PyRregular开源34个数据集基准,找不规则时序方向baseline的可以直接抄作业
现实世界中的时间序列数据常因采样不均、观测缺失、长度不一等问题而呈现“不规则”性,这给医疗、交通、气象等领域的分析带来了巨大挑战。
针对此问题,本文解析的两篇论文从不同角度给出了解决方案。第一篇由意大利比萨大学提出的 PyRregular 框架,旨在建立统一的不规则时间序列处理标准与分类基准;第二篇提出的 APN 模型,则聚焦于预测任务,通过创新的自适应分块聚合机制,在保证精度的同时大幅提升计算效率。二者分别从“标准化基准”与“高效建模”两个层面推动了该领域的发展。
我把两篇论文的核心资料整理好了:34个数据集清单+不规则类型标注表以及不规则时间序列精选论文合集感兴趣的可以dd,希望能帮到你~
一、论文1:PYRREGULAR: A UNIFIED FRAMEWORK FOR IRREGULAR TIME SERIES, WITH CLASSIFICATION BENCHMARKS(意大利比萨大学)
方法:
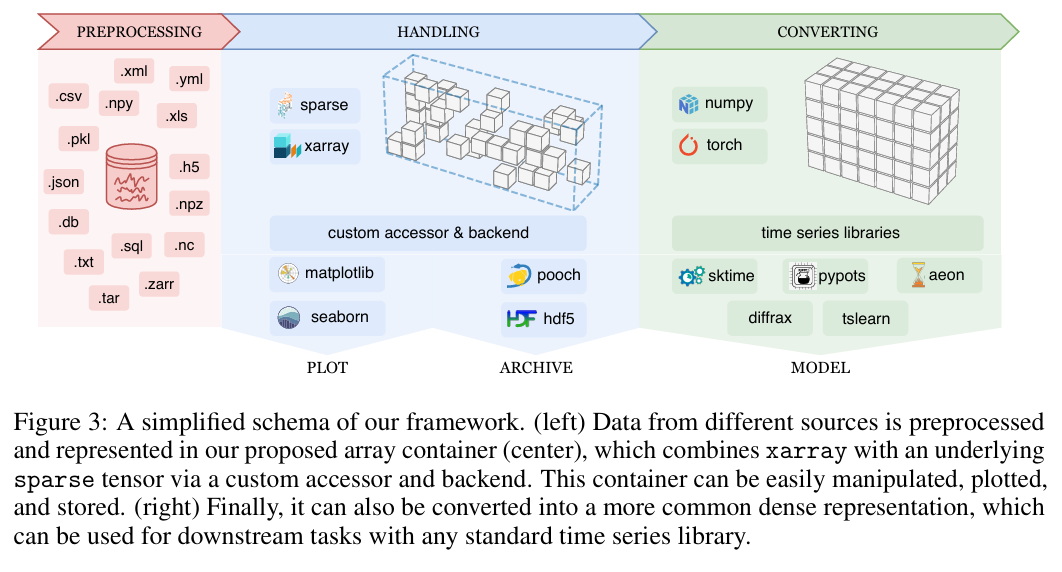
PyRregular 提出了一套处理不规则时间序列的统一框架。它首先定义了三种独立的不规则性类型:不均匀采样、部分观测和参差不齐。框架的核心是将数据转换为基于COO稀疏张量的通用数组格式,并利用 xarray 库存储时间戳,从而实现高效存储与操作。最终,该框架可无缝对接多种现有分类库。
创新点:
-
首个标准化基准:发布了首个包含34个数据集的不规则时间序列分类标准化仓库,并基于此对12种来自不同领域的分类器进行了全面的基准测试。
-
统一数据表示:提出了一种结合稀疏张量与时间戳的统一数组格式,有效区分了“部分观测”和“参差不齐”导致的缺失值,解决了现有格式无法同时处理各类不规则性的痛点。
-
关键发现:基准测试结果显示,原本为规则时间序列设计的 ROCKET 方法在不规则数据上表现最佳,且LightGBM等简单基线模型在性能和效率上优于许多复杂深度学习模型。
-
论文链接:https://arxiv.org/pdf/2505.06047
二、论文2:Rethinking Irregular Time Series Forecasting: A Simple yet Effective Baseline(华东师范大学)
方法:
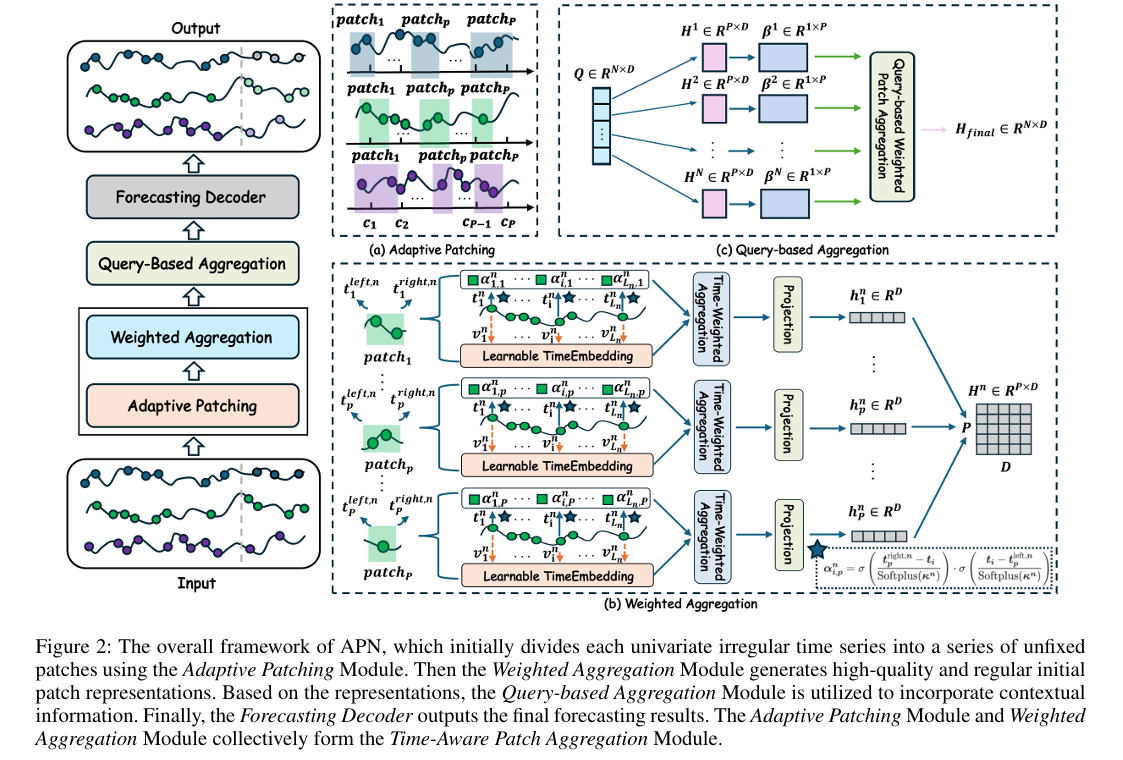
论文提出 APN 框架。核心是时间感知分块聚合模块,该模块为每个通道独立学习动态的“软窗口”,并通过加权平均策略直接聚合窗口内的原始观测值,从而将不规则序列转换为规则、高质量的分块表示。随后,一个轻量级的查询模块汇总历史信息,最后通过一个浅层MLP进行预测。
创新点:
-
自适应分块策略:摒弃了传统固定长度的“硬分割”方法,创新性地提出自适应软分块机制。通过为每个分块学习动态的左右边界,使模型能灵活适应局部信息密度的变化,并保证每个观测点都对所有分块有贡献,避免信息丢失。
-
高效轻量架构:将处理不规则性的复杂性“前加载”到 TAPA 模块,使得后续的聚合与预测模块可以极简化。实验证明,APN 在PhysioNet等多个真实数据集上的预测精度超越了现有最先进方法,同时显著降低了GPU内存、参数量和运行时间。
-
避免插值偏差:与现有通过插值填补缺失值的方法不同,APN 的加权聚合策略直接使用原始观测数据,避免了插值可能引入的数据失真,保证了信息保真度。
-
论文链接:https://arxiv.org/pdf/2505.11250

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 6
6 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)