LLMDet:在大型语言模型的监督下学习强开放词汇目标检测器
摘要
最近的开放词汇检测器利用丰富的区域级标注数据取得了令人满意的性能。在这项工作中,我们表明,通过为每张图像生成图像级别的详细字幕,开放词汇检测器与大型语言模型共同训练可以进一步提高性能。为了实现这一目标,我们首先收集了一个数据集GroundingCap-1M,其中每个图像都伴随着相关的接地标签和图像级详细说明。有了这个数据集,我们对一个开放词汇检器进行了调,其训练目标包括一个标准的接地损失和一个标题生成损失。我们利用大型语言模型为每个感趣的区域生成区域级短标题,并为整个图像生成图像级长标题。在大型语言模型的监督下,得到的检测器LLMDet的性能明显优于基线,具有优越的开放词汇能力。此外,我们表明改进的LLMDet可以反过来构建更强大的大型多模态模型,实现互利。
1、代码和数据集
1.1 代码地址:https: //github.com/iSEE-Laboratory/LLMDet
1.2 数据集:GroundingCap-1M
我们首先收集了一个数据集GroundingCap-1M,其中每个图像都伴随着相关的接地标签和图像级详细说明。有了这个数据集,我们对一个开放词汇检测器进行了微调,其训练目标包括一个标准的接地损失和一个标题生成损失。
GroundingCap-1M中的每个元素都被表述为一个四元组,包含一个图像、一个简短的接地文本、映射到接地文本中的短语的一些带注释的边界框和一个长而详细的图像级标题。

2、 文章要解决的问题
CapDet和DetCLIPv3对每个对象使用简短的标题,例如粗描述和分层类标签,这些都是粗粒度的、个体的,并且缺乏对象之间的关联。或者,包含丰富细节和对图像的全面理解的长图像级标题,比短区域级描述提供了更多的信息,这促使我们探索长详细图像级标题可以给开放词汇检测器带来哪些优势。
3、 提出的创新点
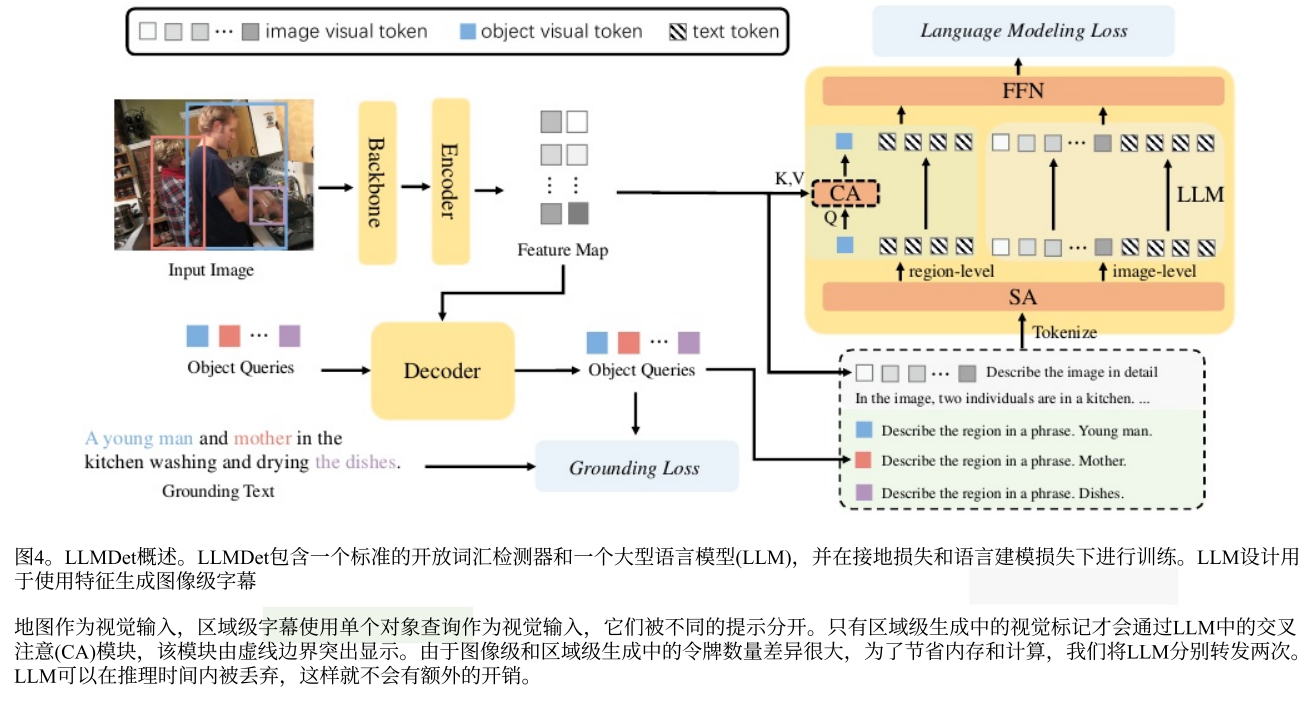
我们提出了LLMDet,它训练一个具有标准接地目标和标题生成目标的开放词汇检测器。一个大型语言模型(LLM)被附加到检测器上,将来自检测器的图像特征和区域特征作为输入,并分别预测图像级别的长详细字幕和区域级别的短短语。
我们利用大型语言模型(LLM)基于预训练的基于检测的开放词汇检测器生成字幕。由于检测器和LLM是分开预训练的,我们首先训练一个投影仪,按照训练大型多模态模型的常用做法,将视觉特征从检测器映射到LLM的输入空间。我们将来自检测器编码器的p5特征映射作为LLM的输入,并要求LLM在语言建模损失的监督下生成完整的图像标题。在这一步中,只有投影仪是可调的(图3中的第1步)。在预对准之后,检测器、投影仪和LLM以端到端的方式进行微调(图3中的步骤2)。
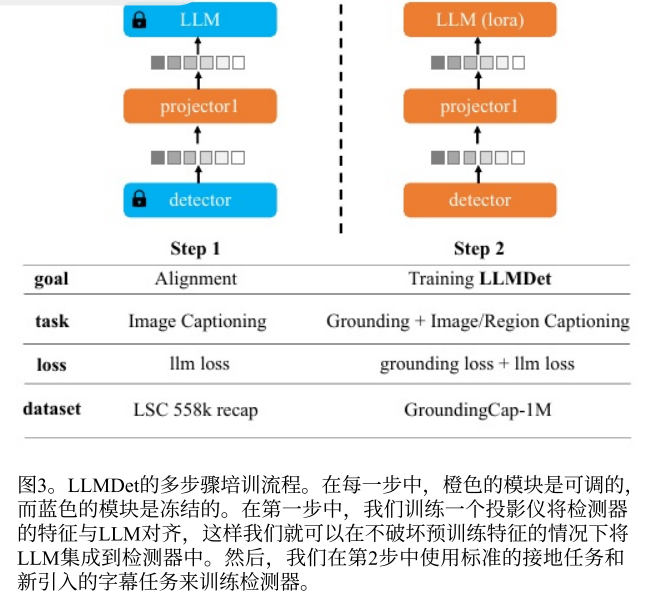
除了原始的接地任务,包括词-区域对齐损失Lalign和框回归损失Lbox,我们还引入了两个任务:图像级字幕生成和区域级字幕生成。
在图像级标题生成任务中,语言模型将检测器的特征映射作为视觉输入,并输出相应的在GroundingCap-1M中标注的长详细标题。遵循训练大型多模态模型的常用做法,我们以对话格式组织LLM的输入数据,其中包括系统消息、用户输入和答案。用户输入包含来自检测器和提示的视觉特征,例如详细描述图像。答案是GroundingCap-1M的说明文字。LLM的目标是在标准语言建模损失Limagelm的监督下,根据用户输入输出答案。由于输出的答案包含各种细节和对图像的全面理解,因此应该在视觉特征中对这些视觉线索进行建模,以便LLM可以最大限度地减少训练损失并正确生成字幕。
4、结论和不足
在大型语言模型的监督下,得到的检测器LLMDet的性能明显优于基线,具有优越的开放词汇能力。此外,我们表明改进的LLMDet可以反过来构建更强大的大型多模态模型,实现互利。
我们探索了一个新的训练目标来提高现有开放词汇检测器的性能。通过利用大型语言模型来生成图像级的详细说明和区域级的粗接地短语,检测器从详细说明中接收到更多的信息和对图像的更全面的理解,并构建丰富的视觉语言表示。由此产生的探测器LLMDet在广泛的基准测试中实现了最先进的性能。我们还表明,改进的LLMDet可以反过来构建强大的大型多模态模型,实现互利。

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 5
5 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)