的数据转换成 blocked arrangement 并传到对应 thread 的 register 中,进而参与 SSM_pack 的前向与反向、conv1d_pack 的前向的运算。而 conv1d_pack 反向需要逆序位置信息,需要借助 smem 将数据错位再传递到对应 register 中。本过程开销为 n 次 HBM 读取(n 与 seqlen 有关,最多16次),2n 次 smem 的读写,n 次 register 的写入。其中读 HBM 为主要开销,已经通过合并访存进行优化。计算过程中对 position_indices 的使用均是用于读register,开销可以忽略不计。
读取 position_indices 过程中的访存操作
实验结果
我们在 8 * NVIDIA A100-80GB 进行数据并行训练 Mamba-1.4B(layer=48, dim=2048),采用 seqlen=4096,itype=bfloat16;语料源自真实语料库,长度在 57 到 2048 之间,平均长度 64,每 step consumed_tokens = 262K; 对比四个方案——拼接序列方案(理论最优方案)、Padding、梯度累加、以及我们的方案。可以看到,我们相较于梯度累加方案提供了 3.06x 的加速比,该方案距离理论最优方案仍有 11.0% 的性能差距,这是 position_indices 的额外读写开支造成的。
各方案训练吞吐量
对算子加速效果进行分析,选取 Padding 方法作为 baseline(因为梯度累加的kernel duration不具备统计价值)。fwd-bwd 过程有 3.91x 加速比, 其中主要加速效果来自GEMM和SSM算子耗时的缩短,即packed_sequence 的稠密性消除了大量空转运算,而那些表现为访存密集型的 conv1d 则加速空间较小。
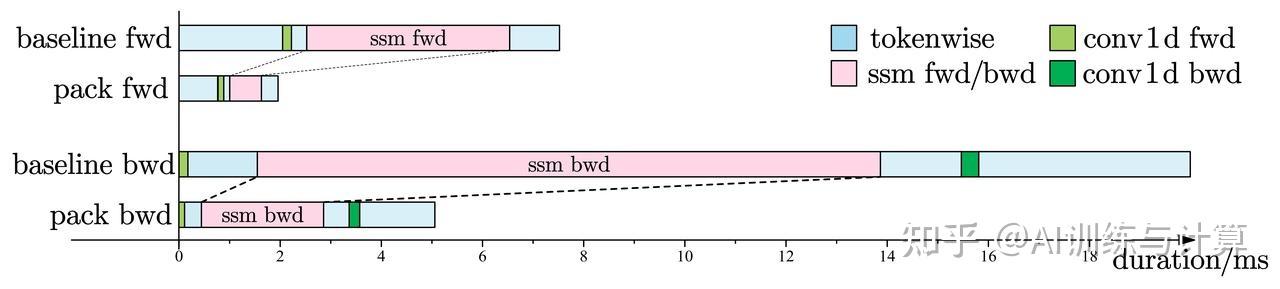
fwd-bwd过程算子耗时
结论与讨论
综上,我们通过引入 position_indices 并修改 Mamba 中的 SSM 和 Conv1d 算子,使 Mamba 训练可以高效利用变长序列样本,大幅提高了整体训练吞吐量。
然而,本工作仍有改进之处,如 position_indices 带来的额外开销仍有待改进,以及对 pack 方法的优化:
本工作使用的 pack 方法是简单地按照接收的顺序打包序列,当包裹无法放得下下一个序列时时就封包。在InternLM2 [12] 的预训练数据集上,使用这种顺序打包法会带来 19.1% 的平均 padding 率。而采用局部贪心算法,先对一部分待打包序列进行排序的再进行贪心打包,可以将 padding 率降到最低 0.46%,但这种方法仍然会带来额外的排序时间开销。
我们计划在未来的工作中解决这一问题,允许在长序列末尾cut这个序列到两个子序列,这两者之间仍然可以保持数据传递, 这样可以在保证语料完整性的同时将填充率降低到零,甚至是支持无限长序列的并行策略。
如果你喜欢我们的内容,请 点赞 、收藏⭐️、关注➕我们!
也欢迎在 评论区与我们互动 !
你的支持是我们持续创作的动力~
Reference:
- https://arxiv.org/abs/2312.00752
- https://arxiv.org/abs/2212.14052
- https://arxiv.org/abs/2305.13048
- https://arxiv.org/abs/2310.13807v2
- https://zhuanlan.zhihu.com/p/683978639
- https://zhuanlan.zhihu.com/p/679487178
- https://github.com/Dao-AILab/flash-attention/blob/3669b25206d5938e3cc74a5f7860e31c38af8204/flash_attn/flash_attn_interface.py#L1048
- https://arxiv.org/abs/2210.03052
- https://github.com/state-spaces/mamba/issues/236
- https://github.com/state-spaces/mamba/issues/356
- https://github.com/state-spaces/mamba/pull/244
- https://arxiv.org/abs/2403.1729

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 7
7 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)