DreamZero&GR00T N2前戏:World Action Models are Zero-shot Policies
DreamZero&GR00T N2前戏:World Action Models are Zero-shot Policies
DreamZero,这是一种基于预训练视频扩散模型主干的世界动作模型 (WAM)。与 VLA 不同,WAM 通过预测未来世界状态和行为来学习物理动力学,并使用视频作为世界如何演变的密集表示。
至关重要的是,通过模型和系统优化,使 14B 自回归视频扩散模型能够以 7Hz 执行实时闭环控制。
WAM 由基于网络规模视频数据训练的视频扩散模型初始化,利用丰富的时空先验来共同生成以语言指令和观察为条件的未来帧和动作。这将动作学习从密集的状态动作模仿转变为逆动态——使运动命令与预测的视觉未来保持一致。
本文解决两个问题:①传统VLA物理感知能力不足,导致的泛化性差 ②视频生成速度慢,本文引入了各种工程方法来提高生成视频的速度
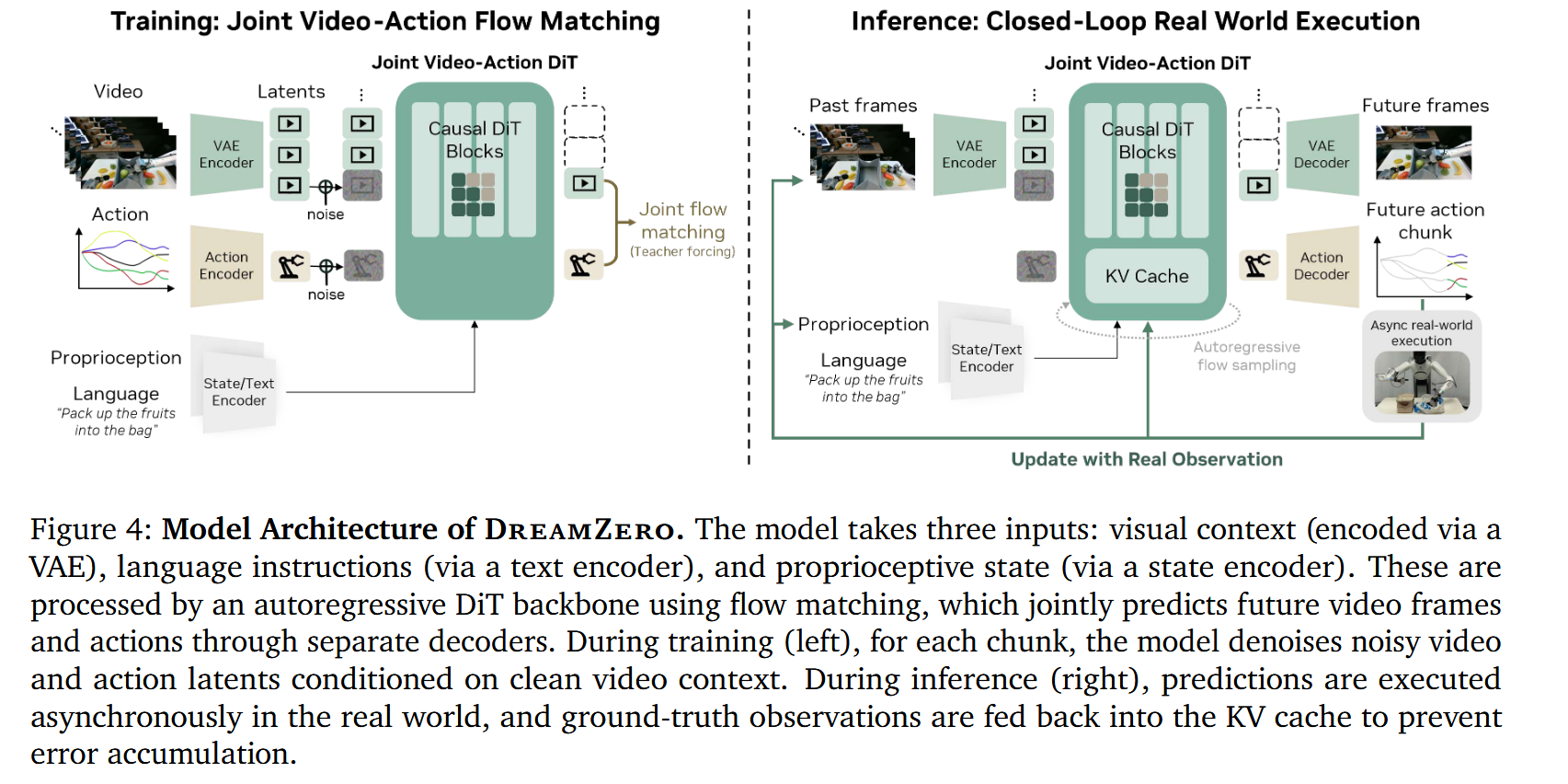
在推理的时候采用自回归架构并利用闭环设置:执行每个动作块后,我们用 KV 缓存中的真实观测值替换预测帧,消除复合错误,同时通过 KV 缓存实现高效推理,并保留本机帧速率以实现精确的模态对齐(参见图 4 右侧)。
特别是,DreamZero 经过训练可以自回归预测视频帧和相应的动作。自回归生成具有以下优点:(1)它通过利用 KV 缓存实现更快的推理速度,(2)策略模型可以利用视觉观察历史作为下一代的指导,(3)它避免了双向模型固有的模态对齐挑战(视频、动作和语言对齐)。具体来说,双向扩散通常需要处理固定长度的序列,这通常需要视频子采样,这会扭曲原生 FPS,可能会损害视频动作对齐。另一方面,自回归生成利用 KV 缓存来支持单个前向传递中的任意长上下文。这保留了原始帧速率,确保视频帧和机器人动作之间的精确对齐。
对于②还有个比较巧妙的设计点,提出了DreamZero-Flash:
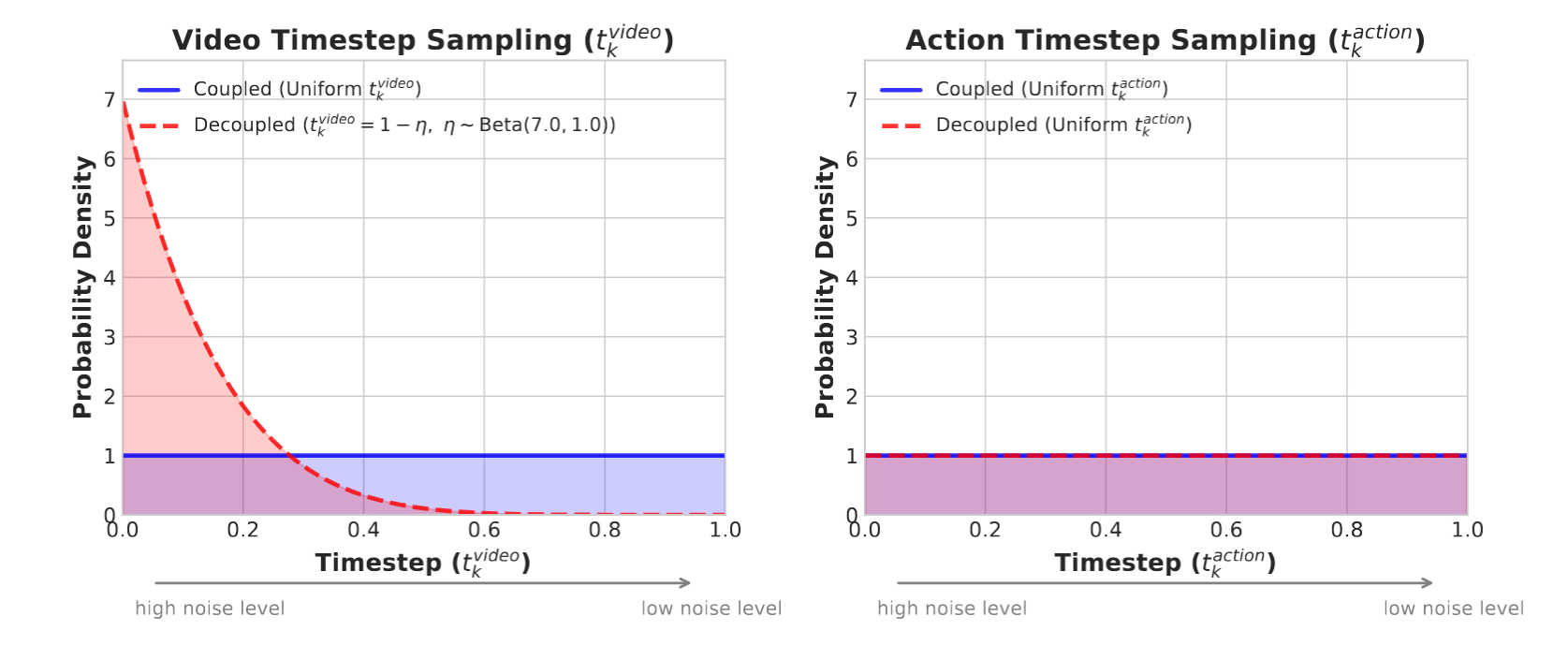
DreamZero(蓝色)将耦合噪声用于视频和动作(均统一)。 DreamZero-Flash(红色)通过 Beta 分布将视频偏向高噪声状态,同时保持动作噪声均匀,训练模型从嘈杂的视觉环境中预测干净的动作。
原版 coupled 训练的问题 如果 video 和 action 总是共享同一个 t,那模型训练时看到的总是: noisy video + noisy action 或较干净 video + 较干净 action 也就是两者噪声水平同步。
但在快速推理,尤其是 few-step / single-step inference 时,现实情况更像是:当前 chunk 的 video 还比较 noisy 但 action 这边需要赶紧尽快变“可执行的干净动作” 这时模型就会遇到没怎么训练过的情况: “我要在视觉上下文还很脏的时候,先把动作预测准。”
DreamZero-Flash 的想法所以作者故意把 video 训练成“经常很脏”,但 action 仍然正常均匀采样。 这样模型会更常见到这样的样本: noisy video context 但 action 需要被预测出来论文原话就是:“this exposes the model to configurations where it must predict clean actions from noisy visual context”,也就是让模型学会“从噪声很大的视觉条件里,也能把动作弄干净”
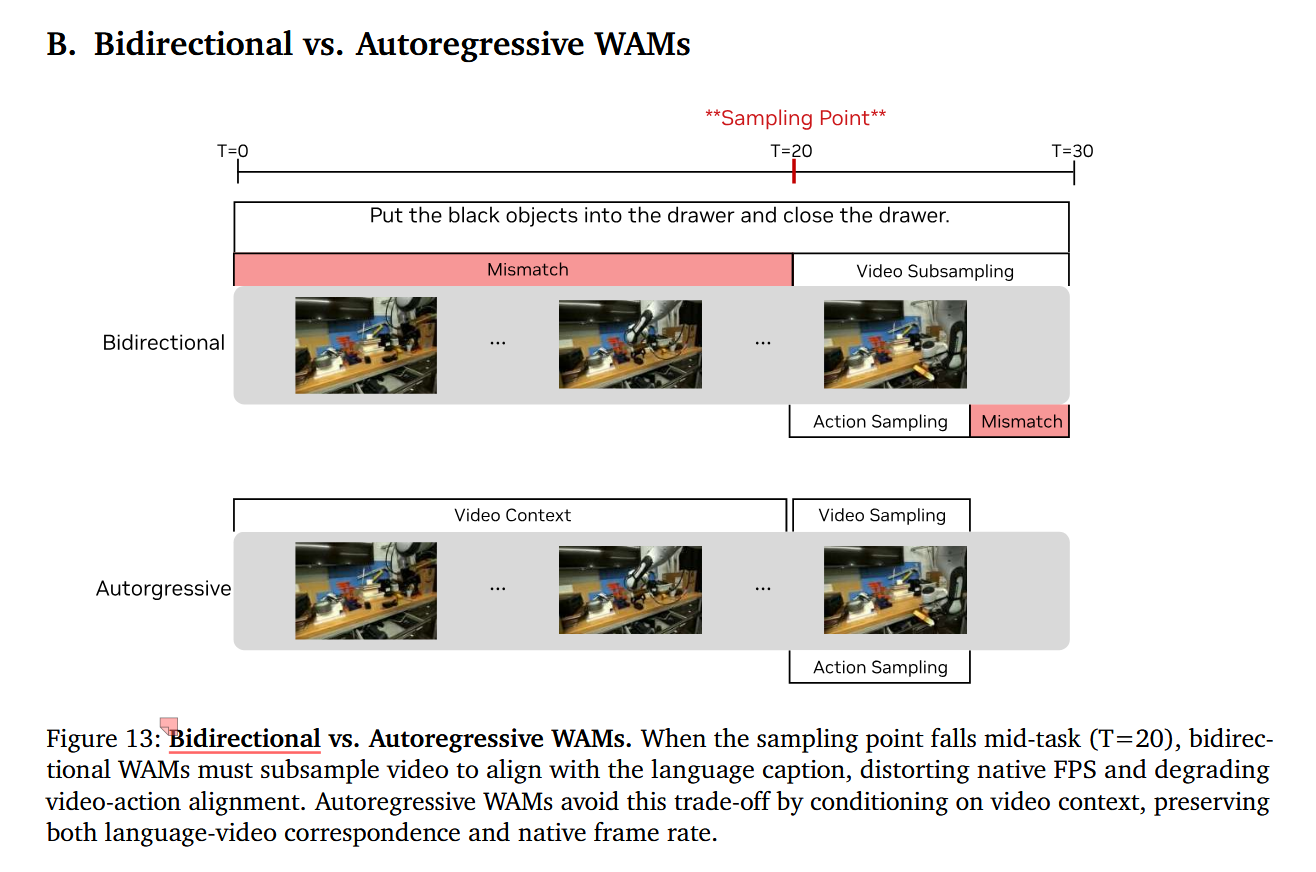
对于双向WAMs,现实任务长度不固定,但双向WAMs模型窗口往往是固定的。 它更像是在一个固定 clip 内做联合去噪、联合建模。论文正文直接说,bidirectional diffusion typically requires processing fixed-length sequences。 给定一条长任务语言标注,模型必须学会“这句指令对应的是视频里的哪一段时间区间”。问题在于,如果用双向架构、又不做视频抽帧,那模型常常只能生成这个任务区间里的一小部分视频。结果就是:语言说的是完整任务视频只覆盖了其中一截语言描述的动作,可能在当前视频帧里根本还没发生这就会出现 language-video mismatch。 那为什么双向 WAM 要“抽帧”?为了缓解上面这个错位,一个自然想法就是: 既然一句语言覆盖的是整段任务,那我就把整段任务的视频抽稀,压缩到固定长度窗口里。 这就是图中 Video Subsampling 的意思。 作者原文就说:为了让视频和任务 caption 覆盖同一个时间区间,双向方法往往需要 subsample the video to match the task caption interval。举个简单例子:原始视频是 5 FPS,整段任务 6 秒,共 30 帧但双向模型这次只能处理 6 帧那就只能从 30 帧里抽 6 帧出来这样做的好处是: 这 6 帧大致覆盖了整段任务,所以跟语言表面上更“对应”了。 坏处是:原本连续的时间轴被压缩了。
所以上面到图片说的这些就是在说明自回归的好。
伪代码写的非常清晰

实验的话比较常规了。然后一些pytorch和cuda的加速就比较偏向工程化/硬件了,比较常规了。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐
 12
12 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)