我开发了一套“多智能体学术法庭”系统:它能把论文冲突变成结构化案件,让 Proposer、Skeptic 和 Judge 多轮辩论,再自动生成裁决、图谱、方法学评分卡、Wiki 回写和持续监测结果。
🚀 我开发了一套“多智能体学术法庭”系统:它能把论文冲突变成结构化案件,让 Proposer、Skeptic 和 Judge 多轮辩论,再自动生成裁决、图谱、方法学评分卡、Wiki 回写和持续监测结果。它不是一个普通的论文总结工具,而是一套真正面向知识冲突治理的研究工作台。
✋ 如果知识库会“打架”,那就别再让一个模型独自做裁判了。
我做了一个会辩论、会裁决、会回写、还会持续监测新论文的产品:多智能体学术法庭(Multi-Agent Academic Court)。
一句话先说清楚:这到底是什么?
这是我开发的一套面向学术研究、AI 知识治理与复杂文献冲突处理的多智能体产品。
它不是普通的“论文总结工具”,也不是只会把内容塞进向量库的“RAG 套壳应用”。
它更像一个由多个 AI 组成的数字化审稿委员会:
- 🧑💻
Proposer负责提出“为什么新论文值得改写旧知识” - 🛡️
Skeptic负责质疑“这篇新论文到底有没有足够证据” - ⚖️
Judge负责综合双方辩论,输出最终裁决 - 🧭 系统再把整个过程写成结构化冲突块、证据图谱、方法学评分卡和 Wiki 回写结果
换句话说,我做的不是“帮你读论文”,而是“帮你治理会冲突的知识”。
为什么我要做这个产品?
我做这个产品,最直接的起点来自一个非常现实的问题:
当你的知识库里只有 10 篇论文时,“更新知识”是一件很轻松的事。
但当知识库变成 100 篇、500 篇、1000 篇之后,真正麻烦的从来不是“找不到资料”,而是:
- 新论文和旧论文说法不一致,谁更可信?
- 不同实验结论适用的边界条件是什么?
- 是应该覆盖旧观点,还是保留旧结论并追加限制条件?
- 如果一个 LLM 直接改写 Wiki,它到底是在“更新知识”,还是在“制造幻觉”?
这正是我想解决的问题。
我不想再做一个“把文献贴进去,然后吐出摘要”的工具。
我想做的是一个更像研究现实世界的系统:知识不是线性累加的,知识是会冲突、会争议、会修订的。
这个项目的开发背景:我借鉴了什么?
这个项目的灵感,明显受到了 LLM Wiki 思路的启发。
借鉴自 LLM Wiki 的核心思想
LLM Wiki 给了我一个非常重要的启发:
- 知识不应该只存在于聊天记录里
- 知识应该沉淀为可维护、可更新、可审阅的 Wiki 页面
- 模型不只是回答问题,而是参与知识库的持续建设
这套思想非常强,但我在继续思考时发现了一个更难的问题:
如果 Wiki 不是“补充知识”,而是“碰到互相冲突的知识”呢?
比如:
- 论文 A 说:模型参数越大越好
- 论文 B 说:在某些高质量小数据场景里,数据质量比参数规模更重要
这时,如果只有一个“LLM 图书管理员”,它很可能做出两种糟糕决策:
- 直接覆盖旧知识,导致知识被粗暴抹除
- 试图生硬融合,最后生成逻辑混乱、边界不清的幻觉结论
于是,我把 LLM Wiki 的“知识维护”继续向前推进了一步,做成了一个真正能处理知识冲突的系统:
从 “LLM Wiki” 到 “Academic Court”
我做的扩展可以概括成一句话:
当知识冲突发生时,不再让一个模型独裁,而是让多个智能体公开辩论,再由系统结构化裁决。
这就是“多智能体学术法庭”的核心出发点。
🗂️ 先用 3 张结构图看懂这个产品
很多人第一次看到这个项目,会以为它只是“多调用几个模型做辩论”。
但实际上,我把它做成的是一套有明确分层、有治理逻辑、有协作闭环的产品。
1. 产品结构树:它不是单功能脚本,而是一套研究工作台
多智能体学术法庭(Multi-Agent Academic Court)
├─ 输入与案件构建层
│ ├─ PDF / Markdown / TXT 上传
│ ├─ Arxiv / DOI 一键导入
│ ├─ 目标 Wiki 页面选择
│ ├─ 主题提示与辩论轮数配置
│ └─ 并案卷宗预览
├─ 冲突发现层
│ ├─ 混合检索
│ ├─ 冲突雷达
│ ├─ 候选页面召回
│ └─ 值得开庭的主题筛选
├─ 多智能体裁决层
│ ├─ 🧑💻 Proposer
│ ├─ 🛡️ Skeptic
│ ├─ ⚖️ Judge
│ └─ 回合制辩论与结构化裁决
├─ 结果表达层
│ ├─ 裁决摘要
│ ├─ Markdown 冲突块
│ ├─ Wiki 回写预览
│ ├─ 方法学评分卡
│ ├─ 陪审团意见
│ ├─ 冲突图谱 Atlas
│ └─ 辩论回放剧场
├─ 持续监测层
│ ├─ RSS / JSON Feed / 手动种子
│ ├─ 新论文命中
│ ├─ 每周冲突简报
│ └─ 主题主页
└─ 团队协作层
├─ 审稿任务
├─ 评论线程
├─ 人工复核
├─ 订阅提醒
├─ 修订记录 / Diff
└─ 管理后台
2. 核心流程图:一篇新论文是怎么进入法庭的
3. 网络拓扑图:系统内部不是“一个模型”,而是一张协作网
┌─────────────────────────┐
│ 📥 新论文 / 新证据输入 │
└──────────┬──────────────┘
│
▼
┌────────────────────────────────┐
│ 🧾 Case Builder 冲突案件构建器 │
└──────────┬─────────────────────┘
│
┌─────────────┼─────────────┐
│ │ │
▼ ▼ ▼
┌────────────────┐ ┌──────────────┐ ┌────────────────┐
│ 🔎 Hybrid │ │ ⚠️ Radar │ │ 📚 Wiki Context │
│ Retrieval │ │ 冲突雷达 │ │ 旧知识上下文 │
└────────┬───────┘ └──────┬───────┘ └────────┬───────┘
└────────────────┴──────────────────┘
│
▼
┌────────────────────────────────────────────────────┐
│ 🏛️ Multi-Agent Court │
│ 🧑💻 Proposer ⇄ 🛡️ Skeptic ⇄ ⚖️ Judge │
└────────────────────────────────────────────────────┘
│
┌──────────────────────────┼──────────────────────────┐
▼ ▼ ▼
┌───────────────┐ ┌──────────────────┐ ┌─────────────────┐
│ 📊 评分卡/陪审团 │ │ 🕸️ Atlas / 回放剧场 │ │ 📝 Markdown 回写 │
└──────┬────────┘ └────────┬─────────┘ └────────┬────────┘
│ │ │
└───────────────┬───────────┴───────────────┬──────────┘
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 👥 审稿协作 / 复核 │ │ 📡 持续监测 / 简报 │
└─────────────────┘ └─────────────────┘
这款产品主要面向哪些客户?
这不是一个只服务某一类用户的小工具,它其实有非常明确的几类核心客户。
1. 🎓 本科生、研究生、博士生
适合那些:
- 正在读大量论文,但很难把观点组织成结构化知识的人
- 做文献综述、开题报告、Related Work 时总觉得“信息很多,但逻辑很散”的人
- 研究某个主题时经常遇到“论文之间互相打架”的情况,却很难判断到底该信谁的人
2. 🧪 实验室、课题组、PI 团队
适合那些:
- 需要持续维护某个研究方向知识库的实验室
- 希望把论文阅读结果沉淀成 Wiki、而不是沉到微信群或飞书聊天里的人
- 需要对研究共识、争议点、边界条件进行多人协作审核的团队
3. 🤖 AI 应用团队 / RAG 开发者 / Agent 工程师
适合那些:
- 在做 RAG、知识问答、企业知识库系统的人
- 已经意识到“检索到内容”不等于“知识就正确”的团队
- 需要处理相互冲突文档、多版本事实和复杂证据链的系统开发者
4. 🏢 企业知识运营、战略研究、行业分析团队
适合那些:
- 需要长期跟踪一个技术主题变化的人
- 希望自动监测新资料、新报告、新论文带来的观点变化的人
- 想把知识管理从“文档堆积”升级为“冲突治理”的组织
它到底帮客户解决了什么难题?
我把这个产品真正解决的问题,归纳成 7 个字:
让知识更新变得可信。
展开来说,它解决的是下面这些高频痛点。
痛点 1:论文很多,但知识无法沉淀
很多研究者每天都在看论文,但最后的成果往往只是:
- 一堆高亮 PDF
- 一堆零散笔记
- 一堆发在群里的观点
没有形成可维护的知识资产。
这个产品把论文输入、冲突提取、辩论裁决、Wiki 回写串成了一整条链路,让“读过”真正变成“留下来”。
痛点 2:知识冲突时,普通 RAG 很容易翻车
传统 RAG 更擅长“找相关内容”,但并不擅长:
- 判断冲突双方谁更强
- 分析方法学差异
- 给出边界条件
- 生成可回写的治理结果
而我的产品专门就是围绕这些问题设计的。
痛点 3:知识更新缺乏审稿感
很多 AI 产品更新知识的方式像“直接覆盖数据库”,这在研究场景里非常危险。
因为研究不是写日报,研究需要保留争议、保留边界、保留证据来源。
我希望系统的输出更像一场“可追溯的学术裁决”,而不是一个“看起来很顺滑的幻觉答案”。
痛点 4:团队协作时,没人知道为什么改了这段知识
知识页一旦更新,团队成员常常会问:
- 这是谁改的?
- 为什么改?
- 原来版本是什么?
- 有没有证据?
- 这个修改有没有人工复核过?
所以我把:
- 修订记录
- Diff 对照
- 人工审稿
- 评论任务
- 订阅提醒
都做进了同一个工作台里。
痛点 5:研究不是一次性输入,而是持续演化
论文今天读完,明天可能就有新的 arXiv 或会议论文来挑战旧观点。
所以系统不只是“跑一次工作流”,还支持:
- 监测源配置
- 自动扫描
- 新论文命中提醒
- 每周冲突简报
- 主题主页聚合
这意味着它不是一个静态工具,而是一个持续运行的研究雷达。
这款产品有哪些核心功能特色?
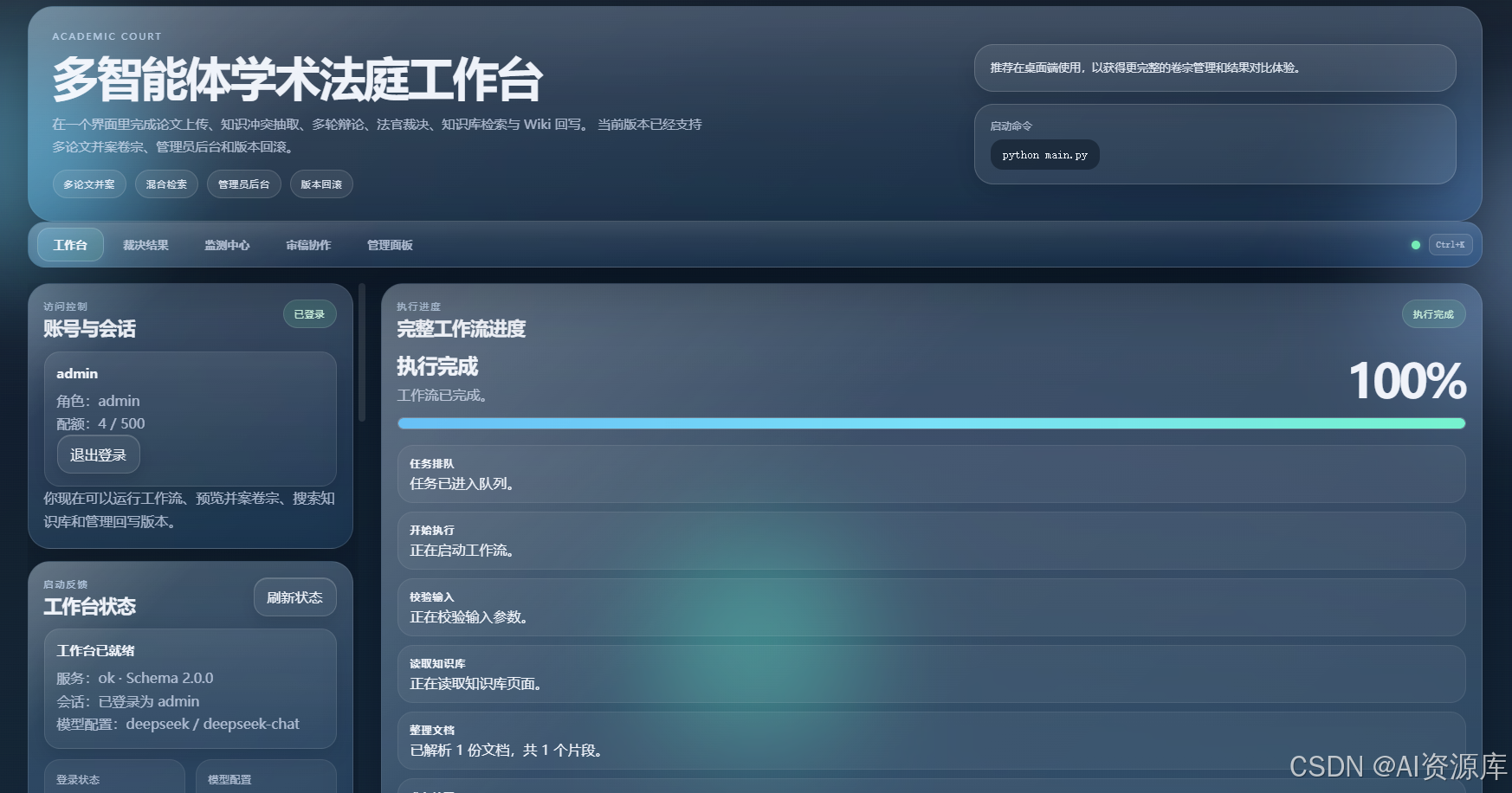
1. 🏠 首页总览图:五大 Tab 的完整工作台
内容:
- 顶部 Hero 区域
- 五大 Tab:
工作台、裁决结果、监测中心、审稿协作、管理面板 - 左侧控制栏 + 右侧结果画布的整体布局
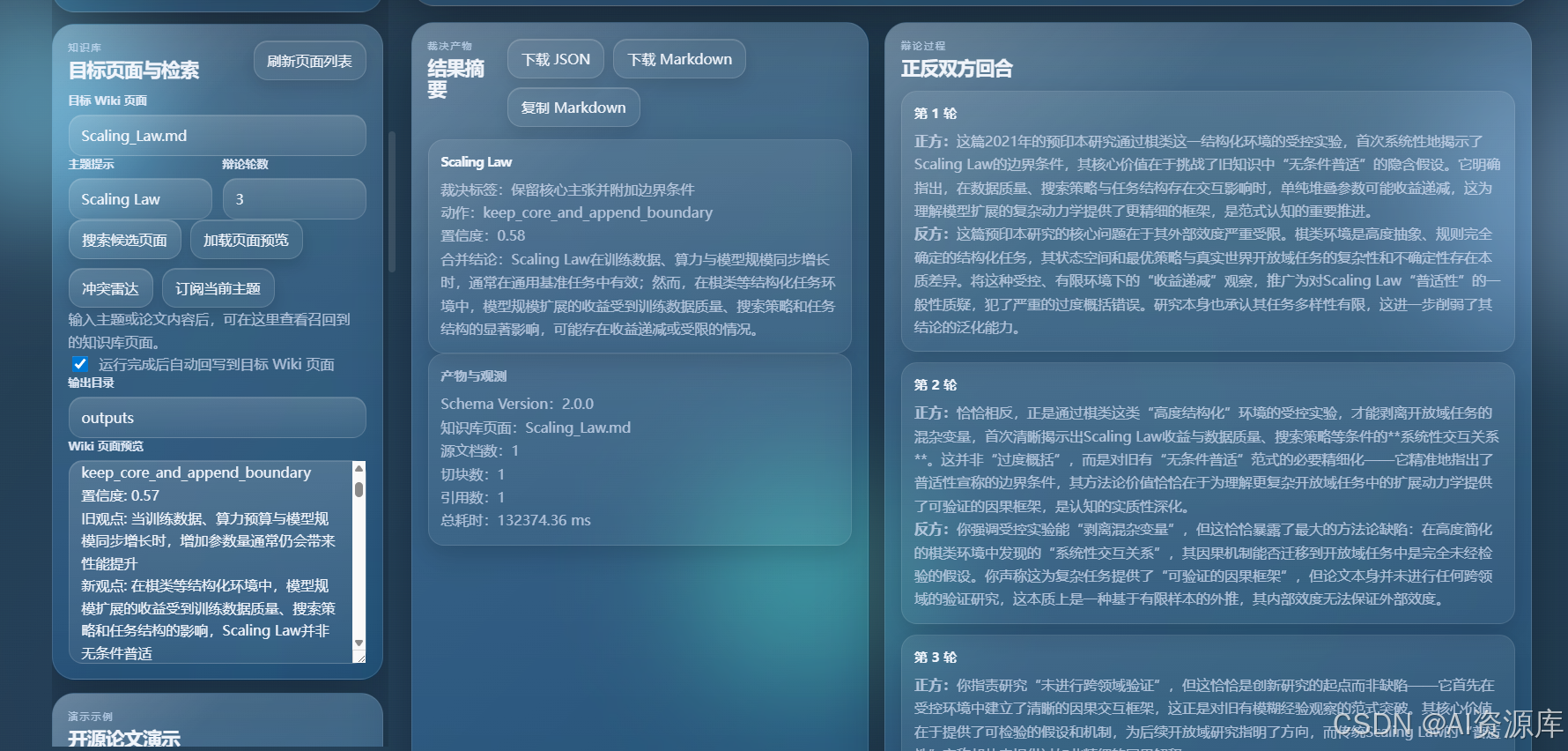
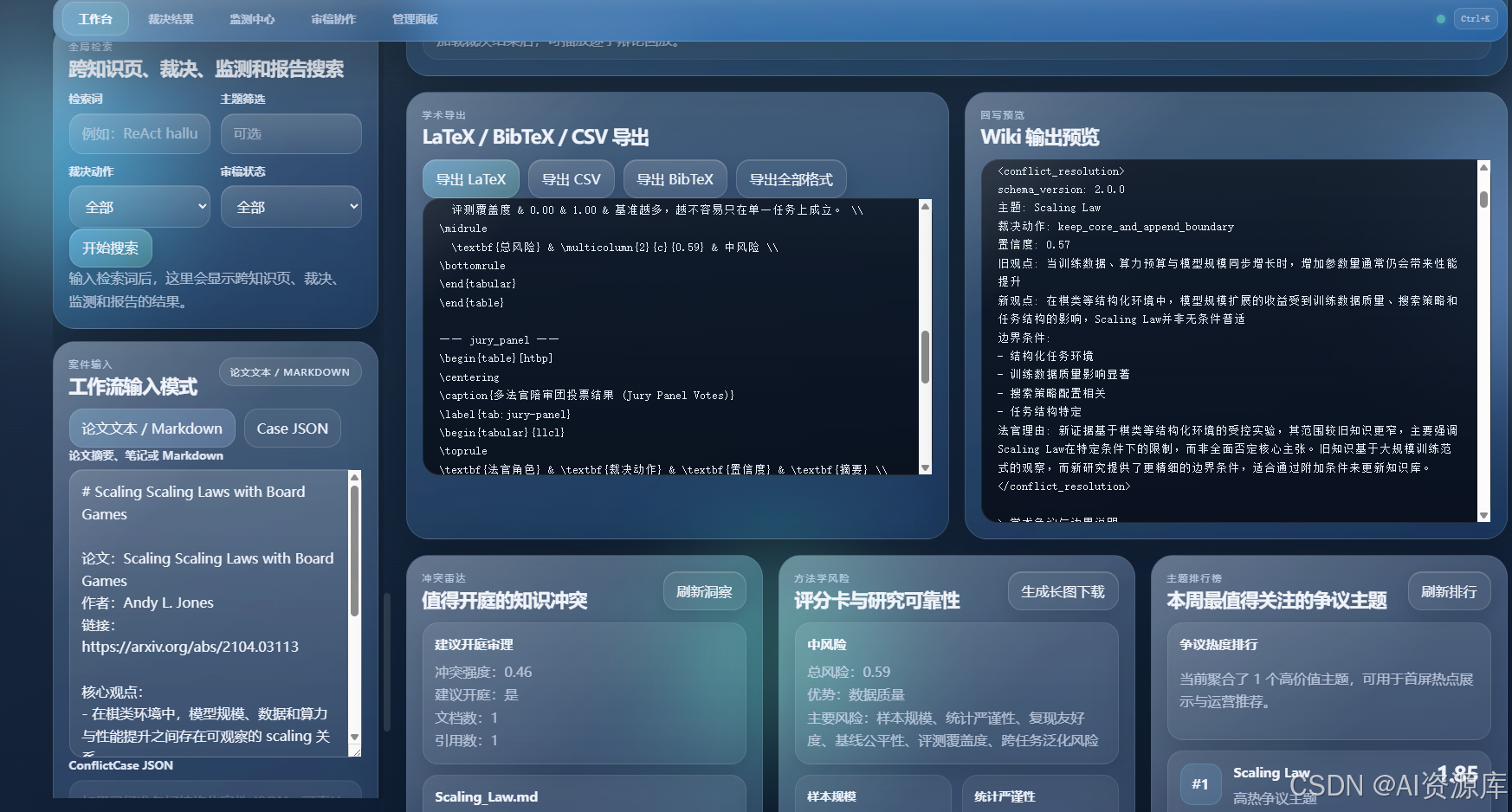
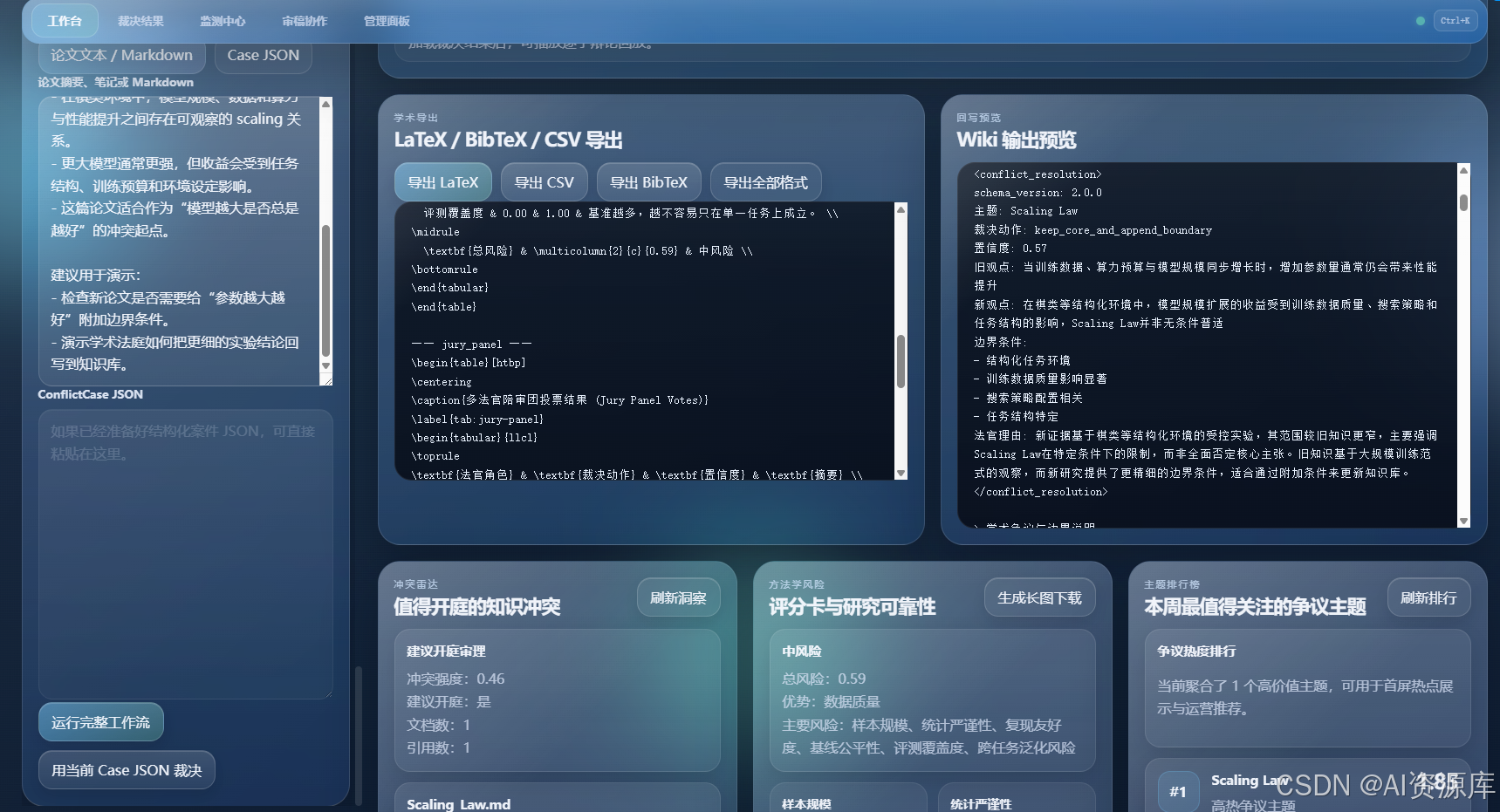
2. 🧾 工作台输入区:论文导入 + 目标 Wiki + 并案卷宗
建议截图内容:
- 论文上传区
- Arxiv / DOI 一键导入
- 目标 Wiki 页面选择
- 主题提示、辩论轮数、输出目录
- 并案卷宗预览区域
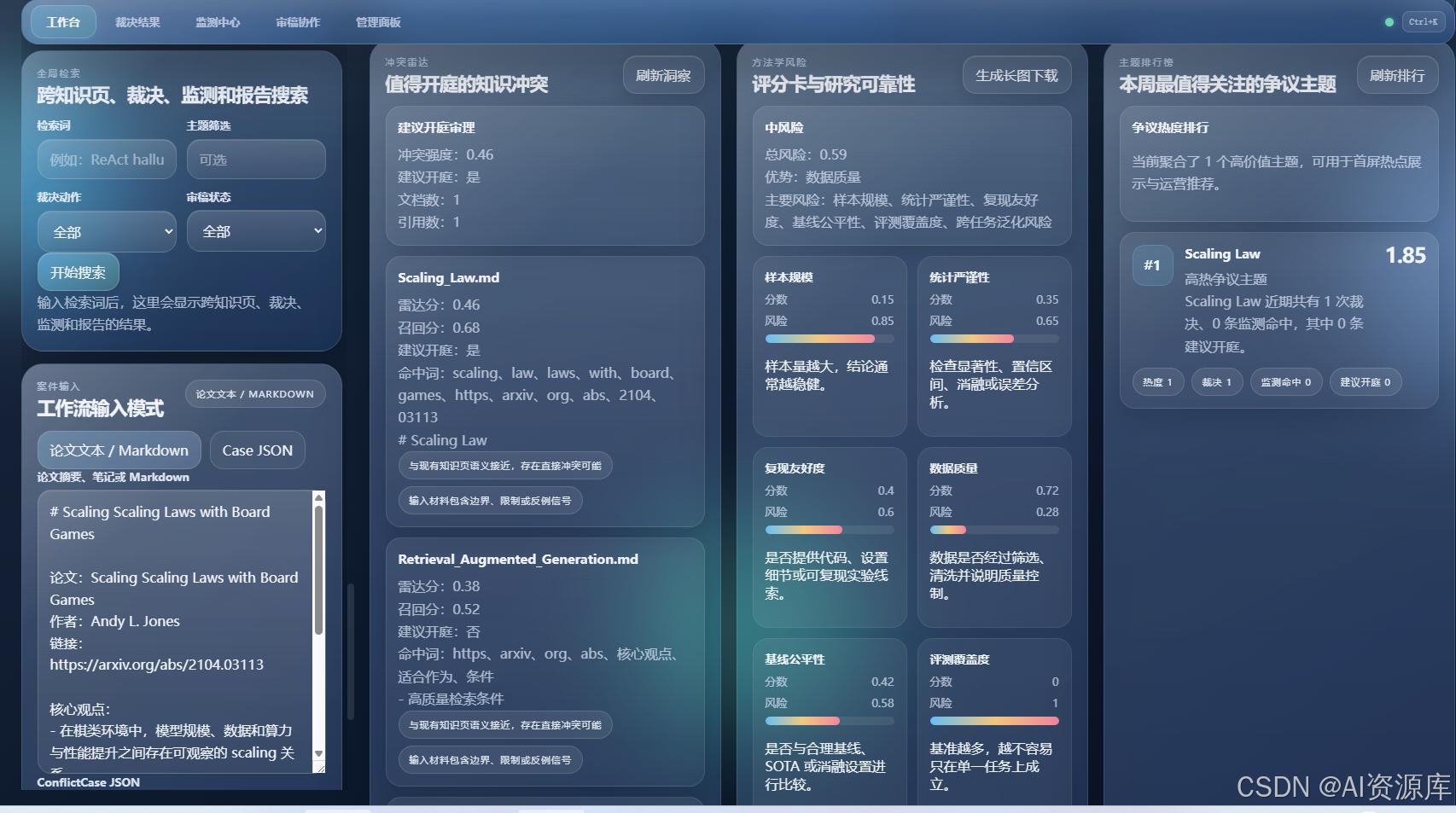
3. ⚠️ 冲突雷达界面:先判断哪些主题值得开庭
建议截图内容:
- 冲突雷达结果卡
- 冲突强度
- 候选冲突页
- 是否建议进入法庭
- 命中词或信号提示
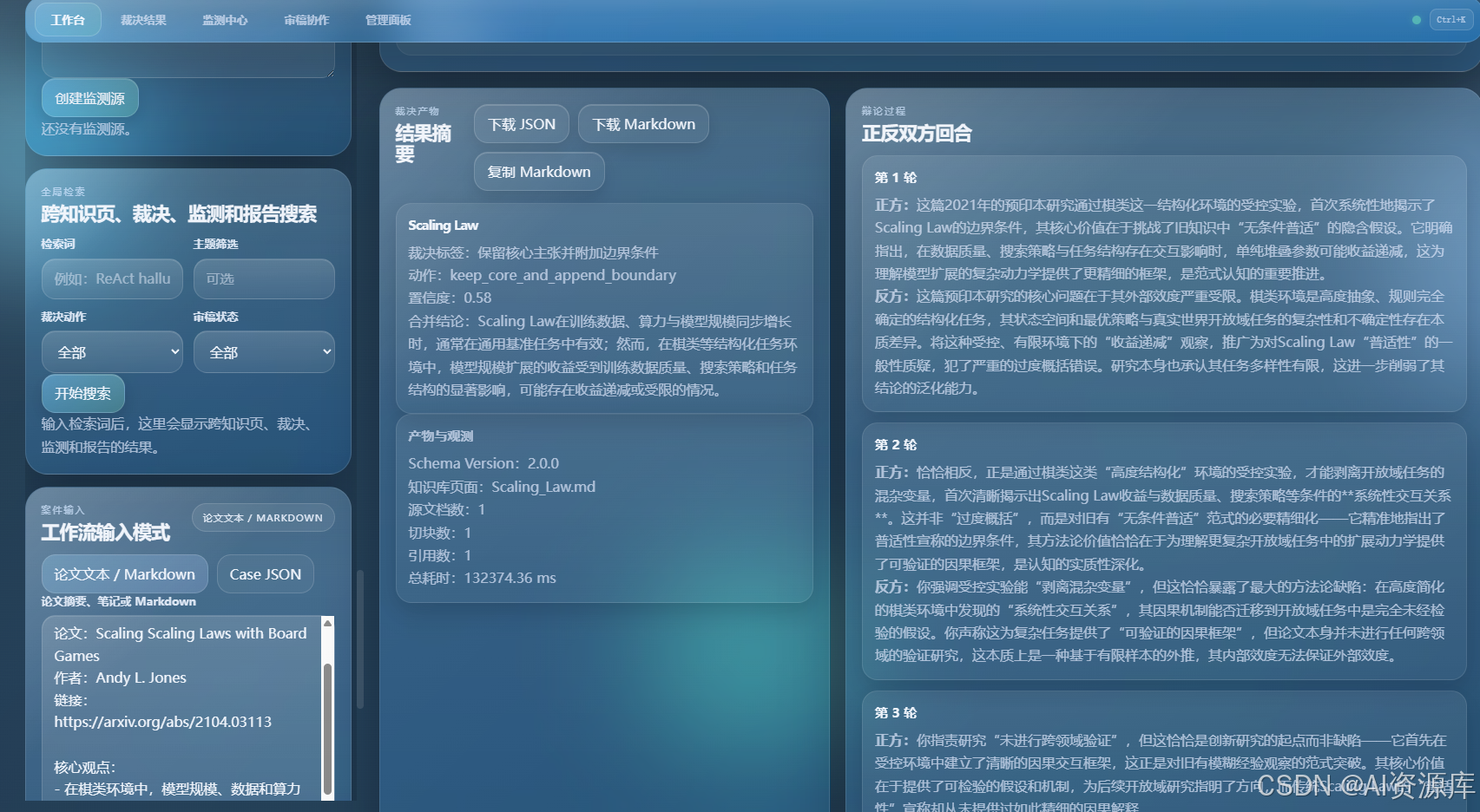
4. 🧑💻🛡️⚖️ 裁决结果总览:Proposer、Skeptic、Judge 的工作流成果
建议截图内容:
- 执行进度条
- 裁决摘要
- 合并结论
- 辩论回合摘要
- Markdown 冲突块输出
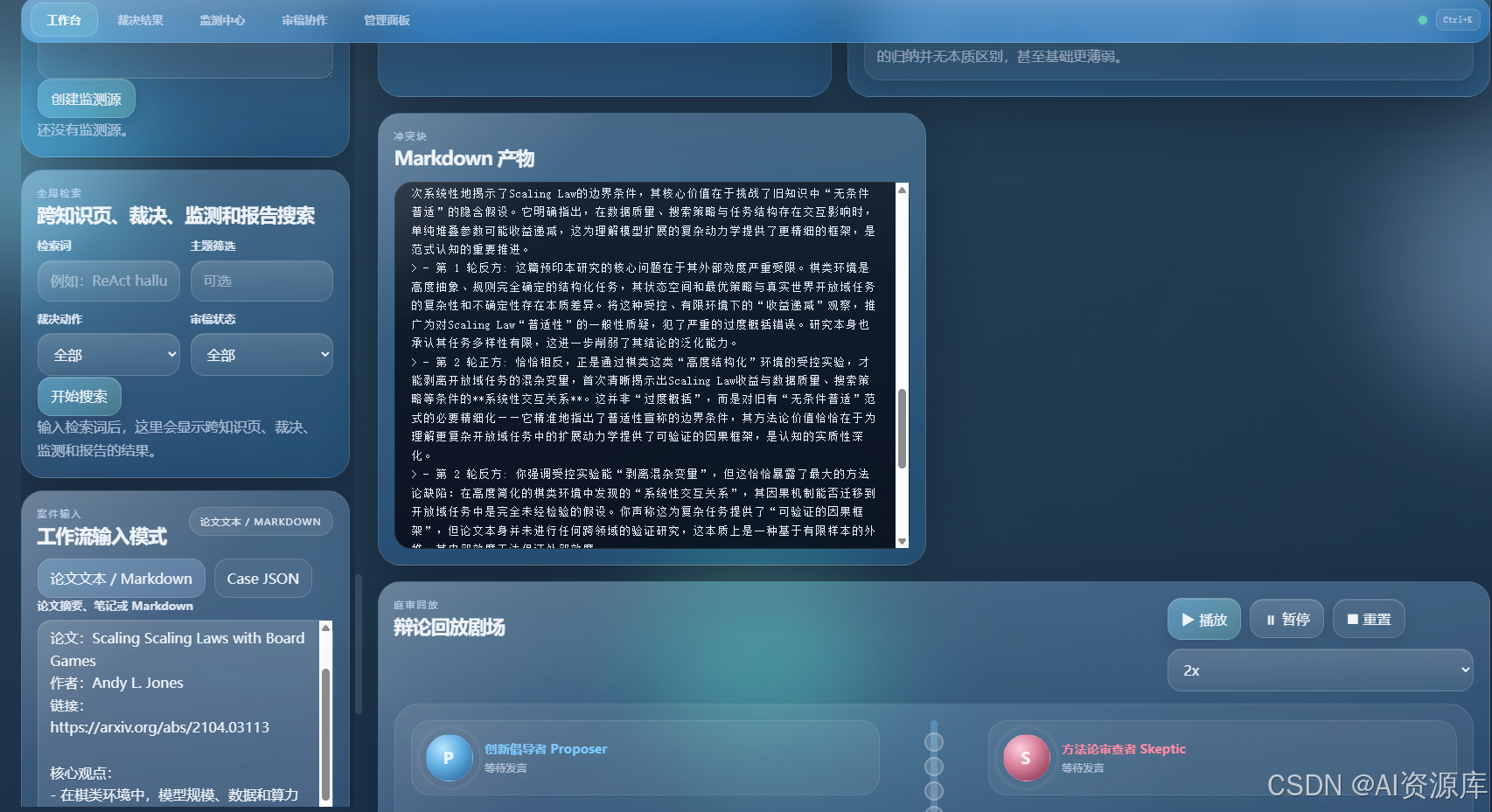
5. 🎭 辩论回放剧场:最有“产品 Wow Factor”的界面
建议截图内容:
- Proposer / Skeptic 双角色头像
- 时间线
- 打字机回放中的发言气泡
- 最终 Verdict 卡片
6. 📊 方法学风险评分卡:体现“不是只会说话,而是会评估研究质量”
建议截图内容:
- 方法学评分卡
- 风险等级
- 各维度分数与风险条
- 陪审团意见或多数意见模块

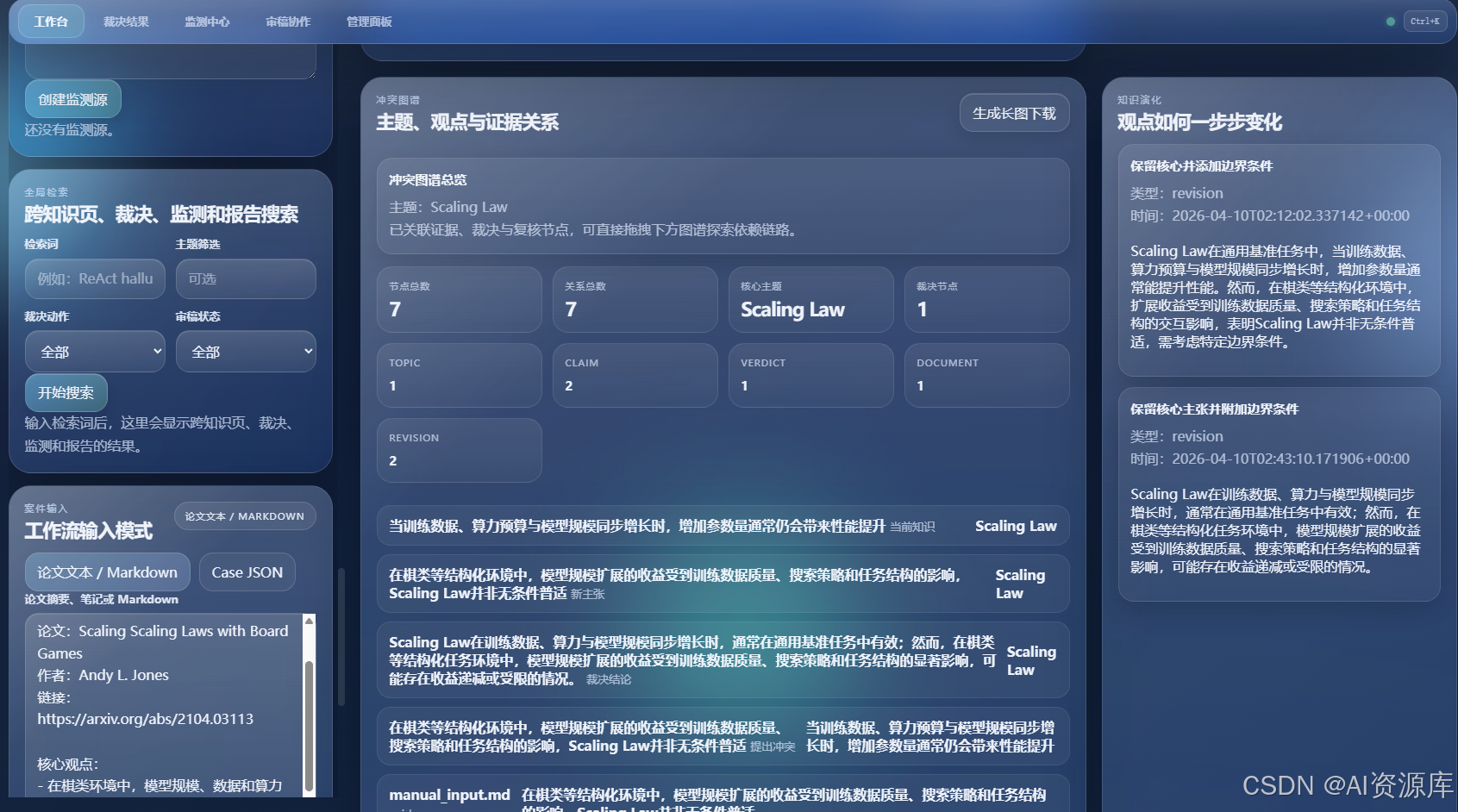
7. 🕸️ 冲突图谱 Atlas:最适合做文章封面图或中部大图
建议截图内容:
- Force-Directed 冲突图谱
- 节点关系
- 主题、证据、裁决等不同类型节点
- 右上角“生成长图下载”按钮也可以一起带上

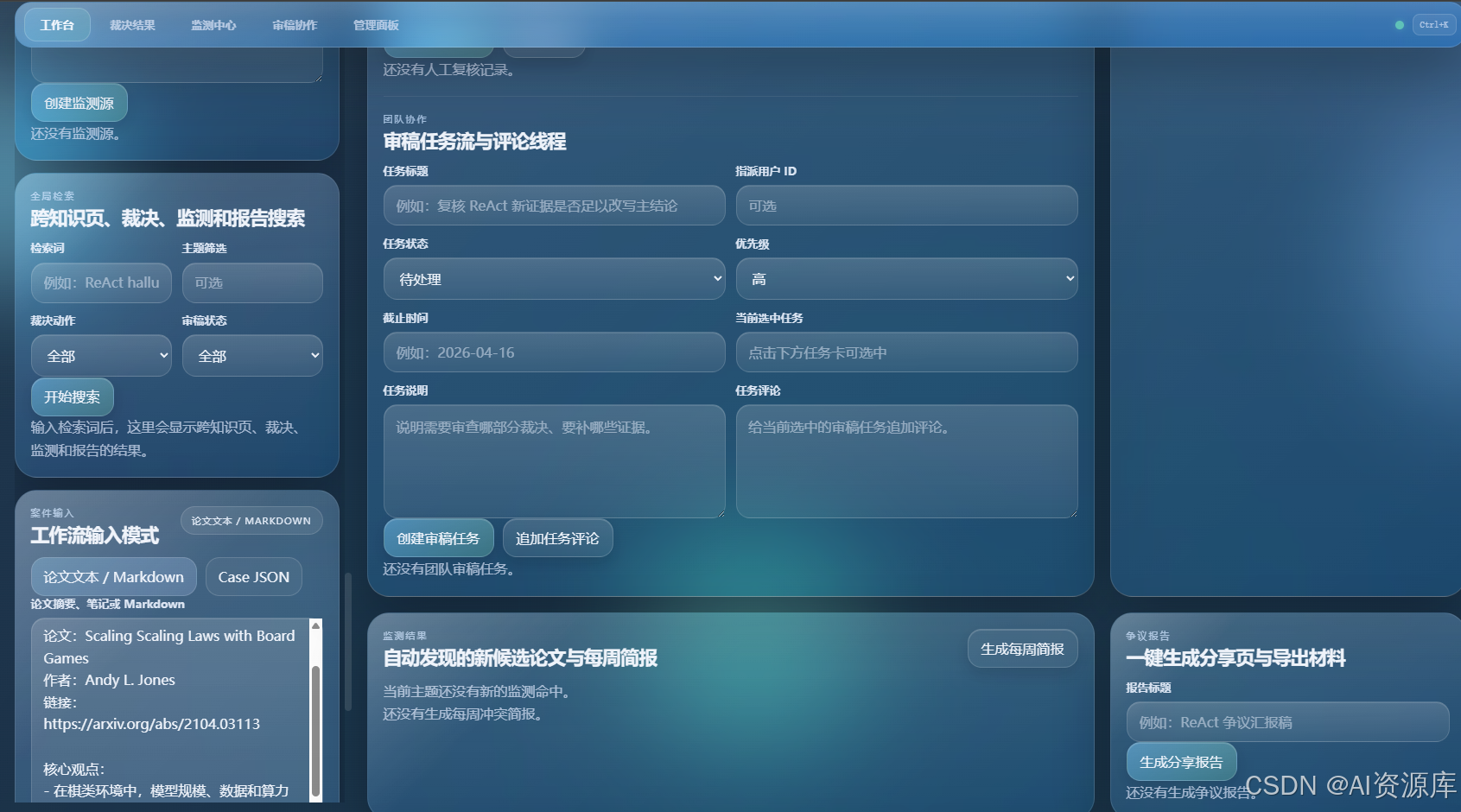
8. 📡 监测中心:持续追踪新论文,不只是一次性跑工作流
建议截图内容:
- 监测源配置
- RSS / JSON Feed / 手动种子
- 每周冲突简报
- 新论文命中结果
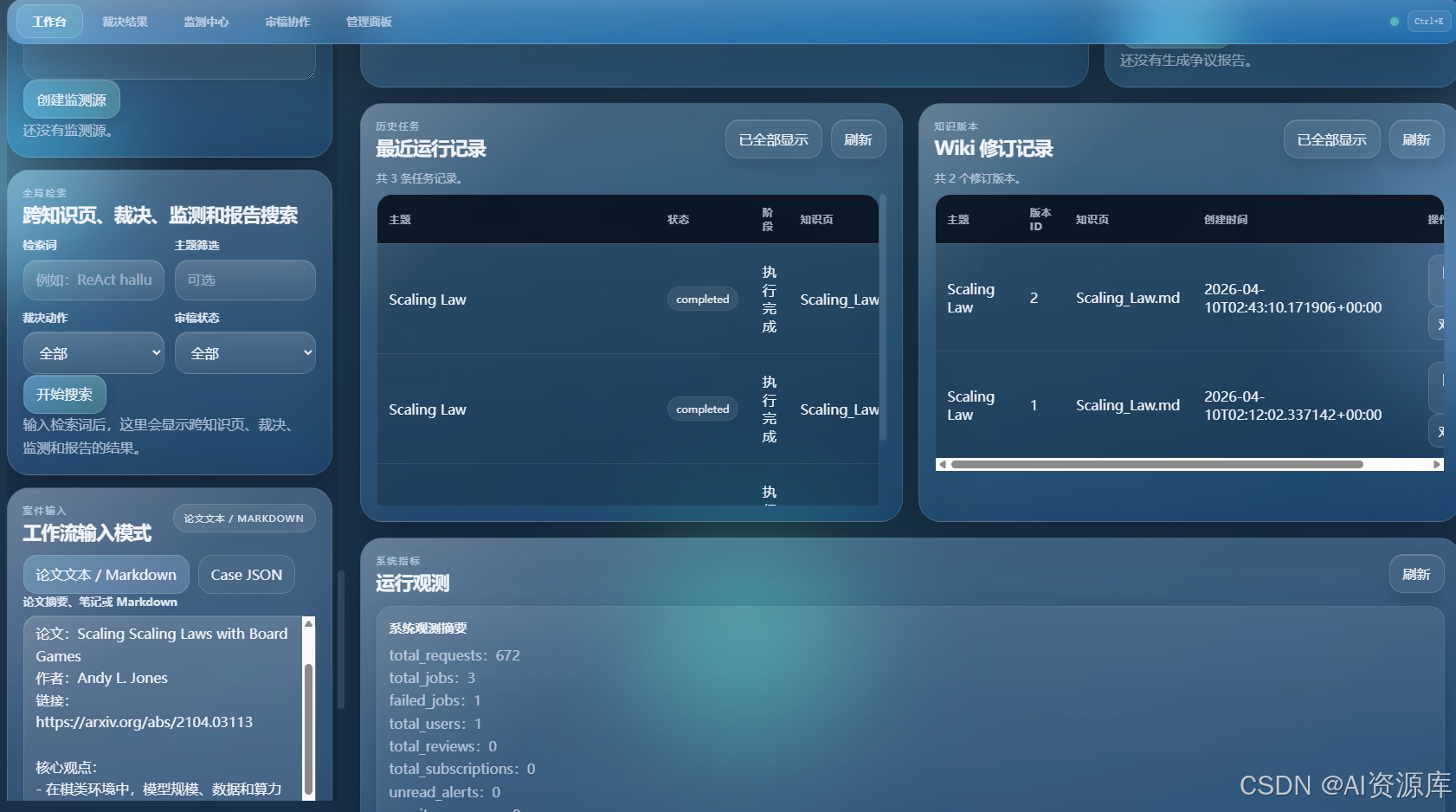
9. 👥 审稿协作 / 管理面板:展示它已经接近团队产品
建议截图内容:
- 审稿任务
- 评论线程
- 订阅提醒
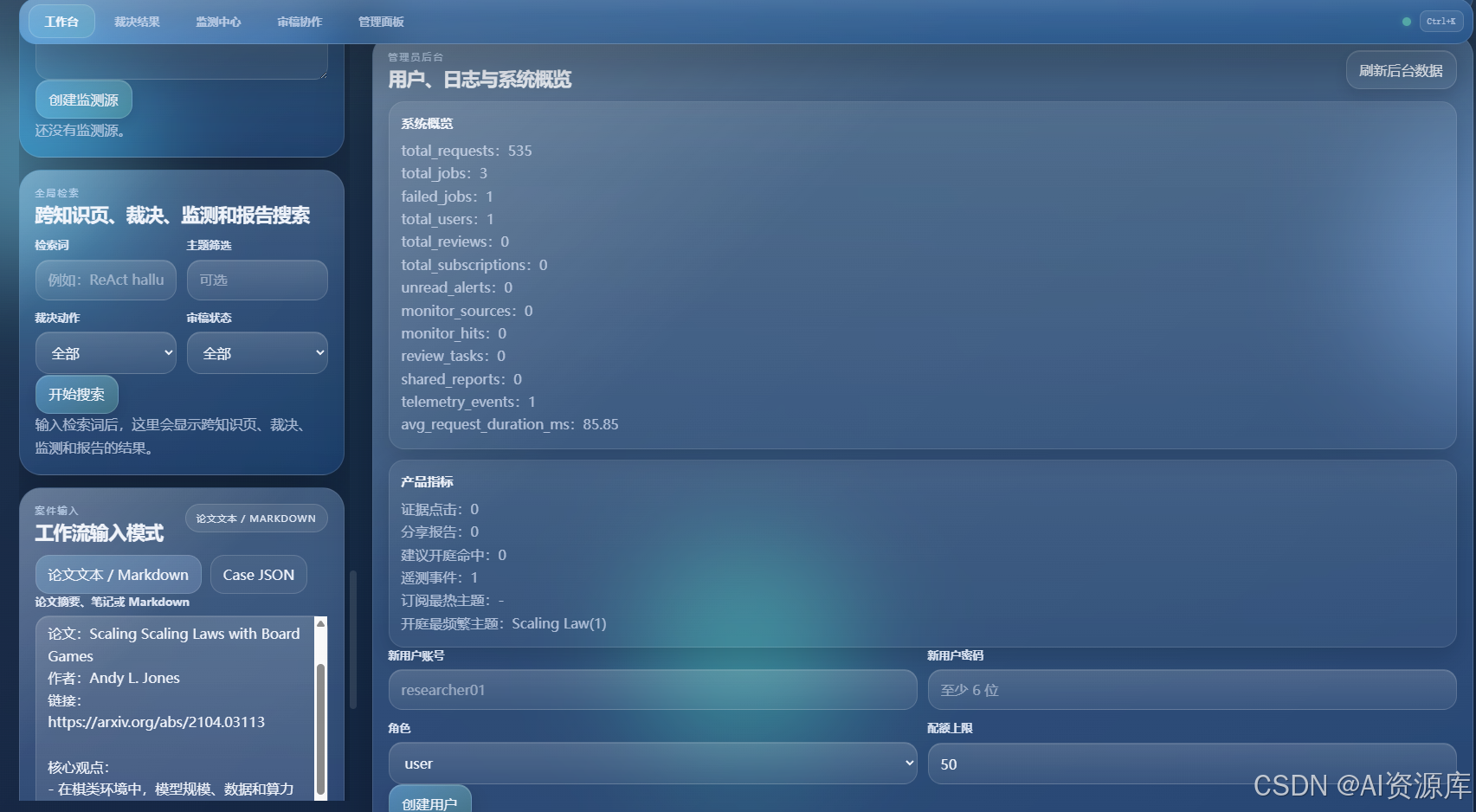
- 管理员后台
- 用户、日志、系统概览
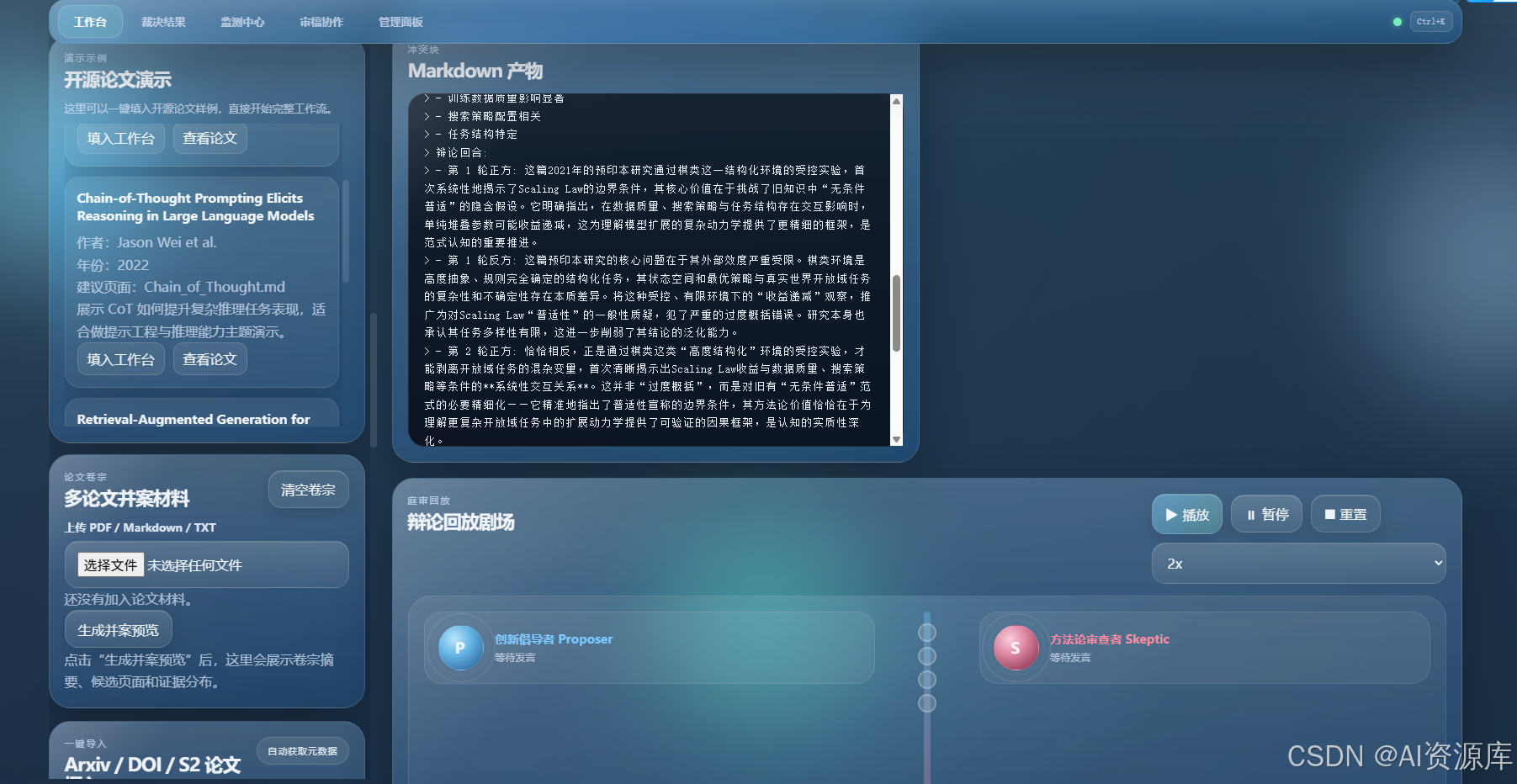
1. 🧾 多论文并案卷宗:不是单篇阅读,而是冲突案件建模
我在产品里设计的第一步,不是“上传一篇论文并总结”,而是把材料组织成一个冲突案件。
你可以:
- 上传 PDF / Markdown / TXT
- 一键导入 Arxiv / DOI / S2 论文
- 输入主题提示
- 选择目标 Wiki 页面
- 生成并案卷宗预览
系统会把这些输入整理成一个结构化冲突场景,而不是只做简单文本拼接。
这很重要,因为只有先把“材料”组织成“案件”,后面的辩论、裁决、证据追踪才成立。
2. ⚠️ 冲突雷达:先发现“哪里值得开庭”
很多时候,真正难的不是裁决,而是先判断:
哪些主题真的发生了值得处理的知识冲突?
所以我做了一个“冲突雷达”模块。
它会综合:
- 当前输入论文
- 知识库已有页面
- 检索召回结果
- 词法与语义信号
来评估某个主题是否存在高冲突强度,并给出:
- 冲突分数
- 是否建议进入法庭
- 候选冲突页
- 召回理由与命中线索
这让产品不只是“能裁决”,而是先能告诉你“哪里该裁决”。
3. 🧑💻🛡️⚖️ 多智能体学术法庭:让 AI 真正辩起来
这是整个系统最有辨识度的核心。
在进入法庭后,系统会启动多个角色:
Proposer:代表新观点,尽力论证其价值Skeptic:代表质疑方,寻找证据漏洞、样本规模问题、适用范围问题Judge:根据双方辩论做出最终裁决
而且这不是一轮“你一句我一句”的装饰性流程,我在系统里设计的是回合制辩论机制,强调:
- 论点推进
- 反驳链条
- 证据权重
- 边界条件补充
最终法官不会只输出一句空话,而会输出结构化裁决,例如:
- 保留旧规则
- 合并新结论
- 追加边界条件
- 标记待人工复核
4. 🎭 辩论回放剧场:把“AI 推理过程”做成能看懂的展示体验
我很在意一个问题:
AI 不是只要结果正确,还要让人“看懂它是怎么得出这个结果的”。
所以我做了“辩论回放剧场”。
它会把原本冷冰冰的结构化轨迹,转成更具展示力的前端体验:
- 双角色回放
- 动态 Avatar
- 逐字打字机播放
- 回合时间线
- 最终裁决卡片
这对 Demo、路演、汇报、展示都非常有用。
因为很多时候,真正打动人的不是一句“系统能处理冲突”,而是你能直观看到:
Proposer 在推动观点,Skeptic 在拆逻辑,Judge 在给结论。
这会让产品的“智能体感”一下子立住。
5. 📊 方法学风险评分卡:不只看观点,还看研究质量
很多论文冲突,并不是“谁说得更大声”,而是“谁的方法学更可靠”。
所以我做了方法学评分卡,来帮助系统和用户判断:
- 数据规模是否足够
- 风险等级如何
- 哪些维度存在方法学隐患
- 研究强项和脆弱点分别是什么
这让系统不只是生成“文本结论”,还给出一种更像研究评审的量化支撑。
6. 👩⚖️ 陪审团机制:不是单法官独裁,而是多意见综合
为了让裁决更稳,我还在产品里加入了“陪审团”风格的输出。
系统可以给出:
- 多数意见
- 分歧度
- 是否存在明显分歧裁决
- 各个意见的理由摘要
这意味着系统不会假装“世界上只有一个正确答案”,而是允许研究现实中的不确定性存在。
这点我觉得非常重要,也非常像真正的学术讨论。
7. 🕸️ 冲突图谱 Atlas:把抽象知识关系画出来
我非常喜欢这个功能,因为它让“知识冲突”第一次有了空间感。
在 Atlas 里,系统会把:
- 主题
- 旧观点
- 新观点
- 证据节点
- 裁决节点
- 修订节点
- 复核节点
画成一个可以拖拽的力导向图谱。
这和市面上很多“纯文本输出”的工具不同,它能把复杂关系显性化。
对于研究者、产品经理、技术负责人来说,这种图形化理解非常有价值。
而且现在我还加入了:
- 发光图谱视觉
- 长图下载能力
所以它不仅适合分析,也适合传播。
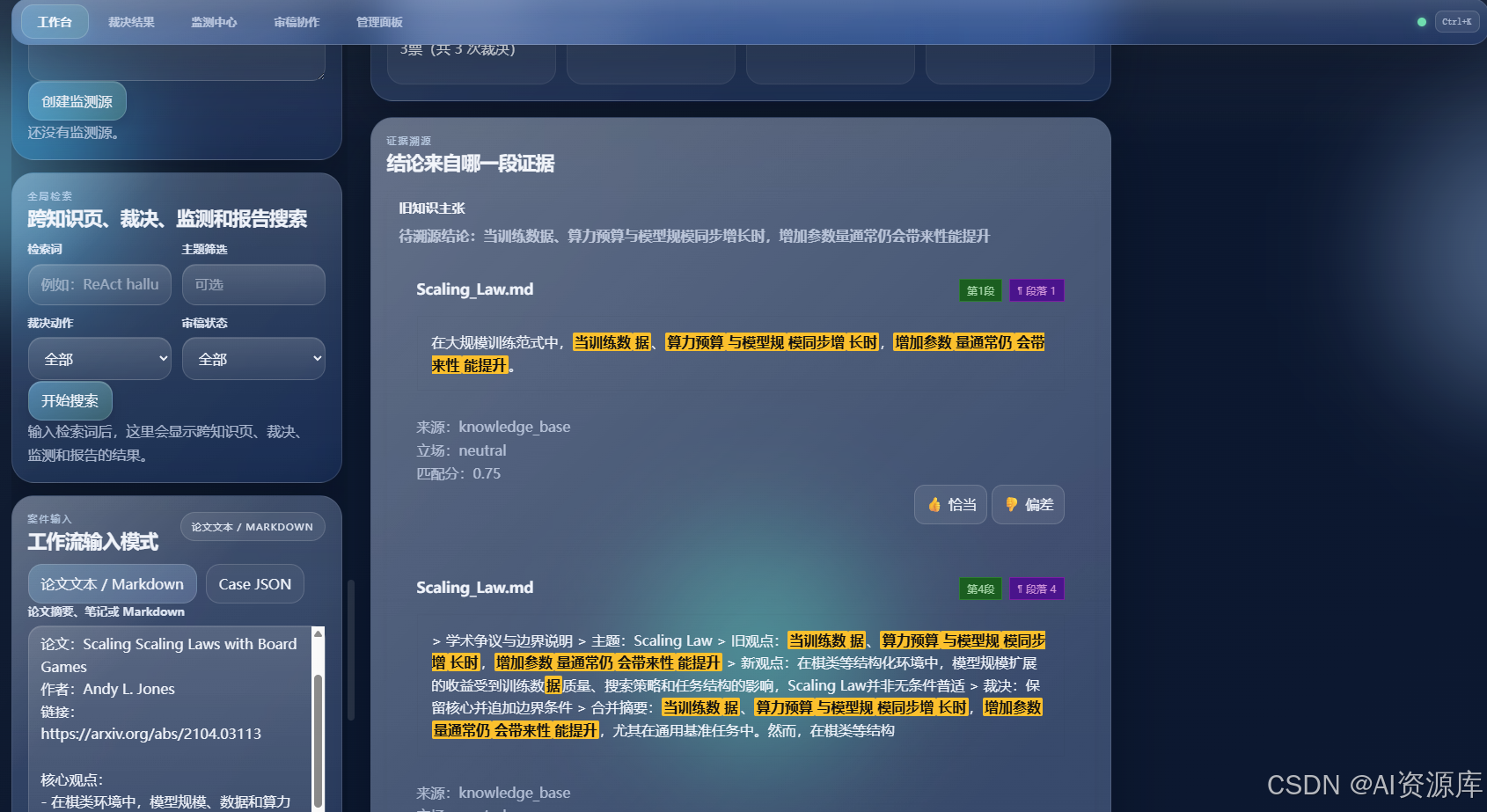
8. 🔍 证据溯源 + Diff 对照:每次更新都讲得清楚
我特别不想让这个产品变成“AI 改完了,但没人知道为什么”的黑箱。
所以它支持:
- 证据片段溯源
- 页码/段落锚点
- 命中词高亮
- 历史修订记录
- Side-by-Side Diff 对照
这样用户不只能看到“结果”,还能看到:
- 结论来自哪段原文
- 旧版本和新版本具体差别是什么
- 这次修改是不是合理
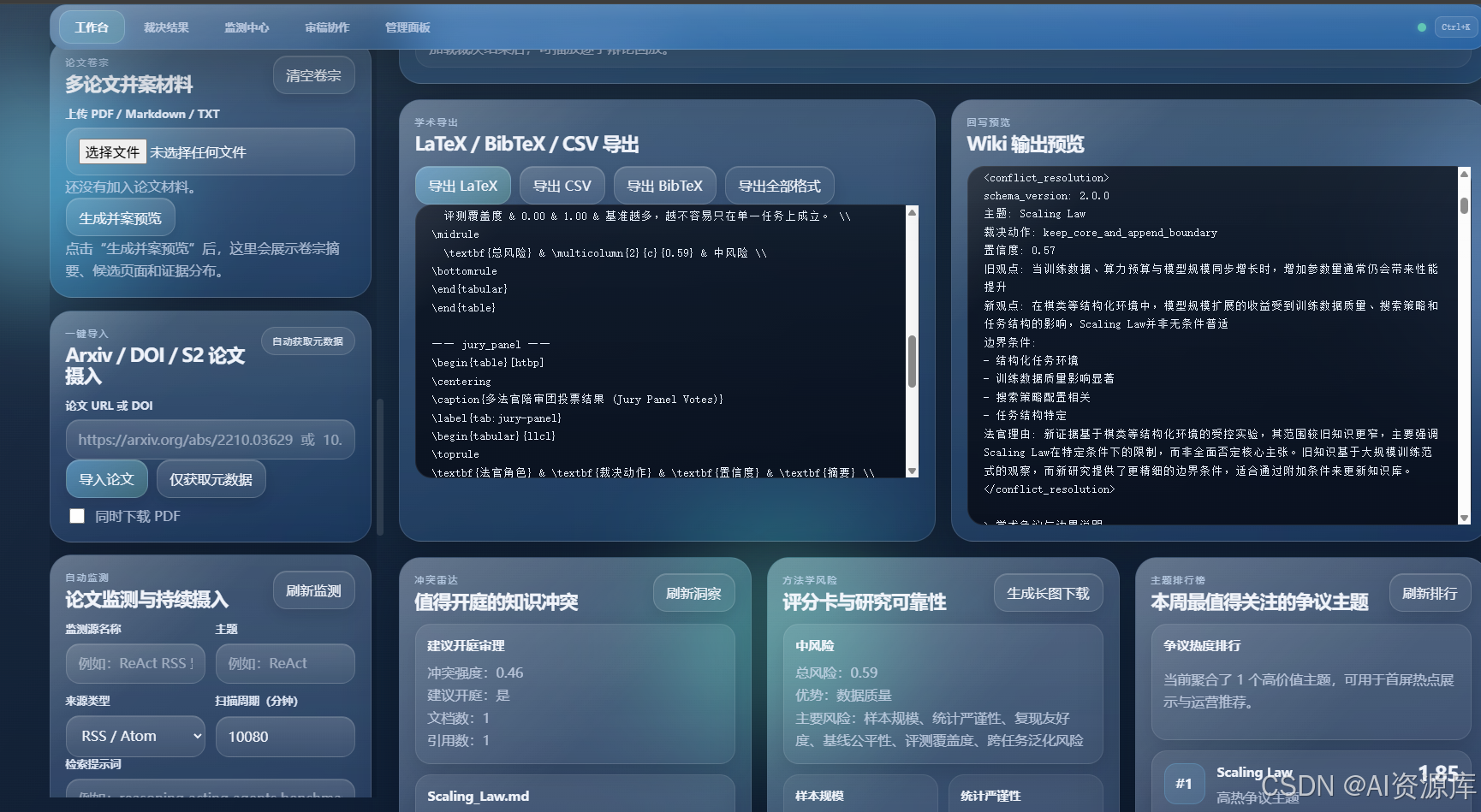
9. 📡 自动监测与每周简报:让知识库活起来
一个真正实用的研究产品,不能只会处理“你手动喂给它的东西”。
它还要能持续盯着世界变化。
所以我做了自动监测模块,你可以配置:
- RSS / Atom
- JSON Feed
- 手动种子数据
- 主题关键词
- 监测周期
系统会自动发现候选论文,并生成:
- 监测命中
- 冲突强度
- 是否建议进入法庭
- 每周冲突简报
这让产品从“单次使用工具”变成“持续运行的研究观察站”。
10. 🧩 审稿协作与管理后台:从个人工具升级为团队工作台
如果一个系统只适合一个人默默使用,它很难真正进入团队。
所以我做了:
- 审稿任务
- 评论线程
- 人工复核动作
- 主题订阅
- 提醒机制
- 用户与权限管理
- 请求日志与后台概览
这使它从一个“酷炫 Demo”真正长成一个可以被团队采用的产品原型。
它和市场上的其他产品相比,鲜明区别到底在哪?
这是我最想强调的一段。
不是普通的论文总结工具
很多产品做的是:
- 输入论文
- 输出摘要
- 顺手给你几个关键词
而我做的是:
- 输入冲突材料
- 识别知识冲突
- 多角色辩论
- 裁决并回写 Wiki
- 形成可追踪知识演化链
两者不是一个层级。
不是普通的 RAG 系统
普通 RAG 的目标是“尽可能召回相关内容”。
而我的产品更进一步,关注的是:
- 内容冲不冲突?
- 谁的证据更强?
- 该不该改写知识页?
- 应不应该保留边界?
也就是说,它处理的不只是“检索”,而是“知识治理”。
不是一个聊天机器人外壳
很多 AI 产品本质上还是问答界面。
我的产品则是完整的工作流系统,包含:
- 摄入
- 建模
- 辩论
- 裁决
- 回写
- 修订
- 监测
- 分享
- 协作
它更像一个“研究操作系统”的雏形,而不是一个会说话的助手。
不是只看结论,而是保留争议过程
我觉得这点尤其有特色。
市面上很多产品的逻辑是:
帮你把世界变得“看起来一致”
而我的产品承认现实:
很多知识本来就是不一致的,真正有价值的是把冲突表达清楚、裁决清楚、边界写清楚。
这是一种更接近研究世界的产品观。
这个产品最适合拿来做什么?
如果你问我:这套系统最适合落在哪些具体场景里?
我的答案会是下面这些。
场景 1:做文献综述 / 开题报告 / 研究图谱
这其实是我认为最“刚需”的场景之一,尤其适合本科生、研究生、博士生和刚进组的研究助理。
传统做法通常是这样的:
- ✋ 打开二三十篇论文 PDF
- ✋ 一边读一边截图、一边记笔记
- ✋ 到最后写综述时才发现:我知道每篇论文说了什么,但我不知道它们之间的关系是什么
而这个产品更适合做的是:
- 🧾 把某个主题下的多篇论文组织成一个冲突案件
- ⚠️ 先让系统自动扫描哪些观点之间真正存在冲突
- 🧑💻🛡️⚖️ 再通过多智能体辩论,把“谁支持什么、谁挑战什么、边界在哪里”梳理清楚
- 🕸️ 最后通过 Atlas 图谱把争议结构、证据节点和裁决节点一口气可视化出来
这意味着你在写开题报告、综述文章或研究地图时,不再只是拿到一堆零散摘要,而是能拿到一套更接近“研究争议地图”的结果:
- 哪些论文是共识性结论
- 哪些论文是挑战性结论
- 哪些结论只在特定数据规模或特定任务里成立
- 哪些地方值得作为 Related Work 的对比重点
一个很真实的使用方式
比如你正在做一个方向:
“ReAct 是否真的比纯 Chain-of-Thought 更适合复杂任务代理?”
你完全可以这样用:
- 导入几篇代表性论文
- 选择目标 Wiki 页面
- 让系统先跑冲突雷达
- 进入学术法庭
- 读取裁决摘要、方法学评分卡和 Atlas 图谱
- 最后把结果回写成你自己的研究 Wiki
最后你拿到的,就不是“几篇论文的摘要”,而是一份更适合直接进入论文写作的结构化材料。
这个场景最有价值的地方
- 🎓 对学生来说,它能大幅降低“看过很多论文但写不出来”的痛苦
- 🧠 对研究者来说,它能更快定位真正有研究价值的争议点
- 🚀 对开题来说,它特别适合把“研究空白”和“争议边界”讲清楚
场景 2:做实验室内部 Wiki
这也是我很看重的一个场景,因为很多实验室其实并不缺文献,而是缺“可传承的知识系统”。
现实中的实验室经常会遇到这些问题:
- 新同学入组后,要花很久才能知道“这个方向目前的主流观点是什么”
- 老师和师兄师姐口头说过很多关键边界,但没人写进正式文档
- 每次读到新论文,大家会在群里聊一阵,但知识并没有真正沉淀下来
- 同一个主题隔几个月就会被重新讨论一次,因为没有清晰的版本记录
而我做的这套系统,特别适合把实验室的知识管理从“碎片交流”升级成“持续治理”。
在实验室里可以怎么用?
- 📚 把每个研究方向维护成一个 Wiki 页面
- 📥 每周导入本周新论文或会议新结果
- ⚠️ 用冲突雷达先标出哪些页面可能被挑战
- ⚖️ 对关键更新进入法庭裁决
- 📝 把裁决结果自动回写到目标知识页
- 🔍 保留 Diff、证据溯源和修订记录
- 👥 让师兄、老师、组员在审稿协作区做人工复核
这样之后,实验室的知识就不再是“谁记忆力最好谁说了算”,而是:
- 有版本
- 有证据
- 有争议记录
- 有修订理由
- 有人工复核痕迹
这个场景下,它更像什么?
如果说普通 Wiki 更像“静态资料柜”,
那这套系统更像一个会持续运转的研究知识中台。
我觉得它尤其适合下面这些团队:
- 🧪 长期做某一固定方向的课题组
- 🧪 需要代际传承研究知识的实验室
- 🧪 做综述、benchmark、survey 的研究团队
用一句话概括这个场景
它不是帮实验室“多记一点东西”,而是帮实验室把“研究共识、争议边界和知识演化”真正留存下来。
场景 3:做 RAG / Agent 系统的知识治理后端
这一点其实很关键,而且我认为它是这个项目最容易被低估的价值之一。
现在很多团队在做:
- RAG 问答系统
- 企业知识库
- Agent 自动化工作流
- 多文档事实整合
但这些系统有一个常见误区:
大家把很多精力花在“怎么把内容检索出来”,却没有足够重视“检索出来的内容彼此冲突时怎么办”。
这正是我觉得这套系统可以往后端治理层走的原因。
它在 RAG / Agent 架构里可以扮演什么角色?
它不一定非要作为一个独立前端工作台存在。
它也可以作为你整套知识系统中的“裁决中枢”:
用户问题
↓
Retriever / Search
↓
召回多份外部知识
↓
Academic Court 冲突治理层
├─ 检查知识是否互相冲突
├─ 判断哪一方证据更强
├─ 识别边界条件与失效区间
├─ 输出结构化裁决
└─ 决定是否回写知识库
↓
最终答案 / 最终知识页 / 最终 Agent 行动
这会带来什么好处?
- 🛡️ 降低“把冲突事实同时塞进答案里”的风险
- 🛡️ 降低“单模型自信胡编统一结论”的概率
- 🛡️ 让系统在面对版本冲突、研究冲突、政策冲突时更可审计
- 🛡️ 让知识库更新从“覆盖式写入”变成“裁决式写入”
对 Agent 系统尤其有价值的点
如果你做的是 Agent,而不是简单问答,那么冲突治理会更重要。
因为 Agent 一旦基于错误知识采取行动,后果往往比聊天机器人说错一句话更严重。
所以我觉得这套系统特别适合作为:
- 企业级知识问答系统的“裁决层”
- 多文档事实融合的“治理层”
- 自动化知识回写系统的“安全阀”
- Agent 工作流里的“可信知识仲裁器”
用一句更工程化的话说
如果普通 RAG 解决的是“找得到”,那这套系统解决的是“信得过”。
而在复杂系统里,后者往往比前者更难,也更值钱。
场景 4:做面向客户或投资人的高质量 Demo
这个场景我必须单独展开讲,因为这套产品在“展示感”上其实非常强。
很多技术项目的问题不是“功能不够”,而是:
- 讲不清楚
- 展示不直观
- 很难让外行一眼看懂
- Demo 一打开就像后台管理系统或者命令行脚本
而我做这个产品时,恰恰很在意“演示说服力”。
尤其是:
- 辩论回放剧场
- Atlas 图谱
- 方法学评分卡
- 长图导出
这些模块几乎天生就适合:
- 🚀 路演
- 🚀 对外发布
- 🚀 客户演示
- 🚀 投资人介绍
- 🚀 技术发布会
为什么它适合做高质量 Demo?
因为它同时具备了 4 种非常强的展示元素:
1. 有故事线
不是打开页面后随便点两下,而是可以完整演示:
输入新论文 → 发现冲突 → 多智能体辩论 → 生成裁决 → 回写知识 → 持续监测
这是一条非常完整的产品叙事线。
2. 有“角色感”
Proposer、Skeptic、Judge 这三个角色一出来,哪怕对方不懂技术,也能立刻明白:
- 一个在主张更新
- 一个在质疑证据
- 一个在做最后判断
这会比一大段技术术语更容易打动人。
3. 有可视化高潮
最适合做“哇哦时刻”的几个页面就是:
- 🎭 辩论回放剧场
- 🕸️ Atlas 图谱
- 📊 方法学评分卡
- 🖼️ 长图导出
这些页面都不是纯后台感,而是很有传播张力。
4. 有传播素材
长图导出特别适合做:
- 社交媒体宣传图
- 产品介绍封面
- 路演资料附图
- 微信群/朋友圈传播素材
如果我来演示,我会怎么走一遍?
一个 5 分钟 Demo 路线
- 先打开首页,让对方看到五大 Tab 和完整工作台
- 导入一篇新论文或直接填入一个演示案例
- 运行冲突雷达,说明系统不是盲目裁决,而是先发现冲突
- 进入裁决结果页,展示 Proposer / Skeptic / Judge 的输出
- 播放辩论回放剧场,把“智能体对抗”讲出来
- 拉到方法学评分卡,说明系统不是空口裁决,而是有质量评估
- 展示 Atlas 图谱,把复杂关系一图讲清
- 最后点一下长图导出,告诉对方这套东西还能直接传播
为什么这对客户和投资人有用?
因为他们看到的不是“一个技术点”,而是一整套:
- 有逻辑
- 有流程
- 有界面
- 有输出
- 有传播力
的产品雏形。
这和那些只能展示“这里接了模型 API、那里做了检索”的项目,气质上完全不一样。
🎬 如果你要把这篇博客写得更炸,我建议再加一段“30 秒看懂 Demo 路线”
你甚至可以直接把下面这段也放进文章里,特别适合让读者快速代入:
30 秒看懂这套产品怎么演示:
├─ 第 1 步:打开工作台,导入论文或演示案例
├─ 第 2 步:冲突雷达判断是否值得开庭
├─ 第 3 步:多智能体法庭启动,Proposer / Skeptic 开始交锋
├─ 第 4 步:Judge 给出结构化裁决
├─ 第 5 步:生成方法学评分卡与陪审团意见
├─ 第 6 步:用 Atlas 图谱解释证据关系
└─ 第 7 步:导出长图,完成传播闭环
我为什么敢说这是一个“有产品感”的系统?
因为我在设计它时,并没有把它当成一个纯技术实验。
我一直在往“产品完整性”上补:
- 有工作台,不只是命令行
- 有状态反馈,不只是黑盒处理
- 有审稿协作,不只是单人使用
- 有监测机制,不只是一次性跑完
- 有图谱、回放和分享,不只是工程功能
我希望它最终给人的感觉,不是“某个模型串了几个 prompt”,而是:
这是一个真的可以把知识冲突纳入流程治理的产品。
明确说明一下:这是我开发的产品
这一点我想写得直接一点。
多智能体学术法庭(Multi-Agent Academic Court)是我亲自开发和持续打磨的产品。
它从最初的研究灵感出发,逐步长成了一个具备:
- 多智能体辩论引擎
- Web 工作台
- 冲突图谱
- 方法学评分卡
- 持续监测
- 审稿协作
- 回写与修订管理
等完整能力的系统。
如果你看到这里,觉得它不像一个“玩具项目”,那其实正是我希望达到的效果。
如果继续优化,我觉得还可以往哪几个方向走?
这个产品已经很有展示力,但如果继续打磨,我认为还有一些很值得做的方向。
1. 🌍 更强的多语言知识治理
目前已经能处理中英文学术语境,但后续可以继续强化:
- 中英混合论文的统一裁决
- 多语言 Wiki 页面联动
- 跨语言观点对齐
2. 📈 更强的证据可信度计算
后续可以加入更细的研究质量因子,比如:
- 样本量权重
- 数据集影响范围
- 引文与时效性
- 可复现实验信号
3. 👥 更完整的团队协作体验
例如:
- 更细粒度的角色权限
- 多人审稿流转
- 审核 SLA
- 冲突升级机制
4. 📢 更强的分享与传播能力
现在已经支持长图下载,未来还可以继续做:
- 一键分享页
- 主题专题页
- 可嵌入报告卡片
- 面向社交媒体的传播模板
5. 🧠 更智能的“知识演化建议”
不仅告诉你“是否要改”,还可以进一步告诉你:
- 这页知识应该怎么重构
- 哪一段应该被拆开
- 哪些旧结论已经进入高风险区
如果你觉得还需要优化,欢迎在评论区 @我
如果你看到这里,觉得这个产品还有哪些地方可以继续优化,或者你特别想看我下一步加什么功能,欢迎你:
- 在评论区直接
@我 - 告诉我你最想优化的模块
- 告诉我你最想新增的功能
- 告诉我你希望它服务哪类真实场景
我会非常认真地看这些反馈。
因为这个项目本身,就是我想长期打磨的一套系统,而不是一篇写完就结束的 Demo 说明。
如果你愿意,你甚至可以直接抛给我一些更“刁钻”的问题,比如:
- 能不能做成企业知识治理平台?
- 能不能支持更多模型混用?
- 能不能接入更正式的评审流程?
- 能不能成为实验室的研究操作中台?
这些问题,我都很乐意继续往下做。
最后,我想用一句话总结这个项目
很多 AI 产品在解决“如何更快得到答案”。
而我开发的这个产品,更想解决的是:
当答案彼此冲突时,我们怎样让知识被更可信地维护下来。
如果 LLM Wiki 让知识第一次有了“自动沉淀”的形态,
那我希望这套 多智能体学术法庭,能进一步让知识拥有“公开辩论、结构化裁决与持续治理”的能力。
这就是我做这个产品的意义。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐

 21
21 0
0- 0



 已为社区贡献40条内容
已为社区贡献40条内容

所有评论(0)