中小型团队知识库搭建:AI开源实践方案
在企业知识管理与技术文档体系建设中,传统Wiki载体普遍存在检索效率低、内容维护成本高、AI能力缺失、多源文档兼容差等问题。作为AI原生开源知识库,以大模型为核心驱动,提供全链路知识生产、管理、检索与问答能力,同时可对接BeeParser智能文档解析,实现非结构化文档到AI可用数据的高效转换,满足私有化部署、多端集成与复杂文档处理需求。
一、核心技术与能力
基于AGPL‑3.0开源协议,采用前后端分离架构,支持Docker快速部署、内网私有化运行、多模型接入(在线大模型与本地模型),核心能力覆盖文档编辑、智能检索、AI问答、权限管控、多渠道集成五大模块。
1. 核心技术
- AI原生能力:集成向量检索、重排序模型与生成模型,实现语义搜索、精准问答、AI辅助创作,突破关键词匹配局限,支持答案溯源,降低AI幻觉风险。
- 富文本与多格式兼容:原生支持Markdown/HTML混合编辑,可导出Word、PDF、Markdown等格式,适配技术文档、产品手册、FAQ、博客等多场景内容形态。
- 多源内容导入:支持URL、Sitemap、RSS、离线文件批量导入,降低存量文档迁移成本。
- 企业级权限体系:前后台分离权限、角色管理、多方式访问认证(密码、钉钉/飞书/企业微信、LDAP、OAuth、GitHub),满足组织级管控需求。
- 轻量化集成:提供网页挂件、IM机器人(钉钉、飞书、企业微信等)、问答API,实现知识多端触达。
2. 与智能文档解析融合
智能文档解析是面向AI场景的毫秒级文档解析,支持PDF、Word、PPT、Excel、图片(JPG/PNG)等10+格式,可将扫描件、复杂排版文档高精度转为标准Markdown,稳定提取表格、公式、图表等结构化信息,提供API与Agent快速接入,与形成文档解析→知识入库→智能应用的闭环。
两者融合优势:
- 非结构化文档一键入库:智能文档解析PDF、扫描合同、技术手册,输出Markdown直接导入,无需人工排版;
- 提升知识库质量:复杂版式、多语言、表格内容完整保留,检索与问答准确率显著提升;
- 全链路自动化:通过API对接,实现上传→解析→入库→索引→可问答的自动化流程,降低运维成本。
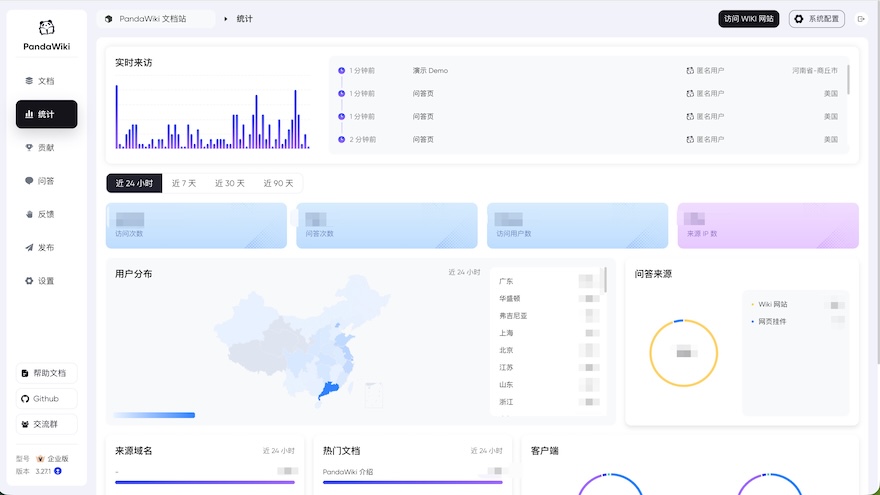
二、实践案例:研发+运维一体化知识库落地
此处采用某中小型技术团队(15–30人)研发运维一体化场景,区别于常规产品文档、内部FAQ案例,聚焦多源异构文档治理、故障知识沉淀、跨团队协作检索,完整呈现+智能文档解析落地流程。
1. 场景痛点
- 研发文档分散:Confluence、GitLab、本地Word、PDF、截图、扫描版运维手册并存,格式混乱;
- 故障排查低效:历史方案散落在聊天记录、邮件、个人笔记,新人上手慢;
- 巡检报告、应急手册难以结构化:扫描件、图片类文档无法检索;
- 权限管控复杂:研发、测试、运维、外包人员权限需分级,禁止越权访问核心配置。
2. 实施方案
- 部署与模型配置
内网Docker部署,接入在线模型,兼顾响应速度与数据安全;配置LDAP认证,统一企业账号权限,避免多套账户管理。
- 文档解析与批量迁移
- 存量Word/PDF/扫描巡检报告通过智能文档解析 API批量解析,输出标准Markdown;
- 解析后自动保留目录层级、表格、配置参数,直接导入,1000+页文档2小时完成迁移;
- 网页文档通过URL/Sitemap批量抓取,自动生成知识库章节结构。
- 知识库结构设计
- 研发层:接口文档、部署指南、代码规范、版本日志;
- 运维层:巡检手册、故障案例、应急流程、配置模板;
- 公共层:FAQ、培训材料、工具使用说明。
- AI能力启用
- 开启语义检索:输入“服务器CPU高排查”,返回关联案例、命令、配置项;
- 配置问答机器人:接入企业微信,群内@机器人即可查询故障方案、接口说明;
- AI辅助创作:自动生成故障报告模板、巡检小结,降低文案成本。
- 精细化权限配置
- 研发:读写技术文档;
- 运维:读写故障案例、巡检手册;
- 外包:只读公共FAQ,禁止访问敏感配置。
3. 落地效果
- 文档检索效率提升70%,故障平均处理时长缩短40%;
- 扫描件、图片类文档100%可检索,信息丢失率降至接近0;
- 新人入职培训周期从2周缩短至5天,知识传承标准化;
- 全流程私有化,敏感配置不出内网,满足合规要求。

三、使用心得与技术优化建议
1. 核心使用心得
- AI能力要用在刀刃上:优先用于语义检索、答案生成、内容摘要,复杂逻辑与敏感内容保留人工审核,平衡效率与准确性;
- 文档结构化是关键:借助智能文档解析先标准化再入库,比直接导入原生格式更利于AI理解;
- 权限前置设计:按团队、岗位、密级规划角色,避免后期重构权限体系;
- 轻量化集成优先:先落地IM机器人与网页挂件,快速验证价值,再逐步深化定制开发。
2. 技术优化要点
- 部署:内网环境建议配置独立向量库,提升高并发检索速度;
- 模型:高频问答用轻量模型,复杂创作用增强模型,平衡成本与效果;
- 解析:扫描件优先用智能文档解析高精度模式,确保公式、表格、多语言完整提取;
- 索引:定期重建文档索引,提升新增内容的检索命中率。
四、总结
以开源可控、AI原生、轻量化部署、强集成性,为企业提供低成本、高可用的知识库底座;搭配智能文档解析,补齐非结构化文档、扫描件、复杂排版文档的处理短板,形成文档解析→知识治理→智能检索→多端问答的完整闭环。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐



 9
9 0
0- 0



 已为社区贡献20条内容
已为社区贡献20条内容

所有评论(0)