科技公司搭建内部知识库,避开这6大误区,让知识真正变现
在数字化转型的浪潮下,对于一家科技公司而言,代码是骨骼,数据是血液,而内部知识库则是企业的“大脑皮层”。
我们见过太多这样的案例:公司斥巨资采购了最先进的文档系统,甚至引入了炫酷的AI大模型,结果上线三个月后,日活归零,系统沦为无人问津的数字垃圾场。
为什么你的知识库建不起来?为什么员工宁愿在群里吼一声,也不愿去库里搜一下?
根本原因在于,很多企业把知识库当成了项目来做,而不是当成产品来运营。今天,我们就来拆解搭建内部知识库时最容易踩的6大致命误区,并给出破局之道。
误区一:把知识库当成网盘或数据垃圾场
这是最普遍的认知偏差。很多团队认为,知识库就是把所有的Word、PDF、PPT丢进服务器。
- 现状:只有文件的堆砌,没有结构。同一个技术方案,存在v1、v2、最终版、打死不改版。员工搜出来十个文档,根本不知道哪个是现行有效的。
- 痛点:缺乏上下文。一份技术文档如果没有背景说明、适用场景和失效时间,它就是一堆死数据。
破局之道:
知识库的核心不是存,而是理。必须建立结构化思维。每一份入库的知识,都应该像产品一样被打上标签、关联相关项目、注明版本状态。拒绝文件上传即结束,要追求知识入库即服务。
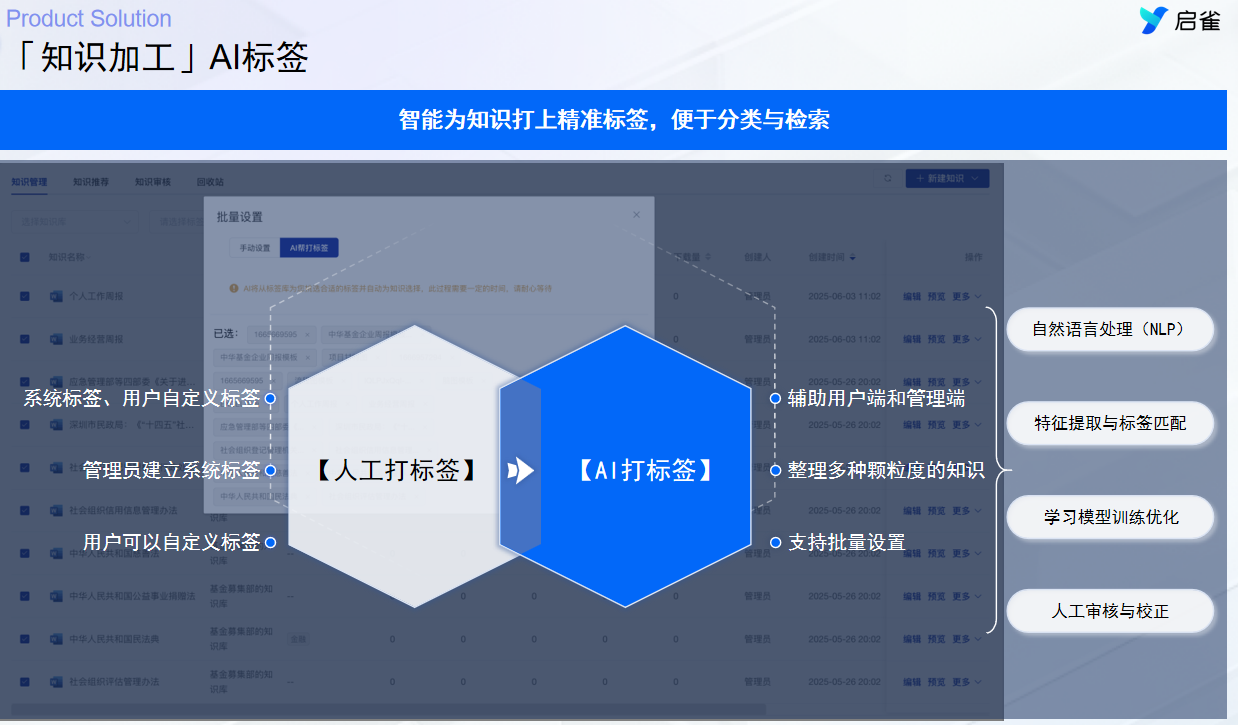
误区二:重技术选型,轻运营机制
很多CTO或技术负责人容易陷入工具控的怪圈,花费大量时间对比启雀、Notion、Confluence、飞书文档等工具的优劣,却忽略了内容运营。
- 现状:系统搭建得很漂亮,但里面空空如也。或者充满了低质量的、格式混乱的内容。
- 痛点:缺乏“园丁”。没有指定谁来维护、谁来审核、谁来更新。员工分享知识被视为额外工作,没有激励,大家自然不愿意贡献。
破局之道:
工具只占30%,运营占70%。你需要建立一套知识贡献积分制,比如上传一份高质量案例可以兑换年假或奖金。同时,必须设立知识审核官,确保入库内容的质量。
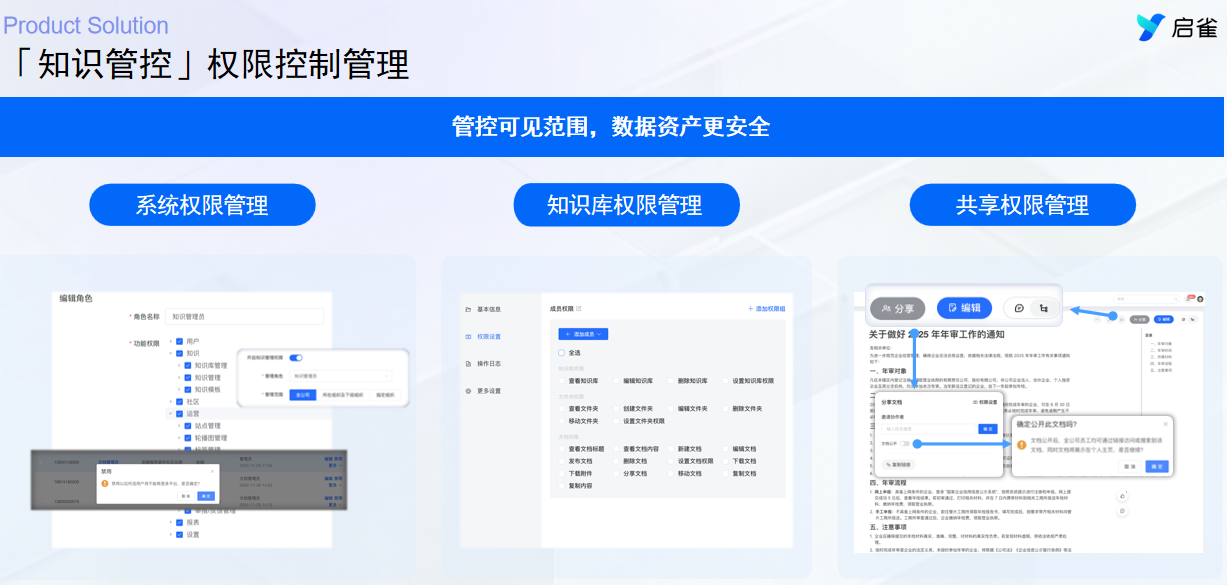
误区三:权限管理过于严苛——宁错杀,不放过
出于安全焦虑,很多公司把知识库锁成了黑盒。
- 现状:默认不可见。除了自己部门的文档,其他部门的一律看不到。申请一个查看权限需要经过三级审批。
- 痛点:制造了新的信息孤岛。科技公司需要跨部门协作(如产品与研发、研发与测试),过度的权限隔离会严重阻碍信息流动。
破局之道:
遵循默认开放,例外保密的原则。对于非核心机密的技术文档、通用规范,应全员可见。透明的信息环境能激发创新,也能让新员工更快融入。
误区四:目录结构照搬组织架构
很多公司搭建知识库时,直接按照公司的部门树来建目录:总经办、研发部、市场部...
- 现状:组织架构是经常调整的,而知识是相对稳定的。一旦部门合并或拆分,知识库目录就要大动干戈。
- 痛点:业务割裂。一个项目往往涉及多个部门,按部门分目录会导致项目资料分散在各处,无法形成闭环。
破局之道:
按业务场景或项目分类,而不是按部门分类。例如,建立“双11大促作战室”、“API接口规范库”、“故障复盘中心”等专题库,让知识围绕业务流转动。
误区五:只建不拆——缺乏生命周期管理
科技行业的技术迭代极快。一年前的架构文档、三年前的API接口说明,现在可能已经完全作废。
- 现状:知识库里充斥着过期的、错误的文档。
- 痛点:误导新人。新员工入职,搜到一个看似完美的旧方案照着做,结果踩了大坑,甚至导致线上故障。
破局之道:
建立文档的保质期制度。就像食品一样,技术文档也有保质期。定期(如每季度)对核心文档进行复核,过期的内容必须标记“已归档”或“已失效”,防止误用。
误区六:期待一劳永逸
很多管理层认为,知识库是一个项目,上线了就结束了。
- 现状:上线即巅峰,随后数据断崖式下跌。
- 痛点:忽视搜索体验。如果搜索功能不好用(不支持模糊搜索、语义搜索),员工依然找不到东西,就会放弃使用。
破局之道:
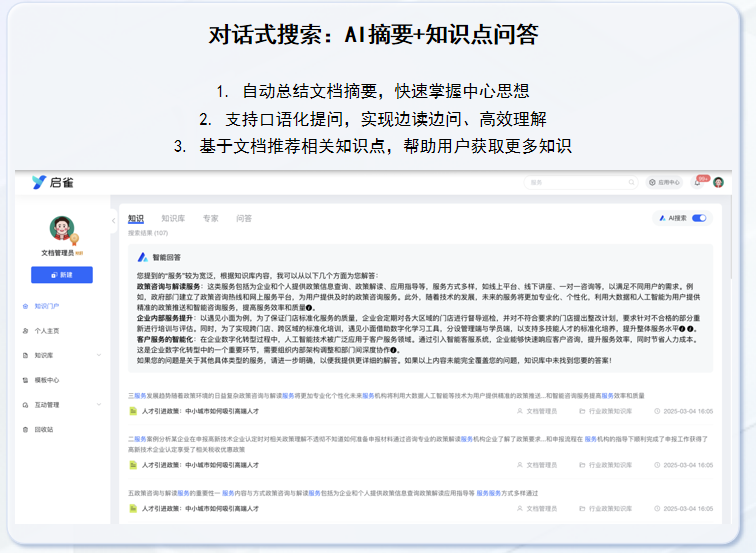
知识库是一个持续迭代的产品。你需要关注搜索无结果率、文档点赞/点踩率,并根据反馈不断优化。现在,引入AI大模型进行语义检索(RAG技术)已成为趋势,它能像ChatGPT一样直接回答员工的问题,而不是扔出一堆链接,这能极大提升使用体验。
结语:让知识“活”起来
对于科技公司而言,鲜活和准确是知识库的生命线。
成功的知识库,不是看存了多少TB的数据,而是看它是否解决了实际问题,是否缩短了新人上手的时间,是否避免了重复造轮子。
避开上述误区,从存文件转向管知识,从买工具转向做运营,你的知识库才能真正成为企业的第二大脑。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 23
23 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)