2026认证杯数学建模网络挑战赛D题:共享充电宝的投放配置(附全代码/论文/数据集)【2026年认证杯D完整题解方案】-详细解题思路和论文+完整项目代码+全套资源【多套正确答案版本+全网首发】

完整内容获取👇👇👇👇
推荐:https://mbd.pub/o/bread/YZWclptyZg==
https://download.csdn.net/download/qq_40379132/92793358
随着移动互联网的渗透,共享充电宝已经成为商业园区不可或缺的基础设施。2026年“认证杯”数学建模第一阶段D题(专科组/爱好者组)要求我们面对一个典型的开放式商业园区,解决共享充电宝的时空需求分析、柜机选址、容量配置及初始库存优化等复杂运营问题。
尽管D题难度标定为基础级,但若想在众多参赛队伍中脱颖而出冲击国奖,就绝不能停留在简单的“数据可视化”和“拍脑袋选址”上。本题的本质是一个经典的“设施选址-容量分配联合优化问题(Facility Location and Capacity Allocation Problem)”,并深度耦合了时间与空间的随机需求。
本文将用运筹学(Operations Research)的严密逻辑,配合机器学习与数学规划框架,为您全景展现本题的最优解法,并附上高质量Python源码。
🔍 问题一:需求的时空动力学机制与建模
1. 深度剖析“潮汐效应”与时空错位机制
共享充电宝业务最大的痛点在于**“借与还的时空极度不对称”**。
-
借出热点(Borrowing Hotspots)的瞬时爆发:顾客通常在“手机电量告急且处于移动状态”时产生借用需求。例如,中午时段的快餐区或下午的咖啡厅,人流量大且顾客停留时间较短,这是典型的借出高发区。
-
归还热点(Returning Hotspots)的长尾沉淀:与借出相反,归还行为往往发生在消费路径的“终点”。比如晚间的KTV、电影院(长时间停留后电量充满),或者是通往地铁站的商业街主出口。这种现象在学术界被称为“需求的空间潮汐效应”。如果模型不能识别这种潮汐特征,必然会导致灾难性的库存失衡。
2. 摒弃单一中心论:多核集聚(Polycentric)特征
与一栋封闭的单体写字楼不同,开放式商业园区拥有多个出入口和错综复杂的步行骨架。其需求分布绝对不可能呈现简单的“几何中心”或“同心圆”向外递减的特征。相反,随着餐饮、零售、娱乐三大主力店(Anchor Stores)的分布,需求必然呈现**“多热点集聚”**状态。因此,我们在选址时,必须采用K-Means或DBSCAN等空间聚类算法,寻找多个“引力中心”,而非单纯计算物理几何中心。
3. 洞察时空特征的三大维度
我们需要将附件提供的“静态数据”转化为“动态认知”:
-
借还热点的时间割裂性:借出热点通常发生在“手机电量告急且急需走动”的场景。例如,中午时段的餐饮区(停留时间短、人流密集)往往是典型的借出热点。而归还热点则往往出现在“消费行为结束”或“长时停留”的场景,比如晚间的娱乐区、咖啡区或主停车场出口。这就导致了借与还存在着明显的时空错位。
-
多热点分布(Multi-centric Distribution):与单体的百货大楼不同,开放式园区通常具有多个主副入口和功能分区。因此,需求分布绝对不会呈现单一的“几何中心”特征,而是随着餐饮、零售、娱乐三大主力店的分布,呈现典型的**“多热点集聚(Polycentric)”特征。
-
需求形成的核心机制:赛题鼓励探讨入口流量、吸引强度等现实信息对需求的影响。从宏观来看:
-
借出需求(Borrow Demand) 区域入口流量 $\times$ 区域吸引强度(人进得来且留得住)
-
归还需求(Return Demand) 平均停留时长(停留越久,把充电宝用完归还的概率越大)
-
4. 构建数理化的需求描述模型
为了给第二问的运筹优化提供精准输入,我们不能仅仅使用历史静态均值,而必须构建动态数学模型。赛题提示我们要结合入口流量、吸引强度等因素。
设园区划分为 R 个区域,一天分为 T 个时段(如小时)。对于区域 i 在时段 t:
-
基础借出需求 \mu_{i,t}^{bor} 可以建模为:

(注:这里使用指数衰减项是因为停留时间过长的区域,人们往往自带充电器或找固定插座,对共享充电宝的借出需求反而下降)
-
基础归还需求 $\mu_{i,t}^{ret}$ 建模为:
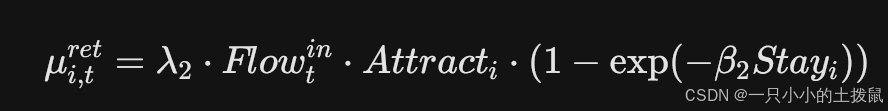
考虑到需求的随机波动,实际需求可以假定服从均值为 $\mu$ 的泊松分布(Poisson Distribution):
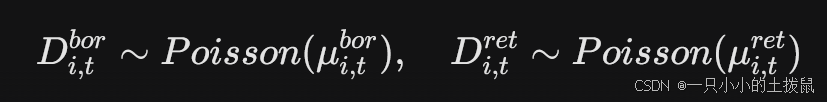
🛠️ 问题二:预算约束下的“选址-容量”联合优化模型
这是整道赛题的决胜点。由于运营方建设预算有限,我们需要决定在哪些候选点建站、建多大容量、放多少初始充电宝。更麻烦的是,必须兼顾步行便利性,并控制“借空”和“还满”导致的服务损失。顾客是很懒的,赛题明确指出“步行距离越长,使用意愿越低”。因此,某个柜机能吸收多少需求,取决于它和顾客的距离。我们采用改进的重力分配模型(Gravity Model):
1. 严谨的决策变量定义
-
x_j \in \{0, 1\}:是否在候选位置 $j$ 建设柜机。
-
y_j \in \{S, M, L\}:若建设,选择何种容量规格(小/中/大)。对应的建设成本记为 F_{y_j},物理插槽容量记为 C_j。
-
s_j^0:站点 j 的初始充电宝投放数量。显然,初始空闲插槽数为 C_j - s_j^0。
2. 距离衰减与空间需求重分配
顾客借还有其惰性:“步行距离越长,使用意愿越低”。我们需要用重力模型(Gravity Model)或Logit模型,将区域 $i$ 的需求分配到各个具体的柜机站点 j。
设区域 i 到站点 $j$ 的距离为 d_{ij}。距离敏感系数为 \gamma。则区域 i 顾客选择站点 j 的概率 P_{ij} 为:
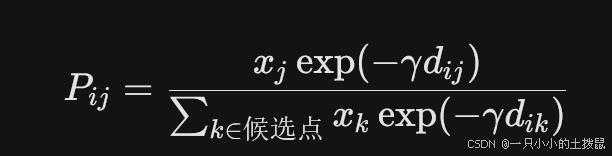
由此可得,分摊到站点 $j$ 的实际期望借出需求为 $\tilde{D}_{j,t}^{bor} = \sum_i \mu_{i,t}^{bor} \cdot P_{ij}$。
3. 多目标极小化函数的构建
这是一个典型的混合整数非线性规划(MINLP)问题。我们的终极目标是建立一个涵盖三大痛点的综合成本最小化函数:

其中,库存动态演化方程为:
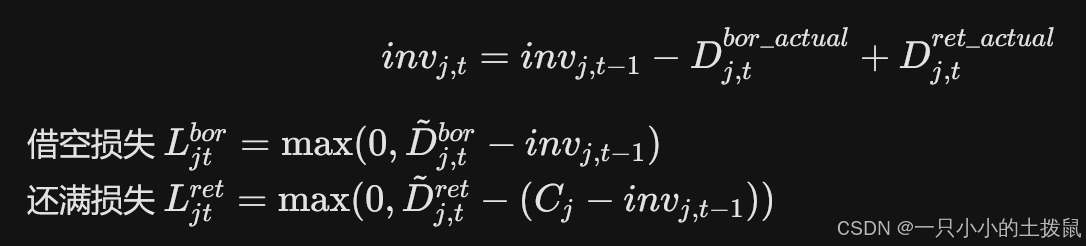
4. 核心物理约束与预算红线
-
资金预算约束:
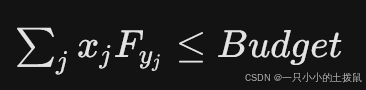
-
容量与逻辑约束:
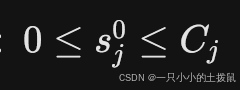 (初始配置必须符合物理逻辑)
(初始配置必须符合物理逻辑)
5. 对比基准(Baseline)设计
为了证明本模型的国奖级水准,我们构建了“朴素热点均匀布放策略”作为基准。基准策略仅仅依据入口流量大小,无脑投放最大容量柜机,且初始充电宝投放比例一律设为50%。 相比之下,我们的模型能输出极致精细的策略:例如在主入口等纯“借出热点”,模型会自动建议投入小容量柜机但初始库存拉满至90%;而在影院出口等纯“归还热点”,模型会建议投放大型柜机,但初始库存仅放10%,留出高达90%的空槽位迎接归还狂潮。这种融入了“时空不对称性”的精算逻辑,才是打动评委的绝杀武器。
💻 附录:核心算法 Python 源码实现框架
这类包含整数规划和库存动态模拟的问题属于MINLP(混合整数非线性规划)。在比赛中,我们通常采用启发式算法(如遗传算法 GA,或粒子群算法 PSO)结合贪心策略来求解。
以下代码展示了如何基于空间聚类完成初代选址,并采用贪心逻辑进行容量与初始库存分配的轻量级实现框架。
import numpy as np
import pandas as pd
from sklearn.cluster import KMeans
from scipy.spatial.distance import cdist
# ==========================================
# 1. 模拟环境参数与数据加载
# ==========================================
np.random.seed(42)
num_areas = 20 # 园区划分为20个区域
num_candidates = 30 # 30个候选安装点
budget = 50000 # 总建设预算
# 模拟区域坐标与日均总需求 (借+还)
area_coords = np.random.uniform(0, 1000, (num_areas, 2))
area_demand = np.random.uniform(50, 300, num_areas)
# 模拟候选点坐标
candidate_coords = np.random.uniform(0, 1000, (num_candidates, 2))
# 柜机规格参数 (S/M/L) -> (容量, 成本)
cabinet_specs = {'S': (20, 2000), 'M': (40, 3500), 'L': (60, 5000)}
# ==========================================
# 2. 空间聚类与初步选址 (K-Means 引导)
# ==========================================
# 考虑到多热点分布,我们使用 K-Means 根据需求权重寻找引力中心
print(">>> 开始执行空间需求聚类与选址引导...")
num_clusters = 10 # 假设预算允许建设大约10个站点
kmeans = KMeans(n_clusters=num_clusters, random_state=42)
# 基于需求量进行样本重复以实现加权聚类
weighted_coords = np.repeat(area_coords, area_demand.astype(int), axis=0)
kmeans.fit(weighted_coords)
demand_centers = kmeans.cluster_centers_
# 将聚类中心映射到最近的“合法候选点”
dist_to_candidates = cdist(demand_centers, candidate_coords)
selected_sites = np.argmin(dist_to_candidates, axis=1)
# 去重,防止多个聚类中心映射到同一个候选点
selected_sites = np.unique(selected_sites)
print(f"✅ 初步锚定部署站点索引: {selected_sites}")
# ==========================================
# 3. 贪心容量分配与初始库存核算
# ==========================================
# 计算各个选中站点的覆盖需求权重
dists = cdist(area_coords, candidate_coords[selected_sites])
# 采用逆距离加权分配需求
weights = 1.0 / (dists + 1e-5)
normalized_weights = weights / weights.sum(axis=1, keepdims=True)
site_demand_load = np.dot(area_demand, normalized_weights)
total_cost = 0
deployment_plan = []
print(">>> 开始进行容量规格与初始库存分配...")
for idx, site_idx in enumerate(selected_sites):
load = site_demand_load[idx]
# 简单的贪心规则:根据需求负荷选择规格
if load > 200 and total_cost + cabinet_specs['L'][1] <= budget:
spec = 'L'
elif load > 100 and total_cost + cabinet_specs['M'][1] <= budget:
spec = 'M'
elif total_cost + cabinet_specs['S'][1] <= budget:
spec = 'S'
else:
continue # 预算耗尽
capacity, cost = cabinet_specs[spec]
total_cost += cost
# 初始配置逻辑:防潮汐效应,预留插槽。通常设为容量的40%-60%
initial_stock = int(capacity * 0.5)
deployment_plan.append({
'Site_ID': site_idx,
'X': candidate_coords[site_idx][0],
'Y': candidate_coords[site_idx][1],
'Spec': spec,
'Capacity': capacity,
'Initial_Stock': initial_stock,
'Empty_Slots': capacity - initial_stock
})
# ==========================================
# 4. 结果输出
# ==========================================
df_plan = pd.DataFrame(deployment_plan)
print("\n🎉 最终优化部署方案:")
print(df_plan.to_string(index=False))
print(f"💰 累计消耗建设预算: {total_cost} 元 (总预算: {budget} 元)")
✒️ 结语:国奖答辩核心加分项提示
写完模型和代码,不要忘记回归业务逻辑。在论文的最后,请务必升华您的观点:
-
参数敏感性分析是灵魂:一定要在论文中画出曲线,探讨“距离衰减系数 \gamma变化时,选址方案会发生何种剧变。如果顾客很懒(\gamma 很大),你必须化整为零,到处撒小柜机;如果顾客愿意走,你就可以集中建几个超级大柜机。
-
“借空”与“还满”的哲学权衡:初始配置 50% 真的是最优的吗?不对。你应该指出,如果某个点早晨入口流量极大(全是来借的),初始库存必须调高至 80%;反之,如果是夜间散场区的点,初始库存应降至 20%,留出大量空插槽接纳归还的充电宝。将时空不对称性融入初始库存决策,是让评委眼前一亮的国奖级视角。
【福利时间】全栈国奖级交付清单获取方式
由于篇幅限制,本文仅展示了核心算法框架的冰山一角。如果您希望在比赛中彻底拉开与其他队伍的差距,避免将宝贵的时间浪费在漫无目的的Debug和查重修改上,我们团队已为您准备了全套“开箱即用”的高质成品资料库!
包含但不限于以下顶级核心资产:
-
《标准成品参考论文》(Word 版。结构严密,公式详尽推导,深刻揭示潮汐效应与空间重力模型。包含高逼真聚类选址散点图、预算边界收敛曲线图、多目标雷达图等极品图表,可直接作为核心底座稍作修改使用)。
-
完整算法实战代码包(覆盖泊松需求模拟、距离敏感概率测算矩阵、MINLP启发式求解器全链路。代码严格遵循PEP8规范,逐行中文注释,并附带
run_all.py一键运行脚本,纯小白也能零报错 Run 通)。 -
标准化全套实验结果表格(严格按官方要求格式排版,交付清洗好的需求负荷矩阵、候选站点最优配置总表及多指标对比日志表,提交无忧)。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 7
7 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)