Dify知识库文件处理链路优化:从上传到检索的稳定闭环方案解析!
本文针对Dify知识库建设中常见的文件处理链路问题,提出了一套稳定高效的解决方案。方案采用Dify上传工作流、FastAPI后端与MinIO对象存储,实现了从文件上传到检索回链的完整闭环。文章详细阐述了如何解决联调中的常见错误(如422、401、no_files等),并通过异步化处理、请求兼容性、可观测日志等设计要点提升系统稳定性。同时,文章还分享了联调过程中踩过的典型坑及解决方法,并提出了先稳定再扩展的工程策略。该方案将上传链路从临时脚本升级为工程组件,实现了知识库问答的可追溯,为构建高质量的知识库系统提供了重要参考。
很多团队在做 Dify 知识库时,最先遇到的不是模型问题,而是文件处理链路问题:上传能不能稳定成功?分段能不能自动完成?回答能不能回溯到原文件?线上报错能不能快速定位?
这篇分享从技术视角总结我们落地的一套方案:Dify 上传工作流 + FastAPI 后端 + MinIO 对象存储,实现从上传到检索回链的完整闭环,并解决了联调中最常见的 422、401、no_files、序列化异常和分段依赖异常。
一、我们到底在解决什么技术问题?
在企业知识库场景中,常见痛点不是上传一次成功,而是持续稳定可复现:
-
上传成功但知识库没分段
文件进入系统了,但 pipeline 没跑通或分段失败,检索不到内容。
-
对象存储与文档断链
MinIO 里有文件,Dify 里有文档,但两者没有可靠关联,问答无法回溯原文。
-
跨系统参数脆弱
Dify Workflow、HTTP Request、FastAPI、Dify Dataset API 多段串联,任一字段名偏差就会 422/400。
-
线上排障成本高
没有请求快照与结构化日志时,只能靠猜测是没传文件、key 无效,还是 Dify 分段服务没配。
我们的目标是把这条链路做成工程能力:可用、可观测、可定位、可扩展。
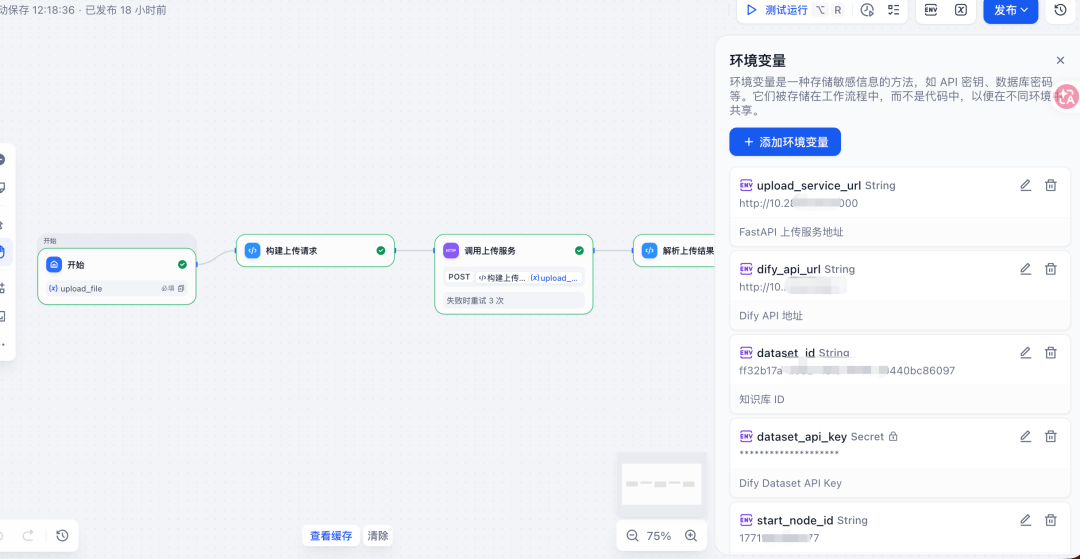
二、总体架构与链路设计
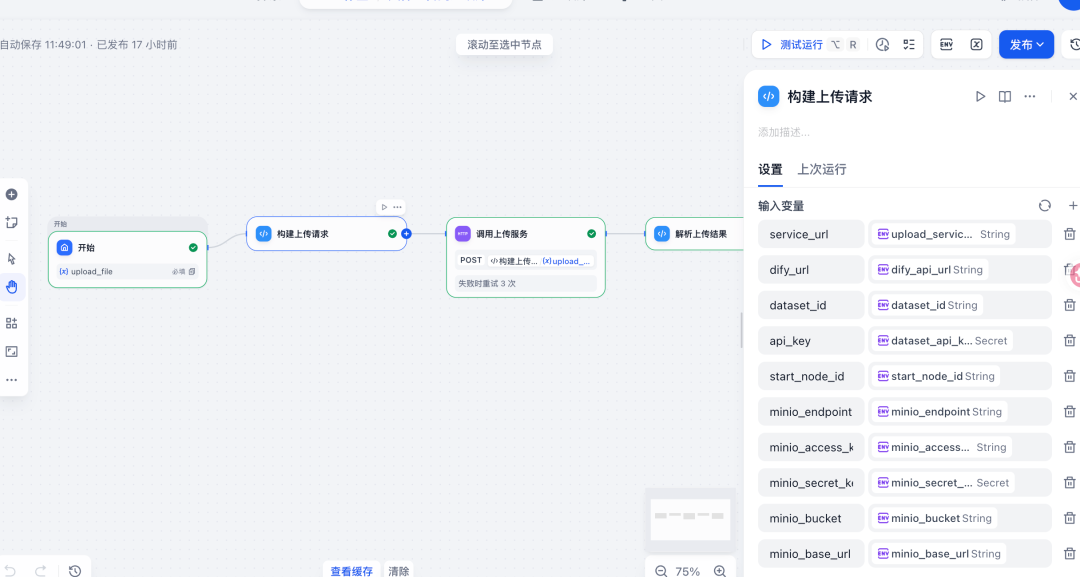
1 上传入口:Dify Workflow
-
用户在 Dify 上传文件
-
Workflow 调用后端 /upload 接口,立即拿到 task_id
-
采用快返加异步处理模式,避免前端阻塞和超时
2 处理核心:FastAPI 服务
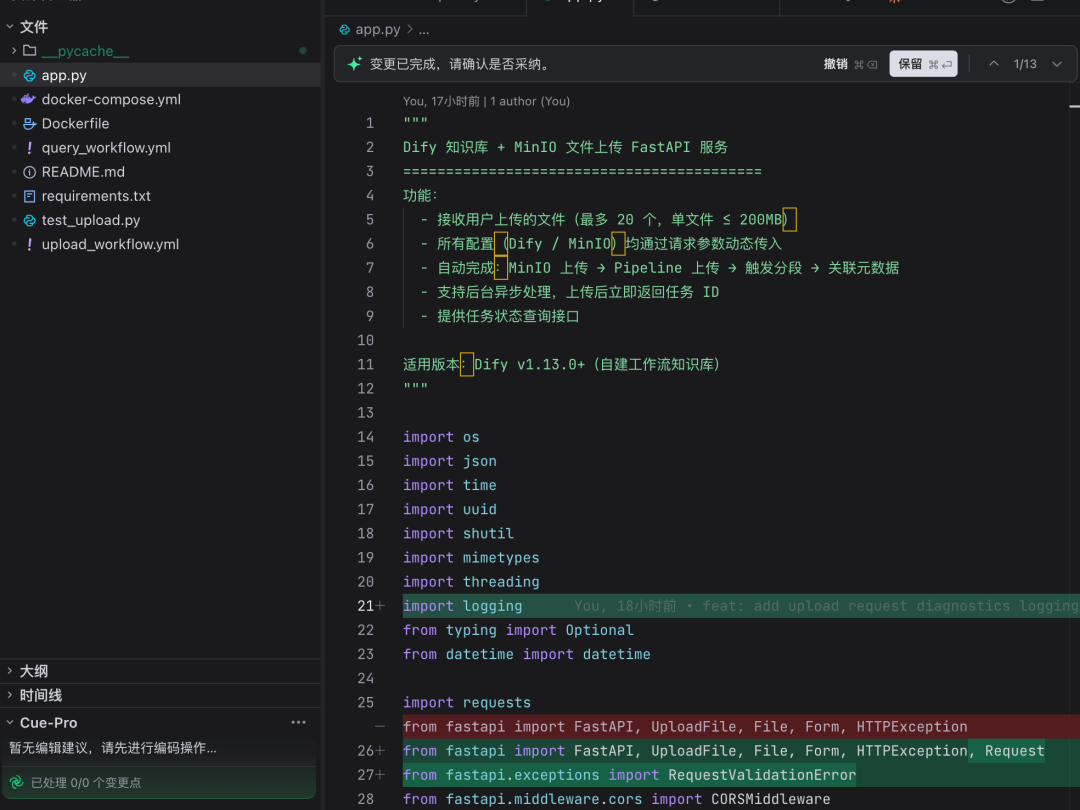
后端在后台线程执行以下步骤:
-
上传文件到 MinIO
-
调 Dify pipeline 文件上传接口
-
触发 pipeline 运行
-
轮询查找对应 document_id
-
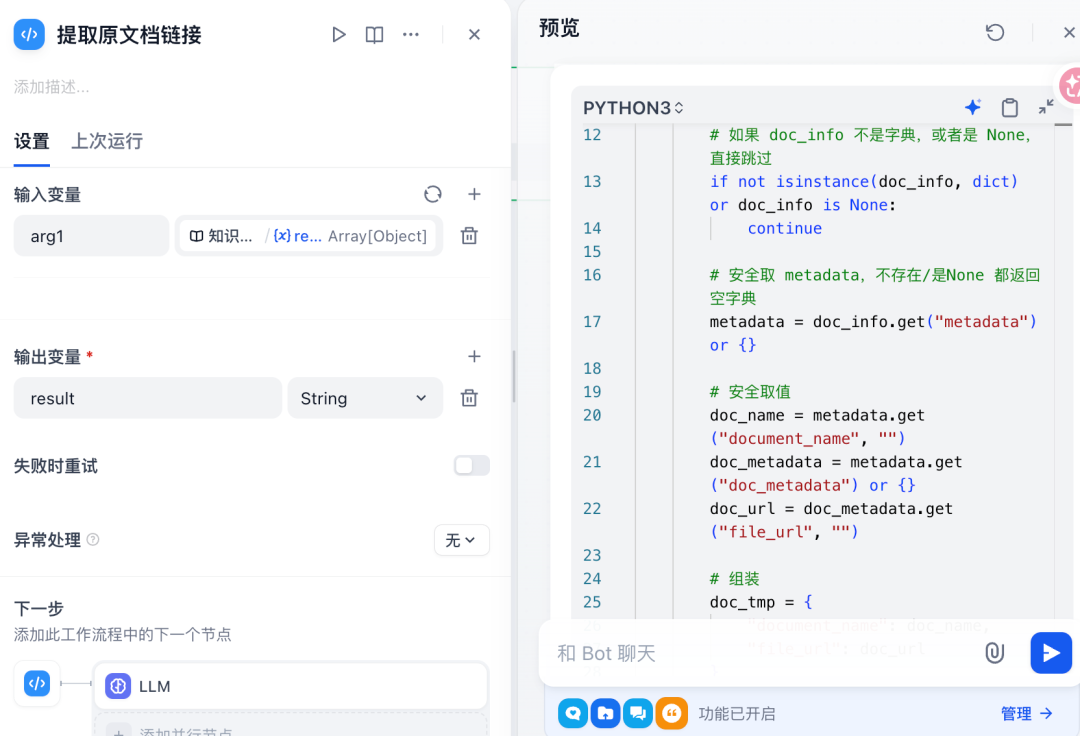
写入元数据(如 file_url)到文档
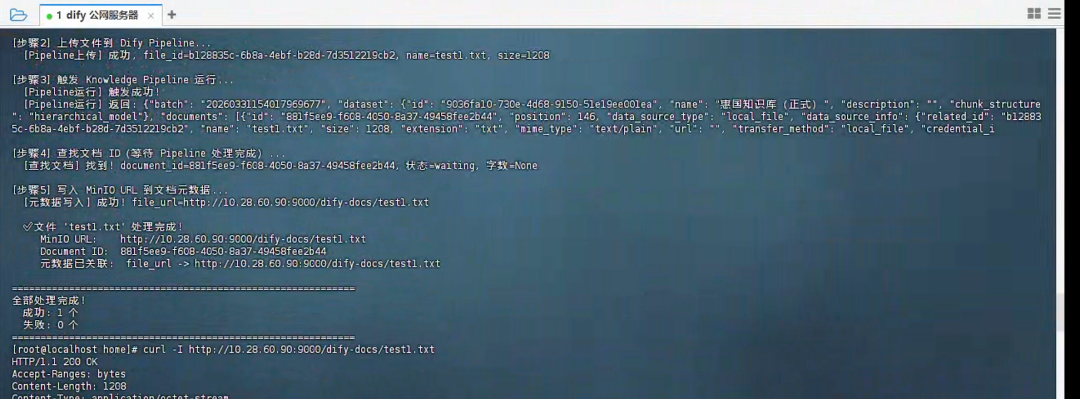
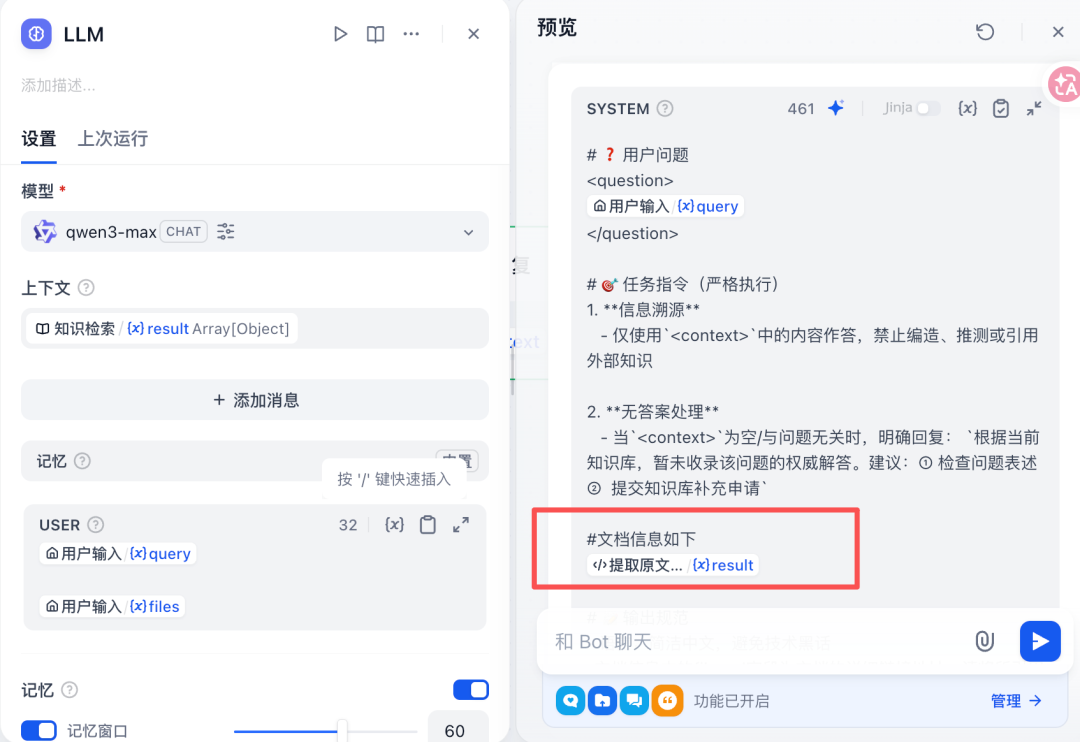
3 查询出口:Dify Query Workflow
-
检索知识片段
-
从 metadata 中提取 file_url
-
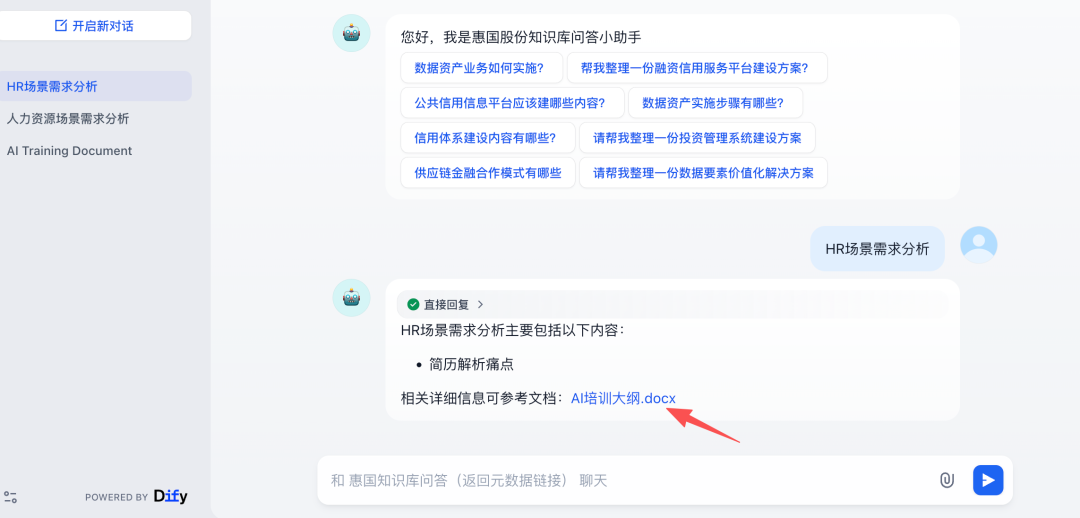
在回答中附参考文件链接,实现答案可追溯
三、实现要点:为什么这套方案更稳
1 上传接口异步化(任务化)
/upload 只做参数校验和文件落盘,快速返回 task_id。
真正耗时步骤(对象存储、pipeline、轮询)在后台执行,配合 /task/{task_id} 查询状态。
收益:接口稳定,调用端体验更好,失败可追踪。
2 请求兼容与输入清洗
联调阶段最常见的问题来自字段格式脏数据:
- URL 带反引号和前后空格
- secret 变量被误传为掩码
- 文件字段名与实际绑定不一致
服务端增加了:
- 参数清洗(去空格、去反引号)
- 掩码 key 防呆校验(如星号直接拒绝)
- 兼容不同文件字段命名(files/file/upload_file/upload_files)
3 可观测日志
服务端输出请求快照(敏感字段脱敏):
- 收到哪些文本字段
- 收到哪些文件字段
- 哪一步失败(missing_fields / no_files / masked_api_key / pipeline 错误)
收益:线上问题能快速定性,不再盲查。
四、联调中踩过的典型坑(及结论)
坑 1:422 Field required: files
现象:Dify 报调用失败,后端提示缺少 files。
根因:HTTP Request 节点没真正发送文件 part。
结论:form-data 必须配置 key=files 且 type=file,并直接绑定 Start 节点文件变量。
坑 2:Type is not JSON serializable: File
现象:工作流在 Code 节点报错,流程中断。
根因:把文件对象传入 Code 节点,Dify 尝试 JSON 序列化失败。
结论:文件对象不要走 Code 节点,直接在 HTTP 节点绑定。
坑 3:401 Access token is invalid
现象:任务创建成功,但后台在初始化元数据阶段失败。
根因:dataset_api_key 无效,或传入了掩码值。
结论:重新填写真实 key(不是页面展示的星号),并发布工作流。
坑 4:UNSTRUCTURED_API_URL must be set
现象:部分文件能处理,部分文件无法自动分段。
根因:Dify 分段依赖的 Unstructured 服务未配置。
结论:在 Dify api/worker 配置 UNSTRUCTURED_API_URL 并重启。
五、当前工程策略:先稳定,再扩展
为了优先稳定交付,当前工作流采用单文件上传策略。
多文件场景建议两种方式:
- Dify 侧迭代节点逐文件调用
- 用户分次上传(每次一个文件)
价值:这样能显著降低 multipart 文件绑定的复杂度,提升线上稳定性和可维护性。
六、这套方案的价值(技术视角)
-
把上传链路从临时脚本变成工程组件
有接口、有任务、有状态、有日志。
-
把可用性升级为可运维
出错不是失败,而是可定位、可修复、可复现。
-
把知识库问答从黑盒变成可追溯系统
每条答案都能附带来源文件链接,满足业务审计与可信回答要求。
七、结语
RAG 的上限往往不取决于模型,而取决于数据链路工程质量。
真正可生产的知识库系统,不是跑通一次,而是每次都能跑通、出了问题能快速定位。
如果你也在做 Dify 企业知识库,这条链路建议优先工程化:
先打通上传闭环,再优化分段质量,最后做召回与答案策略。
2026年AI行业最大的机会,毫无疑问就在应用层!
字节跳动已有7个团队全速布局Agent
大模型岗位暴增69%,年薪破百万!
腾讯、京东、百度开放招聘技术岗,80%与AI相关……
如今,超过60%的企业都在推进AI产品落地,而真正能交付项目的 大模型应用开发工程师 **,**却极度稀缺!
落地AI应用绝对不是写几个prompt,调几个API就能搞定的,企业真正需要的,是能搞定这三项核心能力的人:
✅RAG:融入外部信息,修正模型输出,给模型装靠谱大脑
✅Agent智能体:让AI自主干活,通过工具调用(Tools)环境交互,多步推理完成复杂任务。比如做智能客服等等……
✅微调:针对特定任务优化,让模型适配业务
目前,脉脉上有超过1000家企业发布大模型相关岗位,人工智能岗平均月薪7.8w!实习生日薪高达4000!远超其他行业收入水平!
技术的稀缺性,才是你「值钱」的关键!
具备AI能力的程序员,比传统开发高出不止一截!有的人早就转行AI方向,拿到百万年薪!👇🏻👇🏻

AI浪潮,正在重构程序员的核心竞争力!现在入场,仍是最佳时机!
我把大模型的学习全流程已经整理📚好了!抓住AI时代风口,轻松解锁职业新可能,希望大家都能把握机遇,实现薪资/职业跃迁~
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

⭐️从大模型微调到AI Agent智能体搭建
剖析AI技术的应用场景,用实战经验落地AI技术。从GPT到最火的开源模型,让你从容面对AI技术革新!
大模型微调
-
掌握主流大模型(如DeepSeek、Qwen等)的微调技术,针对特定场景优化模型性能。
-
学习如何利用领域数据(如制造、医药、金融等)进行模型定制,提升任务准确性和效率。
RAG应用开发
- 深入理解检索增强生成(Retrieval-Augmented Generation, RAG)技术,构建高效的知识检索与生成系统。
- 应用于垂类场景(如法律文档分析、医疗诊断辅助、金融报告生成等),实现精准信息提取与内容生成。
AI Agent智能体搭建
- 学习如何设计和开发AI Agent,实现多任务协同、自主决策和复杂问题解决。
- 构建垂类场景下的智能助手(如制造业中的设备故障诊断Agent、金融领域的投资分析Agent等)。

如果你也有以下诉求:
快速链接产品/业务团队,参与前沿项目
构建技术壁垒,从竞争者中脱颖而出
避开35岁裁员危险期,顺利拿下高薪岗
迭代技术水平,延长未来20年的新职业发展!
……
那这节课你一定要来听!
因为,留给普通程序员的时间真的不多了!
立即扫码,即可免费预约
「AI技术原理 + 实战应用 + 职业发展」
「大模型应用开发实战公开课」
👇👇

👍🏻还有靠谱的内推机会+直聘权益!!
完课后赠送:大模型应用案例集、AI商业落地白皮书

AtomGit 是由开放原子开源基金会联合 CSDN 等生态伙伴共同推出的新一代开源与人工智能协作平台。平台坚持“开放、中立、公益”的理念,把代码托管、模型共享、数据集托管、智能体开发体验和算力服务整合在一起,为开发者提供从开发、训练到部署的一站式体验。
更多推荐


 9
9 0
0- 0



 已为社区贡献139条内容
已为社区贡献139条内容

所有评论(0)