做 LLM 必懂的两大核心数据集:ShareGPT 微调 + 微软 LLM Trace 推理全拆解
ShareGPT对话数据集
简介
这个数据集主要来源就是用户真实对话,大家把自己和模型的对话分享出来,就形成了这个数据集。ShareGPT 是目前大模型对话微调(SFT)、多轮对话能力评估、对齐研究最主流的开源数据集,没有之一。基础规模:从最初的 5.2 万条对话,扩展到目前主流的约 9 万条高质量对话,还有开源的中英文双语平行版 ShareGPT-90k,覆盖中文场景。
{
"id": "唯一对话ID",
"conversations": [
{"from": "human", "value": "用户的提问内容"},
{"from": "gpt", "value": "大模型的回复内容"},
{"from": "human", "value": "用户的多轮追问/补充"},
{"from": "gpt", "value": "模型的上下文连贯回复"}
],
"system": "可选:系统提示词,设定模型的角色/行为规范",
"tools": "可选:函数调用/工具使用的相关描述"
}
内容类似下面这样:
{
"conversations": [
{
"role": "user",
"content": "What is the capital of France?"
},
{
"role": "assistant",
"content": "The capital of France is Paris."
},
{
"role": "user",
"content": "Can you tell me more about Paris?"
},
{
"role": "assistant",
"content": "Paris is the largest city and the capital of France. It is known for its art, culture, and history..."
}
]
}
数据集核心可利用的特征
- 多轮对话的上下文连贯性:记录了用户从初始提问→追问→修正需求,模型能从中学到如何根据前面的对话历史来理解用户当前的真实需求,保持回复的连贯性。简单来说就是让模型获得有理解上下文的能力。
- 真实场景的指令分布:覆盖日常问答、编程、创作、知识科普、逻辑推理等全场景,没有人工构造的 “理想化指令”,多样化的场景。简单来说就是这些指令来自用户真实和大模型的交互场景,模型学了这样的数据,面对没见过的真实用户问题时,泛化能力会更强。
- 对话质量的天然筛选:用户愿意分享的对话,大多是模型回复质量高、交互流畅的样本,天然过滤了低质量、体验差的对话数据。
- 角色与格式的标准化:统一的 human/gpt 角色划分,可直接适配绝大多数对话大模型的训练模板,无需复杂的数据清洗。简单来说就是不用额外写代码区分说话人,直接就能喂给微调框架,省了很多数据处理的功夫。
做实验时,怎么利用这个数据集
核心场景 1:大模型对话能力 SFT 微调:
首先先介绍一下SFT(Supervised Fine-Tuning):意思是有监督微调简单说就是用标注好的数据,让模型学习 “人类问什么,模型该怎么答” 的对应关系。
比如 ShareGPT 里有这样一条真实对话:
<human>怎么做番茄炒蛋?</human>
<gpt>先把鸡蛋打散,番茄切块。热锅倒油,倒入蛋液炒至凝固盛出。再倒点油,放入番茄块炒出汁水,加少许盐和糖调味,最后倒入炒好的鸡蛋翻炒均匀即可。</gpt>
训练时,会把整个对话拼接成:
“<human>怎么做番茄炒蛋?</human><gpt>先把鸡蛋打散…… 翻炒均匀即可。</gpt>”
的格式,让模型预测 “<gpt>” 后面的文本。模型一开始可能输出混乱的步骤,通过损失函数看预测和数据集中优质回复的差距,再反向传播调整参数,慢慢就学会看到 “怎么做番茄炒蛋?” 这个问题时,输出类似数据集里的清晰步骤,这就是 SFT 让模型学习 “人类问什么,模型该怎么答” 的过程。
核心场景 2:大模型多轮对话能力评估
它是衡量模型多轮对话、上下文理解、指令跟随能力的标准测试集。具体来说,可从ShareGPT 里选一些没用来训练的多轮对话,比如用户先问 “推荐一部喜剧电影”,接着说 “不要美国的”,然后把前两轮用户的提问输入自己的模型,让模型生成第三轮回复,再和数据集中原本的高质量回复对比,通过查看文本相似度指标看模型是否能理解 “不要美国的” 这个上下文约束,回复是否连贯、符合需求。
微软 LLM Trace 数据集(Azure LLM Inference Traces)
是什么?
微软 LLM Trace 是真实生产环境的 LLM 推理服务全链路跟踪数据集,它存储在云平台上,海量用户每一次调用 LLM 的完整运行日志,核心用来研究 LLM 推理性能、集群调度、资源优化,因为 GDPR 隐私合规要求,它不开放原始的 prompt 和回复文本,只记录不涉及用户隐私的调用核心特征GitHub
核心字段定义:
Timestamp:这次请求的毫秒级精确时间戳,用来还原请求的时序规律。
Input_tokens:用户输入 prompt 的 token 长度
Output_tokens:模型生成回复的 token 长度
Service_id:匿名化的 LLM 推理服务标识(区分不同规格的模型服务)
Latency_ms:这次请求的端到端总耗时(延迟)
开源数据集格式:
timestamp,input_tokens,output_tokens,service_id,latency_ms
1699651200000,487,212,Service_A,1187
1699651200001,124,89,Service_B,452
1699651200003,1024,512,Service_A,2890
1699651200005,32,16,Service_B,210
1699651200007,768,384,Service_A,1956微软官方定义的标准格式(给内部工程师开发使用不涉及隐私泄露):
{
"info": {
"trace_id": "trace_123456",
"request_time": "2024-01-01 12:00:00",
"execution_time_ms": 890,
"status": "OK"
},
"data": {
"request": "{\"query\": \"怎么做番茄炒蛋?\", \"user_id\": \"anonymous\"}",
"response": "{\"answer\": \"先把鸡蛋打散,番茄切块。热锅倒油,倒入蛋液炒至凝固盛出。再倒点油,放入番茄块炒出汁水,加少许盐和糖调味,最后倒入炒好的鸡蛋翻炒均匀即可。\"}",
"spans": [
{
"span_id": "span_1",
"span_type": "CHAT_MODEL",
"inputs": {"messages": [{"role": "user", "content": "怎么做番茄炒蛋?"}]},
"outputs": {"role": "assistant", "content": "先把鸡蛋打散,番茄切块。热锅倒油,倒入蛋液炒至凝固盛出。再倒点油,放入番茄块炒出汁水,加少许盐和糖调味,最后倒入炒好的鸡蛋翻炒均匀即可。"},
"start_time": "2024-01-01 12:00:00.100",
"end_time": "2024-01-01 12:00:00.990",
"token_usage": {"input_tokens": 12, "output_tokens": 58}
}
]
}
}首先介绍下大模型推理引擎是什么?
大模型本身,就像一个背了全天下菜谱、菜做得好不好吃全看它的大厨,它只管用户问什么,该答什么内容。推理,就是用户发一句提问,模型一句一句生成回答的过程,就像客人点了菜,大厨把菜做出来的全过程。而大模型推理引擎,就是给这个大厨专门搭的一整套后厨系统。
光有大厨根本开不了饭店:你总不能让大厨自己接客人的订单、自己切菜备菜、自己排号、自己给客人上菜、自己管灶台不炸锅吧?同时来 100 个客人,大厨一个人直接忙崩,客人全跑了。推理引擎,就是干大厨之外的所有事,让大厨只需要专心炒菜,还能同时服务好多人,大家等的时间短,饭店也不卡壳、不倒闭。
第一件事:当「接单传菜员」,帮你和大厨 “对上话”
大厨(大模型)只看得懂它自己的专属暗号(就是之前说的 token),看不懂你说的大白话。你给模型发一句 “怎么做番茄炒蛋”,引擎先接过来,把这句话转换成大厨能看懂的暗号,递到大厨手里;大厨把菜做好了(生成了回答的暗号),引擎再把暗号翻译回你能看懂的大白话,发回给你。没有这个传菜员,你和大厨根本说不上话,模型连你的问题都接不到。
第二件事:当「排号调度总管」,解决你最关心的「多用户同时用不卡」的问题
同时来 100 个客人点菜:要是一个一个炒,,全跑了;要是全堆给大厨一起炒,大厨直接忙炸,锅都烧了,谁的菜都出不来。引擎这个调度总管,就专门管这件事:
- 先看每个客人点的菜是大是小:比如有的客人只点 “一碗米饭”(短提问,只要几个字的回答),有的客人点 “一桌满汉全席”(长文档输入,要几千字的回答);可以类比到操作系统的短进程优先。
- 再安排炒菜顺序:把好几个 “一碗米饭” 的小单子,凑一起给大厨一起炒,省时间;把 “满汉全席” 的大单子,单独安排一个灶台,不让它堵了小单子;
- 还能预判高峰期:比如晚上 8 点是饭点,客人扎堆来,引擎就提前把灶台火力拉满,多安排人手,不让饭店崩了。
模型引擎本质就是大模型这个 “算力厨师” 的专用操作系统与调度中枢
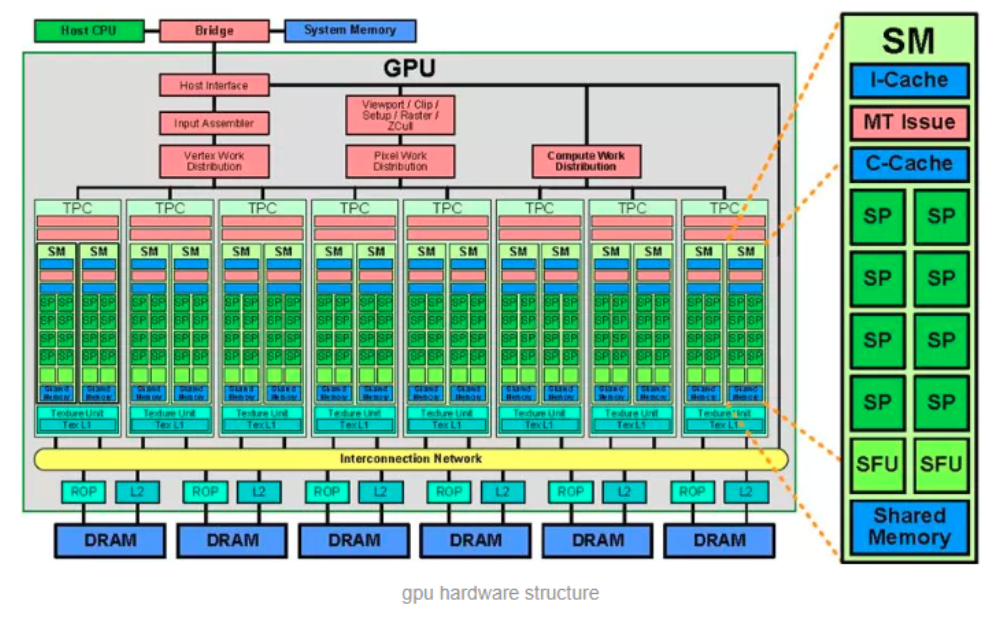
大模型就像一位天生拥有无数只手的主厨,极致并行是它的本能。但一次能炒多少菜、会不会翻车,完全取决于后厨的灶台数量(SM)和火力上限(算力)。 生成每个词的核心计算(注意力机制和矩阵乘法),本质就是把一道大菜拆解成数百万个独立、相同的小任务。
高并发下,灶台和火力的硬限制到底是什么?
灶台 = GPU 硬件底层的SM 流式多处理器(GPU 的最小独立计算单元)
总火力上限=GPU 的总算力(TFLOPS)+ 显存带宽(处理多个KV的速度)
这个数据集到底在记录什么?
微软 LLM Trace 数据集,就是全国几百家饭店,几百万个客人真实的点菜记录:
- 客人几点来的?
- 点的菜是大是小?
- 做这个菜用了多久?
从真实的LLM使用记录里,收集一堆“任务纸条”,每张写着:要处理多少字(input+output tokens)和什么时间来的(timestamp)。
然后用这些纸条测试你的每一个动态批处理策略:小任务(短token)凑成一批一起算,大任务(长token)单独成批不拖累别人。
最后对比固定批处理,看谁的总吞吐量更高、平均延迟更低。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 10
10 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)